SentenceTransformer based on sbintuitions/sarashina-embedding-v2-1b
This is a sentence-transformers model finetuned from sbintuitions/sarashina-embedding-v2-1b on the jsts dataset. It maps sentences & paragraphs to a 1792-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
Model Details
Model Description
- Model Type: Sentence Transformer
- Base model: sbintuitions/sarashina-embedding-v2-1b
- Maximum Sequence Length: 8192 tokens
- Output Dimensionality: 1792 dimensions
- Similarity Function: Cosine Similarity
- Training Dataset:
- Language: jpn
Model Sources
Full Model Architecture
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False, 'architecture': 'LlamaModel'})
(1): Pooling({'word_embedding_dimension': 1792, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': True, 'include_prompt': False})
)
Usage
Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
pip install -U sentence-transformers
Then you can load this model and run inference.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("kushalc1/sarashina-embedding-v2-1b-jsts-matryoshka")
sentences = [
'樹木に囲まれた芝生の上に三頭のキリンが立っています。',
'芝生の上に数頭のキリンが歩いています。',
'茶色のテーブルの上にピザと飲み物が置かれています。',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
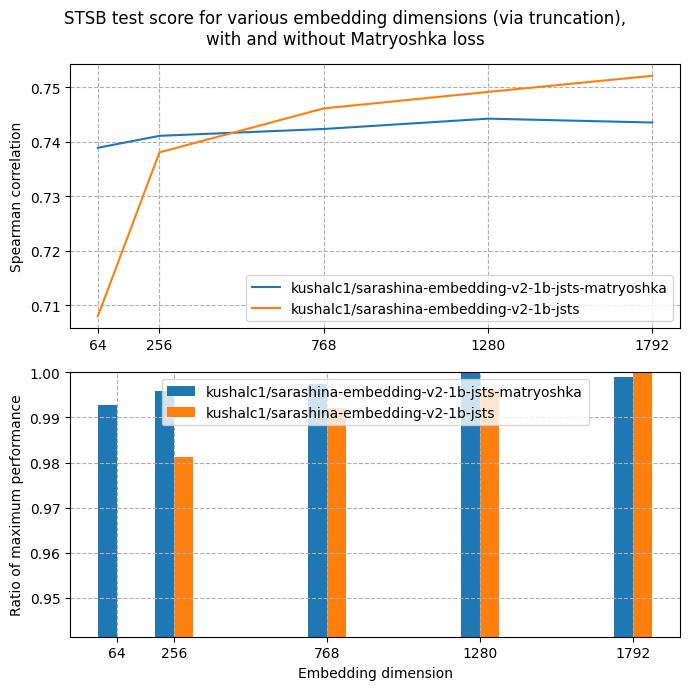
Evaluation
Metrics
Semantic Similarity
| Metric |
sts-dev-1792 |
sts-test-1792 |
| pearson_cosine |
0.8125 |
0.8124 |
| spearman_cosine |
0.7521 |
0.7521 |
Semantic Similarity
| Metric |
sts-dev-1280 |
sts-test-1280 |
| pearson_cosine |
0.8099 |
0.8099 |
| spearman_cosine |
0.7492 |
0.7491 |
Semantic Similarity
| Metric |
sts-dev-768 |
sts-test-768 |
| pearson_cosine |
0.8058 |
0.8057 |
| spearman_cosine |
0.7462 |
0.7461 |
Semantic Similarity
| Metric |
sts-dev-256 |
sts-test-256 |
| pearson_cosine |
0.7946 |
0.7945 |
| spearman_cosine |
0.7381 |
0.738 |
Semantic Similarity
| Metric |
sts-dev-64 |
sts-test-64 |
| pearson_cosine |
0.753 |
0.7531 |
| spearman_cosine |
0.708 |
0.708 |
Training Details
Training Dataset
jsts
Evaluation Dataset
jsts
Training Hyperparameters
Non-Default Hyperparameters
eval_strategy: stepsper_device_train_batch_size: 16per_device_eval_batch_size: 16num_train_epochs: 4warmup_ratio: 0.1fp16: True
All Hyperparameters
Click to expand
overwrite_output_dir: Falsedo_predict: Falseeval_strategy: stepsprediction_loss_only: Trueper_device_train_batch_size: 16per_device_eval_batch_size: 16per_gpu_train_batch_size: Noneper_gpu_eval_batch_size: Nonegradient_accumulation_steps: 1eval_accumulation_steps: Nonetorch_empty_cache_steps: Nonelearning_rate: 5e-05weight_decay: 0.0adam_beta1: 0.9adam_beta2: 0.999adam_epsilon: 1e-08max_grad_norm: 1.0num_train_epochs: 4max_steps: -1lr_scheduler_type: linearlr_scheduler_kwargs: {}warmup_ratio: 0.1warmup_steps: 0log_level: passivelog_level_replica: warninglog_on_each_node: Truelogging_nan_inf_filter: Truesave_safetensors: Truesave_on_each_node: Falsesave_only_model: Falserestore_callback_states_from_checkpoint: Falseno_cuda: Falseuse_cpu: Falseuse_mps_device: Falseseed: 42data_seed: Nonejit_mode_eval: Falseuse_ipex: Falsebf16: Falsefp16: Truefp16_opt_level: O1half_precision_backend: autobf16_full_eval: Falsefp16_full_eval: Falsetf32: Nonelocal_rank: 0ddp_backend: Nonetpu_num_cores: Nonetpu_metrics_debug: Falsedebug: []dataloader_drop_last: Falsedataloader_num_workers: 0dataloader_prefetch_factor: Nonepast_index: -1disable_tqdm: Falseremove_unused_columns: Truelabel_names: Noneload_best_model_at_end: Falseignore_data_skip: Falsefsdp: []fsdp_min_num_params: 0fsdp_config: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}fsdp_transformer_layer_cls_to_wrap: Noneaccelerator_config: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}parallelism_config: Nonedeepspeed: Nonelabel_smoothing_factor: 0.0optim: adamw_torch_fusedoptim_args: Noneadafactor: Falsegroup_by_length: Falselength_column_name: lengthddp_find_unused_parameters: Noneddp_bucket_cap_mb: Noneddp_broadcast_buffers: Falsedataloader_pin_memory: Truedataloader_persistent_workers: Falseskip_memory_metrics: Trueuse_legacy_prediction_loop: Falsepush_to_hub: Falseresume_from_checkpoint: Nonehub_model_id: Nonehub_strategy: every_savehub_private_repo: Nonehub_always_push: Falsehub_revision: Nonegradient_checkpointing: Falsegradient_checkpointing_kwargs: Noneinclude_inputs_for_metrics: Falseinclude_for_metrics: []eval_do_concat_batches: Truefp16_backend: autopush_to_hub_model_id: Nonepush_to_hub_organization: Nonemp_parameters: auto_find_batch_size: Falsefull_determinism: Falsetorchdynamo: Noneray_scope: lastddp_timeout: 1800torch_compile: Falsetorch_compile_backend: Nonetorch_compile_mode: Noneinclude_tokens_per_second: Falseinclude_num_input_tokens_seen: Falseneftune_noise_alpha: Noneoptim_target_modules: Nonebatch_eval_metrics: Falseeval_on_start: Falseuse_liger_kernel: Falseliger_kernel_config: Noneeval_use_gather_object: Falseaverage_tokens_across_devices: Falseprompts: Nonebatch_sampler: batch_samplermulti_dataset_batch_sampler: proportionalrouter_mapping: {}learning_rate_mapping: {}
Training Logs
| Epoch |
Step |
Training Loss |
Validation Loss |
sts-dev-1792_spearman_cosine |
sts-dev-1280_spearman_cosine |
sts-dev-768_spearman_cosine |
sts-dev-256_spearman_cosine |
sts-dev-64_spearman_cosine |
sts-test-1792_spearman_cosine |
sts-test-1280_spearman_cosine |
sts-test-768_spearman_cosine |
sts-test-256_spearman_cosine |
sts-test-64_spearman_cosine |
| 0.1284 |
100 |
0.9104 |
1.0803 |
0.7732 |
0.7742 |
0.7700 |
0.7659 |
0.7287 |
- |
- |
- |
- |
- |
| 0.2567 |
200 |
1.0621 |
1.1598 |
0.7208 |
0.7204 |
0.7198 |
0.7096 |
0.6787 |
- |
- |
- |
- |
- |
| 0.3851 |
300 |
1.2289 |
1.4808 |
0.6225 |
0.6305 |
0.6234 |
0.6154 |
0.5922 |
- |
- |
- |
- |
- |
| 0.5135 |
400 |
1.215 |
1.3408 |
0.6559 |
0.6527 |
0.6497 |
0.6473 |
0.6329 |
- |
- |
- |
- |
- |
| 0.6418 |
500 |
1.2991 |
1.4541 |
0.6300 |
0.6324 |
0.6314 |
0.6276 |
0.5959 |
- |
- |
- |
- |
- |
| 0.7702 |
600 |
1.2537 |
1.3891 |
0.6418 |
0.6416 |
0.6422 |
0.6389 |
0.6019 |
- |
- |
- |
- |
- |
| 0.8986 |
700 |
1.2248 |
1.2778 |
0.6817 |
0.6855 |
0.6832 |
0.6800 |
0.6562 |
- |
- |
- |
- |
- |
| 1.0270 |
800 |
1.1772 |
1.3947 |
0.6674 |
0.6666 |
0.6652 |
0.6618 |
0.6392 |
- |
- |
- |
- |
- |
| 1.1553 |
900 |
1.119 |
1.2291 |
0.7086 |
0.7066 |
0.7018 |
0.7032 |
0.6758 |
- |
- |
- |
- |
- |
| 1.2837 |
1000 |
1.0503 |
1.1655 |
0.7183 |
0.7163 |
0.7135 |
0.7130 |
0.6961 |
- |
- |
- |
- |
- |
| 1.4121 |
1100 |
1.0729 |
1.1550 |
0.7333 |
0.7340 |
0.7299 |
0.7260 |
0.6955 |
- |
- |
- |
- |
- |
| 1.5404 |
1200 |
1.0952 |
1.3186 |
0.6753 |
0.6790 |
0.6728 |
0.6738 |
0.6417 |
- |
- |
- |
- |
- |
| 1.6688 |
1300 |
1.0284 |
1.1816 |
0.7146 |
0.7131 |
0.7071 |
0.7096 |
0.6786 |
- |
- |
- |
- |
- |
| 1.7972 |
1400 |
1.0248 |
1.1495 |
0.7282 |
0.7270 |
0.7206 |
0.7196 |
0.6913 |
- |
- |
- |
- |
- |
| 1.9255 |
1500 |
1.0138 |
1.1371 |
0.7264 |
0.7240 |
0.7175 |
0.7130 |
0.6738 |
- |
- |
- |
- |
- |
| 2.0539 |
1600 |
0.9739 |
1.1577 |
0.7173 |
0.7143 |
0.7088 |
0.7142 |
0.6881 |
- |
- |
- |
- |
- |
| 2.1823 |
1700 |
0.7908 |
1.1627 |
0.7358 |
0.7341 |
0.7300 |
0.7278 |
0.7045 |
- |
- |
- |
- |
- |
| 2.3107 |
1800 |
0.8877 |
1.1396 |
0.7312 |
0.7303 |
0.7263 |
0.7219 |
0.6942 |
- |
- |
- |
- |
- |
| 2.4390 |
1900 |
0.8403 |
1.1868 |
0.7395 |
0.7379 |
0.7346 |
0.7324 |
0.7167 |
- |
- |
- |
- |
- |
| 2.5674 |
2000 |
0.8558 |
1.1481 |
0.7424 |
0.7411 |
0.7379 |
0.7373 |
0.7143 |
- |
- |
- |
- |
- |
| 2.6958 |
2100 |
0.8304 |
1.1377 |
0.7391 |
0.7366 |
0.7314 |
0.7287 |
0.7075 |
- |
- |
- |
- |
- |
| 2.8241 |
2200 |
0.8053 |
1.0874 |
0.7384 |
0.7367 |
0.7313 |
0.7284 |
0.7153 |
- |
- |
- |
- |
- |
| 2.9525 |
2300 |
0.8071 |
1.0720 |
0.7504 |
0.7487 |
0.7436 |
0.7372 |
0.7205 |
- |
- |
- |
- |
- |
| 3.0809 |
2400 |
0.6082 |
1.1407 |
0.7533 |
0.7521 |
0.7480 |
0.7403 |
0.7195 |
- |
- |
- |
- |
- |
| 3.2092 |
2500 |
0.5183 |
1.1555 |
0.7562 |
0.7546 |
0.7505 |
0.7437 |
0.7124 |
- |
- |
- |
- |
- |
| 3.3376 |
2600 |
0.5311 |
1.1923 |
0.7494 |
0.7476 |
0.7434 |
0.7382 |
0.7084 |
- |
- |
- |
- |
- |
| 3.4660 |
2700 |
0.4914 |
1.1752 |
0.7446 |
0.7416 |
0.7376 |
0.7326 |
0.7034 |
- |
- |
- |
- |
- |
| 3.5944 |
2800 |
0.5486 |
1.1924 |
0.7472 |
0.7439 |
0.7400 |
0.7313 |
0.6989 |
- |
- |
- |
- |
- |
| 3.7227 |
2900 |
0.4702 |
1.1903 |
0.7526 |
0.7497 |
0.7466 |
0.7380 |
0.7075 |
- |
- |
- |
- |
- |
| 3.8511 |
3000 |
0.4674 |
1.1749 |
0.7519 |
0.7487 |
0.7459 |
0.7378 |
0.7071 |
- |
- |
- |
- |
- |
| 3.9795 |
3100 |
0.4696 |
1.1795 |
0.7521 |
0.7492 |
0.7462 |
0.7381 |
0.7080 |
- |
- |
- |
- |
- |
| -1 |
-1 |
- |
- |
- |
- |
- |
- |
- |
0.7521 |
0.7491 |
0.7461 |
0.7380 |
0.7080 |
Framework Versions
- Python: 3.12.6
- Sentence Transformers: 5.2.0
- Transformers: 4.56.0
- PyTorch: 2.8.0+cu129
- Accelerate: 1.10.1
- Datasets: 4.4.2
- Tokenizers: 0.22.0
Citation
BibTeX
Sentence Transformers
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
MultipleNegativesRankingLoss
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
