Disclaimer: This model was trained for research only\n\n> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)\n\n> Made with <span style=\"color: #e25555;\">♥</span> in Spain"},"model_labels":{"kind":"list like","value":["dyed-lifted-polyps","dyed-resection-margins","esophagitis","normal-cecum","normal-pylorus","normal-z-line","polyps","ulcerative-colitis"],"string":"[\n \"dyed-lifted-polyps\",\n \"dyed-resection-margins\",\n \"esophagitis\",\n \"normal-cecum\",\n \"normal-pylorus\",\n \"normal-z-line\",\n \"polyps\",\n \"ulcerative-colitis\"\n]","isConversational":false}}},{"rowIdx":83,"cells":{"model_id":{"kind":"string","value":"nateraw/food"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# nateraw/food\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the nateraw/food101 dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.4501\n- Accuracy: 0.8913\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 128\n- eval_batch_size: 128\n- seed: 1337\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5.0\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| 0.8271 | 1.0 | 592 | 0.6070 | 0.8562 |\n| 0.4376 | 2.0 | 1184 | 0.4947 | 0.8691 |\n| 0.2089 | 3.0 | 1776 | 0.4876 | 0.8747 |\n| 0.0882 | 4.0 | 2368 | 0.4639 | 0.8857 |\n| 0.0452 | 5.0 | 2960 | 0.4501 | 0.8913 |\n\n\n### Framework versions\n\n- Transformers 4.9.0.dev0\n- Pytorch 1.9.0+cu102\n- Datasets 1.9.1.dev0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["apple_pie","baby_back_ribs","bruschetta","waffles","caesar_salad","cannoli","caprese_salad","carrot_cake","ceviche","cheese_plate","cheesecake","chicken_curry","chicken_quesadilla","baklava","chicken_wings","chocolate_cake","chocolate_mousse","churros","clam_chowder","club_sandwich","crab_cakes","creme_brulee","croque_madame","cup_cakes","beef_carpaccio","deviled_eggs","donuts","dumplings","edamame","eggs_benedict","escargots","falafel","filet_mignon","fish_and_chips","foie_gras","beef_tartare","french_fries","french_onion_soup","french_toast","fried_calamari","fried_rice","frozen_yogurt","garlic_bread","gnocchi","greek_salad","grilled_cheese_sandwich","beet_salad","grilled_salmon","guacamole","gyoza","hamburger","hot_and_sour_soup","hot_dog","huevos_rancheros","hummus","ice_cream","lasagna","beignets","lobster_bisque","lobster_roll_sandwich","macaroni_and_cheese","macarons","miso_soup","mussels","nachos","omelette","onion_rings","oysters","bibimbap","pad_thai","paella","pancakes","panna_cotta","peking_duck","pho","pizza","pork_chop","poutine","prime_rib","bread_pudding","pulled_pork_sandwich","ramen","ravioli","red_velvet_cake","risotto","samosa","sashimi","scallops","seaweed_salad","shrimp_and_grits","breakfast_burrito","spaghetti_bolognese","spaghetti_carbonara","spring_rolls","steak","strawberry_shortcake","sushi","tacos","takoyaki","tiramisu","tuna_tartare"],"string":"[\n \"apple_pie\",\n \"baby_back_ribs\",\n \"bruschetta\",\n \"waffles\",\n \"caesar_salad\",\n \"cannoli\",\n \"caprese_salad\",\n \"carrot_cake\",\n \"ceviche\",\n \"cheese_plate\",\n \"cheesecake\",\n \"chicken_curry\",\n \"chicken_quesadilla\",\n \"baklava\",\n \"chicken_wings\",\n \"chocolate_cake\",\n \"chocolate_mousse\",\n \"churros\",\n \"clam_chowder\",\n \"club_sandwich\",\n \"crab_cakes\",\n \"creme_brulee\",\n \"croque_madame\",\n \"cup_cakes\",\n \"beef_carpaccio\",\n \"deviled_eggs\",\n \"donuts\",\n \"dumplings\",\n \"edamame\",\n \"eggs_benedict\",\n \"escargots\",\n \"falafel\",\n \"filet_mignon\",\n \"fish_and_chips\",\n \"foie_gras\",\n \"beef_tartare\",\n \"french_fries\",\n \"french_onion_soup\",\n \"french_toast\",\n \"fried_calamari\",\n \"fried_rice\",\n \"frozen_yogurt\",\n \"garlic_bread\",\n \"gnocchi\",\n \"greek_salad\",\n \"grilled_cheese_sandwich\",\n \"beet_salad\",\n \"grilled_salmon\",\n \"guacamole\",\n \"gyoza\",\n \"hamburger\",\n \"hot_and_sour_soup\",\n \"hot_dog\",\n \"huevos_rancheros\",\n \"hummus\",\n \"ice_cream\",\n \"lasagna\",\n \"beignets\",\n \"lobster_bisque\",\n \"lobster_roll_sandwich\",\n \"macaroni_and_cheese\",\n \"macarons\",\n \"miso_soup\",\n \"mussels\",\n \"nachos\",\n \"omelette\",\n \"onion_rings\",\n \"oysters\",\n \"bibimbap\",\n \"pad_thai\",\n \"paella\",\n \"pancakes\",\n \"panna_cotta\",\n \"peking_duck\",\n \"pho\",\n \"pizza\",\n \"pork_chop\",\n \"poutine\",\n \"prime_rib\",\n \"bread_pudding\",\n \"pulled_pork_sandwich\",\n \"ramen\",\n \"ravioli\",\n \"red_velvet_cake\",\n \"risotto\",\n \"samosa\",\n \"sashimi\",\n \"scallops\",\n \"seaweed_salad\",\n \"shrimp_and_grits\",\n \"breakfast_burrito\",\n \"spaghetti_bolognese\",\n \"spaghetti_carbonara\",\n \"spring_rolls\",\n \"steak\",\n \"strawberry_shortcake\",\n \"sushi\",\n \"tacos\",\n \"takoyaki\",\n \"tiramisu\",\n \"tuna_tartare\"\n]","isConversational":false}}},{"rowIdx":84,"cells":{"model_id":{"kind":"string","value":"nateraw/huggingpics-package-demo-2"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# huggingpics-package-demo-2\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.3761\n- Acc: 0.9403\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 4.0\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Acc |\n|:-------------:|:-----:|:----:|:---------------:|:------:|\n| 1.0328 | 1.0 | 24 | 0.9442 | 0.7463 |\n| 0.8742 | 2.0 | 48 | 0.7099 | 0.9403 |\n| 0.6451 | 3.0 | 72 | 0.5050 | 0.9403 |\n| 0.508 | 4.0 | 96 | 0.3761 | 0.9403 |\n\n\n### Framework versions\n\n- Transformers 4.12.3\n- Pytorch 1.9.0+cu111\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["corgi","husky","shibu inu"],"string":"[\n \"corgi\",\n \"husky\",\n \"shibu inu\"\n]","isConversational":false}}},{"rowIdx":85,"cells":{"model_id":{"kind":"string","value":"nateraw/huggingpics-package-demo"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# huggingpics-package-demo\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.3761\n- Acc: 0.9403\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 4.0\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Acc |\n|:-------------:|:-----:|:----:|:---------------:|:------:|\n| 1.0328 | 1.0 | 24 | 0.9442 | 0.7463 |\n| 0.8742 | 2.0 | 48 | 0.7099 | 0.9403 |\n| 0.6451 | 3.0 | 72 | 0.5050 | 0.9403 |\n| 0.508 | 4.0 | 96 | 0.3761 | 0.9403 |\n\n\n### Framework versions\n\n- Transformers 4.12.3\n- Pytorch 1.9.0+cu111\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["corgi","husky","shibu inu"],"string":"[\n \"corgi\",\n \"husky\",\n \"shibu inu\"\n]","isConversational":false}}},{"rowIdx":86,"cells":{"model_id":{"kind":"string","value":"nateraw/pasta-shapes"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# pasta-shapes\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.3761\n- Acc: 0.9403\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 4.0\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Acc |\n|:-------------:|:-----:|:----:|:---------------:|:------:|\n| 1.0328 | 1.0 | 24 | 0.9442 | 0.7463 |\n| 0.8742 | 2.0 | 48 | 0.7099 | 0.9403 |\n| 0.6451 | 3.0 | 72 | 0.5050 | 0.9403 |\n| 0.508 | 4.0 | 96 | 0.3761 | 0.9403 |\n\n\n### Framework versions\n\n- Transformers 4.12.3\n- Pytorch 1.9.0+cu111\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["corgi","husky","shibu inu"],"string":"[\n \"corgi\",\n \"husky\",\n \"shibu inu\"\n]","isConversational":false}}},{"rowIdx":87,"cells":{"model_id":{"kind":"string","value":"nateraw/planes-trains-automobiles"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# planes-trains-automobiles\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the huggingpics dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.0534\n- Accuracy: 0.9851\n\n\n## Model description\n\nAutogenerated by HuggingPics🤗🖼️\n\nCreate your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).\n\nReport any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).\n## Example Images\n\n\n#### automobiles\n\n\n\n#### planes\n\n\n\n#### trains\n\n\n\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 1337\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 4\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| 0.0283 | 1.0 | 48 | 0.0434 | 0.9851 |\n| 0.0224 | 2.0 | 96 | 0.0548 | 0.9851 |\n| 0.0203 | 3.0 | 144 | 0.0445 | 0.9851 |\n| 0.0195 | 4.0 | 192 | 0.0534 | 0.9851 |\n\n\n### Framework versions\n\n- Transformers 4.9.2\n- Pytorch 1.9.0+cu102\n- Datasets 1.11.0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["automobiles","planes","trains"],"string":"[\n \"automobiles\",\n \"planes\",\n \"trains\"\n]","isConversational":false}}},{"rowIdx":88,"cells":{"model_id":{"kind":"string","value":"nateraw/test_model_a"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# test_model_a\n\nThis model is a fine-tuned version of [lysandre/tiny-vit-random](https://huggingface.co/lysandre/tiny-vit-random) on the image_folder dataset.\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- training_steps: 40\n\n### Framework versions\n\n- Transformers 4.8.2\n- Pytorch 1.9.0+cu102\n- Datasets 1.9.1.dev0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["cat","dog"],"string":"[\n \"cat\",\n \"dog\"\n]","isConversational":false}}},{"rowIdx":89,"cells":{"model_id":{"kind":"string","value":"nateraw/trainer-rare-puppers"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# trainer-rare-puppers\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the huggingpics dataset.\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| No log | 1.0 | 48 | 0.4087 | 0.8806 |\n\n\n### Framework versions\n\n- Transformers 4.9.2\n- Pytorch 1.9.0+cu102\n- Datasets 1.11.0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["corgi","samoyed","shiba inu"],"string":"[\n \"corgi\",\n \"samoyed\",\n \"shiba inu\"\n]","isConversational":false}}},{"rowIdx":90,"cells":{"model_id":{"kind":"string","value":"nateraw/vit-age-classifier"},"model_card":{"kind":"string","value":"\n\n\nA vision transformer finetuned to classify the age of a given person's face. \n\n\n\n\n```python\nimport requests\nfrom PIL import Image\nfrom io import BytesIO\n\nfrom transformers import ViTFeatureExtractor, ViTForImageClassification\n\n# Get example image from official fairface repo + read it in as an image\nr = requests.get('https://github.com/dchen236/FairFace/blob/master/detected_faces/race_Asian_face0.jpg?raw=true')\nim = Image.open(BytesIO(r.content))\n\n# Init model, transforms\nmodel = ViTForImageClassification.from_pretrained('nateraw/vit-age-classifier')\ntransforms = ViTFeatureExtractor.from_pretrained('nateraw/vit-age-classifier')\n\n# Transform our image and pass it through the model\ninputs = transforms(im, return_tensors='pt')\noutput = model(**inputs)\n\n# Predicted Class probabilities\nproba = output.logits.softmax(1)\n\n# Predicted Classes\npreds = proba.argmax(1)\n```"},"model_labels":{"kind":"list like","value":["0-2","3-9","10-19","20-29","30-39","40-49","50-59","60-69","more than 70"],"string":"[\n \"0-2\",\n \"3-9\",\n \"10-19\",\n \"20-29\",\n \"30-39\",\n \"40-49\",\n \"50-59\",\n \"60-69\",\n \"more than 70\"\n]","isConversational":false}}},{"rowIdx":91,"cells":{"model_id":{"kind":"string","value":"nateraw/vit-base-beans-demo-v2"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# vit-base-beans-demo-v2\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.0099\n- Accuracy: 1.0\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| 0.0705 | 1.54 | 100 | 0.0562 | 0.9925 |\n| 0.0123 | 3.08 | 200 | 0.0124 | 1.0 |\n| 0.008 | 4.62 | 300 | 0.0099 | 1.0 |\n\n\n### Framework versions\n\n- Transformers 4.10.0.dev0\n- Pytorch 1.9.0+cu102\n- Datasets 1.11.0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["angular_leaf_spot","bean_rust","healthy"],"string":"[\n \"angular_leaf_spot\",\n \"bean_rust\",\n \"healthy\"\n]","isConversational":false}}},{"rowIdx":92,"cells":{"model_id":{"kind":"string","value":"nateraw/vit-base-beans-demo-v3"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# vit-base-beans-demo-v3\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.0645\n- Accuracy: 0.9850\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 2\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| 0.0397 | 1.54 | 100 | 0.0645 | 0.9850 |\n\n\n### Framework versions\n\n- Transformers 4.10.0.dev0\n- Pytorch 1.9.0+cu102\n- Datasets 1.11.0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["angular_leaf_spot","bean_rust","healthy"],"string":"[\n \"angular_leaf_spot\",\n \"bean_rust\",\n \"healthy\"\n]","isConversational":false}}},{"rowIdx":93,"cells":{"model_id":{"kind":"string","value":"nateraw/vit-base-beans-demo"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# vit-base-beans-demo\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.0853\n- Accuracy: 0.9774\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| 0.0545 | 1.54 | 100 | 0.1436 | 0.9624 |\n| 0.006 | 3.08 | 200 | 0.1058 | 0.9699 |\n| 0.0038 | 4.62 | 300 | 0.0853 | 0.9774 |\n\n\n### Framework versions\n\n- Transformers 4.9.2\n- Pytorch 1.9.0+cu102\n- Datasets 1.11.0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["angular_leaf_spot","bean_rust","healthy"],"string":"[\n \"angular_leaf_spot\",\n \"bean_rust\",\n \"healthy\"\n]","isConversational":false}}},{"rowIdx":94,"cells":{"model_id":{"kind":"string","value":"nateraw/vit-base-beans"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# vit-base-beans\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.0942\n- Accuracy: 0.9774\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 1337\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5.0\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| 0.2809 | 1.0 | 130 | 0.2287 | 0.9699 |\n| 0.1097 | 2.0 | 260 | 0.1676 | 0.9624 |\n| 0.1027 | 3.0 | 390 | 0.0942 | 0.9774 |\n| 0.0923 | 4.0 | 520 | 0.1104 | 0.9699 |\n| 0.1726 | 5.0 | 650 | 0.1030 | 0.9699 |\n\n\n### Framework versions\n\n- Transformers 4.10.0.dev0\n- Pytorch 1.9.0+cu102\n- Datasets 1.11.1.dev0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["angular_leaf_spot","bean_rust","healthy"],"string":"[\n \"angular_leaf_spot\",\n \"bean_rust\",\n \"healthy\"\n]","isConversational":false}}},{"rowIdx":95,"cells":{"model_id":{"kind":"string","value":"nateraw/vit-base-cats-vs-dogs"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# vit-base-cats-vs-dogs\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the cats_vs_dogs dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.0202\n- Accuracy: 0.9935\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 64\n- eval_batch_size: 64\n- seed: 1337\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 5.0\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| 0.064 | 1.0 | 311 | 0.0483 | 0.9849 |\n| 0.0622 | 2.0 | 622 | 0.0275 | 0.9903 |\n| 0.0366 | 3.0 | 933 | 0.0262 | 0.9917 |\n| 0.0294 | 4.0 | 1244 | 0.0219 | 0.9932 |\n| 0.0161 | 5.0 | 1555 | 0.0202 | 0.9935 |\n\n\n### Framework versions\n\n- Transformers 4.8.1\n- Pytorch 1.9.0+cu102\n- Datasets 1.11.1.dev0\n- Tokenizers 0.10.3\n"},"model_labels":{"kind":"list like","value":["cat","dog"],"string":"[\n \"cat\",\n \"dog\"\n]","isConversational":false}}},{"rowIdx":96,"cells":{"model_id":{"kind":"string","value":"nateraw/vit-base-patch16-224-cifar10"},"model_card":{"kind":"string","value":"\n# Vision Transformer Fine Tuned on CIFAR10\n\nVision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) and **fine-tuned on CIFAR10** at resolution 224x224.\n\nCheck out the code at my [my Github repo](https://github.com/nateraw/huggingface-vit-finetune).\n\n## Usage\n\n```python\nfrom transformers import ViTFeatureExtractor, ViTForImageClassification\nfrom PIL import Image\nimport requests\n\nurl = 'https://www.cs.toronto.edu/~kriz/cifar-10-sample/dog10.png'\nimage = Image.open(requests.get(url, stream=True).raw)\nfeature_extractor = ViTFeatureExtractor.from_pretrained('nateraw/vit-base-patch16-224-cifar10')\nmodel = ViTForImageClassification.from_pretrained('nateraw/vit-base-patch16-224-cifar10')\ninputs = feature_extractor(images=image, return_tensors=\"pt\")\noutputs = model(**inputs)\npreds = outputs.logits.argmax(dim=1)\n\nclasses = [\n 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'\n]\nclasses[preds[0]]\n```\n\n## Model description\n\nThe Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. \nImages are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.\nNote that this model does not provide any fine-tuned heads, as these were zero'd by Google researchers. However, the model does include the pre-trained pooler, which can be used for downstream tasks (such as image classification).\n\nBy pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.\n"},"model_labels":{"kind":"list like","value":["label_0","label_1","label_2","label_3","label_4","label_5","label_6","label_7","label_8","label_9"],"string":"[\n \"label_0\",\n \"label_1\",\n \"label_2\",\n \"label_3\",\n \"label_4\",\n \"label_5\",\n \"label_6\",\n \"label_7\",\n \"label_8\",\n \"label_9\"\n]","isConversational":false}}},{"rowIdx":97,"cells":{"model_id":{"kind":"string","value":"nickmuchi/vit-base-beans"},"model_card":{"kind":"string","value":"\n<!-- This model card has been generated automatically according to the information the Trainer had access to. You\nshould probably proofread and complete it, then remove this comment. -->\n\n# vit-base-beans\n\nThis model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 0.0505\n- Accuracy: 0.9850\n\n## Model description\n\nMore information needed\n\n## Intended uses & limitations\n\nMore information needed\n\n## Training and evaluation data\n\nMore information needed\n\n## Training procedure\n\n### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 8\n- mixed_precision_training: Native AMP\n\n### Training results\n\n| Training Loss | Epoch | Step | Validation Loss | Accuracy |\n|:-------------:|:-----:|:----:|:---------------:|:--------:|\n| 0.1166 | 1.54 | 100 | 0.0764 | 0.9850 |\n| 0.1607 | 3.08 | 200 | 0.2114 | 0.9398 |\n| 0.0067 | 4.62 | 300 | 0.0692 | 0.9774 |\n| 0.005 | 6.15 | 400 | 0.0944 | 0.9624 |\n| 0.0043 | 7.69 | 500 | 0.0505 | 0.9850 |\n\n\n### Framework versions\n\n- Transformers 4.16.2\n- Pytorch 1.10.0+cu111\n- Datasets 1.18.3\n- Tokenizers 0.11.0\n"},"model_labels":{"kind":"list like","value":["angular_leaf_spot","bean_rust","healthy"],"string":"[\n \"angular_leaf_spot\",\n \"bean_rust\",\n \"healthy\"\n]","isConversational":false}}},{"rowIdx":98,"cells":{"model_id":{"kind":"string","value":"nielsr/beit-base-patch16-224"},"model_card":{"kind":"string","value":"\n# BEiT (base-sized model, fine-tuned on ImageNet-1k after being intermediately fine-tuned on ImageNet-22k) \n\nBEiT (BERT pre-training of Image Transformers) model pre-trained in a self-supervised way on ImageNet-22k (14 million images, 21,841 classes) at resolution 224x224, and also fine-tuned on the same dataset at the same resolution. It was introduced in the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit). \n\nDisclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team."},"model_labels":{"kind":"list like","value":["tench, tinca tinca","goldfish, carassius auratus","great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias","tiger shark, galeocerdo cuvieri","hammerhead, hammerhead shark","electric ray, crampfish, numbfish, torpedo","stingray","cock","hen","ostrich, struthio camelus","brambling, fringilla montifringilla","goldfinch, carduelis carduelis","house finch, linnet, carpodacus mexicanus","junco, snowbird","indigo bunting, indigo finch, indigo bird, passerina cyanea","robin, american robin, turdus migratorius","bulbul","jay","magpie","chickadee","water ouzel, dipper","kite","bald eagle, american eagle, haliaeetus leucocephalus","vulture","great grey owl, great gray owl, strix nebulosa","european fire salamander, salamandra salamandra","common newt, triturus vulgaris","eft","spotted salamander, ambystoma maculatum","axolotl, mud puppy, ambystoma mexicanum","bullfrog, rana catesbeiana","tree frog, tree-frog","tailed frog, bell toad, ribbed toad, tailed toad, ascaphus trui","loggerhead, loggerhead turtle, caretta caretta","leatherback turtle, leatherback, leathery turtle, dermochelys coriacea","mud turtle","terrapin","box turtle, box tortoise","banded gecko","common iguana, iguana, iguana iguana","american chameleon, anole, anolis carolinensis","whiptail, whiptail lizard","agama","frilled lizard, chlamydosaurus kingi","alligator lizard","gila monster, heloderma suspectum","green lizard, lacerta viridis","african chameleon, chamaeleo chamaeleon","komodo dragon, komodo lizard, dragon lizard, giant lizard, varanus komodoensis","african crocodile, nile crocodile, crocodylus niloticus","american alligator, alligator mississipiensis","triceratops","thunder snake, worm snake, carphophis amoenus","ringneck snake, ring-necked snake, ring snake","hognose snake, puff adder, sand viper","green snake, grass snake","king snake, kingsnake","garter snake, grass snake","water snake","vine snake","night snake, hypsiglena torquata","boa constrictor, constrictor constrictor","rock python, rock snake, python sebae","indian cobra, naja naja","green mamba","sea snake","horned viper, cerastes, sand viper, horned asp, cerastes cornutus","diamondback, diamondback rattlesnake, crotalus adamanteus","sidewinder, horned rattlesnake, crotalus cerastes","trilobite","harvestman, daddy longlegs, phalangium opilio","scorpion","black and gold garden spider, argiope aurantia","barn spider, araneus cavaticus","garden spider, aranea diademata","black widow, latrodectus mactans","tarantula","wolf spider, hunting spider","tick","centipede","black grouse","ptarmigan","ruffed grouse, partridge, bonasa umbellus","prairie chicken, prairie grouse, prairie fowl","peacock","quail","partridge","african grey, african gray, psittacus erithacus","macaw","sulphur-crested cockatoo, kakatoe galerita, cacatua galerita","lorikeet","coucal","bee eater","hornbill","hummingbird","jacamar","toucan","drake","red-breasted merganser, mergus serrator","goose","black swan, cygnus atratus","tusker","echidna, spiny anteater, anteater","platypus, duckbill, duckbilled platypus, duck-billed platypus, ornithorhynchus anatinus","wallaby, brush kangaroo","koala, koala bear, kangaroo bear, native bear, phascolarctos cinereus","wombat","jellyfish","sea anemone, anemone","brain coral","flatworm, platyhelminth","nematode, nematode worm, roundworm","conch","snail","slug","sea slug, nudibranch","chiton, coat-of-mail shell, sea cradle, polyplacophore","chambered nautilus, pearly nautilus, nautilus","dungeness crab, cancer magister","rock crab, cancer irroratus","fiddler crab","king crab, alaska crab, alaskan king crab, alaska king crab, paralithodes camtschatica","american lobster, northern lobster, maine lobster, homarus americanus","spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish","crayfish, crawfish, crawdad, crawdaddy","hermit crab","isopod","white stork, ciconia ciconia","black stork, ciconia nigra","spoonbill","flamingo","little blue heron, egretta caerulea","american egret, great white heron, egretta albus","bittern","crane","limpkin, aramus pictus","european gallinule, porphyrio porphyrio","american coot, marsh hen, mud hen, water hen, fulica americana","bustard","ruddy turnstone, arenaria interpres","red-backed sandpiper, dunlin, erolia alpina","redshank, tringa totanus","dowitcher","oystercatcher, oyster catcher","pelican","king penguin, aptenodytes patagonica","albatross, mollymawk","grey whale, gray whale, devilfish, eschrichtius gibbosus, eschrichtius robustus","killer whale, killer, orca, grampus, sea wolf, orcinus orca","dugong, dugong dugon","sea lion","chihuahua","japanese spaniel","maltese dog, maltese terrier, maltese","pekinese, pekingese, peke","shih-tzu","blenheim spaniel","papillon","toy terrier","rhodesian ridgeback","afghan hound, afghan","basset, basset hound","beagle","bloodhound, sleuthhound","bluetick","black-and-tan coonhound","walker hound, walker foxhound","english foxhound","redbone","borzoi, russian wolfhound","irish wolfhound","italian greyhound","whippet","ibizan hound, ibizan podenco","norwegian elkhound, elkhound","otterhound, otter hound","saluki, gazelle hound","scottish deerhound, deerhound","weimaraner","staffordshire bullterrier, staffordshire bull terrier","american staffordshire terrier, staffordshire terrier, american pit bull terrier, pit bull terrier","bedlington terrier","border terrier","kerry blue terrier","irish terrier","norfolk terrier","norwich terrier","yorkshire terrier","wire-haired fox terrier","lakeland terrier","sealyham terrier, sealyham","airedale, airedale terrier","cairn, cairn terrier","australian terrier","dandie dinmont, dandie dinmont terrier","boston bull, boston terrier","miniature schnauzer","giant schnauzer","standard schnauzer","scotch terrier, scottish terrier, scottie","tibetan terrier, chrysanthemum dog","silky terrier, sydney silky","soft-coated wheaten terrier","west highland white terrier","lhasa, lhasa apso","flat-coated retriever","curly-coated retriever","golden retriever","labrador retriever","chesapeake bay retriever","german short-haired pointer","vizsla, hungarian pointer","english setter","irish setter, red setter","gordon setter","brittany spaniel","clumber, clumber spaniel","english springer, english springer spaniel","welsh springer spaniel","cocker spaniel, english cocker spaniel, cocker","sussex spaniel","irish water spaniel","kuvasz","schipperke","groenendael","malinois","briard","kelpie","komondor","old english sheepdog, bobtail","shetland sheepdog, shetland sheep dog, shetland","collie","border collie","bouvier des flandres, bouviers des flandres","rottweiler","german shepherd, german shepherd dog, german police dog, alsatian","doberman, doberman pinscher","miniature pinscher","greater swiss mountain dog","bernese mountain dog","appenzeller","entlebucher","boxer","bull mastiff","tibetan mastiff","french bulldog","great dane","saint bernard, st bernard","eskimo dog, husky","malamute, malemute, alaskan malamute","siberian husky","dalmatian, coach dog, carriage dog","affenpinscher, monkey pinscher, monkey dog","basenji","pug, pug-dog","leonberg","newfoundland, newfoundland dog","great pyrenees","samoyed, samoyede","pomeranian","chow, chow chow","keeshond","brabancon griffon","pembroke, pembroke welsh corgi","cardigan, cardigan welsh corgi","toy poodle","miniature poodle","standard poodle","mexican hairless","timber wolf, grey wolf, gray wolf, canis lupus","white wolf, arctic wolf, canis lupus tundrarum","red wolf, maned wolf, canis rufus, canis niger","coyote, prairie wolf, brush wolf, canis latrans","dingo, warrigal, warragal, canis dingo","dhole, cuon alpinus","african hunting dog, hyena dog, cape hunting dog, lycaon pictus","hyena, hyaena","red fox, vulpes vulpes","kit fox, vulpes macrotis","arctic fox, white fox, alopex lagopus","grey fox, gray fox, urocyon cinereoargenteus","tabby, tabby cat","tiger cat","persian cat","siamese cat, siamese","egyptian cat","cougar, puma, catamount, mountain lion, painter, panther, felis concolor","lynx, catamount","leopard, panthera pardus","snow leopard, ounce, panthera uncia","jaguar, panther, panthera onca, felis onca","lion, king of beasts, panthera leo","tiger, panthera tigris","cheetah, chetah, acinonyx jubatus","brown bear, bruin, ursus arctos","american black bear, black bear, ursus americanus, euarctos americanus","ice bear, polar bear, ursus maritimus, thalarctos maritimus","sloth bear, melursus ursinus, ursus ursinus","mongoose","meerkat, mierkat","tiger beetle","ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle","ground beetle, carabid beetle","long-horned beetle, longicorn, longicorn beetle","leaf beetle, chrysomelid","dung beetle","rhinoceros beetle","weevil","fly","bee","ant, emmet, pismire","grasshopper, hopper","cricket","walking stick, walkingstick, stick insect","cockroach, roach","mantis, mantid","cicada, cicala","leafhopper","lacewing, lacewing fly","dragonfly, darning needle, devil's darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk","damselfly","admiral","ringlet, ringlet butterfly","monarch, monarch butterfly, milkweed butterfly, danaus plexippus","cabbage butterfly","sulphur butterfly, sulfur butterfly","lycaenid, lycaenid butterfly","starfish, sea star","sea urchin","sea cucumber, holothurian","wood rabbit, cottontail, cottontail rabbit","hare","angora, angora rabbit","hamster","porcupine, hedgehog","fox squirrel, eastern fox squirrel, sciurus niger","marmot","beaver","guinea pig, cavia cobaya","sorrel","zebra","hog, pig, grunter, squealer, sus scrofa","wild boar, boar, sus scrofa","warthog","hippopotamus, hippo, river horse, hippopotamus amphibius","ox","water buffalo, water ox, asiatic buffalo, bubalus bubalis","bison","ram, tup","bighorn, bighorn sheep, cimarron, rocky mountain bighorn, rocky mountain sheep, ovis canadensis","ibex, capra ibex","hartebeest","impala, aepyceros melampus","gazelle","arabian camel, dromedary, camelus dromedarius","llama","weasel","mink","polecat, fitch, foulmart, foumart, mustela putorius","black-footed ferret, ferret, mustela nigripes","otter","skunk, polecat, wood pussy","badger","armadillo","three-toed sloth, ai, bradypus tridactylus","orangutan, orang, orangutang, pongo pygmaeus","gorilla, gorilla gorilla","chimpanzee, chimp, pan troglodytes","gibbon, hylobates lar","siamang, hylobates syndactylus, symphalangus syndactylus","guenon, guenon monkey","patas, hussar monkey, erythrocebus patas","baboon","macaque","langur","colobus, colobus monkey","proboscis monkey, nasalis larvatus","marmoset","capuchin, ringtail, cebus capucinus","howler monkey, howler","titi, titi monkey","spider monkey, ateles geoffroyi","squirrel monkey, saimiri sciureus","madagascar cat, ring-tailed lemur, lemur catta","indri, indris, indri indri, indri brevicaudatus","indian elephant, elephas maximus","african elephant, loxodonta africana","lesser panda, red panda, panda, bear cat, cat bear, ailurus fulgens","giant panda, panda, panda bear, coon bear, ailuropoda melanoleuca","barracouta, snoek","eel","coho, cohoe, coho salmon, blue jack, silver salmon, oncorhynchus kisutch","rock beauty, holocanthus tricolor","anemone fish","sturgeon","gar, garfish, garpike, billfish, lepisosteus osseus","lionfish","puffer, pufferfish, blowfish, globefish","abacus","abaya","academic gown, academic robe, judge's robe","accordion, piano accordion, squeeze box","acoustic guitar","aircraft carrier, carrier, flattop, attack aircraft carrier","airliner","airship, dirigible","altar","ambulance","amphibian, amphibious vehicle","analog clock","apiary, bee house","apron","ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin","assault rifle, assault gun","backpack, back pack, knapsack, packsack, rucksack, haversack","bakery, bakeshop, bakehouse","balance beam, beam","balloon","ballpoint, ballpoint pen, ballpen, biro","band aid","banjo","bannister, banister, balustrade, balusters, handrail","barbell","barber chair","barbershop","barn","barometer","barrel, cask","barrow, garden cart, lawn cart, wheelbarrow","baseball","basketball","bassinet","bassoon","bathing cap, swimming cap","bath towel","bathtub, bathing tub, bath, tub","beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon","beacon, lighthouse, beacon light, pharos","beaker","bearskin, busby, shako","beer bottle","beer glass","bell cote, bell cot","bib","bicycle-built-for-two, tandem bicycle, tandem","bikini, two-piece","binder, ring-binder","binoculars, field glasses, opera glasses","birdhouse","boathouse","bobsled, bobsleigh, bob","bolo tie, bolo, bola tie, bola","bonnet, poke bonnet","bookcase","bookshop, bookstore, bookstall","bottlecap","bow","bow tie, bow-tie, bowtie","brass, memorial tablet, plaque","brassiere, bra, bandeau","breakwater, groin, groyne, mole, bulwark, seawall, jetty","breastplate, aegis, egis","broom","bucket, pail","buckle","bulletproof vest","bullet train, bullet","butcher shop, meat market","cab, hack, taxi, taxicab","caldron, cauldron","candle, taper, wax light","cannon","canoe","can opener, tin opener","cardigan","car mirror","carousel, carrousel, merry-go-round, roundabout, whirligig","carpenter's kit, tool kit","carton","car wheel","cash machine, cash dispenser, automated teller machine, automatic teller machine, automated teller, automatic teller, atm","cassette","cassette player","castle","catamaran","cd player","cello, violoncello","cellular telephone, cellular phone, cellphone, cell, mobile phone","chain","chainlink fence","chain mail, ring mail, mail, chain armor, chain armour, ring armor, ring armour","chain saw, chainsaw","chest","chiffonier, commode","chime, bell, gong","china cabinet, china closet","christmas stocking","church, church building","cinema, movie theater, movie theatre, movie house, picture palace","cleaver, meat cleaver, chopper","cliff dwelling","cloak","clog, geta, patten, sabot","cocktail shaker","coffee mug","coffeepot","coil, spiral, volute, whorl, helix","combination lock","computer keyboard, keypad","confectionery, confectionary, candy store","container ship, containership, container vessel","convertible","corkscrew, bottle screw","cornet, horn, trumpet, trump","cowboy boot","cowboy hat, ten-gallon hat","cradle","crane","crash helmet","crate","crib, cot","crock pot","croquet ball","crutch","cuirass","dam, dike, dyke","desk","desktop computer","dial telephone, dial phone","diaper, nappy, napkin","digital clock","digital watch","dining table, board","dishrag, dishcloth","dishwasher, dish washer, dishwashing machine","disk brake, disc brake","dock, dockage, docking facility","dogsled, dog sled, dog sleigh","dome","doormat, welcome mat","drilling platform, offshore rig","drum, membranophone, tympan","drumstick","dumbbell","dutch oven","electric fan, blower","electric guitar","electric locomotive","entertainment center","envelope","espresso maker","face powder","feather boa, boa","file, file cabinet, filing cabinet","fireboat","fire engine, fire truck","fire screen, fireguard","flagpole, flagstaff","flute, transverse flute","folding chair","football helmet","forklift","fountain","fountain pen","four-poster","freight car","french horn, horn","frying pan, frypan, skillet","fur coat","garbage truck, dustcart","gasmask, respirator, gas helmet","gas pump, gasoline pump, petrol pump, island dispenser","goblet","go-kart","golf ball","golfcart, golf cart","gondola","gong, tam-tam","gown","grand piano, grand","greenhouse, nursery, glasshouse","grille, radiator grille","grocery store, grocery, food market, market","guillotine","hair slide","hair spray","half track","hammer","hamper","hand blower, blow dryer, blow drier, hair dryer, hair drier","hand-held computer, hand-held microcomputer","handkerchief, hankie, hanky, hankey","hard disc, hard disk, fixed disk","harmonica, mouth organ, harp, mouth harp","harp","harvester, reaper","hatchet","holster","home theater, home theatre","honeycomb","hook, claw","hoopskirt, crinoline","horizontal bar, high bar","horse cart, horse-cart","hourglass","ipod","iron, smoothing iron","jack-o'-lantern","jean, blue jean, denim","jeep, landrover","jersey, t-shirt, tee shirt","jigsaw puzzle","jinrikisha, ricksha, rickshaw","joystick","kimono","knee pad","knot","lab coat, laboratory coat","ladle","lampshade, lamp shade","laptop, laptop computer","lawn mower, mower","lens cap, lens cover","letter opener, paper knife, paperknife","library","lifeboat","lighter, light, igniter, ignitor","limousine, limo","liner, ocean liner","lipstick, lip rouge","loafer","lotion","loudspeaker, speaker, speaker unit, loudspeaker system, speaker system","loupe, jeweler's loupe","lumbermill, sawmill","magnetic compass","mailbag, postbag","mailbox, letter box","maillot","maillot, tank suit","manhole cover","maraca","marimba, xylophone","mask","matchstick","maypole","maze, labyrinth","measuring cup","medicine chest, medicine cabinet","megalith, megalithic structure","microphone, mike","microwave, microwave oven","military uniform","milk can","minibus","miniskirt, mini","minivan","missile","mitten","mixing bowl","mobile home, manufactured home","model t","modem","monastery","monitor","moped","mortar","mortarboard","mosque","mosquito net","motor scooter, scooter","mountain bike, all-terrain bike, off-roader","mountain tent","mouse, computer mouse","mousetrap","moving van","muzzle","nail","neck brace","necklace","nipple","notebook, notebook computer","obelisk","oboe, hautboy, hautbois","ocarina, sweet potato","odometer, hodometer, mileometer, milometer","oil filter","organ, pipe organ","oscilloscope, scope, cathode-ray oscilloscope, cro","overskirt","oxcart","oxygen mask","packet","paddle, boat paddle","paddlewheel, paddle wheel","padlock","paintbrush","pajama, pyjama, pj's, jammies","palace","panpipe, pandean pipe, syrinx","paper towel","parachute, chute","parallel bars, bars","park bench","parking meter","passenger car, coach, carriage","patio, terrace","pay-phone, pay-station","pedestal, plinth, footstall","pencil box, pencil case","pencil sharpener","perfume, essence","petri dish","photocopier","pick, plectrum, plectron","pickelhaube","picket fence, paling","pickup, pickup truck","pier","piggy bank, penny bank","pill bottle","pillow","ping-pong ball","pinwheel","pirate, pirate ship","pitcher, ewer","plane, carpenter's plane, woodworking plane","planetarium","plastic bag","plate rack","plow, plough","plunger, plumber's helper","polaroid camera, polaroid land camera","pole","police van, police wagon, paddy wagon, patrol wagon, wagon, black maria","poncho","pool table, billiard table, snooker table","pop bottle, soda bottle","pot, flowerpot","potter's wheel","power drill","prayer rug, prayer mat","printer","prison, prison house","projectile, missile","projector","puck, hockey puck","punching bag, punch bag, punching ball, punchball","purse","quill, quill pen","quilt, comforter, comfort, puff","racer, race car, racing car","racket, racquet","radiator","radio, wireless","radio telescope, radio reflector","rain barrel","recreational vehicle, rv, r.v.","reel","reflex camera","refrigerator, icebox","remote control, remote","restaurant, eating house, eating place, eatery","revolver, six-gun, six-shooter","rifle","rocking chair, rocker","rotisserie","rubber eraser, rubber, pencil eraser","rugby ball","rule, ruler","running shoe","safe","safety pin","saltshaker, salt shaker","sandal","sarong","sax, saxophone","scabbard","scale, weighing machine","school bus","schooner","scoreboard","screen, crt screen","screw","screwdriver","seat belt, seatbelt","sewing machine","shield, buckler","shoe shop, shoe-shop, shoe store","shoji","shopping basket","shopping cart","shovel","shower cap","shower curtain","ski","ski mask","sleeping bag","slide rule, slipstick","sliding door","slot, one-armed bandit","snorkel","snowmobile","snowplow, snowplough","soap dispenser","soccer ball","sock","solar dish, solar collector, solar furnace","sombrero","soup bowl","space bar","space heater","space shuttle","spatula","speedboat","spider web, spider's web","spindle","sports car, sport car","spotlight, spot","stage","steam locomotive","steel arch bridge","steel drum","stethoscope","stole","stone wall","stopwatch, stop watch","stove","strainer","streetcar, tram, tramcar, trolley, trolley car","stretcher","studio couch, day bed","stupa, tope","submarine, pigboat, sub, u-boat","suit, suit of clothes","sundial","sunglass","sunglasses, dark glasses, shades","sunscreen, sunblock, sun blocker","suspension bridge","swab, swob, mop","sweatshirt","swimming trunks, bathing trunks","swing","switch, electric switch, electrical switch","syringe","table lamp","tank, army tank, armored combat vehicle, armoured combat vehicle","tape player","teapot","teddy, teddy bear","television, television system","tennis ball","thatch, thatched roof","theater curtain, theatre curtain","thimble","thresher, thrasher, threshing machine","throne","tile roof","toaster","tobacco shop, tobacconist shop, tobacconist","toilet seat","torch","totem pole","tow truck, tow car, wrecker","toyshop","tractor","trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi","tray","trench coat","tricycle, trike, velocipede","trimaran","tripod","triumphal arch","trolleybus, trolley coach, trackless trolley","trombone","tub, vat","turnstile","typewriter keyboard","umbrella","unicycle, monocycle","upright, upright piano","vacuum, vacuum cleaner","vase","vault","velvet","vending machine","vestment","viaduct","violin, fiddle","volleyball","waffle iron","wall clock","wallet, billfold, notecase, pocketbook","wardrobe, closet, press","warplane, military plane","washbasin, handbasin, washbowl, lavabo, wash-hand basin","washer, automatic washer, washing machine","water bottle","water jug","water tower","whiskey jug","whistle","wig","window screen","window shade","windsor tie","wine bottle","wing","wok","wooden spoon","wool, woolen, woollen","worm fence, snake fence, snake-rail fence, virginia fence","wreck","yawl","yurt","web site, website, internet site, site","comic book","crossword puzzle, crossword","street sign","traffic light, traffic signal, stoplight","book jacket, dust cover, dust jacket, dust wrapper","menu","plate","guacamole","consomme","hot pot, hotpot","trifle","ice cream, icecream","ice lolly, lolly, lollipop, popsicle","french loaf","bagel, beigel","pretzel","cheeseburger","hotdog, hot dog, red hot","mashed potato","head cabbage","broccoli","cauliflower","zucchini, courgette","spaghetti squash","acorn squash","butternut squash","cucumber, cuke","artichoke, globe artichoke","bell pepper","cardoon","mushroom","granny smith","strawberry","orange","lemon","fig","pineapple, ananas","banana","jackfruit, jak, jack","custard apple","pomegranate","hay","carbonara","chocolate sauce, chocolate syrup","dough","meat loaf, meatloaf","pizza, pizza pie","potpie","burrito","red wine","espresso","cup","eggnog","alp","bubble","cliff, drop, drop-off","coral reef","geyser","lakeside, lakeshore","promontory, headland, head, foreland","sandbar, sand bar","seashore, coast, seacoast, sea-coast","valley, vale","volcano","ballplayer, baseball player","groom, bridegroom","scuba diver","rapeseed","daisy","yellow lady's slipper, yellow lady-slipper, cypripedium calceolus, cypripedium parviflorum","corn","acorn","hip, rose hip, rosehip","buckeye, horse chestnut, conker","coral fungus","agaric","gyromitra","stinkhorn, carrion fungus","earthstar","hen-of-the-woods, hen of the woods, polyporus frondosus, grifola frondosa","bolete","ear, spike, capitulum","toilet tissue, toilet paper, bathroom tissue"],"string":"[\n \"tench, tinca tinca\",\n \"goldfish, carassius auratus\",\n \"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias\",\n \"tiger shark, galeocerdo cuvieri\",\n \"hammerhead, hammerhead shark\",\n \"electric ray, crampfish, numbfish, torpedo\",\n \"stingray\",\n \"cock\",\n \"hen\",\n \"ostrich, struthio camelus\",\n \"brambling, fringilla montifringilla\",\n \"goldfinch, carduelis carduelis\",\n \"house finch, linnet, carpodacus mexicanus\",\n \"junco, snowbird\",\n \"indigo bunting, indigo finch, indigo bird, passerina cyanea\",\n \"robin, american robin, turdus migratorius\",\n \"bulbul\",\n \"jay\",\n \"magpie\",\n \"chickadee\",\n \"water ouzel, dipper\",\n \"kite\",\n \"bald eagle, american eagle, haliaeetus leucocephalus\",\n \"vulture\",\n \"great grey owl, great gray owl, strix nebulosa\",\n \"european fire salamander, salamandra salamandra\",\n \"common newt, triturus vulgaris\",\n \"eft\",\n \"spotted salamander, ambystoma maculatum\",\n \"axolotl, mud puppy, ambystoma mexicanum\",\n \"bullfrog, rana catesbeiana\",\n \"tree frog, tree-frog\",\n \"tailed frog, bell toad, ribbed toad, tailed toad, ascaphus trui\",\n \"loggerhead, loggerhead turtle, caretta caretta\",\n \"leatherback turtle, leatherback, leathery turtle, dermochelys coriacea\",\n \"mud turtle\",\n \"terrapin\",\n \"box turtle, box tortoise\",\n \"banded gecko\",\n \"common iguana, iguana, iguana iguana\",\n \"american chameleon, anole, anolis carolinensis\",\n \"whiptail, whiptail lizard\",\n \"agama\",\n \"frilled lizard, chlamydosaurus kingi\",\n \"alligator lizard\",\n \"gila monster, heloderma suspectum\",\n \"green lizard, lacerta viridis\",\n \"african chameleon, chamaeleo chamaeleon\",\n \"komodo dragon, komodo lizard, dragon lizard, giant lizard, varanus komodoensis\",\n \"african crocodile, nile crocodile, crocodylus niloticus\",\n \"american alligator, alligator mississipiensis\",\n \"triceratops\",\n \"thunder snake, worm snake, carphophis amoenus\",\n \"ringneck snake, ring-necked snake, ring snake\",\n \"hognose snake, puff adder, sand viper\",\n \"green snake, grass snake\",\n \"king snake, kingsnake\",\n \"garter snake, grass snake\",\n \"water snake\",\n \"vine snake\",\n \"night snake, hypsiglena torquata\",\n \"boa constrictor, constrictor constrictor\",\n \"rock python, rock snake, python sebae\",\n \"indian cobra, naja naja\",\n \"green mamba\",\n \"sea snake\",\n \"horned viper, cerastes, sand viper, horned asp, cerastes cornutus\",\n \"diamondback, diamondback rattlesnake, crotalus adamanteus\",\n \"sidewinder, horned rattlesnake, crotalus cerastes\",\n \"trilobite\",\n \"harvestman, daddy longlegs, phalangium opilio\",\n \"scorpion\",\n \"black and gold garden spider, argiope aurantia\",\n \"barn spider, araneus cavaticus\",\n \"garden spider, aranea diademata\",\n \"black widow, latrodectus mactans\",\n \"tarantula\",\n \"wolf spider, hunting spider\",\n \"tick\",\n \"centipede\",\n \"black grouse\",\n \"ptarmigan\",\n \"ruffed grouse, partridge, bonasa umbellus\",\n \"prairie chicken, prairie grouse, prairie fowl\",\n \"peacock\",\n \"quail\",\n \"partridge\",\n \"african grey, african gray, psittacus erithacus\",\n \"macaw\",\n \"sulphur-crested cockatoo, kakatoe galerita, cacatua galerita\",\n \"lorikeet\",\n \"coucal\",\n \"bee eater\",\n \"hornbill\",\n \"hummingbird\",\n \"jacamar\",\n \"toucan\",\n \"drake\",\n \"red-breasted merganser, mergus serrator\",\n \"goose\",\n \"black swan, cygnus atratus\",\n \"tusker\",\n \"echidna, spiny anteater, anteater\",\n \"platypus, duckbill, duckbilled platypus, duck-billed platypus, ornithorhynchus anatinus\",\n \"wallaby, brush kangaroo\",\n \"koala, koala bear, kangaroo bear, native bear, phascolarctos cinereus\",\n \"wombat\",\n \"jellyfish\",\n \"sea anemone, anemone\",\n \"brain coral\",\n \"flatworm, platyhelminth\",\n \"nematode, nematode worm, roundworm\",\n \"conch\",\n \"snail\",\n \"slug\",\n \"sea slug, nudibranch\",\n \"chiton, coat-of-mail shell, sea cradle, polyplacophore\",\n \"chambered nautilus, pearly nautilus, nautilus\",\n \"dungeness crab, cancer magister\",\n \"rock crab, cancer irroratus\",\n \"fiddler crab\",\n \"king crab, alaska crab, alaskan king crab, alaska king crab, paralithodes camtschatica\",\n \"american lobster, northern lobster, maine lobster, homarus americanus\",\n \"spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish\",\n \"crayfish, crawfish, crawdad, crawdaddy\",\n \"hermit crab\",\n \"isopod\",\n \"white stork, ciconia ciconia\",\n \"black stork, ciconia nigra\",\n \"spoonbill\",\n \"flamingo\",\n \"little blue heron, egretta caerulea\",\n \"american egret, great white heron, egretta albus\",\n \"bittern\",\n \"crane\",\n \"limpkin, aramus pictus\",\n \"european gallinule, porphyrio porphyrio\",\n \"american coot, marsh hen, mud hen, water hen, fulica americana\",\n \"bustard\",\n \"ruddy turnstone, arenaria interpres\",\n \"red-backed sandpiper, dunlin, erolia alpina\",\n \"redshank, tringa totanus\",\n \"dowitcher\",\n \"oystercatcher, oyster catcher\",\n \"pelican\",\n \"king penguin, aptenodytes patagonica\",\n \"albatross, mollymawk\",\n \"grey whale, gray whale, devilfish, eschrichtius gibbosus, eschrichtius robustus\",\n \"killer whale, killer, orca, grampus, sea wolf, orcinus orca\",\n \"dugong, dugong dugon\",\n \"sea lion\",\n \"chihuahua\",\n \"japanese spaniel\",\n \"maltese dog, maltese terrier, maltese\",\n \"pekinese, pekingese, peke\",\n \"shih-tzu\",\n \"blenheim spaniel\",\n \"papillon\",\n \"toy terrier\",\n \"rhodesian ridgeback\",\n \"afghan hound, afghan\",\n \"basset, basset hound\",\n \"beagle\",\n \"bloodhound, sleuthhound\",\n \"bluetick\",\n \"black-and-tan coonhound\",\n \"walker hound, walker foxhound\",\n \"english foxhound\",\n \"redbone\",\n \"borzoi, russian wolfhound\",\n \"irish wolfhound\",\n \"italian greyhound\",\n \"whippet\",\n \"ibizan hound, ibizan podenco\",\n \"norwegian elkhound, elkhound\",\n \"otterhound, otter hound\",\n \"saluki, gazelle hound\",\n \"scottish deerhound, deerhound\",\n \"weimaraner\",\n \"staffordshire bullterrier, staffordshire bull terrier\",\n \"american staffordshire terrier, staffordshire terrier, american pit bull terrier, pit bull terrier\",\n \"bedlington terrier\",\n \"border terrier\",\n \"kerry blue terrier\",\n \"irish terrier\",\n \"norfolk terrier\",\n \"norwich terrier\",\n \"yorkshire terrier\",\n \"wire-haired fox terrier\",\n \"lakeland terrier\",\n \"sealyham terrier, sealyham\",\n \"airedale, airedale terrier\",\n \"cairn, cairn terrier\",\n \"australian terrier\",\n \"dandie dinmont, dandie dinmont terrier\",\n \"boston bull, boston terrier\",\n \"miniature schnauzer\",\n \"giant schnauzer\",\n \"standard schnauzer\",\n \"scotch terrier, scottish terrier, scottie\",\n \"tibetan terrier, chrysanthemum dog\",\n \"silky terrier, sydney silky\",\n \"soft-coated wheaten terrier\",\n \"west highland white terrier\",\n \"lhasa, lhasa apso\",\n \"flat-coated retriever\",\n \"curly-coated retriever\",\n \"golden retriever\",\n \"labrador retriever\",\n \"chesapeake bay retriever\",\n \"german short-haired pointer\",\n \"vizsla, hungarian pointer\",\n \"english setter\",\n \"irish setter, red setter\",\n \"gordon setter\",\n \"brittany spaniel\",\n \"clumber, clumber spaniel\",\n \"english springer, english springer spaniel\",\n \"welsh springer spaniel\",\n \"cocker spaniel, english cocker spaniel, cocker\",\n \"sussex spaniel\",\n \"irish water spaniel\",\n \"kuvasz\",\n \"schipperke\",\n \"groenendael\",\n \"malinois\",\n \"briard\",\n \"kelpie\",\n \"komondor\",\n \"old english sheepdog, bobtail\",\n \"shetland sheepdog, shetland sheep dog, shetland\",\n \"collie\",\n \"border collie\",\n \"bouvier des flandres, bouviers des flandres\",\n \"rottweiler\",\n \"german shepherd, german shepherd dog, german police dog, alsatian\",\n \"doberman, doberman pinscher\",\n \"miniature pinscher\",\n \"greater swiss mountain dog\",\n \"bernese mountain dog\",\n \"appenzeller\",\n \"entlebucher\",\n \"boxer\",\n \"bull mastiff\",\n \"tibetan mastiff\",\n \"french bulldog\",\n \"great dane\",\n \"saint bernard, st bernard\",\n \"eskimo dog, husky\",\n \"malamute, malemute, alaskan malamute\",\n \"siberian husky\",\n \"dalmatian, coach dog, carriage dog\",\n \"affenpinscher, monkey pinscher, monkey dog\",\n \"basenji\",\n \"pug, pug-dog\",\n \"leonberg\",\n \"newfoundland, newfoundland dog\",\n \"great pyrenees\",\n \"samoyed, samoyede\",\n \"pomeranian\",\n \"chow, chow chow\",\n \"keeshond\",\n \"brabancon griffon\",\n \"pembroke, pembroke welsh corgi\",\n \"cardigan, cardigan welsh corgi\",\n \"toy poodle\",\n \"miniature poodle\",\n \"standard poodle\",\n \"mexican hairless\",\n \"timber wolf, grey wolf, gray wolf, canis lupus\",\n \"white wolf, arctic wolf, canis lupus tundrarum\",\n \"red wolf, maned wolf, canis rufus, canis niger\",\n \"coyote, prairie wolf, brush wolf, canis latrans\",\n \"dingo, warrigal, warragal, canis dingo\",\n \"dhole, cuon alpinus\",\n \"african hunting dog, hyena dog, cape hunting dog, lycaon pictus\",\n \"hyena, hyaena\",\n \"red fox, vulpes vulpes\",\n \"kit fox, vulpes macrotis\",\n \"arctic fox, white fox, alopex lagopus\",\n \"grey fox, gray fox, urocyon cinereoargenteus\",\n \"tabby, tabby cat\",\n \"tiger cat\",\n \"persian cat\",\n \"siamese cat, siamese\",\n \"egyptian cat\",\n \"cougar, puma, catamount, mountain lion, painter, panther, felis concolor\",\n \"lynx, catamount\",\n \"leopard, panthera pardus\",\n \"snow leopard, ounce, panthera uncia\",\n \"jaguar, panther, panthera onca, felis onca\",\n \"lion, king of beasts, panthera leo\",\n \"tiger, panthera tigris\",\n \"cheetah, chetah, acinonyx jubatus\",\n \"brown bear, bruin, ursus arctos\",\n \"american black bear, black bear, ursus americanus, euarctos americanus\",\n \"ice bear, polar bear, ursus maritimus, thalarctos maritimus\",\n \"sloth bear, melursus ursinus, ursus ursinus\",\n \"mongoose\",\n \"meerkat, mierkat\",\n \"tiger beetle\",\n \"ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle\",\n \"ground beetle, carabid beetle\",\n \"long-horned beetle, longicorn, longicorn beetle\",\n \"leaf beetle, chrysomelid\",\n \"dung beetle\",\n \"rhinoceros beetle\",\n \"weevil\",\n \"fly\",\n \"bee\",\n \"ant, emmet, pismire\",\n \"grasshopper, hopper\",\n \"cricket\",\n \"walking stick, walkingstick, stick insect\",\n \"cockroach, roach\",\n \"mantis, mantid\",\n \"cicada, cicala\",\n \"leafhopper\",\n \"lacewing, lacewing fly\",\n \"dragonfly, darning needle, devil's darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk\",\n \"damselfly\",\n \"admiral\",\n \"ringlet, ringlet butterfly\",\n \"monarch, monarch butterfly, milkweed butterfly, danaus plexippus\",\n \"cabbage butterfly\",\n \"sulphur butterfly, sulfur butterfly\",\n \"lycaenid, lycaenid butterfly\",\n \"starfish, sea star\",\n \"sea urchin\",\n \"sea cucumber, holothurian\",\n \"wood rabbit, cottontail, cottontail rabbit\",\n \"hare\",\n \"angora, angora rabbit\",\n \"hamster\",\n \"porcupine, hedgehog\",\n \"fox squirrel, eastern fox squirrel, sciurus niger\",\n \"marmot\",\n \"beaver\",\n \"guinea pig, cavia cobaya\",\n \"sorrel\",\n \"zebra\",\n \"hog, pig, grunter, squealer, sus scrofa\",\n \"wild boar, boar, sus scrofa\",\n \"warthog\",\n \"hippopotamus, hippo, river horse, hippopotamus amphibius\",\n \"ox\",\n \"water buffalo, water ox, asiatic buffalo, bubalus bubalis\",\n \"bison\",\n \"ram, tup\",\n \"bighorn, bighorn sheep, cimarron, rocky mountain bighorn, rocky mountain sheep, ovis canadensis\",\n \"ibex, capra ibex\",\n \"hartebeest\",\n \"impala, aepyceros melampus\",\n \"gazelle\",\n \"arabian camel, dromedary, camelus dromedarius\",\n \"llama\",\n \"weasel\",\n \"mink\",\n \"polecat, fitch, foulmart, foumart, mustela putorius\",\n \"black-footed ferret, ferret, mustela nigripes\",\n \"otter\",\n \"skunk, polecat, wood pussy\",\n \"badger\",\n \"armadillo\",\n \"three-toed sloth, ai, bradypus tridactylus\",\n \"orangutan, orang, orangutang, pongo pygmaeus\",\n \"gorilla, gorilla gorilla\",\n \"chimpanzee, chimp, pan troglodytes\",\n \"gibbon, hylobates lar\",\n \"siamang, hylobates syndactylus, symphalangus syndactylus\",\n \"guenon, guenon monkey\",\n \"patas, hussar monkey, erythrocebus patas\",\n \"baboon\",\n \"macaque\",\n \"langur\",\n \"colobus, colobus monkey\",\n \"proboscis monkey, nasalis larvatus\",\n \"marmoset\",\n \"capuchin, ringtail, cebus capucinus\",\n \"howler monkey, howler\",\n \"titi, titi monkey\",\n \"spider monkey, ateles geoffroyi\",\n \"squirrel monkey, saimiri sciureus\",\n \"madagascar cat, ring-tailed lemur, lemur catta\",\n \"indri, indris, indri indri, indri brevicaudatus\",\n \"indian elephant, elephas maximus\",\n \"african elephant, loxodonta africana\",\n \"lesser panda, red panda, panda, bear cat, cat bear, ailurus fulgens\",\n \"giant panda, panda, panda bear, coon bear, ailuropoda melanoleuca\",\n \"barracouta, snoek\",\n \"eel\",\n \"coho, cohoe, coho salmon, blue jack, silver salmon, oncorhynchus kisutch\",\n \"rock beauty, holocanthus tricolor\",\n \"anemone fish\",\n \"sturgeon\",\n \"gar, garfish, garpike, billfish, lepisosteus osseus\",\n \"lionfish\",\n \"puffer, pufferfish, blowfish, globefish\",\n \"abacus\",\n \"abaya\",\n \"academic gown, academic robe, judge's robe\",\n \"accordion, piano accordion, squeeze box\",\n \"acoustic guitar\",\n \"aircraft carrier, carrier, flattop, attack aircraft carrier\",\n \"airliner\",\n \"airship, dirigible\",\n \"altar\",\n \"ambulance\",\n \"amphibian, amphibious vehicle\",\n \"analog clock\",\n \"apiary, bee house\",\n \"apron\",\n \"ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin\",\n \"assault rifle, assault gun\",\n \"backpack, back pack, knapsack, packsack, rucksack, haversack\",\n \"bakery, bakeshop, bakehouse\",\n \"balance beam, beam\",\n \"balloon\",\n \"ballpoint, ballpoint pen, ballpen, biro\",\n \"band aid\",\n \"banjo\",\n \"bannister, banister, balustrade, balusters, handrail\",\n \"barbell\",\n \"barber chair\",\n \"barbershop\",\n \"barn\",\n \"barometer\",\n \"barrel, cask\",\n \"barrow, garden cart, lawn cart, wheelbarrow\",\n \"baseball\",\n \"basketball\",\n \"bassinet\",\n \"bassoon\",\n \"bathing cap, swimming cap\",\n \"bath towel\",\n \"bathtub, bathing tub, bath, tub\",\n \"beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon\",\n \"beacon, lighthouse, beacon light, pharos\",\n \"beaker\",\n \"bearskin, busby, shako\",\n \"beer bottle\",\n \"beer glass\",\n \"bell cote, bell cot\",\n \"bib\",\n \"bicycle-built-for-two, tandem bicycle, tandem\",\n \"bikini, two-piece\",\n \"binder, ring-binder\",\n \"binoculars, field glasses, opera glasses\",\n \"birdhouse\",\n \"boathouse\",\n \"bobsled, bobsleigh, bob\",\n \"bolo tie, bolo, bola tie, bola\",\n \"bonnet, poke bonnet\",\n \"bookcase\",\n \"bookshop, bookstore, bookstall\",\n \"bottlecap\",\n \"bow\",\n \"bow tie, bow-tie, bowtie\",\n \"brass, memorial tablet, plaque\",\n \"brassiere, bra, bandeau\",\n \"breakwater, groin, groyne, mole, bulwark, seawall, jetty\",\n \"breastplate, aegis, egis\",\n \"broom\",\n \"bucket, pail\",\n \"buckle\",\n \"bulletproof vest\",\n \"bullet train, bullet\",\n \"butcher shop, meat market\",\n \"cab, hack, taxi, taxicab\",\n \"caldron, cauldron\",\n \"candle, taper, wax light\",\n \"cannon\",\n \"canoe\",\n \"can opener, tin opener\",\n \"cardigan\",\n \"car mirror\",\n \"carousel, carrousel, merry-go-round, roundabout, whirligig\",\n \"carpenter's kit, tool kit\",\n \"carton\",\n \"car wheel\",\n \"cash machine, cash dispenser, automated teller machine, automatic teller machine, automated teller, automatic teller, atm\",\n \"cassette\",\n \"cassette player\",\n \"castle\",\n \"catamaran\",\n \"cd player\",\n \"cello, violoncello\",\n \"cellular telephone, cellular phone, cellphone, cell, mobile phone\",\n \"chain\",\n \"chainlink fence\",\n \"chain mail, ring mail, mail, chain armor, chain armour, ring armor, ring armour\",\n \"chain saw, chainsaw\",\n \"chest\",\n \"chiffonier, commode\",\n \"chime, bell, gong\",\n \"china cabinet, china closet\",\n \"christmas stocking\",\n \"church, church building\",\n \"cinema, movie theater, movie theatre, movie house, picture palace\",\n \"cleaver, meat cleaver, chopper\",\n \"cliff dwelling\",\n \"cloak\",\n \"clog, geta, patten, sabot\",\n \"cocktail shaker\",\n \"coffee mug\",\n \"coffeepot\",\n \"coil, spiral, volute, whorl, helix\",\n \"combination lock\",\n \"computer keyboard, keypad\",\n \"confectionery, confectionary, candy store\",\n \"container ship, containership, container vessel\",\n \"convertible\",\n \"corkscrew, bottle screw\",\n \"cornet, horn, trumpet, trump\",\n \"cowboy boot\",\n \"cowboy hat, ten-gallon hat\",\n \"cradle\",\n \"crane\",\n \"crash helmet\",\n \"crate\",\n \"crib, cot\",\n \"crock pot\",\n \"croquet ball\",\n \"crutch\",\n \"cuirass\",\n \"dam, dike, dyke\",\n \"desk\",\n \"desktop computer\",\n \"dial telephone, dial phone\",\n \"diaper, nappy, napkin\",\n \"digital clock\",\n \"digital watch\",\n \"dining table, board\",\n \"dishrag, dishcloth\",\n \"dishwasher, dish washer, dishwashing machine\",\n \"disk brake, disc brake\",\n \"dock, dockage, docking facility\",\n \"dogsled, dog sled, dog sleigh\",\n \"dome\",\n \"doormat, welcome mat\",\n \"drilling platform, offshore rig\",\n \"drum, membranophone, tympan\",\n \"drumstick\",\n \"dumbbell\",\n \"dutch oven\",\n \"electric fan, blower\",\n \"electric guitar\",\n \"electric locomotive\",\n \"entertainment center\",\n \"envelope\",\n \"espresso maker\",\n \"face powder\",\n \"feather boa, boa\",\n \"file, file cabinet, filing cabinet\",\n \"fireboat\",\n \"fire engine, fire truck\",\n \"fire screen, fireguard\",\n \"flagpole, flagstaff\",\n \"flute, transverse flute\",\n \"folding chair\",\n \"football helmet\",\n \"forklift\",\n \"fountain\",\n \"fountain pen\",\n \"four-poster\",\n \"freight car\",\n \"french horn, horn\",\n \"frying pan, frypan, skillet\",\n \"fur coat\",\n \"garbage truck, dustcart\",\n \"gasmask, respirator, gas helmet\",\n \"gas pump, gasoline pump, petrol pump, island dispenser\",\n \"goblet\",\n \"go-kart\",\n \"golf ball\",\n \"golfcart, golf cart\",\n \"gondola\",\n \"gong, tam-tam\",\n \"gown\",\n \"grand piano, grand\",\n \"greenhouse, nursery, glasshouse\",\n \"grille, radiator grille\",\n \"grocery store, grocery, food market, market\",\n \"guillotine\",\n \"hair slide\",\n \"hair spray\",\n \"half track\",\n \"hammer\",\n \"hamper\",\n \"hand blower, blow dryer, blow drier, hair dryer, hair drier\",\n \"hand-held computer, hand-held microcomputer\",\n \"handkerchief, hankie, hanky, hankey\",\n \"hard disc, hard disk, fixed disk\",\n \"harmonica, mouth organ, harp, mouth harp\",\n \"harp\",\n \"harvester, reaper\",\n \"hatchet\",\n \"holster\",\n \"home theater, home theatre\",\n \"honeycomb\",\n \"hook, claw\",\n \"hoopskirt, crinoline\",\n \"horizontal bar, high bar\",\n \"horse cart, horse-cart\",\n \"hourglass\",\n \"ipod\",\n \"iron, smoothing iron\",\n \"jack-o'-lantern\",\n \"jean, blue jean, denim\",\n \"jeep, landrover\",\n \"jersey, t-shirt, tee shirt\",\n \"jigsaw puzzle\",\n \"jinrikisha, ricksha, rickshaw\",\n \"joystick\",\n \"kimono\",\n \"knee pad\",\n \"knot\",\n \"lab coat, laboratory coat\",\n \"ladle\",\n \"lampshade, lamp shade\",\n \"laptop, laptop computer\",\n \"lawn mower, mower\",\n \"lens cap, lens cover\",\n \"letter opener, paper knife, paperknife\",\n \"library\",\n \"lifeboat\",\n \"lighter, light, igniter, ignitor\",\n \"limousine, limo\",\n \"liner, ocean liner\",\n \"lipstick, lip rouge\",\n \"loafer\",\n \"lotion\",\n \"loudspeaker, speaker, speaker unit, loudspeaker system, speaker system\",\n \"loupe, jeweler's loupe\",\n \"lumbermill, sawmill\",\n \"magnetic compass\",\n \"mailbag, postbag\",\n \"mailbox, letter box\",\n \"maillot\",\n \"maillot, tank suit\",\n \"manhole cover\",\n \"maraca\",\n \"marimba, xylophone\",\n \"mask\",\n \"matchstick\",\n \"maypole\",\n \"maze, labyrinth\",\n \"measuring cup\",\n \"medicine chest, medicine cabinet\",\n \"megalith, megalithic structure\",\n \"microphone, mike\",\n \"microwave, microwave oven\",\n \"military uniform\",\n \"milk can\",\n \"minibus\",\n \"miniskirt, mini\",\n \"minivan\",\n \"missile\",\n \"mitten\",\n \"mixing bowl\",\n \"mobile home, manufactured home\",\n \"model t\",\n \"modem\",\n \"monastery\",\n \"monitor\",\n \"moped\",\n \"mortar\",\n \"mortarboard\",\n \"mosque\",\n \"mosquito net\",\n \"motor scooter, scooter\",\n \"mountain bike, all-terrain bike, off-roader\",\n \"mountain tent\",\n \"mouse, computer mouse\",\n \"mousetrap\",\n \"moving van\",\n \"muzzle\",\n \"nail\",\n \"neck brace\",\n \"necklace\",\n \"nipple\",\n \"notebook, notebook computer\",\n \"obelisk\",\n \"oboe, hautboy, hautbois\",\n \"ocarina, sweet potato\",\n \"odometer, hodometer, mileometer, milometer\",\n \"oil filter\",\n \"organ, pipe organ\",\n \"oscilloscope, scope, cathode-ray oscilloscope, cro\",\n \"overskirt\",\n \"oxcart\",\n \"oxygen mask\",\n \"packet\",\n \"paddle, boat paddle\",\n \"paddlewheel, paddle wheel\",\n \"padlock\",\n \"paintbrush\",\n \"pajama, pyjama, pj's, jammies\",\n \"palace\",\n \"panpipe, pandean pipe, syrinx\",\n \"paper towel\",\n \"parachute, chute\",\n \"parallel bars, bars\",\n \"park bench\",\n \"parking meter\",\n \"passenger car, coach, carriage\",\n \"patio, terrace\",\n \"pay-phone, pay-station\",\n \"pedestal, plinth, footstall\",\n \"pencil box, pencil case\",\n \"pencil sharpener\",\n \"perfume, essence\",\n \"petri dish\",\n \"photocopier\",\n \"pick, plectrum, plectron\",\n \"pickelhaube\",\n \"picket fence, paling\",\n \"pickup, pickup truck\",\n \"pier\",\n \"piggy bank, penny bank\",\n \"pill bottle\",\n \"pillow\",\n \"ping-pong ball\",\n \"pinwheel\",\n \"pirate, pirate ship\",\n \"pitcher, ewer\",\n \"plane, carpenter's plane, woodworking plane\",\n \"planetarium\",\n \"plastic bag\",\n \"plate rack\",\n \"plow, plough\",\n \"plunger, plumber's helper\",\n \"polaroid camera, polaroid land camera\",\n \"pole\",\n \"police van, police wagon, paddy wagon, patrol wagon, wagon, black maria\",\n \"poncho\",\n \"pool table, billiard table, snooker table\",\n \"pop bottle, soda bottle\",\n \"pot, flowerpot\",\n \"potter's wheel\",\n \"power drill\",\n \"prayer rug, prayer mat\",\n \"printer\",\n \"prison, prison house\",\n \"projectile, missile\",\n \"projector\",\n \"puck, hockey puck\",\n \"punching bag, punch bag, punching ball, punchball\",\n \"purse\",\n \"quill, quill pen\",\n \"quilt, comforter, comfort, puff\",\n \"racer, race car, racing car\",\n \"racket, racquet\",\n \"radiator\",\n \"radio, wireless\",\n \"radio telescope, radio reflector\",\n \"rain barrel\",\n \"recreational vehicle, rv, r.v.\",\n \"reel\",\n \"reflex camera\",\n \"refrigerator, icebox\",\n \"remote control, remote\",\n \"restaurant, eating house, eating place, eatery\",\n \"revolver, six-gun, six-shooter\",\n \"rifle\",\n \"rocking chair, rocker\",\n \"rotisserie\",\n \"rubber eraser, rubber, pencil eraser\",\n \"rugby ball\",\n \"rule, ruler\",\n \"running shoe\",\n \"safe\",\n \"safety pin\",\n \"saltshaker, salt shaker\",\n \"sandal\",\n \"sarong\",\n \"sax, saxophone\",\n \"scabbard\",\n \"scale, weighing machine\",\n \"school bus\",\n \"schooner\",\n \"scoreboard\",\n \"screen, crt screen\",\n \"screw\",\n \"screwdriver\",\n \"seat belt, seatbelt\",\n \"sewing machine\",\n \"shield, buckler\",\n \"shoe shop, shoe-shop, shoe store\",\n \"shoji\",\n \"shopping basket\",\n \"shopping cart\",\n \"shovel\",\n \"shower cap\",\n \"shower curtain\",\n \"ski\",\n \"ski mask\",\n \"sleeping bag\",\n \"slide rule, slipstick\",\n \"sliding door\",\n \"slot, one-armed bandit\",\n \"snorkel\",\n \"snowmobile\",\n \"snowplow, snowplough\",\n \"soap dispenser\",\n \"soccer ball\",\n \"sock\",\n \"solar dish, solar collector, solar furnace\",\n \"sombrero\",\n \"soup bowl\",\n \"space bar\",\n \"space heater\",\n \"space shuttle\",\n \"spatula\",\n \"speedboat\",\n \"spider web, spider's web\",\n \"spindle\",\n \"sports car, sport car\",\n \"spotlight, spot\",\n \"stage\",\n \"steam locomotive\",\n \"steel arch bridge\",\n \"steel drum\",\n \"stethoscope\",\n \"stole\",\n \"stone wall\",\n \"stopwatch, stop watch\",\n \"stove\",\n \"strainer\",\n \"streetcar, tram, tramcar, trolley, trolley car\",\n \"stretcher\",\n \"studio couch, day bed\",\n \"stupa, tope\",\n \"submarine, pigboat, sub, u-boat\",\n \"suit, suit of clothes\",\n \"sundial\",\n \"sunglass\",\n \"sunglasses, dark glasses, shades\",\n \"sunscreen, sunblock, sun blocker\",\n \"suspension bridge\",\n \"swab, swob, mop\",\n \"sweatshirt\",\n \"swimming trunks, bathing trunks\",\n \"swing\",\n \"switch, electric switch, electrical switch\",\n \"syringe\",\n \"table lamp\",\n \"tank, army tank, armored combat vehicle, armoured combat vehicle\",\n \"tape player\",\n \"teapot\",\n \"teddy, teddy bear\",\n \"television, television system\",\n \"tennis ball\",\n \"thatch, thatched roof\",\n \"theater curtain, theatre curtain\",\n \"thimble\",\n \"thresher, thrasher, threshing machine\",\n \"throne\",\n \"tile roof\",\n \"toaster\",\n \"tobacco shop, tobacconist shop, tobacconist\",\n \"toilet seat\",\n \"torch\",\n \"totem pole\",\n \"tow truck, tow car, wrecker\",\n \"toyshop\",\n \"tractor\",\n \"trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi\",\n \"tray\",\n \"trench coat\",\n \"tricycle, trike, velocipede\",\n \"trimaran\",\n \"tripod\",\n \"triumphal arch\",\n \"trolleybus, trolley coach, trackless trolley\",\n \"trombone\",\n \"tub, vat\",\n \"turnstile\",\n \"typewriter keyboard\",\n \"umbrella\",\n \"unicycle, monocycle\",\n \"upright, upright piano\",\n \"vacuum, vacuum cleaner\",\n \"vase\",\n \"vault\",\n \"velvet\",\n \"vending machine\",\n \"vestment\",\n \"viaduct\",\n \"violin, fiddle\",\n \"volleyball\",\n \"waffle iron\",\n \"wall clock\",\n \"wallet, billfold, notecase, pocketbook\",\n \"wardrobe, closet, press\",\n \"warplane, military plane\",\n \"washbasin, handbasin, washbowl, lavabo, wash-hand basin\",\n \"washer, automatic washer, washing machine\",\n \"water bottle\",\n \"water jug\",\n \"water tower\",\n \"whiskey jug\",\n \"whistle\",\n \"wig\",\n \"window screen\",\n \"window shade\",\n \"windsor tie\",\n \"wine bottle\",\n \"wing\",\n \"wok\",\n \"wooden spoon\",\n \"wool, woolen, woollen\",\n \"worm fence, snake fence, snake-rail fence, virginia fence\",\n \"wreck\",\n \"yawl\",\n \"yurt\",\n \"web site, website, internet site, site\",\n \"comic book\",\n \"crossword puzzle, crossword\",\n \"street sign\",\n \"traffic light, traffic signal, stoplight\",\n \"book jacket, dust cover, dust jacket, dust wrapper\",\n \"menu\",\n \"plate\",\n \"guacamole\",\n \"consomme\",\n \"hot pot, hotpot\",\n \"trifle\",\n \"ice cream, icecream\",\n \"ice lolly, lolly, lollipop, popsicle\",\n \"french loaf\",\n \"bagel, beigel\",\n \"pretzel\",\n \"cheeseburger\",\n \"hotdog, hot dog, red hot\",\n \"mashed potato\",\n \"head cabbage\",\n \"broccoli\",\n \"cauliflower\",\n \"zucchini, courgette\",\n \"spaghetti squash\",\n \"acorn squash\",\n \"butternut squash\",\n \"cucumber, cuke\",\n \"artichoke, globe artichoke\",\n \"bell pepper\",\n \"cardoon\",\n \"mushroom\",\n \"granny smith\",\n \"strawberry\",\n \"orange\",\n \"lemon\",\n \"fig\",\n \"pineapple, ananas\",\n \"banana\",\n \"jackfruit, jak, jack\",\n \"custard apple\",\n \"pomegranate\",\n \"hay\",\n \"carbonara\",\n \"chocolate sauce, chocolate syrup\",\n \"dough\",\n \"meat loaf, meatloaf\",\n \"pizza, pizza pie\",\n \"potpie\",\n \"burrito\",\n \"red wine\",\n \"espresso\",\n \"cup\",\n \"eggnog\",\n \"alp\",\n \"bubble\",\n \"cliff, drop, drop-off\",\n \"coral reef\",\n \"geyser\",\n \"lakeside, lakeshore\",\n \"promontory, headland, head, foreland\",\n \"sandbar, sand bar\",\n \"seashore, coast, seacoast, sea-coast\",\n \"valley, vale\",\n \"volcano\",\n \"ballplayer, baseball player\",\n \"groom, bridegroom\",\n \"scuba diver\",\n \"rapeseed\",\n \"daisy\",\n \"yellow lady's slipper, yellow lady-slipper, cypripedium calceolus, cypripedium parviflorum\",\n \"corn\",\n \"acorn\",\n \"hip, rose hip, rosehip\",\n \"buckeye, horse chestnut, conker\",\n \"coral fungus\",\n \"agaric\",\n \"gyromitra\",\n \"stinkhorn, carrion fungus\",\n \"earthstar\",\n \"hen-of-the-woods, hen of the woods, polyporus frondosus, grifola frondosa\",\n \"bolete\",\n \"ear, spike, capitulum\",\n \"toilet tissue, toilet paper, bathroom tissue\"\n]","isConversational":false}}},{"rowIdx":99,"cells":{"model_id":{"kind":"string","value":"nielsr/beit-large-patch16-224-pt22k-ft22k"},"model_card":{"kind":"string","value":"\n# BEiT (large-sized model, fine-tuned on ImageNet-22k) \n\nBEiT (BERT pre-training of Image Transformers) model pre-trained in a self-supervised way on ImageNet-22k (14 million images, 21,841 classes) at resolution 224x224, and also fine-tuned on the same dataset at the same resolution. It was introduced in the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit). \n\nDisclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team."},"model_labels":{"kind":"list like","value":["organism, being","benthos","heterotroph","cell","person, individual, someone, somebody, mortal, soul","animal, animate_being, beast, brute, creature, fauna","plant, flora, plant_life","food, nutrient","artifact, artefact","hop","check-in","dressage","curvet, vaulting","piaffe","funambulism, tightrope_walking","rock_climbing","contact_sport","outdoor_sport, field_sport","gymnastics, gymnastic_exercise","acrobatics, tumbling","track_and_field","track, running","jumping","broad_jump, long_jump","high_jump","fosbury_flop","skiing","cross-country_skiing","ski_jumping","water_sport, aquatics","swimming, swim","bathe","dip, plunge","dive, diving","floating, natation","dead-man's_float, prone_float","belly_flop, belly_flopper, belly_whop, belly_whopper","cliff_diving","flip","gainer, full_gainer","half_gainer","jackknife","swan_dive, swallow_dive","skin_diving, skin-dive","scuba_diving","snorkeling, snorkel_diving","surfing, surfboarding, surfriding","water-skiing","rowing, row","sculling","boxing, pugilism, fisticuffs","professional_boxing","in-fighting","fight","rope-a-dope","spar, sparring","archery","sledding","tobogganing","luging","bobsledding","wrestling, rassling, grappling","greco-roman_wrestling","professional_wrestling","sumo","skating","ice_skating","figure_skating","rollerblading","roller_skating","skateboarding","speed_skating","racing","auto_racing, car_racing","boat_racing","hydroplane_racing","camel_racing","greyhound_racing","horse_racing","riding, horseback_riding, equitation","equestrian_sport","pony-trekking","showjumping, stadium_jumping","cross-country_riding, cross-country_jumping","cycling","bicycling","motorcycling","dune_cycling","blood_sport","bullfighting, tauromachy","cockfighting","hunt, hunting","battue","beagling","coursing","deer_hunting, deer_hunt","ducking, duck_hunting","fox_hunting, foxhunt","pigsticking","fishing, sportfishing","angling","fly-fishing","troll, trolling","casting, cast","bait_casting","fly_casting","overcast","surf_casting, surf_fishing","day_game","athletic_game","ice_hockey, hockey, hockey_game","tetherball","water_polo","outdoor_game","golf, golf_game","professional_golf","round_of_golf, round","medal_play, stroke_play","match_play","miniature_golf","croquet","quoits, horseshoes","shuffleboard, shovelboard","field_game","field_hockey, hockey","shinny, shinney","football, football_game","american_football, american_football_game","professional_football","touch_football","hurling","rugby, rugby_football, rugger","ball_game, ballgame","baseball, baseball_game","ball","professional_baseball","hardball","perfect_game","no-hit_game, no-hitter","one-hitter, 1-hitter","two-hitter, 2-hitter","three-hitter, 3-hitter","four-hitter, 4-hitter","five-hitter, 5-hitter","softball, softball_game","rounders","stickball, stickball_game","cricket","lacrosse","polo","pushball","soccer, association_football","court_game","handball","racquetball","fives","squash, squash_racquets, squash_rackets","volleyball, volleyball_game","jai_alai, pelota","badminton","battledore, battledore_and_shuttlecock","basketball, basketball_game, hoops","professional_basketball","deck_tennis","netball","tennis, lawn_tennis","professional_tennis","singles","singles","doubles","doubles","royal_tennis, real_tennis, court_tennis","pallone","sport, athletics","clasp, clench, clutch, clutches, grasp, grip, hold","judo","team_sport","last_supper, lord's_supper","seder, passover_supper","camping, encampment, bivouacking, tenting","pest","critter","creepy-crawly","darter","peeper","homeotherm, homoiotherm, homotherm","poikilotherm, ectotherm","range_animal","scavenger","bottom-feeder, bottom-dweller","bottom-feeder","work_animal","beast_of_burden, jument","draft_animal","pack_animal, sumpter","domestic_animal, domesticated_animal","feeder","feeder","stocker","hatchling","head","migrator","molter, moulter","pet","stayer","stunt","marine_animal, marine_creature, sea_animal, sea_creature","by-catch, bycatch","female","hen","male","adult","young, offspring","orphan","young_mammal","baby","pup, whelp","wolf_pup, wolf_cub","puppy","cub, young_carnivore","lion_cub","bear_cub","tiger_cub","kit","suckling","sire","dam","thoroughbred, purebred, pureblood","giant","mutant","carnivore","herbivore","insectivore","acrodont","pleurodont","microorganism, micro-organism","monohybrid","arbovirus, arborvirus","adenovirus","arenavirus","marburg_virus","arenaviridae","vesiculovirus","reoviridae","variola_major, variola_major_virus","viroid, virusoid","coliphage","paramyxovirus","poliovirus","herpes, herpes_virus","herpes_simplex_1, hs1, hsv-1, hsv-i","herpes_zoster, herpes_zoster_virus","herpes_varicella_zoster, herpes_varicella_zoster_virus","cytomegalovirus, cmv","varicella_zoster_virus","polyoma, polyoma_virus","lyssavirus","reovirus","rotavirus","moneran, moneron","archaebacteria, archaebacterium, archaeobacteria, archeobacteria","bacteroid","bacillus_anthracis, anthrax_bacillus","yersinia_pestis","brucella","spirillum, spirilla","botulinus, botulinum, clostridium_botulinum","clostridium_perfringens","cyanobacteria, blue-green_algae","trichodesmium","nitric_bacteria, nitrobacteria","spirillum","francisella, genus_francisella","gonococcus, neisseria_gonorrhoeae","corynebacterium_diphtheriae, c._diphtheriae, klebs-loeffler_bacillus","enteric_bacteria, enterobacteria, enterics, entric","klebsiella","salmonella_typhimurium","typhoid_bacillus, salmonella_typhosa, salmonella_typhi","nitrate_bacterium, nitric_bacterium","nitrite_bacterium, nitrous_bacterium","actinomycete","streptomyces","streptomyces_erythreus","streptomyces_griseus","tubercle_bacillus, mycobacterium_tuberculosis","pus-forming_bacteria","streptobacillus","myxobacteria, myxobacterium, myxobacter, gliding_bacteria, slime_bacteria","staphylococcus, staphylococci, staph","diplococcus","pneumococcus, diplococcus_pneumoniae","streptococcus, streptococci, strep","spirochete, spirochaete","planktonic_algae","zooplankton","parasite","endoparasite, entoparasite, entozoan, entozoon, endozoan","ectoparasite, ectozoan, ectozoon, epizoan, epizoon","pathogen","commensal","myrmecophile","protoctist","protozoan, protozoon","sarcodinian, sarcodine","heliozoan","endameba","ameba, amoeba","globigerina","testacean","arcella","difflugia","ciliate, ciliated_protozoan, ciliophoran","paramecium, paramecia","stentor","alga, algae","arame","seagrass","golden_algae","yellow-green_algae","brown_algae","kelp","fucoid, fucoid_algae","fucoid","fucus","bladderwrack, ascophyllum_nodosum","green_algae, chlorophyte","pond_scum","chlorella","stonewort","desmid","sea_moss","eukaryote, eucaryote","prokaryote, procaryote","zooid","leishmania, genus_leishmania","zoomastigote, zooflagellate","polymastigote","costia, costia_necatrix","giardia","cryptomonad, cryptophyte","sporozoan","sporozoite","trophozoite","merozoite","coccidium, eimeria","gregarine","plasmodium, plasmodium_vivax, malaria_parasite","leucocytozoan, leucocytozoon","microsporidian","ostariophysi, order_ostariophysi","cypriniform_fish","loach","cyprinid, cyprinid_fish","carp","domestic_carp, cyprinus_carpio","leather_carp","mirror_carp","european_bream, abramis_brama","tench, tinca_tinca","dace, leuciscus_leuciscus","chub, leuciscus_cephalus","shiner","common_shiner, silversides, notropis_cornutus","roach, rutilus_rutilus","rudd, scardinius_erythrophthalmus","minnow, phoxinus_phoxinus","gudgeon, gobio_gobio","goldfish, carassius_auratus","crucian_carp, carassius_carassius, carassius_vulgaris","electric_eel, electrophorus_electric","catostomid","buffalo_fish, buffalofish","black_buffalo, ictiobus_niger","hog_sucker, hog_molly, hypentelium_nigricans","redhorse, redhorse_sucker","cyprinodont","killifish","mummichog, fundulus_heteroclitus","striped_killifish, mayfish, may_fish, fundulus_majalis","rivulus","flagfish, american_flagfish, jordanella_floridae","swordtail, helleri, topminnow, xyphophorus_helleri","guppy, rainbow_fish, lebistes_reticulatus","topminnow, poeciliid_fish, poeciliid, live-bearer","mosquitofish, gambusia_affinis","platy, platypoecilus_maculatus","mollie, molly","squirrelfish","reef_squirrelfish, holocentrus_coruscus","deepwater_squirrelfish, holocentrus_bullisi","holocentrus_ascensionis","soldierfish, soldier-fish","anomalops, flashlight_fish","flashlight_fish, photoblepharon_palpebratus","john_dory, zeus_faber","boarfish, capros_aper","boarfish","cornetfish","stickleback, prickleback","three-spined_stickleback, gasterosteus_aculeatus","ten-spined_stickleback, gasterosteus_pungitius","pipefish, needlefish","dwarf_pipefish, syngnathus_hildebrandi","deepwater_pipefish, cosmocampus_profundus","seahorse, sea_horse","snipefish, bellows_fish","shrimpfish, shrimp-fish","trumpetfish, aulostomus_maculatus","pellicle","embryo, conceptus, fertilized_egg","fetus, foetus","abortus","spawn","blastula, blastosphere","blastocyst, blastodermic_vessicle","gastrula","morula","yolk, vitellus","chordate","cephalochordate","lancelet, amphioxus","tunicate, urochordate, urochord","ascidian","sea_squirt","salp, salpa","doliolum","larvacean","appendicularia","ascidian_tadpole","vertebrate, craniate","amniota","amniote","aquatic_vertebrate","jawless_vertebrate, jawless_fish, agnathan","ostracoderm","heterostracan","anaspid","conodont","cyclostome","lamprey, lamprey_eel, lamper_eel","sea_lamprey, petromyzon_marinus","hagfish, hag, slime_eels","myxine_glutinosa","eptatretus","gnathostome","placoderm","cartilaginous_fish, chondrichthian","holocephalan, holocephalian","chimaera","rabbitfish, chimaera_monstrosa","elasmobranch, selachian","shark","cow_shark, six-gilled_shark, hexanchus_griseus","mackerel_shark","porbeagle, lamna_nasus","mako, mako_shark","shortfin_mako, isurus_oxyrhincus","longfin_mako, isurus_paucus","bonito_shark, blue_pointed, isurus_glaucus","great_white_shark, white_shark, man-eater, man-eating_shark, carcharodon_carcharias","basking_shark, cetorhinus_maximus","thresher, thrasher, thresher_shark, fox_shark, alopius_vulpinus","carpet_shark, orectolobus_barbatus","nurse_shark, ginglymostoma_cirratum","sand_tiger, sand_shark, carcharias_taurus, odontaspis_taurus","whale_shark, rhincodon_typus","requiem_shark","bull_shark, cub_shark, carcharhinus_leucas","sandbar_shark, carcharhinus_plumbeus","blacktip_shark, sandbar_shark, carcharhinus_limbatus","whitetip_shark, oceanic_whitetip_shark, white-tipped_shark, carcharinus_longimanus","dusky_shark, carcharhinus_obscurus","lemon_shark, negaprion_brevirostris","blue_shark, great_blue_shark, prionace_glauca","tiger_shark, galeocerdo_cuvieri","soupfin_shark, soupfin, soup-fin, galeorhinus_zyopterus","dogfish","smooth_dogfish","smoothhound, smoothhound_shark, mustelus_mustelus","american_smooth_dogfish, mustelus_canis","florida_smoothhound, mustelus_norrisi","whitetip_shark, reef_whitetip_shark, triaenodon_obseus","spiny_dogfish","atlantic_spiny_dogfish, squalus_acanthias","pacific_spiny_dogfish, squalus_suckleyi","hammerhead, hammerhead_shark","smooth_hammerhead, sphyrna_zygaena","smalleye_hammerhead, sphyrna_tudes","shovelhead, bonnethead, bonnet_shark, sphyrna_tiburo","angel_shark, angelfish, squatina_squatina, monkfish","ray","electric_ray, crampfish, numbfish, torpedo","sawfish","smalltooth_sawfish, pristis_pectinatus","guitarfish","stingray","roughtail_stingray, dasyatis_centroura","butterfly_ray","eagle_ray","spotted_eagle_ray, spotted_ray, aetobatus_narinari","cownose_ray, cow-nosed_ray, rhinoptera_bonasus","manta, manta_ray, devilfish","atlantic_manta, manta_birostris","devil_ray, mobula_hypostoma","skate","grey_skate, gray_skate, raja_batis","little_skate, raja_erinacea","thorny_skate, raja_radiata","barndoor_skate, raja_laevis","bird","dickeybird, dickey-bird, dickybird, dicky-bird","fledgling, fledgeling","nestling, baby_bird","cock","gamecock, fighting_cock","hen","nester","night_bird","night_raven","bird_of_passage","archaeopteryx, archeopteryx, archaeopteryx_lithographica","archaeornis","ratite, ratite_bird, flightless_bird","carinate, carinate_bird, flying_bird","ostrich, struthio_camelus","cassowary","emu, dromaius_novaehollandiae, emu_novaehollandiae","kiwi, apteryx","rhea, rhea_americana","rhea, nandu, pterocnemia_pennata","elephant_bird, aepyornis","moa","passerine, passeriform_bird","nonpasserine_bird","oscine, oscine_bird","songbird, songster","honey_eater, honeysucker","accentor","hedge_sparrow, sparrow, dunnock, prunella_modularis","lark","skylark, alauda_arvensis","wagtail","pipit, titlark, lark","meadow_pipit, anthus_pratensis","finch","chaffinch, fringilla_coelebs","brambling, fringilla_montifringilla","goldfinch, carduelis_carduelis","linnet, lintwhite, carduelis_cannabina","siskin, carduelis_spinus","red_siskin, carduelis_cucullata","redpoll, carduelis_flammea","redpoll, carduelis_hornemanni","new_world_goldfinch, goldfinch, yellowbird, spinus_tristis","pine_siskin, pine_finch, spinus_pinus","house_finch, linnet, carpodacus_mexicanus","purple_finch, carpodacus_purpureus","canary, canary_bird","common_canary, serinus_canaria","serin","crossbill, loxia_curvirostra","bullfinch, pyrrhula_pyrrhula","junco, snowbird","dark-eyed_junco, slate-colored_junco, junco_hyemalis","new_world_sparrow","vesper_sparrow, grass_finch, pooecetes_gramineus","white-throated_sparrow, whitethroat, zonotrichia_albicollis","white-crowned_sparrow, zonotrichia_leucophrys","chipping_sparrow, spizella_passerina","field_sparrow, spizella_pusilla","tree_sparrow, spizella_arborea","song_sparrow, melospiza_melodia","swamp_sparrow, melospiza_georgiana","bunting","indigo_bunting, indigo_finch, indigo_bird, passerina_cyanea","ortolan, ortolan_bunting, emberiza_hortulana","reed_bunting, emberiza_schoeniclus","yellowhammer, yellow_bunting, emberiza_citrinella","yellow-breasted_bunting, emberiza_aureola","snow_bunting, snowbird, snowflake, plectrophenax_nivalis","honeycreeper","banana_quit","sparrow, true_sparrow","english_sparrow, house_sparrow, passer_domesticus","tree_sparrow, passer_montanus","grosbeak, grossbeak","evening_grosbeak, hesperiphona_vespertina","hawfinch, coccothraustes_coccothraustes","pine_grosbeak, pinicola_enucleator","cardinal, cardinal_grosbeak, richmondena_cardinalis, cardinalis_cardinalis, redbird","pyrrhuloxia, pyrrhuloxia_sinuata","towhee","chewink, cheewink, pipilo_erythrophthalmus","green-tailed_towhee, chlorura_chlorura","weaver, weaverbird, weaver_finch","baya, ploceus_philippinus","whydah, whidah, widow_bird","java_sparrow, java_finch, ricebird, padda_oryzivora","avadavat, amadavat","grassfinch, grass_finch","zebra_finch, poephila_castanotis","honeycreeper, hawaiian_honeycreeper","lyrebird","scrubbird, scrub-bird, scrub_bird","broadbill","tyrannid","new_world_flycatcher, flycatcher, tyrant_flycatcher, tyrant_bird","kingbird, tyrannus_tyrannus","arkansas_kingbird, western_kingbird","cassin's_kingbird, tyrannus_vociferans","eastern_kingbird","grey_kingbird, gray_kingbird, petchary, tyrannus_domenicensis_domenicensis","pewee, peewee, peewit, pewit, wood_pewee, contopus_virens","western_wood_pewee, contopus_sordidulus","phoebe, phoebe_bird, sayornis_phoebe","vermillion_flycatcher, firebird, pyrocephalus_rubinus_mexicanus","cotinga, chatterer","cock_of_the_rock, rupicola_rupicola","cock_of_the_rock, rupicola_peruviana","manakin","bellbird","umbrella_bird, cephalopterus_ornatus","ovenbird","antbird, ant_bird","ant_thrush","ant_shrike","spotted_antbird, hylophylax_naevioides","woodhewer, woodcreeper, wood-creeper, tree_creeper","pitta","scissortail, scissortailed_flycatcher, muscivora-forficata","old_world_flycatcher, true_flycatcher, flycatcher","spotted_flycatcher, muscicapa_striata, muscicapa_grisola","thickhead, whistler","thrush","missel_thrush, mistle_thrush, mistletoe_thrush, turdus_viscivorus","song_thrush, mavis, throstle, turdus_philomelos","fieldfare, snowbird, turdus_pilaris","redwing, turdus_iliacus","blackbird, merl, merle, ouzel, ousel, european_blackbird, turdus_merula","ring_ouzel, ring_blackbird, ring_thrush, turdus_torquatus","robin, american_robin, turdus_migratorius","clay-colored_robin, turdus_greyi","hermit_thrush, hylocichla_guttata","veery, wilson's_thrush, hylocichla_fuscescens","wood_thrush, hylocichla_mustelina","nightingale, luscinia_megarhynchos","thrush_nightingale, luscinia_luscinia","bulbul","old_world_chat, chat","stonechat, saxicola_torquata","whinchat, saxicola_rubetra","solitaire","redstart, redtail","wheatear","bluebird","robin, redbreast, robin_redbreast, old_world_robin, erithacus_rubecola","bluethroat, erithacus_svecicus","warbler","gnatcatcher","kinglet","goldcrest, golden-crested_kinglet, regulus_regulus","gold-crowned_kinglet, regulus_satrata","ruby-crowned_kinglet, ruby-crowned_wren, regulus_calendula","old_world_warbler, true_warbler","blackcap, silvia_atricapilla","greater_whitethroat, whitethroat, sylvia_communis","lesser_whitethroat, whitethroat, sylvia_curruca","wood_warbler, phylloscopus_sibilatrix","sedge_warbler, sedge_bird, sedge_wren, reedbird, acrocephalus_schoenobaenus","wren_warbler","tailorbird, orthotomus_sutorius","babbler, cackler","new_world_warbler, wood_warbler","parula_warbler, northern_parula, parula_americana","wilson's_warbler, wilson's_blackcap, wilsonia_pusilla","flycatching_warbler","american_redstart, redstart, setophaga_ruticilla","cape_may_warbler, dendroica_tigrina","yellow_warbler, golden_warbler, yellowbird, dendroica_petechia","blackburn, blackburnian_warbler, dendroica_fusca","audubon's_warbler, audubon_warbler, dendroica_auduboni","myrtle_warbler, myrtle_bird, dendroica_coronata","blackpoll, dendroica_striate","new_world_chat, chat","yellow-breasted_chat, icteria_virens","ovenbird, seiurus_aurocapillus","water_thrush","yellowthroat","common_yellowthroat, maryland_yellowthroat, geothlypis_trichas","riflebird, ptloris_paradisea","new_world_oriole, american_oriole, oriole","northern_oriole, icterus_galbula","baltimore_oriole, baltimore_bird, hangbird, firebird, icterus_galbula_galbula","bullock's_oriole, icterus_galbula_bullockii","orchard_oriole, icterus_spurius","meadowlark, lark","eastern_meadowlark, sturnella_magna","western_meadowlark, sturnella_neglecta","cacique, cazique","bobolink, ricebird, reedbird, dolichonyx_oryzivorus","new_world_blackbird, blackbird","grackle, crow_blackbird","purple_grackle, quiscalus_quiscula","rusty_blackbird, rusty_grackle, euphagus_carilonus","cowbird","red-winged_blackbird, redwing, agelaius_phoeniceus","old_world_oriole, oriole","golden_oriole, oriolus_oriolus","fig-bird","starling","common_starling, sturnus_vulgaris","rose-colored_starling, rose-colored_pastor, pastor_sturnus, pastor_roseus","myna, mynah, mina, minah, myna_bird, mynah_bird","crested_myna, acridotheres_tristis","hill_myna, indian_grackle, grackle, gracula_religiosa","corvine_bird","crow","american_crow, corvus_brachyrhyncos","raven, corvus_corax","rook, corvus_frugilegus","jackdaw, daw, corvus_monedula","chough","jay","old_world_jay","common_european_jay, garullus_garullus","new_world_jay","blue_jay, jaybird, cyanocitta_cristata","canada_jay, grey_jay, gray_jay, camp_robber, whisker_jack, perisoreus_canadensis","rocky_mountain_jay, perisoreus_canadensis_capitalis","nutcracker","common_nutcracker, nucifraga_caryocatactes","clark's_nutcracker, nucifraga_columbiana","magpie","european_magpie, pica_pica","american_magpie, pica_pica_hudsonia","australian_magpie","butcherbird","currawong, bell_magpie","piping_crow, piping_crow-shrike, gymnorhina_tibicen","wren, jenny_wren","winter_wren, troglodytes_troglodytes","house_wren, troglodytes_aedon","marsh_wren","long-billed_marsh_wren, cistothorus_palustris","sedge_wren, short-billed_marsh_wren, cistothorus_platensis","rock_wren, salpinctes_obsoletus","carolina_wren, thryothorus_ludovicianus","cactus_wren","mockingbird, mocker, mimus_polyglotktos","blue_mockingbird, melanotis_caerulescens","catbird, grey_catbird, gray_catbird, dumetella_carolinensis","thrasher, mocking_thrush","brown_thrasher, brown_thrush, toxostoma_rufums","new_zealand_wren","rock_wren, xenicus_gilviventris","rifleman_bird, acanthisitta_chloris","creeper, tree_creeper","brown_creeper, american_creeper, certhia_americana","european_creeper, certhia_familiaris","wall_creeper, tichodrome, tichodroma_muriaria","european_nuthatch, sitta_europaea","red-breasted_nuthatch, sitta_canadensis","white-breasted_nuthatch, sitta_carolinensis","titmouse, tit","chickadee","black-capped_chickadee, blackcap, parus_atricapillus","tufted_titmouse, parus_bicolor","carolina_chickadee, parus_carolinensis","blue_tit, tomtit, parus_caeruleus","bushtit, bush_tit","wren-tit, chamaea_fasciata","verdin, auriparus_flaviceps","fairy_bluebird, bluebird","swallow","barn_swallow, chimney_swallow, hirundo_rustica","cliff_swallow, hirundo_pyrrhonota","tree_swallow, tree_martin, hirundo_nigricans","white-bellied_swallow, tree_swallow, iridoprocne_bicolor","martin","house_martin, delichon_urbica","bank_martin, bank_swallow, sand_martin, riparia_riparia","purple_martin, progne_subis","wood_swallow, swallow_shrike","tanager","scarlet_tanager, piranga_olivacea, redbird, firebird","western_tanager, piranga_ludoviciana","summer_tanager, summer_redbird, piranga_rubra","hepatic_tanager, piranga_flava_hepatica","shrike","butcherbird","european_shrike, lanius_excubitor","northern_shrike, lanius_borealis","white-rumped_shrike, lanius_ludovicianus_excubitorides","loggerhead_shrike, lanius_lucovicianus","migrant_shrike, lanius_ludovicianus_migrans","bush_shrike","black-fronted_bush_shrike, chlorophoneus_nigrifrons","bowerbird, catbird","satin_bowerbird, satin_bird, ptilonorhynchus_violaceus","great_bowerbird, chlamydera_nuchalis","water_ouzel, dipper","european_water_ouzel, cinclus_aquaticus","american_water_ouzel, cinclus_mexicanus","vireo","red-eyed_vireo, vireo_olivaceous","solitary_vireo, vireo_solitarius","blue-headed_vireo, vireo_solitarius_solitarius","waxwing","cedar_waxwing, cedarbird, bombycilla_cedrorun","bohemian_waxwing, bombycilla_garrulus","bird_of_prey, raptor, raptorial_bird","accipitriformes, order_accipitriformes","hawk","eyas","tiercel, tercel, tercelet","goshawk, accipiter_gentilis","sparrow_hawk, accipiter_nisus","cooper's_hawk, blue_darter, accipiter_cooperii","chicken_hawk, hen_hawk","buteonine","redtail, red-tailed_hawk, buteo_jamaicensis","rough-legged_hawk, roughleg, buteo_lagopus","red-shouldered_hawk, buteo_lineatus","buzzard, buteo_buteo","honey_buzzard, pernis_apivorus","kite","black_kite, milvus_migrans","swallow-tailed_kite, swallow-tailed_hawk, elanoides_forficatus","white-tailed_kite, elanus_leucurus","harrier","marsh_harrier, circus_aeruginosus","montagu's_harrier, circus_pygargus","marsh_hawk, northern_harrier, hen_harrier, circus_cyaneus","harrier_eagle, short-toed_eagle","falcon","peregrine, peregrine_falcon, falco_peregrinus","falcon-gentle, falcon-gentil","gyrfalcon, gerfalcon, falco_rusticolus","kestrel, falco_tinnunculus","sparrow_hawk, american_kestrel, kestrel, falco_sparverius","pigeon_hawk, merlin, falco_columbarius","hobby, falco_subbuteo","caracara","audubon's_caracara, polyborus_cheriway_audubonii","carancha, polyborus_plancus","eagle, bird_of_jove","young_bird","eaglet","harpy, harpy_eagle, harpia_harpyja","golden_eagle, aquila_chrysaetos","tawny_eagle, aquila_rapax","bald_eagle, american_eagle, haliaeetus_leucocephalus","sea_eagle","kamchatkan_sea_eagle, stellar's_sea_eagle, haliaeetus_pelagicus","ern, erne, grey_sea_eagle, gray_sea_eagle, european_sea_eagle, white-tailed_sea_eagle, haliatus_albicilla","fishing_eagle, haliaeetus_leucorhyphus","osprey, fish_hawk, fish_eagle, sea_eagle, pandion_haliaetus","vulture","aegypiidae, family_aegypiidae","old_world_vulture","griffon_vulture, griffon, gyps_fulvus","bearded_vulture, lammergeier, lammergeyer, gypaetus_barbatus","egyptian_vulture, pharaoh's_chicken, neophron_percnopterus","black_vulture, aegypius_monachus","secretary_bird, sagittarius_serpentarius","new_world_vulture, cathartid","buzzard, turkey_buzzard, turkey_vulture, cathartes_aura","condor","andean_condor, vultur_gryphus","california_condor, gymnogyps_californianus","black_vulture, carrion_crow, coragyps_atratus","king_vulture, sarcorhamphus_papa","owl, bird_of_minerva, bird_of_night, hooter","owlet","little_owl, athene_noctua","horned_owl","great_horned_owl, bubo_virginianus","great_grey_owl, great_gray_owl, strix_nebulosa","tawny_owl, strix_aluco","barred_owl, strix_varia","screech_owl, otus_asio","screech_owl","scops_owl","spotted_owl, strix_occidentalis","old_world_scops_owl, otus_scops","oriental_scops_owl, otus_sunia","hoot_owl","hawk_owl, surnia_ulula","long-eared_owl, asio_otus","laughing_owl, laughing_jackass, sceloglaux_albifacies","barn_owl, tyto_alba","amphibian","ichyostega","urodele, caudate","salamander","european_fire_salamander, salamandra_salamandra","spotted_salamander, fire_salamander, salamandra_maculosa","alpine_salamander, salamandra_atra","newt, triton","common_newt, triturus_vulgaris","red_eft, notophthalmus_viridescens","pacific_newt","rough-skinned_newt, taricha_granulosa","california_newt, taricha_torosa","eft","ambystomid, ambystomid_salamander","mole_salamander, ambystoma_talpoideum","spotted_salamander, ambystoma_maculatum","tiger_salamander, ambystoma_tigrinum","axolotl, mud_puppy, ambystoma_mexicanum","waterdog","hellbender, mud_puppy, cryptobranchus_alleganiensis","giant_salamander, megalobatrachus_maximus","olm, proteus_anguinus","mud_puppy, necturus_maculosus","dicamptodon, dicamptodontid","pacific_giant_salamander, dicamptodon_ensatus","olympic_salamander, rhyacotriton_olympicus","lungless_salamander, plethodont","eastern_red-backed_salamander, plethodon_cinereus","western_red-backed_salamander, plethodon_vehiculum","dusky_salamander","climbing_salamander","arboreal_salamander, aneides_lugubris","slender_salamander, worm_salamander","web-toed_salamander","shasta_salamander, hydromantes_shastae","limestone_salamander, hydromantes_brunus","amphiuma, congo_snake, congo_eel, blind_eel","siren","frog, toad, toad_frog, anuran, batrachian, salientian","true_frog, ranid","wood-frog, wood_frog, rana_sylvatica","leopard_frog, spring_frog, rana_pipiens","bullfrog, rana_catesbeiana","green_frog, spring_frog, rana_clamitans","cascades_frog, rana_cascadae","goliath_frog, rana_goliath","pickerel_frog, rana_palustris","tarahumara_frog, rana_tarahumarae","grass_frog, rana_temporaria","leptodactylid_frog, leptodactylid","robber_frog","barking_frog, robber_frog, hylactophryne_augusti","crapaud, south_american_bullfrog, leptodactylus_pentadactylus","tree_frog, tree-frog","tailed_frog, bell_toad, ribbed_toad, tailed_toad, ascaphus_trui","liopelma_hamiltoni","true_toad","bufo","agua, agua_toad, bufo_marinus","european_toad, bufo_bufo","natterjack, bufo_calamita","american_toad, bufo_americanus","eurasian_green_toad, bufo_viridis","american_green_toad, bufo_debilis","yosemite_toad, bufo_canorus","texas_toad, bufo_speciosus","southwestern_toad, bufo_microscaphus","western_toad, bufo_boreas","obstetrical_toad, midwife_toad, alytes_obstetricans","midwife_toad, alytes_cisternasi","fire-bellied_toad, bombina_bombina","spadefoot, spadefoot_toad","western_spadefoot, scaphiopus_hammondii","southern_spadefoot, scaphiopus_multiplicatus","plains_spadefoot, scaphiopus_bombifrons","tree_toad, tree_frog, tree-frog","spring_peeper, hyla_crucifer","pacific_tree_toad, hyla_regilla","canyon_treefrog, hyla_arenicolor","chameleon_tree_frog","cricket_frog","northern_cricket_frog, acris_crepitans","eastern_cricket_frog, acris_gryllus","chorus_frog","lowland_burrowing_treefrog, northern_casque-headed_frog, pternohyla_fodiens","western_narrow-mouthed_toad, gastrophryne_olivacea","eastern_narrow-mouthed_toad, gastrophryne_carolinensis","sheep_frog","tongueless_frog","surinam_toad, pipa_pipa, pipa_americana","african_clawed_frog, xenopus_laevis","south_american_poison_toad","caecilian, blindworm","reptile, reptilian","anapsid, anapsid_reptile","diapsid, diapsid_reptile","diapsida, subclass_diapsida","chelonian, chelonian_reptile","turtle","sea_turtle, marine_turtle","green_turtle, chelonia_mydas","loggerhead, loggerhead_turtle, caretta_caretta","ridley","atlantic_ridley, bastard_ridley, bastard_turtle, lepidochelys_kempii","pacific_ridley, olive_ridley, lepidochelys_olivacea","hawksbill_turtle, hawksbill, hawkbill, tortoiseshell_turtle, eretmochelys_imbricata","leatherback_turtle, leatherback, leathery_turtle, dermochelys_coriacea","snapping_turtle","common_snapping_turtle, snapper, chelydra_serpentina","alligator_snapping_turtle, alligator_snapper, macroclemys_temmincki","mud_turtle","musk_turtle, stinkpot","terrapin","diamondback_terrapin, malaclemys_centrata","red-bellied_terrapin, red-bellied_turtle, redbelly, pseudemys_rubriventris","slider, yellow-bellied_terrapin, pseudemys_scripta","cooter, river_cooter, pseudemys_concinna","box_turtle, box_tortoise","western_box_turtle, terrapene_ornata","painted_turtle, painted_terrapin, painted_tortoise, chrysemys_picta","tortoise","european_tortoise, testudo_graeca","giant_tortoise","gopher_tortoise, gopher_turtle, gopher, gopherus_polypemus","desert_tortoise, gopherus_agassizii","texas_tortoise","soft-shelled_turtle, pancake_turtle","spiny_softshell, trionyx_spiniferus","smooth_softshell, trionyx_muticus","tuatara, sphenodon_punctatum","saurian","lizard","gecko","flying_gecko, fringed_gecko, ptychozoon_homalocephalum","banded_gecko","iguanid, iguanid_lizard","common_iguana, iguana, iguana_iguana","marine_iguana, amblyrhynchus_cristatus","desert_iguana, dipsosaurus_dorsalis","chuckwalla, sauromalus_obesus","zebra-tailed_lizard, gridiron-tailed_lizard, callisaurus_draconoides","fringe-toed_lizard, uma_notata","earless_lizard","collared_lizard","leopard_lizard","spiny_lizard","fence_lizard","western_fence_lizard, swift, blue-belly, sceloporus_occidentalis","eastern_fence_lizard, pine_lizard, sceloporus_undulatus","sagebrush_lizard, sceloporus_graciosus","side-blotched_lizard, sand_lizard, uta_stansburiana","tree_lizard, urosaurus_ornatus","horned_lizard, horned_toad, horny_frog","texas_horned_lizard, phrynosoma_cornutum","basilisk","american_chameleon, anole, anolis_carolinensis","worm_lizard","night_lizard","skink, scincid, scincid_lizard","western_skink, eumeces_skiltonianus","mountain_skink, eumeces_callicephalus","teiid_lizard, teiid","whiptail, whiptail_lizard","racerunner, race_runner, six-lined_racerunner, cnemidophorus_sexlineatus","plateau_striped_whiptail, cnemidophorus_velox","chihuahuan_spotted_whiptail, cnemidophorus_exsanguis","western_whiptail, cnemidophorus_tigris","checkered_whiptail, cnemidophorus_tesselatus","teju","caiman_lizard","agamid, agamid_lizard","agama","frilled_lizard, chlamydosaurus_kingi","moloch","mountain_devil, spiny_lizard, moloch_horridus","anguid_lizard","alligator_lizard","blindworm, slowworm, anguis_fragilis","glass_lizard, glass_snake, joint_snake","legless_lizard","lanthanotus_borneensis","venomous_lizard","gila_monster, heloderma_suspectum","beaded_lizard, mexican_beaded_lizard, heloderma_horridum","lacertid_lizard, lacertid","sand_lizard, lacerta_agilis","green_lizard, lacerta_viridis","chameleon, chamaeleon","african_chameleon, chamaeleo_chamaeleon","horned_chameleon, chamaeleo_oweni","monitor, monitor_lizard, varan","african_monitor, varanus_niloticus","komodo_dragon, komodo_lizard, dragon_lizard, giant_lizard, varanus_komodoensis","crocodilian_reptile, crocodilian","crocodile","african_crocodile, nile_crocodile, crocodylus_niloticus","asian_crocodile, crocodylus_porosus","morlett's_crocodile","false_gavial, tomistoma_schlegeli","alligator, gator","american_alligator, alligator_mississipiensis","chinese_alligator, alligator_sinensis","caiman, cayman","spectacled_caiman, caiman_sclerops","gavial, gavialis_gangeticus","armored_dinosaur","stegosaur, stegosaurus, stegosaur_stenops","ankylosaur, ankylosaurus","edmontonia","bone-headed_dinosaur","pachycephalosaur, pachycephalosaurus","ceratopsian, horned_dinosaur","protoceratops","triceratops","styracosaur, styracosaurus","psittacosaur, psittacosaurus","ornithopod, ornithopod_dinosaur","hadrosaur, hadrosaurus, duck-billed_dinosaur","trachodon, trachodont","saurischian, saurischian_dinosaur","sauropod, sauropod_dinosaur","apatosaur, apatosaurus, brontosaur, brontosaurus, thunder_lizard, apatosaurus_excelsus","barosaur, barosaurus","diplodocus","argentinosaur","theropod, theropod_dinosaur, bird-footed_dinosaur","ceratosaur, ceratosaurus","coelophysis","tyrannosaur, tyrannosaurus, tyrannosaurus_rex","allosaur, allosaurus","ornithomimid","maniraptor","oviraptorid","velociraptor","deinonychus","utahraptor, superslasher","synapsid, synapsid_reptile","dicynodont","pelycosaur","dimetrodon","pterosaur, flying_reptile","pterodactyl","ichthyosaur","ichthyosaurus","stenopterygius, stenopterygius_quadrisicissus","plesiosaur, plesiosaurus","nothosaur","snake, serpent, ophidian","colubrid_snake, colubrid","hoop_snake","thunder_snake, worm_snake, carphophis_amoenus","ringneck_snake, ring-necked_snake, ring_snake","hognose_snake, puff_adder, sand_viper","leaf-nosed_snake","green_snake, grass_snake","smooth_green_snake, opheodrys_vernalis","rough_green_snake, opheodrys_aestivus","green_snake","racer","blacksnake, black_racer, coluber_constrictor","blue_racer, coluber_constrictor_flaviventris","horseshoe_whipsnake, coluber_hippocrepis","whip-snake, whip_snake, whipsnake","coachwhip, coachwhip_snake, masticophis_flagellum","california_whipsnake, striped_racer, masticophis_lateralis","sonoran_whipsnake, masticophis_bilineatus","rat_snake","corn_snake, red_rat_snake, elaphe_guttata","black_rat_snake, blacksnake, pilot_blacksnake, mountain_blacksnake, elaphe_obsoleta","chicken_snake","indian_rat_snake, ptyas_mucosus","glossy_snake, arizona_elegans","bull_snake, bull-snake","gopher_snake, pituophis_melanoleucus","pine_snake","king_snake, kingsnake","common_kingsnake, lampropeltis_getulus","milk_snake, house_snake, milk_adder, checkered_adder, lampropeltis_triangulum","garter_snake, grass_snake","common_garter_snake, thamnophis_sirtalis","ribbon_snake, thamnophis_sauritus","western_ribbon_snake, thamnophis_proximus","lined_snake, tropidoclonion_lineatum","ground_snake, sonora_semiannulata","eastern_ground_snake, potamophis_striatula, haldea_striatula","water_snake","common_water_snake, banded_water_snake, natrix_sipedon, nerodia_sipedon","water_moccasin","grass_snake, ring_snake, ringed_snake, natrix_natrix","viperine_grass_snake, natrix_maura","red-bellied_snake, storeria_occipitamaculata","sand_snake","banded_sand_snake, chilomeniscus_cinctus","black-headed_snake","vine_snake","lyre_snake","sonoran_lyre_snake, trimorphodon_lambda","night_snake, hypsiglena_torquata","blind_snake, worm_snake","western_blind_snake, leptotyphlops_humilis","indigo_snake, gopher_snake, drymarchon_corais","eastern_indigo_snake, drymarchon_corais_couperi","constrictor","boa","boa_constrictor, constrictor_constrictor","rubber_boa, tow-headed_snake, charina_bottae","rosy_boa, lichanura_trivirgata","anaconda, eunectes_murinus","python","carpet_snake, python_variegatus, morelia_spilotes_variegatus","reticulated_python, python_reticulatus","indian_python, python_molurus","rock_python, rock_snake, python_sebae","amethystine_python","elapid, elapid_snake","coral_snake, harlequin-snake, new_world_coral_snake","eastern_coral_snake, micrurus_fulvius","western_coral_snake, micruroides_euryxanthus","coral_snake, old_world_coral_snake","african_coral_snake, aspidelaps_lubricus","australian_coral_snake, rhynchoelaps_australis","copperhead, denisonia_superba","cobra","indian_cobra, naja_naja","asp, egyptian_cobra, naja_haje","black-necked_cobra, spitting_cobra, naja_nigricollis","hamadryad, king_cobra, ophiophagus_hannah, naja_hannah","ringhals, rinkhals, spitting_snake, hemachatus_haemachatus","mamba","black_mamba, dendroaspis_augusticeps","green_mamba","death_adder, acanthophis_antarcticus","tiger_snake, notechis_scutatus","australian_blacksnake, pseudechis_porphyriacus","krait","banded_krait, banded_adder, bungarus_fasciatus","taipan, oxyuranus_scutellatus","sea_snake","viper","adder, common_viper, vipera_berus","asp, asp_viper, vipera_aspis","puff_adder, bitis_arietans","gaboon_viper, bitis_gabonica","horned_viper, cerastes, sand_viper, horned_asp, cerastes_cornutus","pit_viper","copperhead, agkistrodon_contortrix","water_moccasin, cottonmouth, cottonmouth_moccasin, agkistrodon_piscivorus","rattlesnake, rattler","diamondback, diamondback_rattlesnake, crotalus_adamanteus","timber_rattlesnake, banded_rattlesnake, crotalus_horridus_horridus","canebrake_rattlesnake, canebrake_rattler, crotalus_horridus_atricaudatus","prairie_rattlesnake, prairie_rattler, western_rattlesnake, crotalus_viridis","sidewinder, horned_rattlesnake, crotalus_cerastes","western_diamondback, western_diamondback_rattlesnake, crotalus_atrox","rock_rattlesnake, crotalus_lepidus","tiger_rattlesnake, crotalus_tigris","mojave_rattlesnake, crotalus_scutulatus","speckled_rattlesnake, crotalus_mitchellii","massasauga, massasauga_rattler, sistrurus_catenatus","ground_rattler, massasauga, sistrurus_miliaris","fer-de-lance, bothrops_atrops","carcase, carcass","carrion","arthropod","trilobite","arachnid, arachnoid","harvestman, daddy_longlegs, phalangium_opilio","scorpion","false_scorpion, pseudoscorpion","book_scorpion, chelifer_cancroides","whip-scorpion, whip_scorpion","vinegarroon, mastigoproctus_giganteus","spider","orb-weaving_spider","black_and_gold_garden_spider, argiope_aurantia","barn_spider, araneus_cavaticus","garden_spider, aranea_diademata","comb-footed_spider, theridiid","black_widow, latrodectus_mactans","tarantula","wolf_spider, hunting_spider","european_wolf_spider, tarantula, lycosa_tarentula","trap-door_spider","acarine","tick","hard_tick, ixodid","ixodes_dammini, deer_tick","ixodes_neotomae","ixodes_pacificus, western_black-legged_tick","ixodes_scapularis, black-legged_tick","sheep-tick, sheep_tick, ixodes_ricinus","ixodes_persulcatus","ixodes_dentatus","ixodes_spinipalpis","wood_tick, american_dog_tick, dermacentor_variabilis","soft_tick, argasid","mite","web-spinning_mite","acarid","trombidiid","trombiculid","harvest_mite, chigger, jigger, redbug","acarus, genus_acarus","itch_mite, sarcoptid","rust_mite","spider_mite, tetranychid","red_spider, red_spider_mite, panonychus_ulmi","myriapod","garden_centipede, garden_symphilid, symphilid, scutigerella_immaculata","tardigrade","centipede","house_centipede, scutigera_coleoptrata","millipede, millepede, milliped","sea_spider, pycnogonid","merostomata, class_merostomata","horseshoe_crab, king_crab, limulus_polyphemus, xiphosurus_polyphemus","asian_horseshoe_crab","eurypterid","tongue_worm, pentastomid","gallinaceous_bird, gallinacean","domestic_fowl, fowl, poultry","dorking","plymouth_rock","cornish, cornish_fowl","rock_cornish","game_fowl","cochin, cochin_china","jungle_fowl, gallina","jungle_cock","jungle_hen","red_jungle_fowl, gallus_gallus","chicken, gallus_gallus","bantam","chick, biddy","cock, rooster","cockerel","capon","hen, biddy","cackler","brood_hen, broody, broody_hen, setting_hen, sitter","mother_hen","layer","pullet","spring_chicken","rhode_island_red","dominique, dominick","orpington","turkey, meleagris_gallopavo","turkey_cock, gobbler, tom, tom_turkey","ocellated_turkey, agriocharis_ocellata","grouse","black_grouse","european_black_grouse, heathfowl, lyrurus_tetrix","asian_black_grouse, lyrurus_mlokosiewiczi","blackcock, black_cock","greyhen, grayhen, grey_hen, gray_hen, heath_hen","ptarmigan","red_grouse, moorfowl, moorbird, moor-bird, moorgame, lagopus_scoticus","moorhen","capercaillie, capercailzie, horse_of_the_wood, tetrao_urogallus","spruce_grouse, canachites_canadensis","sage_grouse, sage_hen, centrocercus_urophasianus","ruffed_grouse, partridge, bonasa_umbellus","sharp-tailed_grouse, sprigtail, sprig_tail, pedioecetes_phasianellus","prairie_chicken, prairie_grouse, prairie_fowl","greater_prairie_chicken, tympanuchus_cupido","lesser_prairie_chicken, tympanuchus_pallidicinctus","heath_hen, tympanuchus_cupido_cupido","guan","curassow","piping_guan","chachalaca","texas_chachalaca, ortilis_vetula_macalli","megapode, mound_bird, mound-bird, mound_builder, scrub_fowl","mallee_fowl, leipoa, lowan, leipoa_ocellata","mallee_hen","brush_turkey, alectura_lathami","maleo, macrocephalon_maleo","phasianid","pheasant","ring-necked_pheasant, phasianus_colchicus","afropavo, congo_peafowl, afropavo_congensis","argus, argus_pheasant","golden_pheasant, chrysolophus_pictus","bobwhite, bobwhite_quail, partridge","northern_bobwhite, colinus_virginianus","old_world_quail","migratory_quail, coturnix_coturnix, coturnix_communis","monal, monaul","peafowl, bird_of_juno","peachick, pea-chick","peacock","peahen","blue_peafowl, pavo_cristatus","green_peafowl, pavo_muticus","quail","california_quail, lofortyx_californicus","tragopan","partridge","hungarian_partridge, grey_partridge, gray_partridge, perdix_perdix","red-legged_partridge, alectoris_ruffa","greek_partridge, rock_partridge, alectoris_graeca","mountain_quail, mountain_partridge, oreortyx_picta_palmeri","guinea_fowl, guinea, numida_meleagris","guinea_hen","hoatzin, hoactzin, stinkbird, opisthocomus_hoazin","tinamou, partridge","columbiform_bird","dodo, raphus_cucullatus","pigeon","pouter_pigeon, pouter","dove","rock_dove, rock_pigeon, columba_livia","band-tailed_pigeon, band-tail_pigeon, bandtail, columba_fasciata","wood_pigeon, ringdove, cushat, columba_palumbus","turtledove","streptopelia_turtur","ringdove, streptopelia_risoria","australian_turtledove, turtledove, stictopelia_cuneata","mourning_dove, zenaidura_macroura","domestic_pigeon","squab","fairy_swallow","roller, tumbler, tumbler_pigeon","homing_pigeon, homer","carrier_pigeon","passenger_pigeon, ectopistes_migratorius","sandgrouse, sand_grouse","painted_sandgrouse, pterocles_indicus","pin-tailed_sandgrouse, pin-tailed_grouse, pterocles_alchata","pallas's_sandgrouse, syrrhaptes_paradoxus","parrot","popinjay","poll, poll_parrot","african_grey, african_gray, psittacus_erithacus","amazon","macaw","kea, nestor_notabilis","cockatoo","sulphur-crested_cockatoo, kakatoe_galerita, cacatua_galerita","pink_cockatoo, kakatoe_leadbeateri","cockateel, cockatiel, cockatoo_parrot, nymphicus_hollandicus","lovebird","lory","lorikeet","varied_lorikeet, glossopsitta_versicolor","rainbow_lorikeet, trichoglossus_moluccanus","parakeet, parrakeet, parroket, paraquet, paroquet, parroquet","carolina_parakeet, conuropsis_carolinensis","budgerigar, budgereegah, budgerygah, budgie, grass_parakeet, lovebird, shell_parakeet, melopsittacus_undulatus","ring-necked_parakeet, psittacula_krameri","cuculiform_bird","cuckoo","european_cuckoo, cuculus_canorus","black-billed_cuckoo, coccyzus_erythropthalmus","roadrunner, chaparral_cock, geococcyx_californianus","ani","coucal","crow_pheasant, centropus_sinensis","touraco, turaco, turacou, turakoo","coraciiform_bird","roller","european_roller, coracias_garrulus","ground_roller","kingfisher","eurasian_kingfisher, alcedo_atthis","belted_kingfisher, ceryle_alcyon","kookaburra, laughing_jackass, dacelo_gigas","bee_eater","hornbill","hoopoe, hoopoo","euopean_hoopoe, upupa_epops","wood_hoopoe","motmot, momot","tody","apodiform_bird","swift","european_swift, apus_apus","chimney_swift, chimney_swallow, chateura_pelagica","swiftlet, collocalia_inexpectata","tree_swift, crested_swift","hummingbird","archilochus_colubris","thornbill","goatsucker, nightjar, caprimulgid","european_goatsucker, european_nightjar, caprimulgus_europaeus","chuck-will's-widow, caprimulgus_carolinensis","whippoorwill, caprimulgus_vociferus","poorwill, phalaenoptilus_nuttallii","frogmouth","oilbird, guacharo, steatornis_caripensis","piciform_bird","woodpecker, peckerwood, pecker","green_woodpecker, picus_viridis","downy_woodpecker","flicker","yellow-shafted_flicker, colaptes_auratus, yellowhammer","gilded_flicker, colaptes_chrysoides","red-shafted_flicker, colaptes_caper_collaris","ivorybill, ivory-billed_woodpecker, campephilus_principalis","redheaded_woodpecker, redhead, melanerpes_erythrocephalus","sapsucker","yellow-bellied_sapsucker, sphyrapicus_varius","red-breasted_sapsucker, sphyrapicus_varius_ruber","wryneck","piculet","barbet","puffbird","honey_guide","jacamar","toucan","toucanet","trogon","quetzal, quetzal_bird","resplendent_quetzel, resplendent_trogon, pharomacrus_mocino","aquatic_bird","waterfowl, water_bird, waterbird","anseriform_bird","duck","drake","quack-quack","duckling","diving_duck","dabbling_duck, dabbler","mallard, anas_platyrhynchos","black_duck, anas_rubripes","teal","greenwing, green-winged_teal, anas_crecca","bluewing, blue-winged_teal, anas_discors","garganey, anas_querquedula","widgeon, wigeon, anas_penelope","american_widgeon, baldpate, anas_americana","shoveler, shoveller, broadbill, anas_clypeata","pintail, pin-tailed_duck, anas_acuta","sheldrake","shelduck","ruddy_duck, oxyura_jamaicensis","bufflehead, butterball, dipper, bucephela_albeola","goldeneye, whistler, bucephela_clangula","barrow's_goldeneye, bucephala_islandica","canvasback, canvasback_duck, aythya_valisineria","pochard, aythya_ferina","redhead, aythya_americana","scaup, scaup_duck, bluebill, broadbill","greater_scaup, aythya_marila","lesser_scaup, lesser_scaup_duck, lake_duck, aythya_affinis","wild_duck","wood_duck, summer_duck, wood_widgeon, aix_sponsa","wood_drake","mandarin_duck, aix_galericulata","muscovy_duck, musk_duck, cairina_moschata","sea_duck","eider, eider_duck","scoter, scooter","common_scoter, melanitta_nigra","old_squaw, oldwife, clangula_hyemalis","merganser, fish_duck, sawbill, sheldrake","goosander, mergus_merganser","american_merganser, mergus_merganser_americanus","red-breasted_merganser, mergus_serrator","smew, mergus_albellus","hooded_merganser, hooded_sheldrake, lophodytes_cucullatus","goose","gosling","gander","chinese_goose, anser_cygnoides","greylag, graylag, greylag_goose, graylag_goose, anser_anser","blue_goose, chen_caerulescens","snow_goose","brant, brant_goose, brent, brent_goose","common_brant_goose, branta_bernicla","honker, canada_goose, canadian_goose, branta_canadensis","barnacle_goose, barnacle, branta_leucopsis","coscoroba","swan","cob","pen","cygnet","mute_swan, cygnus_olor","whooper, whooper_swan, cygnus_cygnus","tundra_swan, cygnus_columbianus","whistling_swan, cygnus_columbianus_columbianus","bewick's_swan, cygnus_columbianus_bewickii","trumpeter, trumpeter_swan, cygnus_buccinator","black_swan, cygnus_atratus","screamer","horned_screamer, anhima_cornuta","crested_screamer","chaja, chauna_torquata","mammal, mammalian","female_mammal","tusker","prototherian","monotreme, egg-laying_mammal","echidna, spiny_anteater, anteater","echidna, spiny_anteater, anteater","platypus, duckbill, duckbilled_platypus, duck-billed_platypus, ornithorhynchus_anatinus","marsupial, pouched_mammal","opossum, possum","common_opossum, didelphis_virginiana, didelphis_marsupialis","crab-eating_opossum","opossum_rat","bandicoot","rabbit-eared_bandicoot, rabbit_bandicoot, bilby, macrotis_lagotis","kangaroo","giant_kangaroo, great_grey_kangaroo, macropus_giganteus","wallaby, brush_kangaroo","common_wallaby, macropus_agiles","hare_wallaby, kangaroo_hare","nail-tailed_wallaby, nail-tailed_kangaroo","rock_wallaby, rock_kangaroo","pademelon, paddymelon","tree_wallaby, tree_kangaroo","musk_kangaroo, hypsiprymnodon_moschatus","rat_kangaroo, kangaroo_rat","potoroo","bettong","jerboa_kangaroo, kangaroo_jerboa","phalanger, opossum, possum","cuscus","brush-tailed_phalanger, trichosurus_vulpecula","flying_phalanger, flying_opossum, flying_squirrel","koala, koala_bear, kangaroo_bear, native_bear, phascolarctos_cinereus","wombat","dasyurid_marsupial, dasyurid","dasyure","eastern_dasyure, dasyurus_quoll","native_cat, dasyurus_viverrinus","thylacine, tasmanian_wolf, tasmanian_tiger, thylacinus_cynocephalus","tasmanian_devil, ursine_dasyure, sarcophilus_hariisi","pouched_mouse, marsupial_mouse, marsupial_rat","numbat, banded_anteater, anteater, myrmecobius_fasciatus","pouched_mole, marsupial_mole, notoryctus_typhlops","placental, placental_mammal, eutherian, eutherian_mammal","livestock, stock, farm_animal","bull","cow","calf","calf","yearling","buck","doe","insectivore","mole","starnose_mole, star-nosed_mole, condylura_cristata","brewer's_mole, hair-tailed_mole, parascalops_breweri","golden_mole","shrew_mole","asiatic_shrew_mole, uropsilus_soricipes","american_shrew_mole, neurotrichus_gibbsii","shrew, shrewmouse","common_shrew, sorex_araneus","masked_shrew, sorex_cinereus","short-tailed_shrew, blarina_brevicauda","water_shrew","american_water_shrew, sorex_palustris","european_water_shrew, neomys_fodiens","mediterranean_water_shrew, neomys_anomalus","least_shrew, cryptotis_parva","hedgehog, erinaceus_europaeus, erinaceus_europeaeus","tenrec, tendrac","tailless_tenrec, tenrec_ecaudatus","otter_shrew, potamogale, potamogale_velox","eiderdown","aftershaft","sickle_feather","contour_feather","bastard_wing, alula, spurious_wing","saddle_hackle, saddle_feather","encolure","hair","squama","scute","sclerite","plastron","scallop_shell","oyster_shell","theca","invertebrate","sponge, poriferan, parazoan","choanocyte, collar_cell","glass_sponge","venus's_flower_basket","metazoan","coelenterate, cnidarian","planula","polyp","medusa, medusoid, medusan","jellyfish","scyphozoan","chrysaora_quinquecirrha","hydrozoan, hydroid","hydra","siphonophore","nanomia","portuguese_man-of-war, man-of-war, jellyfish","praya","apolemia","anthozoan, actinozoan","sea_anemone, anemone","actinia, actinian, actiniarian","sea_pen","coral","gorgonian, gorgonian_coral","sea_feather","sea_fan","red_coral","stony_coral, madrepore, madriporian_coral","brain_coral","staghorn_coral, stag's-horn_coral","mushroom_coral","ctenophore, comb_jelly","beroe","platyctenean","sea_gooseberry","venus's_girdle, cestum_veneris","worm","helminth, parasitic_worm","woodworm","woodborer, borer","acanthocephalan, spiny-headed_worm","arrowworm, chaetognath","bladder_worm","flatworm, platyhelminth","planarian, planaria","fluke, trematode, trematode_worm","cercaria","liver_fluke, fasciola_hepatica","fasciolopsis_buski","schistosome, blood_fluke","tapeworm, cestode","echinococcus","taenia","ribbon_worm, nemertean, nemertine, proboscis_worm","beard_worm, pogonophoran","rotifer","nematode, nematode_worm, roundworm","common_roundworm, ascaris_lumbricoides","chicken_roundworm, ascaridia_galli","pinworm, threadworm, enterobius_vermicularis","eelworm","vinegar_eel, vinegar_worm, anguillula_aceti, turbatrix_aceti","trichina, trichinella_spiralis","hookworm","filaria","guinea_worm, dracunculus_medinensis","annelid, annelid_worm, segmented_worm","archiannelid","oligochaete, oligochaete_worm","earthworm, angleworm, fishworm, fishing_worm, wiggler, nightwalker, nightcrawler, crawler, dew_worm, red_worm","polychaete, polychete, polychaete_worm, polychete_worm","lugworm, lug, lobworm","sea_mouse","bloodworm","leech, bloodsucker, hirudinean","medicinal_leech, hirudo_medicinalis","horseleech","mollusk, mollusc, shellfish","scaphopod","tooth_shell, tusk_shell","gastropod, univalve","abalone, ear-shell","ormer, sea-ear, haliotis_tuberculata","scorpion_shell","conch","giant_conch, strombus_gigas","snail","edible_snail, helix_pomatia","garden_snail","brown_snail, helix_aspersa","helix_hortensis","slug","seasnail","neritid, neritid_gastropod","nerita","bleeding_tooth, nerita_peloronta","neritina","whelk","moon_shell, moonshell","periwinkle, winkle","limpet","common_limpet, patella_vulgata","keyhole_limpet, fissurella_apertura, diodora_apertura","river_limpet, freshwater_limpet, ancylus_fluviatilis","sea_slug, nudibranch","sea_hare, aplysia_punctata","hermissenda_crassicornis","bubble_shell","physa","cowrie, cowry","money_cowrie, cypraea_moneta","tiger_cowrie, cypraea_tigris","solenogaster, aplacophoran","chiton, coat-of-mail_shell, sea_cradle, polyplacophore","bivalve, pelecypod, lamellibranch","spat","clam","seashell","soft-shell_clam, steamer, steamer_clam, long-neck_clam, mya_arenaria","quahog, quahaug, hard-shell_clam, hard_clam, round_clam, venus_mercenaria, mercenaria_mercenaria","littleneck, littleneck_clam","cherrystone, cherrystone_clam","geoduck","razor_clam, jackknife_clam, knife-handle","giant_clam, tridacna_gigas","cockle","edible_cockle, cardium_edule","oyster","japanese_oyster, ostrea_gigas","virginia_oyster","pearl_oyster, pinctada_margaritifera","saddle_oyster, anomia_ephippium","window_oyster, windowpane_oyster, capiz, placuna_placenta","ark_shell","blood_clam","mussel","marine_mussel, mytilid","edible_mussel, mytilus_edulis","freshwater_mussel, freshwater_clam","pearly-shelled_mussel","thin-shelled_mussel","zebra_mussel, dreissena_polymorpha","scallop, scollop, escallop","bay_scallop, pecten_irradians","sea_scallop, giant_scallop, pecten_magellanicus","shipworm, teredinid","teredo","piddock","cephalopod, cephalopod_mollusk","chambered_nautilus, pearly_nautilus, nautilus","octopod","octopus, devilfish","paper_nautilus, nautilus, argonaut, argonauta_argo","decapod","squid","loligo","ommastrephes","architeuthis, giant_squid","cuttlefish, cuttle","spirula, spirula_peronii","crustacean","malacostracan_crustacean","decapod_crustacean, decapod","brachyuran","crab","stone_crab, menippe_mercenaria","hard-shell_crab","soft-shell_crab, soft-shelled_crab","dungeness_crab, cancer_magister","rock_crab, cancer_irroratus","jonah_crab, cancer_borealis","swimming_crab","english_lady_crab, portunus_puber","american_lady_crab, lady_crab, calico_crab, ovalipes_ocellatus","blue_crab, callinectes_sapidus","fiddler_crab","pea_crab","king_crab, alaska_crab, alaskan_king_crab, alaska_king_crab, paralithodes_camtschatica","spider_crab","european_spider_crab, king_crab, maja_squinado","giant_crab, macrocheira_kaempferi","lobster","true_lobster","american_lobster, northern_lobster, maine_lobster, homarus_americanus","european_lobster, homarus_vulgaris","cape_lobster, homarus_capensis","norway_lobster, nephrops_norvegicus","spiny_lobster, langouste, rock_lobster, crawfish, crayfish, sea_crawfish","crayfish, crawfish, crawdad, crawdaddy","old_world_crayfish, ecrevisse","american_crayfish","hermit_crab","shrimp","snapping_shrimp, pistol_shrimp","prawn","long-clawed_prawn, river_prawn, palaemon_australis","tropical_prawn","krill","euphausia_pacifica","opossum_shrimp","stomatopod, stomatopod_crustacean","mantis_shrimp, mantis_crab","squilla, mantis_prawn","isopod","woodlouse, slater","pill_bug","sow_bug","sea_louse, sea_slater","amphipod","skeleton_shrimp","whale_louse","daphnia, water_flea","fairy_shrimp","brine_shrimp, artemia_salina","tadpole_shrimp","copepod, copepod_crustacean","cyclops, water_flea","seed_shrimp, mussel_shrimp, ostracod","barnacle, cirriped, cirripede","acorn_barnacle, rock_barnacle, balanus_balanoides","goose_barnacle, gooseneck_barnacle, lepas_fascicularis","onychophoran, velvet_worm, peripatus","wading_bird, wader","stork","white_stork, ciconia_ciconia","black_stork, ciconia_nigra","adjutant_bird, adjutant, adjutant_stork, leptoptilus_dubius","marabou, marabout, marabou_stork, leptoptilus_crumeniferus","openbill","jabiru, jabiru_mycteria","saddlebill, jabiru, ephippiorhynchus_senegalensis","policeman_bird, black-necked_stork, jabiru, xenorhyncus_asiaticus","wood_ibis, wood_stork, flinthead, mycteria_americana","shoebill, shoebird, balaeniceps_rex","ibis","wood_ibis, wood_stork, ibis_ibis","sacred_ibis, threskiornis_aethiopica","spoonbill","common_spoonbill, platalea_leucorodia","roseate_spoonbill, ajaia_ajaja","flamingo","heron","great_blue_heron, ardea_herodius","great_white_heron, ardea_occidentalis","egret","little_blue_heron, egretta_caerulea","snowy_egret, snowy_heron, egretta_thula","little_egret, egretta_garzetta","great_white_heron, casmerodius_albus","american_egret, great_white_heron, egretta_albus","cattle_egret, bubulcus_ibis","night_heron, night_raven","black-crowned_night_heron, nycticorax_nycticorax","yellow-crowned_night_heron, nyctanassa_violacea","boatbill, boat-billed_heron, broadbill, cochlearius_cochlearius","bittern","american_bittern, stake_driver, botaurus_lentiginosus","european_bittern, botaurus_stellaris","least_bittern, ixobrychus_exilis","crane","whooping_crane, whooper, grus_americana","courlan, aramus_guarauna","limpkin, aramus_pictus","crested_cariama, seriema, cariama_cristata","chunga, seriema, chunga_burmeisteri","rail","weka, maori_hen, wood_hen","crake","corncrake, land_rail, crex_crex","spotted_crake, porzana_porzana","gallinule, marsh_hen, water_hen, swamphen","florida_gallinule, gallinula_chloropus_cachinnans","moorhen, gallinula_chloropus","purple_gallinule","european_gallinule, porphyrio_porphyrio","american_gallinule, porphyrula_martinica","notornis, takahe, notornis_mantelli","coot","american_coot, marsh_hen, mud_hen, water_hen, fulica_americana","old_world_coot, fulica_atra","bustard","great_bustard, otis_tarda","plain_turkey, choriotis_australis","button_quail, button-quail, bustard_quail, hemipode","striped_button_quail, turnix_sylvatica","plain_wanderer, pedionomus_torquatus","trumpeter","brazilian_trumpeter, psophia_crepitans","seabird, sea_bird, seafowl","shorebird, shore_bird, limicoline_bird","plover","piping_plover, charadrius_melodus","killdeer, kildeer, killdeer_plover, charadrius_vociferus","dotterel, dotrel, charadrius_morinellus, eudromias_morinellus","golden_plover","lapwing, green_plover, peewit, pewit","turnstone","ruddy_turnstone, arenaria_interpres","black_turnstone, arenaria-melanocephala","sandpiper","surfbird, aphriza_virgata","european_sandpiper, actitis_hypoleucos","spotted_sandpiper, actitis_macularia","least_sandpiper, stint, erolia_minutilla","red-backed_sandpiper, dunlin, erolia_alpina","greenshank, tringa_nebularia","redshank, tringa_totanus","yellowlegs","greater_yellowlegs, tringa_melanoleuca","lesser_yellowlegs, tringa_flavipes","pectoral_sandpiper, jacksnipe, calidris_melanotos","knot, greyback, grayback, calidris_canutus","curlew_sandpiper, calidris_ferruginea","sanderling, crocethia_alba","upland_sandpiper, upland_plover, bartramian_sandpiper, bartramia_longicauda","ruff, philomachus_pugnax","reeve","tattler","polynesian_tattler, heteroscelus_incanus","willet, catoptrophorus_semipalmatus","woodcock","eurasian_woodcock, scolopax_rusticola","american_woodcock, woodcock_snipe, philohela_minor","snipe","whole_snipe, gallinago_gallinago","wilson's_snipe, gallinago_gallinago_delicata","great_snipe, woodcock_snipe, gallinago_media","jacksnipe, half_snipe, limnocryptes_minima","dowitcher","greyback, grayback, limnodromus_griseus","red-breasted_snipe, limnodromus_scolopaceus","curlew","european_curlew, numenius_arquata","eskimo_curlew, numenius_borealis","godwit","hudsonian_godwit, limosa_haemastica","stilt, stiltbird, longlegs, long-legs, stilt_plover, himantopus_stilt","black-necked_stilt, himantopus_mexicanus","black-winged_stilt, himantopus_himantopus","white-headed_stilt, himantopus_himantopus_leucocephalus","kaki, himantopus_novae-zelandiae","stilt, australian_stilt","banded_stilt, cladorhyncus_leucocephalum","avocet","oystercatcher, oyster_catcher","phalarope","red_phalarope, phalaropus_fulicarius","northern_phalarope, lobipes_lobatus","wilson's_phalarope, steganopus_tricolor","pratincole, glareole","courser","cream-colored_courser, cursorius_cursor","crocodile_bird, pluvianus_aegyptius","stone_curlew, thick-knee, burhinus_oedicnemus","coastal_diving_bird","larid","gull, seagull, sea_gull","mew, mew_gull, sea_mew, larus_canus","black-backed_gull, great_black-backed_gull, cob, larus_marinus","herring_gull, larus_argentatus","laughing_gull, blackcap, pewit, pewit_gull, larus_ridibundus","ivory_gull, pagophila_eburnea","kittiwake","tern","sea_swallow, sterna_hirundo","skimmer","jaeger","parasitic_jaeger, arctic_skua, stercorarius_parasiticus","skua, bonxie","great_skua, catharacta_skua","auk","auklet","razorbill, razor-billed_auk, alca_torda","little_auk, dovekie, plautus_alle","guillemot","black_guillemot, cepphus_grylle","pigeon_guillemot, cepphus_columba","murre","common_murre, uria_aalge","thick-billed_murre, uria_lomvia","puffin","atlantic_puffin, fratercula_arctica","horned_puffin, fratercula_corniculata","tufted_puffin, lunda_cirrhata","gaviiform_seabird","loon, diver","podicipitiform_seabird","grebe","great_crested_grebe, podiceps_cristatus","red-necked_grebe, podiceps_grisegena","black-necked_grebe, eared_grebe, podiceps_nigricollis","dabchick, little_grebe, podiceps_ruficollis","pied-billed_grebe, podilymbus_podiceps","pelecaniform_seabird","pelican","white_pelican, pelecanus_erythrorhynchos","old_world_white_pelican, pelecanus_onocrotalus","frigate_bird, man-of-war_bird","gannet","solan, solan_goose, solant_goose, sula_bassana","booby","cormorant, phalacrocorax_carbo","snakebird, anhinga, darter","water_turkey, anhinga_anhinga","tropic_bird, tropicbird, boatswain_bird","sphenisciform_seabird","penguin","adelie, adelie_penguin, pygoscelis_adeliae","king_penguin, aptenodytes_patagonica","emperor_penguin, aptenodytes_forsteri","jackass_penguin, spheniscus_demersus","rock_hopper, crested_penguin","pelagic_bird, oceanic_bird","procellariiform_seabird","albatross, mollymawk","wandering_albatross, diomedea_exulans","black-footed_albatross, gooney, gooney_bird, goonie, goony, diomedea_nigripes","petrel","white-chinned_petrel, procellaria_aequinoctialis","giant_petrel, giant_fulmar, macronectes_giganteus","fulmar, fulmar_petrel, fulmarus_glacialis","shearwater","manx_shearwater, puffinus_puffinus","storm_petrel","stormy_petrel, northern_storm_petrel, hydrobates_pelagicus","mother_carey's_chicken, mother_carey's_hen, oceanites_oceanicus","diving_petrel","aquatic_mammal","cetacean, cetacean_mammal, blower","whale","baleen_whale, whalebone_whale","right_whale","bowhead, bowhead_whale, greenland_whale, balaena_mysticetus","rorqual, razorback","blue_whale, sulfur_bottom, balaenoptera_musculus","finback, finback_whale, fin_whale, common_rorqual, balaenoptera_physalus","sei_whale, balaenoptera_borealis","lesser_rorqual, piked_whale, minke_whale, balaenoptera_acutorostrata","humpback, humpback_whale, megaptera_novaeangliae","grey_whale, gray_whale, devilfish, eschrichtius_gibbosus, eschrichtius_robustus","toothed_whale","sperm_whale, cachalot, black_whale, physeter_catodon","pygmy_sperm_whale, kogia_breviceps","dwarf_sperm_whale, kogia_simus","beaked_whale","bottle-nosed_whale, bottlenose_whale, bottlenose, hyperoodon_ampullatus","dolphin","common_dolphin, delphinus_delphis","bottlenose_dolphin, bottle-nosed_dolphin, bottlenose","atlantic_bottlenose_dolphin, tursiops_truncatus","pacific_bottlenose_dolphin, tursiops_gilli","porpoise","harbor_porpoise, herring_hog, phocoena_phocoena","vaquita, phocoena_sinus","grampus, grampus_griseus","killer_whale, killer, orca, grampus, sea_wolf, orcinus_orca","pilot_whale, black_whale, common_blackfish, blackfish, globicephala_melaena","river_dolphin","narwhal, narwal, narwhale, monodon_monoceros","white_whale, beluga, delphinapterus_leucas","sea_cow, sirenian_mammal, sirenian","manatee, trichechus_manatus","dugong, dugong_dugon","steller's_sea_cow, hydrodamalis_gigas","carnivore","omnivore","pinniped_mammal, pinniped, pinnatiped","seal","crabeater_seal, crab-eating_seal","eared_seal","fur_seal","guadalupe_fur_seal, arctocephalus_philippi","fur_seal","alaska_fur_seal, callorhinus_ursinus","sea_lion","south_american_sea_lion, otaria_byronia","california_sea_lion, zalophus_californianus, zalophus_californicus","australian_sea_lion, zalophus_lobatus","steller_sea_lion, steller's_sea_lion, eumetopias_jubatus","earless_seal, true_seal, hair_seal","harbor_seal, common_seal, phoca_vitulina","harp_seal, pagophilus_groenlandicus","elephant_seal, sea_elephant","bearded_seal, squareflipper_square_flipper, erignathus_barbatus","hooded_seal, bladdernose, cystophora_cristata","walrus, seahorse, sea_horse","atlantic_walrus, odobenus_rosmarus","pacific_walrus, odobenus_divergens","fissipedia","fissiped_mammal, fissiped","aardvark, ant_bear, anteater, orycteropus_afer","canine, canid","bitch","brood_bitch","dog, domestic_dog, canis_familiaris","pooch, doggie, doggy, barker, bow-wow","cur, mongrel, mutt","feist, fice","pariah_dog, pye-dog, pie-dog","lapdog","toy_dog, toy","chihuahua","japanese_spaniel","maltese_dog, maltese_terrier, maltese","pekinese, pekingese, peke","shih-tzu","toy_spaniel","english_toy_spaniel","blenheim_spaniel","king_charles_spaniel","papillon","toy_terrier","hunting_dog","courser","rhodesian_ridgeback","hound, hound_dog","afghan_hound, afghan","basset, basset_hound","beagle","bloodhound, sleuthhound","bluetick","boarhound","coonhound","coondog","black-and-tan_coonhound","dachshund, dachsie, badger_dog","sausage_dog, sausage_hound","foxhound","american_foxhound","walker_hound, walker_foxhound","english_foxhound","harrier","plott_hound","redbone","wolfhound","borzoi, russian_wolfhound","irish_wolfhound","greyhound","italian_greyhound","whippet","ibizan_hound, ibizan_podenco","norwegian_elkhound, elkhound","otterhound, otter_hound","saluki, gazelle_hound","scottish_deerhound, deerhound","staghound","weimaraner","terrier","bullterrier, bull_terrier","staffordshire_bullterrier, staffordshire_bull_terrier","american_staffordshire_terrier, staffordshire_terrier, american_pit_bull_terrier, pit_bull_terrier","bedlington_terrier","border_terrier","kerry_blue_terrier","irish_terrier","norfolk_terrier","norwich_terrier","yorkshire_terrier","rat_terrier, ratter","manchester_terrier, black-and-tan_terrier","toy_manchester, toy_manchester_terrier","fox_terrier","smooth-haired_fox_terrier","wire-haired_fox_terrier","wirehair, wirehaired_terrier, wire-haired_terrier","lakeland_terrier","welsh_terrier","sealyham_terrier, sealyham","airedale, airedale_terrier","cairn, cairn_terrier","australian_terrier","dandie_dinmont, dandie_dinmont_terrier","boston_bull, boston_terrier","schnauzer","miniature_schnauzer","giant_schnauzer","standard_schnauzer","scotch_terrier, scottish_terrier, scottie","tibetan_terrier, chrysanthemum_dog","silky_terrier, sydney_silky","skye_terrier","clydesdale_terrier","soft-coated_wheaten_terrier","west_highland_white_terrier","lhasa, lhasa_apso","sporting_dog, gun_dog","bird_dog","water_dog","retriever","flat-coated_retriever","curly-coated_retriever","golden_retriever","labrador_retriever","chesapeake_bay_retriever","pointer, spanish_pointer","german_short-haired_pointer","setter","vizsla, hungarian_pointer","english_setter","irish_setter, red_setter","gordon_setter","spaniel","brittany_spaniel","clumber, clumber_spaniel","field_spaniel","springer_spaniel, springer","english_springer, english_springer_spaniel","welsh_springer_spaniel","cocker_spaniel, english_cocker_spaniel, cocker","sussex_spaniel","water_spaniel","american_water_spaniel","irish_water_spaniel","griffon, wire-haired_pointing_griffon","working_dog","watchdog, guard_dog","kuvasz","attack_dog","housedog","schipperke","shepherd_dog, sheepdog, sheep_dog","belgian_sheepdog, belgian_shepherd","groenendael","malinois","briard","kelpie","komondor","old_english_sheepdog, bobtail","shetland_sheepdog, shetland_sheep_dog, shetland","collie","border_collie","bouvier_des_flandres, bouviers_des_flandres","rottweiler","german_shepherd, german_shepherd_dog, german_police_dog, alsatian","police_dog","pinscher","doberman, doberman_pinscher","miniature_pinscher","sennenhunde","greater_swiss_mountain_dog","bernese_mountain_dog","appenzeller","entlebucher","boxer","mastiff","bull_mastiff","tibetan_mastiff","bulldog, english_bulldog","french_bulldog","great_dane","guide_dog","seeing_eye_dog","hearing_dog","saint_bernard, st_bernard","seizure-alert_dog","sled_dog, sledge_dog","eskimo_dog, husky","malamute, malemute, alaskan_malamute","siberian_husky","dalmatian, coach_dog, carriage_dog","liver-spotted_dalmatian","affenpinscher, monkey_pinscher, monkey_dog","basenji","pug, pug-dog","leonberg","newfoundland, newfoundland_dog","great_pyrenees","spitz","samoyed, samoyede","pomeranian","chow, chow_chow","keeshond","griffon, brussels_griffon, belgian_griffon","brabancon_griffon","corgi, welsh_corgi","pembroke, pembroke_welsh_corgi","cardigan, cardigan_welsh_corgi","poodle, poodle_dog","toy_poodle","miniature_poodle","standard_poodle","large_poodle","mexican_hairless","wolf","timber_wolf, grey_wolf, gray_wolf, canis_lupus","white_wolf, arctic_wolf, canis_lupus_tundrarum","red_wolf, maned_wolf, canis_rufus, canis_niger","coyote, prairie_wolf, brush_wolf, canis_latrans","coydog","jackal, canis_aureus","wild_dog","dingo, warrigal, warragal, canis_dingo","dhole, cuon_alpinus","crab-eating_dog, crab-eating_fox, dusicyon_cancrivorus","raccoon_dog, nyctereutes_procyonides","african_hunting_dog, hyena_dog, cape_hunting_dog, lycaon_pictus","hyena, hyaena","striped_hyena, hyaena_hyaena","brown_hyena, strand_wolf, hyaena_brunnea","spotted_hyena, laughing_hyena, crocuta_crocuta","aardwolf, proteles_cristata","fox","vixen","reynard","red_fox, vulpes_vulpes","black_fox","silver_fox","red_fox, vulpes_fulva","kit_fox, prairie_fox, vulpes_velox","kit_fox, vulpes_macrotis","arctic_fox, white_fox, alopex_lagopus","blue_fox","grey_fox, gray_fox, urocyon_cinereoargenteus","feline, felid","cat, true_cat","domestic_cat, house_cat, felis_domesticus, felis_catus","kitty, kitty-cat, puss, pussy, pussycat","mouser","alley_cat","stray","tom, tomcat","gib","tabby, queen","kitten, kitty","tabby, tabby_cat","tiger_cat","tortoiseshell, tortoiseshell-cat, calico_cat","persian_cat","angora, angora_cat","siamese_cat, siamese","blue_point_siamese","burmese_cat","egyptian_cat","maltese, maltese_cat","abyssinian, abyssinian_cat","manx, manx_cat","wildcat","sand_cat","european_wildcat, catamountain, felis_silvestris","cougar, puma, catamount, mountain_lion, painter, panther, felis_concolor","ocelot, panther_cat, felis_pardalis","jaguarundi, jaguarundi_cat, jaguarondi, eyra, felis_yagouaroundi","kaffir_cat, caffer_cat, felis_ocreata","jungle_cat, felis_chaus","serval, felis_serval","leopard_cat, felis_bengalensis","margay, margay_cat, felis_wiedi","manul, pallas's_cat, felis_manul","lynx, catamount","common_lynx, lynx_lynx","canada_lynx, lynx_canadensis","bobcat, bay_lynx, lynx_rufus","spotted_lynx, lynx_pardina","caracal, desert_lynx, lynx_caracal","big_cat, cat","leopard, panthera_pardus","leopardess","panther","snow_leopard, ounce, panthera_uncia","jaguar, panther, panthera_onca, felis_onca","lion, king_of_beasts, panthera_leo","lioness","lionet","tiger, panthera_tigris","bengal_tiger","tigress","liger","tiglon, tigon","cheetah, chetah, acinonyx_jubatus","saber-toothed_tiger, sabertooth","smiledon_californicus","bear","brown_bear, bruin, ursus_arctos","bruin","syrian_bear, ursus_arctos_syriacus","grizzly, grizzly_bear, silvertip, silver-tip, ursus_horribilis, ursus_arctos_horribilis","alaskan_brown_bear, kodiak_bear, kodiak, ursus_middendorffi, ursus_arctos_middendorffi","american_black_bear, black_bear, ursus_americanus, euarctos_americanus","cinnamon_bear","asiatic_black_bear, black_bear, ursus_thibetanus, selenarctos_thibetanus","ice_bear, polar_bear, ursus_maritimus, thalarctos_maritimus","sloth_bear, melursus_ursinus, ursus_ursinus","viverrine, viverrine_mammal","civet, civet_cat","large_civet, viverra_zibetha","small_civet, viverricula_indica, viverricula_malaccensis","binturong, bearcat, arctictis_bintourong","cryptoprocta, genus_cryptoprocta","fossa, fossa_cat, cryptoprocta_ferox","fanaloka, fossa_fossa","genet, genetta_genetta","banded_palm_civet, hemigalus_hardwickii","mongoose","indian_mongoose, herpestes_nyula","ichneumon, herpestes_ichneumon","palm_cat, palm_civet","meerkat, mierkat","slender-tailed_meerkat, suricata_suricatta","suricate, suricata_tetradactyla","bat, chiropteran","fruit_bat, megabat","flying_fox","pteropus_capestratus","pteropus_hypomelanus","harpy, harpy_bat, tube-nosed_bat, tube-nosed_fruit_bat","cynopterus_sphinx","carnivorous_bat, microbat","mouse-eared_bat","leafnose_bat, leaf-nosed_bat","macrotus, macrotus_californicus","spearnose_bat","phyllostomus_hastatus","hognose_bat, choeronycteris_mexicana","horseshoe_bat","horseshoe_bat","orange_bat, orange_horseshoe_bat, rhinonicteris_aurantius","false_vampire, false_vampire_bat","big-eared_bat, megaderma_lyra","vespertilian_bat, vespertilionid","frosted_bat, vespertilio_murinus","red_bat, lasiurus_borealis","brown_bat","little_brown_bat, little_brown_myotis, myotis_leucifugus","cave_myotis, myotis_velifer","big_brown_bat, eptesicus_fuscus","serotine, european_brown_bat, eptesicus_serotinus","pallid_bat, cave_bat, antrozous_pallidus","pipistrelle, pipistrel, pipistrellus_pipistrellus","eastern_pipistrel, pipistrellus_subflavus","jackass_bat, spotted_bat, euderma_maculata","long-eared_bat","western_big-eared_bat, plecotus_townsendi","freetail, free-tailed_bat, freetailed_bat","guano_bat, mexican_freetail_bat, tadarida_brasiliensis","pocketed_bat, pocketed_freetail_bat, tadirida_femorosacca","mastiff_bat","vampire_bat, true_vampire_bat","desmodus_rotundus","hairy-legged_vampire_bat, diphylla_ecaudata","predator, predatory_animal","prey, quarry","game","big_game","game_bird","fossorial_mammal","tetrapod","quadruped","hexapod","biped","insect","social_insect","holometabola, metabola","defoliator","pollinator","gallfly","scorpion_fly","hanging_fly","collembolan, springtail","beetle","tiger_beetle","ladybug, ladybeetle, lady_beetle, ladybird, ladybird_beetle","two-spotted_ladybug, adalia_bipunctata","mexican_bean_beetle, bean_beetle, epilachna_varivestis","hippodamia_convergens","vedalia, rodolia_cardinalis","ground_beetle, carabid_beetle","bombardier_beetle","calosoma","searcher, searcher_beetle, calosoma_scrutator","firefly, lightning_bug","glowworm","long-horned_beetle, longicorn, longicorn_beetle","sawyer, sawyer_beetle","pine_sawyer","leaf_beetle, chrysomelid","flea_beetle","colorado_potato_beetle, colorado_beetle, potato_bug, potato_beetle, leptinotarsa_decemlineata","carpet_beetle, carpet_bug","buffalo_carpet_beetle, anthrenus_scrophulariae","black_carpet_beetle","clerid_beetle, clerid","bee_beetle","lamellicorn_beetle","scarabaeid_beetle, scarabaeid, scarabaean","dung_beetle","scarab, scarabaeus, scarabaeus_sacer","tumblebug","dorbeetle","june_beetle, june_bug, may_bug, may_beetle","green_june_beetle, figeater","japanese_beetle, popillia_japonica","oriental_beetle, asiatic_beetle, anomala_orientalis","rhinoceros_beetle","melolonthid_beetle","cockchafer, may_bug, may_beetle, melolontha_melolontha","rose_chafer, rose_bug, macrodactylus_subspinosus","rose_chafer, rose_beetle, cetonia_aurata","stag_beetle","elaterid_beetle, elater, elaterid","click_beetle, skipjack, snapping_beetle","firefly, fire_beetle, pyrophorus_noctiluca","wireworm","water_beetle","whirligig_beetle","deathwatch_beetle, deathwatch, xestobium_rufovillosum","weevil","snout_beetle","boll_weevil, anthonomus_grandis","blister_beetle, meloid","oil_beetle","spanish_fly","dutch-elm_beetle, scolytus_multistriatus","bark_beetle","spruce_bark_beetle, dendroctonus_rufipennis","rove_beetle","darkling_beetle, darkling_groung_beetle, tenebrionid","mealworm","flour_beetle, flour_weevil","seed_beetle, seed_weevil","pea_weevil, bruchus_pisorum","bean_weevil, acanthoscelides_obtectus","rice_weevil, black_weevil, sitophylus_oryzae","asian_longhorned_beetle, anoplophora_glabripennis","web_spinner","louse, sucking_louse","common_louse, pediculus_humanus","head_louse, pediculus_capitis","body_louse, cootie, pediculus_corporis","crab_louse, pubic_louse, crab, phthirius_pubis","bird_louse, biting_louse, louse","flea","pulex_irritans","dog_flea, ctenocephalides_canis","cat_flea, ctenocephalides_felis","chigoe, chigger, chigoe_flea, tunga_penetrans","sticktight, sticktight_flea, echidnophaga_gallinacea","dipterous_insect, two-winged_insects, dipteran, dipteron","gall_midge, gallfly, gall_gnat","hessian_fly, mayetiola_destructor","fly","housefly, house_fly, musca_domestica","tsetse_fly, tsetse, tzetze_fly, tzetze, glossina","blowfly, blow_fly","bluebottle, calliphora_vicina","greenbottle, greenbottle_fly","flesh_fly, sarcophaga_carnaria","tachina_fly","gadfly","botfly","human_botfly, dermatobia_hominis","sheep_botfly, sheep_gadfly, oestrus_ovis","warble_fly","horsefly, cleg, clegg, horse_fly","bee_fly","robber_fly, bee_killer","fruit_fly, pomace_fly","apple_maggot, railroad_worm, rhagoletis_pomonella","mediterranean_fruit_fly, medfly, ceratitis_capitata","drosophila, drosophila_melanogaster","vinegar_fly","leaf_miner, leaf-miner","louse_fly, hippoboscid","horse_tick, horsefly, hippobosca_equina","sheep_ked, sheep-tick, sheep_tick, melophagus_ovinus","horn_fly, haematobia_irritans","mosquito","wiggler, wriggler","gnat","yellow-fever_mosquito, aedes_aegypti","asian_tiger_mosquito, aedes_albopictus","anopheline","malarial_mosquito, malaria_mosquito","common_mosquito, culex_pipiens","culex_quinquefasciatus, culex_fatigans","gnat","punkie, punky, punkey, no-see-um, biting_midge","midge","fungus_gnat","psychodid","sand_fly, sandfly, phlebotomus_papatasii","fungus_gnat, sciara, sciarid","armyworm","crane_fly, daddy_longlegs","blackfly, black_fly, buffalo_gnat","hymenopterous_insect, hymenopteran, hymenopteron, hymenopter","bee","drone","queen_bee","worker","soldier","worker_bee","honeybee, apis_mellifera","africanized_bee, africanized_honey_bee, killer_bee, apis_mellifera_scutellata, apis_mellifera_adansonii","black_bee, german_bee","carniolan_bee","italian_bee","carpenter_bee","bumblebee, humblebee","cuckoo-bumblebee","andrena, andrenid, mining_bee","nomia_melanderi, alkali_bee","leaf-cutting_bee, leaf-cutter, leaf-cutter_bee","mason_bee","potter_bee","wasp","vespid, vespid_wasp","paper_wasp","hornet","giant_hornet, vespa_crabro","common_wasp, vespula_vulgaris","bald-faced_hornet, white-faced_hornet, vespula_maculata","yellow_jacket, yellow_hornet, vespula_maculifrons","polistes_annularis","mason_wasp","potter_wasp","mutillidae, family_mutillidae","velvet_ant","sphecoid_wasp, sphecoid","mason_wasp","digger_wasp","cicada_killer, sphecius_speciosis","mud_dauber","gall_wasp, gallfly, cynipid_wasp, cynipid_gall_wasp","chalcid_fly, chalcidfly, chalcid, chalcid_wasp","strawworm, jointworm","chalcis_fly","ichneumon_fly","sawfly","birch_leaf_miner, fenusa_pusilla","ant, emmet, pismire","pharaoh_ant, pharaoh's_ant, monomorium_pharaonis","little_black_ant, monomorium_minimum","army_ant, driver_ant, legionary_ant","carpenter_ant","fire_ant","wood_ant, formica_rufa","slave_ant","formica_fusca","slave-making_ant, slave-maker","sanguinary_ant, formica_sanguinea","bulldog_ant","amazon_ant, polyergus_rufescens","termite, white_ant","dry-wood_termite","reticulitermes_lucifugus","mastotermes_darwiniensis","mastotermes_electrodominicus","powder-post_termite, cryptotermes_brevis","orthopterous_insect, orthopteron, orthopteran","grasshopper, hopper","short-horned_grasshopper, acridid","locust","migratory_locust, locusta_migratoria","migratory_grasshopper","long-horned_grasshopper, tettigoniid","katydid","mormon_cricket, anabrus_simplex","sand_cricket, jerusalem_cricket, stenopelmatus_fuscus","cricket","mole_cricket","european_house_cricket, acheta_domestica","field_cricket, acheta_assimilis","tree_cricket","snowy_tree_cricket, oecanthus_fultoni","phasmid, phasmid_insect","walking_stick, walkingstick, stick_insect","diapheromera, diapheromera_femorata","walking_leaf, leaf_insect","cockroach, roach","oriental_cockroach, oriental_roach, asiatic_cockroach, blackbeetle, blatta_orientalis","american_cockroach, periplaneta_americana","australian_cockroach, periplaneta_australasiae","german_cockroach, croton_bug, crotonbug, water_bug, blattella_germanica","giant_cockroach","mantis, mantid","praying_mantis, praying_mantid, mantis_religioso","bug","hemipterous_insect, bug, hemipteran, hemipteron","leaf_bug, plant_bug","mirid_bug, mirid, capsid","four-lined_plant_bug, four-lined_leaf_bug, poecilocapsus_lineatus","lygus_bug","tarnished_plant_bug, lygus_lineolaris","lace_bug","lygaeid, lygaeid_bug","chinch_bug, blissus_leucopterus","coreid_bug, coreid","squash_bug, anasa_tristis","leaf-footed_bug, leaf-foot_bug","bedbug, bed_bug, chinch, cimex_lectularius","backswimmer, notonecta_undulata","true_bug","heteropterous_insect","water_bug","giant_water_bug","water_scorpion","water_boatman, boat_bug","water_strider, pond-skater, water_skater","common_pond-skater, gerris_lacustris","assassin_bug, reduviid","conenose, cone-nosed_bug, conenose_bug, big_bedbug, kissing_bug","wheel_bug, arilus_cristatus","firebug","cotton_stainer","homopterous_insect, homopteran","whitefly","citrus_whitefly, dialeurodes_citri","greenhouse_whitefly, trialeurodes_vaporariorum","sweet-potato_whitefly","superbug, bemisia_tabaci, poinsettia_strain","cotton_strain","coccid_insect","scale_insect","soft_scale","brown_soft_scale, coccus_hesperidum","armored_scale","san_jose_scale, aspidiotus_perniciosus","cochineal_insect, cochineal, dactylopius_coccus","mealybug, mealy_bug","citrophilous_mealybug, citrophilus_mealybug, pseudococcus_fragilis","comstock_mealybug, comstock's_mealybug, pseudococcus_comstocki","citrus_mealybug, planococcus_citri","plant_louse, louse","aphid","apple_aphid, green_apple_aphid, aphis_pomi","blackfly, bean_aphid, aphis_fabae","greenfly","green_peach_aphid","ant_cow","woolly_aphid, woolly_plant_louse","woolly_apple_aphid, american_blight, eriosoma_lanigerum","woolly_alder_aphid, prociphilus_tessellatus","adelgid","balsam_woolly_aphid, adelges_piceae","spruce_gall_aphid, adelges_abietis","woolly_adelgid","jumping_plant_louse, psylla, psyllid","cicada, cicala","dog-day_cicada, harvest_fly","seventeen-year_locust, periodical_cicada, magicicada_septendecim","spittle_insect, spittlebug","froghopper","meadow_spittlebug, philaenus_spumarius","pine_spittlebug","saratoga_spittlebug, aphrophora_saratogensis","leafhopper","plant_hopper, planthopper","treehopper","lantern_fly, lantern-fly","psocopterous_insect","psocid","bark-louse, bark_louse","booklouse, book_louse, deathwatch, liposcelis_divinatorius","common_booklouse, trogium_pulsatorium","ephemerid, ephemeropteran","mayfly, dayfly, shadfly","stonefly, stone_fly, plecopteran","neuropteron, neuropteran, neuropterous_insect","ant_lion, antlion, antlion_fly","doodlebug, ant_lion, antlion","lacewing, lacewing_fly","aphid_lion, aphis_lion","green_lacewing, chrysopid, stink_fly","brown_lacewing, hemerobiid, hemerobiid_fly","dobson, dobsonfly, dobson_fly, corydalus_cornutus","hellgrammiate, dobson","fish_fly, fish-fly","alderfly, alder_fly, sialis_lutaria","snakefly","mantispid","odonate","dragonfly, darning_needle, devil's_darning_needle, sewing_needle, snake_feeder, snake_doctor, mosquito_hawk, skeeter_hawk","damselfly","trichopterous_insect, trichopteran, trichopteron","caddis_fly, caddis-fly, caddice_fly, caddice-fly","caseworm","caddisworm, strawworm","thysanuran_insect, thysanuron","bristletail","silverfish, lepisma_saccharina","firebrat, thermobia_domestica","jumping_bristletail, machilid","thysanopter, thysanopteron, thysanopterous_insect","thrips, thrip, thripid","tobacco_thrips, frankliniella_fusca","onion_thrips, onion_louse, thrips_tobaci","earwig","common_european_earwig, forficula_auricularia","lepidopterous_insect, lepidopteron, lepidopteran","butterfly","nymphalid, nymphalid_butterfly, brush-footed_butterfly, four-footed_butterfly","mourning_cloak, mourning_cloak_butterfly, camberwell_beauty, nymphalis_antiopa","tortoiseshell, tortoiseshell_butterfly","painted_beauty, vanessa_virginiensis","admiral","red_admiral, vanessa_atalanta","white_admiral, limenitis_camilla","banded_purple, white_admiral, limenitis_arthemis","red-spotted_purple, limenitis_astyanax","viceroy, limenitis_archippus","anglewing","ringlet, ringlet_butterfly","comma, comma_butterfly, polygonia_comma","fritillary","silverspot","emperor_butterfly, emperor","purple_emperor, apatura_iris","peacock, peacock_butterfly, inachis_io","danaid, danaid_butterfly","monarch, monarch_butterfly, milkweed_butterfly, danaus_plexippus","pierid, pierid_butterfly","cabbage_butterfly","small_white, pieris_rapae","large_white, pieris_brassicae","southern_cabbage_butterfly, pieris_protodice","sulphur_butterfly, sulfur_butterfly","lycaenid, lycaenid_butterfly","blue","copper","american_copper, lycaena_hypophlaeas","hairstreak, hairstreak_butterfly","strymon_melinus","moth","moth_miller, miller","tortricid, tortricid_moth","leaf_roller, leaf-roller","tea_tortrix, tortrix, homona_coffearia","orange_tortrix, tortrix, argyrotaenia_citrana","codling_moth, codlin_moth, carpocapsa_pomonella","lymantriid, tussock_moth","tussock_caterpillar","gypsy_moth, gipsy_moth, lymantria_dispar","browntail, brown-tail_moth, euproctis_phaeorrhoea","gold-tail_moth, euproctis_chrysorrhoea","geometrid, geometrid_moth","paleacrita_vernata","alsophila_pometaria","cankerworm","spring_cankerworm","fall_cankerworm","measuring_worm, inchworm, looper","pyralid, pyralid_moth","bee_moth, wax_moth, galleria_mellonella","corn_borer, european_corn_borer_moth, corn_borer_moth, pyrausta_nubilalis","mediterranean_flour_moth, anagasta_kuehniella","tobacco_moth, cacao_moth, ephestia_elutella","almond_moth, fig_moth, cadra_cautella","raisin_moth, cadra_figulilella","tineoid, tineoid_moth","tineid, tineid_moth","clothes_moth","casemaking_clothes_moth, tinea_pellionella","webbing_clothes_moth, webbing_moth, tineola_bisselliella","carpet_moth, tapestry_moth, trichophaga_tapetzella","gelechiid, gelechiid_moth","grain_moth","angoumois_moth, angoumois_grain_moth, sitotroga_cerealella","potato_moth, potato_tuber_moth, splitworm, phthorimaea_operculella","potato_tuberworm, phthorimaea_operculella","noctuid_moth, noctuid, owlet_moth","cutworm","underwing","red_underwing, catocala_nupta","antler_moth, cerapteryx_graminis","heliothis_moth, heliothis_zia","army_cutworm, chorizagrotis_auxiliaris","armyworm, pseudaletia_unipuncta","armyworm, army_worm, pseudaletia_unipuncta","spodoptera_exigua","beet_armyworm, spodoptera_exigua","spodoptera_frugiperda","fall_armyworm, spodoptera_frugiperda","hawkmoth, hawk_moth, sphingid, sphinx_moth, hummingbird_moth","manduca_sexta","tobacco_hornworm, tomato_worm, manduca_sexta","manduca_quinquemaculata","tomato_hornworm, potato_worm, manduca_quinquemaculata","death's-head_moth, acherontia_atropos","bombycid, bombycid_moth, silkworm_moth","domestic_silkworm_moth, domesticated_silkworm_moth, bombyx_mori","silkworm","saturniid, saturniid_moth","emperor, emperor_moth, saturnia_pavonia","imperial_moth, eacles_imperialis","giant_silkworm_moth, silkworm_moth","silkworm, giant_silkworm, wild_wilkworm","luna_moth, actias_luna","cecropia, cecropia_moth, hyalophora_cecropia","cynthia_moth, samia_cynthia, samia_walkeri","ailanthus_silkworm, samia_cynthia","io_moth, automeris_io","polyphemus_moth, antheraea_polyphemus","pernyi_moth, antheraea_pernyi","tussah, tusseh, tussur, tussore, tusser, antheraea_mylitta","atlas_moth, atticus_atlas","arctiid, arctiid_moth","tiger_moth","cinnabar, cinnabar_moth, callimorpha_jacobeae","lasiocampid, lasiocampid_moth","eggar, egger","tent-caterpillar_moth, malacosoma_americana","tent_caterpillar","tent-caterpillar_moth, malacosoma_disstria","forest_tent_caterpillar, malacosoma_disstria","lappet, lappet_moth","lappet_caterpillar","webworm","webworm_moth","hyphantria_cunea","fall_webworm, hyphantria_cunea","garden_webworm, loxostege_similalis","instar","caterpillar","corn_borer, pyrausta_nubilalis","bollworm","pink_bollworm, gelechia_gossypiella","corn_earworm, cotton_bollworm, tomato_fruitworm, tobacco_budworm, vetchworm, heliothis_zia","cabbageworm, pieris_rapae","woolly_bear, woolly_bear_caterpillar","woolly_bear_moth","larva","nymph","leptocephalus","grub","maggot","leatherjacket","pupa","chrysalis","imago","queen","phoronid","bryozoan, polyzoan, sea_mat, sea_moss, moss_animal","brachiopod, lamp_shell, lampshell","peanut_worm, sipunculid","echinoderm","starfish, sea_star","brittle_star, brittle-star, serpent_star","basket_star, basket_fish","astrophyton_muricatum","sea_urchin","edible_sea_urchin, echinus_esculentus","sand_dollar","heart_urchin","crinoid","sea_lily","feather_star, comatulid","sea_cucumber, holothurian","trepang, holothuria_edulis","duplicidentata","lagomorph, gnawing_mammal","leporid, leporid_mammal","rabbit, coney, cony","rabbit_ears","lapin","bunny, bunny_rabbit","european_rabbit, old_world_rabbit, oryctolagus_cuniculus","wood_rabbit, cottontail, cottontail_rabbit","eastern_cottontail, sylvilagus_floridanus","swamp_rabbit, canecutter, swamp_hare, sylvilagus_aquaticus","marsh_hare, swamp_rabbit, sylvilagus_palustris","hare","leveret","european_hare, lepus_europaeus","jackrabbit","white-tailed_jackrabbit, whitetail_jackrabbit, lepus_townsendi","blacktail_jackrabbit, lepus_californicus","polar_hare, arctic_hare, lepus_arcticus","snowshoe_hare, snowshoe_rabbit, varying_hare, lepus_americanus","belgian_hare, leporide","angora, angora_rabbit","pika, mouse_hare, rock_rabbit, coney, cony","little_chief_hare, ochotona_princeps","collared_pika, ochotona_collaris","rodent, gnawer","mouse","rat","pocket_rat","murine","house_mouse, mus_musculus","harvest_mouse, micromyx_minutus","field_mouse, fieldmouse","nude_mouse","european_wood_mouse, apodemus_sylvaticus","brown_rat, norway_rat, rattus_norvegicus","wharf_rat","sewer_rat","black_rat, roof_rat, rattus_rattus","bandicoot_rat, mole_rat","jerboa_rat","kangaroo_mouse","water_rat","beaver_rat","new_world_mouse","american_harvest_mouse, harvest_mouse","wood_mouse","white-footed_mouse, vesper_mouse, peromyscus_leucopus","deer_mouse, peromyscus_maniculatus","cactus_mouse, peromyscus_eremicus","cotton_mouse, peromyscus_gossypinus","pygmy_mouse, baiomys_taylori","grasshopper_mouse","muskrat, musquash, ondatra_zibethica","round-tailed_muskrat, florida_water_rat, neofiber_alleni","cotton_rat, sigmodon_hispidus","wood_rat, wood-rat","dusky-footed_wood_rat","vole, field_mouse","packrat, pack_rat, trade_rat, bushytail_woodrat, neotoma_cinerea","dusky-footed_woodrat, neotoma_fuscipes","eastern_woodrat, neotoma_floridana","rice_rat, oryzomys_palustris","pine_vole, pine_mouse, pitymys_pinetorum","meadow_vole, meadow_mouse, microtus_pennsylvaticus","water_vole, richardson_vole, microtus_richardsoni","prairie_vole, microtus_ochrogaster","water_vole, water_rat, arvicola_amphibius","red-backed_mouse, redback_vole","phenacomys","hamster","eurasian_hamster, cricetus_cricetus","golden_hamster, syrian_hamster, mesocricetus_auratus","gerbil, gerbille","jird","tamarisk_gerbil, meriones_unguiculatus","sand_rat, meriones_longifrons","lemming","european_lemming, lemmus_lemmus","brown_lemming, lemmus_trimucronatus","grey_lemming, gray_lemming, red-backed_lemming","pied_lemming","hudson_bay_collared_lemming, dicrostonyx_hudsonius","southern_bog_lemming, synaptomys_cooperi","northern_bog_lemming, synaptomys_borealis","porcupine, hedgehog","old_world_porcupine","brush-tailed_porcupine, brush-tail_porcupine","long-tailed_porcupine, trichys_lipura","new_world_porcupine","canada_porcupine, erethizon_dorsatum","pocket_mouse","silky_pocket_mouse, perognathus_flavus","plains_pocket_mouse, perognathus_flavescens","hispid_pocket_mouse, perognathus_hispidus","mexican_pocket_mouse, liomys_irroratus","kangaroo_rat, desert_rat, dipodomys_phillipsii","ord_kangaroo_rat, dipodomys_ordi","kangaroo_mouse, dwarf_pocket_rat","jumping_mouse","meadow_jumping_mouse, zapus_hudsonius","jerboa","typical_jerboa","jaculus_jaculus","dormouse","loir, glis_glis","hazel_mouse, muscardinus_avellanarius","lerot","gopher, pocket_gopher, pouched_rat","plains_pocket_gopher, geomys_bursarius","southeastern_pocket_gopher, geomys_pinetis","valley_pocket_gopher, thomomys_bottae","northern_pocket_gopher, thomomys_talpoides","squirrel","tree_squirrel","eastern_grey_squirrel, eastern_gray_squirrel, cat_squirrel, sciurus_carolinensis","western_grey_squirrel, western_gray_squirrel, sciurus_griseus","fox_squirrel, eastern_fox_squirrel, sciurus_niger","black_squirrel","red_squirrel, cat_squirrel, sciurus_vulgaris","american_red_squirrel, spruce_squirrel, red_squirrel, sciurus_hudsonicus, tamiasciurus_hudsonicus","chickeree, douglas_squirrel, tamiasciurus_douglasi","antelope_squirrel, whitetail_antelope_squirrel, antelope_chipmunk, citellus_leucurus","ground_squirrel, gopher, spermophile","mantled_ground_squirrel, citellus_lateralis","suslik, souslik, citellus_citellus","flickertail, richardson_ground_squirrel, citellus_richardsoni","rock_squirrel, citellus_variegatus","arctic_ground_squirrel, parka_squirrel, citellus_parryi","prairie_dog, prairie_marmot","blacktail_prairie_dog, cynomys_ludovicianus","whitetail_prairie_dog, cynomys_gunnisoni","eastern_chipmunk, hackee, striped_squirrel, ground_squirrel, tamias_striatus","chipmunk","baronduki, baranduki, barunduki, burunduki, eutamius_asiaticus, eutamius_sibiricus","american_flying_squirrel","southern_flying_squirrel, glaucomys_volans","northern_flying_squirrel, glaucomys_sabrinus","marmot","groundhog, woodchuck, marmota_monax","hoary_marmot, whistler, whistling_marmot, marmota_caligata","yellowbelly_marmot, rockchuck, marmota_flaviventris","asiatic_flying_squirrel","beaver","old_world_beaver, castor_fiber","new_world_beaver, castor_canadensis","mountain_beaver, sewellel, aplodontia_rufa","cavy","guinea_pig, cavia_cobaya","aperea, wild_cavy, cavia_porcellus","mara, dolichotis_patagonum","capybara, capibara, hydrochoerus_hydrochaeris","agouti, dasyprocta_aguti","paca, cuniculus_paca","mountain_paca","coypu, nutria, myocastor_coypus","chinchilla, chinchilla_laniger","mountain_chinchilla, mountain_viscacha","viscacha, chinchillon, lagostomus_maximus","abrocome, chinchilla_rat, rat_chinchilla","mole_rat","mole_rat","sand_rat","naked_mole_rat","queen, queen_mole_rat","damaraland_mole_rat","ungulata","ungulate, hoofed_mammal","unguiculate, unguiculate_mammal","dinoceras, uintathere","hyrax, coney, cony, dassie, das","rock_hyrax, rock_rabbit, procavia_capensis","odd-toed_ungulate, perissodactyl, perissodactyl_mammal","equine, equid","horse, equus_caballus","roan","stablemate, stable_companion","gee-gee","eohippus, dawn_horse","foal","filly","colt","male_horse","ridgeling, ridgling, ridgel, ridgil","stallion, entire","stud, studhorse","gelding","mare, female_horse","broodmare, stud_mare","saddle_horse, riding_horse, mount","remount","palfrey","warhorse","cavalry_horse","charger, courser","steed","prancer","hack","cow_pony","quarter_horse","morgan","tennessee_walker, tennessee_walking_horse, walking_horse, plantation_walking_horse","american_saddle_horse","appaloosa","arabian, arab","lippizan, lipizzan, lippizaner","pony","polo_pony","mustang","bronco, bronc, broncho","bucking_bronco","buckskin","crowbait, crow-bait","dun","grey, gray","wild_horse","tarpan, equus_caballus_gomelini","przewalski's_horse, przevalski's_horse, equus_caballus_przewalskii, equus_caballus_przevalskii","cayuse, indian_pony","hack","hack, jade, nag, plug","plow_horse, plough_horse","pony","shetland_pony","welsh_pony","exmoor","racehorse, race_horse, bangtail","thoroughbred","steeplechaser","racer","finisher","pony","yearling","dark_horse","mudder","nonstarter","stalking-horse","harness_horse","cob","hackney","workhorse","draft_horse, draught_horse, dray_horse","packhorse","carthorse, cart_horse, drayhorse","clydesdale","percheron","farm_horse, dobbin","shire, shire_horse","pole_horse, poler","post_horse, post-horse, poster","coach_horse","pacer","pacer, pacemaker, pacesetter","trotting_horse, trotter","pole_horse","stepper, high_stepper","chestnut","liver_chestnut","bay","sorrel","palomino","pinto","ass","domestic_ass, donkey, equus_asinus","burro","moke","jack, jackass","jennet, jenny, jenny_ass","mule","hinny","wild_ass","african_wild_ass, equus_asinus","kiang, equus_kiang","onager, equus_hemionus","chigetai, dziggetai, equus_hemionus_hemionus","zebra","common_zebra, burchell's_zebra, equus_burchelli","mountain_zebra, equus_zebra_zebra","grevy's_zebra, equus_grevyi","quagga, equus_quagga","rhinoceros, rhino","indian_rhinoceros, rhinoceros_unicornis","woolly_rhinoceros, rhinoceros_antiquitatis","white_rhinoceros, ceratotherium_simum, diceros_simus","black_rhinoceros, diceros_bicornis","tapir","new_world_tapir, tapirus_terrestris","malayan_tapir, indian_tapir, tapirus_indicus","even-toed_ungulate, artiodactyl, artiodactyl_mammal","swine","hog, pig, grunter, squealer, sus_scrofa","piglet, piggy, shoat, shote","sucking_pig","porker","boar","sow","razorback, razorback_hog, razorbacked_hog","wild_boar, boar, sus_scrofa","babirusa, babiroussa, babirussa, babyrousa_babyrussa","warthog","peccary, musk_hog","collared_peccary, javelina, tayassu_angulatus, tayassu_tajacu, peccari_angulatus","white-lipped_peccary, tayassu_pecari","hippopotamus, hippo, river_horse, hippopotamus_amphibius","ruminant","bovid","bovine","ox, wild_ox","cattle, cows, kine, oxen, bos_taurus","ox","stirk","bullock, steer","bull","cow, moo-cow","heifer","bullock","dogie, dogy, leppy","maverick","beef, beef_cattle","longhorn, texas_longhorn","brahman, brahma, brahmin, bos_indicus","zebu","aurochs, urus, bos_primigenius","yak, bos_grunniens","banteng, banting, tsine, bos_banteng","welsh, welsh_black","red_poll","santa_gertrudis","aberdeen_angus, angus, black_angus","africander","dairy_cattle, dairy_cow, milch_cow, milk_cow, milcher, milker","ayrshire","brown_swiss","charolais","jersey","devon","grade","durham, shorthorn","milking_shorthorn","galloway","friesian, holstein, holstein-friesian","guernsey","hereford, whiteface","cattalo, beefalo","old_world_buffalo, buffalo","water_buffalo, water_ox, asiatic_buffalo, bubalus_bubalis","indian_buffalo","carabao","anoa, dwarf_buffalo, anoa_depressicornis","tamarau, tamarao, bubalus_mindorensis, anoa_mindorensis","cape_buffalo, synercus_caffer","asian_wild_ox","gaur, bibos_gaurus","gayal, mithan, bibos_frontalis","bison","american_bison, american_buffalo, buffalo, bison_bison","wisent, aurochs, bison_bonasus","musk_ox, musk_sheep, ovibos_moschatus","sheep","ewe","ram, tup","wether","lamb","lambkin","baa-lamb","hog, hogget, hogg","teg","persian_lamb","black_sheep","domestic_sheep, ovis_aries","cotswold","hampshire, hampshire_down","lincoln","exmoor","cheviot","broadtail, caracul, karakul","longwool","merino, merino_sheep","rambouillet","wild_sheep","argali, argal, ovis_ammon","marco_polo_sheep, marco_polo's_sheep, ovis_poli","urial, ovis_vignei","dall_sheep, dall's_sheep, white_sheep, ovis_montana_dalli","mountain_sheep","bighorn, bighorn_sheep, cimarron, rocky_mountain_bighorn, rocky_mountain_sheep, ovis_canadensis","mouflon, moufflon, ovis_musimon","aoudad, arui, audad, barbary_sheep, maned_sheep, ammotragus_lervia","goat, caprine_animal","kid","billy, billy_goat, he-goat","nanny, nanny-goat, she-goat","domestic_goat, capra_hircus","cashmere_goat, kashmir_goat","angora, angora_goat","wild_goat","bezoar_goat, pasang, capra_aegagrus","markhor, markhoor, capra_falconeri","ibex, capra_ibex","goat_antelope","mountain_goat, rocky_mountain_goat, oreamnos_americanus","goral, naemorhedus_goral","serow","chamois, rupicapra_rupicapra","takin, gnu_goat, budorcas_taxicolor","antelope","blackbuck, black_buck, antilope_cervicapra","gerenuk, litocranius_walleri","addax, addax_nasomaculatus","gnu, wildebeest","dik-dik","hartebeest","sassaby, topi, damaliscus_lunatus","impala, aepyceros_melampus","gazelle","thomson's_gazelle, gazella_thomsoni","gazella_subgutturosa","springbok, springbuck, antidorcas_marsupialis, antidorcas_euchore","bongo, tragelaphus_eurycerus, boocercus_eurycerus","kudu, koodoo, koudou","greater_kudu, tragelaphus_strepsiceros","lesser_kudu, tragelaphus_imberbis","harnessed_antelope","nyala, tragelaphus_angasi","mountain_nyala, tragelaphus_buxtoni","bushbuck, guib, tragelaphus_scriptus","nilgai, nylghai, nylghau, blue_bull, boselaphus_tragocamelus","sable_antelope, hippotragus_niger","saiga, saiga_tatarica","steenbok, steinbok, raphicerus_campestris","eland","common_eland, taurotragus_oryx","giant_eland, taurotragus_derbianus","kob, kobus_kob","lechwe, kobus_leche","waterbuck","puku, adenota_vardoni","oryx, pasang","gemsbok, gemsbuck, oryx_gazella","forest_goat, spindle_horn, pseudoryx_nghetinhensis","pronghorn, prongbuck, pronghorn_antelope, american_antelope, antilocapra_americana","deer, cervid","stag","royal, royal_stag","pricket","fawn","red_deer, elk, american_elk, wapiti, cervus_elaphus","hart, stag","hind","brocket","sambar, sambur, cervus_unicolor","wapiti, elk, american_elk, cervus_elaphus_canadensis","japanese_deer, sika, cervus_nipon, cervus_sika","virginia_deer, white_tail, whitetail, white-tailed_deer, whitetail_deer, odocoileus_virginianus","mule_deer, burro_deer, odocoileus_hemionus","black-tailed_deer, blacktail_deer, blacktail, odocoileus_hemionus_columbianus","elk, european_elk, moose, alces_alces","fallow_deer, dama_dama","roe_deer, capreolus_capreolus","roebuck","caribou, reindeer, greenland_caribou, rangifer_tarandus","woodland_caribou, rangifer_caribou","barren_ground_caribou, rangifer_arcticus","brocket","muntjac, barking_deer","musk_deer, moschus_moschiferus","pere_david's_deer, elaphure, elaphurus_davidianus","chevrotain, mouse_deer","kanchil, tragulus_kanchil","napu, tragulus_javanicus","water_chevrotain, water_deer, hyemoschus_aquaticus","camel","arabian_camel, dromedary, camelus_dromedarius","bactrian_camel, camelus_bactrianus","llama","domestic_llama, lama_peruana","guanaco, lama_guanicoe","alpaca, lama_pacos","vicuna, vicugna_vicugna","giraffe, camelopard, giraffa_camelopardalis","okapi, okapia_johnstoni","musteline_mammal, mustelid, musteline","weasel","ermine, shorttail_weasel, mustela_erminea","stoat","new_world_least_weasel, mustela_rixosa","old_world_least_weasel, mustela_nivalis","longtail_weasel, long-tailed_weasel, mustela_frenata","mink","american_mink, mustela_vison","polecat, fitch, foulmart, foumart, mustela_putorius","ferret","black-footed_ferret, ferret, mustela_nigripes","muishond","snake_muishond, poecilogale_albinucha","striped_muishond, ictonyx_striata","otter","river_otter, lutra_canadensis","eurasian_otter, lutra_lutra","sea_otter, enhydra_lutris","skunk, polecat, wood_pussy","striped_skunk, mephitis_mephitis","hooded_skunk, mephitis_macroura","hog-nosed_skunk, hognosed_skunk, badger_skunk, rooter_skunk, conepatus_leuconotus","spotted_skunk, little_spotted_skunk, spilogale_putorius","badger","american_badger, taxidea_taxus","eurasian_badger, meles_meles","ratel, honey_badger, mellivora_capensis","ferret_badger","hog_badger, hog-nosed_badger, sand_badger, arctonyx_collaris","wolverine, carcajou, skunk_bear, gulo_luscus","glutton, gulo_gulo, wolverine","grison, grison_vittatus, galictis_vittatus","marten, marten_cat","pine_marten, martes_martes","sable, martes_zibellina","american_marten, american_sable, martes_americana","stone_marten, beech_marten, martes_foina","fisher, pekan, fisher_cat, black_cat, martes_pennanti","yellow-throated_marten, charronia_flavigula","tayra, taira, eira_barbara","fictional_animal","pachyderm","edentate","armadillo","peba, nine-banded_armadillo, texas_armadillo, dasypus_novemcinctus","apar, three-banded_armadillo, tolypeutes_tricinctus","tatouay, cabassous, cabassous_unicinctus","peludo, poyou, euphractus_sexcinctus","giant_armadillo, tatou, tatu, priodontes_giganteus","pichiciago, pichiciego, fairy_armadillo, chlamyphore, chlamyphorus_truncatus","sloth, tree_sloth","three-toed_sloth, ai, bradypus_tridactylus","two-toed_sloth, unau, unai, choloepus_didactylus","two-toed_sloth, unau, unai, choloepus_hoffmanni","megatherian, megatheriid, megatherian_mammal","mylodontid","anteater, new_world_anteater","ant_bear, giant_anteater, great_anteater, tamanoir, myrmecophaga_jubata","silky_anteater, two-toed_anteater, cyclopes_didactylus","tamandua, tamandu, lesser_anteater, tamandua_tetradactyla","pangolin, scaly_anteater, anteater","coronet","scapular","tadpole, polliwog, pollywog","primate","simian","ape","anthropoid","anthropoid_ape","hominoid","hominid","homo, man, human_being, human","world, human_race, humanity, humankind, human_beings, humans, mankind, man","homo_erectus","pithecanthropus, pithecanthropus_erectus, genus_pithecanthropus","java_man, trinil_man","peking_man","sinanthropus, genus_sinanthropus","homo_soloensis","javanthropus, genus_javanthropus","homo_habilis","homo_sapiens","neandertal_man, neanderthal_man, neandertal, neanderthal, homo_sapiens_neanderthalensis","cro-magnon","homo_sapiens_sapiens, modern_man","australopithecine","australopithecus_afarensis","australopithecus_africanus","australopithecus_boisei","zinjanthropus, genus_zinjanthropus","australopithecus_robustus","paranthropus, genus_paranthropus","sivapithecus","rudapithecus, dryopithecus_rudapithecus_hungaricus","proconsul","aegyptopithecus","great_ape, pongid","orangutan, orang, orangutang, pongo_pygmaeus","gorilla, gorilla_gorilla","western_lowland_gorilla, gorilla_gorilla_gorilla","eastern_lowland_gorilla, gorilla_gorilla_grauri","mountain_gorilla, gorilla_gorilla_beringei","silverback","chimpanzee, chimp, pan_troglodytes","western_chimpanzee, pan_troglodytes_verus","eastern_chimpanzee, pan_troglodytes_schweinfurthii","central_chimpanzee, pan_troglodytes_troglodytes","pygmy_chimpanzee, bonobo, pan_paniscus","lesser_ape","gibbon, hylobates_lar","siamang, hylobates_syndactylus, symphalangus_syndactylus","monkey","old_world_monkey, catarrhine","guenon, guenon_monkey","talapoin, cercopithecus_talapoin","grivet, cercopithecus_aethiops","vervet, vervet_monkey, cercopithecus_aethiops_pygerythrus","green_monkey, african_green_monkey, cercopithecus_aethiops_sabaeus","mangabey","patas, hussar_monkey, erythrocebus_patas","baboon","chacma, chacma_baboon, papio_ursinus","mandrill, mandrillus_sphinx","drill, mandrillus_leucophaeus","macaque","rhesus, rhesus_monkey, macaca_mulatta","bonnet_macaque, bonnet_monkey, capped_macaque, crown_monkey, macaca_radiata","barbary_ape, macaca_sylvana","crab-eating_macaque, croo_monkey, macaca_irus","langur","entellus, hanuman, presbytes_entellus, semnopithecus_entellus","colobus, colobus_monkey","guereza, colobus_guereza","proboscis_monkey, nasalis_larvatus","new_world_monkey, platyrrhine, platyrrhinian","marmoset","true_marmoset","pygmy_marmoset, cebuella_pygmaea","tamarin, lion_monkey, lion_marmoset, leoncita","silky_tamarin, leontocebus_rosalia","pinche, leontocebus_oedipus","capuchin, ringtail, cebus_capucinus","douroucouli, aotus_trivirgatus","howler_monkey, howler","saki","uakari","titi, titi_monkey","spider_monkey, ateles_geoffroyi","squirrel_monkey, saimiri_sciureus","woolly_monkey","tree_shrew","prosimian","lemur","madagascar_cat, ring-tailed_lemur, lemur_catta","aye-aye, daubentonia_madagascariensis","slender_loris, loris_gracilis","slow_loris, nycticebus_tardigradua, nycticebus_pygmaeus","potto, kinkajou, perodicticus_potto","angwantibo, golden_potto, arctocebus_calabarensis","galago, bushbaby, bush_baby","indri, indris, indri_indri, indri_brevicaudatus","woolly_indris, avahi_laniger","tarsier","tarsius_syrichta","tarsius_glis","flying_lemur, flying_cat, colugo","cynocephalus_variegatus","proboscidean, proboscidian","elephant","rogue_elephant","indian_elephant, elephas_maximus","african_elephant, loxodonta_africana","mammoth","woolly_mammoth, northern_mammoth, mammuthus_primigenius","columbian_mammoth, mammuthus_columbi","imperial_mammoth, imperial_elephant, archidiskidon_imperator","mastodon, mastodont","plantigrade_mammal, plantigrade","digitigrade_mammal, digitigrade","procyonid","raccoon, racoon","common_raccoon, common_racoon, coon, ringtail, procyon_lotor","crab-eating_raccoon, procyon_cancrivorus","bassarisk, cacomistle, cacomixle, coon_cat, raccoon_fox, ringtail, ring-tailed_cat, civet_cat, miner's_cat, bassariscus_astutus","kinkajou, honey_bear, potto, potos_flavus, potos_caudivolvulus","coati, coati-mondi, coati-mundi, coon_cat, nasua_narica","lesser_panda, red_panda, panda, bear_cat, cat_bear, ailurus_fulgens","giant_panda, panda, panda_bear, coon_bear, ailuropoda_melanoleuca","twitterer","fish","fingerling","game_fish, sport_fish","food_fish","rough_fish","groundfish, bottom_fish","young_fish","parr","mouthbreeder","spawner","barracouta, snoek","crossopterygian, lobefin, lobe-finned_fish","coelacanth, latimeria_chalumnae","lungfish","ceratodus","catfish, siluriform_fish","silurid, silurid_fish","european_catfish, sheatfish, silurus_glanis","electric_catfish, malopterurus_electricus","bullhead, bullhead_catfish","horned_pout, hornpout, pout, ameiurus_melas","brown_bullhead","channel_catfish, channel_cat, ictalurus_punctatus","blue_catfish, blue_cat, blue_channel_catfish, blue_channel_cat","flathead_catfish, mudcat, goujon, shovelnose_catfish, spoonbill_catfish, pylodictus_olivaris","armored_catfish","sea_catfish","gadoid, gadoid_fish","cod, codfish","codling","atlantic_cod, gadus_morhua","pacific_cod, alaska_cod, gadus_macrocephalus","whiting, merlangus_merlangus, gadus_merlangus","burbot, eelpout, ling, cusk, lota_lota","haddock, melanogrammus_aeglefinus","pollack, pollock, pollachius_pollachius","hake","silver_hake, merluccius_bilinearis, whiting","ling","cusk, torsk, brosme_brosme","grenadier, rattail, rattail_fish","eel","elver","common_eel, freshwater_eel","tuna, anguilla_sucklandii","moray, moray_eel","conger, conger_eel","teleost_fish, teleost, teleostan","beaked_salmon, sandfish, gonorhynchus_gonorhynchus","clupeid_fish, clupeid","whitebait","brit, britt","shad","common_american_shad, alosa_sapidissima","river_shad, alosa_chrysocloris","allice_shad, allis_shad, allice, allis, alosa_alosa","alewife, alosa_pseudoharengus, pomolobus_pseudoharengus","menhaden, brevoortia_tyrannis","herring, clupea_harangus","atlantic_herring, clupea_harengus_harengus","pacific_herring, clupea_harengus_pallasii","sardine","sild","brisling, sprat, clupea_sprattus","pilchard, sardine, sardina_pilchardus","pacific_sardine, sardinops_caerulea","anchovy","mediterranean_anchovy, engraulis_encrasicholus","salmonid","salmon","parr","blackfish","redfish","atlantic_salmon, salmo_salar","landlocked_salmon, lake_salmon","sockeye, sockeye_salmon, red_salmon, blueback_salmon, oncorhynchus_nerka","chinook, chinook_salmon, king_salmon, quinnat_salmon, oncorhynchus_tshawytscha","coho, cohoe, coho_salmon, blue_jack, silver_salmon, oncorhynchus_kisutch","trout","brown_trout, salmon_trout, salmo_trutta","rainbow_trout, salmo_gairdneri","sea_trout","lake_trout, salmon_trout, salvelinus_namaycush","brook_trout, speckled_trout, salvelinus_fontinalis","char, charr","arctic_char, salvelinus_alpinus","whitefish","lake_whitefish, coregonus_clupeaformis","cisco, lake_herring, coregonus_artedi","round_whitefish, menominee_whitefish, prosopium_cylindraceum","smelt","sparling, european_smelt, osmerus_eperlanus","capelin, capelan, caplin","tarpon, tarpon_atlanticus","ladyfish, tenpounder, elops_saurus","bonefish, albula_vulpes","argentine","lanternfish","lizardfish, snakefish, snake-fish","lancetfish, lancet_fish, wolffish","opah, moonfish, lampris_regius","new_world_opah, lampris_guttatus","ribbonfish","dealfish, trachipterus_arcticus","oarfish, king_of_the_herring, ribbonfish, regalecus_glesne","batfish","goosefish, angler, anglerfish, angler_fish, monkfish, lotte, allmouth, lophius_americanus","toadfish, opsanus_tau","oyster_fish, oyster-fish, oysterfish","frogfish","sargassum_fish","needlefish, gar, billfish","timucu","flying_fish","monoplane_flying_fish, two-wing_flying_fish","halfbeak","saury, billfish, scomberesox_saurus","spiny-finned_fish, acanthopterygian","lingcod, ophiodon_elongatus","percoid_fish, percoid, percoidean","perch","climbing_perch, anabas_testudineus, a._testudineus","perch","yellow_perch, perca_flavescens","european_perch, perca_fluviatilis","pike-perch, pike_perch","walleye, walleyed_pike, jack_salmon, dory, stizostedion_vitreum","blue_pike, blue_pickerel, blue_pikeperch, blue_walleye, strizostedion_vitreum_glaucum","snail_darter, percina_tanasi","cusk-eel","brotula","pearlfish, pearl-fish","robalo","snook","pike","northern_pike, esox_lucius","muskellunge, esox_masquinongy","pickerel","chain_pickerel, chain_pike, esox_niger","redfin_pickerel, barred_pickerel, esox_americanus","sunfish, centrarchid","crappie","black_crappie, pomoxis_nigromaculatus","white_crappie, pomoxis_annularis","freshwater_bream, bream","pumpkinseed, lepomis_gibbosus","bluegill, lepomis_macrochirus","spotted_sunfish, stumpknocker, lepomis_punctatus","freshwater_bass","rock_bass, rock_sunfish, ambloplites_rupestris","black_bass","kentucky_black_bass, spotted_black_bass, micropterus_pseudoplites","smallmouth, smallmouth_bass, smallmouthed_bass, smallmouth_black_bass, smallmouthed_black_bass, micropterus_dolomieu","largemouth, largemouth_bass, largemouthed_bass, largemouth_black_bass, largemouthed_black_bass, micropterus_salmoides","bass","serranid_fish, serranid","white_perch, silver_perch, morone_americana","yellow_bass, morone_interrupta","blackmouth_bass, synagrops_bellus","rock_sea_bass, rock_bass, centropristis_philadelphica","striped_bass, striper, roccus_saxatilis, rockfish","stone_bass, wreckfish, polyprion_americanus","grouper","hind","rock_hind, epinephelus_adscensionis","creole-fish, paranthias_furcifer","jewfish, mycteroperca_bonaci","soapfish","surfperch, surffish, surf_fish","rainbow_seaperch, rainbow_perch, hipsurus_caryi","bigeye","catalufa, priacanthus_arenatus","cardinalfish","flame_fish, flamefish, apogon_maculatus","tilefish, lopholatilus_chamaeleonticeps","bluefish, pomatomus_saltatrix","cobia, rachycentron_canadum, sergeant_fish","remora, suckerfish, sucking_fish","sharksucker, echeneis_naucrates","whale_sucker, whalesucker, remilegia_australis","carangid_fish, carangid","jack","crevalle_jack, jack_crevalle, caranx_hippos","yellow_jack, caranx_bartholomaei","runner, blue_runner, caranx_crysos","rainbow_runner, elagatis_bipinnulata","leatherjacket, leatherjack","threadfish, thread-fish, alectis_ciliaris","moonfish, atlantic_moonfish, horsefish, horsehead, horse-head, dollarfish, selene_setapinnis","lookdown, lookdown_fish, selene_vomer","amberjack, amberfish","yellowtail, seriola_dorsalis","kingfish, seriola_grandis","pompano","florida_pompano, trachinotus_carolinus","permit, trachinotus_falcatus","scad","horse_mackerel, jack_mackerel, spanish_mackerel, saurel, trachurus_symmetricus","horse_mackerel, saurel, trachurus_trachurus","bigeye_scad, big-eyed_scad, goggle-eye, selar_crumenophthalmus","mackerel_scad, mackerel_shad, decapterus_macarellus","round_scad, cigarfish, quiaquia, decapterus_punctatus","dolphinfish, dolphin, mahimahi","coryphaena_hippurus","coryphaena_equisetis","pomfret, brama_raii","characin, characin_fish, characid","tetra","cardinal_tetra, paracheirodon_axelrodi","piranha, pirana, caribe","cichlid, cichlid_fish","bolti, tilapia_nilotica","snapper","red_snapper, lutjanus_blackfordi","grey_snapper, gray_snapper, mangrove_snapper, lutjanus_griseus","mutton_snapper, muttonfish, lutjanus_analis","schoolmaster, lutjanus_apodus","yellowtail, yellowtail_snapper, ocyurus_chrysurus","grunt","margate, haemulon_album","spanish_grunt, haemulon_macrostomum","tomtate, haemulon_aurolineatum","cottonwick, haemulon_malanurum","sailor's-choice, sailors_choice, haemulon_parra","porkfish, pork-fish, anisotremus_virginicus","pompon, black_margate, anisotremus_surinamensis","pigfish, hogfish, orthopristis_chrysopterus","sparid, sparid_fish","sea_bream, bream","porgy","red_porgy, pagrus_pagrus","european_sea_bream, pagellus_centrodontus","atlantic_sea_bream, archosargus_rhomboidalis","sheepshead, archosargus_probatocephalus","pinfish, sailor's-choice, squirrelfish, lagodon_rhomboides","sheepshead_porgy, calamus_penna","snapper, chrysophrys_auratus","black_bream, chrysophrys_australis","scup, northern_porgy, northern_scup, stenotomus_chrysops","scup, southern_porgy, southern_scup, stenotomus_aculeatus","sciaenid_fish, sciaenid","striped_drum, equetus_pulcher","jackknife-fish, equetus_lanceolatus","silver_perch, mademoiselle, bairdiella_chrysoura","red_drum, channel_bass, redfish, sciaenops_ocellatus","mulloway, jewfish, sciaena_antarctica","maigre, maiger, sciaena_aquila","croaker","atlantic_croaker, micropogonias_undulatus","yellowfin_croaker, surffish, surf_fish, umbrina_roncador","whiting","kingfish","king_whiting, menticirrhus_americanus","northern_whiting, menticirrhus_saxatilis","corbina, menticirrhus_undulatus","white_croaker, chenfish, kingfish, genyonemus_lineatus","white_croaker, queenfish, seriphus_politus","sea_trout","weakfish, cynoscion_regalis","spotted_weakfish, spotted_sea_trout, spotted_squeateague, cynoscion_nebulosus","mullet","goatfish, red_mullet, surmullet, mullus_surmuletus","red_goatfish, mullus_auratus","yellow_goatfish, mulloidichthys_martinicus","mullet, grey_mullet, gray_mullet","striped_mullet, mugil_cephalus","white_mullet, mugil_curema","liza, mugil_liza","silversides, silverside","jacksmelt, atherinopsis_californiensis","barracuda","great_barracuda, sphyraena_barracuda","sweeper","sea_chub","bermuda_chub, rudderfish, kyphosus_sectatrix","spadefish, angelfish, chaetodipterus_faber","butterfly_fish","chaetodon","angelfish","rock_beauty, holocanthus_tricolor","damselfish, demoiselle","beaugregory, pomacentrus_leucostictus","anemone_fish","clown_anemone_fish, amphiprion_percula","sergeant_major, abudefduf_saxatilis","wrasse","pigfish, giant_pigfish, achoerodus_gouldii","hogfish, hog_snapper, lachnolaimus_maximus","slippery_dick, halicoeres_bivittatus","puddingwife, pudding-wife, halicoeres_radiatus","bluehead, thalassoma_bifasciatum","pearly_razorfish, hemipteronatus_novacula","tautog, blackfish, tautoga_onitis","cunner, bergall, tautogolabrus_adspersus","parrotfish, polly_fish, pollyfish","threadfin","jawfish","stargazer","sand_stargazer","blenny, combtooth_blenny","shanny, blennius_pholis","molly_miller, scartella_cristata","clinid, clinid_fish","pikeblenny","bluethroat_pikeblenny, chaenopsis_ocellata","gunnel, bracketed_blenny","rock_gunnel, butterfish, pholis_gunnellus","eelblenny","wrymouth, ghostfish, cryptacanthodes_maculatus","wolffish, wolf_fish, catfish","viviparous_eelpout, zoarces_viviparus","ocean_pout, macrozoarces_americanus","sand_lance, sand_launce, sand_eel, launce","dragonet","goby, gudgeon","mudskipper, mudspringer","sleeper, sleeper_goby","flathead","archerfish, toxotes_jaculatrix","surgeonfish","gempylid","snake_mackerel, gempylus_serpens","escolar, lepidocybium_flavobrunneum","oilfish, ruvettus_pretiosus","cutlassfish, frost_fish, hairtail","scombroid, scombroid_fish","mackerel","common_mackerel, shiner, scomber_scombrus","spanish_mackerel, scomber_colias","chub_mackerel, tinker, scomber_japonicus","wahoo, acanthocybium_solandri","spanish_mackerel","king_mackerel, cavalla, cero, scomberomorus_cavalla","scomberomorus_maculatus","cero, pintado, kingfish, scomberomorus_regalis","sierra, scomberomorus_sierra","tuna, tunny","albacore, long-fin_tunny, thunnus_alalunga","bluefin, bluefin_tuna, horse_mackerel, thunnus_thynnus","yellowfin, yellowfin_tuna, thunnus_albacares","bonito","skipjack, atlantic_bonito, sarda_sarda","chile_bonito, chilean_bonito, pacific_bonito, sarda_chiliensis","skipjack, skipjack_tuna, euthynnus_pelamis","bonito, oceanic_bonito, katsuwonus_pelamis","swordfish, xiphias_gladius","sailfish","atlantic_sailfish, istiophorus_albicans","billfish","marlin","blue_marlin, makaira_nigricans","black_marlin, makaira_mazara, makaira_marlina","striped_marlin, makaira_mitsukurii","white_marlin, makaira_albida","spearfish","louvar, luvarus_imperialis","dollarfish, poronotus_triacanthus","palometa, california_pompano, palometa_simillima","harvestfish, paprilus_alepidotus","driftfish","barrelfish, black_rudderfish, hyperglyphe_perciformis","clingfish","tripletail","atlantic_tripletail, lobotes_surinamensis","pacific_tripletail, lobotes_pacificus","mojarra","yellowfin_mojarra, gerres_cinereus","silver_jenny, eucinostomus_gula","whiting","ganoid, ganoid_fish","bowfin, grindle, dogfish, amia_calva","paddlefish, duckbill, polyodon_spathula","chinese_paddlefish, psephurus_gladis","sturgeon","pacific_sturgeon, white_sturgeon, sacramento_sturgeon, acipenser_transmontanus","beluga, hausen, white_sturgeon, acipenser_huso","gar, garfish, garpike, billfish, lepisosteus_osseus","scorpaenoid, scorpaenoid_fish","scorpaenid, scorpaenid_fish","scorpionfish, scorpion_fish, sea_scorpion","plumed_scorpionfish, scorpaena_grandicornis","lionfish","stonefish, synanceja_verrucosa","rockfish","copper_rockfish, sebastodes_caurinus","vermillion_rockfish, rasher, sebastodes_miniatus","red_rockfish, sebastodes_ruberrimus","rosefish, ocean_perch, sebastodes_marinus","bullhead","miller's-thumb","sea_raven, hemitripterus_americanus","lumpfish, cyclopterus_lumpus","lumpsucker","pogge, armed_bullhead, agonus_cataphractus","greenling","kelp_greenling, hexagrammos_decagrammus","painted_greenling, convict_fish, convictfish, oxylebius_pictus","flathead","gurnard","tub_gurnard, yellow_gurnard, trigla_lucerna","sea_robin, searobin","northern_sea_robin, prionotus_carolinus","flying_gurnard, flying_robin, butterflyfish","plectognath, plectognath_fish","triggerfish","queen_triggerfish, bessy_cerca, oldwench, oldwife, balistes_vetula","filefish","leatherjacket, leatherfish","boxfish, trunkfish","cowfish, lactophrys_quadricornis","puffer, pufferfish, blowfish, globefish","spiny_puffer","porcupinefish, porcupine_fish, diodon_hystrix","balloonfish, diodon_holocanthus","burrfish","ocean_sunfish, sunfish, mola, headfish","sharptail_mola, mola_lanceolata","flatfish","flounder","righteye_flounder, righteyed_flounder","plaice, pleuronectes_platessa","european_flatfish, platichthys_flesus","yellowtail_flounder, limanda_ferruginea","winter_flounder, blackback_flounder, lemon_sole, pseudopleuronectes_americanus","lemon_sole, microstomus_kitt","american_plaice, hippoglossoides_platessoides","halibut, holibut","atlantic_halibut, hippoglossus_hippoglossus","pacific_halibut, hippoglossus_stenolepsis","lefteye_flounder, lefteyed_flounder","southern_flounder, paralichthys_lethostigmus","summer_flounder, paralichthys_dentatus","whiff","horned_whiff, citharichthys_cornutus","sand_dab","windowpane, scophthalmus_aquosus","brill, scophthalmus_rhombus","turbot, psetta_maxima","tonguefish, tongue-fish","sole","european_sole, solea_solea","english_sole, lemon_sole, parophrys_vitulus","hogchoker, trinectes_maculatus","aba","abacus","abandoned_ship, derelict","a_battery","abattoir, butchery, shambles, slaughterhouse","abaya","abbe_condenser","abbey","abbey","abbey","abney_level","abrader, abradant","abrading_stone","abutment","abutment_arch","academic_costume","academic_gown, academic_robe, judge's_robe","accelerator, throttle, throttle_valve","accelerator, particle_accelerator, atom_smasher","accelerator, accelerator_pedal, gas_pedal, gas, throttle, gun","accelerometer","accessory, accoutrement, accouterment","accommodating_lens_implant, accommodating_iol","accommodation","accordion, piano_accordion, squeeze_box","acetate_disk, phonograph_recording_disk","acetate_rayon, acetate","achromatic_lens","acoustic_delay_line, sonic_delay_line","acoustic_device","acoustic_guitar","acoustic_modem","acropolis","acrylic","acrylic, acrylic_paint","actinometer","action, action_mechanism","active_matrix_screen","actuator","adapter, adaptor","adder","adding_machine, totalizer, totaliser","addressing_machine, addressograph","adhesive_bandage","adit","adjoining_room","adjustable_wrench, adjustable_spanner","adobe, adobe_brick","adz, adze","aeolian_harp, aeolian_lyre, wind_harp","aerator","aerial_torpedo","aerosol, aerosol_container, aerosol_can, aerosol_bomb, spray_can","aertex","afghan","afro-wig","afterburner","after-shave, after-shave_lotion","agateware","agglomerator","aglet, aiglet, aiguilette","aglet, aiglet","agora, public_square","aigrette, aigret","aileron","air_bag","airbrake","airbrush","airbus","air_compressor","air_conditioner, air_conditioning","aircraft","aircraft_carrier, carrier, flattop, attack_aircraft_carrier","aircraft_engine","air_cushion, air_spring","airdock, hangar, repair_shed","airfield, landing_field, flying_field, field","air_filter, air_cleaner","airfoil, aerofoil, control_surface, surface","airframe","air_gun, airgun, air_rifle","air_hammer, jackhammer, pneumatic_hammer","air_horn","airing_cupboard","airliner","airmailer","airplane, aeroplane, plane","airplane_propeller, airscrew, prop","airport, airdrome, aerodrome, drome","air_pump, vacuum_pump","air_search_radar","airship, dirigible","air_terminal, airport_terminal","air-to-air_missile","air-to-ground_missile, air-to-surface_missile","aisle","aladdin's_lamp","alarm, warning_device, alarm_system","alarm_clock, alarm","alb","alcazar","alcohol_thermometer, alcohol-in-glass_thermometer","alehouse","alembic","algometer","alidade, alidad","alidade, alidad","a-line","allen_screw","allen_wrench","alligator_wrench","alms_dish, alms_tray","alpaca","alpenstock","altar","altar, communion_table, lord's_table","altarpiece, reredos","altazimuth","alternator","altimeter","amati","ambulance","amen_corner","american_organ","ammeter","ammonia_clock","ammunition, ammo","amphibian, amphibious_aircraft","amphibian, amphibious_vehicle","amphitheater, amphitheatre, coliseum","amphitheater, amphitheatre","amphora","amplifier","ampulla","amusement_arcade","analog_clock","analog_computer, analogue_computer","analog_watch","analytical_balance, chemical_balance","analyzer, analyser","anamorphosis, anamorphism","anastigmat","anchor, ground_tackle","anchor_chain, anchor_rope","anchor_light, riding_light, riding_lamp","and_circuit, and_gate","andiron, firedog, dog, dog-iron","android, humanoid, mechanical_man","anechoic_chamber","anemometer, wind_gauge, wind_gage","aneroid_barometer, aneroid","angiocardiogram","angioscope","angle_bracket, angle_iron","angledozer","ankle_brace","anklet, anklets, bobbysock, bobbysocks","anklet","ankus","anode","anode","answering_machine","antenna, aerial, transmitting_aerial","anteroom, antechamber, entrance_hall, hall, foyer, lobby, vestibule","antiaircraft, antiaircraft_gun, flak, flack, pom-pom, ack-ack, ack-ack_gun","antiballistic_missile, abm","antifouling_paint","anti-g_suit, g_suit","antimacassar","antiperspirant","anti-submarine_rocket","anvil","ao_dai","apadana","apartment, flat","apartment_building, apartment_house","aperture","aperture","apiary, bee_house","apparatus, setup","apparel, wearing_apparel, dress, clothes","applecart","appliance","appliance, contraption, contrivance, convenience, gadget, gizmo, gismo, widget","applicator, applier","appointment, fitting","apron","apron_string","apse, apsis","aqualung, aqua-lung, scuba","aquaplane","aquarium, fish_tank, marine_museum","arabesque","arbor, arbour, bower, pergola","arcade, colonnade","arch","architecture","architrave","arch_support","arc_lamp, arc_light","arctic, galosh, golosh, rubber, gumshoe","area","areaway","argyle, argyll","ark","arm","armament","armature","armband","armchair","armet","arm_guard, arm_pad","armhole","armilla","armlet, arm_band","armoire","armor, armour","armored_car, armoured_car","armored_car, armoured_car","armored_personnel_carrier, armoured_personnel_carrier, apc","armored_vehicle, armoured_vehicle","armor_plate, armour_plate, armor_plating, plate_armor, plate_armour","armory, armoury, arsenal","armrest","arquebus, harquebus, hackbut, hagbut","array","array, raiment, regalia","arrester, arrester_hook","arrow","arsenal, armory, armoury","arterial_road","arthrogram","arthroscope","artificial_heart","artificial_horizon, gyro_horizon, flight_indicator","artificial_joint","artificial_kidney, hemodialyzer","artificial_skin","artillery, heavy_weapon, gun, ordnance","artillery_shell","artist's_loft","art_school","ascot","ashcan, trash_can, garbage_can, wastebin, ash_bin, ash-bin, ashbin, dustbin, trash_barrel, trash_bin","ash-pan","ashtray","aspergill, aspersorium","aspersorium","aspirator","aspirin_powder, headache_powder","assault_gun","assault_rifle, assault_gun","assegai, assagai","assembly","assembly","assembly_hall","assembly_plant","astatic_coils","astatic_galvanometer","astrodome","astrolabe","astronomical_telescope","astronomy_satellite","athenaeum, atheneum","athletic_sock, sweat_sock, varsity_sock","athletic_supporter, supporter, suspensor, jockstrap, jock","atlas, telamon","atmometer, evaporometer","atom_bomb, atomic_bomb, a-bomb, fission_bomb, plutonium_bomb","atomic_clock","atomic_pile, atomic_reactor, pile, chain_reactor","atomizer, atomiser, spray, sprayer, nebulizer, nebuliser","atrium","attache_case, attache","attachment, bond","attack_submarine","attenuator","attic","attic_fan","attire, garb, dress","audio_amplifier","audiocassette","audio_cd, audio_compact_disc","audiometer, sonometer","audio_system, sound_system","audiotape","audiotape","audiovisual, audiovisual_aid","auditorium","auger, gimlet, screw_auger, wimble","autobahn","autoclave, sterilizer, steriliser","autofocus","autogiro, autogyro, gyroplane","autoinjector","autoloader, self-loader","automat","automat","automatic_choke","automatic_firearm, automatic_gun, automatic_weapon","automatic_pistol, automatic","automatic_rifle, automatic, machine_rifle","automatic_transmission, automatic_drive","automation","automaton, robot, golem","automobile_engine","automobile_factory, auto_factory, car_factory","automobile_horn, car_horn, motor_horn, horn, hooter","autopilot, automatic_pilot, robot_pilot","autoradiograph","autostrada","auxiliary_boiler, donkey_boiler","auxiliary_engine, donkey_engine","auxiliary_pump, donkey_pump","auxiliary_research_submarine","auxiliary_storage, external_storage, secondary_storage","aviary, bird_sanctuary, volary","awl","awning, sunshade, sunblind","ax, axe","ax_handle, axe_handle","ax_head, axe_head","axis, axis_of_rotation","axle","axle_bar","axletree","babushka","baby_bed, baby's_bed","baby_buggy, baby_carriage, carriage, perambulator, pram, stroller, go-cart, pushchair, pusher","baby_grand, baby_grand_piano, parlor_grand, parlor_grand_piano, parlour_grand, parlour_grand_piano","baby_powder","baby_shoe","back, backrest","back","backbench","backboard","backboard, basketball_backboard","backbone","back_brace","backgammon_board","background, desktop, screen_background","backhoe","backlighting","backpack, back_pack, knapsack, packsack, rucksack, haversack","backpacking_tent, pack_tent","backplate","back_porch","backsaw, back_saw","backscratcher","backseat","backspace_key, backspace, backspacer","backstairs","backstay","backstop","backsword","backup_system","badminton_court","badminton_equipment","badminton_racket, badminton_racquet, battledore","bag","bag, traveling_bag, travelling_bag, grip, suitcase","bag, handbag, pocketbook, purse","baggage, luggage","baggage","baggage_car, luggage_van","baggage_claim","bagpipe","bailey","bailey","bailey_bridge","bain-marie","bait, decoy, lure","baize","bakery, bakeshop, bakehouse","balaclava, balaclava_helmet","balalaika","balance","balance_beam, beam","balance_wheel, balance","balbriggan","balcony","balcony","baldachin","baldric, baldrick","bale","baling_wire","ball","ball","ball_and_chain","ball-and-socket_joint","ballast, light_ballast","ball_bearing, needle_bearing, roller_bearing","ball_cartridge","ballcock, ball_cock","balldress","ballet_skirt, tutu","ball_gown","ballistic_galvanometer","ballistic_missile","ballistic_pendulum","ballistocardiograph, cardiograph","balloon","balloon_bomb, fugo","balloon_sail","ballot_box","ballpark, park","ball-peen_hammer","ballpoint, ballpoint_pen, ballpen, biro","ballroom, dance_hall, dance_palace","ball_valve","balsa_raft, kon_tiki","baluster","banana_boat","band","bandage, patch","band_aid","bandanna, bandana","bandbox","banderilla","bandoleer, bandolier","bandoneon","bandsaw, band_saw","bandwagon","bangalore_torpedo","bangle, bauble, gaud, gewgaw, novelty, fallal, trinket","banjo","banner, streamer","bannister, banister, balustrade, balusters, handrail","banquette","banyan, banian","baptismal_font, baptistry, baptistery, font","bar","bar","barbecue, barbeque","barbed_wire, barbwire","barbell","barber_chair","barbershop","barbette_carriage","barbican, barbacan","bar_bit","bareboat","barge, flatboat, hoy, lighter","barge_pole","baritone, baritone_horn","bark, barque","bar_magnet","bar_mask","barn","barndoor","barn_door","barnyard","barograph","barometer","barong","barouche","bar_printer","barrack","barrage_balloon","barrel, cask","barrel, gun_barrel","barrelhouse, honky-tonk","barrel_knot, blood_knot","barrel_organ, grind_organ, hand_organ, hurdy_gurdy, hurdy-gurdy, street_organ","barrel_vault","barrette","barricade","barrier","barroom, bar, saloon, ginmill, taproom","barrow, garden_cart, lawn_cart, wheelbarrow","bascule","base, pedestal, stand","base, bag","baseball","baseball_bat, lumber","baseball_cap, jockey_cap, golf_cap","baseball_equipment","baseball_glove, glove, baseball_mitt, mitt","basement, cellar","basement","basic_point_defense_missile_system","basilica, roman_basilica","basilica","basilisk","basin","basinet","basket, handbasket","basket, basketball_hoop, hoop","basketball","basketball_court","basketball_equipment","basket_weave","bass","bass_clarinet","bass_drum, gran_casa","basset_horn","bass_fiddle, bass_viol, bull_fiddle, double_bass, contrabass, string_bass","bass_guitar","bass_horn, sousaphone, tuba","bassinet","bassinet","bassoon","baster","bastinado","bastion","bastion, citadel","bat","bath","bath_chair","bathhouse, bagnio","bathhouse, bathing_machine","bathing_cap, swimming_cap","bath_oil","bathrobe","bathroom, bath","bath_salts","bath_towel","bathtub, bathing_tub, bath, tub","bathyscaphe, bathyscaph, bathyscape","bathysphere","batik","batiste","baton, wand","baton","baton","baton","battering_ram","batter's_box","battery, electric_battery","battery, stamp_battery","batting_cage, cage","batting_glove","batting_helmet","battle-ax, battle-axe","battle_cruiser","battle_dress","battlement, crenelation, crenellation","battleship, battlewagon","battle_sight, battlesight","bay","bay","bayonet","bay_rum","bay_window, bow_window","bazaar, bazar","bazaar, bazar","bazooka","b_battery","bb_gun","beach_house","beach_towel","beach_wagon, station_wagon, wagon, estate_car, beach_waggon, station_waggon, waggon","beachwear","beacon, lighthouse, beacon_light, pharos","beading_plane","beaker","beaker","beam","beam_balance","beanbag","beanie, beany","bearing","bearing_rein, checkrein","bearing_wall","bearskin, busby, shako","beater","beating-reed_instrument, reed_instrument, reed","beaver, castor","beaver","beckman_thermometer","bed","bed","bed_and_breakfast, bed-and-breakfast","bedclothes, bed_clothing, bedding","bedford_cord","bed_jacket","bedpan","bedpost","bedroll","bedroom, sleeping_room, sleeping_accommodation, chamber, bedchamber","bedroom_furniture","bedsitting_room, bedsitter, bedsit","bedspread, bedcover, bed_cover, bed_covering, counterpane, spread","bedspring","bedstead, bedframe","beefcake","beehive, hive","beeper, pager","beer_barrel, beer_keg","beer_bottle","beer_can","beer_garden","beer_glass","beer_hall","beer_mat","beer_mug, stein","belaying_pin","belfry","bell","bell_arch","bellarmine, longbeard, long-beard, greybeard","bellbottom_trousers, bell-bottoms, bellbottom_pants","bell_cote, bell_cot","bell_foundry","bell_gable","bell_jar, bell_glass","bellows","bellpull","bell_push","bell_seat, balloon_seat","bell_tent","bell_tower","bellyband","belt","belt, belt_ammunition, belted_ammunition","belt_buckle","belting","bench","bench_clamp","bench_hook","bench_lathe","bench_press","bender","beret","berlin","bermuda_shorts, jamaica_shorts","berth, bunk, built_in_bed","besom","bessemer_converter","bethel","betting_shop","bevatron","bevel, bevel_square","bevel_gear, pinion_and_crown_wheel, pinion_and_ring_gear","b-flat_clarinet, licorice_stick","bib","bib-and-tucker","bicorn, bicorne","bicycle, bike, wheel, cycle","bicycle-built-for-two, tandem_bicycle, tandem","bicycle_chain","bicycle_clip, trouser_clip","bicycle_pump","bicycle_rack","bicycle_seat, saddle","bicycle_wheel","bidet","bier","bier","bi-fold_door","bifocals","big_blue, blu-82","big_board","bight","bikini, two-piece","bikini_pants","bilge","bilge_keel","bilge_pump","bilge_well","bill, peak, eyeshade, visor, vizor","bill, billhook","billboard, hoarding","billiard_ball","billiard_room, billiard_saloon, billiard_parlor, billiard_parlour, billiard_hall","bin","binder, ligature","binder, ring-binder","bindery","binding, book_binding, cover, back","bin_liner","binnacle","binoculars, field_glasses, opera_glasses","binocular_microscope","biochip","biohazard_suit","bioscope","biplane","birch, birch_rod","birchbark_canoe, birchbark, birch_bark","birdbath","birdcage","birdcall","bird_feeder, birdfeeder, feeder","birdhouse","bird_shot, buckshot, duck_shot","biretta, berretta, birretta","bishop","bistro","bit","bit","bite_plate, biteplate","bitewing","bitumastic","black","black","blackboard, chalkboard","blackboard_eraser","black_box","blackface","blackjack, cosh, sap","black_tie","blackwash","bladder","blade","blade, vane","blade","blank, dummy, blank_shell","blanket, cover","blast_furnace","blasting_cap","blazer, sport_jacket, sport_coat, sports_jacket, sports_coat","blender, liquidizer, liquidiser","blimp, sausage_balloon, sausage","blind, screen","blind_curve, blind_bend","blindfold","bling, bling_bling","blinker, flasher","blister_pack, bubble_pack","block","blockade","blockade-runner","block_and_tackle","blockbuster","blockhouse","block_plane","bloodmobile","bloomers, pants, drawers, knickers","blouse","blower","blowtorch, torch, blowlamp","blucher","bludgeon","blue","blue_chip","blunderbuss","blunt_file","boarding","boarding_house, boardinghouse","boardroom, council_chamber","boards","boat","boater, leghorn, panama, panama_hat, sailor, skimmer, straw_hat","boat_hook","boathouse","boatswain's_chair, bosun's_chair","boat_train","boatyard","bobbin, spool, reel","bobby_pin, hairgrip, grip","bobsled, bobsleigh, bob","bobsled, bobsleigh","bocce_ball, bocci_ball, boccie_ball","bodega","bodice","bodkin, threader","bodkin","bodkin","body","body_armor, body_armour, suit_of_armor, suit_of_armour, coat_of_mail, cataphract","body_lotion","body_stocking","body_plethysmograph","body_pad","bodywork","bofors_gun","bogy, bogie, bogey","boiler, steam_boiler","boiling_water_reactor, bwr","bolero","bollard, bitt","bolo, bolo_knife","bolo_tie, bolo, bola_tie, bola","bolt","bolt, deadbolt","bolt","bolt_cutter","bomb","bombazine","bomb_calorimeter, bomb","bomber","bomber_jacket","bomblet, cluster_bomblet","bomb_rack","bombshell","bomb_shelter, air-raid_shelter, bombproof","bone-ash_cup, cupel, refractory_pot","bone_china","bones, castanets, clappers, finger_cymbals","boneshaker","bongo, bongo_drum","bonnet, poke_bonnet","book","book_bag","bookbindery","bookcase","bookend","bookmark, bookmarker","bookmobile","bookshelf","bookshop, bookstore, bookstall","boom","boom, microphone_boom","boomerang, throwing_stick, throw_stick","booster, booster_rocket, booster_unit, takeoff_booster, takeoff_rocket","booster, booster_amplifier, booster_station, relay_link, relay_station, relay_transmitter","boot","boot","boot_camp","bootee, bootie","booth, cubicle, stall, kiosk","booth","booth","boothose","bootjack","bootlace","bootleg","bootstrap","bore_bit, borer, rock_drill, stone_drill","boron_chamber","borstal","bosom","boston_rocker","bota","bottle","bottle, feeding_bottle, nursing_bottle","bottle_bank","bottlebrush","bottlecap","bottle_opener","bottling_plant","bottom, freighter, merchantman, merchant_ship","boucle","boudoir","boulle, boule, buhl","bouncing_betty","bouquet, corsage, posy, nosegay","boutique, dress_shop","boutonniere","bow","bow","bow, bowknot","bow_and_arrow","bowed_stringed_instrument, string","bowie_knife","bowl","bowl","bowl","bowler_hat, bowler, derby_hat, derby, plug_hat","bowline, bowline_knot","bowling_alley","bowling_ball, bowl","bowling_equipment","bowling_pin, pin","bowling_shoe","bowsprit","bowstring","bow_tie, bow-tie, bowtie","box","box, loge","box, box_seat","box_beam, box_girder","box_camera, box_kodak","boxcar","box_coat","boxing_equipment","boxing_glove, glove","box_office, ticket_office, ticket_booth","box_spring","box_wrench, box_end_wrench","brace, bracing","brace, braces, orthodontic_braces","brace","brace, suspender, gallus","brace_and_bit","bracelet, bangle","bracer, armguard","brace_wrench","bracket, wall_bracket","bradawl, pricker","brake","brake","brake_band","brake_cylinder, hydraulic_brake_cylinder, master_cylinder","brake_disk","brake_drum, drum","brake_lining","brake_pad","brake_pedal","brake_shoe, shoe, skid","brake_system, brakes","brass, brass_instrument","brass, memorial_tablet, plaque","brass","brassard","brasserie","brassie","brassiere, bra, bandeau","brass_knucks, knucks, brass_knuckles, knuckles, knuckle_duster","brattice","brazier, brasier","breadbasket","bread-bin, breadbox","bread_knife","breakable","breakfast_area, breakfast_nook","breakfast_table","breakwater, groin, groyne, mole, bulwark, seawall, jetty","breast_drill","breast_implant","breastplate, aegis, egis","breast_pocket","breathalyzer, breathalyser","breechblock, breech_closer","breechcloth, breechclout, loincloth","breeches, knee_breeches, knee_pants, knickerbockers, knickers","breeches_buoy","breechloader","breeder_reactor","bren, bren_gun","brewpub","brick","brickkiln","bricklayer's_hammer","brick_trowel, mason's_trowel","brickwork","bridal_gown, wedding_gown, wedding_dress","bridge, span","bridge, nosepiece","bridle","bridle_path, bridle_road","bridoon","briefcase","briefcase_bomb","briefcase_computer","briefs, jockey_shorts","brig","brig","brigandine","brigantine, hermaphrodite_brig","brilliantine","brilliant_pebble","brim","bristle_brush","britches","broad_arrow","broadax, broadaxe","brochette","broadcaster, spreader","broadcloth","broadcloth","broad_hatchet","broadloom","broadside","broadsword","brocade","brogan, brogue, clodhopper, work_shoe","broiler","broken_arch","bronchoscope","broom","broom_closet","broomstick, broom_handle","brougham","browning_automatic_rifle, bar","browning_machine_gun, peacemaker","brownstone","brunch_coat","brush","brussels_carpet","brussels_lace","bubble","bubble_chamber","bubble_jet_printer, bubble-jet_printer, bubblejet","buckboard","bucket, pail","bucket_seat","bucket_shop","buckle","buckram","bucksaw","buckskins","buff, buffer","buffer, polisher","buffer, buffer_storage, buffer_store","buffet, counter, sideboard","buffing_wheel","buggy, roadster","bugle","building, edifice","building_complex, complex","bulldog_clip, alligator_clip","bulldog_wrench","bulldozer, dozer","bullet, slug","bulletproof_vest","bullet_train, bullet","bullhorn, loud_hailer, loud-hailer","bullion","bullnose, bullnosed_plane","bullpen, detention_cell, detention_centre","bullpen","bullring","bulwark","bumboat","bumper","bumper","bumper_car, dodgem","bumper_guard","bumper_jack","bundle, sheaf","bung, spile","bungalow, cottage","bungee, bungee_cord","bunghole","bunk","bunk, feed_bunk","bunk_bed, bunk","bunker, sand_trap, trap","bunker, dugout","bunker","bunsen_burner, bunsen, etna","bunting","bur, burr","burberry","burette, buret","burglar_alarm","burial_chamber, sepulcher, sepulchre, sepulture","burial_garment","burial_mound, grave_mound, barrow, tumulus","burin","burqa, burka","burlap, gunny","burn_bag","burner","burnous, burnoose, burnouse","burp_gun, machine_pistol","burr","bus, autobus, coach, charabanc, double-decker, jitney, motorbus, motorcoach, omnibus, passenger_vehicle","bushel_basket","bushing, cylindrical_lining","bush_jacket","business_suit","buskin, combat_boot, desert_boot, half_boot, top_boot","bustier","bustle","butcher_knife","butcher_shop, meat_market","butter_dish","butterfly_valve","butter_knife","butt_hinge","butt_joint, butt","button","buttonhook","buttress, buttressing","butt_shaft","butt_weld, butt-weld","buzz_bomb, robot_bomb, flying_bomb, doodlebug, v-1","buzzer","bvd, bvd's","bypass_condenser, bypass_capacitor","byway, bypath, byroad","cab, hack, taxi, taxicab","cab, cabriolet","cab","cabana","cabaret, nightclub, night_club, club, nightspot","caber","cabin","cabin","cabin_car, caboose","cabin_class, second_class, economy_class","cabin_cruiser, cruiser, pleasure_boat, pleasure_craft","cabinet","cabinet, console","cabinet, locker, storage_locker","cabinetwork","cabin_liner","cable, cable_television, cable_system, cable_television_service","cable, line, transmission_line","cable_car, car","cache, memory_cache","caddy, tea_caddy","caesium_clock","cafe, coffeehouse, coffee_shop, coffee_bar","cafeteria","cafeteria_tray","caff","caftan, kaftan","caftan, kaftan","cage, coop","cage","cagoule","caisson","calash, caleche, calash_top","calceus","calcimine","calculator, calculating_machine","caldron, cauldron","calico","caliper, calliper","call-board","call_center, call_centre","caller_id","calliope, steam_organ","calorimeter","calpac, calpack, kalpac","camail, aventail, ventail","camber_arch","cambric","camcorder","camel's_hair, camelhair","camera, photographic_camera","camera_lens, optical_lens","camera_lucida","camera_obscura","camera_tripod","camise","camisole","camisole, underbodice","camlet","camouflage","camouflage, camo","camp, encampment, cantonment, bivouac","camp","camp, refugee_camp","campaign_hat","campanile, belfry","camp_chair","camper, camping_bus, motor_home","camper_trailer","campstool","camshaft","can, tin, tin_can","canal","canal_boat, narrow_boat, narrowboat","candelabrum, candelabra","candid_camera","candle, taper, wax_light","candlepin","candlesnuffer","candlestick, candle_holder","candlewick","candy_thermometer","cane","cane","cangue","canister, cannister, tin","cannery","cannikin","cannikin","cannon","cannon","cannon","cannon","cannonball, cannon_ball, round_shot","canoe","can_opener, tin_opener","canopic_jar, canopic_vase","canopy","canopy","canopy","canteen","canteen","canteen","canteen, mobile_canteen","canteen","cant_hook","cantilever","cantilever_bridge","cantle","canton_crepe","canvas, canvass","canvas, canvass","canvas_tent, canvas, canvass","cap","cap","cap","capacitor, capacitance, condenser, electrical_condenser","caparison, trapping, housing","cape, mantle","capital_ship","capitol","cap_opener","capote, hooded_cloak","capote, hooded_coat","cap_screw","capstan","capstone, copestone, coping_stone, stretcher","capsule","captain's_chair","car, auto, automobile, machine, motorcar","car, railcar, railway_car, railroad_car","car, elevator_car","carabiner, karabiner, snap_ring","carafe, decanter","caravansary, caravanserai, khan, caravan_inn","car_battery, automobile_battery","carbine","car_bomb","carbon_arc_lamp, carbon_arc","carboy","carburetor, carburettor","car_carrier","cardcase","cardiac_monitor, heart_monitor","cardigan","card_index, card_catalog, card_catalogue","cardiograph, electrocardiograph","cardioid_microphone","car_door","cardroom","card_table","card_table","car-ferry","cargo_area, cargo_deck, cargo_hold, hold, storage_area","cargo_container","cargo_door","cargo_hatch","cargo_helicopter","cargo_liner","cargo_ship, cargo_vessel","carillon","car_mirror","caroche","carousel, carrousel, merry-go-round, roundabout, whirligig","carpenter's_hammer, claw_hammer, clawhammer","carpenter's_kit, tool_kit","carpenter's_level","carpenter's_mallet","carpenter's_rule","carpenter's_square","carpetbag","carpet_beater, rug_beater","carpet_loom","carpet_pad, rug_pad, underlay, underlayment","carpet_sweeper, sweeper","carpet_tack","carport, car_port","carrack, carack","carrel, carrell, cubicle, stall","carriage, equipage, rig","carriage","carriage_bolt","carriageway","carriage_wrench","carrick_bend","carrier","carryall, holdall, tote, tote_bag","carrycot","car_seat","cart","car_tire, automobile_tire, auto_tire, rubber_tire","carton","cartouche, cartouch","car_train","cartridge","cartridge, pickup","cartridge_belt","cartridge_extractor, cartridge_remover, extractor","cartridge_fuse","cartridge_holder, cartridge_clip, clip, magazine","cartwheel","carving_fork","carving_knife","car_wheel","caryatid","cascade_liquefier","cascade_transformer","case","case, display_case, showcase, vitrine","case, compositor's_case, typesetter's_case","casein_paint, casein","case_knife, sheath_knife","case_knife","casement","casement_window","casern","case_shot, canister, canister_shot","cash_bar","cashbox, money_box, till","cash_machine, cash_dispenser, automated_teller_machine, automatic_teller_machine, automated_teller, automatic_teller, atm","cashmere","cash_register, register","casing, case","casino, gambling_casino","casket, jewel_casket","casque","casquet, casquetel","cassegrainian_telescope, gregorian_telescope","casserole","cassette","cassette_deck","cassette_player","cassette_recorder","cassette_tape","cassock","cast, plaster_cast, plaster_bandage","caster, castor","caster, castor","castle","castle, rook","catacomb","catafalque","catalytic_converter","catalytic_cracker, cat_cracker","catamaran","catapult, arbalest, arbalist, ballista, bricole, mangonel, onager, trebuchet, trebucket","catapult, launcher","catboat","cat_box","catch","catchall","catcher's_mask","catchment","caterpillar, cat","cathedra, bishop's_throne","cathedral","cathedral, duomo","catheter","cathode","cathode-ray_tube, crt","cat-o'-nine-tails, cat","cat's-paw","catsup_bottle, ketchup_bottle","cattle_car","cattle_guard, cattle_grid","cattleship, cattle_boat","cautery, cauterant","cavalier_hat, slouch_hat","cavalry_sword, saber, sabre","cavetto","cavity_wall","c_battery","c-clamp","cd_drive","cd_player","cd-r, compact_disc_recordable, cd-wo, compact_disc_write-once","cd-rom, compact_disc_read-only_memory","cd-rom_drive","cedar_chest","ceiling","celesta","cell, electric_cell","cell, jail_cell, prison_cell","cellar, wine_cellar","cellblock, ward","cello, violoncello","cellophane","cellular_telephone, cellular_phone, cellphone, cell, mobile_phone","cellulose_tape, scotch_tape, sellotape","cenotaph, empty_tomb","censer, thurible","center, centre","center_punch","centigrade_thermometer","central_processing_unit, cpu, c.p.u., central_processor, processor, mainframe","centrifugal_pump","centrifuge, extractor, separator","ceramic","ceramic_ware","cereal_bowl","cereal_box","cerecloth","cesspool, cesspit, sink, sump","chachka, tsatske, tshatshke, tchotchke","chador, chadar, chaddar, chuddar","chafing_dish","chain","chain","chainlink_fence","chain_mail, ring_mail, mail, chain_armor, chain_armour, ring_armor, ring_armour","chain_printer","chain_saw, chainsaw","chain_store","chain_tongs","chain_wrench","chair","chair","chair_of_state","chairlift, chair_lift","chaise, shay","chaise_longue, chaise, daybed","chalet","chalice, goblet","chalk","challis","chamberpot, potty, thunder_mug","chambray","chamfer_bit","chamfer_plane","chamois_cloth","chancel, sanctuary, bema","chancellery","chancery","chandelier, pendant, pendent","chandlery","chanfron, chamfron, testiere, frontstall, front-stall","chanter, melody_pipe","chantry","chap","chapel","chapterhouse, fraternity_house, frat_house","chapterhouse","character_printer, character-at-a-time_printer, serial_printer","charcuterie","charge-exchange_accelerator","charger, battery_charger","chariot","chariot","charnel_house, charnel","chassis","chassis","chasuble","chateau","chatelaine","checker, chequer","checkout, checkout_counter","cheekpiece","cheeseboard, cheese_tray","cheesecloth","cheese_cutter","cheese_press","chemical_bomb, gas_bomb","chemical_plant","chemical_reactor","chemise, sack, shift","chemise, shimmy, shift, slip, teddy","chenille","chessman, chess_piece","chest","chesterfield","chest_of_drawers, chest, bureau, dresser","chest_protector","cheval-de-frise, chevaux-de-frise","cheval_glass","chicane","chicken_coop, coop, hencoop, henhouse","chicken_wire","chicken_yard, hen_yard, chicken_run, fowl_run","chiffon","chiffonier, commode","child's_room","chime, bell, gong","chimney_breast","chimney_corner, inglenook","china","china_cabinet, china_closet","chinchilla","chinese_lantern","chinese_puzzle","chinning_bar","chino","chino","chin_rest","chin_strap","chintz","chip, microchip, micro_chip, silicon_chip, microprocessor_chip","chip, poker_chip","chisel","chlamys","choir","choir_loft","choke","choke, choke_coil, choking_coil","chokey, choky","choo-choo","chopine, platform","chordophone","christmas_stocking","chronograph","chronometer","chronoscope","chuck","chuck_wagon","chukka, chukka_boot","church, church_building","church_bell","church_hat","church_key","church_tower","churidars","churn, butter_churn","ciderpress","cigar_band","cigar_box","cigar_cutter","cigarette_butt","cigarette_case","cigarette_holder","cigar_lighter, cigarette_lighter, pocket_lighter","cinch, girth","cinema, movie_theater, movie_theatre, movie_house, picture_palace","cinquefoil","circle, round","circlet","circuit, electrical_circuit, electric_circuit","circuit_board, circuit_card, board, card, plug-in, add-in","circuit_breaker, breaker","circuitry","circular_plane, compass_plane","circular_saw, buzz_saw","circus_tent, big_top, round_top, top","cistern","cistern, water_tank","cittern, cithern, cither, citole, gittern","city_hall","cityscape","city_university","civies, civvies","civilian_clothing, civilian_dress, civilian_garb, plain_clothes","clack_valve, clack, clapper_valve","clamp, clinch","clamshell, grapple","clapper, tongue","clapperboard","clarence","clarinet","clark_cell, clark_standard_cell","clasp","clasp_knife, jackknife","classroom, schoolroom","clavichord","clavier, klavier","clay_pigeon","claymore_mine, claymore","claymore","cleaners, dry_cleaners","cleaning_implement, cleaning_device, cleaning_equipment","cleaning_pad","clean_room, white_room","clearway","cleat","cleat","cleats","cleaver, meat_cleaver, chopper","clerestory, clearstory","clevis","clews","cliff_dwelling","climbing_frame","clinch","clinch, clench","clincher","clinic","clinical_thermometer, mercury-in-glass_clinical_thermometer","clinker, clinker_brick","clinometer, inclinometer","clip","clip_lead","clip-on","clipper","clipper","clipper, clipper_ship","cloak","cloak","cloakroom, coatroom","cloche","cloche","clock","clock_pendulum","clock_radio","clock_tower","clockwork","clog, geta, patten, sabot","cloisonne","cloister","closed_circuit, loop","closed-circuit_television","closed_loop, closed-loop_system","closet","closeup_lens","cloth_cap, flat_cap","cloth_covering","clothesbrush","clothes_closet, clothespress","clothes_dryer, clothes_drier","clothes_hamper, laundry_basket, clothes_basket, voider","clotheshorse","clothespin, clothes_pin, clothes_peg","clothes_tree, coat_tree, coat_stand","clothing, article_of_clothing, vesture, wear, wearable, habiliment","clothing_store, haberdashery, haberdashery_store, mens_store","clout_nail, clout","clove_hitch","club_car, lounge_car","clubroom","cluster_bomb","clutch","clutch, clutch_pedal","clutch_bag, clutch","coach, four-in-hand, coach-and-four","coach_house, carriage_house, remise","coal_car","coal_chute","coal_house","coal_shovel","coaming","coaster_brake","coat","coat_button","coat_closet","coatdress","coatee","coat_hanger, clothes_hanger, dress_hanger","coating, coat","coating","coat_of_paint","coatrack, coat_rack, hatrack","coattail","coaxial_cable, coax, coax_cable","cobweb","cobweb","cockcroft_and_walton_accelerator, cockcroft-walton_accelerator, cockcroft_and_walton_voltage_multiplier, cockcroft-walton_voltage_multiplier","cocked_hat","cockhorse","cockleshell","cockpit","cockpit","cockpit","cockscomb, coxcomb","cocktail_dress, sheath","cocktail_lounge","cocktail_shaker","cocotte","codpiece","coelostat","coffee_can","coffee_cup","coffee_filter","coffee_maker","coffee_mill, coffee_grinder","coffee_mug","coffeepot","coffee_stall","coffee_table, cocktail_table","coffee_urn","coffer","coffey_still","coffin, casket","cog, sprocket","coif","coil, spiral, volute, whorl, helix","coil","coil","coil_spring, volute_spring","coin_box","colander, cullender","cold_cathode","cold_chisel, set_chisel","cold_cream, coldcream, face_cream, vanishing_cream","cold_frame","collar, neckband","collar","college","collet, collet_chuck","collider","colliery, pit","collimator","collimator","cologne, cologne_water, eau_de_cologne","colonnade","colonoscope","colorimeter, tintometer","colors, colours","color_television, colour_television, color_television_system, colour_television_system, color_tv, colour_tv","color_tube, colour_tube, color_television_tube, colour_television_tube, color_tv_tube, colour_tv_tube","color_wash, colour_wash","colt","colter, coulter","columbarium","columbarium, cinerarium","column, pillar","column, pillar","comb","comb","comber","combination_lock","combination_plane","combine","comforter, pacifier, baby's_dummy, teething_ring","command_module","commissary","commissary","commodity, trade_good, good","common_ax, common_axe, dayton_ax, dayton_axe","common_room","communications_satellite","communication_system","community_center, civic_center","commutator","commuter, commuter_train","compact, powder_compact","compact, compact_car","compact_disk, compact_disc, cd","compact-disk_burner, cd_burner","companionway","compartment","compartment","compass","compass","compass_card, mariner's_compass","compass_saw","compound","compound_lens","compound_lever","compound_microscope","compress","compression_bandage, tourniquet","compressor","computer, computing_machine, computing_device, data_processor, electronic_computer, information_processing_system","computer_circuit","computerized_axial_tomography_scanner, cat_scanner","computer_keyboard, keypad","computer_monitor","computer_network","computer_screen, computer_display","computer_store","computer_system, computing_system, automatic_data_processing_system, adp_system, adps","concentration_camp, stockade","concert_grand, concert_piano","concert_hall","concertina","concertina","concrete_mixer, cement_mixer","condensation_pump, diffusion_pump","condenser, optical_condenser","condenser","condenser","condenser_microphone, capacitor_microphone","condominium","condominium, condo","conductor","cone_clutch, cone_friction_clutch","confectionery, confectionary, candy_store","conference_center, conference_house","conference_room","conference_table, council_table, council_board","confessional","conformal_projection, orthomorphic_projection","congress_boot, congress_shoe, congress_gaiter","conic_projection, conical_projection","connecting_rod","connecting_room","connection, connexion, connector, connecter, connective","conning_tower","conning_tower","conservatory, hothouse, indoor_garden","conservatory, conservatoire","console","console","console_table, console","consulate","contact, tangency","contact, contact_lens","container","container_ship, containership, container_vessel","containment","contrabassoon, contrafagotto, double_bassoon","control, controller","control_center","control_circuit, negative_feedback_circuit","control_key, command_key","control_panel, instrument_panel, control_board, board, panel","control_rod","control_room","control_system","control_tower","convector","convenience_store","convent","conventicle, meetinghouse","converging_lens, convex_lens","converter, convertor","convertible","convertible, sofa_bed","conveyance, transport","conveyer_belt, conveyor_belt, conveyer, conveyor, transporter","cooker","cookfire","cookhouse","cookie_cutter","cookie_jar, cooky_jar","cookie_sheet, baking_tray","cooking_utensil, cookware","cookstove","coolant_system","cooler, ice_chest","cooling_system, cooling","cooling_system, engine_cooling_system","cooling_tower","coonskin_cap, coonskin","cope","coping_saw","copperware","copyholder","coquille","coracle","corbel, truss","corbel_arch","corbel_step, corbie-step, corbiestep, crow_step","corbie_gable","cord, corduroy","cord, electric_cord","cordage","cords, corduroys","core","core_bit","core_drill","corer","cork, bottle_cork","corker","corkscrew, bottle_screw","corncrib","corner, quoin","corner, nook","corner_post","cornet, horn, trumpet, trump","cornice","cornice","cornice, valance, valance_board, pelmet","correctional_institution","corrugated_fastener, wiggle_nail","corselet, corslet","corset, girdle, stays","cosmetic","cosmotron","costume","costume","costume","costume","cosy, tea_cosy, cozy, tea_cozy","cot, camp_bed","cottage_tent","cotter, cottar","cotter_pin","cotton","cotton_flannel, canton_flannel","cotton_mill","couch","couch","couchette","coude_telescope, coude_system","counter","counter, tabulator","counter","counterbore, countersink, countersink_bit","counter_tube","country_house","country_store, general_store, trading_post","coupe","coupling, coupler","court, courtyard","court","court, courtroom","court","courtelle","courthouse","courthouse","coverall","covered_bridge","covered_couch","covered_wagon, conestoga_wagon, conestoga, prairie_wagon, prairie_schooner","covering","coverlet","cover_plate","cowbarn, cowshed, cow_barn, cowhouse, byre","cowbell","cowboy_boot","cowboy_hat, ten-gallon_hat","cowhide","cowl","cow_pen, cattle_pen, corral","cpu_board, mother_board","crackle, crackleware, crackle_china","cradle","craft","cramp, cramp_iron","crampon, crampoon, climbing_iron, climber","crampon, crampoon","crane","craniometer","crank, starter","crankcase","crankshaft","crash_barrier","crash_helmet","crate","cravat","crayon, wax_crayon","crazy_quilt","cream, ointment, emollient","cream_pitcher, creamer","creche, foundling_hospital","creche","credenza, credence","creel","crematory, crematorium, cremation_chamber","crematory, crematorium","crepe, crape","crepe_de_chine","crescent_wrench","cretonne","crib, cot","crib","cricket_ball","cricket_bat, bat","cricket_equipment","cringle, eyelet, loop, grommet, grummet","crinoline","crinoline","crochet_needle, crochet_hook","crock, earthenware_jar","crock_pot","crook, shepherd's_crook","crookes_radiometer","crookes_tube","croquet_ball","croquet_equipment","croquet_mallet","cross","crossbar","crossbar","crossbar","crossbench","cross_bit","crossbow","crosscut_saw, crosscut_handsaw, cutoff_saw","crossjack, mizzen_course","crosspiece","crotchet","croupier's_rake","crowbar, wrecking_bar, pry, pry_bar","crown, diadem","crown, crownwork, jacket, jacket_crown, cap","crown_jewels","crown_lens","crow's_nest","crucible, melting_pot","crucifix, rood, rood-tree","cruet, crewet","cruet-stand","cruise_control","cruise_missile","cruiser","cruiser, police_cruiser, patrol_car, police_car, prowl_car, squad_car","cruise_ship, cruise_liner","crupper","cruse","crusher","crutch","cryometer","cryoscope","cryostat","crypt","crystal, watch_crystal, watch_glass","crystal_detector","crystal_microphone","crystal_oscillator, quartz_oscillator","crystal_set","cubitiere","cucking_stool, ducking_stool","cuckoo_clock","cuddy","cudgel","cue, cue_stick, pool_cue, pool_stick","cue_ball","cuff, turnup","cuirass","cuisse","cul, cul_de_sac, dead_end","culdoscope","cullis","culotte","cultivator, tiller","culverin","culverin","culvert","cup","cupboard, closet","cup_hook","cupola","cupola","curb, curb_bit","curb_roof","curbstone, kerbstone","curette, curet","curler, hair_curler, roller, crimper","curling_iron","currycomb","cursor, pointer","curtain, drape, drapery, mantle, pall","customhouse, customshouse","cutaway, cutaway_drawing, cutaway_model","cutlas, cutlass","cutoff","cutout","cutter, cutlery, cutting_tool","cutter","cutting_implement","cutting_room","cutty_stool","cutwork","cybercafe","cyclopean_masonry","cyclostyle","cyclotron","cylinder","cylinder, piston_chamber","cylinder_lock","cymbal","dacha","dacron, terylene","dado","dado_plane","dagger, sticker","dairy, dairy_farm","dais, podium, pulpit, rostrum, ambo, stump, soapbox","daisy_print_wheel, daisy_wheel","daisywheel_printer","dam, dike, dyke","damask","dampener, moistener","damper, muffler","damper_block, piano_damper","dark_lantern, bull's-eye","darkroom","darning_needle, embroidery_needle","dart","dart","dashboard, fascia","dashiki, daishiki","dash-pot","data_converter","data_input_device, input_device","data_multiplexer","data_system, information_system","davenport","davenport","davit","daybed, divan_bed","daybook, ledger","day_nursery, day_care_center","day_school","dead_axle","deadeye","deadhead","deanery","deathbed","death_camp","death_house, death_row","death_knell, death_bell","death_seat","deck","deck","deck_chair, beach_chair","deck-house","deckle","deckle_edge, deckle","declinometer, transit_declinometer","decoder","decolletage","decoupage","dedicated_file_server","deep-freeze, deepfreeze, deep_freezer, freezer","deerstalker","defense_system, defence_system","defensive_structure, defense, defence","defibrillator","defilade","deflector","delayed_action","delay_line","delft","delicatessen, deli, food_shop","delivery_truck, delivery_van, panel_truck","delta_wing","demijohn","demitasse","den","denim, dungaree, jean","densimeter, densitometer","densitometer","dental_appliance","dental_floss, floss","dental_implant","dentist's_drill, burr_drill","denture, dental_plate, plate","deodorant, deodourant","department_store, emporium","departure_lounge","depilatory, depilator, epilator","depressor","depth_finder","depth_gauge, depth_gage","derrick","derrick","derringer","desk","desk_phone","desktop_computer","dessert_spoon","destroyer, guided_missile_destroyer","destroyer_escort","detached_house, single_dwelling","detector, sensor, sensing_element","detector","detention_home, detention_house, house_of_detention, detention_camp","detonating_fuse","detonator, detonating_device, cap","developer","device","dewar_flask, dewar","dhoti","dhow","dial, telephone_dial","dial","dial","dialog_box, panel","dial_telephone, dial_phone","dialyzer, dialysis_machine","diamante","diaper, nappy, napkin","diaper","diaphone","diaphragm, stop","diaphragm","diathermy_machine","dibble, dibber","dice_cup, dice_box","dicer","dickey, dickie, dicky, shirtfront","dickey, dickie, dicky, dickey-seat, dickie-seat, dicky-seat","dictaphone","die","diesel, diesel_engine, diesel_motor","diesel-electric_locomotive, diesel-electric","diesel-hydraulic_locomotive, diesel-hydraulic","diesel_locomotive","diestock","differential_analyzer","differential_gear, differential","diffuser, diffusor","diffuser, diffusor","digester","diggings, digs, domiciliation, lodgings, pad","digital-analog_converter, digital-to-analog_converter","digital_audiotape, dat","digital_camera","digital_clock","digital_computer","digital_display, alphanumeric_display","digital_subscriber_line, dsl","digital_voltmeter","digital_watch","digitizer, digitiser, analog-digital_converter, analog-to-digital_converter","dilator, dilater","dildo","dimity","dimmer","diner","dinette","dinghy, dory, rowboat","dining_area","dining_car, diner, dining_compartment, buffet_car","dining-hall","dining_room, dining-room","dining-room_furniture","dining-room_table","dining_table, board","dinner_bell","dinner_dress, dinner_gown, formal, evening_gown","dinner_jacket, tux, tuxedo, black_tie","dinner_napkin","dinner_pail, dinner_bucket","dinner_table","dinner_theater, dinner_theatre","diode, semiconductor_diode, junction_rectifier, crystal_rectifier","diode, rectifying_tube, rectifying_valve","dip","diplomatic_building","dipole, dipole_antenna","dipper","dipstick","dip_switch, dual_inline_package_switch","directional_antenna","directional_microphone","direction_finder","dirk","dirndl","dirndl","dirty_bomb","discharge_lamp","discharge_pipe","disco, discotheque","discount_house, discount_store, discounter, wholesale_house","discus, saucer","disguise","dish","dish, dish_aerial, dish_antenna, saucer","dishpan","dish_rack","dishrag, dishcloth","dishtowel, dish_towel, tea_towel","dishwasher, dish_washer, dishwashing_machine","disk, disc","disk_brake, disc_brake","disk_clutch","disk_controller","disk_drive, disc_drive, hard_drive, winchester_drive","diskette, floppy, floppy_disk","disk_harrow, disc_harrow","dispatch_case, dispatch_box","dispensary","dispenser","display, video_display","display_adapter, display_adaptor","display_panel, display_board, board","display_window, shop_window, shopwindow, show_window","disposal, electric_pig, garbage_disposal","disrupting_explosive, bursting_explosive","distaff","distillery, still","distributor, distributer, electrical_distributor","distributor_cam","distributor_cap","distributor_housing","distributor_point, breaker_point, point","ditch","ditch_spade, long-handled_spade","ditty_bag","divan","divan, diwan","dive_bomber","diverging_lens, concave_lens","divided_highway, dual_carriageway","divider","diving_bell","divining_rod, dowser, dowsing_rod, waterfinder, water_finder","diving_suit, diving_dress","dixie","dixie_cup, paper_cup","dock, dockage, docking_facility","doeskin","dogcart","doggie_bag, doggy_bag","dogsled, dog_sled, dog_sleigh","dog_wrench","doily, doyley, doyly","doll, dolly","dollhouse, doll's_house","dolly","dolman","dolman, dolman_jacket","dolman_sleeve","dolmen, cromlech, portal_tomb","dome","dome, domed_stadium, covered_stadium","domino, half_mask, eye_mask","dongle","donkey_jacket","door","door","door","doorbell, bell, buzzer","doorframe, doorcase","doorjamb, doorpost","doorlock","doormat, welcome_mat","doornail","doorplate","doorsill, doorstep, threshold","doorstop, doorstopper","doppler_radar","dormer, dormer_window","dormer_window","dormitory, dorm, residence_hall, hall, student_residence","dormitory, dormitory_room, dorm_room","dosemeter, dosimeter","dossal, dossel","dot_matrix_printer, matrix_printer, dot_printer","double_bed","double-bitted_ax, double-bitted_axe, western_ax, western_axe","double_boiler, double_saucepan","double-breasted_jacket","double-breasted_suit","double_door","double_glazing","double-hung_window","double_knit","doubler","double_reed","double-reed_instrument, double_reed","doublet","doubletree","douche, douche_bag","dovecote, columbarium, columbary","dover's_powder","dovetail, dovetail_joint","dovetail_plane","dowel, dowel_pin, joggle","downstage","drafting_instrument","drafting_table, drawing_table","dragunov","drainage_ditch","drainage_system","drain_basket","drainplug","drape","drapery","drawbar","drawbridge, lift_bridge","drawer","drawers, underdrawers, shorts, boxers, boxershorts","drawing_chalk","drawing_room, withdrawing_room","drawing_room","drawknife, drawshave","drawstring_bag","dray, camion","dreadnought, dreadnaught","dredge","dredger","dredging_bucket","dress, frock","dress_blues, dress_whites","dresser","dress_hat, high_hat, opera_hat, silk_hat, stovepipe, top_hat, topper, beaver","dressing, medical_dressing","dressing_case","dressing_gown, robe-de-chambre, lounging_robe","dressing_room","dressing_sack, dressing_sacque","dressing_table, dresser, vanity, toilet_table","dress_rack","dress_shirt, evening_shirt","dress_suit, full_dress, tailcoat, tail_coat, tails, white_tie, white_tie_and_tails","dress_uniform","drift_net","drill","electric_drill","drilling_platform, offshore_rig","drill_press","drill_rig, drilling_rig, oilrig, oil_rig","drinking_fountain, water_fountain, bubbler","drinking_vessel","drip_loop","drip_mat","drip_pan","dripping_pan, drip_pan","drip_pot","drive","drive","drive_line, drive_line_system","driver, number_one_wood","driveshaft","driveway, drive, private_road","driving_iron, one_iron","driving_wheel","drogue, drogue_chute, drogue_parachute","drogue_parachute","drone, drone_pipe, bourdon","drone, pilotless_aircraft, radio-controlled_aircraft","drop_arch","drop_cloth","drop_curtain, drop_cloth, drop","drop_forge, drop_hammer, drop_press","drop-leaf_table","dropper, eye_dropper","droshky, drosky","drove, drove_chisel","drugget","drugstore, apothecary's_shop, chemist's, chemist's_shop, pharmacy","drum, membranophone, tympan","drum, metal_drum","drum_brake","drumhead, head","drum_printer","drum_sander, electric_sander, sander, smoother","drumstick","dry_battery","dry-bulb_thermometer","dry_cell","dry_dock, drydock, graving_dock","dryer, drier","dry_fly","dry_kiln","dry_masonry","dry_point","dry_wall, dry-stone_wall","dual_scan_display","duck","duckboard","duckpin","dudeen","duffel, duffle","duffel_bag, duffle_bag, duffel, duffle","duffel_coat, duffle_coat","dugout","dugout_canoe, dugout, pirogue","dulciana","dulcimer","dulcimer","dumbbell","dumb_bomb, gravity_bomb","dumbwaiter, food_elevator","dumdum, dumdum_bullet","dumpcart","dumpster","dump_truck, dumper, tipper_truck, tipper_lorry, tip_truck, tipper","dumpy_level","dunce_cap, dunce's_cap, fool's_cap","dune_buggy, beach_buggy","dungeon","duplex_apartment, duplex","duplex_house, duplex, semidetached_house","duplicator, copier","dust_bag, vacuum_bag","dustcloth, dustrag, duster","dust_cover","dust_cover, dust_sheet","dustmop, dust_mop, dry_mop","dustpan","dutch_oven","dutch_oven","dwelling, home, domicile, abode, habitation, dwelling_house","dye-works","dynamo","dynamometer, ergometer","eames_chair","earflap, earlap","early_warning_radar","early_warning_system","earmuff","earphone, earpiece, headphone, phone","earplug","earplug","earthenware","earthwork","easel","easy_chair, lounge_chair, overstuffed_chair","eaves","ecclesiastical_attire, ecclesiastical_robe","echinus","echocardiograph","edger","edge_tool","efficiency_apartment","egg-and-dart, egg-and-anchor, egg-and-tongue","eggbeater, eggwhisk","egg_timer","eiderdown, duvet, continental_quilt","eight_ball","ejection_seat, ejector_seat, capsule","elastic","elastic_bandage","elastoplast","elbow","elbow_pad","electric, electric_automobile, electric_car","electrical_cable","electrical_contact","electrical_converter","electrical_device","electrical_system","electric_bell","electric_blanket","electric_chair, chair, death_chair, hot_seat","electric_clock","electric-discharge_lamp, gas-discharge_lamp","electric_fan, blower","electric_frying_pan","electric_furnace","electric_guitar","electric_hammer","electric_heater, electric_fire","electric_lamp","electric_locomotive","electric_meter, power_meter","electric_mixer","electric_motor","electric_organ, electronic_organ, hammond_organ, organ","electric_range","electric_refrigerator, fridge","electric_toothbrush","electric_typewriter","electro-acoustic_transducer","electrode","electrodynamometer","electroencephalograph","electrograph","electrolytic, electrolytic_capacitor, electrolytic_condenser","electrolytic_cell","electromagnet","electrometer","electromyograph","electron_accelerator","electron_gun","electronic_balance","electronic_converter","electronic_device","electronic_equipment","electronic_fetal_monitor, electronic_foetal_monitor, fetal_monitor, foetal_monitor","electronic_instrument, electronic_musical_instrument","electronic_voltmeter","electron_microscope","electron_multiplier","electrophorus","electroscope","electrostatic_generator, electrostatic_machine, wimshurst_machine, van_de_graaff_generator","electrostatic_printer","elevator, lift","elevator","elevator_shaft","embankment","embassy","embellishment","emergency_room, er","emesis_basin","emitter","empty","emulsion, photographic_emulsion","enamel","enamel","enamelware","encaustic","encephalogram, pneumoencephalogram","enclosure","endoscope","energizer, energiser","engine","engine","engineering, engine_room","enginery","english_horn, cor_anglais","english_saddle, english_cavalry_saddle","enlarger","ensemble","ensign","entablature","entertainment_center","entrenching_tool, trenching_spade","entrenchment, intrenchment","envelope","envelope","envelope, gasbag","eolith","epauliere","epee","epergne","epicyclic_train, epicyclic_gear_train","epidiascope","epilating_wax","equalizer, equaliser","equatorial","equipment","erasable_programmable_read-only_memory, eprom","eraser","erecting_prism","erection","erlenmeyer_flask","escape_hatch","escapement","escape_wheel","escarpment, escarp, scarp, protective_embankment","escutcheon, scutcheon","esophagoscope, oesophagoscope","espadrille","espalier","espresso_maker","espresso_shop","establishment","estaminet","estradiol_patch","etagere","etamine, etamin","etching","ethernet","ethernet_cable","eton_jacket","etui","eudiometer","euphonium","evaporative_cooler","evening_bag","exercise_bike, exercycle","exercise_device","exhaust, exhaust_system","exhaust_fan","exhaust_valve","exhibition_hall, exhibition_area","exocet","expansion_bit, expansive_bit","expansion_bolt","explosive_detection_system, eds","explosive_device","explosive_trace_detection, etd","express, limited","extension, telephone_extension, extension_phone","extension_cord","external-combustion_engine","external_drive","extractor","eyebrow_pencil","eyecup, eyebath, eye_cup","eyeliner","eyepatch, patch","eyepiece, ocular","eyeshadow","fabric, cloth, material, textile","facade, frontage, frontal","face_guard","face_mask","faceplate","face_powder","face_veil","facing, cladding","facing","facing, veneer","facsimile, facsimile_machine, fax","factory, mill, manufacturing_plant, manufactory","factory_ship","fagot, faggot","fagot_stitch, faggot_stitch","fahrenheit_thermometer","faience","faille","fairlead","fairy_light","falchion","fallboard, fall-board","fallout_shelter","false_face","false_teeth","family_room","fan","fan_belt","fan_blade","fancy_dress, masquerade, masquerade_costume","fanion","fanlight","fanjet, fan-jet, fanjet_engine, turbojet, turbojet_engine, turbofan, turbofan_engine","fanjet, fan-jet, turbofan, turbojet","fanny_pack, butt_pack","fan_tracery","fan_vaulting","farm_building","farmer's_market, green_market, greenmarket","farmhouse","farm_machine","farmplace, farm-place, farmstead","farmyard","farthingale","fastener, fastening, holdfast, fixing","fast_reactor","fat_farm","fatigues","faucet, spigot","fauld","fauteuil","feather_boa, boa","featheredge","fedora, felt_hat, homburg, stetson, trilby","feedback_circuit, feedback_loop","feedlot","fell, felled_seam","felloe, felly","felt","felt-tip_pen, felt-tipped_pen, felt_tip, magic_marker","felucca","fence, fencing","fencing_mask, fencer's_mask","fencing_sword","fender, wing","fender, buffer, cowcatcher, pilot","ferris_wheel","ferrule, collet","ferry, ferryboat","ferule","festoon","fetoscope, foetoscope","fetter, hobble","fez, tarboosh","fiber, fibre, vulcanized_fiber","fiber_optic_cable, fibre_optic_cable","fiberscope","fichu","fiddlestick, violin_bow","field_artillery, field_gun","field_coil, field_winding","field-effect_transistor, fet","field-emission_microscope","field_glass, glass, spyglass","field_hockey_ball","field_hospital","field_house, sports_arena","field_lens","field_magnet","field-sequential_color_television, field-sequential_color_tv, field-sequential_color_television_system, field-sequential_color_tv_system","field_tent","fieldwork","fife","fifth_wheel, spare","fighter, fighter_aircraft, attack_aircraft","fighting_chair","fig_leaf","figure_eight, figure_of_eight","figure_loom, figured-fabric_loom","figure_skate","filament","filature","file","file, file_cabinet, filing_cabinet","file_folder","file_server","filigree, filagree, fillagree","filling","film, photographic_film","film, plastic_film","film_advance","filter","filter","finder, viewfinder, view_finder","finery","fine-tooth_comb, fine-toothed_comb","finger","fingerboard","finger_bowl","finger_paint, fingerpaint","finger-painting","finger_plate, escutcheon, scutcheon","fingerstall, cot","finish_coat, finishing_coat","finish_coat, finishing_coat","finisher","fin_keel","fipple","fipple_flute, fipple_pipe, recorder, vertical_flute","fire","fire_alarm, smoke_alarm","firearm, piece, small-arm","fire_bell","fireboat","firebox","firebrick","fire_control_radar","fire_control_system","fire_engine, fire_truck","fire_extinguisher, extinguisher, asphyxiator","fire_iron","fireman's_ax, fireman's_axe","fireplace, hearth, open_fireplace","fire_screen, fireguard","fire_tongs, coal_tongs","fire_tower","firewall","firing_chamber, gun_chamber","firing_pin","firkin","firmer_chisel","first-aid_kit","first-aid_station","first_base","first_class","fishbowl, fish_bowl, goldfish_bowl","fisherman's_bend","fisherman's_knot, true_lover's_knot, truelove_knot","fisherman's_lure, fish_lure","fishhook","fishing_boat, fishing_smack, fishing_vessel","fishing_gear, tackle, fishing_tackle, fishing_rig, rig","fishing_rod, fishing_pole","fish_joint","fish_knife","fishnet, fishing_net","fish_slice","fitment","fixative","fixer-upper","flag","flageolet, treble_recorder, shepherd's_pipe","flagon","flagpole, flagstaff","flagship","flail","flambeau","flamethrower","flange, rim","flannel","flannel, gabardine, tweed, white","flannelette","flap, flaps","flash, photoflash, flash_lamp, flashgun, flashbulb, flash_bulb","flash","flash_camera","flasher","flashlight, torch","flashlight_battery","flash_memory","flask","flat_arch, straight_arch","flatbed","flatbed_press, cylinder_press","flat_bench","flatcar, flatbed, flat","flat_file","flatlet","flat_panel_display, fpd","flats","flat_tip_screwdriver","fleece","fleet_ballistic_missile_submarine","fleur-de-lis, fleur-de-lys","flight_simulator, trainer","flintlock","flintlock, firelock","flip-flop, thong","flipper, fin","float, plasterer's_float","floating_dock, floating_dry_dock","floatplane, pontoon_plane","flood, floodlight, flood_lamp, photoflood","floor, flooring","floor, level, storey, story","floor","floorboard","floor_cover, floor_covering","floor_joist","floor_lamp","flophouse, dosshouse","florist, florist_shop, flower_store","floss","flotsam, jetsam","flour_bin","flour_mill","flowerbed, flower_bed, bed_of_flowers","flugelhorn, fluegelhorn","fluid_drive","fluid_flywheel","flume","fluorescent_lamp","fluoroscope, roentgenoscope","flush_toilet, lavatory","flute, transverse_flute","flute, flute_glass, champagne_flute","flux_applicator","fluxmeter","fly","flying_boat","flying_buttress, arc-boutant","flying_carpet","flying_jib","fly_rod","fly_tent","flytrap","flywheel","fob, watch_chain, watch_guard","foghorn","foglamp","foil","fold, sheepfold, sheep_pen, sheepcote","folder","folding_chair","folding_door, accordion_door","folding_saw","food_court","food_processor","food_hamper","foot","footage","football","football_helmet","football_stadium","footbath","foot_brake","footbridge, overcrossing, pedestrian_bridge","foothold, footing","footlocker, locker","foot_rule","footstool, footrest, ottoman, tuffet","footwear, footgear","footwear","forceps","force_pump","fore-and-after","fore-and-aft_sail","forecastle, fo'c'sle","forecourt","foredeck","fore_edge, foredge","foreground","foremast","fore_plane","foresail","forestay","foretop","fore-topmast","fore-topsail","forge","fork","forklift","formalwear, eveningwear, evening_dress, evening_clothes","formica","fortification, munition","fortress, fort","forty-five","foucault_pendulum","foulard","foul-weather_gear","foundation_garment, foundation","foundry, metalworks","fountain","fountain_pen","four-in-hand","four-poster","four-pounder","four-stroke_engine, four-stroke_internal-combustion_engine","four-wheel_drive, 4wd","four-wheel_drive, 4wd","four-wheeler","fowling_piece","foxhole, fox_hole","fragmentation_bomb, antipersonnel_bomb, anti-personnel_bomb, daisy_cutter","frail","fraise","frame, framing","frame","frame_buffer","framework","francis_turbine","franking_machine","free_house","free-reed","free-reed_instrument","freewheel","freight_car","freight_elevator, service_elevator","freight_liner, liner_train","freight_train, rattler","french_door","french_horn, horn","french_polish, french_polish_shellac","french_roof","french_window","fresnel_lens","fret","friary","friction_clutch","frieze","frieze","frigate","frigate","frill, flounce, ruffle, furbelow","frisbee","frock","frock_coat","frontlet, frontal","front_porch","front_projector","fruit_machine","frying_pan, frypan, skillet","fuel_filter","fuel_gauge, fuel_indicator","fuel_injection, fuel_injection_system","fuel_system","full-dress_uniform","full_metal_jacket","full_skirt","fumigator","funeral_home, funeral_parlor, funeral_parlour, funeral_chapel, funeral_church, funeral-residence","funnel","funny_wagon","fur","fur_coat","fur_hat","furnace","furnace_lining, refractory","furnace_room","furnishing","furnishing, trappings","furniture, piece_of_furniture, article_of_furniture","fur-piece","furrow","fuse, electrical_fuse, safety_fuse","fusee_drive, fusee","fuselage","fusil","fustian","futon","gabardine","gable, gable_end, gable_wall","gable_roof, saddle_roof, saddleback, saddleback_roof","gadgetry","gaff","gaff","gaff","gaffsail, gaff-headed_sail","gaff_topsail, fore-and-aft_topsail","gag, muzzle","gaiter","gaiter","galilean_telescope","galleon","gallery","gallery, art_gallery, picture_gallery","galley, ship's_galley, caboose, cookhouse","galley","galley","gallows","gallows_tree, gallows-tree, gibbet, gallous","galvanometer","gambling_house, gambling_den, gambling_hell, gaming_house","gambrel, gambrel_roof","game","gamebag","game_equipment","gaming_table","gamp, brolly","gangplank, gangboard, gangway","gangsaw","gangway","gantlet","gantry, gauntry","garage","garage, service_department","garand_rifle, garand, m-1, m-1_rifle","garbage","garbage_truck, dustcart","garboard, garboard_plank, garboard_strake","garden","garden","garden_rake","garden_spade","garden_tool, lawn_tool","garden_trowel","gargoyle","garibaldi","garlic_press","garment","garment_bag","garrison_cap, overseas_cap","garrote, garotte, garrotte, iron_collar","garter, supporter","garter_belt, suspender_belt","garter_stitch","gas_guzzler","gas_shell","gas_bracket","gas_burner, gas_jet","gas-cooled_reactor","gas-discharge_tube","gas_engine","gas_fixture","gas_furnace","gas_gun","gas_heater","gas_holder, gasometer","gasket","gas_lamp","gas_maser","gasmask, respirator, gas_helmet","gas_meter, gasometer","gasoline_engine, petrol_engine","gasoline_gauge, gasoline_gage, gas_gauge, gas_gage, petrol_gauge, petrol_gage","gas_oven","gas_oven","gas_pump, gasoline_pump, petrol_pump, island_dispenser","gas_range, gas_stove, gas_cooker","gas_ring","gas_tank, gasoline_tank, petrol_tank","gas_thermometer, air_thermometer","gastroscope","gas_turbine","gas-turbine_ship","gat, rod","gate","gatehouse","gateleg_table","gatepost","gathered_skirt","gatling_gun","gauge, gage","gauntlet, gantlet","gauntlet, gantlet, metal_glove","gauze, netting, veiling","gauze, gauze_bandage","gavel","gazebo, summerhouse","gear, gear_wheel, geared_wheel, cogwheel","gear, paraphernalia, appurtenance","gear, gear_mechanism","gearbox, gear_box, gear_case","gearing, gear, geartrain, power_train, train","gearset","gearshift, gearstick, shifter, gear_lever","geiger_counter, geiger-muller_counter","geiger_tube, geiger-muller_tube","gene_chip, dna_chip","general-purpose_bomb, gp_bomb","generator","generator","generator","geneva_gown","geodesic_dome","georgette","gharry","ghat","ghetto_blaster, boom_box","gift_shop, novelty_shop","gift_wrapping","gig","gig","gig","gig","gildhall","gill_net","gilt, gilding","gimbal","gingham","girandole, girandola","girder","girdle, cincture, sash, waistband, waistcloth","glass, drinking_glass","glass","glass_cutter","glasses_case","glebe_house","glengarry","glider, sailplane","global_positioning_system, gps","glockenspiel, orchestral_bells","glory_hole, lazaretto","glove","glove_compartment","glow_lamp","glow_tube","glyptic_art, glyptography","glyptics, lithoglyptics","gnomon","goal","goalmouth","goalpost","goblet","godown","goggles","go-kart","gold_plate","golf_bag","golf_ball","golfcart, golf_cart","golf_club, golf-club, club","golf-club_head, club_head, club-head, clubhead","golf_equipment","golf_glove","golliwog, golliwogg","gondola","gong, tam-tam","goniometer","gordian_knot","gorget","gossamer","gothic_arch","gouache","gouge","gourd, calabash","government_building","government_office","gown","gown, robe","gown, surgical_gown, scrubs","grab","grab_bag","grab_bar","grace_cup","grade_separation","graduated_cylinder","graffito, graffiti","gramophone, acoustic_gramophone","granary, garner","grandfather_clock, longcase_clock","grand_piano, grand","graniteware","granny_knot, granny","grape_arbor, grape_arbour","grapnel, grapnel_anchor","grapnel, grapple, grappler, grappling_hook, grappling_iron","grass_skirt","grate, grating","grate, grating","grater","graver, graving_tool, pointel, pointrel","gravestone, headstone, tombstone","gravimeter, gravity_meter","gravure, photogravure, heliogravure","gravy_boat, gravy_holder, sauceboat, boat","grey, gray","grease-gun, gun","greasepaint","greasy_spoon","greatcoat, overcoat, topcoat","great_hall","greave, jambeau","greengrocery","greenhouse, nursery, glasshouse","grenade","grid, gridiron","griddle","grill, grille, grillwork","grille, radiator_grille","grillroom, grill","grinder","grinding_wheel, emery_wheel","grindstone","gripsack","gristmill","grocery_bag","grocery_store, grocery, food_market, market","grogram","groined_vault","groover","grosgrain","gros_point","ground, earth","ground_bait","ground_control","ground_floor, first_floor, ground_level","groundsheet, ground_cloth","g-string, thong","guard, safety, safety_device","guard_boat","guardroom","guardroom","guard_ship","guard's_van","gueridon","guarnerius","guesthouse","guestroom","guidance_system, guidance_device","guided_missile","guided_missile_cruiser","guided_missile_frigate","guildhall","guilloche","guillotine","guimpe","guimpe","guitar","guitar_pick","gulag","gun","gunboat","gun_carriage","gun_case","gun_emplacement, weapons_emplacement","gun_enclosure, gun_turret, turret","gunlock, firing_mechanism","gunnery","gunnysack, gunny_sack, burlap_bag","gun_pendulum","gun_room","gunsight, gun-sight","gun_trigger, trigger","gurney","gusher","gusset, inset","gusset, gusset_plate","guy, guy_cable, guy_wire, guy_rope","gymnastic_apparatus, exerciser","gym_shoe, sneaker, tennis_shoe","gym_suit","gymslip","gypsy_cab","gyrocompass","gyroscope, gyro","gyrostabilizer, gyrostabiliser","habergeon","habit","habit, riding_habit","hacienda","hacksaw, hack_saw, metal_saw","haft, helve","hairbrush","haircloth, hair","hairdressing, hair_tonic, hair_oil, hair_grease","hairnet","hairpiece, false_hair, postiche","hairpin","hair_shirt","hair_slide","hair_spray","hairspring","hair_trigger","halberd","half_binding","half_hatchet","half_hitch","half_track","hall","hall","hall","hall_of_fame","hall_of_residence","hallstand","halter","halter, hackamore","hame","hammer","hammer, power_hammer","hammer","hammerhead","hammock, sack","hamper","hand","handball","handbarrow","handbell","hand_blower, blow_dryer, blow_drier, hair_dryer, hair_drier","handbow","hand_brake, emergency, emergency_brake, parking_brake","hand_calculator, pocket_calculator","handcar","handcart, pushcart, cart, go-cart","hand_cream","handcuff, cuff, handlock, manacle","hand_drill, handheld_drill","hand_glass, simple_microscope, magnifying_glass","hand_glass, hand_mirror","hand_grenade","hand-held_computer, hand-held_microcomputer","handhold","handkerchief, hankie, hanky, hankey","handlebar","handloom","hand_lotion","hand_luggage","hand-me-down","hand_mower","hand_pump","handrest","handsaw, hand_saw, carpenter's_saw","handset, french_telephone","hand_shovel","handspike","handstamp, rubber_stamp","hand_throttle","hand_tool","hand_towel, face_towel","hand_truck, truck","handwear, hand_wear","handwheel","handwheel","hangar_queen","hanger","hang_glider","hangman's_rope, hangman's_halter, halter, hemp, hempen_necktie","hank","hansom, hansom_cab","harbor, harbour","hard_disc, hard_disk, fixed_disk","hard_hat, tin_hat, safety_hat","hardtop","hardware, ironware","hardware_store, ironmonger, ironmonger's_shop","harmonica, mouth_organ, harp, mouth_harp","harmonium, organ, reed_organ","harness","harness","harp","harp","harpoon","harpoon_gun","harpoon_log","harpsichord, cembalo","harris_tweed","harrow","harvester, reaper","hash_house","hasp","hat, chapeau, lid","hatbox","hatch","hatchback, hatchback_door","hatchback","hatchel, heckle","hatchet","hatpin","hauberk, byrnie","hawaiian_guitar, steel_guitar","hawse, hawsehole, hawsepipe","hawser","hawser_bend","hay_bale","hayfork","hayloft, haymow, mow","haymaker, hay_conditioner","hayrack, hayrig","hayrack","hazard","head","head","head","headboard","head_covering, veil","headdress, headgear","header","header","header, coping, cope","header, lintel","headfast","head_gasket","head_gate","headgear","headlight, headlamp","headpiece","headpin, kingpin","headquarters, central_office, main_office, home_office, home_base","headrace","headrest","headsail","headscarf","headset","head_shop","headstall, headpiece","headstock","health_spa, spa, health_club","hearing_aid, ear_trumpet","hearing_aid, deaf-aid","hearse","hearth, fireside","hearthrug","heart-lung_machine","heat_engine","heater, warmer","heat_exchanger","heating_pad, hot_pad","heat_lamp, infrared_lamp","heat_pump","heat-seeking_missile","heat_shield","heat_sink","heaume","heaver","heavier-than-air_craft","heckelphone, basset_oboe","hectograph, heliotype","hedge, hedgerow","hedge_trimmer","helicon, bombardon","helicopter, chopper, whirlybird, eggbeater","heliograph","heliometer","helm","helmet","helmet","hematocrit, haematocrit","hemming-stitch","hemostat, haemostat","hemstitch, hemstitching","henroost","heraldry","hermitage","herringbone","herringbone, herringbone_pattern","herschelian_telescope, off-axis_reflector","hessian_boot, hessian, jackboot, wellington, wellington_boot","heterodyne_receiver, superheterodyne_receiver, superhet","hibachi","hideaway, retreat","hi-fi, high_fidelity_sound_system","high_altar","high-angle_gun","highball_glass","highboard","highboy, tallboy","highchair, feeding_chair","high_gear, high","high-hat_cymbal, high_hat","highlighter","highlighter","high-pass_filter","high-rise, tower_block","high_table","high-warp_loom","hijab","hinge, flexible_joint","hinging_post, swinging_post","hip_boot, thigh_boot","hipflask, pocket_flask","hip_pad","hip_pocket","hippodrome","hip_roof, hipped_roof","hitch","hitch","hitching_post","hitchrack, hitching_bar","hob","hobble_skirt","hockey_skate","hockey_stick","hod","hodoscope","hoe","hoe_handle","hogshead","hoist","hold, keep","holder","holding_cell","holding_device","holding_pen, holding_paddock, holding_yard","hollowware, holloware","holster","holster","holy_of_holies, sanctum_sanctorum","home, nursing_home, rest_home","home_appliance, household_appliance","home_computer","home_plate, home_base, home, plate","home_room, homeroom","homespun","homestead","home_theater, home_theatre","homing_torpedo","hone","honeycomb","hood, bonnet, cowl, cowling","hood","hood","hood, exhaust_hood","hood","hood_latch","hook","hook, claw","hook","hookah, narghile, nargileh, sheesha, shisha, chicha, calean, kalian, water_pipe, hubble-bubble, hubbly-bubbly","hook_and_eye","hookup, assemblage","hookup","hook_wrench, hook_spanner","hoopskirt, crinoline","hoosegow, hoosgow","hoover","hope_chest, wedding_chest","hopper","hopsacking, hopsack","horizontal_bar, high_bar","horizontal_stabilizer, horizontal_stabiliser, tailplane","horizontal_tail","horn","horn","horn","horn_button","hornpipe, pibgorn, stockhorn","horse, gymnastic_horse","horsebox","horsecar","horse_cart, horse-cart","horsecloth","horse-drawn_vehicle","horsehair","horsehair_wig","horseless_carriage","horse_pistol, horse-pistol","horseshoe, shoe","horseshoe","horse-trail","horsewhip","hose","hosiery, hose","hospice","hospital, infirmary","hospital_bed","hospital_room","hospital_ship","hospital_train","hostel, youth_hostel, student_lodging","hostel, hostelry, inn, lodge, auberge","hot-air_balloon","hotel","hotel-casino, casino-hotel","hotel-casino, casino-hotel","hotel_room","hot_line","hot_pants","hot_plate, hotplate","hot_rod, hot-rod","hot_spot, hotspot","hot_tub","hot-water_bottle, hot-water_bag","houndstooth_check, hound's-tooth_check, dogstooth_check, dogs-tooth_check, dog's-tooth_check","hourglass","hour_hand, little_hand","house","house","houseboat","houselights","house_of_cards, cardhouse, card-house, cardcastle","house_of_correction","house_paint, housepaint","housetop","housing, lodging, living_accommodations","hovel, hut, hutch, shack, shanty","hovercraft, ground-effect_machine","howdah, houdah","huarache, huaraches","hub-and-spoke, hub-and-spoke_system","hubcap","huck, huckaback","hug-me-tight","hula-hoop","hulk","hull","humeral_veil, veil","humvee, hum-vee","hunter, hunting_watch","hunting_knife","hurdle","hurricane_deck, hurricane_roof, promenade_deck, awning_deck","hurricane_lamp, hurricane_lantern, tornado_lantern, storm_lantern, storm_lamp","hut, army_hut, field_hut","hutch","hutment","hydraulic_brake, hydraulic_brakes","hydraulic_press","hydraulic_pump, hydraulic_ram","hydraulic_system","hydraulic_transmission, hydraulic_transmission_system","hydroelectric_turbine","hydrofoil, hydroplane","hydrofoil, foil","hydrogen_bomb, h-bomb, fusion_bomb, thermonuclear_bomb","hydrometer, gravimeter","hygrodeik","hygrometer","hygroscope","hyperbaric_chamber","hypercoaster","hypermarket","hypodermic_needle","hypodermic_syringe, hypodermic, hypo","hypsometer","hysterosalpingogram","i-beam","ice_ax, ice_axe, piolet","iceboat, ice_yacht, scooter","icebreaker, iceboat","iced-tea_spoon","ice_hockey_rink, ice-hockey_rink","ice_machine","ice_maker","ice_pack, ice_bag","icepick, ice_pick","ice_rink, ice-skating_rink, ice","ice_skate","ice_tongs","icetray","iconoscope","identikit, identikit_picture","idle_pulley, idler_pulley, idle_wheel","igloo, iglu","ignition_coil","ignition_key","ignition_switch","imaret","immovable_bandage","impact_printer","impeller","implant","implement","impression","imprint","improvised_explosive_device, i.e.d., ied","impulse_turbine","in-basket, in-tray","incendiary_bomb, incendiary, firebomb","incinerator","inclined_plane","inclinometer, dip_circle","inclinometer","incrustation, encrustation","incubator, brooder","index_register","indiaman","indian_club","indicator","induction_coil","inductor, inductance","industrial_watercourse","inertial_guidance_system, inertial_navigation_system","inflater, inflator","inhaler, inhalator","injector","ink_bottle, inkpot","ink_eraser","ink-jet_printer","inkle","inkstand","inkwell, inkstand","inlay","inside_caliper","insole, innersole","instep","instillator","institution","instrument","instrument_of_punishment","instrument_of_torture","intaglio, diaglyph","intake_valve","integrated_circuit, microcircuit","integrator, planimeter","intelnet","interceptor","interchange","intercommunication_system, intercom","intercontinental_ballistic_missile, icbm","interface, port","interferometer","interior_door","internal-combustion_engine, ice","internal_drive","internet, net, cyberspace","interphone","interrupter","intersection, crossroad, crossway, crossing, carrefour","interstice","intraocular_lens","intravenous_pyelogram, ivp","inverter","ion_engine","ionization_chamber, ionization_tube","ipod","video_ipod","iron, smoothing_iron","iron","iron, branding_iron","irons, chains","ironclad","iron_foundry","iron_horse","ironing","iron_lung","ironmongery","ironworks","irrigation_ditch","izar","jabot","jack","jack, jackstones","jack","jack","jacket","jacket","jacket","jack-in-the-box","jack-o'-lantern","jack_plane","jacob's_ladder, jack_ladder, pilot_ladder","jaconet","jacquard_loom, jacquard","jacquard","jag, dag","jail, jailhouse, gaol, clink, slammer, poky, pokey","jalousie","jamb","jammer","jampot, jamjar","japan","jar","jarvik_heart, jarvik_artificial_heart","jaunting_car, jaunty_car","javelin","jaw","jaws_of_life","jean, blue_jean, denim","jeep, landrover","jellaba","jerkin","jeroboam, double-magnum","jersey","jersey, t-shirt, tee_shirt","jet, jet_plane, jet-propelled_plane","jet_bridge","jet_engine","jetliner","jeweler's_glass","jewelled_headdress, jeweled_headdress","jew's_harp, jews'_harp, mouth_bow","jib","jibboom","jig","jig","jiggermast, jigger","jigsaw, scroll_saw, fretsaw","jigsaw_puzzle","jinrikisha, ricksha, rickshaw","jobcentre","jodhpurs, jodhpur_breeches, riding_breeches","jodhpur, jodhpur_boot, jodhpur_shoe","joinery","joint","joint_direct_attack_munition, jdam","jointer, jointer_plane, jointing_plane, long_plane","joist","jolly_boat, jolly","jorum","joss_house","journal_bearing","journal_box","joystick","jungle_gym","junk","jug","jukebox, nickelodeon","jumbojet, jumbo_jet","jumper, pinafore, pinny","jumper","jumper","jumper","jumper_cable, jumper_lead, lead, booster_cable","jump_seat","jump_suit","jump_suit, jumpsuit","junction","junction, conjunction","junction_barrier, barrier_strip","junk_shop","jury_box","jury_mast","kachina","kaffiyeh","kalansuwa","kalashnikov","kameez","kanzu","katharometer","kayak","kazoo","keel","keelboat","keelson","keep, donjon, dungeon","keg","kennel, doghouse, dog_house","kepi, peaked_cap, service_cap, yachting_cap","keratoscope","kerchief","ketch","kettle, boiler","kettle, kettledrum, tympanum, tympani, timpani","key","key","keyboard","keyboard_buffer","keyboard_instrument","keyhole","keyhole_saw","khadi, khaddar","khaki","khakis","khimar","khukuri","kick_pleat","kicksorter, pulse_height_analyzer","kickstand","kick_starter, kick_start","kid_glove, suede_glove","kiln","kilt","kimono","kinescope, picture_tube, television_tube","kinetoscope","king","king","kingbolt, kingpin, swivel_pin","king_post","kipp's_apparatus","kirk","kirpan","kirtle","kirtle","kit, outfit","kit","kitbag, kit_bag","kitchen","kitchen_appliance","kitchenette","kitchen_table","kitchen_utensil","kitchenware","kite_balloon","klaxon, claxon","klieg_light","klystron","knee_brace","knee-high, knee-hi","knee_pad","knee_piece","knife","knife","knife_blade","knight, horse","knit","knitting_machine","knitting_needle","knitwear","knob, boss","knob, pommel","knobble","knobkerrie, knobkerry","knocker, doorknocker, rapper","knot","knuckle_joint, hinge_joint","kohl","koto","kraal","kremlin","kris, creese, crease","krummhorn, crumhorn, cromorne","kundt's_tube","kurdistan","kurta","kylix, cylix","kymograph, cymograph","lab_bench, laboratory_bench","lab_coat, laboratory_coat","lace","lacquer","lacquerware","lacrosse_ball","ladder-back","ladder-back, ladder-back_chair","ladder_truck, aerial_ladder_truck","ladies'_room, powder_room","ladle","lady_chapel","lagerphone","lag_screw, lag_bolt","lake_dwelling, pile_dwelling","lally, lally_column","lamasery","lambrequin","lame","laminar_flow_clean_room","laminate","lamination","lamp","lamp","lamp_house, lamphouse, lamp_housing","lamppost","lampshade, lamp_shade","lanai","lancet_arch, lancet","lancet_window","landau","lander","landing_craft","landing_flap","landing_gear","landing_net","landing_skid","land_line, landline","land_mine, ground-emplaced_mine, booby_trap","land_office","lanolin","lantern","lanyard, laniard","lap, lap_covering","laparoscope","lapboard","lapel","lap_joint, splice","laptop, laptop_computer","laryngoscope","laser, optical_maser","laser-guided_bomb, lgb","laser_printer","lash, thong","lashing","lasso, lariat, riata, reata","latch","latch, door_latch","latchet","latchkey","lateen, lateen_sail","latex_paint, latex, rubber-base_paint","lath","lathe","latrine","lattice, latticework, fretwork","launch","launcher, rocket_launcher","laundry, wash, washing, washables","laundry_cart","laundry_truck","lavalava","lavaliere, lavalier, lavalliere","laver","lawn_chair, garden_chair","lawn_furniture","lawn_mower, mower","layette","lead-acid_battery, lead-acid_accumulator","lead-in","leading_rein","lead_pencil","leaf_spring","lean-to","lean-to_tent","leash, tether, lead","leatherette, imitation_leather","leather_strip","leclanche_cell","lectern, reading_desk","lecture_room","lederhosen","ledger_board","leg","leg","legging, leging, leg_covering","leiden_jar, leyden_jar","leisure_wear","lens, lense, lens_system","lens, electron_lens","lens_cap, lens_cover","lens_implant, interocular_lens_implant, iol","leotard, unitard, body_suit, cat_suit","letter_case","letter_opener, paper_knife, paperknife","levee","level, spirit_level","lever","lever, lever_tumbler","lever","lever_lock","levi's, levis","liberty_ship","library","library","lid","liebig_condenser","lie_detector","lifeboat","life_buoy, lifesaver, life_belt, life_ring","life_jacket, life_vest, cork_jacket","life_office","life_preserver, preserver, flotation_device","life-support_system, life_support","life-support_system, life_support","lifting_device","lift_pump","ligament","ligature","light, light_source","light_arm","light_bulb, lightbulb, bulb, incandescent_lamp, electric_light, electric-light_bulb","light_circuit, lighting_circuit","light-emitting_diode, led","lighter, light, igniter, ignitor","lighter-than-air_craft","light_filter, diffusing_screen","lighting","light_machine_gun","light_meter, exposure_meter, photometer","light_microscope","lightning_rod, lightning_conductor","light_pen, electronic_stylus","lightship","lilo","limber","limekiln","limiter, clipper","limousine, limo","linear_accelerator, linac","linen","line_printer, line-at-a-time_printer","liner, ocean_liner","liner, lining","lingerie, intimate_apparel","lining, liner","link, data_link","linkage","link_trainer","linocut","linoleum_knife, linoleum_cutter","linotype, linotype_machine","linsey-woolsey","linstock","lion-jaw_forceps","lip-gloss","lipstick, lip_rouge","liqueur_glass","liquid_crystal_display, lcd","liquid_metal_reactor","lisle","lister, lister_plow, lister_plough, middlebreaker, middle_buster","litterbin, litter_basket, litter-basket","little_theater, little_theatre","live_axle, driving_axle","living_quarters, quarters","living_room, living-room, sitting_room, front_room, parlor, parlour","load","loafer","loaner","lobe","lobster_pot","local","local_area_network, lan","local_oscillator, heterodyne_oscillator","lochaber_ax","lock","lock, ignition_lock","lock, lock_chamber","lock","lockage","locker","locker_room","locket","lock-gate","locking_pliers","lockring, lock_ring, lock_washer","lockstitch","lockup","locomotive, engine, locomotive_engine, railway_locomotive","lodge, indian_lodge","lodge, hunting_lodge","lodge","lodging_house, rooming_house","loft, attic, garret","loft, pigeon_loft","loft","log_cabin","loggia","longbow","long_iron","long_johns","long_sleeve","long_tom","long_trousers, long_pants","long_underwear, union_suit","looking_glass, glass","lookout, observation_tower, lookout_station, observatory","loom","loop_knot","lorgnette","lorraine_cross, cross_of_lorraine","lorry, camion","lota","lotion","loudspeaker, speaker, speaker_unit, loudspeaker_system, speaker_system","lounge, waiting_room, waiting_area","lounger","lounging_jacket, smoking_jacket","lounging_pajama, lounging_pyjama","loungewear","loupe, jeweler's_loupe","louvered_window, jalousie","love_knot, lovers'_knot, lover's_knot, true_lovers'_knot, true_lover's_knot","love_seat, loveseat, tete-a-tete, vis-a-vis","loving_cup","lowboy","low-pass_filter","low-warp-loom","lp, l-p","l-plate","lubber's_hole","lubricating_system, force-feed_lubricating_system, force_feed, pressure-feed_lubricating_system, pressure_feed","luff","lug","luge","luger","luggage_carrier","luggage_compartment, automobile_trunk, trunk","luggage_rack, roof_rack","lugger","lugsail, lug","lug_wrench","lumberjack, lumber_jacket","lumbermill, sawmill","lunar_excursion_module, lunar_module, lem","lunchroom","lunette","lungi, lungyi, longyi","lunula","lusterware","lute","luxury_liner, express_luxury_liner","lyceum","lychgate, lichgate","lyre","machete, matchet, panga","machicolation","machine","machine, simple_machine","machine_bolt","machine_gun","machinery","machine_screw","machine_tool","machinist's_vise, metalworking_vise","machmeter","mackinaw","mackinaw, mackinaw_boat","mackinaw, mackinaw_coat","mackintosh, macintosh","macrame","madras","mae_west, air_jacket","magazine_rack","magic_lantern","magnet","magnetic_bottle","magnetic_compass","magnetic_core_memory, core_memory","magnetic_disk, magnetic_disc, disk, disc","magnetic_head","magnetic_mine","magnetic_needle","magnetic_recorder","magnetic_stripe","magnetic_tape, mag_tape, tape","magneto, magnetoelectric_machine","magnetometer, gaussmeter","magnetron","magnifier","magnum","magnus_hitch","mail","mailbag, postbag","mailbag, mail_pouch","mailboat, mail_boat, packet, packet_boat","mailbox, letter_box","mail_car","maildrop","mailer","maillot","maillot, tank_suit","mailsorter","mail_train","mainframe, mainframe_computer","mainmast","main_rotor","mainsail","mainspring","main-topmast","main-topsail","main_yard","maisonette, maisonnette","majolica, maiolica","makeup, make-up, war_paint","maksutov_telescope","malacca, malacca_cane","mallet, beetle","mallet, hammer","mallet","mammogram","mandola","mandolin","manger, trough","mangle","manhole","manhole_cover","man-of-war, ship_of_the_line","manometer","manor, manor_house","manor_hall, hall","manpad","mansard, mansard_roof","manse","mansion, mansion_house, manse, hall, residence","mantel, mantelpiece, mantle, mantlepiece, chimneypiece","mantelet, mantilla","mantilla","mao_jacket","map","maquiladora","maraca","marble","marching_order","marimba, xylophone","marina","marker","marketplace, market_place, mart, market","marlinespike, marlinspike, marlingspike","marocain, crepe_marocain","marquee, marquise","marquetry, marqueterie","marriage_bed","martello_tower","martingale","mascara","maser","masher","mashie, five_iron","mashie_niblick, seven_iron","masjid, musjid","mask","mask","masonite","mason_jar","masonry","mason's_level","massage_parlor","massage_parlor","mass_spectrograph","mass_spectrometer, spectrometer","mast","mast","mastaba, mastabah","master_bedroom","masterpiece, chef-d'oeuvre","mat","mat, gym_mat","match, lucifer, friction_match","match","matchboard","matchbook","matchbox","matchlock","match_plane, tonguing_and_grooving_plane","matchstick","material","materiel, equipage","maternity_hospital","maternity_ward","matrix","matthew_walker, matthew_walker_knot","matting","mattock","mattress_cover","maul, sledge, sledgehammer","maulstick, mahlstick","mauser","mausoleum","maxi","maxim_gun","maximum_and_minimum_thermometer","maypole","maze, labyrinth","mazer","means","measure","measuring_cup","measuring_instrument, measuring_system, measuring_device","measuring_stick, measure, measuring_rod","meat_counter","meat_grinder","meat_hook","meat_house","meat_safe","meat_thermometer","mechanical_device","mechanical_piano, pianola, player_piano","mechanical_system","mechanism","medical_building, health_facility, healthcare_facility","medical_instrument","medicine_ball","medicine_chest, medicine_cabinet","medline","megalith, megalithic_structure","megaphone","memorial, monument","memory, computer_memory, storage, computer_storage, store, memory_board","memory_chip","memory_device, storage_device","menagerie, zoo, zoological_garden","mending","menhir, standing_stone","menorah","menorah","man's_clothing","men's_room, men's","mercantile_establishment, retail_store, sales_outlet, outlet","mercury_barometer","mercury_cell","mercury_thermometer, mercury-in-glass_thermometer","mercury-vapor_lamp","mercy_seat","merlon","mess, mess_hall","mess_jacket, monkey_jacket, shell_jacket","mess_kit","messuage","metal_detector","metallic","metal_screw","metal_wood","meteorological_balloon","meter","meterstick, metrestick","metronome","mezzanine, mezzanine_floor, entresol","mezzanine, first_balcony","microbalance","microbrewery","microfiche","microfilm","micrometer, micrometer_gauge, micrometer_caliper","microphone, mike","microprocessor","microscope","microtome","microwave, microwave_oven","microwave_diathermy_machine","microwave_linear_accelerator","middy, middy_blouse","midiron, two_iron","mihrab","mihrab","military_hospital","military_quarters","military_uniform","military_vehicle","milk_bar","milk_can","milk_float","milking_machine","milking_stool","milk_wagon, milkwagon","mill, grinder, milling_machinery","milldam","miller, milling_machine","milliammeter","millinery, woman's_hat","millinery, hat_shop","milling","millivoltmeter","millstone","millstone","millwheel, mill_wheel","mimeograph, mimeo, mimeograph_machine, roneo, roneograph","minaret","mincer, mincing_machine","mine","mine_detector","minelayer","mineshaft","minibar, cellaret","minibike, motorbike","minibus","minicar","minicomputer","ministry","miniskirt, mini","minisub, minisubmarine","minivan","miniver","mink, mink_coat","minster","mint","minute_hand, big_hand","minuteman","mirror","missile","missile_defense_system, missile_defence_system","miter_box, mitre_box","miter_joint, mitre_joint, miter, mitre","mitten","mixer","mixer","mixing_bowl","mixing_faucet","mizzen, mizen","mizzenmast, mizenmast, mizzen, mizen","mobcap","mobile_home, manufactured_home","moccasin, mocassin","mock-up","mod_con","model_t","modem","modillion","module","module","mohair","moire, watered-silk","mold, mould, cast","moldboard, mouldboard","moldboard_plow, mouldboard_plough","moleskin","molotov_cocktail, petrol_bomb, gasoline_bomb","monastery","monastic_habit","moneybag","money_belt","monitor","monitor","monitor, monitoring_device","monkey-wrench, monkey_wrench","monk's_cloth","monochrome","monocle, eyeglass","monofocal_lens_implant, monofocal_iol","monoplane","monotype","monstrance, ostensorium","mooring_tower, mooring_mast","moorish_arch, horseshoe_arch","moped","mop_handle","moquette","morgue, mortuary, dead_room","morion, cabasset","morning_dress","morning_dress","morning_room","morris_chair","mortar, howitzer, trench_mortar","mortar","mortarboard","mortise_joint, mortise-and-tenon_joint","mosaic","mosque","mosquito_net","motel","motel_room","mother_hubbard, muumuu","motion-picture_camera, movie_camera, cine-camera","motion-picture_film, movie_film, cine-film","motley","motley","motor","motorboat, powerboat","motorcycle, bike","motor_hotel, motor_inn, motor_lodge, tourist_court, court","motorized_wheelchair","motor_scooter, scooter","motor_vehicle, automotive_vehicle","mound, hill","mound, hill, pitcher's_mound","mount, setting","mountain_bike, all-terrain_bike, off-roader","mountain_tent","mouse, computer_mouse","mouse_button","mousetrap","mousse, hair_mousse, hair_gel","mouthpiece, embouchure","mouthpiece","mouthpiece, gumshield","movement","movie_projector, cine_projector, film_projector","moving-coil_galvanometer","moving_van","mud_brick","mudguard, splash_guard, splash-guard","mudhif","muff","muffle","muffler","mufti","mug","mulch","mule, scuff","multichannel_recorder","multiengine_airplane, multiengine_plane","multiplex","multiplexer","multiprocessor","multistage_rocket, step_rocket","munition, ordnance, ordnance_store","murphy_bed","musette, shepherd's_pipe","musette_pipe","museum","mushroom_anchor","musical_instrument, instrument","music_box, musical_box","music_hall, vaudeville_theater, vaudeville_theatre","music_school","music_stand, music_rack","music_stool, piano_stool","musket","musket_ball, ball","muslin","mustache_cup, moustache_cup","mustard_plaster, sinapism","mute","muzzle_loader","muzzle","myelogram","nacelle","nail","nailbrush","nailfile","nailhead","nailhead","nail_polish, nail_enamel, nail_varnish","nainsook","napier's_bones, napier's_rods","nard, spikenard","narrowbody_aircraft, narrow-body_aircraft, narrow-body","narrow_wale","narthex","narthex","nasotracheal_tube","national_monument","nautilus, nuclear_submarine, nuclear-powered_submarine","navigational_system","naval_equipment","naval_gun","naval_missile","naval_radar","naval_tactical_data_system","naval_weaponry","nave","navigational_instrument","nebuchadnezzar","neckband","neck_brace","neckcloth, stock","neckerchief","necklace","necklet","neckline","neckpiece","necktie, tie","neckwear","needle","needle","needlenose_pliers","needlework, needlecraft","negative","negative_magnetic_pole, negative_pole, south-seeking_pole","negative_pole","negligee, neglige, peignoir, wrapper, housecoat","neolith","neon_lamp, neon_induction_lamp, neon_tube","nephoscope","nest","nest_egg","net, network, mesh, meshing, meshwork","net","net","net","network, electronic_network","network","neutron_bomb","newel","newel_post, newel","newspaper, paper","newsroom","newsroom","newsstand","newtonian_telescope, newtonian_reflector","nib, pen_nib","niblick, nine_iron","nicad, nickel-cadmium_accumulator","nickel-iron_battery, nickel-iron_accumulator","nicol_prism","night_bell","nightcap","nightgown, gown, nightie, night-robe, nightdress","night_latch","night-light","nightshirt","nightwear, sleepwear, nightclothes","ninepin, skittle, skittle_pin","ninepin_ball, skittle_ball","ninon","nipple","nipple_shield","niqab","nissen_hut, quonset_hut","nogging","noisemaker","nonsmoker, nonsmoking_car","non-volatile_storage, nonvolatile_storage","norfolk_jacket","noria","nosebag, feedbag","noseband, nosepiece","nose_flute","nosewheel","notebook, notebook_computer","nuclear-powered_ship","nuclear_reactor, reactor","nuclear_rocket","nuclear_weapon, atomic_weapon","nude, nude_painting","numdah, numdah_rug, nammad","nun's_habit","nursery, baby's_room","nut_and_bolt","nutcracker","nylon","nylons, nylon_stocking, rayons, rayon_stocking, silk_stocking","oar","oast","oast_house","obelisk","object_ball","objective, objective_lens, object_lens, object_glass","oblique_bandage","oboe, hautboy, hautbois","oboe_da_caccia","oboe_d'amore","observation_dome","observatory","obstacle","obturator","ocarina, sweet_potato","octant","odd-leg_caliper","odometer, hodometer, mileometer, milometer","oeil_de_boeuf","office, business_office","office_building, office_block","office_furniture","officer's_mess","off-line_equipment, auxiliary_equipment","ogee, cyma_reversa","ogee_arch, keel_arch","ohmmeter","oil, oil_color, oil_colour","oilcan","oilcloth","oil_filter","oil_heater, oilstove, kerosene_heater, kerosine_heater","oil_lamp, kerosene_lamp, kerosine_lamp","oil_paint","oil_pump","oil_refinery, petroleum_refinery","oilskin, slicker","oil_slick","oilstone","oil_tanker, oiler, tanker, tank_ship","old_school_tie","olive_drab","olive_drab, olive-drab_uniform","olympian_zeus","omelet_pan, omelette_pan","omnidirectional_antenna, nondirectional_antenna","omnirange, omnidirectional_range, omnidirectional_radio_range","onion_dome","open-air_market, open-air_marketplace, market_square","open_circuit","open-end_wrench, tappet_wrench","opener","open-hearth_furnace","openside_plane, rabbet_plane","open_sight","openwork","opera, opera_house","opera_cloak, opera_hood","operating_microscope","operating_room, or, operating_theater, operating_theatre, surgery","operating_table","ophthalmoscope","optical_device","optical_disk, optical_disc","optical_instrument","optical_pyrometer, pyroscope","optical_telescope","orchestra_pit, pit","ordinary, ordinary_bicycle","organ, pipe_organ","organdy, organdie","organic_light-emitting_diode, oled","organ_loft","organ_pipe, pipe, pipework","organza","oriel, oriel_window","oriflamme","o_ring","orlon","orlop_deck, orlop, fourth_deck","orphanage, orphans'_asylum","orphrey","orrery","orthicon, image_orthicon","orthochromatic_film","orthopter, ornithopter","orthoscope","oscillograph","oscilloscope, scope, cathode-ray_oscilloscope, cro","ossuary","otoscope, auriscope, auroscope","ottoman, pouf, pouffe, puff, hassock","oubliette","out-basket, out-tray","outboard_motor, outboard","outboard_motorboat, outboard","outbuilding","outerwear, overclothes","outfall","outfit, getup, rig, turnout","outfitter","outhouse, privy, earth-closet, jakes","output_device","outrigger","outrigger_canoe","outside_caliper","outside_mirror","outwork","oven","oven_thermometer","overall","overall, boilersuit, boilers_suit","overcoat, overcoating","overdrive","overgarment, outer_garment","overhand_knot","overhang","overhead_projector","overmantel","overnighter, overnight_bag, overnight_case","overpass, flyover","override","overshoe","overskirt","oxbow","oxbridge","oxcart","oxeye","oxford","oximeter","oxyacetylene_torch","oxygen_mask","oyster_bar","oyster_bed, oyster_bank, oyster_park","pace_car","pacemaker, artificial_pacemaker","pack","pack","pack, face_pack","package, parcel","package_store, liquor_store, off-licence","packaging","packet","packing_box, packing_case","packinghouse, packing_plant","packinghouse","packing_needle","packsaddle","paddle, boat_paddle","paddle","paddle","paddle_box, paddle-box","paddle_steamer, paddle-wheeler","paddlewheel, paddle_wheel","paddock","padlock","page_printer, page-at-a-time_printer","paint, pigment","paintball","paintball_gun","paintbox","paintbrush","paisley","pajama, pyjama, pj's, jammies","pajama, pyjama","palace","palace, castle","palace","palanquin, palankeen","paleolith","palestra, palaestra","palette, pallet","palette_knife","palisade","pallet","pallette, palette","pallium","pallium","pan","pan, cooking_pan","pancake_turner","panchromatic_film","panda_car","paneling, panelling, pane","panhandle","panic_button","pannier","pannier","pannikin","panopticon","panopticon","panpipe, pandean_pipe, syrinx","pantaloon","pantechnicon","pantheon","pantheon","pantie, panty, scanty, step-in","panting, trousering","pant_leg, trouser_leg","pantograph","pantry, larder, buttery","pants_suit, pantsuit","panty_girdle","pantyhose","panzer","paper_chain","paper_clip, paperclip, gem_clip","paper_cutter","paper_fastener","paper_feed","paper_mill","paper_towel","parabolic_mirror","parabolic_reflector, paraboloid_reflector","parachute, chute","parallel_bars, bars","parallel_circuit, shunt_circuit","parallel_interface, parallel_port","parang","parapet, breastwork","parapet","parasail","parasol, sunshade","parer, paring_knife","parfait_glass","pargeting, pargetting, pargetry","pari-mutuel_machine, totalizer, totaliser, totalizator, totalisator","parka, windbreaker, windcheater, anorak","park_bench","parking_meter","parlor, parlour","parquet, parquet_floor","parquetry, parqueterie","parsonage, vicarage, rectory","parsons_table","partial_denture","particle_detector","partition, divider","parts_bin","party_line","party_wall","parvis","passenger_car, coach, carriage","passenger_ship","passenger_train","passenger_van","passe-partout","passive_matrix_display","passkey, passe-partout, master_key, master","pass-through","pastry_cart","patch","patchcord","patchouli, patchouly, pachouli","patch_pocket","patchwork, patchwork_quilt","patent_log, screw_log, taffrail_log","paternoster","patina","patio, terrace","patisserie","patka","patrol_boat, patrol_ship","patty-pan","pave","pavilion, marquee","pavior, paviour, paving_machine","pavis, pavise","pawn","pawnbroker's_shop, pawnshop, loan_office","pay-phone, pay-station","pc_board","peach_orchard","pea_jacket, peacoat","peavey, peavy, cant_dog, dog_hook","pectoral, pectoral_medallion","pedal, treadle, foot_pedal, foot_lever","pedal_pusher, toreador_pants","pedestal, plinth, footstall","pedestal_table","pedestrian_crossing, zebra_crossing","pedicab, cycle_rickshaw","pediment","pedometer","peeler","peep_sight","peg, nog","peg, pin, thole, tholepin, rowlock, oarlock","peg","peg, wooden_leg, leg, pegleg","pegboard","pelham","pelican_crossing","pelisse","pelvimeter","pen","penal_colony","penal_institution, penal_facility","penalty_box","pen-and-ink","pencil","pencil","pencil_box, pencil_case","pencil_sharpener","pendant_earring, drop_earring, eardrop","pendulum","pendulum_clock","pendulum_watch","penetration_bomb","penile_implant","penitentiary, pen","penknife","penlight","pennant, pennon, streamer, waft","pennywhistle, tin_whistle, whistle","penthouse","pentode","peplos, peplus, peplum","peplum","pepper_mill, pepper_grinder","pepper_shaker, pepper_box, pepper_pot","pepper_spray","percale","percolator","percussion_cap","percussion_instrument, percussive_instrument","perforation","perfume, essence","perfumery","perfumery","perfumery","peripheral, computer_peripheral, peripheral_device","periscope","peristyle","periwig, peruke","permanent_press, durable_press","perpetual_motion_machine","personal_computer, pc, microcomputer","personal_digital_assistant, pda, personal_organizer, personal_organiser, organizer, organiser","personnel_carrier","pestle","pestle, muller, pounder","petcock","petri_dish","petrolatum_gauze","pet_shop","petticoat, half-slip, underskirt","pew, church_bench","phial, vial, ampule, ampul, ampoule","phillips_screw","phillips_screwdriver","phonograph_needle, needle","phonograph_record, phonograph_recording, record, disk, disc, platter","photocathode","photocoagulator","photocopier","photographic_equipment","photographic_paper, photographic_material","photometer","photomicrograph","photostat, photostat_machine","photostat","physical_pendulum, compound_pendulum","piano, pianoforte, forte-piano","piano_action","piano_keyboard, fingerboard, clavier","piano_wire","piccolo","pick, pickax, pickaxe","pick","pick, plectrum, plectron","pickelhaube","picket_boat","picket_fence, paling","picket_ship","pickle_barrel","pickup, pickup_truck","picture_frame","picture_hat","picture_rail","picture_window","piece_of_cloth, piece_of_material","pied-a-terre","pier","pier","pier_arch","pier_glass, pier_mirror","pier_table","pieta","piezometer","pig_bed, pig","piggery, pig_farm","piggy_bank, penny_bank","pilaster","pile, spile, piling, stilt","pile_driver","pill_bottle","pillbox, toque, turban","pillion","pillory","pillow","pillow_block","pillow_lace, bobbin_lace","pillow_sham","pilot_bit","pilot_boat","pilot_burner, pilot_light, pilot","pilot_cloth","pilot_engine","pilothouse, wheelhouse","pilot_light, pilot_lamp, indicator_lamp","pin","pin, flag","pin, pin_tumbler","pinata","pinball_machine, pin_table","pince-nez","pincer, pair_of_pincers, tweezer, pair_of_tweezers","pinch_bar","pincurl_clip","pinfold","ping-pong_ball","pinhead","pinion","pinnacle","pinprick","pinstripe","pinstripe","pinstripe","pintle","pinwheel, pinwheel_wind_collector","pinwheel","tabor_pipe","pipe","pipe_bomb","pipe_cleaner","pipe_cutter","pipefitting, pipe_fitting","pipet, pipette","pipe_vise, pipe_clamp","pipe_wrench, tube_wrench","pique","pirate, pirate_ship","piste","pistol, handgun, side_arm, shooting_iron","pistol_grip","piston, plunger","piston_ring","piston_rod","pit","pitcher, ewer","pitchfork","pitching_wedge","pitch_pipe","pith_hat, pith_helmet, sun_helmet, topee, topi","piton","pitot-static_tube, pitot_head, pitot_tube","pitot_tube, pitot","pitsaw","pivot, pin","pivoting_window","pizzeria, pizza_shop, pizza_parlor","place_of_business, business_establishment","place_of_worship, house_of_prayer, house_of_god, house_of_worship","placket","planchet, coin_blank","plane, carpenter's_plane, woodworking_plane","plane, planer, planing_machine","plane_seat","planetarium","planetarium","planetarium","planetary_gear, epicyclic_gear, planet_wheel, planet_gear","plank-bed","planking","planner","plant, works, industrial_plant","planter","plaster, adhesive_plaster, sticking_plaster","plasterboard, gypsum_board","plastering_trowel","plastic_bag","plastic_bomb","plastic_laminate","plastic_wrap","plastron","plastron","plastron","plate, scale, shell","plate, collection_plate","plate","platen","platen","plate_rack","plate_rail","platform","platform, weapons_platform","platform","platform_bed","platform_rocker","plating, metal_plating","platter","playback","playbox, play-box","playground","playpen, pen","playsuit","plaza, mall, center, shopping_mall, shopping_center, shopping_centre","pleat, plait","plenum","plethysmograph","pleximeter, plessimeter","plexor, plessor, percussor","pliers, pair_of_pliers, plyers","plimsoll","plotter","plow, plough","plug, stopper, stopple","plug, male_plug","plug_fuse","plughole","plumb_bob, plumb, plummet","plumb_level","plunger, plumber's_helper","plus_fours","plush","plywood, plyboard","pneumatic_drill","p-n_junction","p-n-p_transistor","poacher","pocket","pocket_battleship","pocketcomb, pocket_comb","pocket_flap","pocket-handkerchief","pocketknife, pocket_knife","pocket_watch","pod, fuel_pod","pogo_stick","point-and-shoot_camera","pointed_arch","pointing_trowel","point_lace, needlepoint","poker, stove_poker, fire_hook, salamander","polarimeter, polariscope","polaroid","polaroid_camera, polaroid_land_camera","pole","pole","poleax, poleaxe","poleax, poleaxe","police_boat","police_van, police_wagon, paddy_wagon, patrol_wagon, wagon, black_maria","polling_booth","polo_ball","polo_mallet, polo_stick","polonaise","polo_shirt, sport_shirt","polyester","polygraph","pomade, pomatum","pommel_horse, side_horse","poncho","pongee","poniard, bodkin","pontifical","pontoon","pontoon_bridge, bateau_bridge, floating_bridge","pony_cart, ponycart, donkey_cart, tub-cart","pool_ball","poolroom","pool_table, billiard_table, snooker_table","poop_deck","poor_box, alms_box, mite_box","poorhouse","pop_bottle, soda_bottle","popgun","poplin","popper","poppet, poppet_valve","pop_tent","porcelain","porch","porkpie, porkpie_hat","porringer","portable","portable_computer","portable_circular_saw, portable_saw","portcullis","porte-cochere","porte-cochere","portfolio","porthole","portico","portiere","portmanteau, gladstone, gladstone_bag","portrait_camera","portrait_lens","positive_pole, positive_magnetic_pole, north-seeking_pole","positive_pole","positron_emission_tomography_scanner, pet_scanner","post","postage_meter","post_and_lintel","post_chaise","postern","post_exchange, px","posthole_digger, post-hole_digger","post_horn","posthouse, post_house","pot","pot, flowerpot","potbelly, potbelly_stove","potemkin_village","potential_divider, voltage_divider","potentiometer, pot","potentiometer","potpourri","potsherd","potter's_wheel","pottery, clayware","pottle","potty_seat, potty_chair","pouch","poultice, cataplasm, plaster","pound, dog_pound","pound_net","powder","powder_and_shot","powdered_mustard, dry_mustard","powder_horn, powder_flask","powder_keg","power_brake","power_cord","power_drill","power_line, power_cable","power_loom","power_mower, motor_mower","power_pack","power_saw, saw, sawing_machine","power_shovel, excavator, digger, shovel","power_steering, power-assisted_steering","power_takeoff, pto","power_tool","praetorium, pretorium","prayer_rug, prayer_mat","prayer_shawl, tallith, tallis","precipitator, electrostatic_precipitator, cottrell_precipitator","prefab","presbytery","presence_chamber","press, mechanical_press","press, printing_press","press","press_box","press_gallery","press_of_sail, press_of_canvas","pressure_cabin","pressure_cooker","pressure_dome","pressure_gauge, pressure_gage","pressurized_water_reactor, pwr","pressure_suit","pricket","prie-dieu","primary_coil, primary_winding, primary","primus_stove, primus","prince_albert","print","print_buffer","printed_circuit","printer, printing_machine","printer","printer_cable","priory","prison, prison_house","prison_camp, internment_camp, prisoner_of_war_camp, pow_camp","privateer","private_line","privet_hedge","probe","proctoscope","prod, goad","production_line, assembly_line, line","projectile, missile","projector","projector","prolonge","prolonge_knot, sailor's_breastplate","prompter, autocue","prong","propeller, propellor","propeller_plane","propjet, turboprop, turbo-propeller_plane","proportional_counter_tube, proportional_counter","propulsion_system","proscenium, proscenium_wall","proscenium_arch","prosthesis, prosthetic_device","protective_covering, protective_cover, protection","protective_garment","proton_accelerator","protractor","pruner, pruning_hook, lopper","pruning_knife","pruning_saw","pruning_shears","psaltery","psychrometer","pt_boat, mosquito_boat, mosquito_craft, motor_torpedo_boat","public_address_system, p.a._system, pa_system, p.a., pa","public_house, pub, saloon, pothouse, gin_mill, taphouse","public_toilet, comfort_station, public_convenience, convenience, public_lavatory, restroom, toilet_facility, wash_room","public_transport","public_works","puck, hockey_puck","pull","pullback, tieback","pull_chain","pulley, pulley-block, pulley_block, block","pull-off, rest_area, rest_stop, layby, lay-by","pullman, pullman_car","pullover, slipover","pull-through","pulse_counter","pulse_generator","pulse_timing_circuit","pump","pump","pump_action, slide_action","pump_house, pumping_station","pump_room","pump-type_pliers","pump_well","punch, puncher","punchboard","punch_bowl","punching_bag, punch_bag, punching_ball, punchball","punch_pliers","punch_press","punnet","punt","pup_tent, shelter_tent","purdah","purifier","purl, purl_stitch","purse","push-bike","push_broom","push_button, push, button","push-button_radio","pusher, zori","put-put","puttee","putter, putting_iron","putty_knife","puzzle","pylon, power_pylon","pylon","pyramidal_tent","pyrograph","pyrometer","pyrometric_cone","pyrostat","pyx, pix","pyx, pix, pyx_chest, pix_chest","pyxis","quad, quadrangle","quadrant","quadraphony, quadraphonic_system, quadriphonic_system","quartering","quarterstaff","quartz_battery, quartz_mill","quartz_lamp","queen","queen","queen_post","quern","quill, quill_pen","quilt, comforter, comfort, puff","quilted_bedspread","quilting","quipu","quirk_molding, quirk_moulding","quirt","quiver","quoin, coign, coigne","quoit","qwerty_keyboard","rabbet, rebate","rabbet_joint","rabbit_ears","rabbit_hutch","raceabout","racer, race_car, racing_car","raceway, race","racing_boat","racing_gig","racing_skiff, single_shell","rack, stand","rack","rack, wheel","rack_and_pinion","racket, racquet","racquetball","radar, microwave_radar, radio_detection_and_ranging, radiolocation","radial, radial_tire, radial-ply_tire","radial_engine, rotary_engine","radiation_pyrometer","radiator","radiator","radiator_cap","radiator_hose","radio, wireless","radio_antenna, radio_aerial","radio_chassis","radio_compass","radiogram, radiograph, shadowgraph, skiagraph, skiagram","radio_interferometer","radio_link, link","radiometer","radiomicrometer","radio-phonograph, radio-gramophone","radio_receiver, receiving_set, radio_set, radio, tuner, wireless","radiotelegraph, radiotelegraphy, wireless_telegraph, wireless_telegraphy","radiotelephone, radiophone, wireless_telephone","radio_telescope, radio_reflector","radiotherapy_equipment","radio_transmitter","radome, radar_dome","raft","rafter, balk, baulk","raft_foundation","rag, shred, tag, tag_end, tatter","ragbag","raglan","raglan_sleeve","rail","rail_fence","railhead","railing, rail","railing","railroad_bed","railroad_tunnel","rain_barrel","raincoat, waterproof","rain_gauge, rain_gage, pluviometer, udometer","rain_stick","rake","rake_handle","ram_disk","ramekin, ramequin","ramjet, ramjet_engine, atherodyde, athodyd, flying_drainpipe","rammer","ramp, incline","rampant_arch","rampart, bulwark, wall","ramrod","ramrod","ranch, spread, cattle_ranch, cattle_farm","ranch_house","random-access_memory, random_access_memory, random_memory, ram, read/write_memory","rangefinder, range_finder","range_hood","range_pole, ranging_pole, flagpole","rapier, tuck","rariora","rasp, wood_file","ratchet, rachet, ratch","ratchet_wheel","rathskeller","ratline, ratlin","rat-tail_file","rattan, ratan","rattrap","rayon","razor","razorblade","reaction-propulsion_engine, reaction_engine","reaction_turbine","reactor","reading_lamp","reading_room","read-only_memory, rom, read-only_storage, fixed_storage","read-only_memory_chip","readout, read-out","read/write_head, head","ready-to-wear","real_storage","reamer","reamer, juicer, juice_reamer","rearview_mirror","reaumur_thermometer","rebozo","receiver, receiving_system","receptacle","reception_desk","reception_room","recess, niche","reciprocating_engine","recliner, reclining_chair, lounger","reconnaissance_plane","reconnaissance_vehicle, scout_car","record_changer, auto-changer, changer","recorder, recording_equipment, recording_machine","recording","recording_system","record_player, phonograph","record_sleeve, record_cover","recovery_room","recreational_vehicle, rv, r.v.","recreation_room, rec_room","recycling_bin","recycling_plant","redbrick_university","red_carpet","redoubt","redoubt","reduction_gear","reed_pipe","reed_stop","reef_knot, flat_knot","reel","reel","refectory","refectory_table","refinery","reflecting_telescope, reflector","reflectometer","reflector","reflex_camera","reflux_condenser","reformatory, reform_school, training_school","reformer","refracting_telescope","refractometer","refrigeration_system","refrigerator, icebox","refrigerator_car","refuge, sanctuary, asylum","regalia","regimentals","regulator","rein","relay, electrical_relay","release, button","religious_residence, cloister","reliquary","remote_control, remote","remote_terminal, link-attached_terminal, remote_station, link-attached_station","removable_disk","rendering","rep, repp","repair_shop, fix-it_shop","repeater","repeating_firearm, repeater","repository, monument","reproducer","rerebrace, upper_cannon","rescue_equipment","research_center, research_facility","reseau","reservoir","reset","reset_button","residence","resistance_pyrometer","resistor, resistance","resonator","resonator, cavity_resonator, resonating_chamber","resort_hotel, spa","respirator, inhalator","restaurant, eating_house, eating_place, eatery","rest_house","restraint, constraint","resuscitator","retainer","retaining_wall","reticle, reticule, graticule","reticulation","reticule","retort","retractor","return_key, return","reverberatory_furnace","revers, revere","reverse, reverse_gear","reversible","revetment, revetement, stone_facing","revetment","revolver, six-gun, six-shooter","revolving_door, revolver","rheometer","rheostat, variable_resistor","rhinoscope","rib","riband, ribband","ribbed_vault","ribbing","ribbon_development","rib_joint_pliers","ricer","riddle","ride","ridge, ridgepole, rooftree","ridge_rope","riding_boot","riding_crop, hunting_crop","riding_mower","rifle","rifle_ball","rifle_grenade","rig","rigger, rigger_brush","rigger","rigging, tackle","rigout","ringlet","rings","rink, skating_rink","riot_gun","ripcord","ripcord","ripping_bar","ripping_chisel","ripsaw, splitsaw","riser","riser, riser_pipe, riser_pipeline, riser_main","ritz","river_boat","rivet","riveting_machine, riveter, rivetter","roach_clip, roach_holder","road, route","roadbed","roadblock, barricade","roadhouse","roadster, runabout, two-seater","roadway","roaster","robe","robotics_equipment","rochon_prism, wollaston_prism","rock_bit, roller_bit","rocker","rocker, cradle","rocker_arm, valve_rocker","rocket, rocket_engine","rocket, projectile","rocking_chair, rocker","rod","rodeo","roll","roller","roller","roller_bandage","in-line_skate","rollerblade","roller_blind","roller_coaster, big_dipper, chute-the-chute","roller_skate","roller_towel","roll_film","rolling_hitch","rolling_mill","rolling_pin","rolling_stock","roll-on","roll-on","roll-on_roll-off","rolodex","roman_arch, semicircular_arch","roman_building","romper, romper_suit","rood_screen","roof","roof","roofing","room","roomette","room_light","roost","rope","rope_bridge","rope_tow","rose_water","rose_window, rosette","rosin_bag","rotary_actuator, positioner","rotary_engine","rotary_press","rotating_mechanism","rotating_shaft, shaft","rotisserie","rotisserie","rotor","rotor, rotor_coil","rotor","rotor_blade, rotary_wing","rotor_head, rotor_shaft","rotunda","rotunda","rouge, paint, blusher","roughcast","rouleau","roulette, toothed_wheel","roulette_ball","roulette_wheel, wheel","round, unit_of_ammunition, one_shot","round_arch","round-bottom_flask","roundel","round_file","roundhouse","router","router","router_plane","rowel","row_house, town_house","rowing_boat","rowlock_arch","royal","royal_mast","rubber_band, elastic_band, elastic","rubber_boot, gum_boot","rubber_bullet","rubber_eraser, rubber, pencil_eraser","rudder","rudder","rudder_blade","rug, carpet, carpeting","rugby_ball","ruin","rule, ruler","rumble","rumble_seat","rummer","rumpus_room, playroom, game_room","runcible_spoon","rundle, spoke, rung","running_shoe","running_suit","runway","rushlight, rush_candle","russet","rya, rya_rug","saber, sabre","saber_saw, jigsaw, reciprocating_saw","sable","sable, sable_brush, sable's_hair_pencil","sable_coat","sabot, wooden_shoe","sachet","sack, poke, paper_bag, carrier_bag","sack, sacque","sackbut","sackcloth","sackcloth","sack_coat","sacking, bagging","saddle","saddlebag","saddle_blanket, saddlecloth, horse_blanket","saddle_oxford, saddle_shoe","saddlery","saddle_seat","saddle_stitch","safe","safe","safe-deposit, safe-deposit_box, safety-deposit, safety_deposit_box, deposit_box, lockbox","safe_house","safety_arch","safety_belt, life_belt, safety_harness","safety_bicycle, safety_bike","safety_bolt, safety_lock","safety_curtain","safety_fuse","safety_lamp, davy_lamp","safety_match, book_matches","safety_net","safety_pin","safety_rail, guardrail","safety_razor","safety_valve, relief_valve, escape_valve, escape_cock, escape","sail, canvas, canvass, sheet","sail","sailboat, sailing_boat","sailcloth","sailing_vessel, sailing_ship","sailing_warship","sailor_cap","sailor_suit","salad_bar","salad_bowl","salinometer","sallet, salade","salon","salon","salon, beauty_salon, beauty_parlor, beauty_parlour, beauty_shop","saltbox","saltcellar","saltshaker, salt_shaker","saltworks","salver","salwar, shalwar","sam_browne_belt","samisen, shamisen","samite","samovar","sampan","sandal","sandbag","sandblaster","sandbox","sandglass","sand_wedge","sandwich_board","sanitary_napkin, sanitary_towel, kotex","cling_film, clingfilm, saran_wrap","sarcenet, sarsenet","sarcophagus","sari, saree","sarong","sash, window_sash","sash_fastener, sash_lock, window_lock","sash_window","satchel","sateen","satellite, artificial_satellite, orbiter","satellite_receiver","satellite_television, satellite_tv","satellite_transmitter","satin","saturday_night_special","saucepan","saucepot","sauna, sweat_room","savings_bank, coin_bank, money_box, bank","saw","sawed-off_shotgun","sawhorse, horse, sawbuck, buck","sawmill","saw_set","sax, saxophone","saxhorn","scabbard","scaffolding, staging","scale","scale, weighing_machine","scaler","scaling_ladder","scalpel","scanner, electronic_scanner","scanner","scanner, digital_scanner, image_scanner","scantling, stud","scarf","scarf_joint, scarf","scatter_rug, throw_rug","scauper, scorper","schmidt_telescope, schmidt_camera","school, schoolhouse","schoolbag","school_bell","school_bus","school_ship, training_ship","school_system","schooner","schooner","scientific_instrument","scimitar","scintillation_counter","scissors, pair_of_scissors","sclerometer","scoinson_arch, sconcheon_arch","sconce","sconce","scoop","scooter","scoreboard","scouring_pad","scow","scow","scraper","scratcher","screen","screen, cover, covert, concealment","screen","screen, crt_screen","screen_door, screen","screening","screw","screw, screw_propeller","screw","screwdriver","screw_eye","screw_key","screw_thread, thread","screwtop","screw_wrench","scriber, scribe, scratch_awl","scrim","scrimshaw","scriptorium","scrubber","scrub_brush, scrubbing_brush, scrubber","scrub_plane","scuffer","scuffle, scuffle_hoe, dutch_hoe","scull","scull","scullery","sculpture","scuttle, coal_scuttle","scyphus","scythe","seabag","sea_boat","sea_chest","sealing_wax, seal","sealskin","seam","seaplane, hydroplane","searchlight","searing_iron","seat","seat","seat","seat_belt, seatbelt","secateurs","secondary_coil, secondary_winding, secondary","second_balcony, family_circle, upper_balcony, peanut_gallery","second_base","second_hand","secretary, writing_table, escritoire, secretaire","sectional","security_blanket","security_system, security_measure, security","security_system","sedan, saloon","sedan, sedan_chair","seeder","seeker","seersucker","segmental_arch","segway, segway_human_transporter, segway_ht","seidel","seine","seismograph","selector, selector_switch","selenium_cell","self-propelled_vehicle","self-registering_thermometer","self-starter","selsyn, synchro","selvage, selvedge","semaphore","semiautomatic_firearm","semiautomatic_pistol, semiautomatic","semiconductor_device, semiconductor_unit, semiconductor","semi-detached_house","semigloss","semitrailer, semi","sennit","sensitometer","sentry_box","separate","septic_tank","sequence, episode","sequencer, sequenator","serape, sarape","serge","serger","serial_port","serpent","serration","server","server, host","service_club","serving_cart","serving_dish","servo, servomechanism, servosystem","set","set_gun, spring_gun","setscrew","setscrew","set_square","settee","settle, settee","settlement_house","seventy-eight, 78","seven_wonders_of_the_ancient_world, seven_wonders_of_the_world","sewage_disposal_plant, disposal_plant","sewer, sewerage, cloaca","sewing_basket","sewing_kit","sewing_machine","sewing_needle","sewing_room","sextant","sgraffito","shackle, bond, hamper, trammel","shackle","shade","shadow_box","shaft","shag_rug","shaker","shank","shank, stem","shantung","shaper, shaping_machine","shaping_tool","sharkskin","sharpener","sharpie","shaver, electric_shaver, electric_razor","shaving_brush","shaving_cream, shaving_soap","shaving_foam","shawl","shawm","shears","sheath","sheathing, overlay, overlayer","shed","sheep_bell","sheepshank","sheepskin_coat, afghan","sheepwalk, sheeprun","sheet, bed_sheet","sheet_bend, becket_bend, weaver's_knot, weaver's_hitch","sheeting","sheet_pile, sheath_pile, sheet_piling","sheetrock","shelf","shelf_bracket","shell","shell, case, casing","shell, racing_shell","shellac, shellac_varnish","shelter","shelter","shelter","sheltered_workshop","sheraton","shield, buckler","shield","shielding","shift_key, shift","shillelagh, shillalah","shim","shingle","shin_guard, shinpad","ship","shipboard_system","shipping, cargo_ships, merchant_marine, merchant_vessels","shipping_room","ship-towed_long-range_acoustic_detection_system","shipwreck","shirt","shirt_button","shirtdress","shirtfront","shirting","shirtsleeve","shirttail","shirtwaist, shirtwaister","shiv","shock_absorber, shock, cushion","shoe","shoe","shoebox","shoehorn","shoe_shop, shoe-shop, shoe_store","shoetree","shofar, shophar","shoji","shooting_brake","shooting_lodge, shooting_box","shooting_stick","shop, store","shop_bell","shopping_bag","shopping_basket","shopping_cart","short_circuit, short","short_iron","short_pants, shorts, trunks","short_sleeve","shortwave_diathermy_machine","shot","shot_glass, jigger, pony","shotgun, scattergun","shotgun_shell","shot_tower","shoulder","shoulder_bag","shouldered_arch","shoulder_holster","shoulder_pad","shoulder_patch","shovel","shovel","shovel_hat","showboat","shower","shower_cap","shower_curtain","shower_room","shower_stall, shower_bath","showroom, salesroom, saleroom","shrapnel","shredder","shrimper","shrine","shrink-wrap","shunt","shunt, electrical_shunt, bypass","shunter","shutter","shutter","shuttle","shuttle","shuttle_bus","shuttlecock, bird, birdie, shuttle","shuttle_helicopter","sibley_tent","sickbay, sick_berth","sickbed","sickle, reaping_hook, reap_hook","sickroom","sideboard","sidecar","side_chapel","sidelight, running_light","sidesaddle","sidewalk, pavement","sidewall","side-wheeler","sidewinder","sieve, screen","sifter","sights","sigmoidoscope, flexible_sigmoidoscope","signal_box, signal_tower","signaling_device","signboard, sign","silencer, muffler","silent_butler","silex","silk","silks","silo","silver_plate","silverpoint","simple_pendulum","simulator","single_bed","single-breasted_jacket","single-breasted_suit","single_prop, single-propeller_plane","single-reed_instrument, single-reed_woodwind","single-rotor_helicopter","singlestick, fencing_stick, backsword","singlet, vest, undershirt","siren","sister_ship","sitar","sitz_bath, hip_bath","six-pack, six_pack, sixpack","skate","skateboard","skeg","skein","skeleton, skeletal_frame, frame, underframe","skeleton_key","skep","skep","sketch, study","sketcher","skew_arch","skewer","ski","ski_binding, binding","skibob","ski_boot","ski_cap, stocking_cap, toboggan_cap","skidder","skid_lid","skiff","ski_jump","ski_lodge","ski_mask","skimmer","ski_parka, ski_jacket","ski-plane","ski_pole","ski_rack","skirt","skirt","ski_tow, ski_lift, lift","skivvies","skullcap","skybox","skyhook","skylight, fanlight","skysail","skyscraper","skywalk","slacks","slack_suit","slasher","slash_pocket","slat, spline","slate","slate_pencil","slate_roof","sled, sledge, sleigh","sleeper","sleeper","sleeping_bag","sleeping_car, sleeper, wagon-lit","sleeve, arm","sleeve","sleigh_bed","sleigh_bell, cascabel","slice_bar","slicer","slicer","slide, playground_slide, sliding_board","slide_fastener, zip, zipper, zip_fastener","slide_projector","slide_rule, slipstick","slide_valve","sliding_door","sliding_seat","sliding_window","sling, scarf_bandage, triangular_bandage","sling","slingback, sling","slinger_ring","slip_clutch, slip_friction_clutch","slipcover","slip-joint_pliers","slipknot","slip-on","slipper, carpet_slipper","slip_ring","slit_lamp","slit_trench","sloop","sloop_of_war","slop_basin, slop_bowl","slop_pail, slop_jar","slops","slopshop, slopseller's_shop","slot, one-armed_bandit","slot_machine, coin_machine","sluice, sluiceway, penstock","smack","small_boat","small_computer_system_interface, scsi","small_ship","small_stores","smart_bomb","smelling_bottle","smocking","smoke_bomb, smoke_grenade","smokehouse, meat_house","smoker, smoking_car, smoking_carriage, smoking_compartment","smoke_screen, smokescreen","smoking_room","smoothbore","smooth_plane, smoothing_plane","snack_bar, snack_counter, buffet","snaffle, snaffle_bit","snap, snap_fastener, press_stud","snap_brim","snap-brim_hat","snare, gin, noose","snare_drum, snare, side_drum","snatch_block","snifter, brandy_snifter, brandy_glass","sniper_rifle, precision_rifle","snips, tinsnips","sno-cat","snood","snorkel, schnorkel, schnorchel, snorkel_breather, breather","snorkel","snowbank, snow_bank","snowboard","snowmobile","snowplow, snowplough","snowshoe","snowsuit","snow_thrower, snow_blower","snuffbox","snuffer","snuffers","soapbox","soap_dish","soap_dispenser","soap_pad","soccer_ball","sock","socket","socket_wrench","socle","soda_can","soda_fountain","soda_fountain","sod_house, soddy, adobe_house","sodium-vapor_lamp, sodium-vapour_lamp","sofa, couch, lounge","soffit","softball, playground_ball","soft_pedal","soil_pipe","solar_array, solar_battery, solar_panel","solar_cell, photovoltaic_cell","solar_dish, solar_collector, solar_furnace","solar_heater","solar_house","solar_telescope","solar_thermal_system","soldering_iron","solenoid","solleret, sabaton","sombrero","sonic_depth_finder, fathometer","sonogram, echogram","sonograph","sorter","souk","sound_bow","soundbox, body","sound_camera","sounder","sound_film","sounding_board, soundboard","sounding_rocket","sound_recording, audio_recording, audio","sound_spectrograph","soup_bowl","soup_ladle","soupspoon, soup_spoon","source_of_illumination","sourdine","soutache","soutane","sou'wester","soybean_future","space_bar","space_capsule, capsule","spacecraft, ballistic_capsule, space_vehicle","space_heater","space_helmet","space_rocket","space_shuttle","space_station, space_platform, space_laboratory","spacesuit","spade","spade_bit","spaghetti_junction","spandau","spandex","spandrel, spandril","spanker","spar","sparge_pipe","spark_arrester, sparker","spark_arrester","spark_chamber, spark_counter","spark_coil","spark_gap","spark_lever","spark_plug, sparking_plug, plug","sparkplug_wrench","spark_transmitter","spat, gaiter","spatula","spatula","speakerphone","speaking_trumpet","spear, lance, shaft","spear, gig, fizgig, fishgig, lance","specialty_store","specimen_bottle","spectacle","spectacles, specs, eyeglasses, glasses","spectator_pump, spectator","spectrograph","spectrophotometer","spectroscope, prism_spectroscope","speculum","speedboat","speed_bump","speedometer, speed_indicator","speed_skate, racing_skate","spherometer","sphygmomanometer","spicemill","spice_rack","spider","spider_web, spider's_web","spike","spike","spindle","spindle, mandrel, mandril, arbor","spindle","spin_dryer, spin_drier","spinet","spinet","spinnaker","spinner","spinning_frame","spinning_jenny","spinning_machine","spinning_rod","spinning_wheel","spiral_bandage","spiral_ratchet_screwdriver, ratchet_screwdriver","spiral_spring","spirit_lamp","spirit_stove","spirometer","spit","spittoon, cuspidor","splashboard, splasher, dashboard","splasher","splice, splicing","splicer","splint","split_rail, fence_rail","spode","spoiler","spoiler","spoke, wheel_spoke, radius","spokeshave","sponge_cloth","sponge_mop","spoon","spoon","spork","sporran","sport_kite, stunt_kite","sports_car, sport_car","sports_equipment","sports_implement","sportswear, athletic_wear, activewear","sport_utility, sport_utility_vehicle, s.u.v., suv","spot","spotlight, spot","spot_weld, spot-weld","spouter","sprag","spray_gun","spray_paint","spreader","sprig","spring","spring_balance, spring_scale","springboard","sprinkler","sprinkler_system","sprit","spritsail","sprocket, sprocket_wheel","sprocket","spun_yarn","spur, gad","spur_gear, spur_wheel","sputnik","spy_satellite","squad_room","square","square_knot","square-rigger","square_sail","squash_ball","squash_racket, squash_racquet, bat","squawk_box, squawker, intercom_speaker","squeegee","squeezer","squelch_circuit, squelch, squelcher","squinch","stabilizer, stabiliser","stabilizer","stabilizer_bar, anti-sway_bar","stable, stalls, horse_barn","stable_gear, saddlery, tack","stabling","stacks","staddle","stadium, bowl, arena, sports_stadium","stage","stagecoach, stage","stained-glass_window","stair-carpet","stair-rod","stairwell","stake","stall, stand, sales_booth","stall","stamp","stamp_mill, stamping_mill","stamping_machine, stamper","stanchion","stand","standard","standard_cell","standard_transmission, stick_shift","standing_press","stanhope","stanley_steamer","staple","staple","staple_gun, staplegun, tacker","stapler, stapling_machine","starship, spaceship","starter, starter_motor, starting_motor","starting_gate, starting_stall","stassano_furnace, electric-arc_furnace","statehouse","stately_home","state_prison","stateroom","static_tube","station","stator, stator_coil","statue","stay","staysail","steakhouse, chophouse","steak_knife","stealth_aircraft","stealth_bomber","stealth_fighter","steam_bath, steam_room, vapor_bath, vapour_bath","steamboat","steam_chest","steam_engine","steamer, steamship","steamer","steam_iron","steam_locomotive","steamroller, road_roller","steam_shovel","steam_turbine","steam_whistle","steel","steel_arch_bridge","steel_drum","steel_mill, steelworks, steel_plant, steel_factory","steel-wool_pad","steelyard, lever_scale, beam_scale","steeple, spire","steerage","steering_gear","steering_linkage","steering_system, steering_mechanism","steering_wheel, wheel","stele, stela","stem-winder","stencil","sten_gun","stenograph","step, stair","step-down_transformer","step_stool","step-up_transformer","stereo, stereophony, stereo_system, stereophonic_system","stereoscope","stern_chaser","sternpost","sternwheeler","stethoscope","stewing_pan, stewpan","stick","stick","stick, control_stick, joystick","stick","stile","stiletto","still","stillroom, still_room","stillson_wrench","stilt","stinger","stink_bomb, stench_bomb","stirrer","stirrup, stirrup_iron","stirrup_pump","stob","stock, gunstock","stockade","stockcar","stock_car","stockinet, stockinette","stocking","stock-in-trade","stockpot","stockroom, stock_room","stocks","stock_saddle, western_saddle","stockyard","stole","stomacher","stomach_pump","stone_wall","stoneware","stonework","stool","stoop, stoep","stop_bath, short-stop, short-stop_bath","stopcock, cock, turncock","stopper_knot","stopwatch, stop_watch","storage_battery, accumulator","storage_cell, secondary_cell","storage_ring","storage_space","storeroom, storage_room, stowage","storm_cellar, cyclone_cellar, tornado_cellar","storm_door","storm_window, storm_sash","stoup, stoop","stoup","stove","stove, kitchen_stove, range, kitchen_range, cooking_stove","stove_bolt","stovepipe","stovepipe_iron","stradavarius, strad","straight_chair, side_chair","straightedge","straightener","straight_flute, straight-fluted_drill","straight_pin","straight_razor","strainer","straitjacket, straightjacket","strap","strap","strap_hinge, joint_hinge","strapless","streamer_fly","streamliner","street","street","streetcar, tram, tramcar, trolley, trolley_car","street_clothes","streetlight, street_lamp","stretcher","stretcher","stretch_pants","strickle","strickle","stringed_instrument","stringer","stringer","string_tie","strip","strip_lighting","strip_mall","stroboscope, strobe, strobe_light","strongbox, deedbox","stronghold, fastness","strongroom","strop","structural_member","structure, construction","student_center","student_lamp","student_union","stud_finder","studio_apartment, studio","studio_couch, day_bed","study","study_hall","stuffing_nut, packing_nut","stump","stun_gun, stun_baton","stupa, tope","sty, pigsty, pigpen","stylus, style","stylus","sub-assembly","subcompact, subcompact_car","submachine_gun","submarine, pigboat, sub, u-boat","submarine_torpedo","submersible, submersible_warship","submersible","subtracter","subway_token","subway_train","subwoofer","suction_cup","suction_pump","sudatorium, sudatory","suede_cloth, suede","sugar_bowl","sugar_refinery","sugar_spoon, sugar_shell","suit, suit_of_clothes","suite, rooms","suiting","sulky","summer_house","sumo_ring","sump","sump_pump","sunbonnet","sunday_best, sunday_clothes","sun_deck","sundial","sundress","sundries","sun_gear","sunglass","sunglasses, dark_glasses, shades","sunhat, sun_hat","sunlamp, sun_lamp, sunray_lamp, sun-ray_lamp","sun_parlor, sun_parlour, sun_porch, sunporch, sunroom, sun_lounge, solarium","sunroof, sunshine-roof","sunscreen, sunblock, sun_blocker","sunsuit","supercharger","supercomputer","superconducting_supercollider","superhighway, information_superhighway","supermarket","superstructure","supertanker","supper_club","supplejack","supply_chamber","supply_closet","support","support","support_column","support_hose, support_stocking","supporting_structure","supporting_tower","surcoat","surface_gauge, surface_gage, scribing_block","surface_lift","surface_search_radar","surface_ship","surface-to-air_missile, sam","surface-to-air_missile_system","surfboat","surcoat","surgeon's_knot","surgery","surge_suppressor, surge_protector, spike_suppressor, spike_arrester, lightning_arrester","surgical_dressing","surgical_instrument","surgical_knife","surplice","surrey","surtout","surveillance_system","surveying_instrument, surveyor's_instrument","surveyor's_level","sushi_bar","suspension, suspension_system","suspension_bridge","suspensory, suspensory_bandage","sustaining_pedal, loud_pedal","suture, surgical_seam","swab, swob, mop","swab","swaddling_clothes, swaddling_bands","swag","swage_block","swagger_stick","swallow-tailed_coat, swallowtail, morning_coat","swamp_buggy, marsh_buggy","swan's_down","swathe, wrapping","swatter, flyswatter, flyswat","sweat_bag","sweatband","sweater, jumper","sweat_pants, sweatpants","sweatshirt","sweatshop","sweat_suit, sweatsuit, sweats, workout_suit","sweep, sweep_oar","sweep_hand, sweep-second","swimming_trunks, bathing_trunks","swimsuit, swimwear, bathing_suit, swimming_costume, bathing_costume","swing","swing_door, swinging_door","switch, electric_switch, electrical_switch","switchblade, switchblade_knife, flick-knife, flick_knife","switch_engine, donkey_engine","swivel","swivel_chair","swizzle_stick","sword, blade, brand, steel","sword_cane, sword_stick","s_wrench","synagogue, temple, tabernacle","synchrocyclotron","synchroflash","synchromesh","synchronous_converter, rotary, rotary_converter","synchronous_motor","synchrotron","synchroscope, synchronoscope, synchronizer, synchroniser","synthesizer, synthesiser","syringe","system","tabard","tabernacle","tabi, tabis","tab_key, tab","table","table","tablefork","table_knife","table_lamp","table_saw","tablespoon","tablet-armed_chair","table-tennis_table, ping-pong_table, pingpong_table","table-tennis_racquet, table-tennis_bat, pingpong_paddle","tabletop","tableware","tabor, tabour","taboret, tabouret","tachistoscope, t-scope","tachograph","tachometer, tach","tachymeter, tacheometer","tack","tack_hammer","taffeta","taffrail","tailgate, tailboard","taillight, tail_lamp, rear_light, rear_lamp","tailor-made","tailor's_chalk","tailpipe","tail_rotor, anti-torque_rotor","tailstock","take-up","talaria","talcum, talcum_powder","tam, tam-o'-shanter, tammy","tambour","tambour, embroidery_frame, embroidery_hoop","tambourine","tammy","tamp, tamper, tamping_bar","tampax","tampion, tompion","tampon","tandoor","tangram","tank, storage_tank","tank, army_tank, armored_combat_vehicle, armoured_combat_vehicle","tankard","tank_car, tank","tank_destroyer","tank_engine, tank_locomotive","tanker_plane","tank_shell","tank_top","tannoy","tap, spigot","tapa, tappa","tape, tape_recording, taping","tape, tapeline, tape_measure","tape_deck","tape_drive, tape_transport, transport","tape_player","tape_recorder, tape_machine","taper_file","tapestry, tapis","tappet","tap_wrench","tare","target, butt","target_acquisition_system","tarmacadam, tarmac, macadam","tarpaulin, tarp","tartan, plaid","tasset, tasse","tattoo","tavern, tap_house","tawse","taximeter","t-bar_lift, t-bar, alpine_lift","tea_bag","tea_ball","tea_cart, teacart, tea_trolley, tea_wagon","tea_chest","teaching_aid","teacup","tea_gown","teakettle","tea_maker","teapot","teashop, teahouse, tearoom, tea_parlor, tea_parlour","teaspoon","tea-strainer","tea_table","tea_tray","tea_urn","tee, golf_tee","tee_hinge, t_hinge","telecom_hotel, telco_building","telecommunication_system, telecom_system, telecommunication_equipment, telecom_equipment","telegraph, telegraphy","telegraph_key","telemeter","telephone, phone, telephone_set","telephone_bell","telephone_booth, phone_booth, call_box, telephone_box, telephone_kiosk","telephone_cord, phone_cord","telephone_jack, phone_jack","telephone_line, phone_line, telephone_circuit, subscriber_line, line","telephone_plug, phone_plug","telephone_pole, telegraph_pole, telegraph_post","telephone_receiver, receiver","telephone_system, phone_system","telephone_wire, telephone_line, telegraph_wire, telegraph_line","telephoto_lens, zoom_lens","teleprompter","telescope, scope","telescopic_sight, telescope_sight","telethermometer","teletypewriter, teleprinter, teletype_machine, telex, telex_machine","television, television_system","television_antenna, tv-antenna","television_camera, tv_camera, camera","television_equipment, video_equipment","television_monitor, tv_monitor","television_receiver, television, television_set, tv, tv_set, idiot_box, boob_tube, telly, goggle_box","television_room, tv_room","television_transmitter","telpher, telfer","telpherage, telferage","tempera, poster_paint, poster_color, poster_colour","temple","temple","temporary_hookup, patch","tender, supply_ship","tender, ship's_boat, pinnace, cutter","tender","tenement, tenement_house","tennis_ball","tennis_camp","tennis_racket, tennis_racquet","tenon","tenor_drum, tom-tom","tenoroon","tenpenny_nail","tenpin","tensimeter","tensiometer","tensiometer","tensiometer","tent, collapsible_shelter","tenter","tenterhook","tent-fly, rainfly, fly_sheet, fly, tent_flap","tent_peg","tepee, tipi, teepee","terminal, pole","terminal","terraced_house","terra_cotta","terrarium","terra_sigillata, samian_ware","terry, terry_cloth, terrycloth","tesla_coil","tessera","test_equipment","test_rocket, research_rocket, test_instrument_vehicle","test_room, testing_room","testudo","tetraskelion, tetraskele","tetrode","textile_machine","textile_mill","thatch, thatched_roof","theater, theatre, house","theater_curtain, theatre_curtain","theater_light","theodolite, transit","theremin","thermal_printer","thermal_reactor","thermocouple, thermocouple_junction","thermoelectric_thermometer, thermel, electric_thermometer","thermograph, thermometrograph","thermograph","thermohydrometer, thermogravimeter","thermojunction","thermometer","thermonuclear_reactor, fusion_reactor","thermopile","thermos, thermos_bottle, thermos_flask","thermostat, thermoregulator","thigh_pad","thill","thimble","thinning_shears","third_base, third","third_gear, third","third_rail","thong","thong","three-centered_arch, basket-handle_arch","three-decker","three-dimensional_radar, 3d_radar","three-piece_suit","three-quarter_binding","three-way_switch, three-point_switch","thresher, thrasher, threshing_machine","threshing_floor","thriftshop, second-hand_store","throat_protector","throne","thrust_bearing","thruster","thumb","thumbhole","thumbscrew","thumbstall","thumbtack, drawing_pin, pushpin","thunderer","thwart, cross_thwart","tiara","ticking","tickler_coil","tie, tie_beam","tie, railroad_tie, crosstie, sleeper","tie_rack","tie_rod","tights, leotards","tile","tile_cutter","tile_roof","tiller","tilter","tilt-top_table, tip-top_table, tip_table","timber","timber","timber_hitch","timbrel","time_bomb, infernal_machine","time_capsule","time_clock","time-delay_measuring_instrument, time-delay_measuring_system","time-fuse","timepiece, timekeeper, horologe","timer","timer","time-switch","tin","tinderbox","tine","tinfoil, tin_foil","tippet","tire_chain, snow_chain","tire_iron, tire_tool","titfer","tithe_barn","titrator","toaster","toaster_oven","toasting_fork","toastrack","tobacco_pouch","tobacco_shop, tobacconist_shop, tobacconist","toboggan","toby, toby_jug, toby_fillpot_jug","tocsin, warning_bell","toe","toecap","toehold","toga","toga_virilis","toggle","toggle_bolt","toggle_joint","toggle_switch, toggle, on-off_switch, on/off_switch","togs, threads, duds","toilet, lavatory, lav, can, john, privy, bathroom","toilet_bag, sponge_bag","toilet_bowl","toilet_kit, travel_kit","toilet_powder, bath_powder, dusting_powder","toiletry, toilet_articles","toilet_seat","toilet_water, eau_de_toilette","tokamak","token","tollbooth, tolbooth, tollhouse","toll_bridge","tollgate, tollbar","toll_line","tomahawk, hatchet","tommy_gun, thompson_submachine_gun","tomograph","tone_arm, pickup, pickup_arm","toner","tongs, pair_of_tongs","tongue","tongue_and_groove_joint","tongue_depressor","tonometer","tool","tool_bag","toolbox, tool_chest, tool_cabinet, tool_case","toolshed, toolhouse","tooth","tooth","toothbrush","toothpick","top","top, cover","topgallant, topgallant_mast","topgallant, topgallant_sail","topiary","topknot","topmast","topper","topsail","toque","torch","torpedo","torpedo","torpedo","torpedo_boat","torpedo-boat_destroyer","torpedo_tube","torque_converter","torque_wrench","torture_chamber","totem_pole","touch_screen, touchscreen","toupee, toupe","touring_car, phaeton, tourer","tourist_class, third_class","towel","toweling, towelling","towel_rack, towel_horse","towel_rail, towel_bar","tower","town_hall","towpath, towing_path","tow_truck, tow_car, wrecker","toy","toy_box, toy_chest","toyshop","trace_detector","track, rail, rails, runway","track","trackball","tracked_vehicle","tract_house","tract_housing","traction_engine","tractor","tractor","trail_bike, dirt_bike, scrambler","trailer, house_trailer","trailer","trailer_camp, trailer_park","trailer_truck, tractor_trailer, trucking_rig, rig, articulated_lorry, semi","trailing_edge","train, railroad_train","tramline, tramway, streetcar_track","trammel","trampoline","tramp_steamer, tramp","tramway, tram, aerial_tramway, cable_tramway, ropeway","transdermal_patch, skin_patch","transept","transformer","transistor, junction_transistor, electronic_transistor","transit_instrument","transmission, transmission_system","transmission_shaft","transmitter, sender","transom, traverse","transom, transom_window, fanlight","transponder","transporter","transporter, car_transporter","transport_ship","trap","trap_door","trapeze","trave, traverse, crossbeam, crosspiece","travel_iron","trawl, dragnet, trawl_net","trawl, trawl_line, spiller, setline, trotline","trawler, dragger","tray","tray_cloth","tread","tread","treadmill, treadwheel, tread-wheel","treadmill","treasure_chest","treasure_ship","treenail, trenail, trunnel","trefoil_arch","trellis, treillage","trench","trench_coat","trench_knife","trepan","trepan, trephine","trestle","trestle","trestle_bridge","trestle_table","trestlework","trews","trial_balloon","triangle","triangle","triclinium","triclinium","tricorn, tricorne","tricot","tricycle, trike, velocipede","trident","trigger","trimaran","trimmer","trimmer_arch","triode","tripod","triptych","trip_wire","trireme","triskelion, triskele","triumphal_arch","trivet","trivet","troika","troll","trolleybus, trolley_coach, trackless_trolley","trombone","troop_carrier, troop_transport","troopship","trophy_case","trough","trouser","trouser_cuff","trouser_press, pants_presser","trouser, pant","trousseau","trowel","truck, motortruck","trumpet_arch","truncheon, nightstick, baton, billy, billystick, billy_club","trundle_bed, trundle, truckle_bed, truckle","trunk","trunk_hose","trunk_lid","trunk_line","truss","truss_bridge","try_square","t-square","tub, vat","tube, vacuum_tube, thermionic_vacuum_tube, thermionic_tube, electron_tube, thermionic_valve","tuck_box","tucker","tucker-bag","tuck_shop","tudor_arch, four-centered_arch","tudung","tugboat, tug, towboat, tower","tulle","tumble-dryer, tumble_drier","tumbler","tumbrel, tumbril","tun","tunic","tuning_fork","tupik, tupek, sealskin_tent","turban","turbine","turbogenerator","tureen","turkish_bath","turkish_towel, terry_towel","turk's_head","turnbuckle","turner, food_turner","turnery","turnpike","turnspit","turnstile","turntable","turntable, lazy_susan","turret","turret_clock","turtleneck, turtle, polo-neck","tweed","tweeter","twenty-two, .22","twenty-two_pistol","twenty-two_rifle","twill","twill, twill_weave","twin_bed","twinjet","twist_bit, twist_drill","two-by-four","two-man_tent","two-piece, two-piece_suit, lounge_suit","typesetting_machine","typewriter","typewriter_carriage","typewriter_keyboard","tyrolean, tirolean","uke, ukulele","ulster","ultracentrifuge","ultramicroscope, dark-field_microscope","ultrasuede","ultraviolet_lamp, ultraviolet_source","umbrella","umbrella_tent","undercarriage","undercoat, underseal","undergarment, unmentionable","underpants","underwear, underclothes, underclothing","undies","uneven_parallel_bars, uneven_bars","unicycle, monocycle","uniform","universal_joint, universal","university","upholstery","upholstery_material","upholstery_needle","uplift","upper_berth, upper","upright, upright_piano","upset, swage","upstairs","urceole","urn","urn","used-car, secondhand_car","utensil","uzi","vacation_home","vacuum, vacuum_cleaner","vacuum_chamber","vacuum_flask, vacuum_bottle","vacuum_gauge, vacuum_gage","valenciennes, valenciennes_lace","valise","valve","valve","valve-in-head_engine","vambrace, lower_cannon","van","van, caravan","vane","vaporizer, vaporiser","variable-pitch_propeller","variometer","varnish","vase","vault","vault, bank_vault","vaulting_horse, long_horse, buck","vehicle","velcro","velocipede","velour, velours","velvet","velveteen","vending_machine","veneer, veneering","venetian_blind","venn_diagram, venn's_diagram","ventilation, ventilation_system, ventilating_system","ventilation_shaft","ventilator","veranda, verandah, gallery","verdigris","vernier_caliper, vernier_micrometer","vernier_scale, vernier","vertical_file","vertical_stabilizer, vertical_stabiliser, vertical_fin, tail_fin, tailfin","vertical_tail","very_pistol, verey_pistol","vessel, watercraft","vessel","vest, waistcoat","vestiture","vestment","vest_pocket","vestry, sacristy","viaduct","vibraphone, vibraharp, vibes","vibrator","vibrator","victrola","vicuna","videocassette","videocassette_recorder, vcr","videodisk, videodisc, dvd","video_recording, video","videotape","videotape","vigil_light, vigil_candle","villa","villa","villa","viol","viola","viola_da_braccio","viola_da_gamba, gamba, bass_viol","viola_d'amore","violin, fiddle","virginal, pair_of_virginals","viscometer, viscosimeter","viscose_rayon, viscose","vise, bench_vise","visor, vizor","visual_display_unit, vdu","vivarium","viyella","voile","volleyball","volleyball_net","voltage_regulator","voltaic_cell, galvanic_cell, primary_cell","voltaic_pile, pile, galvanic_pile","voltmeter","vomitory","von_neumann_machine","voting_booth","voting_machine","voussoir","vox_angelica, voix_celeste","vox_humana","waders","wading_pool","waffle_iron","wagon, waggon","wagon, coaster_wagon","wagon_tire","wagon_wheel","wain","wainscot, wainscoting, wainscotting","wainscoting, wainscotting","waist_pack, belt_bag","walker, baby-walker, go-cart","walker, zimmer, zimmer_frame","walker","walkie-talkie, walky-talky","walk-in","walking_shoe","walking_stick","walkman","walk-up_apartment, walk-up","wall","wall","wall_clock","wallet, billfold, notecase, pocketbook","wall_tent","wall_unit","wand","wankel_engine, wankel_rotary_engine, epitrochoidal_engine","ward, hospital_ward","wardrobe, closet, press","wardroom","warehouse, storage_warehouse","warming_pan","war_paint","warplane, military_plane","war_room","warship, war_vessel, combat_ship","wash","wash-and-wear","washbasin, handbasin, washbowl, lavabo, wash-hand_basin","washboard, splashboard","washboard","washer, automatic_washer, washing_machine","washer","washhouse","washroom","washstand, wash-hand_stand","washtub","wastepaper_basket, waste-paper_basket, wastebasket, waste_basket, circular_file","watch, ticker","watch_cap","watch_case","watch_glass","watchtower","water-base_paint","water_bed","water_bottle","water_butt","water_cart","water_chute","water_closet, closet, w.c., loo","watercolor, water-color, watercolour, water-colour","water-cooled_reactor","water_cooler","water_faucet, water_tap, tap, hydrant","water_filter","water_gauge, water_gage, water_glass","water_glass","water_hazard","water_heater, hot-water_heater, hot-water_tank","watering_can, watering_pot","watering_cart","water_jacket","water_jug","water_jump","water_level","water_meter","water_mill","waterproof","waterproofing","water_pump","water_scooter, sea_scooter, scooter","water_ski","waterspout","water_tower","water_wagon, water_waggon","waterwheel, water_wheel","waterwheel, water_wheel","water_wings","waterworks","wattmeter","waxwork, wax_figure","ways, shipway, slipway","weapon, arm, weapon_system","weaponry, arms, implements_of_war, weapons_system, munition","weapons_carrier","weathercock","weatherglass","weather_satellite, meteorological_satellite","weather_ship","weathervane, weather_vane, vane, wind_vane","web, entanglement","web","webbing","webcam","wedge","wedge","wedgie","wedgwood","weeder, weed-whacker","weeds, widow's_weeds","weekender","weighbridge","weight, free_weight, exercising_weight","weir","weir","welcome_wagon","weld","welder's_mask","weldment","well","wellhead","welt","weston_cell, cadmium_cell","wet_bar","wet-bulb_thermometer","wet_cell","wet_fly","wet_suit","whaleboat","whaler, whaling_ship","whaling_gun","wheel","wheel","wheel_and_axle","wheelchair","wheeled_vehicle","wheelwork","wherry","wherry, norfolk_wherry","whetstone","whiffletree, whippletree, swingletree","whip","whipcord","whipping_post","whipstitch, whipping, whipstitching","whirler","whisk, whisk_broom","whisk","whiskey_bottle","whiskey_jug","whispering_gallery, whispering_dome","whistle","whistle","white","white_goods","whitewash","whorehouse, brothel, bordello, bagnio, house_of_prostitution, house_of_ill_repute, bawdyhouse, cathouse, sporting_house","wick, taper","wicker, wickerwork, caning","wicker_basket","wicket, hoop","wicket","wickiup, wikiup","wide-angle_lens, fisheye_lens","widebody_aircraft, wide-body_aircraft, wide-body, twin-aisle_airplane","wide_wale","widow's_walk","wiffle, wiffle_ball","wig","wigwam","wilton, wilton_carpet","wimple","wincey","winceyette","winch, windlass","winchester","windbreak, shelterbelt","winder, key","wind_instrument, wind","windjammer","windmill, aerogenerator, wind_generator","windmill","window","window","window_blind","window_box","window_envelope","window_frame","window_screen","window_seat","window_shade","windowsill","windshield, windscreen","windshield_wiper, windscreen_wiper, wiper, wiper_blade","windsor_chair","windsor_knot","windsor_tie","wind_tee","wind_tunnel","wind_turbine","wine_bar","wine_bottle","wine_bucket, wine_cooler","wine_cask, wine_barrel","wineglass","winepress","winery, wine_maker","wineskin","wing","wing_chair","wing_nut, wing-nut, wing_screw, butterfly_nut, thumbnut","wing_tip","wing_tip","winker, blinker, blinder","wiper, wiper_arm, contact_arm","wiper_motor","wire","wire, conducting_wire","wire_cloth","wire_cutter","wire_gauge, wire_gage","wireless_local_area_network, wlan, wireless_fidelity, wifi","wire_matrix_printer, wire_printer, stylus_printer","wire_recorder","wire_stripper","wirework, grillwork","wiring","wishing_cap","witness_box, witness_stand","wok","woman's_clothing","wood","woodcarving","wood_chisel","woodenware","wooden_spoon","woodscrew","woodshed","wood_vise, woodworking_vise, shoulder_vise","woodwind, woodwind_instrument, wood","woof, weft, filling, pick","woofer","wool, woolen, woollen","workbasket, workbox, workbag","workbench, work_bench, bench","work-clothing, work-clothes","workhouse","workhouse","workpiece","workroom","works, workings","work-shirt","workstation","worktable, work_table","workwear","world_wide_web, www, web","worm_fence, snake_fence, snake-rail_fence, virginia_fence","worm_gear","worm_wheel","worsted","worsted, worsted_yarn","wrap, wrapper","wraparound","wrapping, wrap, wrapper","wreck","wrench, spanner","wrestling_mat","wringer","wrist_pad","wrist_pin, gudgeon_pin","wristwatch, wrist_watch","writing_arm","writing_desk","writing_desk","writing_implement","xerographic_printer","xerox, xerographic_copier, xerox_machine","x-ray_film","x-ray_machine","x-ray_tube","yacht, racing_yacht","yacht_chair","yagi, yagi_aerial","yard","yard","yardarm","yard_marker","yardstick, yard_measure","yarmulke, yarmulka, yarmelke","yashmak, yashmac","yataghan","yawl, dandy","yawl","yoke","yoke","yoke, coupling","yurt","zamboni","zero","ziggurat, zikkurat, zikurat","zill","zip_gun","zither, cither, zithern","zoot_suit","shading","grain","wood_grain, woodgrain, woodiness","graining, woodgraining","marbleization, marbleisation, marbleizing, marbleising","light, lightness","aura, aureole, halo, nimbus, glory, gloriole","sunniness","glint","opalescence, iridescence","polish, gloss, glossiness, burnish","primary_color_for_pigments, primary_colour_for_pigments","primary_color_for_light, primary_colour_for_light","colorlessness, colourlessness, achromatism, achromaticity","mottle","achromia","shade, tint, tincture, tone","chromatic_color, chromatic_colour, spectral_color, spectral_colour","black, blackness, inkiness","coal_black, ebony, jet_black, pitch_black, sable, soot_black","alabaster","bone, ivory, pearl, off-white","gray, grayness, grey, greyness","ash_grey, ash_gray, silver, silver_grey, silver_gray","charcoal, charcoal_grey, charcoal_gray, oxford_grey, oxford_gray","sanguine","turkey_red, alizarine_red","crimson, ruby, deep_red","dark_red","claret","fuschia","maroon","orange, orangeness","reddish_orange","yellow, yellowness","gamboge, lemon, lemon_yellow, maize","pale_yellow, straw, wheat","green, greenness, viridity","greenishness","sea_green","sage_green","bottle_green","emerald","olive_green, olive-green","jade_green, jade","blue, blueness","azure, cerulean, sapphire, lazuline, sky-blue","steel_blue","greenish_blue, aqua, aquamarine, turquoise, cobalt_blue, peacock_blue","purplish_blue, royal_blue","purple, purpleness","tyrian_purple","indigo","lavender","reddish_purple, royal_purple","pink","carnation","rose, rosiness","chestnut","chocolate, coffee, deep_brown, umber, burnt_umber","light_brown","tan, topaz","beige, ecru","reddish_brown, sepia, burnt_sienna, venetian_red, mahogany","brick_red","copper, copper_color","indian_red","puce","olive","ultramarine","complementary_color, complementary","pigmentation","complexion, skin_color, skin_colour","ruddiness, rosiness","nonsolid_color, nonsolid_colour, dithered_color, dithered_colour","aposematic_coloration, warning_coloration","cryptic_coloration","ring","center_of_curvature, centre_of_curvature","cadaver, corpse, stiff, clay, remains","mandibular_notch","rib","skin, tegument, cutis","skin_graft","epidermal_cell","melanocyte","prickle_cell","columnar_cell, columnar_epithelial_cell","spongioblast","squamous_cell","amyloid_plaque, amyloid_protein_plaque","dental_plaque, bacterial_plaque","macule, macula","freckle, lentigo","bouffant","sausage_curl","forelock","spit_curl, kiss_curl","pigtail","pageboy","pompadour","thatch","soup-strainer, toothbrush","mustachio, moustachio, handle-bars","walrus_mustache, walrus_moustache","stubble","vandyke_beard, vandyke","soul_patch, attilio","esophageal_smear","paraduodenal_smear, duodenal_smear","specimen","punctum","glenoid_fossa, glenoid_cavity","diastema","marrow, bone_marrow","mouth, oral_cavity, oral_fissure, rima_oris","canthus","milk","mother's_milk","colostrum, foremilk","vein, vena, venous_blood_vessel","ganglion_cell, gangliocyte","x_chromosome","embryonic_cell, formative_cell","myeloblast","sideroblast","osteocyte","megalocyte, macrocyte","leukocyte, leucocyte, white_blood_cell, white_cell, white_blood_corpuscle, white_corpuscle, wbc","histiocyte","fixed_phagocyte","lymphocyte, lymph_cell","monoblast","neutrophil, neutrophile","microphage","sickle_cell","siderocyte","spherocyte","ootid","oocyte","spermatid","leydig_cell, leydig's_cell","striated_muscle_cell, striated_muscle_fiber","smooth_muscle_cell","ranvier's_nodes, nodes_of_ranvier","neuroglia, glia","astrocyte","protoplasmic_astrocyte","oligodendrocyte","proprioceptor","dendrite","sensory_fiber, afferent_fiber","subarachnoid_space","cerebral_cortex, cerebral_mantle, pallium, cortex","renal_cortex","prepuce, foreskin","head, caput","scalp","frontal_eminence","suture, sutura, fibrous_joint","foramen_magnum","esophagogastric_junction, oesophagogastric_junction","heel","cuticle","hangnail, agnail","exoskeleton","abdominal_wall","lemon","coordinate_axis","landscape","medium","vehicle","paper","channel, transmission_channel","film, cinema, celluloid","silver_screen","free_press","press, public_press","print_media","storage_medium, data-storage_medium","magnetic_storage_medium, magnetic_medium, magnetic_storage","journalism, news_media","fleet_street","photojournalism","news_photography","rotogravure","newspaper, paper","daily","gazette","school_newspaper, school_paper","tabloid, rag, sheet","yellow_journalism, tabloid, tab","telecommunication, telecom","telephone, telephony","voice_mail, voicemail","call, phone_call, telephone_call","call-back","collect_call","call_forwarding","call-in","call_waiting","crank_call","local_call","long_distance, long-distance_call, trunk_call","toll_call","wake-up_call","three-way_calling","telegraphy","cable, cablegram, overseas_telegram","wireless","radiotelegraph, radiotelegraphy, wireless_telegraphy","radiotelephone, radiotelephony, wireless_telephone","broadcasting","rediffusion","multiplex","radio, radiocommunication, wireless","television, telecasting, tv, video","cable_television, cable","high-definition_television, hdtv","reception","signal_detection, detection","hakham","web_site, website, internet_site, site","chat_room, chatroom","portal_site, portal","jotter","breviary","wordbook","desk_dictionary, collegiate_dictionary","reckoner, ready_reckoner","document, written_document, papers","album, record_album","concept_album","rock_opera","tribute_album, benefit_album","magazine, mag","colour_supplement","comic_book","news_magazine","pulp, pulp_magazine","slick, slick_magazine, glossy","trade_magazine","movie, film, picture, moving_picture, moving-picture_show, motion_picture, motion-picture_show, picture_show, pic, flick","outtake","shoot-'em-up","spaghetti_western","encyclical, encyclical_letter","crossword_puzzle, crossword","sign","street_sign","traffic_light, traffic_signal, stoplight","swastika, hakenkreuz","concert","artwork, art, graphics, nontextual_matter","lobe","book_jacket, dust_cover, dust_jacket, dust_wrapper","cairn","three-day_event","comfort_food","comestible, edible, eatable, pabulum, victual, victuals","tuck","course","dainty, delicacy, goody, kickshaw, treat","dish","fast_food","finger_food","ingesta","kosher","fare","diet","diet","dietary","balanced_diet","bland_diet, ulcer_diet","clear_liquid_diet","diabetic_diet","dietary_supplement","carbohydrate_loading, carbo_loading","fad_diet","gluten-free_diet","high-protein_diet","high-vitamin_diet, vitamin-deficiency_diet","light_diet","liquid_diet","low-calorie_diet","low-fat_diet","low-sodium_diet, low-salt_diet, salt-free_diet","macrobiotic_diet","reducing_diet, obesity_diet","soft_diet, pap, spoon_food","vegetarianism","menu","chow, chuck, eats, grub","board, table","mess","ration","field_ration","k_ration","c-ration","foodstuff, food_product","starches","breadstuff","coloring, colouring, food_coloring, food_colouring, food_color, food_colour","concentrate","tomato_concentrate","meal","kibble","cornmeal, indian_meal","farina","matzo_meal, matzoh_meal, matzah_meal","oatmeal, rolled_oats","pea_flour","roughage, fiber","bran","flour","plain_flour","wheat_flour","whole_wheat_flour, graham_flour, graham, whole_meal_flour","soybean_meal, soybean_flour, soy_flour","semolina","corn_gluten_feed","nutriment, nourishment, nutrition, sustenance, aliment, alimentation, victuals","commissariat, provisions, provender, viands, victuals","larder","frozen_food, frozen_foods","canned_food, canned_foods, canned_goods, tinned_goods","canned_meat, tinned_meat","spam","dehydrated_food, dehydrated_foods","square_meal","meal, repast","potluck","refection","refreshment","breakfast","continental_breakfast, petit_dejeuner","brunch","lunch, luncheon, tiffin, dejeuner","business_lunch","high_tea","tea, afternoon_tea, teatime","dinner","supper","buffet","picnic","cookout","barbecue, barbeque","clambake","fish_fry","bite, collation, snack","nosh","nosh-up","ploughman's_lunch","coffee_break, tea_break","banquet, feast, spread","entree, main_course","piece_de_resistance","plate","adobo","side_dish, side_order, entremets","special","casserole","chicken_casserole","chicken_cacciatore, chicken_cacciatora, hunter's_chicken","antipasto","appetizer, appetiser, starter","canape","cocktail","fruit_cocktail","crab_cocktail","shrimp_cocktail","hors_d'oeuvre","relish","dip","bean_dip","cheese_dip","clam_dip","guacamole","soup","soup_du_jour","alphabet_soup","consomme","madrilene","bisque","borsch, borsh, borscht, borsht, borshch, bortsch","broth","barley_water","bouillon","beef_broth, beef_stock","chicken_broth, chicken_stock","broth, stock","stock_cube","chicken_soup","cock-a-leekie, cocky-leeky","gazpacho","gumbo","julienne","marmite","mock_turtle_soup","mulligatawny","oxtail_soup","pea_soup","pepper_pot, philadelphia_pepper_pot","petite_marmite, minestrone, vegetable_soup","potage, pottage","pottage","turtle_soup, green_turtle_soup","eggdrop_soup","chowder","corn_chowder","clam_chowder","manhattan_clam_chowder","new_england_clam_chowder","fish_chowder","won_ton, wonton, wonton_soup","split-pea_soup","green_pea_soup, potage_st._germain","lentil_soup","scotch_broth","vichyssoise","stew","bigos","brunswick_stew","burgoo","burgoo","olla_podrida, spanish_burgoo","mulligan_stew, mulligan, irish_burgoo","purloo, chicken_purloo, poilu","goulash, hungarian_goulash, gulyas","hotchpotch","hot_pot, hotpot","beef_goulash","pork-and-veal_goulash","porkholt","irish_stew","oyster_stew","lobster_stew","lobscouse, lobscuse, scouse","fish_stew","bouillabaisse","matelote","paella","fricassee","chicken_stew","turkey_stew","beef_stew","ragout","ratatouille","salmi","pot-au-feu","slumgullion","smorgasbord","viand","ready-mix","brownie_mix","cake_mix","lemonade_mix","self-rising_flour, self-raising_flour","choice_morsel, tidbit, titbit","savory, savoury","calf's-foot_jelly","caramel, caramelized_sugar","lump_sugar","cane_sugar","castor_sugar, caster_sugar","powdered_sugar","granulated_sugar","icing_sugar","corn_sugar","brown_sugar","demerara, demerara_sugar","sweet, confection","confectionery","confiture","sweetmeat","candy, confect","candy_bar","carob_bar","hardbake","hard_candy","barley-sugar, barley_candy","brandyball","jawbreaker","lemon_drop","sourball","patty","peppermint_patty","bonbon","brittle, toffee, toffy","peanut_brittle","chewing_gum, gum","gum_ball","bubble_gum","butterscotch","candied_fruit, succade, crystallized_fruit","candied_apple, candy_apple, taffy_apple, caramel_apple, toffee_apple","crystallized_ginger","grapefruit_peel","lemon_peel","orange_peel","candied_citrus_peel","candy_cane","candy_corn","caramel","center, centre","comfit","cotton_candy, spun_sugar, candyfloss","dragee","dragee","fondant","fudge","chocolate_fudge","divinity, divinity_fudge","penuche, penoche, panoche, panocha","gumdrop","jujube","honey_crisp","mint, mint_candy","horehound","peppermint, peppermint_candy","jelly_bean, jelly_egg","kiss, candy_kiss","molasses_kiss","meringue_kiss","chocolate_kiss","licorice, liquorice","life_saver","lollipop, sucker, all-day_sucker","lozenge","cachou","cough_drop, troche, pastille, pastil","marshmallow","marzipan, marchpane","nougat","nougat_bar","nut_bar","peanut_bar","popcorn_ball","praline","rock_candy","rock_candy, rock","sugar_candy","sugarplum","taffy","molasses_taffy","truffle, chocolate_truffle","turkish_delight","dessert, sweet, afters","ambrosia, nectar","ambrosia","baked_alaska","blancmange","charlotte","compote, fruit_compote","dumpling","flan","frozen_dessert","junket","mousse","mousse","pavlova","peach_melba","whip","prune_whip","pudding","pudding, pud","syllabub, sillabub","tiramisu","trifle","tipsy_cake","jello, jell-o","apple_dumpling","ice, frappe","water_ice, sorbet","ice_cream, icecream","ice-cream_cone","chocolate_ice_cream","neapolitan_ice_cream","peach_ice_cream","sherbert, sherbet","strawberry_ice_cream","tutti-frutti","vanilla_ice_cream","ice_lolly, lolly, lollipop, popsicle","ice_milk","frozen_yogurt","snowball","snowball","parfait","ice-cream_sundae, sundae","split","banana_split","frozen_pudding","frozen_custard, soft_ice_cream","pudding","flummery","fish_mousse","chicken_mousse","chocolate_mousse","plum_pudding, christmas_pudding","carrot_pudding","corn_pudding","steamed_pudding","duff, plum_duff","vanilla_pudding","chocolate_pudding","brown_betty","nesselrode, nesselrode_pudding","pease_pudding","custard","creme_caramel","creme_anglais","creme_brulee","fruit_custard","tapioca","tapioca_pudding","roly-poly, roly-poly_pudding","suet_pudding","bavarian_cream","maraschino, maraschino_cherry","nonpareil","zabaglione, sabayon","garnish","pastry, pastry_dough","turnover","apple_turnover","knish","pirogi, piroshki, pirozhki","samosa","timbale","puff_paste, pate_feuillete","phyllo","puff_batter, pouf_paste, pate_a_choux","ice-cream_cake, icebox_cake","doughnut, donut, sinker","fish_cake, fish_ball","fish_stick, fish_finger","conserve, preserve, conserves, preserves","apple_butter","chowchow","jam","lemon_curd, lemon_cheese","strawberry_jam, strawberry_preserves","jelly","apple_jelly","crabapple_jelly","grape_jelly","marmalade","orange_marmalade","gelatin, jelly","gelatin_dessert","buffalo_wing","barbecued_wing","mess","mince","puree","barbecue, barbeque","biryani, biriani","escalope_de_veau_orloff","saute","patty, cake","veal_parmesan, veal_parmigiana","veal_cordon_bleu","margarine, margarin, oleo, oleomargarine, marge","mincemeat","stuffing, dressing","turkey_stuffing","oyster_stuffing, oyster_dressing","forcemeat, farce","bread, breadstuff, staff_of_life","anadama_bread","bap","barmbrack","breadstick, bread-stick","grissino","brown_bread, boston_brown_bread","bun, roll","tea_bread","caraway_seed_bread","challah, hallah","cinnamon_bread","cracked-wheat_bread","cracker","crouton","dark_bread, whole_wheat_bread, whole_meal_bread, brown_bread","english_muffin","flatbread","garlic_bread","gluten_bread","graham_bread","host","flatbrod","bannock","chapatti, chapati","pita, pocket_bread","loaf_of_bread, loaf","french_loaf","matzo, matzoh, matzah, unleavened_bread","nan, naan","onion_bread","raisin_bread","quick_bread","banana_bread","date_bread","date-nut_bread","nut_bread","oatcake","irish_soda_bread","skillet_bread, fry_bread","rye_bread","black_bread, pumpernickel","jewish_rye_bread, jewish_rye","limpa","swedish_rye_bread, swedish_rye","salt-rising_bread","simnel","sour_bread, sourdough_bread","toast","wafer","white_bread, light_bread","baguet, baguette","french_bread","italian_bread","cornbread","corn_cake","skillet_corn_bread","ashcake, ash_cake, corn_tash","hoecake","cornpone, pone","corn_dab, corn_dodger, dodger","hush_puppy, hushpuppy","johnnycake, johnny_cake, journey_cake","shawnee_cake","spoon_bread, batter_bread","cinnamon_toast","orange_toast","melba_toast","zwieback, rusk, brussels_biscuit, twice-baked_bread","frankfurter_bun, hotdog_bun","hamburger_bun, hamburger_roll","muffin, gem","bran_muffin","corn_muffin","yorkshire_pudding","popover","scone","drop_scone, griddlecake, scotch_pancake","cross_bun, hot_cross_bun","brioche","crescent_roll, croissant","hard_roll, vienna_roll","soft_roll","kaiser_roll","parker_house_roll","clover-leaf_roll","onion_roll","bialy, bialystoker","sweet_roll, coffee_roll","bear_claw, bear_paw","cinnamon_roll, cinnamon_bun, cinnamon_snail","honey_bun, sticky_bun, caramel_bun, schnecken","pinwheel_roll","danish, danish_pastry","bagel, beigel","onion_bagel","biscuit","rolled_biscuit","baking-powder_biscuit","buttermilk_biscuit, soda_biscuit","shortcake","hardtack, pilot_biscuit, pilot_bread, sea_biscuit, ship_biscuit","saltine","soda_cracker","oyster_cracker","water_biscuit","graham_cracker","pretzel","soft_pretzel","sandwich","sandwich_plate","butty","ham_sandwich","chicken_sandwich","club_sandwich, three-decker, triple-decker","open-face_sandwich, open_sandwich","hamburger, beefburger, burger","cheeseburger","tunaburger","hotdog, hot_dog, red_hot","sloppy_joe","bomber, grinder, hero, hero_sandwich, hoagie, hoagy, cuban_sandwich, italian_sandwich, poor_boy, sub, submarine, submarine_sandwich, torpedo, wedge, zep","gyro","bacon-lettuce-tomato_sandwich, blt","reuben","western, western_sandwich","wrap","spaghetti","hasty_pudding","gruel","congee, jook","skilly","edible_fruit","vegetable, veggie, veg","julienne, julienne_vegetable","raw_vegetable, rabbit_food","crudites","celery_stick","legume","pulse","potherb","greens, green, leafy_vegetable","chop-suey_greens","bean_curd, tofu","solanaceous_vegetable","root_vegetable","potato, white_potato, irish_potato, murphy, spud, tater","baked_potato","french_fries, french-fried_potatoes, fries, chips","home_fries, home-fried_potatoes","jacket_potato","mashed_potato","potato_skin, potato_peel, potato_peelings","uruguay_potato","yam","sweet_potato","yam","snack_food","chip, crisp, potato_chip, saratoga_chip","corn_chip","tortilla_chip","nacho","eggplant, aubergine, mad_apple","pieplant, rhubarb","cruciferous_vegetable","mustard, mustard_greens, leaf_mustard, indian_mustard","cabbage, chou","kale, kail, cole","collards, collard_greens","chinese_cabbage, celery_cabbage, chinese_celery","bok_choy, bok_choi","head_cabbage","red_cabbage","savoy_cabbage, savoy","broccoli","cauliflower","brussels_sprouts","broccoli_rabe, broccoli_raab","squash","summer_squash","yellow_squash","crookneck, crookneck_squash, summer_crookneck","zucchini, courgette","marrow, vegetable_marrow","cocozelle","pattypan_squash","spaghetti_squash","winter_squash","acorn_squash","butternut_squash","hubbard_squash","turban_squash","buttercup_squash","cushaw","winter_crookneck_squash","cucumber, cuke","gherkin","artichoke, globe_artichoke","artichoke_heart","jerusalem_artichoke, sunchoke","asparagus","bamboo_shoot","sprout","bean_sprout","alfalfa_sprout","beet, beetroot","beet_green","sugar_beet","mangel-wurzel","chard, swiss_chard, spinach_beet, leaf_beet","pepper","sweet_pepper","bell_pepper","green_pepper","globe_pepper","pimento, pimiento","hot_pepper","chili, chili_pepper, chilli, chilly, chile","jalapeno, jalapeno_pepper","chipotle","cayenne, cayenne_pepper","tabasco, red_pepper","onion","bermuda_onion","green_onion, spring_onion, scallion","vidalia_onion","spanish_onion","purple_onion, red_onion","leek","shallot","salad_green, salad_greens","lettuce","butterhead_lettuce","buttercrunch","bibb_lettuce","boston_lettuce","crisphead_lettuce, iceberg_lettuce, iceberg","cos, cos_lettuce, romaine, romaine_lettuce","leaf_lettuce, loose-leaf_lettuce","celtuce","bean, edible_bean","goa_bean","lentil","pea","green_pea, garden_pea","marrowfat_pea","snow_pea, sugar_pea","sugar_snap_pea","split-pea","chickpea, garbanzo","cajan_pea, pigeon_pea, dahl","field_pea","mushy_peas","black-eyed_pea, cowpea","common_bean","kidney_bean","navy_bean, pea_bean, white_bean","pinto_bean","frijole","black_bean, turtle_bean","fresh_bean","flageolet, haricot","green_bean","snap_bean, snap","string_bean","kentucky_wonder, kentucky_wonder_bean","scarlet_runner, scarlet_runner_bean, runner_bean, english_runner_bean","haricot_vert, haricots_verts, french_bean","wax_bean, yellow_bean","shell_bean","lima_bean","fordhooks","sieva_bean, butter_bean, butterbean, civet_bean","fava_bean, broad_bean","soy, soybean, soya, soya_bean","green_soybean","field_soybean","cardoon","carrot","carrot_stick","celery","pascal_celery, paschal_celery","celeriac, celery_root","chicory, curly_endive","radicchio","coffee_substitute","chicory, chicory_root","postum","chicory_escarole, endive, escarole","belgian_endive, french_endive, witloof","corn, edible_corn","sweet_corn, green_corn","hominy","lye_hominy","pearl_hominy","popcorn","cress","watercress","garden_cress","winter_cress","dandelion_green","gumbo, okra","kohlrabi, turnip_cabbage","lamb's-quarter, pigweed, wild_spinach","wild_spinach","tomato","beefsteak_tomato","cherry_tomato","plum_tomato","tomatillo, husk_tomato, mexican_husk_tomato","mushroom","stuffed_mushroom","salsify","oyster_plant, vegetable_oyster","scorzonera, black_salsify","parsnip","pumpkin","radish","turnip","white_turnip","rutabaga, swede, swedish_turnip, yellow_turnip","turnip_greens","sorrel, common_sorrel","french_sorrel","spinach","taro, taro_root, cocoyam, dasheen, edda","truffle, earthnut","edible_nut","bunya_bunya","peanut, earthnut, goober, goober_pea, groundnut, monkey_nut","freestone","cling, clingstone","windfall","apple","crab_apple, crabapple","eating_apple, dessert_apple","baldwin","cortland","cox's_orange_pippin","delicious","golden_delicious, yellow_delicious","red_delicious","empire","grimes'_golden","jonathan","mcintosh","macoun","northern_spy","pearmain","pippin","prima","stayman","winesap","stayman_winesap","cooking_apple","bramley's_seedling","granny_smith","lane's_prince_albert","newtown_wonder","rome_beauty","berry","bilberry, whortleberry, european_blueberry","huckleberry","blueberry","wintergreen, boxberry, checkerberry, teaberry, spiceberry","cranberry","lingonberry, mountain_cranberry, cowberry, lowbush_cranberry","currant","gooseberry","black_currant","red_currant","blackberry","boysenberry","dewberry","loganberry","raspberry","saskatoon, serviceberry, shadberry, juneberry","strawberry","sugarberry, hackberry","persimmon","acerola, barbados_cherry, surinam_cherry, west_indian_cherry","carambola, star_fruit","ceriman, monstera","carissa_plum, natal_plum","citrus, citrus_fruit, citrous_fruit","orange","temple_orange","mandarin, mandarin_orange","clementine","satsuma","tangerine","tangelo, ugli, ugli_fruit","bitter_orange, seville_orange, sour_orange","sweet_orange","jaffa_orange","navel_orange","valencia_orange","kumquat","lemon","lime","key_lime","grapefruit","pomelo, shaddock","citrange","citron","almond","jordan_almond","apricot","peach","nectarine","pitahaya","plum","damson, damson_plum","greengage, greengage_plum","beach_plum","sloe","victoria_plum","dried_fruit","dried_apricot","prune","raisin","seedless_raisin, sultana","seeded_raisin","currant","fig","pineapple, ananas","anchovy_pear, river_pear","banana","passion_fruit","granadilla","sweet_calabash","bell_apple, sweet_cup, water_lemon, yellow_granadilla","breadfruit","jackfruit, jak, jack","cacao_bean, cocoa_bean","cocoa","canistel, eggfruit","melon","melon_ball","muskmelon, sweet_melon","cantaloup, cantaloupe","winter_melon","honeydew, honeydew_melon","persian_melon","net_melon, netted_melon, nutmeg_melon","casaba, casaba_melon","watermelon","cherry","sweet_cherry, black_cherry","bing_cherry","heart_cherry, oxheart, oxheart_cherry","blackheart, blackheart_cherry","capulin, mexican_black_cherry","sour_cherry","amarelle","morello","cocoa_plum, coco_plum, icaco","gherkin","grape","fox_grape","concord_grape","catawba","muscadine, bullace_grape","scuppernong","slipskin_grape","vinifera_grape","emperor","muscat, muscatel, muscat_grape","ribier","sultana","tokay","flame_tokay","thompson_seedless","custard_apple","cherimoya, cherimolla","soursop, guanabana","sweetsop, annon, sugar_apple","ilama","pond_apple","papaw, pawpaw","papaya","kai_apple","ketembilla, kitembilla, kitambilla","ackee, akee","durian","feijoa, pineapple_guava","genip, spanish_lime","genipap, genipap_fruit","kiwi, kiwi_fruit, chinese_gooseberry","loquat, japanese_plum","mangosteen","mango","sapodilla, sapodilla_plum, sapota","sapote, mammee, marmalade_plum","tamarind, tamarindo","avocado, alligator_pear, avocado_pear, aguacate","date","elderberry","guava","mombin","hog_plum, yellow_mombin","hog_plum, wild_plum","jaboticaba","jujube, chinese_date, chinese_jujube","litchi, litchi_nut, litchee, lichi, leechee, lichee, lychee","longanberry, dragon's_eye","mamey, mammee, mammee_apple","marang","medlar","medlar","mulberry","olive","black_olive, ripe_olive","green_olive","pear","bosc","anjou","bartlett, bartlett_pear","seckel, seckel_pear","plantain","plumcot","pomegranate","prickly_pear","barbados_gooseberry, blade_apple","quandong, quandang, quantong, native_peach","quandong_nut","quince","rambutan, rambotan","pulasan, pulassan","rose_apple","sorb, sorb_apple","sour_gourd, monkey_bread","edible_seed","pumpkin_seed","betel_nut, areca_nut","beechnut","walnut","black_walnut","english_walnut","brazil_nut, brazil","butternut","souari_nut","cashew, cashew_nut","chestnut","chincapin, chinkapin, chinquapin","hazelnut, filbert, cobnut, cob","coconut, cocoanut","coconut_milk, coconut_water","grugru_nut","hickory_nut","cola_extract","macadamia_nut","pecan","pine_nut, pignolia, pinon_nut","pistachio, pistachio_nut","sunflower_seed","anchovy_paste","rollmops","feed, provender","cattle_cake","creep_feed","fodder","feed_grain","eatage, forage, pasture, pasturage, grass","silage, ensilage","oil_cake","oil_meal","alfalfa","broad_bean, horse_bean","hay","timothy","stover","grain, food_grain, cereal","grist","groats","millet","barley, barleycorn","pearl_barley","buckwheat","bulgur, bulghur, bulgur_wheat","wheat, wheat_berry","cracked_wheat","stodge","wheat_germ","oat","rice","brown_rice","white_rice, polished_rice","wild_rice, indian_rice","paddy","slop, slops, swill, pigswill, pigwash","mash","chicken_feed, scratch","cud, rechewed_food","bird_feed, bird_food, birdseed","petfood, pet-food, pet_food","dog_food","cat_food","canary_seed","salad","tossed_salad","green_salad","caesar_salad","salmagundi","salad_nicoise","combination_salad","chef's_salad","potato_salad","pasta_salad","macaroni_salad","fruit_salad","waldorf_salad","crab_louis","herring_salad","tuna_fish_salad, tuna_salad","chicken_salad","coleslaw, slaw","aspic","molded_salad","tabbouleh, tabooli","ingredient, fixings","flavorer, flavourer, flavoring, flavouring, seasoner, seasoning","bouillon_cube","condiment","herb","fines_herbes","spice","spearmint_oil","lemon_oil","wintergreen_oil, oil_of_wintergreen","salt, table_salt, common_salt","celery_salt","onion_salt","seasoned_salt","sour_salt","five_spice_powder","allspice","cinnamon","stick_cinnamon","clove","cumin, cumin_seed","fennel","ginger, gingerroot","ginger, powdered_ginger","mace","nutmeg","pepper, peppercorn","black_pepper","white_pepper","sassafras","basil, sweet_basil","bay_leaf","borage","hyssop","caraway","chervil","chives","comfrey, healing_herb","coriander, chinese_parsley, cilantro","coriander, coriander_seed","costmary","fennel, common_fennel","fennel, florence_fennel, finocchio","fennel_seed","fenugreek, fenugreek_seed","garlic, ail","clove, garlic_clove","garlic_chive","lemon_balm","lovage","marjoram, oregano","mint","mustard_seed","mustard, table_mustard","chinese_mustard","nasturtium","parsley","salad_burnet","rosemary","rue","sage","clary_sage","savory, savoury","summer_savory, summer_savoury","winter_savory, winter_savoury","sweet_woodruff, waldmeister","sweet_cicely","tarragon, estragon","thyme","turmeric","caper","catsup, ketchup, cetchup, tomato_ketchup","cardamom, cardamon, cardamum","cayenne, cayenne_pepper, red_pepper","chili_powder","chili_sauce","chutney, indian_relish","steak_sauce","taco_sauce","salsa","mint_sauce","cranberry_sauce","curry_powder","curry","lamb_curry","duck_sauce, hoisin_sauce","horseradish","marinade","paprika","spanish_paprika","pickle","dill_pickle","bread_and_butter_pickle","pickle_relish","piccalilli","sweet_pickle","applesauce, apple_sauce","soy_sauce, soy","tabasco, tabasco_sauce","tomato_paste","angelica","angelica","almond_extract","anise, aniseed, anise_seed","chinese_anise, star_anise, star_aniseed","juniper_berries","saffron","sesame_seed, benniseed","caraway_seed","poppy_seed","dill, dill_weed","dill_seed","celery_seed","lemon_extract","monosodium_glutamate, msg","vanilla_bean","vinegar, acetum","cider_vinegar","wine_vinegar","sauce","anchovy_sauce","hot_sauce","hard_sauce","horseradish_sauce, sauce_albert","bolognese_pasta_sauce","carbonara","tomato_sauce","tartare_sauce, tartar_sauce","wine_sauce","marchand_de_vin, mushroom_wine_sauce","bread_sauce","plum_sauce","peach_sauce","apricot_sauce","pesto","ravigote, ravigotte","remoulade_sauce","dressing, salad_dressing","sauce_louis","bleu_cheese_dressing, blue_cheese_dressing","blue_cheese_dressing, roquefort_dressing","french_dressing, vinaigrette, sauce_vinaigrette","lorenzo_dressing","anchovy_dressing","italian_dressing","half-and-half_dressing","mayonnaise, mayo","green_mayonnaise, sauce_verte","aioli, aioli_sauce, garlic_sauce","russian_dressing, russian_mayonnaise","salad_cream","thousand_island_dressing","barbecue_sauce","hollandaise","bearnaise","bercy, bercy_butter","bordelaise","bourguignon, bourguignon_sauce, burgundy_sauce","brown_sauce, sauce_espagnole","espagnole, sauce_espagnole","chinese_brown_sauce, brown_sauce","blanc","cheese_sauce","chocolate_sauce, chocolate_syrup","hot-fudge_sauce, fudge_sauce","cocktail_sauce, seafood_sauce","colbert, colbert_butter","white_sauce, bechamel_sauce, bechamel","cream_sauce","mornay_sauce","demiglace, demi-glaze","gravy, pan_gravy","gravy","spaghetti_sauce, pasta_sauce","marinara","mole","hunter's_sauce, sauce_chausseur","mushroom_sauce","mustard_sauce","nantua, shrimp_sauce","hungarian_sauce, paprika_sauce","pepper_sauce, poivrade","roux","smitane","soubise, white_onion_sauce","lyonnaise_sauce, brown_onion_sauce","veloute","allemande, allemande_sauce","caper_sauce","poulette","curry_sauce","worcester_sauce, worcestershire, worcestershire_sauce","coconut_milk, coconut_cream","egg, eggs","egg_white, white, albumen, ovalbumin","egg_yolk, yolk","boiled_egg, coddled_egg","hard-boiled_egg, hard-cooked_egg","easter_egg","easter_egg","chocolate_egg","candy_egg","poached_egg, dropped_egg","scrambled_eggs","deviled_egg, stuffed_egg","shirred_egg, baked_egg, egg_en_cocotte","omelet, omelette","firm_omelet","french_omelet","fluffy_omelet","western_omelet","souffle","fried_egg","dairy_product","milk","milk","sour_milk","soya_milk, soybean_milk, soymilk","formula","pasteurized_milk","cows'_milk","yak's_milk","goats'_milk","acidophilus_milk","raw_milk","scalded_milk","homogenized_milk","certified_milk","powdered_milk, dry_milk, dried_milk, milk_powder","nonfat_dry_milk","evaporated_milk","condensed_milk","skim_milk, skimmed_milk","semi-skimmed_milk","whole_milk","low-fat_milk","buttermilk","cream","clotted_cream, devonshire_cream","double_creme, heavy_whipping_cream","half-and-half","heavy_cream","light_cream, coffee_cream, single_cream","sour_cream, soured_cream","whipping_cream, light_whipping_cream","butter","clarified_butter, drawn_butter","ghee","brown_butter, beurre_noisette","meuniere_butter, lemon_butter","yogurt, yoghurt, yoghourt","blueberry_yogurt","raita","whey","curd","curd","clabber","cheese","paring","cream_cheese","double_cream","mascarpone","triple_cream, triple_creme","cottage_cheese, pot_cheese, farm_cheese, farmer's_cheese","process_cheese, processed_cheese","bleu, blue_cheese","stilton","roquefort","gorgonzola","danish_blue","bavarian_blue","brie","brick_cheese","camembert","cheddar, cheddar_cheese, armerican_cheddar, american_cheese","rat_cheese, store_cheese","cheshire_cheese","double_gloucester","edam","goat_cheese, chevre","gouda, gouda_cheese","grated_cheese","hand_cheese","liederkranz","limburger","mozzarella","muenster","parmesan","quark_cheese, quark","ricotta","string_cheese","swiss_cheese","emmenthal, emmental, emmenthaler, emmentaler","gruyere","sapsago","velveeta","nut_butter","peanut_butter","marshmallow_fluff","onion_butter","pimento_butter","shrimp_butter","lobster_butter","yak_butter","spread, paste","cheese_spread","anchovy_butter","fishpaste","garlic_butter","miso","wasabi","snail_butter","hummus, humus, hommos, hoummos, humous","pate","duck_pate","foie_gras, pate_de_foie_gras","tapenade","tahini","sweetening, sweetener","aspartame","honey","saccharin","sugar, refined_sugar","syrup, sirup","sugar_syrup","molasses","sorghum, sorghum_molasses","treacle, golden_syrup","grenadine","maple_syrup","corn_syrup","miraculous_food, manna, manna_from_heaven","batter","dough","bread_dough","pancake_batter","fritter_batter","coq_au_vin","chicken_provencale","chicken_and_rice","moo_goo_gai_pan","arroz_con_pollo","bacon_and_eggs","barbecued_spareribs, spareribs","beef_bourguignonne, boeuf_bourguignonne","beef_wellington, filet_de_boeuf_en_croute","bitok","boiled_dinner, new_england_boiled_dinner","boston_baked_beans","bubble_and_squeak","pasta","cannelloni","carbonnade_flamande, belgian_beef_stew","cheese_souffle","chicken_marengo","chicken_cordon_bleu","maryland_chicken","chicken_paprika, chicken_paprikash","chicken_tetrazzini","tetrazzini","chicken_kiev","chili, chili_con_carne","chili_dog","chop_suey","chow_mein","codfish_ball, codfish_cake","coquille","coquilles_saint-jacques","croquette","cottage_pie","rissole","dolmas, stuffed_grape_leaves","egg_foo_yong, egg_fu_yung","egg_roll, spring_roll","eggs_benedict","enchilada","falafel, felafel","fish_and_chips","fondue, fondu","cheese_fondue","chocolate_fondue","fondue, fondu","beef_fondue, boeuf_fondu_bourguignon","french_toast","fried_rice, chinese_fried_rice","frittata","frog_legs","galantine","gefilte_fish, fish_ball","haggis","ham_and_eggs","hash","corned_beef_hash","jambalaya","kabob, kebab, shish_kebab","kedgeree","souvlaki, souvlakia","lasagna, lasagne","seafood_newburg","lobster_newburg, lobster_a_la_newburg","shrimp_newburg","newburg_sauce","lobster_thermidor","lutefisk, lutfisk","macaroni_and_cheese","macedoine","meatball","porcupine_ball, porcupines","swedish_meatball","meat_loaf, meatloaf","moussaka","osso_buco","marrow, bone_marrow","pheasant_under_glass","pigs_in_blankets","pilaf, pilaff, pilau, pilaw","bulgur_pilaf","pizza, pizza_pie","sausage_pizza","pepperoni_pizza","cheese_pizza","anchovy_pizza","sicilian_pizza","poi","pork_and_beans","porridge","oatmeal, burgoo","loblolly","potpie","rijsttaffel, rijstaffel, rijstafel","risotto, italian_rice","roulade","fish_loaf","salmon_loaf","salisbury_steak","sauerbraten","sauerkraut","scallopine, scallopini","veal_scallopini","scampi","scotch_egg","scotch_woodcock","scrapple","spaghetti_and_meatballs","spanish_rice","steak_tartare, tartar_steak, cannibal_mound","pepper_steak","steak_au_poivre, peppered_steak, pepper_steak","beef_stroganoff","stuffed_cabbage","kishke, stuffed_derma","stuffed_peppers","stuffed_tomato, hot_stuffed_tomato","stuffed_tomato, cold_stuffed_tomato","succotash","sukiyaki","sashimi","sushi","swiss_steak","tamale","tamale_pie","tempura","teriyaki","terrine","welsh_rarebit, welsh_rabbit, rarebit","schnitzel, wiener_schnitzel","taco","chicken_taco","burrito","beef_burrito","quesadilla","tostada","bean_tostada","refried_beans, frijoles_refritos","beverage, drink, drinkable, potable","wish-wash","concoction, mixture, intermixture","mix, premix","filling","lekvar","potion","elixir","elixir_of_life","philter, philtre, love-potion, love-philter, love-philtre","alcohol, alcoholic_drink, alcoholic_beverage, intoxicant, inebriant","proof_spirit","home_brew, homebrew","hooch, hootch","kava, kavakava","aperitif","brew, brewage","beer","draft_beer, draught_beer","suds","munich_beer, munchener","bock, bock_beer","lager, lager_beer","light_beer","oktoberfest, octoberfest","pilsner, pilsener","shebeen","weissbier, white_beer, wheat_beer","weizenbock","malt","wort","malt, malt_liquor","ale","bitter","burton","pale_ale","porter, porter's_beer","stout","guinness","kvass","mead","metheglin","hydromel","oenomel","near_beer","ginger_beer","sake, saki, rice_beer","wine, vino","vintage","red_wine","white_wine","blush_wine, pink_wine, rose, rose_wine","altar_wine, sacramental_wine","sparkling_wine","champagne, bubbly","cold_duck","burgundy, burgundy_wine","beaujolais","medoc","canary_wine","chablis, white_burgundy","montrachet","chardonnay, pinot_chardonnay","pinot_noir","pinot_blanc","bordeaux, bordeaux_wine","claret, red_bordeaux","chianti","cabernet, cabernet_sauvignon","merlot","sauvignon_blanc","california_wine","cotes_de_provence","dessert_wine","dubonnet","jug_wine","macon, maconnais","moselle","muscadet","plonk","retsina","rhine_wine, rhenish, hock","riesling","liebfraumilch","rhone_wine","rioja","sack","saint_emilion","soave","zinfandel","sauterne, sauternes","straw_wine","table_wine","tokay","vin_ordinaire","vermouth","sweet_vermouth, italian_vermouth","dry_vermouth, french_vermouth","chenin_blanc","verdicchio","vouvray","yquem","generic, generic_wine","varietal, varietal_wine","fortified_wine","madeira","malmsey","port, port_wine","sherry","marsala","muscat, muscatel, muscadel, muscadelle","liquor, spirits, booze, hard_drink, hard_liquor, john_barleycorn, strong_drink","neutral_spirits, ethyl_alcohol","aqua_vitae, ardent_spirits","eau_de_vie","moonshine, bootleg, corn_liquor","bathtub_gin","aquavit, akvavit","arrack, arak","bitters","brandy","applejack","calvados","armagnac","cognac","grappa","kirsch","slivovitz","gin","sloe_gin","geneva, holland_gin, hollands","grog","ouzo","rum","demerara, demerara_rum","jamaica_rum","schnapps, schnaps","pulque","mescal","tequila","vodka","whiskey, whisky","blended_whiskey, blended_whisky","bourbon","corn_whiskey, corn_whisky, corn","firewater","irish, irish_whiskey, irish_whisky","poteen","rye, rye_whiskey, rye_whisky","scotch, scotch_whiskey, scotch_whisky, malt_whiskey, malt_whisky, scotch_malt_whiskey, scotch_malt_whisky","sour_mash, sour_mash_whiskey","liqueur, cordial","absinth, absinthe","amaretto","anisette, anisette_de_bordeaux","benedictine","chartreuse","coffee_liqueur","creme_de_cacao","creme_de_menthe","creme_de_fraise","drambuie","galliano","orange_liqueur","curacao, curacoa","triple_sec","grand_marnier","kummel","maraschino, maraschino_liqueur","pastis","pernod","pousse-cafe","kahlua","ratafia, ratafee","sambuca","mixed_drink","cocktail","dom_pedro","highball","mixer","bishop","bloody_mary","virgin_mary, bloody_shame","bullshot","cobbler","collins, tom_collins","cooler","refresher","smoothie","daiquiri, rum_cocktail","strawberry_daiquiri","nada_daiquiri","spritzer","flip","gimlet","gin_and_tonic","grasshopper","harvey_wallbanger","julep, mint_julep","manhattan","rob_roy","margarita","martini","gin_and_it","vodka_martini","old_fashioned","pink_lady","sazerac","screwdriver","sidecar","scotch_and_soda","sling","brandy_sling","gin_sling","rum_sling","sour","whiskey_sour, whisky_sour","stinger","swizzle","hot_toddy, toddy","zombie, zombi","fizz","irish_coffee","cafe_au_lait","cafe_noir, demitasse","decaffeinated_coffee, decaf","drip_coffee","espresso","caffe_latte, latte","cappuccino, cappuccino_coffee, coffee_cappuccino","iced_coffee, ice_coffee","instant_coffee","mocha, mocha_coffee","mocha","cassareep","turkish_coffee","chocolate_milk","cider, cyder","hard_cider","scrumpy","sweet_cider","mulled_cider","perry","rotgut","slug","cocoa, chocolate, hot_chocolate, drinking_chocolate","criollo","juice","fruit_juice, fruit_crush","nectar","apple_juice","cranberry_juice","grape_juice","must","grapefruit_juice","orange_juice","frozen_orange_juice, orange-juice_concentrate","pineapple_juice","lemon_juice","lime_juice","papaya_juice","tomato_juice","carrot_juice","v-8_juice","koumiss, kumis","fruit_drink, ade","lemonade","limeade","orangeade","malted_milk","mate","mulled_wine","negus","soft_drink","pop, soda, soda_pop, soda_water, tonic","birch_beer","bitter_lemon","cola, dope","cream_soda","egg_cream","ginger_ale, ginger_pop","orange_soda","phosphate","coca_cola, coke","pepsi, pepsi_cola","root_beer","sarsaparilla","tonic, tonic_water, quinine_water","coffee_bean, coffee_berry, coffee","coffee, java","cafe_royale, coffee_royal","fruit_punch","milk_punch","mimosa, buck's_fizz","pina_colada","punch","cup","champagne_cup","claret_cup","wassail","planter's_punch","white_russian","fish_house_punch","may_wine","eggnog","cassiri","spruce_beer","rickey","gin_rickey","tea, tea_leaf","tea_bag","tea","tea-like_drink","cambric_tea","cuppa, cupper","herb_tea, herbal_tea, herbal","tisane","camomile_tea","ice_tea, iced_tea","sun_tea","black_tea","congou, congo, congou_tea, english_breakfast_tea","darjeeling","orange_pekoe, pekoe","souchong, soochong","green_tea","hyson","oolong","water","bottled_water","branch_water","spring_water","sugar_water","drinking_water","ice_water","soda_water, carbonated_water, club_soda, seltzer, sparkling_water","mineral_water","seltzer","vichy_water","perishable, spoilable","couscous","ramekin, ramequin","multivitamin, multivitamin_pill","vitamin_pill","soul_food","mold, mould","people","collection, aggregation, accumulation, assemblage","book, rule_book","library","baseball_club, ball_club, club, nine","crowd","class, form, grade, course","core, nucleus, core_group","concert_band, military_band","dance","wedding, wedding_party","chain, concatenation","power_breakfast","aerie, aery, eyrie, eyry","agora","amusement_park, funfair, pleasure_ground","aphelion","apron","interplanetary_space","interstellar_space","intergalactic_space","bush","semidesert","beam-ends","bridgehead","bus_stop","campsite, campground, camping_site, camping_ground, bivouac, encampment, camping_area","detention_basin","cemetery, graveyard, burial_site, burial_ground, burying_ground, memorial_park, necropolis","trichion, crinion","city, metropolis, urban_center","business_district, downtown","outskirts","borough","cow_pasture","crest","eparchy, exarchate","suburb, suburbia, suburban_area","stockbroker_belt","crawlspace, crawl_space","sheikdom, sheikhdom","residence, abode","domicile, legal_residence","dude_ranch","farmland, farming_area","midfield","firebreak, fireguard","flea_market","battlefront, front, front_line","garbage_heap, junk_heap, rubbish_heap, scrapheap, trash_heap, junk_pile, trash_pile, refuse_heap","benthos, benthic_division, benthonic_zone","goldfield","grainfield, grain_field","half-mast, half-staff","hemline","heronry","hipline","hipline","hole-in-the-wall","junkyard","isoclinic_line, isoclinal","littoral, litoral, littoral_zone, sands","magnetic_pole","grassland","mecca","observer's_meridian","prime_meridian","nombril","no-parking_zone","outdoors, out-of-doors, open_air, open","fairground","pasture, pastureland, grazing_land, lea, ley","perihelion","periselene, perilune","locus_of_infection","kasbah, casbah","waterfront","resort, resort_hotel, holiday_resort","resort_area, playground, vacation_spot","rough","ashram","harborage, harbourage","scrubland","weald","wold","schoolyard","showplace","bedside","sideline, out_of_bounds","ski_resort","soil_horizon","geological_horizon","coal_seam","coalface","field","oilfield","temperate_zone","terreplein","three-mile_limit","desktop","top","kampong, campong","subtropics, semitropics","barrio","veld, veldt","vertex, peak, apex, acme","waterline, water_line, water_level","high-water_mark","low-water_mark","continental_divide","zodiac","aegean_island","sultanate","swiss_canton","abyssal_zone","aerie, aery, eyrie, eyry","air_bubble","alluvial_flat, alluvial_plain","alp","alpine_glacier, alpine_type_of_glacier","anthill, formicary","aquifer","archipelago","arete","arroyo","ascent, acclivity, rise, raise, climb, upgrade","asterism","asthenosphere","atoll","bank","bank","bar","barbecue_pit","barrier_reef","baryon, heavy_particle","basin","beach","honeycomb","belay","ben","berm","bladder_stone, cystolith","bluff","borrow_pit","brae","bubble","burrow, tunnel","butte","caldera","canyon, canon","canyonside","cave","cavern","chasm","cirque, corrie, cwm","cliff, drop, drop-off","cloud","coast","coastland","col, gap","collector","comet","continental_glacier","coral_reef","cove","crag","crater","cultivated_land, farmland, plowland, ploughland, tilled_land, tillage, tilth","dale","defile, gorge","delta","descent, declivity, fall, decline, declination, declension, downslope","diapir","divot","divot","down","downhill","draw","drey","drumlin","dune, sand_dune","escarpment, scarp","esker","fireball","flare_star","floor","fomite, vehicle","foothill","footwall","foreland","foreshore","gauge_boson","geological_formation, formation","geyser","glacier","glen","gopher_hole","gorge","grotto, grot","growler","gulch, flume","gully","hail","highland, upland","hill","hillside","hole, hollow","hollow, holler","hot_spring, thermal_spring","iceberg, berg","icecap, ice_cap","ice_field","ice_floe, floe","ice_mass","inclined_fault","ion","isthmus","kidney_stone, urinary_calculus, nephrolith, renal_calculus","knoll, mound, hillock, hummock, hammock","kopje, koppie","kuiper_belt, edgeworth-kuiper_belt","lake_bed, lake_bottom","lakefront","lakeside, lakeshore","landfall","landfill","lather","leak","ledge, shelf","lepton","lithosphere, geosphere","lowland","lunar_crater","maar","massif","meander","mesa, table","meteorite","microfossil","midstream","molehill","monocline","mountain, mount","mountainside, versant","mouth","mull","natural_depression, depression","natural_elevation, elevation","nullah","ocean","ocean_floor, sea_floor, ocean_bottom, seabed, sea_bottom, davy_jones's_locker, davy_jones","oceanfront","outcrop, outcropping, rock_outcrop","oxbow","pallasite","perforation","photosphere","piedmont","piedmont_glacier, piedmont_type_of_glacier","pinetum","plage","plain, field, champaign","point","polar_glacier","pothole, chuckhole","precipice","promontory, headland, head, foreland","ptyalith","pulsar","quicksand","rabbit_burrow, rabbit_hole","radiator","rainbow","range, mountain_range, range_of_mountains, chain, mountain_chain, chain_of_mountains","rangeland","ravine","reef","ridge","ridge, ridgeline","rift_valley","riparian_forest","ripple_mark","riverbank, riverside","riverbed, river_bottom","rock, stone","roof","saltpan","sandbank","sandbar, sand_bar","sandpit","sanitary_landfill","sawpit","scablands","seashore, coast, seacoast, sea-coast","seaside, seaboard","seif_dune","shell","shiner","shoal","shore","shoreline","sinkhole, sink, swallow_hole","ski_slope","sky","slope, incline, side","snowcap","snowdrift","snowfield","soapsuds, suds, lather","spit, tongue","spoor","spume","star","steep","steppe","strand","streambed, creek_bed","sun, sun","supernova","swale","swamp, swampland","swell","tableland, plateau","talus, scree","tangle","tar_pit","terrace, bench","tidal_basin","tideland","tor","tor","trapezium","troposphere","tundra","twinkler","uphill","urolith","valley, vale","vehicle-borne_transmission","vein, mineral_vein","volcanic_crater, crater","volcano","wadi","wall","warren, rabbit_warren","wasp's_nest, wasps'_nest, hornet's_nest, hornets'_nest","watercourse","waterside","water_table, water_level, groundwater_level","whinstone, whin","wormcast","xenolith","circe","gryphon, griffin, griffon","spiritual_leader","messiah, christ","rhea_silvia, rea_silvia","number_one","adventurer, venturer","anomaly, unusual_person","appointee, appointment","argonaut","ashkenazi","benefactor, helper","color-blind_person","commoner, common_man, common_person","conservator","contrarian","contadino","contestant","cosigner, cosignatory","discussant","enologist, oenologist, fermentologist","entertainer","eulogist, panegyrist","ex-gambler","experimenter","experimenter","exponent","ex-president","face","female, female_person","finisher","inhabitant, habitant, dweller, denizen, indweller","native, indigen, indigene, aborigine, aboriginal","native","juvenile, juvenile_person","lover","male, male_person","mediator, go-between, intermediator, intermediary, intercessor","mediatrix","national, subject","peer, equal, match, compeer","prize_winner, lottery_winner","recipient, receiver","religionist","sensualist","traveler, traveller","unwelcome_person, persona_non_grata","unskilled_person","worker","wrongdoer, offender","black_african","afrikaner, afrikander, boer","aryan","black, black_person, blackamoor, negro, negroid","black_woman","mulatto","white, white_person, caucasian","circassian","semite","chaldean, chaldaean, chaldee","elamite","white_man","wasp, white_anglo-saxon_protestant","gook, slant-eye","mongol, mongolian","tatar, tartar, mongol_tatar","nahuatl","aztec","olmec","biloxi","blackfoot","brule","caddo","cheyenne","chickasaw","cocopa, cocopah","comanche","creek","delaware","diegueno","esselen","eyeish","havasupai","hunkpapa","iowa, ioway","kalapooia, kalapuya, calapooya, calapuya","kamia","kekchi","kichai","kickapoo","kiliwa, kiliwi","malecite","maricopa","mohican, mahican","muskhogean, muskogean","navaho, navajo","nootka","oglala, ogalala","osage","oneida","paiute, piute","passamaquody","penobscot","penutian","potawatomi","powhatan","kachina","salish","shahaptian, sahaptin, sahaptino","shasta","shawnee","sihasapa","teton, lakota, teton_sioux, teton_dakota","taracahitian","tarahumara","tuscarora","tutelo","yana","yavapai","yokuts","yuma","gadaba","kolam","kui","toda","tulu","gujarati, gujerati","kashmiri","punjabi, panjabi","slav","anabaptist","adventist, second_adventist","gentile, non-jew, goy","gentile","catholic","old_catholic","uniat, uniate, uniate_christian","copt","jewess","jihadist","buddhist","zen_buddhist","mahayanist","swami","hare_krishna","shintoist","eurafrican","eurasian","gael","frank","afghan, afghanistani","albanian","algerian","altaic","andorran","angolan","anguillan","austrian","bahamian","bahraini, bahreini","basotho","herero","luba, chiluba","barbadian","bolivian","bornean","carioca","tupi","bruneian","bulgarian","byelorussian, belorussian, white_russian","cameroonian","canadian","french_canadian","central_american","chilean","congolese","cypriot, cypriote, cyprian","dane","djiboutian","britisher, briton, brit","english_person","englishwoman","anglo-saxon","angle","west_saxon","lombard, langobard","limey, john_bull","cantabrigian","cornishman","cornishwoman","lancastrian","lancastrian","geordie","oxonian","ethiopian","amhara","eritrean","finn","komi","livonian","lithuanian","selkup, ostyak-samoyed","parisian","parisienne","creole","creole","gabonese","greek, hellene","dorian","athenian","laconian","guyanese","haitian","malay, malayan","moro","netherlander, dutchman, hollander","icelander","iraqi, iraki","irishman","irishwoman","dubliner","italian","roman","sabine","japanese, nipponese","jordanian","korean","kenyan","lao, laotian","lapp, lapplander, sami, saami, same, saame","latin_american, latino","lebanese","levantine","liberian","luxemburger, luxembourger","macedonian","sabahan","mexican","chicano","mexican-american, mexicano","namibian","nauruan","gurkha","new_zealander, kiwi","nicaraguan","nigerian","hausa, haussa","north_american","nova_scotian, bluenose","omani","pakistani","brahui","south_american_indian","carib, carib_indian","filipino","polynesian","qatari, katari","romanian, rumanian","muscovite","georgian","sarawakian","scandinavian, norse, northman","senegalese","slovene","south_african","south_american","sudanese","syrian","tahitian","tanzanian","tibetan","togolese","tuareg","turki","chuvash","turkoman, turkmen, turcoman","uzbek, uzbeg, uzbak, usbek, usbeg","ugandan","ukranian","yakut","tungus, evenk","igbo","american","anglo-american","alaska_native, alaskan_native, native_alaskan","arkansan, arkansawyer","carolinian","coloradan","connecticuter","delawarean, delawarian","floridian","german_american","illinoisan","mainer, down_easter","marylander","minnesotan, gopher","nebraskan, cornhusker","new_hampshirite, granite_stater","new_jerseyan, new_jerseyite, garden_stater","new_yorker","north_carolinian, tarheel","oregonian, beaver","pennsylvanian, keystone_stater","texan","utahan","uruguayan","vietnamese, annamese","gambian","east_german","berliner","prussian","ghanian","guinean","papuan","walloon","yemeni","yugoslav, jugoslav, yugoslavian, jugoslavian","serbian, serb","xhosa","zairese, zairean","zimbabwean","zulu","gemini, twin","sagittarius, archer","pisces, fish","abbe","abbess, mother_superior, prioress","abnegator","abridger, abbreviator","abstractor, abstracter","absconder","absolver","abecedarian","aberrant","abettor, abetter","abhorrer","abomination","abseiler, rappeller","abstainer, ascetic","academic_administrator","academician","accessory_before_the_fact","companion","accompanist, accompanyist","accomplice, confederate","account_executive, account_representative, registered_representative, customer's_broker, customer's_man","accused","accuser","acid_head","acquaintance, friend","acquirer","aerialist","action_officer","active","active_citizen","actor, histrion, player, thespian, role_player","actor, doer, worker","addict, nut, freak, junkie, junky","adducer","adjuster, adjustor, claims_adjuster, claims_adjustor, claim_agent","adjutant, aide, aide-de-camp","adjutant_general","admirer, adorer","adoptee","adulterer, fornicator","adulteress, fornicatress, hussy, jade, loose_woman, slut, strumpet, trollop","advertiser, advertizer, adman","advisee","advocate, advocator, proponent, exponent","aeronautical_engineer","affiliate","affluent","aficionado","buck_sergeant","agent-in-place","aggravator, annoyance","agitator, fomenter","agnostic","agnostic, doubter","agonist","agony_aunt","agriculturist, agriculturalist, cultivator, grower, raiser","air_attache","air_force_officer, commander","airhead","air_traveler, air_traveller","alarmist","albino","alcoholic, alky, dipsomaniac, boozer, lush, soaker, souse","alderman","alexic","alienee, grantee","alienor","aliterate, aliterate_person","algebraist","allegorizer, allegoriser","alliterator","almoner, medical_social_worker","alpinist","altar_boy","alto","ambassador, embassador","ambassador","ambusher","amicus_curiae, friend_of_the_court","amoralist","amputee","analogist","analphabet, analphabetic","analyst","industry_analyst","market_strategist","anarchist, nihilist, syndicalist","anathema, bete_noire","ancestor, ascendant, ascendent, antecedent, root","anchor, anchorman, anchorperson","ancient","anecdotist, raconteur","angler, troller","animator","animist","annotator","announcer","announcer","anti","anti-american","anti-semite, jew-baiter","anzac","ape-man","aphakic","appellant, plaintiff_in_error","appointee","apprehender","april_fool","aspirant, aspirer, hopeful, wannabe, wannabee","appreciator","appropriator","arabist","archaist","archbishop","archer, bowman","architect, designer","archivist","archpriest, hierarch, high_priest, prelate, primate","aristotelian, aristotelean, peripatetic","armiger","army_attache","army_engineer, military_engineer","army_officer","arranger, adapter, transcriber","arrival, arriver, comer","arthritic","articulator","artilleryman, cannoneer, gunner, machine_gunner","artist's_model, sitter","assayer","assemblyman","assemblywoman","assenter","asserter, declarer, affirmer, asseverator, avower","assignee","assistant, helper, help, supporter","assistant_professor","associate","associate","associate_professor","astronaut, spaceman, cosmonaut","cosmographer, cosmographist","atheist","athlete, jock","attendant, attender, tender","attorney_general","auditor","augur, auspex","aunt, auntie, aunty","au_pair_girl","authoritarian, dictator","authority","authorizer, authoriser","automobile_mechanic, auto-mechanic, car-mechanic, mechanic, grease_monkey","aviator, aeronaut, airman, flier, flyer","aviatrix, airwoman, aviatress","ayah","babu, baboo","baby, babe, sister","baby","baby_boomer, boomer","baby_farmer","back","backbencher","backpacker, packer","backroom_boy, brain_truster","backscratcher","bad_person","baggage","bag_lady","bailee","bailiff","bailor","bairn","baker, bread_maker","balancer","balker, baulker, noncompliant","ball-buster, ball-breaker","ball_carrier, runner","ballet_dancer","ballet_master","ballet_mistress","balletomane","ball_hawk","balloonist","ballplayer, baseball_player","bullfighter, toreador","banderillero","matador","picador","bandsman","banker","bank_robber","bankrupt, insolvent","bantamweight","barmaid","baron, big_businessman, business_leader, king, magnate, mogul, power, top_executive, tycoon","baron","baron","bartender, barman, barkeep, barkeeper, mixologist","baseball_coach, baseball_manager","base_runner, runner","basketball_player, basketeer, cager","basketweaver, basketmaker","basket_maker","bass, basso","bastard, by-blow, love_child, illegitimate_child, illegitimate, whoreson","bat_boy","bather","batman","baton_twirler, twirler","bavarian","beadsman, bedesman","beard","beatnik, beat","beauty_consultant","bedouin, beduin","bedwetter, bed_wetter, wetter","beekeeper, apiarist, apiculturist","beer_drinker, ale_drinker","beggarman","beggarwoman","beldam, beldame","theist","believer, truster","bell_founder","benedick, benedict","berserker, berserk","besieger","best, topper","betrothed","big_brother","bigot","big_shot, big_gun, big_wheel, big_cheese, big_deal, big_enchilada, big_fish, head_honcho","big_sister","billiard_player","biochemist","biographer","bird_fancier","birth","birth-control_campaigner, birth-control_reformer","bisexual, bisexual_person","black_belt","blackmailer, extortioner, extortionist","black_muslim","blacksmith","blade","blind_date","bluecoat","bluestocking, bas_bleu","boatbuilder","boatman, boater, waterman","boatswain, bos'n, bo's'n, bosun, bo'sun","bobby","bodyguard, escort","boffin","bolshevik, marxist, red, bolshie, bolshy","bolshevik, bolshevist","bombshell","bondman, bondsman","bondwoman, bondswoman, bondmaid","bondwoman, bondswoman, bondmaid","bond_servant","book_agent","bookbinder","bookkeeper","bookmaker","bookworm","booster, shoplifter, lifter","bootblack, shoeblack","bootlegger, moonshiner","bootmaker, boot_maker","borderer","border_patrolman","botanist, phytologist, plant_scientist","bottom_feeder","boulevardier","bounty_hunter","bounty_hunter","bourbon","bowler","slugger, slogger","cub, lad, laddie, sonny, sonny_boy","boy_scout","boy_scout","boy_wonder","bragger, braggart, boaster, blowhard, line-shooter, vaunter","brahman, brahmin","brawler","breadwinner","breaststroker","breeder, stock_breeder","brick","bride","bridesmaid, maid_of_honor","bridge_agent","broadcast_journalist","brother","brother-in-law","browser","brummie, brummy","buddy, brother, chum, crony, pal, sidekick","bull","bully","bunny, bunny_girl","burglar","bursar","busboy, waiter's_assistant","business_editor","business_traveler","buster","busybody, nosy-parker, nosey-parker, quidnunc","buttinsky","cabinetmaker, furniture_maker","caddie, golf_caddie","cadet, plebe","caller, caller-out","call_girl","calligrapher, calligraphist","campaigner, candidate, nominee","camper","camp_follower","candidate, prospect","canonist","capitalist","captain, headwaiter, maitre_d'hotel, maitre_d'","captain, senior_pilot","captain","captain, chieftain","captive","captive","cardinal","cardiologist, heart_specialist, heart_surgeon","card_player","cardsharp, card_sharp, cardsharper, card_sharper, sharper, sharpie, sharpy, card_shark","careerist","career_man","caregiver","caretaker","caretaker","caricaturist","carillonneur","caroler, caroller","carpenter","carper, niggler","cartesian","cashier","casualty, injured_party","casualty","casuist, sophist","catechist","catechumen, neophyte","caterer","catholicos","cat_fancier","cavalier, royalist","cavalryman, trooper","caveman, cave_man, cave_dweller, troglodyte","celebrant","celebrant, celebrator, celebrater","celebrity, famous_person","cellist, violoncellist","censor","censor","centenarian","centrist, middle_of_the_roader, moderate, moderationist","centurion","certified_public_accountant, cpa","chachka, tsatske, tshatshke, tchotchke, tchotchkeleh","chambermaid, fille_de_chambre","chameleon","champion, champ, title-holder","chandler","prison_chaplain","charcoal_burner","charge_d'affaires","charioteer","charmer, beguiler","chartered_accountant","chartist, technical_analyst","charwoman, char, cleaning_woman, cleaning_lady, woman","male_chauvinist, sexist","cheapskate, tightwad","chechen","checker","cheerer","cheerleader","cheerleader","cheops, khufu","chess_master","chief_executive_officer, ceo, chief_operating_officer","chief_of_staff","chief_petty_officer","chief_secretary","child, kid, youngster, minor, shaver, nipper, small_fry, tiddler, tike, tyke, fry, nestling","child, kid","child, baby","child_prodigy, infant_prodigy, wonder_child","chimneysweeper, chimneysweep, sweep","chiropractor","chit","choker","choragus","choreographer","chorus_girl, showgirl, chorine","chosen","cicerone","cigar_smoker","cipher, cypher, nobody, nonentity","circus_acrobat","citizen","city_editor","city_father","city_man","city_slicker, city_boy","civic_leader, civil_leader","civil_rights_leader, civil_rights_worker, civil_rights_activist","cleaner","clergyman, reverend, man_of_the_cloth","cleric, churchman, divine, ecclesiastic","clerk","clever_dick, clever_clogs","climatologist","climber","clinician","closer, finisher","closet_queen","clown, buffoon, goof, goofball, merry_andrew","clown, buffoon","coach, private_instructor, tutor","coach, manager, handler","pitching_coach","coachman","coal_miner, collier, pitman","coastguardsman","cobber","cobbler, shoemaker","codger, old_codger","co-beneficiary","cog","cognitive_neuroscientist","coiffeur","coiner","collaborator, cooperator, partner, pardner","colleen","college_student, university_student","collegian, college_man, college_boy","colonial","colonialist","colonizer, coloniser","coloratura, coloratura_soprano","color_guard","colossus, behemoth, giant, heavyweight, titan","comedian","comedienne","comer","commander","commander_in_chief, generalissimo","commanding_officer, commandant, commander","commissar, political_commissar","commissioned_officer","commissioned_military_officer","commissioner","commissioner","committee_member","committeewoman","commodore","communicant","communist, commie","communist","commuter","compere","complexifier","compulsive","computational_linguist","computer_scientist","computer_user","comrade","concert-goer, music_lover","conciliator, make-peace, pacifier, peacemaker, reconciler","conductor","confectioner, candymaker","confederate","confessor","confidant, intimate","confucian, confucianist","rep","conqueror, vanquisher","conservative","nonconformist, chapelgoer","anglican","consignee","consigner, consignor","constable","constructivist","contractor","contralto","contributor","control_freak","convalescent","convener","convict, con, inmate, yard_bird, yardbird","copilot, co-pilot","copycat, imitator, emulator, ape, aper","coreligionist","cornerback","corporatist","correspondent, letter_writer","cosmetician","cosmopolitan, cosmopolite","cossack","cost_accountant","co-star","costumier, costumer, costume_designer","cotter, cottier","cotter, cottar","counselor, counsellor","counterterrorist","counterspy, mole","countess","compromiser","countrywoman","county_agent, agricultural_agent, extension_agent","courtier","cousin, first_cousin, cousin-german, full_cousin","cover_girl, pin-up, lovely","cow","craftsman, artisan, journeyman, artificer","craftsman, crafter","crapshooter","crazy, loony, looney, nutcase, weirdo","creature, wight","creditor","creep, weirdo, weirdie, weirdy, spook","criminologist","critic","croesus","cross-examiner, cross-questioner","crossover_voter, crossover","croupier","crown_prince","crown_princess","cryptanalyst, cryptographer, cryptologist","cub_scout","cuckold","cultist","curandera","curate, minister_of_religion, minister, parson, pastor, rector","curator, conservator","customer_agent","cutter, carver","cyberpunk","cyborg, bionic_man, bionic_woman","cymbalist","cynic","cytogeneticist","cytologist","czar","czar, tsar, tzar","dad, dada, daddy, pa, papa, pappa, pop","dairyman","dalai_lama, grand_lama","dallier, dillydallier, dilly-dallier, mope, lounger","dancer, professional_dancer, terpsichorean","dancer, social_dancer","clog_dancer","dancing-master, dance_master","dark_horse","darling, favorite, favourite, pet, dearie, deary, ducky","date, escort","daughter, girl","dawdler, drone, laggard, lagger, trailer, poke","day_boarder","day_laborer, day_labourer","deacon, protestant_deacon","deaconess","deadeye","deipnosophist","dropout","deadhead","deaf_person","debtor, debitor","deckhand, roustabout","defamer, maligner, slanderer, vilifier, libeler, backbiter, traducer","defense_contractor","deist, freethinker","delegate","deliveryman, delivery_boy, deliverer","demagogue, demagog, rabble-rouser","demigod, superman, ubermensch","demographer, demographist, population_scientist","demonstrator, protester","den_mother","department_head","depositor","deputy","dermatologist, skin_doctor","descender","designated_hitter","designer, intriguer","desk_clerk, hotel_desk_clerk, hotel_clerk","desk_officer","desk_sergeant, deskman, station_keeper","detainee, political_detainee","detective, investigator, tec, police_detective","detective","detractor, disparager, depreciator, knocker","developer","deviationist","devisee","devisor","devourer","dialectician","diarist, diary_keeper, journalist","dietician, dietitian, nutritionist","diocesan","director, theater_director, theatre_director","director","dirty_old_man","disbeliever, nonbeliever, unbeliever","disk_jockey, disc_jockey, dj","dispatcher","distortionist","distributor, distributer","district_attorney, da","district_manager","diver, plunger","divorcee, grass_widow","ex-wife, ex","divorce_lawyer","docent","doctor, doc, physician, md, dr., medico","dodo, fogy, fogey, fossil","doge","dog_in_the_manger","dogmatist, doctrinaire","dolichocephalic","domestic_partner, significant_other, spousal_equivalent, spouse_equivalent","dominican","dominus, dominie, domine, dominee","don, father","donatist","donna","dosser, street_person","double, image, look-alike","double-crosser, double-dealer, two-timer, betrayer, traitor","down-and-out","doyenne","draftsman, drawer","dramatist, playwright","dreamer","dressmaker, modiste, needlewoman, seamstress, sempstress","dressmaker's_model","dribbler, driveller, slobberer, drooler","dribbler","drinker, imbiber, toper, juicer","drinker","drug_addict, junkie, junky","drug_user, substance_abuser, user","druid","drum_majorette, majorette","drummer","drunk","drunkard, drunk, rummy, sot, inebriate, wino","druze, druse","dry, prohibitionist","dry_nurse","duchess","duke","duffer","dunker","dutch_uncle","dyspeptic","eager_beaver, busy_bee, live_wire, sharpie, sharpy","earl","earner, wage_earner","eavesdropper","eccentric, eccentric_person, flake, oddball, geek","eclectic, eclecticist","econometrician, econometrist","economist, economic_expert","ectomorph","editor, editor_in_chief","egocentric, egoist","egotist, egoist, swellhead","ejaculator","elder","elder_statesman","elected_official","electrician, lineman, linesman","elegist","elocutionist","emancipator, manumitter","embryologist","emeritus","emigrant, emigre, emigree, outgoer","emissary, envoy","empress","employee","employer","enchantress, witch","enchantress, temptress, siren, delilah, femme_fatale","encyclopedist, encyclopaedist","endomorph","enemy, foe, foeman, opposition","energizer, energiser, vitalizer, vitaliser, animator","end_man","end_man, corner_man","endorser, indorser","enjoyer","enlisted_woman","enophile, oenophile","entrant","entrant","entrepreneur, enterpriser","envoy, envoy_extraordinary, minister_plenipotentiary","enzymologist","eparch","epidemiologist","epigone, epigon","epileptic","episcopalian","equerry","equerry","erotic","escapee","escapist, dreamer, wishful_thinker","eskimo, esquimau, inuit","espionage_agent","esthetician, aesthetician","etcher","ethnologist","etonian","etymologist","evangelist, revivalist, gospeler, gospeller","evangelist","event_planner","examiner, inspector","examiner, tester, quizzer","exarch","executant","executive_secretary","executive_vice_president","executrix","exegete","exhibitor, exhibitioner, shower","exhibitionist, show-off","exile, expatriate, expat","existentialist, existentialist_philosopher, existential_philosopher","exorcist, exorciser","ex-spouse","extern, medical_extern","extremist","extrovert, extravert","eyewitness","facilitator","fairy_godmother","falangist, phalangist","falconer, hawker","falsifier","familiar","fan, buff, devotee, lover","fanatic, fiend","fancier, enthusiast","farm_boy","farmer, husbandman, granger, sodbuster","farmhand, fieldhand, field_hand, farm_worker","fascist","fascista","fatalist, determinist, predestinarian, predestinationist","father, male_parent, begetter","father, padre","father-figure","father-in-law","fauntleroy, little_lord_fauntleroy","fauve, fauvist","favorite_son","featherweight","federalist","fellow_traveler, fellow_traveller","female_aristocrat","female_offspring","female_child, girl, little_girl","fence","fiance, groom-to-be","fielder, fieldsman","field_judge","fighter_pilot","filer","film_director, director","finder","fire_chief, fire_marshal","fire-eater, fire-swallower","fire-eater, hothead","fireman, firefighter, fire_fighter, fire-eater","fire_marshall","fire_walker","first_baseman, first_sacker","firstborn, eldest","first_lady","first_lieutenant, 1st_lieutenant","first_offender","first_sergeant, sergeant_first_class","fishmonger, fishwife","flagellant","flag_officer","flak_catcher, flak, flack_catcher, flack","flanker_back, flanker","flapper","flatmate","flatterer, adulator","flibbertigibbet, foolish_woman","flight_surgeon","floorwalker, shopwalker","flop, dud, washout","florentine","flower_girl","flower_girl","flutist, flautist, flute_player","fly-by-night","flyweight","flyweight","foe, enemy","folk_dancer","folk_poet","follower","football_hero","football_player, footballer","footman","forefather, father, sire","foremother","foreign_agent","foreigner, outsider","boss","foreman","forester, tree_farmer, arboriculturist","forewoman","forger, counterfeiter","forward","foster-brother, foster_brother","foster-father, foster_father","foster-mother, foster_mother","foster-sister, foster_sister","foster-son, foster_son","founder, beginner, founding_father, father","foundress","four-minute_man","framer","francophobe","freak, monster, monstrosity, lusus_naturae","free_agent, free_spirit, freewheeler","free_agent","freedom_rider","free-liver","freeloader","free_trader","freudian","friar, mendicant","monk, monastic","frontierswoman","front_man, front, figurehead, nominal_head, straw_man, strawman","frotteur","fucker","fucker","fuddy-duddy","fullback","funambulist, tightrope_walker","fundamentalist","fundraiser","futurist","gadgeteer","gagman, gagster, gagwriter","gagman, standup_comedian","gainer, weight_gainer","gal","galoot","gambist","gambler","gamine","garbage_man, garbageman, garbage_collector, garbage_carter, garbage_hauler, refuse_collector, dustman","gardener","garment_cutter","garroter, garrotter, strangler, throttler, choker","gasman","gastroenterologist","gatherer","gawker","gendarme","general, full_general","generator, source, author","geneticist","genitor","gent","geologist","geophysicist","ghostwriter, ghost","gibson_girl","girl, miss, missy, young_lady, young_woman, fille","girlfriend, girl, lady_friend","girlfriend","girl_wonder","girondist, girondin","gitano","gladiator","glassblower","gleaner","goat_herder, goatherd","godchild","godfather","godparent","godson","gofer","goffer, gopher","goldsmith, goldworker, gold-worker","golfer, golf_player, linksman","gondolier, gondoliere","good_guy","good_old_boy, good_ole_boy, good_ol'_boy","good_samaritan","gossip_columnist","gouger","governor_general","grabber","grader","graduate_nurse, trained_nurse","grammarian, syntactician","granddaughter","grande_dame","grandfather, gramps, granddad, grandad, granddaddy, grandpa","grand_inquisitor","grandma, grandmother, granny, grannie, gran, nan, nanna","grandmaster","grandparent","grantee","granter","grass_widower, divorced_man","great-aunt, grandaunt","great_grandchild","great_granddaughter","great_grandmother","great_grandparent","great_grandson","great-nephew, grandnephew","great-niece, grandniece","green_beret","grenadier, grenade_thrower","greeter, saluter, welcomer","gringo","grinner","grocer","groom, bridegroom","groom, bridegroom","grouch, grump, crank, churl, crosspatch","group_captain","grunter","prison_guard, jailer, jailor, gaoler, screw, turnkey","guard","guesser","guest, invitee","guest","guest_of_honor","guest_worker, guestworker","guide","guitarist, guitar_player","gunnery_sergeant","guru","guru","guvnor","guy, cat, hombre, bozo","gymnast","gym_rat","gynecologist, gynaecologist, woman's_doctor","gypsy, gipsy, romany, rommany, romani, roma, bohemian","hack, drudge, hacker","hacker, cyber-terrorist, cyberpunk","haggler","hairdresser, hairstylist, stylist, styler","hakim, hakeem","hakka","halberdier","halfback","half_blood","hand","animal_trainer, handler","handyman, jack_of_all_trades, odd-job_man","hang_glider","hardliner","harlequin","harmonizer, harmoniser","hash_head","hatchet_man, iceman","hater","hatmaker, hatter, milliner, modiste","headman, tribal_chief, chieftain, chief","headmaster, schoolmaster, master","head_nurse","hearer, listener, auditor, attender","heartbreaker","heathen, pagan, gentile, infidel","heavyweight","heavy","heckler, badgerer","hedger","hedger, equivocator, tergiversator","hedonist, pagan, pleasure_seeker","heir, inheritor, heritor","heir_apparent","heiress, inheritress, inheritrix","heir_presumptive","hellion, heller, devil","helmsman, steersman, steerer","hire","hematologist, haematologist","hemiplegic","herald, trumpeter","herbalist, herb_doctor","herder, herdsman, drover","hermaphrodite, intersex, gynandromorph, androgyne, epicene, epicene_person","heroine","heroin_addict","hero_worshiper, hero_worshipper","herr","highbinder","highbrow","high_commissioner","highflier, highflyer","highlander, scottish_highlander, highland_scot","high-muck-a-muck, pooh-bah","high_priest","highjacker, hijacker","hireling, pensionary","historian, historiographer","hitchhiker","hitter, striker","hobbyist","holdout","holdover, hangover","holdup_man, stickup_man","homeboy","homeboy","home_buyer","homegirl","homeless, homeless_person","homeopath, homoeopath","honest_woman","honor_guard, guard_of_honor","hooker","hoper","hornist","horseman, equestrian, horseback_rider","horse_trader","horsewoman","horse_wrangler, wrangler","horticulturist, plantsman","hospital_chaplain","host, innkeeper, boniface","host","hostess","hotelier, hotelkeeper, hotel_manager, hotelman, hosteller","housekeeper","housemaster","housemate","house_physician, resident, resident_physician","house_sitter","housing_commissioner","huckster, cheap-jack","hugger","humanist, humanitarian","humanitarian, do-gooder, improver","hunk","huntress","ex-husband, ex","hydrologist","hyperope","hypertensive","hypnotist, hypnotizer, hypnotiser, mesmerist, mesmerizer","hypocrite, dissembler, dissimulator, phony, phoney, pretender","iceman","iconoclast","ideologist, ideologue","idol, matinee_idol","idolizer, idoliser","imam, imaum","imperialist","important_person, influential_person, personage","inamorato","incumbent, officeholder","incurable","inductee","industrialist","infanticide","inferior","infernal","infielder","infiltrator","informer, betrayer, rat, squealer, blabber","ingenue","ingenue","polymath","in-law, relative-in-law","inquiry_agent","inspector","inspector_general","instigator, initiator","insurance_broker, insurance_agent, general_agent, underwriter","insurgent, insurrectionist, freedom_fighter, rebel","intelligence_analyst","interior_designer, designer, interior_decorator, house_decorator, room_decorator, decorator","interlocutor, conversational_partner","interlocutor, middleman","international_grandmaster","internationalist","internist","interpreter, translator","interpreter","intervenor","introvert","invader, encroacher","invalidator, voider, nullifier","investigator","investor","invigilator","irreligionist","ivy_leaguer","jack_of_all_trades","jacksonian","jane_doe","janissary","jat","javanese, javan","jekyll_and_hyde","jester, fool, motley_fool","jesuit","jezebel","jilt","jobber, middleman, wholesaler","job_candidate","job's_comforter","jockey","john_doe","journalist","judge, justice, jurist","judge_advocate","juggler","jungian","junior","junior","junior, jr, jnr","junior_lightweight","junior_middleweight","jurist, legal_expert","juror, juryman, jurywoman","justice_of_the_peace","justiciar, justiciary","kachina","keyboardist","khedive","kingmaker","king, queen, world-beater","king's_counsel","counsel_to_the_crown","kin, kinsperson, family","enate, matrikin, matrilineal_kin, matrisib, matrilineal_sib","kink","kinswoman","kisser, osculator","kitchen_help","kitchen_police, kp","klansman, ku_kluxer, kluxer","kleptomaniac","kneeler","knight","knocker","knower, apprehender","know-it-all, know-all","kolkhoznik","kshatriya","labor_coach, birthing_coach, doula, monitrice","laborer, manual_laborer, labourer, jack","labourite","lady","lady-in-waiting","lady's_maid","lama","lamb, dear","lame_duck","lamplighter","land_agent","landgrave","landlubber, lubber, landsman","landlubber, landsman, landman","landowner, landholder, property_owner","landscape_architect, landscape_gardener, landscaper, landscapist","langlaufer","languisher","lapidary, lapidarist","lass, lassie, young_girl, jeune_fille","latin","latin","latitudinarian","jehovah's_witness","law_agent","lawgiver, lawmaker","lawman, law_officer, peace_officer","law_student","lawyer, attorney","lay_reader","lazybones","leaker","leaseholder, lessee","lector, lecturer, reader","lector, reader","lecturer","left-hander, lefty, southpaw","legal_representative","legate, official_emissary","legatee","legionnaire, legionary","letterman","liberator","licenser","licentiate","lieutenant","lieutenant_colonel, light_colonel","lieutenant_commander","lieutenant_junior_grade, lieutenant_jg","life","lifeguard, lifesaver","life_tenant","light_flyweight","light_heavyweight, cruiserweight","light_heavyweight","light-o'-love, light-of-love","lightweight","lightweight","lightweight","lilliputian","limnologist","lineman","line_officer","lion-hunter","lisper","lister","literary_critic","literate, literate_person","litigant, litigator","litterer, litterbug, litter_lout","little_brother","little_sister","lobbyist","locksmith","locum_tenens, locum","lord, noble, nobleman","loser","loser, also-ran","failure, loser, nonstarter, unsuccessful_person","lothario","loudmouth, blusterer","lowerclassman, underclassman","lowlander, scottish_lowlander, lowland_scot","loyalist, stalwart","luddite","lumberman, lumberjack, logger, feller, faller","lumper","bedlamite","pyromaniac","lutist, lutanist, lutenist","lutheran","lyricist, lyrist","macebearer, mace, macer","machinist, mechanic, shop_mechanic","madame","maenad","maestro, master","magdalen","magician, prestidigitator, conjurer, conjuror, illusionist","magus","maharani, maharanee","mahatma","maid, maiden","maid, maidservant, housemaid, amah","major","major","major-domo, seneschal","maker, shaper","malahini","malcontent","malik","malingerer, skulker, shammer","malthusian","adonis","man","man","manageress","mandarin","maneuverer, manoeuvrer","maniac","manichaean, manichean, manichee","manicurist","manipulator","man-at-arms","man_of_action, man_of_deeds","man_of_letters","manufacturer, producer","marcher, parader","marchioness, marquise","margrave","margrave","marine, devil_dog, leatherneck, shipboard_soldier","marquess","marquis, marquess","marshal, marshall","martinet, disciplinarian, moralist","mascot","masochist","mason, stonemason","masquerader, masker, masquer","masseur","masseuse","master","master, captain, sea_captain, skipper","master-at-arms","master_of_ceremonies, emcee, host","masturbator, onanist","matchmaker, matcher, marriage_broker","mate, first_mate","mate","mate","mater","material","materialist","matriarch, materfamilias","matriarch","matriculate","matron","mayor, city_manager","mayoress","mechanical_engineer","medalist, medallist, medal_winner","medical_officer, medic","medical_practitioner, medical_man","medical_scientist","medium, spiritualist, sensitive","megalomaniac","melancholic, melancholiac","melkite, melchite","melter","nonmember","board_member","clansman, clanswoman, clan_member","memorizer, memoriser","mendelian","mender, repairer, fixer","mesoamerican","messmate","mestiza","meteorologist","meter_maid","methodist","metis","metropolitan","mezzo-soprano, mezzo","microeconomist, microeconomic_expert","middle-aged_man","middlebrow","middleweight","midwife, accoucheuse","mikado, tenno","milanese","miler","miles_gloriosus","military_attache","military_chaplain, padre, holy_joe, sky_pilot","military_leader","military_officer, officer","military_policeman, mp","mill_agent","mill-hand, factory_worker","millionairess","millwright","minder","mining_engineer","minister, government_minister","ministrant","minor_leaguer, bush_leaguer","minuteman","misanthrope, misanthropist","misfit","mistress","mistress, kept_woman, fancy_woman","mixed-blood","model, poser","class_act","modeler, modeller","modifier","molecular_biologist","monegasque, monacan","monetarist","moneygrubber","moneymaker","mongoloid","monolingual","monologist","moonlighter","moralist","morosoph","morris_dancer","mortal_enemy","mortgagee, mortgage_holder","mortician, undertaker, funeral_undertaker, funeral_director","moss-trooper","mother, female_parent","mother","mother","mother_figure","mother_hen","mother-in-law","mother's_boy, mamma's_boy, mama's_boy","mother's_daughter","motorcycle_cop, motorcycle_policeman, speed_cop","motorcyclist","mound_builder","mountebank, charlatan","mourner, griever, sorrower, lamenter","mouthpiece, mouth","mover","moviegoer, motion-picture_fan","muffin_man","mugwump, independent, fencesitter","mullah, mollah, mulla","muncher","murderess","murder_suspect","musher","musician, instrumentalist, player","musicologist","music_teacher","musketeer","muslimah","mutilator, maimer, mangler","mutineer","mute, deaf-mute, deaf-and-dumb_person","mutterer, mumbler, murmurer","muzzler","mycenaen","mycologist","myope","myrmidon","mystic, religious_mystic","mythologist","naif","nailer","namby-pamby","name_dropper","namer","nan","nanny, nursemaid, nurse","narc, nark, narcotics_agent","narcissist, narcist","nark, copper's_nark","nationalist","nautch_girl","naval_commander","navy_seal, seal","obstructionist, obstructor, obstructer, resister, thwarter","nazarene","nazarene, ebionite","nazi, german_nazi","nebbish, nebbech","necker","neonate, newborn, newborn_infant, newborn_baby","nephew","neurobiologist","neurologist, brain_doctor","neurosurgeon, brain_surgeon","neutral","neutralist","newcomer, fledgling, fledgeling, starter, neophyte, freshman, newbie, entrant","newcomer","new_dealer","newspaper_editor","newsreader, news_reader","newtonian","niece","niggard, skinflint, scrooge, churl","night_porter","night_rider, nightrider","nimby","niqaabi","nitpicker","nobelist, nobel_laureate","noc","noncandidate","noncommissioned_officer, noncom, enlisted_officer","nondescript","nondriver","nonparticipant","nonperson, unperson","nonresident","nonsmoker","northern_baptist","noticer","novelist","novitiate, novice","nuclear_chemist, radiochemist","nudger","nullipara","number_theorist","nurse","nursling, nurseling, suckling","nymph, houri","nymphet","nympholept","nymphomaniac, nympho","oarswoman","oboist","obscurantist","observer, commentator","obstetrician, accoucheur","occupier","occultist","wine_lover","offerer, offeror","office-bearer","office_boy","officeholder, officer","officiant","federal, fed, federal_official","oilman","oil_tycoon","old-age_pensioner","old_boy","old_lady","old_man","oldster, old_person, senior_citizen, golden_ager","old-timer, oldtimer, gaffer, old_geezer, antique","old_woman","oligarch","olympian","omnivore","oncologist","onlooker, looker-on","onomancer","operator","opportunist, self-seeker","optimist","orangeman","orator, speechmaker, rhetorician, public_speaker, speechifier","orderly, hospital_attendant","orderly","orderly_sergeant","ordinand","ordinary","organ-grinder","organist","organization_man","organizer, organiser, arranger","organizer, organiser, labor_organizer","originator, conceiver, mastermind","ornithologist, bird_watcher","orphan","orphan","osteopath, osteopathist","out-and-outer","outdoorswoman","outfielder","outfielder","right_fielder","right-handed_pitcher, right-hander","outlier","owner-occupier","oyabun","packrat","padrone","padrone","page, pageboy","painter","paleo-american, paleo-amerind, paleo-indian","paleontologist, palaeontologist, fossilist","pallbearer, bearer","palmist, palmister, chiromancer","pamperer, spoiler, coddler, mollycoddler","panchen_lama","panelist, panellist","panhandler","paparazzo","paperboy","paperhanger, paperer","paperhanger","papoose, pappoose","pardoner","paretic","parishioner","park_commissioner","parliamentarian, member_of_parliament","parliamentary_agent","parodist, lampooner","parricide","parrot","partaker, sharer","part-timer","party","party_man, party_liner","passenger, rider","passer","paster","pater","patient","patriarch","patriarch","patriarch, paterfamilias","patriot, nationalist","patron, sponsor, supporter","patternmaker","pawnbroker","payer, remunerator","peacekeeper","peasant","pedant, bookworm, scholastic","peddler, pedlar, packman, hawker, pitchman","pederast, paederast, child_molester","penologist","pentathlete","pentecostal, pentecostalist","percussionist","periodontist","peshmerga","personality","personal_representative","personage","persona_grata","persona_non_grata","personification","perspirer, sweater","pervert, deviant, deviate, degenerate","pessimist","pest, blighter, cuss, pesterer, gadfly","peter_pan","petitioner, suppliant, supplicant, requester","petit_juror, petty_juror","pet_sitter, critter_sitter","petter, fondler","pharaoh, pharaoh_of_egypt","pharmacist, druggist, chemist, apothecary, pill_pusher, pill_roller","philanthropist, altruist","philatelist, stamp_collector","philosopher","phonetician","phonologist","photojournalist","photometrist, photometrician","physical_therapist, physiotherapist","physicist","piano_maker","picker, chooser, selector","picnicker, picknicker","pilgrim","pill","pillar, mainstay","pill_head","pilot","piltdown_man, piltdown_hoax","pimp, procurer, panderer, pander, pandar, fancy_man, ponce","pipe_smoker","pip-squeak, squirt, small_fry","pisser, urinator","pitcher, hurler, twirler","pitchman","placeman, placeseeker","placer_miner","plagiarist, plagiarizer, plagiariser, literary_pirate, pirate","plainsman","planner, contriver, deviser","planter, plantation_owner","plasterer","platinum_blond, platinum_blonde","platitudinarian","playboy, man-about-town, corinthian","player, participant","playmate, playfellow","pleaser","pledger","plenipotentiary","plier, plyer","plodder, slowpoke, stick-in-the-mud, slowcoach","plodder, slogger","plotter, mapper","plumber, pipe_fitter","pluralist","pluralist","poet","pointsman","point_woman","policyholder","political_prisoner","political_scientist","politician, politico, pol, political_leader","politician","pollster, poll_taker, headcounter, canvasser","polluter, defiler","pool_player","portraitist, portrait_painter, portrayer, limner","poseuse","positivist, rationalist","postdoc, post_doc","poster_girl","postulator","private_citizen","problem_solver, solver, convergent_thinker","pro-lifer","prosthetist","postulant","potboy, potman","poultryman, poulterer","power_user","power_worker, power-station_worker","practitioner, practician","prayer, supplicant","preceptor, don","predecessor","preemptor, pre-emptor","preemptor, pre-emptor","premature_baby, preterm_baby, premature_infant, preterm_infant, preemie, premie","presbyter","presenter, sponsor","presentist","preserver","president","president_of_the_united_states, united_states_president, president, chief_executive","president, prexy","press_agent, publicity_man, public_relations_man, pr_man","press_photographer","priest","prima_ballerina","prima_donna, diva","prima_donna","primigravida, gravida_i","primordial_dwarf, hypoplastic_dwarf, true_dwarf, normal_dwarf","prince_charming","prince_consort","princeling","prince_of_wales","princess","princess_royal","principal, dealer","principal, school_principal, head_teacher, head","print_seller","prior","private, buck_private, common_soldier","probationer, student_nurse","processor","process-server","proconsul","proconsul","proctologist","proctor, monitor","procurator","procurer, securer","profit_taker","programmer, computer_programmer, coder, software_engineer","promiser, promisor","promoter, booster, plugger","promulgator","propagandist","propagator, disseminator","property_man, propman, property_master","prophetess","prophet","prosecutor, public_prosecutor, prosecuting_officer, prosecuting_attorney","prospector","protectionist","protegee","protozoologist","provost_marshal","pruner, trimmer","psalmist","psephologist","psychiatrist, head-shrinker, shrink","psychic","psycholinguist","psychophysicist","publican, tavern_keeper","pudge","puerpera","punching_bag","punter","punter","puppeteer","puppy, pup","purchasing_agent","puritan","puritan","pursuer","pusher, shover","pusher, drug_peddler, peddler, drug_dealer, drug_trafficker","pusher, thruster","putz","pygmy, pigmy","qadi","quadriplegic","quadruplet, quad","quaker, trembler","quarter","quarterback, signal_caller, field_general","quartermaster","quartermaster_general","quebecois","queen, queen_regnant, female_monarch","queen_of_england","queen","queen","queen_consort","queen_mother","queen's_counsel","question_master, quizmaster","quick_study, sponge","quietist","quitter","rabbi","racist, racialist","radiobiologist","radiologic_technologist","radiologist, radiotherapist","rainmaker","raiser","raja, rajah","rake, rakehell, profligate, rip, blood, roue","ramrod","ranch_hand","ranker","ranter, raver","rape_suspect","rapper","rapporteur","rare_bird, rara_avis","ratepayer","raw_recruit","reader","reading_teacher","realist","real_estate_broker, real_estate_agent, estate_agent, land_agent, house_agent","rear_admiral","receiver","reciter","recruit, enlistee","recruit, military_recruit","recruiter","recruiting-sergeant","redcap","redhead, redheader, red-header, carrottop","redneck, cracker","reeler","reenactor","referral","referee, ref","refiner","reform_jew","registered_nurse, rn","registrar","regius_professor","reliever, allayer, comforter","anchorite, hermit","religious_leader","remover","renaissance_man, generalist","renegade","rentier","repairman, maintenance_man, service_man","reporter, newsman, newsperson","newswoman","representative","reprobate, miscreant","rescuer, recoverer, saver","reservist","resident_commissioner","respecter","restaurateur, restauranter","restrainer, controller","retailer, retail_merchant","retiree, retired_person","returning_officer","revenant","revisionist","revolutionist, revolutionary, subversive, subverter","rheumatologist","rhodesian_man, homo_rhodesiensis","rhymer, rhymester, versifier, poetizer, poetiser","rich_person, wealthy_person, have","rider","riding_master","rifleman","right-hander, right_hander, righthander","right-hand_man, chief_assistant, man_friday","ringer","ringleader","roadman, road_mender","roarer, bawler, bellower, screamer, screecher, shouter, yeller","rocket_engineer, rocket_scientist","rocket_scientist","rock_star","romanov, romanoff","romanticist, romantic","ropemaker, rope-maker, roper","roper","roper","ropewalker, ropedancer","rosebud","rosicrucian","mountie","rough_rider","roundhead","civil_authority, civil_officer","runner","runner","runner","running_back","rusher","rustic","saboteur, wrecker, diversionist","sadist","sailing_master, navigator","sailor, crewman","salesgirl, saleswoman, saleslady","salesman","salesperson, sales_representative, sales_rep","salvager, salvor","sandwichman","sangoma","sannup","sapper","sassenach","satrap","saunterer, stroller, ambler","savoyard","sawyer","scalper","scandalmonger","scapegrace, black_sheep","scene_painter","schemer, plotter","schizophrenic","schlemiel, shlemiel","schlockmeister, shlockmeister","scholar, scholarly_person, bookman, student","scholiast","schoolchild, school-age_child, pupil","schoolfriend","schoolman, medieval_schoolman","schoolmaster","schoolmate, classmate, schoolfellow, class_fellow","scientist","scion","scoffer, flouter, mocker, jeerer","scofflaw","scorekeeper, scorer","scorer","scourer","scout, talent_scout","scoutmaster","scrambler","scratcher","screen_actor, movie_actor","scrutineer, canvasser","scuba_diver","sculptor, sculpturer, carver, statue_maker","sea_scout","seasonal_worker, seasonal","seasoner","second_baseman, second_sacker","second_cousin","seconder","second_fiddle, second_banana","second-in-command","second_lieutenant, 2nd_lieutenant","second-rater, mediocrity","secretary","secretary_of_agriculture, agriculture_secretary","secretary_of_health_and_human_services","secretary_of_state","secretary_of_the_interior, interior_secretary","sectarian, sectary, sectarist","section_hand","secularist","security_consultant","seeded_player, seed","seeder, cloud_seeder","seeker, searcher, quester","segregate","segregator, segregationist","selectman","selectwoman","selfish_person","self-starter","seller, marketer, vender, vendor, trafficker","selling_agent","semanticist, semiotician","semifinalist","seminarian, seminarist","senator","sendee","senior","senior_vice_president","separatist, separationist","septuagenarian","serf, helot, villein","spree_killer","serjeant-at-law, serjeant, sergeant-at-law, sergeant","server","serviceman, military_man, man, military_personnel","settler, colonist","settler","sex_symbol","sexton, sacristan","shaheed","shakespearian, shakespearean","shanghaier, seizer","sharecropper, cropper, sharecrop_farmer","shaver","shavian","sheep","sheik, tribal_sheik, sheikh, tribal_sheikh, arab_chief","shelver","shepherd","ship-breaker","shipmate","shipowner","shipping_agent","shirtmaker","shogun","shopaholic","shop_girl","shop_steward, steward","shot_putter","shrew, termagant","shuffler","shyster, pettifogger","sibling, sib","sick_person, diseased_person, sufferer","sightreader","signaler, signaller","signer","signor, signior","signora","signore","signorina","silent_partner, sleeping_partner","addle-head, addlehead, loon, birdbrain","simperer","singer, vocalist, vocalizer, vocaliser","sinologist","sipper","sirrah","sister","sister, sis","waverer, vacillator, hesitator, hesitater","sitar_player","sixth-former","skateboarder","skeptic, sceptic, doubter","sketcher","skidder","skier","skinny-dipper","skin-diver, aquanaut","skinhead","slasher","slattern, slut, slovenly_woman, trollop","sleeper, slumberer","sleeper","sleeping_beauty","sleuth, sleuthhound","slob, sloven, pig, slovenly_person","sloganeer","slopseller, slop-seller","smasher, stunner, knockout, beauty, ravisher, sweetheart, peach, lulu, looker, mantrap, dish","smirker","smith, metalworker","smoothie, smoothy, sweet_talker, charmer","smuggler, runner, contrabandist, moon_curser, moon-curser","sneezer","snob, prig, snot, snoot","snoop, snooper","snorer","sob_sister","soccer_player","social_anthropologist, cultural_anthropologist","social_climber, climber","socialist","socializer, socialiser","social_scientist","social_secretary","socinian","sociolinguist","sociologist","soda_jerk, soda_jerker","sodalist","sodomite, sodomist, sod, bugger","soldier","son, boy","songster","songstress","songwriter, songster, ballad_maker","sorcerer, magician, wizard, necromancer, thaumaturge, thaumaturgist","sorehead","soul_mate","southern_baptist","sovereign, crowned_head, monarch","spacewalker","spanish_american, hispanic_american, hispanic","sparring_partner, sparring_mate","spastic","speaker, talker, utterer, verbalizer, verbaliser","native_speaker","speaker","speechwriter","specialist, medical_specialist","specifier","spectator, witness, viewer, watcher, looker","speech_therapist","speedskater, speed_skater","spellbinder","sphinx","spinster, old_maid","split_end","sport, sportsman, sportswoman","sport, summercater","sporting_man, outdoor_man","sports_announcer, sportscaster, sports_commentator","sports_editor","sprog","square_dancer","square_shooter, straight_shooter, straight_arrow","squatter","squire","squire","staff_member, staffer","staff_sergeant","stage_director","stainer","stakeholder","stalker","stalking-horse","stammerer, stutterer","stamper, stomper, tramper, trampler","standee","stand-in, substitute, relief, reliever, backup, backup_man, fill-in","star, principal, lead","starlet","starter, dispatcher","statesman, solon, national_leader","state_treasurer","stationer, stationery_seller","stenographer, amanuensis, shorthand_typist","stentor","stepbrother, half-brother, half_brother","stepmother","stepparent","stevedore, loader, longshoreman, docker, dockhand, dock_worker, dockworker, dock-walloper, lumper","steward","steward, flight_attendant","steward","stickler","stiff","stifler, smotherer","stipendiary, stipendiary_magistrate","stitcher","stockjobber","stock_trader","stockist","stoker, fireman","stooper","store_detective","strafer","straight_man, second_banana","stranger, alien, unknown","stranger","strategist, strategian","straw_boss, assistant_foreman","streetwalker, street_girl, hooker, hustler, floozy, floozie, slattern","stretcher-bearer, litter-bearer","struggler","stud, he-man, macho-man","student, pupil, educatee","stumblebum, palooka","stylist","subaltern","subcontractor","subduer, surmounter, overcomer","subject, case, guinea_pig","subordinate, subsidiary, underling, foot_soldier","substitute, reserve, second-stringer","successor, heir","successor, replacement","succorer, succourer","sufi","suffragan, suffragan_bishop","suffragette","sugar_daddy","suicide_bomber","suitor, suer, wooer","sumo_wrestler","sunbather","sundowner","super_heavyweight","superior, higher-up, superordinate","supermom","supernumerary, spear_carrier, extra","supremo","surgeon, operating_surgeon, sawbones","surgeon_general","surgeon_general","surpriser","surveyor","surveyor","survivor, subsister","sutler, victualer, victualler, provisioner","sweeper","sweetheart, sweetie, steady, truelove","swinger, tramp","switcher, whipper","swot, grind, nerd, wonk, dweeb","sycophant, toady, crawler, lackey, ass-kisser","sylph","sympathizer, sympathiser, well-wisher","symphonist","syncopator","syndic","tactician","tagger","tailback","tallyman, tally_clerk","tallyman","tanker, tank_driver","tapper, wiretapper, phone_tapper","tartuffe, tartufe","tarzan","taster, taste_tester, taste-tester, sampler","tax_assessor, assessor","taxer","taxi_dancer","taxonomist, taxonomer, systematist","teacher, instructor","teaching_fellow","tearaway","technical_sergeant","technician","ted, teddy_boy","teetotaler, teetotaller, teetotalist","television_reporter, television_newscaster, tv_reporter, tv_newsman","temporizer, temporiser","tempter","term_infant","toiler","tenant, renter","tenant","tenderfoot","tennis_player","tennis_pro, professional_tennis_player","tenor_saxophonist, tenorist","termer","terror, scourge, threat","tertigravida, gravida_iii","testator, testate","testatrix","testee, examinee","test-tube_baby","texas_ranger, ranger","thane","theatrical_producer","theologian, theologist, theologizer, theologiser","theorist, theoretician, theorizer, theoriser, idealogue","theosophist","therapist, healer","thessalonian","thinker, creative_thinker, mind","thinker","thrower","thurifer","ticket_collector, ticket_taker","tight_end","tiler","timekeeper, timer","timorese","tinkerer, fiddler","tinsmith, tinner","tinter","tippler, social_drinker","tipster, tout","t-man","toastmaster, symposiarch","toast_mistress","tobogganist","tomboy, romp, hoyden","toolmaker","torchbearer","tory","tory","tosser","tosser, jerk-off, wanker","totalitarian","tourist, tourer, holidaymaker","tout, touter","tout, ticket_tout","tovarich, tovarisch","towhead","town_clerk","town_crier, crier","townsman, towner","toxicologist","track_star","trader, bargainer, dealer, monger","trade_unionist, unionist, union_member","traditionalist, diehard","traffic_cop","tragedian","tragedian","tragedienne","trail_boss","trainer","traitor, treasonist","traitress","transactor","transcriber","transfer, transferee","transferee","translator, transcriber","transvestite, cross-dresser","traveling_salesman, travelling_salesman, commercial_traveler, commercial_traveller, roadman, bagman","traverser","trawler","treasury, first_lord_of_the_treasury","trencher","trend-setter, taste-maker, fashion_arbiter","tribesman","trier, attempter, essayer","trifler","trooper","trooper, state_trooper","trotskyite, trotskyist, trot","truant, hooky_player","trumpeter, cornetist","trusty","tudor","tumbler","tutee","twin","two-timer","tyke","tympanist, timpanist","typist","tyrant, autocrat, despot","umpire, ump","understudy, standby","undesirable","unicyclist","unilateralist","unitarian","arminian","universal_donor","unix_guru","unknown_soldier","upsetter","upstager","upstart, parvenu, nouveau-riche, arriviste","upstart","urchin","urologist","usherette","usher, doorkeeper","usurper, supplanter","utility_man","utilizer, utiliser","utopian","uxoricide","vacationer, vacationist","valedictorian, valedictory_speaker","valley_girl","vaulter, pole_vaulter, pole_jumper","vegetarian","vegan","venerator","venture_capitalist","venturer, merchant-venturer","vermin, varmint","very_important_person, vip, high-up, dignitary, panjandrum, high_muckamuck","vibist, vibraphonist","vicar","vicar","vicar-general","vice_chancellor","vicegerent","vice_president, v.p.","vice-regent","victim, dupe","victorian","victualer, victualler","vigilante, vigilance_man","villager","vintager","vintner, wine_merchant","violator, debaucher, ravisher","violator, lawbreaker, law_offender","violist","virago","virologist","visayan, bisayan","viscountess","viscount","visigoth","visionary","visiting_fireman","visiting_professor","visualizer, visualiser","vixen, harpy, hellcat","vizier","voicer","volunteer, unpaid_worker","volunteer, military_volunteer, voluntary","votary","votary","vouchee","vower","voyager","voyeur, peeping_tom, peeper","vulcanizer, vulcaniser","waffler","wagnerian","waif, street_child","wailer","waiter, server","waitress","walking_delegate","walk-on","wallah","wally","waltzer","wanderer, roamer, rover, bird_of_passage","wandering_jew","wanton","warrantee","warrantee","washer","washerman, laundryman","washwoman, washerwoman, laundrywoman, laundress","wassailer, carouser","wastrel, waster","wave","weatherman, weather_forecaster","weekend_warrior","weeder","welder","welfare_case, charity_case","westerner","west-sider","wetter","whaler","whig","whiner, complainer, moaner, sniveller, crybaby, bellyacher, grumbler, squawker","whipper-in","whisperer","whiteface","carmelite, white_friar","augustinian","white_hope, great_white_hope","white_supremacist","whoremaster, whoremonger","whoremaster, whoremonger, john, trick","widow, widow_woman","wife, married_woman","wiggler, wriggler, squirmer","wimp, chicken, crybaby","wing_commander","winger","winner","winner, victor","window_dresser, window_trimmer","winker","wiper","wireman, wirer","wise_guy, smart_aleck, wiseacre, wisenheimer, weisenheimer","witch_doctor","withdrawer","withdrawer","woman, adult_female","woman","wonder_boy, golden_boy","wonderer","working_girl","workman, workingman, working_man, working_person","workmate","worldling","worshiper, worshipper","worthy","wrecker","wright","write-in_candidate, write-in","writer, author","wykehamist","yakuza","yard_bird, yardbird","yardie","yardman","yardmaster, trainmaster, train_dispatcher","yenta","yogi","young_buck, young_man","young_turk","young_turk","zionist","zoo_keeper","genet, edmund_charles_edouard_genet, citizen_genet","kennan, george_f._kennan, george_frost_kennan","munro, h._h._munro, hector_hugh_munro, saki","popper, karl_popper, sir_karl_raimund_popper","stoker, bram_stoker, abraham_stoker","townes, charles_townes, charles_hard_townes","dust_storm, duster, sandstorm, sirocco","parhelion, mock_sun, sundog","snow, snowfall","facula","wave","microflora","wilding","semi-climber","volva","basidiocarp","domatium","apomict","aquatic","bryophyte, nonvascular_plant","acrocarp, acrocarpous_moss","sphagnum, sphagnum_moss, peat_moss, bog_moss","liverwort, hepatic","hepatica, marchantia_polymorpha","pecopteris","pteridophyte, nonflowering_plant","fern","fern_ally","spore","carpospore","chlamydospore","conidium, conidiospore","oospore","tetraspore","zoospore","cryptogam","spermatophyte, phanerogam, seed_plant","seedling","annual","biennial","perennial","hygrophyte","gymnosperm","gnetum, gnetum_gnemon","catha_edulis","ephedra, joint_fir","mahuang, ephedra_sinica","welwitschia, welwitschia_mirabilis","cycad","sago_palm, cycas_revoluta","false_sago, fern_palm, cycas_circinalis","zamia","coontie, florida_arrowroot, seminole_bread, zamia_pumila","ceratozamia","dioon","encephalartos","kaffir_bread, encephalartos_caffer","macrozamia","burrawong, macrozamia_communis, macrozamia_spiralis","pine, pine_tree, true_pine","pinon, pinyon","nut_pine","pinon_pine, mexican_nut_pine, pinus_cembroides","rocky_mountain_pinon, pinus_edulis","single-leaf, single-leaf_pine, single-leaf_pinyon, pinus_monophylla","bishop_pine, bishop's_pine, pinus_muricata","california_single-leaf_pinyon, pinus_californiarum","parry's_pinyon, pinus_quadrifolia, pinus_parryana","spruce_pine, pinus_glabra","black_pine, pinus_nigra","pitch_pine, northern_pitch_pine, pinus_rigida","pond_pine, pinus_serotina","stone_pine, umbrella_pine, european_nut_pine, pinus_pinea","swiss_pine, swiss_stone_pine, arolla_pine, cembra_nut_tree, pinus_cembra","cembra_nut, cedar_nut","swiss_mountain_pine, mountain_pine, dwarf_mountain_pine, mugho_pine, mugo_pine, pinus_mugo","ancient_pine, pinus_longaeva","white_pine","american_white_pine, eastern_white_pine, weymouth_pine, pinus_strobus","western_white_pine, silver_pine, mountain_pine, pinus_monticola","southwestern_white_pine, pinus_strobiformis","limber_pine, pinus_flexilis","whitebark_pine, whitebarked_pine, pinus_albicaulis","yellow_pine","ponderosa, ponderosa_pine, western_yellow_pine, bull_pine, pinus_ponderosa","jeffrey_pine, jeffrey's_pine, black_pine, pinus_jeffreyi","shore_pine, lodgepole, lodgepole_pine, spruce_pine, pinus_contorta","sierra_lodgepole_pine, pinus_contorta_murrayana","loblolly_pine, frankincense_pine, pinus_taeda","jack_pine, pinus_banksiana","swamp_pine","longleaf_pine, pitch_pine, southern_yellow_pine, georgia_pine, pinus_palustris","shortleaf_pine, short-leaf_pine, shortleaf_yellow_pine, pinus_echinata","red_pine, canadian_red_pine, pinus_resinosa","scotch_pine, scots_pine, scotch_fir, pinus_sylvestris","scrub_pine, virginia_pine, jersey_pine, pinus_virginiana","monterey_pine, pinus_radiata","bristlecone_pine, rocky_mountain_bristlecone_pine, pinus_aristata","table-mountain_pine, prickly_pine, hickory_pine, pinus_pungens","knobcone_pine, pinus_attenuata","japanese_red_pine, japanese_table_pine, pinus_densiflora","japanese_black_pine, black_pine, pinus_thunbergii","torrey_pine, torrey's_pine, soledad_pine, grey-leaf_pine, sabine_pine, pinus_torreyana","larch, larch_tree","american_larch, tamarack, black_larch, larix_laricina","western_larch, western_tamarack, oregon_larch, larix_occidentalis","subalpine_larch, larix_lyallii","european_larch, larix_decidua","siberian_larch, larix_siberica, larix_russica","golden_larch, pseudolarix_amabilis","fir, fir_tree, true_fir","silver_fir","amabilis_fir, white_fir, pacific_silver_fir, red_silver_fir, christmas_tree, abies_amabilis","european_silver_fir, christmas_tree, abies_alba","white_fir, colorado_fir, california_white_fir, abies_concolor, abies_lowiana","balsam_fir, balm_of_gilead, canada_balsam, abies_balsamea","fraser_fir, abies_fraseri","lowland_fir, lowland_white_fir, giant_fir, grand_fir, abies_grandis","alpine_fir, subalpine_fir, abies_lasiocarpa","santa_lucia_fir, bristlecone_fir, abies_bracteata, abies_venusta","cedar, cedar_tree, true_cedar","cedar_of_lebanon, cedrus_libani","deodar, deodar_cedar, himalayan_cedar, cedrus_deodara","atlas_cedar, cedrus_atlantica","spruce","norway_spruce, picea_abies","weeping_spruce, brewer's_spruce, picea_breweriana","engelmann_spruce, engelmann's_spruce, picea_engelmannii","white_spruce, picea_glauca","black_spruce, picea_mariana, spruce_pine","siberian_spruce, picea_obovata","sitka_spruce, picea_sitchensis","oriental_spruce, picea_orientalis","colorado_spruce, colorado_blue_spruce, silver_spruce, picea_pungens","red_spruce, eastern_spruce, yellow_spruce, picea_rubens","hemlock, hemlock_tree","eastern_hemlock, canadian_hemlock, spruce_pine, tsuga_canadensis","carolina_hemlock, tsuga_caroliniana","mountain_hemlock, black_hemlock, tsuga_mertensiana","western_hemlock, pacific_hemlock, west_coast_hemlock, tsuga_heterophylla","douglas_fir","green_douglas_fir, douglas_spruce, douglas_pine, douglas_hemlock, oregon_fir, oregon_pine, pseudotsuga_menziesii","big-cone_spruce, big-cone_douglas_fir, pseudotsuga_macrocarpa","cathaya","cedar, cedar_tree","cypress, cypress_tree","gowen_cypress, cupressus_goveniana","pygmy_cypress, cupressus_pigmaea, cupressus_goveniana_pigmaea","santa_cruz_cypress, cupressus_abramsiana, cupressus_goveniana_abramsiana","arizona_cypress, cupressus_arizonica","guadalupe_cypress, cupressus_guadalupensis","monterey_cypress, cupressus_macrocarpa","mexican_cypress, cedar_of_goa, portuguese_cypress, cupressus_lusitanica","italian_cypress, mediterranean_cypress, cupressus_sempervirens","king_william_pine, athrotaxis_selaginoides","chilean_cedar, austrocedrus_chilensis","incense_cedar, red_cedar, calocedrus_decurrens, libocedrus_decurrens","southern_white_cedar, coast_white_cedar, atlantic_white_cedar, white_cypress, white_cedar, chamaecyparis_thyoides","oregon_cedar, port_orford_cedar, lawson's_cypress, lawson's_cedar, chamaecyparis_lawsoniana","yellow_cypress, yellow_cedar, nootka_cypress, alaska_cedar, chamaecyparis_nootkatensis","japanese_cedar, japan_cedar, sugi, cryptomeria_japonica","juniper_berry","incense_cedar","kawaka, libocedrus_plumosa","pahautea, libocedrus_bidwillii, mountain_pine","metasequoia, dawn_redwood, metasequoia_glyptostrodoides","arborvitae","western_red_cedar, red_cedar, canoe_cedar, thuja_plicata","american_arborvitae, northern_white_cedar, white_cedar, thuja_occidentalis","oriental_arborvitae, thuja_orientalis, platycladus_orientalis","hiba_arborvitae, thujopsis_dolobrata","keteleeria","wollemi_pine","araucaria","monkey_puzzle, chile_pine, araucaria_araucana","norfolk_island_pine, araucaria_heterophylla, araucaria_excelsa","new_caledonian_pine, araucaria_columnaris","bunya_bunya, bunya_bunya_tree, araucaria_bidwillii","hoop_pine, moreton_bay_pine, araucaria_cunninghamii","kauri_pine, dammar_pine","kauri, kaury, agathis_australis","amboina_pine, amboyna_pine, agathis_dammara, agathis_alba","dundathu_pine, queensland_kauri, smooth_bark_kauri, agathis_robusta","red_kauri, agathis_lanceolata","plum-yew","california_nutmeg, nutmeg-yew, torreya_californica","stinking_cedar, stinking_yew, torrey_tree, torreya_taxifolia","celery_pine","celery_top_pine, celery-topped_pine, phyllocladus_asplenifolius","tanekaha, phyllocladus_trichomanoides","alpine_celery_pine, phyllocladus_alpinus","yellowwood, yellowwood_tree","gymnospermous_yellowwood","podocarp","yacca, yacca_podocarp, podocarpus_coriaceus","brown_pine, rockingham_podocarp, podocarpus_elatus","cape_yellowwood, african_yellowwood, podocarpus_elongatus","south-african_yellowwood, podocarpus_latifolius","alpine_totara, podocarpus_nivalis","totara, podocarpus_totara","common_yellowwood, bastard_yellowwood, afrocarpus_falcata","kahikatea, new_zealand_dacryberry, new_zealand_white_pine, dacrycarpus_dacrydioides, podocarpus_dacrydioides","rimu, imou_pine, red_pine, dacrydium_cupressinum","tarwood, tar-wood, dacrydium_colensoi","common_sickle_pine, falcatifolium_falciforme","yellow-leaf_sickle_pine, falcatifolium_taxoides","tarwood, tar-wood, new_zealand_mountain_pine, halocarpus_bidwilli, dacrydium_bidwilli","westland_pine, silver_pine, lagarostrobus_colensoi","huon_pine, lagarostrobus_franklinii, dacrydium_franklinii","chilean_rimu, lepidothamnus_fonkii","mountain_rimu, lepidothamnus_laxifolius, dacridium_laxifolius","nagi, nageia_nagi","miro, black_pine, prumnopitys_ferruginea, podocarpus_ferruginea","matai, black_pine, prumnopitys_taxifolia, podocarpus_spicata","plum-fruited_yew, prumnopitys_andina, prumnopitys_elegans","prince_albert_yew, prince_albert's_yew, saxe-gothea_conspicua","sundacarpus_amara, prumnopitys_amara, podocarpus_amara","japanese_umbrella_pine, sciadopitys_verticillata","yew","old_world_yew, english_yew, taxus_baccata","pacific_yew, california_yew, western_yew, taxus_brevifolia","japanese_yew, taxus_cuspidata","florida_yew, taxus_floridana","new_caledonian_yew, austrotaxus_spicata","white-berry_yew, pseudotaxus_chienii","ginkgo, gingko, maidenhair_tree, ginkgo_biloba","angiosperm, flowering_plant","dicot, dicotyledon, magnoliopsid, exogen","monocot, monocotyledon, liliopsid, endogen","floret, floweret","flower","bloomer","wildflower, wild_flower","apetalous_flower","inflorescence","rosebud","gynostegium","pollinium","pistil","gynobase","gynophore","stylopodium","carpophore","cornstalk, corn_stalk","petiolule","mericarp","micropyle","germ_tube","pollen_tube","gemma","galbulus","nectary, honey_gland","pericarp, seed_vessel","epicarp, exocarp","mesocarp","pip","silique, siliqua","cataphyll","perisperm","monocarp, monocarpic_plant, monocarpous_plant","sporophyte","gametophyte","megasporangium, macrosporangium","microspore","microsporangium","microsporophyll","archespore, archesporium","bonduc_nut, nicker_nut, nicker_seed","job's_tears","oilseed, oil-rich_seed","castor_bean","cottonseed","candlenut","peach_pit","hypanthium, floral_cup, calyx_tube","petal, flower_petal","corolla","lip","perianth, chlamys, floral_envelope, perigone, perigonium","thistledown","custard_apple, custard_apple_tree","cherimoya, cherimoya_tree, annona_cherimola","ilama, ilama_tree, annona_diversifolia","soursop, prickly_custard_apple, soursop_tree, annona_muricata","bullock's_heart, bullock's_heart_tree, bullock_heart, annona_reticulata","sweetsop, sweetsop_tree, annona_squamosa","pond_apple, pond-apple_tree, annona_glabra","pawpaw, papaw, papaw_tree, asimina_triloba","ilang-ilang, ylang-ylang, cananga_odorata","lancewood, lancewood_tree, oxandra_lanceolata","guinea_pepper, negro_pepper, xylopia_aethiopica","barberry","american_barberry, berberis_canadensis","common_barberry, european_barberry, berberis_vulgaris","japanese_barberry, berberis_thunbergii","oregon_grape, oregon_holly_grape, hollygrape, mountain_grape, holly-leaves_barberry, mahonia_aquifolium","oregon_grape, mahonia_nervosa","mayapple, may_apple, wild_mandrake, podophyllum_peltatum","may_apple","allspice","carolina_allspice, strawberry_shrub, strawberry_bush, sweet_shrub, calycanthus_floridus","spicebush, california_allspice, calycanthus_occidentalis","katsura_tree, cercidiphyllum_japonicum","laurel","true_laurel, bay, bay_laurel, bay_tree, laurus_nobilis","camphor_tree, cinnamomum_camphora","cinnamon, ceylon_cinnamon, ceylon_cinnamon_tree, cinnamomum_zeylanicum","cassia, cassia-bark_tree, cinnamomum_cassia","cassia_bark, chinese_cinnamon","saigon_cinnamon, cinnamomum_loureirii","cinnamon_bark","spicebush, spice_bush, american_spicebush, benjamin_bush, lindera_benzoin, benzoin_odoriferum","avocado, avocado_tree, persea_americana","laurel-tree, red_bay, persea_borbonia","sassafras, sassafras_tree, sassafras_albidum","california_laurel, california_bay_tree, oregon_myrtle, pepperwood, spice_tree, sassafras_laurel, california_olive, mountain_laurel, umbellularia_californica","anise_tree","purple_anise, illicium_floridanum","star_anise, illicium_anisatum","star_anise, chinese_anise, illicium_verum","magnolia","southern_magnolia, evergreen_magnolia, large-flowering_magnolia, bull_bay, magnolia_grandiflora","umbrella_tree, umbrella_magnolia, elkwood, elk-wood, magnolia_tripetala","earleaved_umbrella_tree, magnolia_fraseri","cucumber_tree, magnolia_acuminata","large-leaved_magnolia, large-leaved_cucumber_tree, great-leaved_macrophylla, magnolia_macrophylla","saucer_magnolia, chinese_magnolia, magnolia_soulangiana","star_magnolia, magnolia_stellata","sweet_bay, swamp_bay, swamp_laurel, magnolia_virginiana","manglietia, genus_manglietia","tulip_tree, tulip_poplar, yellow_poplar, canary_whitewood, liriodendron_tulipifera","moonseed","common_moonseed, canada_moonseed, yellow_parilla, menispermum_canadense","carolina_moonseed, cocculus_carolinus","nutmeg, nutmeg_tree, myristica_fragrans","water_nymph, fragrant_water_lily, pond_lily, nymphaea_odorata","european_white_lily, nymphaea_alba","southern_spatterdock, nuphar_sagittifolium","lotus, indian_lotus, sacred_lotus, nelumbo_nucifera","water_chinquapin, american_lotus, yanquapin, nelumbo_lutea","water-shield, fanwort, cabomba_caroliniana","water-shield, brasenia_schreberi, water-target","peony, paeony","buttercup, butterflower, butter-flower, crowfoot, goldcup, kingcup","meadow_buttercup, tall_buttercup, tall_crowfoot, tall_field_buttercup, ranunculus_acris","water_crowfoot, water_buttercup, ranunculus_aquatilis","lesser_celandine, pilewort, ranunculus_ficaria","lesser_spearwort, ranunculus_flammula","greater_spearwort, ranunculus_lingua","western_buttercup, ranunculus_occidentalis","creeping_buttercup, creeping_crowfoot, ranunculus_repens","cursed_crowfoot, celery-leaved_buttercup, ranunculus_sceleratus","aconite","monkshood, helmetflower, helmet_flower, aconitum_napellus","wolfsbane, wolfbane, wolf's_bane, aconitum_lycoctonum","baneberry, cohosh, herb_christopher","baneberry","red_baneberry, redberry, red-berry, snakeberry, actaea_rubra","pheasant's-eye, adonis_annua","anemone, windflower","alpine_anemone, mountain_anemone, anemone_tetonensis","canada_anemone, anemone_canadensis","thimbleweed, anemone_cylindrica","wood_anemone, anemone_nemorosa","wood_anemone, snowdrop, anemone_quinquefolia","longheaded_thimbleweed, anemone_riparia","snowdrop_anemone, snowdrop_windflower, anemone_sylvestris","virginia_thimbleweed, anemone_virginiana","rue_anemone, anemonella_thalictroides","columbine, aquilegia, aquilege","meeting_house, honeysuckle, aquilegia_canadensis","blue_columbine, aquilegia_caerulea, aquilegia_scopulorum_calcarea","granny's_bonnets, aquilegia_vulgaris","marsh_marigold, kingcup, meadow_bright, may_blob, cowslip, water_dragon, caltha_palustris","american_bugbane, summer_cohosh, cimicifuga_americana","black_cohosh, black_snakeroot, rattle-top, cimicifuga_racemosa","fetid_bugbane, foetid_bugbane, cimicifuga_foetida","clematis","pine_hyacinth, clematis_baldwinii, viorna_baldwinii","blue_jasmine, blue_jessamine, curly_clematis, marsh_clematis, clematis_crispa","golden_clematis, clematis_tangutica","scarlet_clematis, clematis_texensis","leather_flower, clematis_versicolor","leather_flower, vase-fine, vase_vine, clematis_viorna","virgin's_bower, old_man's_beard, devil's_darning_needle, clematis_virginiana","purple_clematis, purple_virgin's_bower, mountain_clematis, clematis_verticillaris","goldthread, golden_thread, coptis_groenlandica, coptis_trifolia_groenlandica","rocket_larkspur, consolida_ambigua, delphinium_ajacis","delphinium","larkspur","winter_aconite, eranthis_hyemalis","lenten_rose, black_hellebore, helleborus_orientalis","green_hellebore, helleborus_viridis","hepatica, liverleaf","goldenseal, golden_seal, yellow_root, turmeric_root, hydrastis_canadensis","false_rue_anemone, false_rue, isopyrum_biternatum","giant_buttercup, laccopetalum_giganteum","nigella","love-in-a-mist, nigella_damascena","fennel_flower, nigella_hispanica","black_caraway, nutmeg_flower, roman_coriander, nigella_sativa","pasqueflower, pasque_flower","meadow_rue","false_bugbane, trautvetteria_carolinensis","globeflower, globe_flower","winter's_bark, winter's_bark_tree, drimys_winteri","pepper_shrub, pseudowintera_colorata, wintera_colorata","sweet_gale, scotch_gale, myrica_gale","wax_myrtle","bay_myrtle, puckerbush, myrica_cerifera","bayberry, candleberry, swamp_candleberry, waxberry, myrica_pensylvanica","sweet_fern, comptonia_peregrina, comptonia_asplenifolia","corkwood, corkwood_tree, leitneria_floridana","jointed_rush, juncus_articulatus","toad_rush, juncus_bufonius","slender_rush, juncus_tenuis","zebrawood, zebrawood_tree","connarus_guianensis","legume, leguminous_plant","legume","peanut","granadilla_tree, granadillo, brya_ebenus","arariba, centrolobium_robustum","tonka_bean, coumara_nut","courbaril, hymenaea_courbaril","melilotus, melilot, sweet_clover","darling_pea, poison_bush","smooth_darling_pea, swainsona_galegifolia","clover, trefoil","alpine_clover, trifolium_alpinum","hop_clover, shamrock, lesser_yellow_trefoil, trifolium_dubium","crimson_clover, italian_clover, trifolium_incarnatum","red_clover, purple_clover, trifolium_pratense","buffalo_clover, trifolium_reflexum, trifolium_stoloniferum","white_clover, dutch_clover, shamrock, trifolium_repens","mimosa","acacia","shittah, shittah_tree","wattle","black_wattle, acacia_auriculiformis","gidgee, stinking_wattle, acacia_cambegei","catechu, jerusalem_thorn, acacia_catechu","silver_wattle, mimosa, acacia_dealbata","huisache, cassie, mimosa_bush, sweet_wattle, sweet_acacia, scented_wattle, flame_tree, acacia_farnesiana","lightwood, acacia_melanoxylon","golden_wattle, acacia_pycnantha","fever_tree, acacia_xanthophloea","coralwood, coral-wood, red_sandalwood, barbados_pride, peacock_flower_fence, adenanthera_pavonina","albizzia, albizia","silk_tree, albizia_julibrissin, albizzia_julibrissin","siris, siris_tree, albizia_lebbeck, albizzia_lebbeck","rain_tree, saman, monkeypod, monkey_pod, zaman, zamang, albizia_saman","calliandra","conacaste, elephant's_ear, enterolobium_cyclocarpa","inga","ice-cream_bean, inga_edulis","guama, inga_laurina","lead_tree, white_popinac, leucaena_glauca, leucaena_leucocephala","wild_tamarind, lysiloma_latisiliqua, lysiloma_bahamensis","sabicu, lysiloma_sabicu","nitta_tree","parkia_javanica","manila_tamarind, camachile, huamachil, wild_tamarind, pithecellobium_dulce","cat's-claw, catclaw, black_bead, pithecellodium_unguis-cati","honey_mesquite, western_honey_mesquite, prosopis_glandulosa","algarroba, algarrobilla, algarobilla","screw_bean, screwbean, tornillo, screwbean_mesquite, prosopis_pubescens","screw_bean","dogbane","indian_hemp, rheumatism_weed, apocynum_cannabinum","bushman's_poison, ordeal_tree, acocanthera_oppositifolia, acocanthera_venenata","impala_lily, mock_azalia, desert_rose, kudu_lily, adenium_obesum, adenium_multiflorum","allamanda","common_allamanda, golden_trumpet, allamanda_cathartica","dita, dita_bark, devil_tree, alstonia_scholaris","nepal_trumpet_flower, easter_lily_vine, beaumontia_grandiflora","carissa","hedge_thorn, natal_plum, carissa_bispinosa","natal_plum, amatungulu, carissa_macrocarpa, carissa_grandiflora","periwinkle, rose_periwinkle, madagascar_periwinkle, old_maid, cape_periwinkle, red_periwinkle, cayenne_jasmine, catharanthus_roseus, vinca_rosea","ivory_tree, conessi, kurchi, kurchee, holarrhena_pubescens, holarrhena_antidysenterica","white_dipladenia, mandevilla_boliviensis, dipladenia_boliviensis","chilean_jasmine, mandevilla_laxa","oleander, rose_bay, nerium_oleander","frangipani, frangipanni","west_indian_jasmine, pagoda_tree, plumeria_alba","rauwolfia, rauvolfia","snakewood, rauwolfia_serpentina","strophanthus_kombe","yellow_oleander, thevetia_peruviana, thevetia_neriifolia","myrtle, vinca_minor","large_periwinkle, vinca_major","arum, aroid","cuckoopint, lords-and-ladies, jack-in-the-pulpit, arum_maculatum","black_calla, arum_palaestinum","calamus","alocasia, elephant's_ear, elephant_ear","giant_taro, alocasia_macrorrhiza","amorphophallus","pungapung, telingo_potato, elephant_yam, amorphophallus_paeonifolius, amorphophallus_campanulatus","devil's_tongue, snake_palm, umbrella_arum, amorphophallus_rivieri","anthurium, tailflower, tail-flower","flamingo_flower, flamingo_plant, anthurium_andraeanum, anthurium_scherzerianum","jack-in-the-pulpit, indian_turnip, wake-robin, arisaema_triphyllum, arisaema_atrorubens","friar's-cowl, arisarum_vulgare","caladium","caladium_bicolor","wild_calla, water_arum, calla_palustris","taro, taro_plant, dalo, dasheen, colocasia_esculenta","taro, cocoyam, dasheen, eddo","cryptocoryne, water_trumpet","dracontium","golden_pothos, pothos, ivy_arum, epipremnum_aureum, scindapsus_aureus","skunk_cabbage, lysichiton_americanum","monstera","ceriman, monstera_deliciosa","nephthytis","nephthytis_afzelii","arrow_arum","green_arrow_arum, tuckahoe, peltandra_virginica","philodendron","pistia, water_lettuce, water_cabbage, pistia_stratiotes, pistia_stratoites","pothos","spathiphyllum, peace_lily, spathe_flower","skunk_cabbage, polecat_weed, foetid_pothos, symplocarpus_foetidus","yautia, tannia, spoonflower, malanga, xanthosoma_sagittifolium, xanthosoma_atrovirens","calla_lily, calla, arum_lily, zantedeschia_aethiopica","pink_calla, zantedeschia_rehmanii","golden_calla","duckweed","common_duckweed, lesser_duckweed, lemna_minor","star-duckweed, lemna_trisulca","great_duckweed, water_flaxseed, spirodela_polyrrhiza","watermeal","common_wolffia, wolffia_columbiana","aralia","american_angelica_tree, devil's_walking_stick, hercules'-club, aralia_spinosa","american_spikenard, petty_morel, life-of-man, aralia_racemosa","bristly_sarsaparilla, bristly_sarsparilla, dwarf_elder, aralia_hispida","japanese_angelica_tree, aralia_elata","chinese_angelica, chinese_angelica_tree, aralia_stipulata","ivy, common_ivy, english_ivy, hedera_helix","puka, meryta_sinclairii","ginseng, nin-sin, panax_ginseng, panax_schinseng, panax_pseudoginseng","ginseng","umbrella_tree, schefflera_actinophylla, brassaia_actinophylla","birthwort, aristolochia_clematitis","dutchman's-pipe, pipe_vine, aristolochia_macrophylla, aristolochia_durior","virginia_snakeroot, virginia_serpentaria, virginia_serpentary, aristolochia_serpentaria","canada_ginger, black_snakeroot, asarum_canadense","heartleaf, heart-leaf, asarum_virginicum","heartleaf, heart-leaf, asarum_shuttleworthii","asarabacca, asarum_europaeum","caryophyllaceous_plant","corn_cockle, corn_campion, crown-of-the-field, agrostemma_githago","sandwort","mountain_sandwort, mountain_starwort, mountain_daisy, arenaria_groenlandica","pine-barren_sandwort, longroot, arenaria_caroliniana","seabeach_sandwort, arenaria_peploides","rock_sandwort, arenaria_stricta","thyme-leaved_sandwort, arenaria_serpyllifolia","mouse-ear_chickweed, mouse_eared_chickweed, mouse_ear, clammy_chickweed, chickweed","snow-in-summer, love-in-a-mist, cerastium_tomentosum","alpine_mouse-ear, arctic_mouse-ear, cerastium_alpinum","pink, garden_pink","sweet_william, dianthus_barbatus","carnation, clove_pink, gillyflower, dianthus_caryophyllus","china_pink, rainbow_pink, dianthus_chinensis","japanese_pink, dianthus_chinensis_heddewigii","maiden_pink, dianthus_deltoides","cheddar_pink, diangus_gratianopolitanus","button_pink, dianthus_latifolius","cottage_pink, grass_pink, dianthus_plumarius","fringed_pink, dianthus_supurbus","drypis","baby's_breath, babies'-breath, gypsophila_paniculata","coral_necklace, illecebrum_verticullatum","lychnis, catchfly","ragged_robin, cuckoo_flower, lychnis_flos-cuculi, lychins_floscuculi","scarlet_lychnis, maltese_cross, lychins_chalcedonica","mullein_pink, rose_campion, gardener's_delight, dusty_miller, lychnis_coronaria","sandwort, moehringia_lateriflora","sandwort, moehringia_mucosa","soapwort, hedge_pink, bouncing_bet, bouncing_bess, saponaria_officinalis","knawel, knawe, scleranthus_annuus","silene, campion, catchfly","moss_campion, silene_acaulis","wild_pink, silene_caroliniana","red_campion, red_bird's_eye, silene_dioica, lychnis_dioica","white_campion, evening_lychnis, white_cockle, bladder_campion, silene_latifolia, lychnis_alba","fire_pink, silene_virginica","bladder_campion, silene_uniflora, silene_vulgaris","corn_spurry, corn_spurrey, spergula_arvensis","sand_spurry, sea_spurry, spergularia_rubra","chickweed","common_chickweed, stellaria_media","cowherb, cow_cockle, vaccaria_hispanica, vaccaria_pyramidata, saponaria_vaccaria","hottentot_fig, hottentot's_fig, sour_fig, carpobrotus_edulis, mesembryanthemum_edule","livingstone_daisy, dorotheanthus_bellidiformis","fig_marigold, pebble_plant","ice_plant, icicle_plant, mesembryanthemum_crystallinum","new_zealand_spinach, tetragonia_tetragonioides, tetragonia_expansa","amaranth","amaranth","tumbleweed, amaranthus_albus, amaranthus_graecizans","prince's-feather, gentleman's-cane, prince's-plume, red_amaranth, purple_amaranth, amaranthus_cruentus, amaranthus_hybridus_hypochondriacus, amaranthus_hybridus_erythrostachys","pigweed, amaranthus_hypochondriacus","thorny_amaranth, amaranthus_spinosus","alligator_weed, alligator_grass, alternanthera_philoxeroides","cockscomb, common_cockscomb, celosia_cristata, celosia_argentea_cristata","cottonweed","globe_amaranth, bachelor's_button, gomphrena_globosa","bloodleaf","saltwort, batis_maritima","lamb's-quarters, pigweed, wild_spinach, chenopodium_album","good-king-henry, allgood, fat_hen, wild_spinach, chenopodium_bonus-henricus","jerusalem_oak, feather_geranium, mexican_tea, chenopodium_botrys, atriplex_mexicana","oak-leaved_goosefoot, oakleaf_goosefoot, chenopodium_glaucum","sowbane, red_goosefoot, chenopodium_hybridum","nettle-leaved_goosefoot, nettleleaf_goosefoot, chenopodium_murale","red_goosefoot, french_spinach, chenopodium_rubrum","stinking_goosefoot, chenopodium_vulvaria","orach, orache","saltbush","garden_orache, mountain_spinach, atriplex_hortensis","desert_holly, atriplex_hymenelytra","quail_bush, quail_brush, white_thistle, atriplex_lentiformis","beet, common_beet, beta_vulgaris","beetroot, beta_vulgaris_rubra","chard, swiss_chard, spinach_beet, leaf_beet, chard_plant, beta_vulgaris_cicla","mangel-wurzel, mangold-wurzel, mangold, beta_vulgaris_vulgaris","winged_pigweed, tumbleweed, cycloloma_atriplicifolium","halogeton, halogeton_glomeratus","glasswort, samphire, salicornia_europaea","saltwort, barilla, glasswort, kali, kelpwort, salsola_kali, salsola_soda","russian_thistle, russian_tumbleweed, russian_cactus, tumbleweed, salsola_kali_tenuifolia","greasewood, black_greasewood, sarcobatus_vermiculatus","scarlet_musk_flower, nyctaginia_capitata","sand_verbena","sweet_sand_verbena, abronia_fragrans","yellow_sand_verbena, abronia_latifolia","beach_pancake, abronia_maritima","beach_sand_verbena, pink_sand_verbena, abronia_umbellata","desert_sand_verbena, abronia_villosa","trailing_four_o'clock, trailing_windmills, allionia_incarnata","bougainvillea","umbrellawort","four_o'clock","common_four-o'clock, marvel-of-peru, mirabilis_jalapa, mirabilis_uniflora","california_four_o'clock, mirabilis_laevis, mirabilis_californica","sweet_four_o'clock, maravilla, mirabilis_longiflora","desert_four_o'clock, colorado_four_o'clock, maravilla, mirabilis_multiflora","mountain_four_o'clock, mirabilis_oblongifolia","cockspur, pisonia_aculeata","rattail_cactus, rat's-tail_cactus, aporocactus_flagelliformis","saguaro, sahuaro, carnegiea_gigantea","night-blooming_cereus","echinocactus, barrel_cactus","hedgehog_cactus","golden_barrel_cactus, echinocactus_grusonii","hedgehog_cereus","rainbow_cactus","epiphyllum, orchid_cactus","barrel_cactus","night-blooming_cereus","chichipe, lemaireocereus_chichipe","mescal, mezcal, peyote, lophophora_williamsii","mescal_button, sacred_mushroom, magic_mushroom","mammillaria","feather_ball, mammillaria_plumosa","garambulla, garambulla_cactus, myrtillocactus_geometrizans","knowlton's_cactus, pediocactus_knowltonii","nopal","prickly_pear, prickly_pear_cactus","cholla, opuntia_cholla","nopal, opuntia_lindheimeri","tuna, opuntia_tuna","barbados_gooseberry, barbados-gooseberry_vine, pereskia_aculeata","mistletoe_cactus","christmas_cactus, schlumbergera_buckleyi, schlumbergera_baridgesii","night-blooming_cereus","crab_cactus, thanksgiving_cactus, zygocactus_truncatus, schlumbergera_truncatus","pokeweed","indian_poke, phytolacca_acinosa","poke, pigeon_berry, garget, scoke, phytolacca_americana","ombu, bella_sombra, phytolacca_dioica","bloodberry, blood_berry, rougeberry, rouge_plant, rivina_humilis","portulaca","rose_moss, sun_plant, portulaca_grandiflora","common_purslane, pussley, pussly, verdolagas, portulaca_oleracea","rock_purslane","red_maids, redmaids, calandrinia_ciliata","carolina_spring_beauty, claytonia_caroliniana","spring_beauty, clatonia_lanceolata","virginia_spring_beauty, claytonia_virginica","siskiyou_lewisia, lewisia_cotyledon","bitterroot, lewisia_rediviva","broad-leaved_montia, montia_cordifolia","blinks, blinking_chickweed, water_chickweed, montia_lamprosperma","toad_lily, montia_chamissoi","winter_purslane, miner's_lettuce, cuban_spinach, montia_perfoliata","flame_flower, flame-flower, flameflower, talinum_aurantiacum","pigmy_talinum, talinum_brevifolium","jewels-of-opar, talinum_paniculatum","caper","native_pomegranate, capparis_arborea","caper_tree, jamaica_caper_tree, capparis_cynophallophora","caper_tree, bay-leaved_caper, capparis_flexuosa","common_caper, capparis_spinosa","spiderflower, cleome","rocky_mountain_bee_plant, stinking_clover, cleome_serrulata","clammyweed, polanisia_graveolens, polanisia_dodecandra","crucifer, cruciferous_plant","cress, cress_plant","watercress","stonecress, stone_cress","garlic_mustard, hedge_garlic, sauce-alone, jack-by-the-hedge, alliaria_officinalis","alyssum, madwort","rose_of_jericho, resurrection_plant, anastatica_hierochuntica","arabidopsis_thaliana, mouse-ear_cress","arabidopsis_lyrata","rock_cress, rockcress","sicklepod, arabis_canadensis","tower_mustard, tower_cress, turritis_glabra, arabis_glabra","horseradish, horseradish_root","winter_cress, st._barbara's_herb, scurvy_grass","yellow_rocket, rockcress, rocket_cress, barbarea_vulgaris, sisymbrium_barbarea","hoary_alison, hoary_alyssum, berteroa_incana","buckler_mustard, biscutalla_laevigata","wild_cabbage, brassica_oleracea","cabbage, cultivated_cabbage, brassica_oleracea","head_cabbage, head_cabbage_plant, brassica_oleracea_capitata","savoy_cabbage","brussels_sprout, brassica_oleracea_gemmifera","cauliflower, brassica_oleracea_botrytis","broccoli, brassica_oleracea_italica","collard","kohlrabi, brassica_oleracea_gongylodes","turnip_plant","turnip, white_turnip, brassica_rapa","rutabaga, turnip_cabbage, swede, swedish_turnip, rutabaga_plant, brassica_napus_napobrassica","broccoli_raab, broccoli_rabe, brassica_rapa_ruvo","mustard","chinese_mustard, indian_mustard, leaf_mustard, gai_choi, brassica_juncea","bok_choy, bok_choi, pakchoi, pak_choi, chinese_white_cabbage, brassica_rapa_chinensis","rape, colza, brassica_napus","rapeseed","shepherd's_purse, shepherd's_pouch, capsella_bursa-pastoris","lady's_smock, cuckooflower, cuckoo_flower, meadow_cress, cardamine_pratensis","coral-root_bittercress, coralroot, coralwort, cardamine_bulbifera, dentaria_bulbifera","crinkleroot, crinkle-root, crinkle_root, pepper_root, toothwort, cardamine_diphylla, dentaria_diphylla","american_watercress, mountain_watercress, cardamine_rotundifolia","spring_cress, cardamine_bulbosa","purple_cress, cardamine_douglasii","wallflower, cheiranthus_cheiri, erysimum_cheiri","prairie_rocket","scurvy_grass, common_scurvy_grass, cochlearia_officinalis","sea_kale, sea_cole, crambe_maritima","tansy_mustard, descurainia_pinnata","draba","wallflower","prairie_rocket","siberian_wall_flower, erysimum_allionii, cheiranthus_allionii","western_wall_flower, erysimum_asperum, cheiranthus_asperus, erysimum_arkansanum","wormseed_mustard, erysimum_cheiranthoides","heliophila","damask_violet, dame's_violet, sweet_rocket, hesperis_matronalis","tansy-leaved_rocket, hugueninia_tanacetifolia, sisymbrium_tanacetifolia","candytuft","woad","dyer's_woad, isatis_tinctoria","bladderpod","sweet_alyssum, sweet_alison, lobularia_maritima","malcolm_stock, stock","virginian_stock, virginia_stock, malcolmia_maritima","stock, gillyflower","brompton_stock, matthiola_incana","bladderpod","chamois_cress, pritzelago_alpina, lepidium_alpina","radish_plant, radish","jointed_charlock, wild_radish, wild_rape, runch, raphanus_raphanistrum","radish, raphanus_sativus","radish, daikon, japanese_radish, raphanus_sativus_longipinnatus","marsh_cress, yellow_watercress, rorippa_islandica","great_yellowcress, rorippa_amphibia, nasturtium_amphibium","schizopetalon, schizopetalon_walkeri","field_mustard, wild_mustard, charlock, chadlock, brassica_kaber, sinapis_arvensis","hedge_mustard, sisymbrium_officinale","desert_plume, prince's-plume, stanleya_pinnata, cleome_pinnata","pennycress","field_pennycress, french_weed, fanweed, penny_grass, stinkweed, mithridate_mustard, thlaspi_arvense","fringepod, lacepod","bladderpod","wasabi","poppy","iceland_poppy, papaver_alpinum","western_poppy, papaver_californicum","prickly_poppy, papaver_argemone","iceland_poppy, arctic_poppy, papaver_nudicaule","oriental_poppy, papaver_orientale","corn_poppy, field_poppy, flanders_poppy, papaver_rhoeas","opium_poppy, papaver_somniferum","prickly_poppy, argemone, white_thistle, devil's_fig","mexican_poppy, argemone_mexicana","bocconia, tree_celandine, bocconia_frutescens","celandine, greater_celandine, swallowwort, swallow_wort, chelidonium_majus","corydalis","climbing_corydalis, corydalis_claviculata, fumaria_claviculata","california_poppy, eschscholtzia_californica","horn_poppy, horned_poppy, yellow_horned_poppy, sea_poppy, glaucium_flavum","golden_cup, mexican_tulip_poppy, hunnemania_fumariifolia","plume_poppy, bocconia, macleaya_cordata","blue_poppy, meconopsis_betonicifolia","welsh_poppy, meconopsis_cambrica","creamcups, platystemon_californicus","matilija_poppy, california_tree_poppy, romneya_coulteri","wind_poppy, flaming_poppy, stylomecon_heterophyllum, papaver_heterophyllum","celandine_poppy, wood_poppy, stylophorum_diphyllum","climbing_fumitory, allegheny_vine, adlumia_fungosa, fumaria_fungosa","bleeding_heart, lyreflower, lyre-flower, dicentra_spectabilis","dutchman's_breeches, dicentra_cucullaria","squirrel_corn, dicentra_canadensis","composite, composite_plant","compass_plant, compass_flower","everlasting, everlasting_flower","achillea","yarrow, milfoil, achillea_millefolium","pink-and-white_everlasting, pink_paper_daisy, acroclinium_roseum","white_snakeroot, white_sanicle, ageratina_altissima, eupatorium_rugosum","ageratum","common_ageratum, ageratum_houstonianum","sweet_sultan, amberboa_moschata, centaurea_moschata","ragweed, ambrosia, bitterweed","common_ragweed, ambrosia_artemisiifolia","great_ragweed, ambrosia_trifida","western_ragweed, perennial_ragweed, ambrosia_psilostachya","ammobium","winged_everlasting, ammobium_alatum","pellitory, pellitory-of-spain, anacyclus_pyrethrum","pearly_everlasting, cottonweed, anaphalis_margaritacea","andryala","plantain-leaved_pussytoes","field_pussytoes","solitary_pussytoes","mountain_everlasting","mayweed, dog_fennel, stinking_mayweed, stinking_chamomile, anthemis_cotula","yellow_chamomile, golden_marguerite, dyers'_chamomile, anthemis_tinctoria","corn_chamomile, field_chamomile, corn_mayweed, anthemis_arvensis","woolly_daisy, dwarf_daisy, antheropeas_wallacei, eriophyllum_wallacei","burdock, clotbur","great_burdock, greater_burdock, cocklebur, arctium_lappa","african_daisy","blue-eyed_african_daisy, arctotis_stoechadifolia, arctotis_venusta","marguerite, marguerite_daisy, paris_daisy, chrysanthemum_frutescens, argyranthemum_frutescens","silversword, argyroxiphium_sandwicense","arnica","heartleaf_arnica, arnica_cordifolia","arnica_montana","lamb_succory, dwarf_nipplewort, arnoseris_minima","artemisia","mugwort","sweet_wormwood, artemisia_annua","field_wormwood, artemisia_campestris","tarragon, estragon, artemisia_dracunculus","sand_sage, silvery_wormwood, artemisia_filifolia","wormwood_sage, prairie_sagewort, artemisia_frigida","western_mugwort, white_sage, cudweed, prairie_sage, artemisia_ludoviciana, artemisia_gnaphalodes","roman_wormwood, artemis_pontica","bud_brush, bud_sagebrush, artemis_spinescens","common_mugwort, artemisia_vulgaris","aster","wood_aster","whorled_aster, aster_acuminatus","heath_aster, aster_arenosus","heart-leaved_aster, aster_cordifolius","white_wood_aster, aster_divaricatus","bushy_aster, aster_dumosus","heath_aster, aster_ericoides","white_prairie_aster, aster_falcatus","stiff_aster, aster_linarifolius","goldilocks, goldilocks_aster, aster_linosyris, linosyris_vulgaris","large-leaved_aster, aster_macrophyllus","new_england_aster, aster_novae-angliae","michaelmas_daisy, new_york_aster, aster_novi-belgii","upland_white_aster, aster_ptarmicoides","short's_aster, aster_shortii","sea_aster, sea_starwort, aster_tripolium","prairie_aster, aster_turbinellis","annual_salt-marsh_aster","aromatic_aster","arrow_leaved_aster","azure_aster","bog_aster","crooked-stemmed_aster","eastern_silvery_aster","flat-topped_white_aster","late_purple_aster","panicled_aster","perennial_salt_marsh_aster","purple-stemmed_aster","rough-leaved_aster","rush_aster","schreiber's_aster","small_white_aster","smooth_aster","southern_aster","starved_aster, calico_aster","tradescant's_aster","wavy-leaved_aster","western_silvery_aster","willow_aster","ayapana, ayapana_triplinervis, eupatorium_aya-pana","mule_fat, baccharis_viminea","balsamroot","daisy","common_daisy, english_daisy, bellis_perennis","bur_marigold, burr_marigold, beggar-ticks, beggar's-ticks, sticktight","spanish_needles, bidens_bipinnata","tickseed_sunflower, bidens_coronata, bidens_trichosperma","european_beggar-ticks, trifid_beggar-ticks, trifid_bur_marigold, bidens_tripartita","slender_knapweed","false_chamomile","swan_river_daisy, brachycome_iberidifolia","woodland_oxeye, buphthalmum_salicifolium","indian_plantain","calendula","common_marigold, pot_marigold, ruddles, scotch_marigold, calendula_officinalis","china_aster, callistephus_chinensis","thistle","welted_thistle, carduus_crispus","musk_thistle, nodding_thistle, carduus_nutans","carline_thistle","stemless_carline_thistle, carlina_acaulis","common_carline_thistle, carlina_vulgaris","safflower, false_saffron, carthamus_tinctorius","safflower_seed","catananche","blue_succory, cupid's_dart, catananche_caerulea","centaury","dusty_miller, centaurea_cineraria, centaurea_gymnocarpa","cornflower, bachelor's_button, bluebottle, centaurea_cyanus","star-thistle, caltrop, centauria_calcitrapa","knapweed","sweet_sultan, centaurea_imperialis","great_knapweed, greater_knapweed, centaurea_scabiosa","barnaby's_thistle, yellow_star-thistle, centaurea_solstitialis","chamomile, camomile, chamaemelum_nobilis, anthemis_nobilis","chaenactis","chrysanthemum","corn_marigold, field_marigold, chrysanthemum_segetum","crown_daisy, chrysanthemum_coronarium","chop-suey_greens, tong_ho, shun_giku, chrysanthemum_coronarium_spatiosum","golden_aster","maryland_golden_aster, chrysopsis_mariana","goldenbush","rabbit_brush, rabbit_bush, chrysothamnus_nauseosus","chicory, succory, chicory_plant, cichorium_intybus","endive, witloof, cichorium_endivia","chicory, chicory_root","plume_thistle, plumed_thistle","canada_thistle, creeping_thistle, cirsium_arvense","field_thistle, cirsium_discolor","woolly_thistle, cirsium_flodmanii","european_woolly_thistle, cirsium_eriophorum","melancholy_thistle, cirsium_heterophylum, cirsium_helenioides","brook_thistle, cirsium_rivulare","bull_thistle, boar_thistle, spear_thistle, cirsium_vulgare, cirsium_lanceolatum","blessed_thistle, sweet_sultan, cnicus_benedictus","mistflower, mist-flower, ageratum, conoclinium_coelestinum, eupatorium_coelestinum","horseweed, canadian_fleabane, fleabane, conyza_canadensis, erigeron_canadensis","coreopsis, tickseed, tickweed, tick-weed","giant_coreopsis, coreopsis_gigantea","sea_dahlia, coreopsis_maritima","calliopsis, coreopsis_tinctoria","cosmos, cosmea","brass_buttons, cotula_coronopifolia","billy_buttons","hawk's-beard, hawk's-beards","artichoke, globe_artichoke, artichoke_plant, cynara_scolymus","cardoon, cynara_cardunculus","dahlia, dahlia_pinnata","german_ivy, delairea_odorata, senecio_milkanioides","florist's_chrysanthemum, florists'_chrysanthemum, mum, dendranthema_grandifloruom, chrysanthemum_morifolium","cape_marigold, sun_marigold, star_of_the_veldt","leopard's-bane, leopardbane","coneflower","globe_thistle","elephant's-foot","tassel_flower, emilia_sagitta","brittlebush, brittle_bush, incienso, encelia_farinosa","sunray, enceliopsis_nudicaulis","engelmannia","fireweed, erechtites_hieracifolia","fleabane","blue_fleabane, erigeron_acer","daisy_fleabane, erigeron_annuus","orange_daisy, orange_fleabane, erigeron_aurantiacus","spreading_fleabane, erigeron_divergens","seaside_daisy, beach_aster, erigeron_glaucous","philadelphia_fleabane, erigeron_philadelphicus","robin's_plantain, erigeron_pulchellus","showy_daisy, erigeron_speciosus","woolly_sunflower","golden_yarrow, eriophyllum_lanatum","dog_fennel, eupatorium_capillifolium","joe-pye_weed, spotted_joe-pye_weed, eupatorium_maculatum","boneset, agueweed, thoroughwort, eupatorium_perfoliatum","joe-pye_weed, purple_boneset, trumpet_weed, marsh_milkweed, eupatorium_purpureum","blue_daisy, blue_marguerite, felicia_amelloides","kingfisher_daisy, felicia_bergeriana","cotton_rose, cudweed, filago","herba_impia, filago_germanica","gaillardia","gazania","treasure_flower, gazania_rigens","african_daisy","barberton_daisy, transvaal_daisy, gerbera_jamesonii","desert_sunflower, gerea_canescens","cudweed","chafeweed, wood_cudweed, gnaphalium_sylvaticum","gumweed, gum_plant, tarweed, rosinweed","grindelia_robusta","curlycup_gumweed, grindelia_squarrosa","little-head_snakeweed, gutierrezia_microcephala","rabbitweed, rabbit-weed, snakeweed, broom_snakeweed, broom_snakeroot, turpentine_weed, gutierrezia_sarothrae","broomweed, broom-weed, gutierrezia_texana","velvet_plant, purple_velvet_plant, royal_velvet_plant, gynura_aurantiaca","goldenbush","camphor_daisy, haplopappus_phyllocephalus","yellow_spiny_daisy, haplopappus_spinulosus","hoary_golden_bush, hazardia_cana","sneezeweed","orange_sneezeweed, owlclaws, helenium_hoopesii","rosilla, helenium_puberulum","sunflower, helianthus","swamp_sunflower, helianthus_angustifolius","common_sunflower, mirasol, helianthus_annuus","giant_sunflower, tall_sunflower, indian_potato, helianthus_giganteus","showy_sunflower, helianthus_laetiflorus","maximilian's_sunflower, helianthus_maximilianii","prairie_sunflower, helianthus_petiolaris","jerusalem_artichoke, girasol, jerusalem_artichoke_sunflower, helianthus_tuberosus","jerusalem_artichoke","strawflower, golden_everlasting, yellow_paper_daisy, helichrysum_bracteatum","heliopsis, oxeye","strawflower","hairy_golden_aster, prairie_golden_aster, heterotheca_villosa, chrysopsis_villosa","hawkweed","rattlesnake_weed, hieracium_venosum","alpine_coltsfoot, homogyne_alpina, tussilago_alpina","alpine_gold, alpine_hulsea, hulsea_algida","dwarf_hulsea, hulsea_nana","cat's-ear, california_dandelion, capeweed, gosmore, hypochaeris_radicata","inula","marsh_elder, iva","burweed_marsh_elder, false_ragweed, iva_xanthifolia","krigia","dwarf_dandelion, krigia_dandelion, krigia_bulbosa","garden_lettuce, common_lettuce, lactuca_sativa","cos_lettuce, romaine_lettuce, lactuca_sativa_longifolia","leaf_lettuce, lactuca_sativa_crispa","celtuce, stem_lettuce, lactuca_sativa_asparagina","prickly_lettuce, horse_thistle, lactuca_serriola, lactuca_scariola","goldfields, lasthenia_chrysostoma","tidytips, tidy_tips, layia_platyglossa","hawkbit","fall_dandelion, arnica_bud, leontodon_autumnalis","edelweiss, leontopodium_alpinum","oxeye_daisy, ox-eyed_daisy, marguerite, moon_daisy, white_daisy, leucanthemum_vulgare, chrysanthemum_leucanthemum","oxeye_daisy, leucanthemum_maximum, chrysanthemum_maximum","shasta_daisy, leucanthemum_superbum, chrysanthemum_maximum_maximum","pyrenees_daisy, leucanthemum_lacustre, chrysanthemum_lacustre","north_island_edelweiss, leucogenes_leontopodium","blazing_star, button_snakeroot, gayfeather, gay-feather, snakeroot","dotted_gayfeather, liatris_punctata","dense_blazing_star, liatris_pycnostachya","texas_star, lindheimera_texana","african_daisy, yellow_ageratum, lonas_inodora, lonas_annua","tahoka_daisy, tansy_leaf_aster, machaeranthera_tanacetifolia","sticky_aster, machaeranthera_bigelovii","mojave_aster, machaeranthera_tortifoloia","tarweed","sweet_false_chamomile, wild_chamomile, german_chamomile, matricaria_recutita, matricaria_chamomilla","pineapple_weed, rayless_chamomile, matricaria_matricarioides","climbing_hempweed, climbing_boneset, wild_climbing_hempweed, climbing_hemp-vine, mikania_scandens","mutisia","rattlesnake_root","white_lettuce, cankerweed, nabalus_alba, prenanthes_alba","daisybush, daisy-bush, daisy_bush","new_zealand_daisybush, olearia_haastii","cotton_thistle, woolly_thistle, scotch_thistle, onopordum_acanthium, onopordon_acanthium","othonna","cascade_everlasting, ozothamnus_secundiflorus, helichrysum_secundiflorum","butterweed","american_feverfew, wild_quinine, prairie_dock, parthenium_integrifolium","cineraria, pericallis_cruenta, senecio_cruentus","florest's_cineraria, pericallis_hybrida","butterbur, bog_rhubarb, petasites_hybridus, petasites_vulgaris","winter_heliotrope, sweet_coltsfoot, petasites_fragrans","sweet_coltsfoot, petasites_sagitattus","oxtongue, bristly_oxtongue, bitterweed, bugloss, picris_echioides","hawkweed","mouse-ear_hawkweed, pilosella_officinarum, hieracium_pilocella","stevia","rattlesnake_root, prenanthes_purpurea","fleabane, feabane_mullet, pulicaria_dysenterica","sheep_plant, vegetable_sheep, raoulia_lutescens, raoulia_australis","coneflower","mexican_hat, ratibida_columnaris","long-head_coneflower, prairie_coneflower, ratibida_columnifera","prairie_coneflower, ratibida_tagetes","swan_river_everlasting, rhodanthe, rhodanthe_manglesii, helipterum_manglesii","coneflower","black-eyed_susan, rudbeckia_hirta, rudbeckia_serotina","cutleaved_coneflower, rudbeckia_laciniata","golden_glow, double_gold, hortensia, rudbeckia_laciniata_hortensia","lavender_cotton, santolina_chamaecyparissus","creeping_zinnia, sanvitalia_procumbens","golden_thistle","spanish_oyster_plant, scolymus_hispanicus","nodding_groundsel, senecio_bigelovii","dusty_miller, senecio_cineraria, cineraria_maritima","butterweed, ragwort, senecio_glabellus","ragwort, tansy_ragwort, ragweed, benweed, senecio_jacobaea","arrowleaf_groundsel, senecio_triangularis","black_salsify, viper's_grass, scorzonera, scorzonera_hispanica","white-topped_aster","narrow-leaved_white-topped_aster","silver_sage, silver_sagebrush, grey_sage, gray_sage, seriphidium_canum, artemisia_cana","sea_wormwood, seriphidium_maritimum, artemisia_maritima","sawwort, serratula_tinctoria","rosinweed, silphium_laciniatum","milk_thistle, lady's_thistle, our_lady's_mild_thistle, holy_thistle, blessed_thistle, silybum_marianum","goldenrod","silverrod, solidago_bicolor","meadow_goldenrod, canadian_goldenrod, solidago_canadensis","missouri_goldenrod, solidago_missouriensis","alpine_goldenrod, solidago_multiradiata","grey_goldenrod, gray_goldenrod, solidago_nemoralis","blue_mountain_tea, sweet_goldenrod, solidago_odora","dyer's_weed, solidago_rugosa","seaside_goldenrod, beach_goldenrod, solidago_sempervirens","narrow_goldenrod, solidago_spathulata","boott's_goldenrod","elliott's_goldenrod","ohio_goldenrod","rough-stemmed_goldenrod","showy_goldenrod","tall_goldenrod","zigzag_goldenrod, broad_leaved_goldenrod","sow_thistle, milk_thistle","milkweed, sonchus_oleraceus","stevia","stokes'_aster, cornflower_aster, stokesia_laevis","marigold","african_marigold, big_marigold, aztec_marigold, tagetes_erecta","french_marigold, tagetes_patula","painted_daisy, pyrethrum, tanacetum_coccineum, chrysanthemum_coccineum","pyrethrum, dalmatian_pyrethrum, dalmatia_pyrethrum, tanacetum_cinerariifolium, chrysanthemum_cinerariifolium","northern_dune_tansy, tanacetum_douglasii","feverfew, tanacetum_parthenium, chrysanthemum_parthenium","dusty_miller, silver-lace, silver_lace, tanacetum_ptarmiciflorum, chrysanthemum_ptarmiciflorum","tansy, golden_buttons, scented_fern, tanacetum_vulgare","dandelion, blowball","common_dandelion, taraxacum_ruderalia, taraxacum_officinale","dandelion_green","russian_dandelion, kok-saghyz, kok-sagyz, taraxacum_kok-saghyz","stemless_hymenoxys, tetraneuris_acaulis, hymenoxys_acaulis","mexican_sunflower, tithonia","easter_daisy, stemless_daisy, townsendia_exscapa","yellow_salsify, tragopogon_dubius","salsify, oyster_plant, vegetable_oyster, tragopogon_porrifolius","meadow_salsify, goatsbeard, shepherd's_clock, tragopogon_pratensis","scentless_camomile, scentless_false_camomile, scentless_mayweed, scentless_hayweed, corn_mayweed, tripleurospermum_inodorum, matricaria_inodorum","turfing_daisy, tripleurospermum_tchihatchewii, matricaria_tchihatchewii","coltsfoot, tussilago_farfara","ursinia","crownbeard, crown-beard, crown_beard","wingstem, golden_ironweed, yellow_ironweed, golden_honey_plant, verbesina_alternifolia, actinomeris_alternifolia","cowpen_daisy, golden_crownbeard, golden_crown_beard, butter_daisy, verbesina_encelioides, ximenesia_encelioides","gravelweed, verbesina_helianthoides","virginia_crownbeard, frostweed, frost-weed, verbesina_virginica","ironweed, vernonia","mule's_ears, wyethia_amplexicaulis","white-rayed_mule's_ears, wyethia_helianthoides","cocklebur, cockle-bur, cockleburr, cockle-burr","xeranthemum","immortelle, xeranthemum_annuum","zinnia, old_maid, old_maid_flower","white_zinnia, zinnia_acerosa","little_golden_zinnia, zinnia_grandiflora","blazing_star, mentzelia_livicaulis, mentzelia_laevicaulis","bartonia, mentzelia_lindleyi","achene","samara, key_fruit, key","campanula, bellflower","creeping_bellflower, campanula_rapunculoides","canterbury_bell, cup_and_saucer, campanula_medium","tall_bellflower, campanula_americana","marsh_bellflower, campanula_aparinoides","clustered_bellflower, campanula_glomerata","peach_bells, peach_bell, willow_bell, campanula_persicifolia","chimney_plant, chimney_bellflower, campanula_pyramidalis","rampion, rampion_bellflower, campanula_rapunculus","tussock_bellflower, spreading_bellflower, campanula_carpatica","orchid, orchidaceous_plant","orchis","male_orchis, early_purple_orchid, orchis_mascula","butterfly_orchid, butterfly_orchis, orchis_papilionaceae","showy_orchis, purple_orchis, purple-hooded_orchis, orchis_spectabilis","aerides","angrecum","jewel_orchid","puttyroot, adam-and-eve, aplectrum_hyemale","arethusa","bog_rose, wild_pink, dragon's_mouth, arethusa_bulbosa","bletia","bletilla_striata, bletia_striata","brassavola","spider_orchid, brassia_lawrenceana","spider_orchid, brassia_verrucosa","caladenia","calanthe","grass_pink, calopogon_pulchellum, calopogon_tuberosum","calypso, fairy-slipper, calypso_bulbosa","cattleya","helleborine","red_helleborine, cephalanthera_rubra","spreading_pogonia, funnel-crest_rosebud_orchid, cleistes_divaricata, pogonia_divaricata","rosebud_orchid, cleistes_rosea, pogonia_rosea","satyr_orchid, coeloglossum_bracteatum","frog_orchid, coeloglossum_viride","coelogyne","coral_root","spotted_coral_root, corallorhiza_maculata","striped_coral_root, corallorhiza_striata","early_coral_root, pale_coral_root, corallorhiza_trifida","swan_orchid, swanflower, swan-flower, swanneck, swan-neck","cymbid, cymbidium","cypripedia","lady's_slipper, lady-slipper, ladies'_slipper, slipper_orchid","moccasin_flower, nerveroot, cypripedium_acaule","common_lady's-slipper, showy_lady's-slipper, showy_lady_slipper, cypripedium_reginae, cypripedium_album","ram's-head, ram's-head_lady's_slipper, cypripedium_arietinum","yellow_lady's_slipper, yellow_lady-slipper, cypripedium_calceolus, cypripedium_parviflorum","large_yellow_lady's_slipper, cypripedium_calceolus_pubescens","california_lady's_slipper, cypripedium_californicum","clustered_lady's_slipper, cypripedium_fasciculatum","mountain_lady's_slipper, cypripedium_montanum","marsh_orchid","common_spotted_orchid, dactylorhiza_fuchsii, dactylorhiza_maculata_fuchsii","dendrobium","disa","phantom_orchid, snow_orchid, eburophyton_austinae","tulip_orchid, encyclia_citrina, cattleya_citrina","butterfly_orchid, encyclia_tampensis, epidendrum_tampense","butterfly_orchid, butterfly_orchis, epidendrum_venosum, encyclia_venosa","epidendron","helleborine","epipactis_helleborine","stream_orchid, chatterbox, giant_helleborine, epipactis_gigantea","tongueflower, tongue-flower","rattlesnake_plantain, helleborine","fragrant_orchid, gymnadenia_conopsea","short-spurred_fragrant_orchid, gymnadenia_odoratissima","fringed_orchis, fringed_orchid","frog_orchid","rein_orchid, rein_orchis","bog_rein_orchid, bog_candles, habenaria_dilatata","white_fringed_orchis, white_fringed_orchid, habenaria_albiflora","elegant_habenaria, habenaria_elegans","purple-fringed_orchid, purple-fringed_orchis, habenaria_fimbriata","coastal_rein_orchid, habenaria_greenei","hooker's_orchid, habenaria_hookeri","ragged_orchid, ragged_orchis, ragged-fringed_orchid, green_fringed_orchis, habenaria_lacera","prairie_orchid, prairie_white-fringed_orchis, habenaria_leucophaea","snowy_orchid, habenaria_nivea","round-leaved_rein_orchid, habenaria_orbiculata","purple_fringeless_orchid, purple_fringeless_orchis, habenaria_peramoena","purple-fringed_orchid, purple-fringed_orchis, habenaria_psycodes","alaska_rein_orchid, habenaria_unalascensis","crested_coral_root, hexalectris_spicata","texas_purple_spike, hexalectris_warnockii","lizard_orchid, himantoglossum_hircinum","laelia","liparis","twayblade","fen_orchid, fen_orchis, liparis_loeselii","broad-leaved_twayblade, listera_convallarioides","lesser_twayblade, listera_cordata","twayblade, listera_ovata","green_adder's_mouth, malaxis-unifolia, malaxis_ophioglossoides","masdevallia","maxillaria","pansy_orchid","odontoglossum","oncidium, dancing_lady_orchid, butterfly_plant, butterfly_orchid","bee_orchid, ophrys_apifera","fly_orchid, ophrys_insectifera, ophrys_muscifera","spider_orchid","early_spider_orchid, ophrys_sphegodes","venus'_slipper, venus's_slipper, venus's_shoe","phaius","moth_orchid, moth_plant","butterfly_plant, phalaenopsis_amabilis","rattlesnake_orchid","lesser_butterfly_orchid, platanthera_bifolia, habenaria_bifolia","greater_butterfly_orchid, platanthera_chlorantha, habenaria_chlorantha","prairie_white-fringed_orchid, platanthera_leucophea","tangle_orchid","indian_crocus","pleurothallis","pogonia","butterfly_orchid","psychopsis_krameriana, oncidium_papilio_kramerianum","psychopsis_papilio, oncidium_papilio","helmet_orchid, greenhood","foxtail_orchid","orange-blossom_orchid, sarcochilus_falcatus","sobralia","ladies'_tresses, lady's_tresses","screw_augur, spiranthes_cernua","hooded_ladies'_tresses, spiranthes_romanzoffiana","western_ladies'_tresses, spiranthes_porrifolia","european_ladies'_tresses, spiranthes_spiralis","stanhopea","stelis","fly_orchid","vanda","blue_orchid, vanda_caerulea","vanilla","vanilla_orchid, vanilla_planifolia","yam, yam_plant","yam","white_yam, water_yam, dioscorea_alata","cinnamon_vine, chinese_yam, dioscorea_batata","elephant's-foot, tortoise_plant, hottentot_bread_vine, hottentot's_bread_vine, dioscorea_elephantipes","wild_yam, dioscorea_paniculata","cush-cush, dioscorea_trifida","black_bryony, black_bindweed, tamus_communis","primrose, primula","english_primrose, primula_vulgaris","cowslip, paigle, primula_veris","oxlip, paigle, primula_elatior","chinese_primrose, primula_sinensis","polyanthus, primula_polyantha","pimpernel","scarlet_pimpernel, red_pimpernel, poor_man's_weatherglass, anagallis_arvensis","bog_pimpernel, anagallis_tenella","chaffweed, bastard_pimpernel, false_pimpernel","cyclamen, cyclamen_purpurascens","sowbread, cyclamen_hederifolium, cyclamen_neopolitanum","sea_milkwort, sea_trifoly, black_saltwort, glaux_maritima","featherfoil, feather-foil","water_gillyflower, american_featherfoil, hottonia_inflata","water_violet, hottonia_palustris","loosestrife","gooseneck_loosestrife, lysimachia_clethroides_duby","yellow_pimpernel, lysimachia_nemorum","fringed_loosestrife, lysimachia_ciliatum","moneywort, creeping_jenny, creeping_charlie, lysimachia_nummularia","swamp_candles, lysimachia_terrestris","whorled_loosestrife, lysimachia_quadrifolia","water_pimpernel","brookweed, samolus_valerandii","brookweed, samolus_parviflorus, samolus_floribundus","coralberry, spiceberry, ardisia_crenata","marlberry, ardisia_escallonoides, ardisia_paniculata","plumbago","leadwort, plumbago_europaea","thrift","sea_lavender, marsh_rosemary, statice","barbasco, joewood, jacquinia_keyensis","gramineous_plant, graminaceous_plant","grass","midgrass","shortgrass, short-grass","sword_grass","tallgrass, tall-grass","herbage, pasturage","goat_grass, aegilops_triuncalis","wheatgrass, wheat-grass","crested_wheatgrass, crested_wheat_grass, fairway_crested_wheat_grass, agropyron_cristatum","bearded_wheatgrass, agropyron_subsecundum","western_wheatgrass, bluestem_wheatgrass, agropyron_smithii","intermediate_wheatgrass, agropyron_intermedium, elymus_hispidus","slender_wheatgrass, agropyron_trachycaulum, agropyron_pauciflorum, elymus_trachycaulos","velvet_bent, velvet_bent_grass, brown_bent, rhode_island_bent, dog_bent, agrostis_canina","cloud_grass, agrostis_nebulosa","meadow_foxtail, alopecurus_pratensis","foxtail, foxtail_grass","broom_grass","broom_sedge, andropogon_virginicus","tall_oat_grass, tall_meadow_grass, evergreen_grass, false_oat, french_rye, arrhenatherum_elatius","toetoe, toitoi, arundo_conspicua, chionochloa_conspicua","oat","cereal_oat, avena_sativa","wild_oat, wild_oat_grass, avena_fatua","slender_wild_oat, avena_barbata","wild_red_oat, animated_oat, avene_sterilis","brome, bromegrass","chess, cheat, bromus_secalinus","field_brome, bromus_arvensis","grama, grama_grass, gramma, gramma_grass","black_grama, bouteloua_eriopoda","buffalo_grass, buchloe_dactyloides","reed_grass","feather_reed_grass, feathertop, calamagrostis_acutiflora","australian_reed_grass, calamagrostic_quadriseta","burgrass, bur_grass","buffel_grass, cenchrus_ciliaris, pennisetum_cenchroides","rhodes_grass, chloris_gayana","pampas_grass, cortaderia_selloana","giant_star_grass, cynodon_plectostachyum","orchard_grass, cocksfoot, cockspur, dactylis_glomerata","egyptian_grass, crowfoot_grass, dactyloctenium_aegypticum","crabgrass, crab_grass, finger_grass","smooth_crabgrass, digitaria_ischaemum","large_crabgrass, hairy_finger_grass, digitaria_sanguinalis","barnyard_grass, barn_grass, barn_millet, echinochloa_crusgalli","japanese_millet, billion-dollar_grass, japanese_barnyard_millet, sanwa_millet, echinochloa_frumentacea","yardgrass, yard_grass, wire_grass, goose_grass, eleusine_indica","finger_millet, ragi, ragee, african_millet, coracan, corakan, kurakkan, eleusine_coracana","lyme_grass","wild_rye","giant_ryegrass, elymus_condensatus, leymus_condensatus","sea_lyme_grass, european_dune_grass, elymus_arenarius, leymus_arenaria","canada_wild_rye, elymus_canadensis","teff, teff_grass, eragrostis_tef, eragrostic_abyssinica","weeping_love_grass, african_love_grass, eragrostis_curvula","plume_grass","ravenna_grass, wool_grass, erianthus_ravennae","fescue, fescue_grass, meadow_fescue, festuca_elatior","reed_meadow_grass, glyceria_grandis","velvet_grass, yorkshire_fog, holcus_lanatus","creeping_soft_grass, holcus_mollis","barleycorn","barley_grass, wall_barley, hordeum_murinum","little_barley, hordeum_pusillum","rye_grass, ryegrass","perennial_ryegrass, english_ryegrass, lolium_perenne","italian_ryegrass, italian_rye, lolium_multiflorum","darnel, tare, bearded_darnel, cheat, lolium_temulentum","nimblewill, nimble_will, muhlenbergia_schreberi","cultivated_rice, oryza_sativa","ricegrass, rice_grass","smilo, smilo_grass, oryzopsis_miliacea","switch_grass, panicum_virgatum","broomcorn_millet, hog_millet, panicum_miliaceum","goose_grass, texas_millet, panicum_texanum","dallisgrass, dallis_grass, paspalum, paspalum_dilatatum","bahia_grass, paspalum_notatum","knotgrass, paspalum_distichum","fountain_grass, pennisetum_ruppelii, pennisetum_setaceum","reed_canary_grass, gardener's_garters, lady's_laces, ribbon_grass, phalaris_arundinacea","canary_grass, birdseed_grass, phalaris_canariensis","timothy, herd's_grass, phleum_pratense","bluegrass, blue_grass","meadowgrass, meadow_grass","wood_meadowgrass, poa_nemoralis, agrostis_alba","noble_cane","munj, munja, saccharum_bengalense, saccharum_munja","broom_beard_grass, prairie_grass, wire_grass, andropogon_scoparius, schizachyrium_scoparium","bluestem, blue_stem, andropogon_furcatus, andropogon_gerardii","rye, secale_cereale","bristlegrass, bristle_grass","giant_foxtail","yellow_bristlegrass, yellow_bristle_grass, yellow_foxtail, glaucous_bristlegrass, setaria_glauca","green_bristlegrass, green_foxtail, rough_bristlegrass, bottle-grass, bottle_grass, setaria_viridis","siberian_millet, setaria_italica_rubrofructa","german_millet, golden_wonder_millet, setaria_italica_stramineofructa","millet","rattan, rattan_cane","malacca","reed","sorghum","grain_sorghum","durra, doura, dourah, egyptian_corn, indian_millet, guinea_corn","feterita, federita, sorghum_vulgare_caudatum","hegari","kaoliang","milo, milo_maize","shallu, sorghum_vulgare_rosburghii","broomcorn, sorghum_vulgare_technicum","cordgrass, cord_grass","salt_reed_grass, spartina_cynosuroides","prairie_cordgrass, freshwater_cordgrass, slough_grass, spartina_pectinmata","smut_grass, blackseed, carpet_grass, sporobolus_poiretii","sand_dropseed, sporobolus_cryptandrus","rush_grass, rush-grass","st._augustine_grass, stenotaphrum_secundatum, buffalo_grass","grain","cereal, cereal_grass","wheat","wheat_berry","durum, durum_wheat, hard_wheat, triticum_durum, triticum_turgidum, macaroni_wheat","spelt, triticum_spelta, triticum_aestivum_spelta","emmer, starch_wheat, two-grain_spelt, triticum_dicoccum","wild_wheat, wild_emmer, triticum_dicoccum_dicoccoides","corn, maize, indian_corn, zea_mays","mealie","corn","dent_corn, zea_mays_indentata","flint_corn, flint_maize, yankee_corn, zea_mays_indurata","popcorn, zea_mays_everta","zoysia","manila_grass, japanese_carpet_grass, zoysia_matrella","korean_lawn_grass, japanese_lawn_grass, zoysia_japonica","bamboo","common_bamboo, bambusa_vulgaris","giant_bamboo, kyo-chiku, dendrocalamus_giganteus","umbrella_plant, umbrella_sedge, cyperus_alternifolius","chufa, yellow_nutgrass, earth_almond, ground_almond, rush_nut, cyperus_esculentus","galingale, galangal, cyperus_longus","nutgrass, nut_grass, nutsedge, nut_sedge, cyperus_rotundus","sand_sedge, sand_reed, carex_arenaria","cypress_sedge, carex_pseudocyperus","cotton_grass, cotton_rush","common_cotton_grass, eriophorum_angustifolium","hardstem_bulrush, hardstemmed_bulrush, scirpus_acutus","wool_grass, scirpus_cyperinus","spike_rush","water_chestnut, chinese_water_chestnut, eleocharis_dulcis","needle_spike_rush, needle_rush, slender_spike_rush, hair_grass, eleocharis_acicularis","creeping_spike_rush, eleocharis_palustris","pandanus, screw_pine","textile_screw_pine, lauhala, pandanus_tectorius","cattail","cat's-tail, bullrush, bulrush, nailrod, reed_mace, reedmace, typha_latifolia","bur_reed","grain, caryopsis","kernel","rye","gourd, gourd_vine","gourd","pumpkin, pumpkin_vine, autumn_pumpkin, cucurbita_pepo","squash, squash_vine","summer_squash, summer_squash_vine, cucurbita_pepo_melopepo","yellow_squash","marrow, marrow_squash, vegetable_marrow","zucchini, courgette","cocozelle, italian_vegetable_marrow","cymling, pattypan_squash","spaghetti_squash","winter_squash, winter_squash_plant","acorn_squash","hubbard_squash, cucurbita_maxima","turban_squash, cucurbita_maxima_turbaniformis","buttercup_squash","butternut_squash, cucurbita_maxima","winter_crookneck, winter_crookneck_squash, cucurbita_moschata","cushaw, cucurbita_mixta, cucurbita_argyrosperma","prairie_gourd, prairie_gourd_vine, missouri_gourd, wild_pumpkin, buffalo_gourd, calabazilla, cucurbita_foetidissima","prairie_gourd","bryony, briony","white_bryony, devil's_turnip, bryonia_alba","sweet_melon, muskmelon, sweet_melon_vine, cucumis_melo","cantaloupe, cantaloup, cantaloupe_vine, cantaloup_vine, cucumis_melo_cantalupensis","winter_melon, persian_melon, honeydew_melon, winter_melon_vine, cucumis_melo_inodorus","net_melon, netted_melon, nutmeg_melon, cucumis_melo_reticulatus","cucumber, cucumber_vine, cucumis_sativus","squirting_cucumber, exploding_cucumber, touch-me-not, ecballium_elaterium","bottle_gourd, calabash, lagenaria_siceraria","luffa, dishcloth_gourd, sponge_gourd, rag_gourd, strainer_vine","loofah, vegetable_sponge, luffa_cylindrica","angled_loofah, sing-kwa, luffa_acutangula","loofa, loofah, luffa, loufah_sponge","balsam_apple, momordica_balsamina","balsam_pear, momordica_charantia","lobelia","water_lobelia, lobelia_dortmanna","mallow","musk_mallow, mus_rose, malva_moschata","common_mallow, malva_neglecta","okra, gumbo, okra_plant, lady's-finger, abelmoschus_esculentus, hibiscus_esculentus","okra","abelmosk, musk_mallow, abelmoschus_moschatus, hibiscus_moschatus","flowering_maple","velvetleaf, velvet-leaf, velvetweed, indian_mallow, butter-print, china_jute, abutilon_theophrasti","hollyhock","rose_mallow, alcea_rosea, althea_rosea","althea, althaea, hollyhock","marsh_mallow, white_mallow, althea_officinalis","poppy_mallow","fringed_poppy_mallow, callirhoe_digitata","purple_poppy_mallow, callirhoe_involucrata","clustered_poppy_mallow, callirhoe_triangulata","sea_island_cotton, tree_cotton, gossypium_barbadense","levant_cotton, gossypium_herbaceum","upland_cotton, gossypium_hirsutum","peruvian_cotton, gossypium_peruvianum","wild_cotton, arizona_wild_cotton, gossypium_thurberi","kenaf, kanaf, deccan_hemp, bimli, bimli_hemp, indian_hemp, bombay_hemp, hibiscus_cannabinus","sorrel_tree, hibiscus_heterophyllus","rose_mallow, swamp_mallow, common_rose_mallow, swamp_rose_mallow, hibiscus_moscheutos","cotton_rose, confederate_rose, confederate_rose_mallow, hibiscus_mutabilis","roselle, rozelle, sorrel, red_sorrel, jamaica_sorrel, hibiscus_sabdariffa","mahoe, majagua, mahagua, balibago, purau, hibiscus_tiliaceus","flower-of-an-hour, flowers-of-an-hour, bladder_ketmia, black-eyed_susan, hibiscus_trionum","lacebark, ribbonwood, houhere, hoheria_populnea","wild_hollyhock, iliamna_remota, sphaeralcea_remota","mountain_hollyhock, iliamna_ruvularis, iliamna_acerifolia","seashore_mallow","salt_marsh_mallow, kosteletzya_virginica","chaparral_mallow, malacothamnus_fasciculatus, sphaeralcea_fasciculata","malope, malope_trifida","false_mallow","waxmallow, wax_mallow, sleeping_hibiscus","glade_mallow, napaea_dioica","pavonia","ribbon_tree, ribbonwood, plagianthus_regius, plagianthus_betulinus","bush_hibiscus, radyera_farragei, hibiscus_farragei","virginia_mallow, sida_hermaphrodita","queensland_hemp, jellyleaf, sida_rhombifolia","indian_mallow, sida_spinosa","checkerbloom, wild_hollyhock, sidalcea_malviflora","globe_mallow, false_mallow","prairie_mallow, red_false_mallow, sphaeralcea_coccinea, malvastrum_coccineum","tulipwood_tree","portia_tree, bendy_tree, seaside_mahoe, thespesia_populnea","red_silk-cotton_tree, simal, bombax_ceiba, bombax_malabarica","cream-of-tartar_tree, sour_gourd, adansonia_gregorii","baobab, monkey-bread_tree, adansonia_digitata","kapok, ceiba_tree, silk-cotton_tree, white_silk-cotton_tree, bombay_ceiba, god_tree, ceiba_pentandra","durian, durion, durian_tree, durio_zibethinus","montezuma","shaving-brush_tree, pseudobombax_ellipticum","quandong, quandong_tree, brisbane_quandong, silver_quandong_tree, blue_fig, elaeocarpus_grandis","quandong, blue_fig","makomako, new_zealand_wine_berry, wineberry, aristotelia_serrata, aristotelia_racemosa","jamaican_cherry, calabur_tree, calabura, silk_wood, silkwood, muntingia_calabura","breakax, breakaxe, break-axe, sloanea_jamaicensis","sterculia","panama_tree, sterculia_apetala","kalumpang, java_olives, sterculia_foetida","bottle-tree, bottle_tree","flame_tree, flame_durrajong, brachychiton_acerifolius, sterculia_acerifolia","flame_tree, broad-leaved_bottletree, brachychiton_australis","kurrajong, currajong, brachychiton_populneus","queensland_bottletree, narrow-leaved_bottletree, brachychiton_rupestris, sterculia_rupestris","kola, kola_nut, kola_nut_tree, goora_nut, cola_acuminata","kola_nut, cola_nut","chinese_parasol_tree, chinese_parasol, japanese_varnish_tree, phoenix_tree, firmiana_simplex","flannelbush, flannel_bush, california_beauty","screw_tree","nut-leaved_screw_tree, helicteres_isora","red_beech, brown_oak, booyong, crow's_foot, stave_wood, silky_elm, heritiera_trifoliolata, terrietia_trifoliolata","looking_glass_tree, heritiera_macrophylla","looking-glass_plant, heritiera_littoralis","honey_bell, honeybells, hermannia_verticillata, mahernia_verticillata","mayeng, maple-leaved_bayur, pterospermum_acerifolium","silver_tree, tarrietia_argyrodendron","cacao, cacao_tree, chocolate_tree, theobroma_cacao","obeche, obechi, arere, samba, triplochiton_scleroxcylon","linden, linden_tree, basswood, lime, lime_tree","american_basswood, american_lime, tilia_americana","small-leaved_linden, small-leaved_lime, tilia_cordata","white_basswood, cottonwood, tilia_heterophylla","japanese_linden, japanese_lime, tilia_japonica","silver_lime, silver_linden, tilia_tomentosa","corchorus","african_hemp, sparmannia_africana","herb, herbaceous_plant","protea","honeypot, king_protea, protea_cynaroides","honeyflower, honey-flower, protea_mellifera","banksia","honeysuckle, australian_honeysuckle, coast_banksia, banksia_integrifolia","smoke_bush","chilean_firebush, chilean_flameflower, embothrium_coccineum","chilean_nut, chile_nut, chile_hazel, chilean_hazelnut, guevina_heterophylla, guevina_avellana","grevillea","red-flowered_silky_oak, grevillea_banksii","silky_oak, grevillea_robusta","beefwood, grevillea_striata","cushion_flower, pincushion_hakea, hakea_laurina","rewa-rewa, new_zealand_honeysuckle","honeyflower, honey-flower, mountain_devil, lambertia_formosa","silver_tree, leucadendron_argenteum","lomatia","macadamia, macadamia_tree","macadamia_integrifolia","macadamia_nut, macadamia_nut_tree, macadamia_ternifolia","queensland_nut, macadamia_tetraphylla","prickly_ash, orites_excelsa","geebung","wheel_tree, firewheel_tree, stenocarpus_sinuatus","scrub_beefwood, beefwood, stenocarpus_salignus","waratah, telopea_oreades","waratah, telopea_speciosissima","casuarina","she-oak","beefwood","australian_pine, casuarina_equisetfolia","heath","tree_heath, briar, brier, erica_arborea","briarroot","winter_heath, spring_heath, erica_carnea","bell_heather, heather_bell, fine-leaved_heath, erica_cinerea","cornish_heath, erica_vagans","spanish_heath, portuguese_heath, erica_lusitanica","prince-of-wales'-heath, prince_of_wales_heath, erica_perspicua","bog_rosemary, moorwort, andromeda_glaucophylla","marsh_andromeda, common_bog_rosemary, andromeda_polifolia","madrona, madrono, manzanita, arbutus_menziesii","strawberry_tree, irish_strawberry, arbutus_unedo","bearberry","alpine_bearberry, black_bearberry, arctostaphylos_alpina","heartleaf_manzanita, arctostaphylos_andersonii","parry_manzanita, arctostaphylos_manzanita","spike_heath, bruckenthalia_spiculifolia","bryanthus","leatherleaf, chamaedaphne_calyculata","connemara_heath, st._dabeoc's_heath, daboecia_cantabrica","trailing_arbutus, mayflower, epigaea_repens","creeping_snowberry, moxie_plum, maidenhair_berry, gaultheria_hispidula","salal, shallon, gaultheria_shallon","huckleberry","black_huckleberry, gaylussacia_baccata","dangleberry, dangle-berry, gaylussacia_frondosa","box_huckleberry, gaylussacia_brachycera","kalmia","mountain_laurel, wood_laurel, american_laurel, calico_bush, kalmia_latifolia","swamp_laurel, bog_laurel, bog_kalmia, kalmia_polifolia","trapper's_tea, glandular_labrador_tea","wild_rosemary, marsh_tea, ledum_palustre","sand_myrtle, leiophyllum_buxifolium","leucothoe","dog_laurel, dog_hobble, switch-ivy, leucothoe_fontanesiana, leucothoe_editorum","sweet_bells, leucothoe_racemosa","alpine_azalea, mountain_azalea, loiseleuria_procumbens","staggerbush, stagger_bush, lyonia_mariana","maleberry, male_berry, privet_andromeda, he-huckleberry, lyonia_ligustrina","fetterbush, fetter_bush, shiny_lyonia, lyonia_lucida","false_azalea, fool's_huckleberry, menziesia_ferruginea","minniebush, minnie_bush, menziesia_pilosa","sorrel_tree, sourwood, titi, oxydendrum_arboreum","mountain_heath, phyllodoce_caerulea, bryanthus_taxifolius","purple_heather, brewer's_mountain_heather, phyllodoce_breweri","fetterbush, mountain_fetterbush, mountain_andromeda, pieris_floribunda","rhododendron","coast_rhododendron, rhododendron_californicum","rosebay, rhododendron_maxima","swamp_azalea, swamp_honeysuckle, white_honeysuckle, rhododendron_viscosum","azalea","cranberry","american_cranberry, large_cranberry, vaccinium_macrocarpon","european_cranberry, small_cranberry, vaccinium_oxycoccus","blueberry, blueberry_bush","farkleberry, sparkleberry, vaccinium_arboreum","low-bush_blueberry, low_blueberry, vaccinium_angustifolium, vaccinium_pennsylvanicum","rabbiteye_blueberry, rabbit-eye_blueberry, rabbiteye, vaccinium_ashei","dwarf_bilberry, dwarf_blueberry, vaccinium_caespitosum","evergreen_blueberry, vaccinium_myrsinites","evergreen_huckleberry, vaccinium_ovatum","bilberry, thin-leaved_bilberry, mountain_blue_berry, viccinium_membranaceum","bilberry, whortleberry, whinberry, blaeberry, viccinium_myrtillus","bog_bilberry, bog_whortleberry, moor_berry, vaccinium_uliginosum_alpinum","dryland_blueberry, dryland_berry, vaccinium_pallidum","grouseberry, grouse-berry, grouse_whortleberry, vaccinium_scoparium","deerberry, squaw_huckleberry, vaccinium_stamineum","cowberry, mountain_cranberry, lingonberry, lingenberry, lingberry, foxberry, vaccinium_vitis-idaea","diapensia","galax, galaxy, wandflower, beetleweed, coltsfoot, galax_urceolata","pyxie, pixie, pixy, pyxidanthera_barbulata","shortia","oconee_bells, shortia_galacifolia","australian_heath","epacris","common_heath, epacris_impressa","common_heath, blunt-leaf_heath, epacris_obtusifolia","port_jackson_heath, epacris_purpurascens","native_cranberry, groundberry, ground-berry, cranberry_heath, astroloma_humifusum, styphelia_humifusum","pink_fivecorner, styphelia_triflora","wintergreen, pyrola","false_wintergreen, pyrola_americana, pyrola_rotundifolia_americana","lesser_wintergreen, pyrola_minor","wild_lily_of_the_valley, shinleaf, pyrola_elliptica","wild_lily_of_the_valley, pyrola_rotundifolia","pipsissewa, prince's_pine","love-in-winter, western_prince's_pine, chimaphila_umbellata, chimaphila_corymbosa","one-flowered_wintergreen, one-flowered_pyrola, moneses_uniflora, pyrola_uniflora","indian_pipe, waxflower, monotropa_uniflora","pinesap, false_beachdrops, monotropa_hypopithys","beech, beech_tree","common_beech, european_beech, fagus_sylvatica","copper_beech, purple_beech, fagus_sylvatica_atropunicea, fagus_purpurea, fagus_sylvatica_purpurea","american_beech, white_beech, red_beech, fagus_grandifolia, fagus_americana","weeping_beech, fagus_pendula, fagus_sylvatica_pendula","japanese_beech","chestnut, chestnut_tree","american_chestnut, american_sweet_chestnut, castanea_dentata","european_chestnut, sweet_chestnut, spanish_chestnut, castanea_sativa","chinese_chestnut, castanea_mollissima","japanese_chestnut, castanea_crenata","allegheny_chinkapin, eastern_chinquapin, chinquapin, dwarf_chestnut, castanea_pumila","ozark_chinkapin, ozark_chinquapin, chinquapin, castanea_ozarkensis","oak_chestnut","giant_chinkapin, golden_chinkapin, chrysolepis_chrysophylla, castanea_chrysophylla, castanopsis_chrysophylla","dwarf_golden_chinkapin, chrysolepis_sempervirens","tanbark_oak, lithocarpus_densiflorus","japanese_oak, lithocarpus_glabra, lithocarpus_glaber","southern_beech, evergreen_beech","myrtle_beech, nothofagus_cuninghamii","coigue, nothofagus_dombeyi","new_zealand_beech","silver_beech, nothofagus_menziesii","roble_beech, nothofagus_obliqua","rauli_beech, nothofagus_procera","black_beech, nothofagus_solanderi","hard_beech, nothofagus_truncata","acorn","cupule, acorn_cup","oak, oak_tree","live_oak","coast_live_oak, california_live_oak, quercus_agrifolia","white_oak","american_white_oak, quercus_alba","arizona_white_oak, quercus_arizonica","swamp_white_oak, swamp_oak, quercus_bicolor","european_turkey_oak, turkey_oak, quercus_cerris","canyon_oak, canyon_live_oak, maul_oak, iron_oak, quercus_chrysolepis","scarlet_oak, quercus_coccinea","jack_oak, northern_pin_oak, quercus_ellipsoidalis","red_oak","southern_red_oak, swamp_red_oak, turkey_oak, quercus_falcata","oregon_white_oak, oregon_oak, garry_oak, quercus_garryana","holm_oak, holm_tree, holly-leaved_oak, evergreen_oak, quercus_ilex","bear_oak, quercus_ilicifolia","shingle_oak, laurel_oak, quercus_imbricaria","bluejack_oak, turkey_oak, quercus_incana","california_black_oak, quercus_kelloggii","american_turkey_oak, turkey_oak, quercus_laevis","laurel_oak, pin_oak, quercus_laurifolia","california_white_oak, valley_oak, valley_white_oak, roble, quercus_lobata","overcup_oak, quercus_lyrata","bur_oak, burr_oak, mossy-cup_oak, mossycup_oak, quercus_macrocarpa","scrub_oak","blackjack_oak, blackjack, jack_oak, quercus_marilandica","swamp_chestnut_oak, quercus_michauxii","japanese_oak, quercus_mongolica, quercus_grosseserrata","chestnut_oak","chinquapin_oak, chinkapin_oak, yellow_chestnut_oak, quercus_muehlenbergii","myrtle_oak, seaside_scrub_oak, quercus_myrtifolia","water_oak, possum_oak, quercus_nigra","nuttall_oak, nuttall's_oak, quercus_nuttalli","durmast, quercus_petraea, quercus_sessiliflora","basket_oak, cow_oak, quercus_prinus, quercus_montana","pin_oak, swamp_oak, quercus_palustris","willow_oak, quercus_phellos","dwarf_chinkapin_oak, dwarf_chinquapin_oak, dwarf_oak, quercus_prinoides","common_oak, english_oak, pedunculate_oak, quercus_robur","northern_red_oak, quercus_rubra, quercus_borealis","shumard_oak, shumard_red_oak, quercus_shumardii","post_oak, box_white_oak, brash_oak, iron_oak, quercus_stellata","cork_oak, quercus_suber","spanish_oak, quercus_texana","huckleberry_oak, quercus_vaccinifolia","chinese_cork_oak, quercus_variabilis","black_oak, yellow_oak, quercitron, quercitron_oak, quercus_velutina","southern_live_oak, quercus_virginiana","interior_live_oak, quercus_wislizenii, quercus_wizlizenii","mast","birch, birch_tree","yellow_birch, betula_alleghaniensis, betula_leutea","american_white_birch, paper_birch, paperbark_birch, canoe_birch, betula_cordifolia, betula_papyrifera","grey_birch, gray_birch, american_grey_birch, american_gray_birch, betula_populifolia","silver_birch, common_birch, european_white_birch, betula_pendula","downy_birch, white_birch, betula_pubescens","black_birch, river_birch, red_birch, betula_nigra","sweet_birch, cherry_birch, black_birch, betula_lenta","yukon_white_birch, betula_neoalaskana","swamp_birch, water_birch, mountain_birch, western_paper_birch, western_birch, betula_fontinalis","newfoundland_dwarf_birch, american_dwarf_birch, betula_glandulosa","alder, alder_tree","common_alder, european_black_alder, alnus_glutinosa, alnus_vulgaris","grey_alder, gray_alder, alnus_incana","seaside_alder, alnus_maritima","white_alder, mountain_alder, alnus_rhombifolia","red_alder, oregon_alder, alnus_rubra","speckled_alder, alnus_rugosa","smooth_alder, hazel_alder, alnus_serrulata","green_alder, alnus_veridis","green_alder, alnus_veridis_crispa, alnus_crispa","hornbeam","european_hornbeam, carpinus_betulus","american_hornbeam, carpinus_caroliniana","hop_hornbeam","old_world_hop_hornbeam, ostrya_carpinifolia","eastern_hop_hornbeam, ironwood, ironwood_tree, ostrya_virginiana","hazelnut, hazel, hazelnut_tree","american_hazel, corylus_americana","cobnut, filbert, corylus_avellana, corylus_avellana_grandis","beaked_hazelnut, corylus_cornuta","centaury","rosita, centaurium_calycosum","lesser_centaury, centaurium_minus","seaside_centaury","slender_centaury","prairie_gentian, tulip_gentian, bluebell, eustoma_grandiflorum","persian_violet, exacum_affine","columbo, american_columbo, deer's-ear, deer's-ears, pyramid_plant, american_gentian","gentian","gentianella, gentiana_acaulis","closed_gentian, blind_gentian, bottle_gentian, gentiana_andrewsii","explorer's_gentian, gentiana_calycosa","closed_gentian, blind_gentian, gentiana_clausa","great_yellow_gentian, gentiana_lutea","marsh_gentian, calathian_violet, gentiana_pneumonanthe","soapwort_gentian, gentiana_saponaria","striped_gentian, gentiana_villosa","agueweed, ague_weed, five-flowered_gentian, stiff_gentian, gentianella_quinquefolia, gentiana_quinquefolia","felwort, gentianella_amarella","fringed_gentian","gentianopsis_crinita, gentiana_crinita","gentianopsis_detonsa, gentiana_detonsa","gentianopsid_procera, gentiana_procera","gentianopsis_thermalis, gentiana_thermalis","tufted_gentian, gentianopsis_holopetala, gentiana_holopetala","spurred_gentian","sabbatia","toothbrush_tree, mustard_tree, salvadora_persica","olive_tree","olive, european_olive_tree, olea_europaea","olive","black_maire, olea_cunninghamii","white_maire, olea_lanceolata","fringe_tree","fringe_bush, chionanthus_virginicus","forestiera","forsythia","ash, ash_tree","white_ash, fraxinus_americana","swamp_ash, fraxinus_caroliniana","flowering_ash, fraxinus_cuspidata","european_ash, common_european_ash, fraxinus_excelsior","oregon_ash, fraxinus_latifolia, fraxinus_oregona","black_ash, basket_ash, brown_ash, hoop_ash, fraxinus_nigra","manna_ash, flowering_ash, fraxinus_ornus","red_ash, downy_ash, fraxinus_pennsylvanica","green_ash, fraxinus_pennsylvanica_subintegerrima","blue_ash, fraxinus_quadrangulata","mountain_ash, fraxinus_texensis","pumpkin_ash, fraxinus_tomentosa","arizona_ash, fraxinus_velutina","jasmine","primrose_jasmine, jasminum_mesnyi","winter_jasmine, jasminum_nudiflorum","common_jasmine, true_jasmine, jessamine, jasminum_officinale","privet","amur_privet, ligustrum_amurense","japanese_privet, ligustrum_japonicum","ligustrum_obtusifolium","common_privet, ligustrum_vulgare","devilwood, american_olive, osmanthus_americanus","mock_privet","lilac","himalayan_lilac, syringa_emodi","persian_lilac, syringa_persica","japanese_tree_lilac, syringa_reticulata, syringa_amurensis_japonica","japanese_lilac, syringa_villosa","common_lilac, syringa_vulgaris","bloodwort","kangaroo_paw, kangaroo's_paw, kangaroo's-foot, kangaroo-foot_plant, australian_sword_lily, anigozanthus_manglesii","virginian_witch_hazel, hamamelis_virginiana","vernal_witch_hazel, hamamelis_vernalis","winter_hazel, flowering_hazel","fothergilla, witch_alder","liquidambar","sweet_gum, sweet_gum_tree, bilsted, red_gum, american_sweet_gum, liquidambar_styraciflua","iron_tree, iron-tree, ironwood, ironwood_tree","walnut, walnut_tree","california_black_walnut, juglans_californica","butternut, butternut_tree, white_walnut, juglans_cinerea","black_walnut, black_walnut_tree, black_hickory, juglans_nigra","english_walnut, english_walnut_tree, circassian_walnut, persian_walnut, juglans_regia","hickory, hickory_tree","water_hickory, bitter_pecan, water_bitternut, carya_aquatica","pignut, pignut_hickory, brown_hickory, black_hickory, carya_glabra","bitternut, bitternut_hickory, bitter_hickory, bitter_pignut, swamp_hickory, carya_cordiformis","pecan, pecan_tree, carya_illinoensis, carya_illinoinsis","big_shellbark, big_shellbark_hickory, big_shagbark, king_nut, king_nut_hickory, carya_laciniosa","nutmeg_hickory, carya_myristicaeformis, carya_myristiciformis","shagbark, shagbark_hickory, shellbark, shellbark_hickory, carya_ovata","mockernut, mockernut_hickory, black_hickory, white-heart_hickory, big-bud_hickory, carya_tomentosa","wing_nut, wing-nut","caucasian_walnut, pterocarya_fraxinifolia","dhawa, dhava","combretum","hiccup_nut, hiccough_nut, combretum_bracteosum","bush_willow, combretum_appiculatum","bush_willow, combretum_erythrophyllum","button_tree, button_mangrove, conocarpus_erectus","white_mangrove, laguncularia_racemosa","oleaster","water_milfoil","anchovy_pear, anchovy_pear_tree, grias_cauliflora","brazil_nut, brazil-nut_tree, bertholletia_excelsa","loosestrife","purple_loosestrife, spiked_loosestrife, lythrum_salicaria","grass_poly, hyssop_loosestrife, lythrum_hyssopifolia","crape_myrtle, crepe_myrtle, crepe_flower, lagerstroemia_indica","queen's_crape_myrtle, pride-of-india, lagerstroemia_speciosa","myrtaceous_tree","myrtle","common_myrtle, myrtus_communis","bayberry, bay-rum_tree, jamaica_bayberry, wild_cinnamon, pimenta_acris","allspice, allspice_tree, pimento_tree, pimenta_dioica","allspice_tree, pimenta_officinalis","sour_cherry, eugenia_corynantha","nakedwood, eugenia_dicrana","surinam_cherry, pitanga, eugenia_uniflora","rose_apple, rose-apple_tree, jambosa, eugenia_jambos","feijoa, feijoa_bush","jaboticaba, jaboticaba_tree, myrciaria_cauliflora","guava, true_guava, guava_bush, psidium_guajava","guava, strawberry_guava, yellow_cattley_guava, psidium_littorale","cattley_guava, purple_strawberry_guava, psidium_cattleianum, psidium_littorale_longipes","brazilian_guava, psidium_guineense","gum_tree, gum","eucalyptus, eucalypt, eucalyptus_tree","flooded_gum","mallee","stringybark","smoothbark","red_gum, peppermint, peppermint_gum, eucalyptus_amygdalina","red_gum, marri, eucalyptus_calophylla","river_red_gum, river_gum, eucalyptus_camaldulensis, eucalyptus_rostrata","mountain_swamp_gum, eucalyptus_camphora","snow_gum, ghost_gum, white_ash, eucalyptus_coriacea, eucalyptus_pauciflora","alpine_ash, mountain_oak, eucalyptus_delegatensis","white_mallee, congoo_mallee, eucalyptus_dumosa","white_stringybark, thin-leaved_stringybark, eucalyptusd_eugenioides","white_mountain_ash, eucalyptus_fraxinoides","blue_gum, fever_tree, eucalyptus_globulus","rose_gum, eucalypt_grandis","cider_gum, eucalypt_gunnii","swamp_gum, eucalypt_ovata","spotted_gum, eucalyptus_maculata","lemon-scented_gum, eucalyptus_citriodora, eucalyptus_maculata_citriodora","black_mallee, black_sally, black_gum, eucalytus_stellulata","forest_red_gum, eucalypt_tereticornis","mountain_ash, eucalyptus_regnans","manna_gum, eucalyptus_viminalis","clove, clove_tree, syzygium_aromaticum, eugenia_aromaticum, eugenia_caryophyllatum","clove","tupelo, tupelo_tree","water_gum, nyssa_aquatica","sour_gum, black_gum, pepperidge, nyssa_sylvatica","enchanter's_nightshade","circaea_lutetiana","willowherb","fireweed, giant_willowherb, rosebay_willowherb, wickup, epilobium_angustifolium","california_fuchsia, humming_bird's_trumpet, epilobium_canum_canum, zauschneria_californica","fuchsia","lady's-eardrop, ladies'-eardrop, lady's-eardrops, ladies'-eardrops, fuchsia_coccinea","evening_primrose","common_evening_primrose, german_rampion, oenothera_biennis","sundrops, oenothera_fruticosa","missouri_primrose, ozark_sundrops, oenothera_macrocarpa","pomegranate, pomegranate_tree, punica_granatum","mangrove, rhizophora_mangle","daphne","garland_flower, daphne_cneorum","spurge_laurel, wood_laurel, daphne_laureola","mezereon, february_daphne, daphne_mezereum","indian_rhododendron, melastoma_malabathricum","medinilla_magnifica","deer_grass, meadow_beauty","canna","achira, indian_shot, arrowroot, canna_indica, canna_edulis","arrowroot, american_arrowroot, obedience_plant, maranta_arundinaceae","banana, banana_tree","dwarf_banana, musa_acuminata","japanese_banana, musa_basjoo","plantain, plantain_tree, musa_paradisiaca","edible_banana, musa_paradisiaca_sapientum","abaca, manila_hemp, musa_textilis","abyssinian_banana, ethiopian_banana, ensete_ventricosum, musa_ensete","ginger","common_ginger, canton_ginger, stem_ginger, zingiber_officinale","turmeric, curcuma_longa, curcuma_domestica","galangal, alpinia_galanga","shellflower, shall-flower, shell_ginger, alpinia_zerumbet, alpinia_speciosa, languas_speciosa","grains_of_paradise, guinea_grains, guinea_pepper, melagueta_pepper, aframomum_melegueta","cardamom, cardamon, elettaria_cardamomum","begonia","fibrous-rooted_begonia","tuberous_begonia","rhizomatous_begonia","christmas_begonia, blooming-fool_begonia, begonia_cheimantha","angel-wing_begonia, begonia_cocchinea","beefsteak_begonia, kidney_begonia, begonia_erythrophylla, begonia_feastii","star_begonia, star-leaf_begonia, begonia_heracleifolia","rex_begonia, king_begonia, painted-leaf_begonia, beefsteak_geranium, begonia_rex","wax_begonia, begonia_semperflorens","socotra_begonia, begonia_socotrana","hybrid_tuberous_begonia, begonia_tuberhybrida","dillenia","guinea_gold_vine, guinea_flower","poon","calaba, santa_maria_tree, calophyllum_calaba","maria, calophyllum_longifolium","laurelwood, lancewood_tree, calophyllum_candidissimum","alexandrian_laurel, calophyllum_inophyllum","clusia","wild_fig, clusia_flava","waxflower, clusia_insignis","pitch_apple, strangler_fig, clusia_rosea, clusia_major","mangosteen, mangosteen_tree, garcinia_mangostana","gamboge_tree, garcinia_hanburyi, garcinia_cambogia, garcinia_gummi-gutta","st_john's_wort","common_st_john's_wort, tutsan, hypericum_androsaemum","great_st_john's_wort, hypericum_ascyron, hypericum_pyramidatum","creeping_st_john's_wort, hypericum_calycinum","low_st_andrew's_cross, hypericum_hypericoides","klammath_weed, hypericum_perforatum","shrubby_st_john's_wort, hypericum_prolificum, hypericum_spathulatum","st_peter's_wort, hypericum_tetrapterum, hypericum_maculatum","marsh_st-john's_wort, hypericum_virginianum","mammee_apple, mammee, mamey, mammee_tree, mammea_americana","rose_chestnut, ironwood, ironwood_tree, mesua_ferrea","bower_actinidia, tara_vine, actinidia_arguta","chinese_gooseberry, kiwi, kiwi_vine, actinidia_chinensis, actinidia_deliciosa","silvervine, silver_vine, actinidia_polygama","wild_cinnamon, white_cinnamon_tree, canella_winterana, canella-alba","papaya, papaia, pawpaw, papaya_tree, melon_tree, carica_papaya","souari, souari_nut, souari_tree, caryocar_nuciferum","rockrose, rock_rose","white-leaved_rockrose, cistus_albidus","common_gum_cistus, cistus_ladanifer, cistus_ladanum","frostweed, frost-weed, frostwort, helianthemum_canadense, crocanthemum_canadense","dipterocarp","red_lauan, red_lauan_tree, shorea_teysmanniana","governor's_plum, governor_plum, madagascar_plum, ramontchi, batoko_palm, flacourtia_indica","kei_apple, kei_apple_bush, dovyalis_caffra","ketembilla, kitembilla, kitambilla, ketembilla_tree, ceylon_gooseberry, dovyalis_hebecarpa","chaulmoogra, chaulmoogra_tree, chaulmugra, hydnocarpus_kurzii, taraktagenos_kurzii, taraktogenos_kurzii","wild_peach, kiggelaria_africana","candlewood","boojum_tree, cirio, fouquieria_columnaris, idria_columnaris","bird's-eye_bush, ochna_serrulata","granadilla, purple_granadillo, passiflora_edulis","granadilla, sweet_granadilla, passiflora_ligularis","granadilla, giant_granadilla, passiflora_quadrangularis","maypop, passiflora_incarnata","jamaica_honeysuckle, yellow_granadilla, passiflora_laurifolia","banana_passion_fruit, passiflora_mollissima","sweet_calabash, passiflora_maliformis","love-in-a-mist, running_pop, wild_water_lemon, passiflora_foetida","reseda","mignonette, sweet_reseda, reseda_odorata","dyer's_rocket, dyer's_mignonette, weld, reseda_luteola","false_tamarisk, german_tamarisk, myricaria_germanica","halophyte","viola","violet","field_pansy, heartsease, viola_arvensis","american_dog_violet, viola_conspersa","dog_violet, heath_violet, viola_canina","horned_violet, tufted_pansy, viola_cornuta","two-eyed_violet, heartsease, viola_ocellata","bird's-foot_violet, pansy_violet, johnny-jump-up, wood_violet, viola_pedata","downy_yellow_violet, viola_pubescens","long-spurred_violet, viola_rostrata","pale_violet, striped_violet, cream_violet, viola_striata","hedge_violet, wood_violet, viola_sylvatica, viola_reichenbachiana","nettle","stinging_nettle, urtica_dioica","roman_nettle, urtica_pipulifera","ramie, ramee, chinese_silk_plant, china_grass, boehmeria_nivea","wood_nettle, laportea_canadensis","australian_nettle, australian_nettle_tree","pellitory-of-the-wall, wall_pellitory, pellitory, parietaria_difussa","richweed, clearweed, dead_nettle, pilea_pumilla","artillery_plant, pilea_microphylla","friendship_plant, panamica, panamiga, pilea_involucrata","queensland_grass-cloth_plant, pipturus_argenteus","pipturus_albidus","cannabis, hemp","indian_hemp, cannabis_indica","mulberry, mulberry_tree","white_mulberry, morus_alba","black_mulberry, morus_nigra","red_mulberry, morus_rubra","osage_orange, bow_wood, mock_orange, maclura_pomifera","breadfruit, breadfruit_tree, artocarpus_communis, artocarpus_altilis","jackfruit, jackfruit_tree, artocarpus_heterophyllus","marang, marang_tree, artocarpus_odoratissima","fig_tree","fig, common_fig, common_fig_tree, ficus_carica","caprifig, ficus_carica_sylvestris","golden_fig, florida_strangler_fig, strangler_fig, wild_fig, ficus_aurea","banyan, banyan_tree, banian, banian_tree, indian_banyan, east_indian_fig_tree, ficus_bengalensis","pipal, pipal_tree, pipul, peepul, sacred_fig, bo_tree, ficus_religiosa","india-rubber_tree, india-rubber_plant, india-rubber_fig, rubber_plant, assam_rubber, ficus_elastica","mistletoe_fig, mistletoe_rubber_plant, ficus_diversifolia, ficus_deltoidea","port_jackson_fig, rusty_rig, little-leaf_fig, botany_bay_fig, ficus_rubiginosa","sycamore, sycamore_fig, mulberry_fig, ficus_sycomorus","paper_mulberry, broussonetia_papyrifera","trumpetwood, trumpet-wood, trumpet_tree, snake_wood, imbauba, cecropia_peltata","elm, elm_tree","winged_elm, wing_elm, ulmus_alata","american_elm, white_elm, water_elm, rock_elm, ulmus_americana","smooth-leaved_elm, european_field_elm, ulmus_carpinifolia","cedar_elm, ulmus_crassifolia","witch_elm, wych_elm, ulmus_glabra","dutch_elm, ulmus_hollandica","huntingdon_elm, ulmus_hollandica_vegetata","water_elm, ulmus_laevis","chinese_elm, ulmus_parvifolia","english_elm, european_elm, ulmus_procera","siberian_elm, chinese_elm, dwarf_elm, ulmus_pumila","slippery_elm, red_elm, ulmus_rubra","jersey_elm, guernsey_elm, wheately_elm, ulmus_sarniensis, ulmus_campestris_sarniensis, ulmus_campestris_wheatleyi","september_elm, red_elm, ulmus_serotina","rock_elm, ulmus_thomasii","hackberry, nettle_tree","european_hackberry, mediterranean_hackberry, celtis_australis","american_hackberry, celtis_occidentalis","sugarberry, celtis_laevigata","iridaceous_plant","bearded_iris","beardless_iris","orrisroot, orris","dwarf_iris, iris_cristata","dutch_iris, iris_filifolia","florentine_iris, orris, iris_germanica_florentina, iris_florentina","stinking_iris, gladdon, gladdon_iris, stinking_gladwyn, roast_beef_plant, iris_foetidissima","german_iris, iris_germanica","japanese_iris, iris_kaempferi","german_iris, iris_kochii","dalmatian_iris, iris_pallida","persian_iris, iris_persica","dutch_iris, iris_tingitana","dwarf_iris, vernal_iris, iris_verna","spanish_iris, xiphium_iris, iris_xiphium","blackberry-lily, leopard_lily, belamcanda_chinensis","crocus","saffron, saffron_crocus, crocus_sativus","corn_lily","blue-eyed_grass","wandflower, sparaxis_tricolor","amaryllis","salsilla, bomarea_edulis","salsilla, bomarea_salsilla","blood_lily","cape_tulip, haemanthus_coccineus","hippeastrum, hippeastrum_puniceum","narcissus","daffodil, narcissus_pseudonarcissus","jonquil, narcissus_jonquilla","jonquil","jacobean_lily, aztec_lily, strekelia_formosissima","liliaceous_plant","mountain_lily, lilium_auratum","canada_lily, wild_yellow_lily, meadow_lily, wild_meadow_lily, lilium_canadense","tiger_lily, leopard_lily, pine_lily, lilium_catesbaei","columbia_tiger_lily, oregon_lily, lilium_columbianum","tiger_lily, devil_lily, kentan, lilium_lancifolium","easter_lily, bermuda_lily, white_trumpet_lily, lilium_longiflorum","coast_lily, lilium_maritinum","turk's-cap, martagon, lilium_martagon","michigan_lily, lilium_michiganense","leopard_lily, panther_lily, lilium_pardalinum","turk's-cap, turk's_cap-lily, lilium_superbum","african_lily, african_tulip, blue_african_lily, agapanthus_africanus","colicroot, colic_root, crow_corn, star_grass, unicorn_root","ague_root, ague_grass, aletris_farinosa","yellow_colicroot, aletris_aurea","alliaceous_plant","hooker's_onion, allium_acuminatum","wild_leek, levant_garlic, kurrat, allium_ampeloprasum","canada_garlic, meadow_leek, rose_leek, allium_canadense","keeled_garlic, allium_carinatum","onion","shallot, eschalot, multiplier_onion, allium_cepa_aggregatum, allium_ascalonicum","nodding_onion, nodding_wild_onion, lady's_leek, allium_cernuum","welsh_onion, japanese_leek, allium_fistulosum","red-skinned_onion, allium_haematochiton","daffodil_garlic, flowering_onion, naples_garlic, allium_neopolitanum","few-flowered_leek, allium_paradoxum","garlic, allium_sativum","sand_leek, giant_garlic, spanish_garlic, rocambole, allium_scorodoprasum","chives, chive, cive, schnittlaugh, allium_schoenoprasum","crow_garlic, false_garlic, field_garlic, stag's_garlic, wild_garlic, allium_vineale","wild_garlic, wood_garlic, ramsons, allium_ursinum","garlic_chive, chinese_chive, oriental_garlic, allium_tuberosum","round-headed_leek, allium_sphaerocephalum","three-cornered_leek, triquetrous_leek, allium_triquetrum","cape_aloe, aloe_ferox","kniphofia, tritoma, flame_flower, flame-flower, flameflower","poker_plant, kniphofia_uvaria","red-hot_poker, kniphofia_praecox","fly_poison, amianthum_muscaetoxicum, amianthum_muscitoxicum","amber_lily, anthericum_torreyi","asparagus, edible_asparagus, asparagus_officinales","asparagus_fern, asparagus_setaceous, asparagus_plumosus","smilax, asparagus_asparagoides","asphodel","jacob's_rod","aspidistra, cast-iron_plant, bar-room_plant, aspidistra_elatio","coral_drops, bessera_elegans","christmas_bells","climbing_onion, bowiea_volubilis","mariposa, mariposa_tulip, mariposa_lily","globe_lily, fairy_lantern","cat's-ear","white_globe_lily, white_fairy_lantern, calochortus_albus","yellow_globe_lily, golden_fairy_lantern, calochortus_amabilis","rose_globe_lily, calochortus_amoenus","star_tulip, elegant_cat's_ears, calochortus_elegans","desert_mariposa_tulip, calochortus_kennedyi","yellow_mariposa_tulip, calochortus_luteus","sagebrush_mariposa_tulip, calochortus_macrocarpus","sego_lily, calochortus_nuttallii","camas, camass, quamash, camosh, camash","common_camas, camassia_quamash","leichtlin's_camas, camassia_leichtlinii","wild_hyacinth, indigo_squill, camassia_scilloides","dogtooth_violet, dogtooth, dog's-tooth_violet","white_dogtooth_violet, white_dog's-tooth_violet, blonde_lilian, erythronium_albidum","yellow_adder's_tongue, trout_lily, amberbell, erythronium_americanum","european_dogtooth, erythronium_dens-canis","fawn_lily, erythronium_californicum","glacier_lily, snow_lily, erythronium_grandiflorum","avalanche_lily, erythronium_montanum","fritillary, checkered_lily","mission_bells, rice-grain_fritillary, fritillaria_affinis, fritillaria_lanceolata, fritillaria_mutica","mission_bells, black_fritillary, fritillaria_biflora","stink_bell, fritillaria_agrestis","crown_imperial, fritillaria_imperialis","white_fritillary, fritillaria_liliaceae","snake's_head_fritillary, guinea-hen_flower, checkered_daffodil, leper_lily, fritillaria_meleagris","adobe_lily, pink_fritillary, fritillaria_pluriflora","scarlet_fritillary, fritillaria_recurva","tulip","dwarf_tulip, tulipa_armena, tulipa_suaveolens","lady_tulip, candlestick_tulip, tulipa_clusiana","tulipa_gesneriana","cottage_tulip","darwin_tulip","gloriosa, glory_lily, climbing_lily, creeping_lily, gloriosa_superba","lemon_lily, hemerocallis_lilio-asphodelus, hemerocallis_flava","common_hyacinth, hyacinthus_orientalis","roman_hyacinth, hyacinthus_orientalis_albulus","summer_hyacinth, cape_hyacinth, hyacinthus_candicans, galtonia_candicans","star-of-bethlehem","bath_asparagus, prussian_asparagus, ornithogalum_pyrenaicum","grape_hyacinth","common_grape_hyacinth, muscari_neglectum","tassel_hyacinth, muscari_comosum","scilla, squill","spring_squill, scilla_verna, sea_onion","false_asphodel","scotch_asphodel, tofieldia_pusilla","sea_squill, sea_onion, squill, urginea_maritima","squill","butcher's_broom, ruscus_aculeatus","bog_asphodel","european_bog_asphodel, narthecium_ossifragum","american_bog_asphodel, narthecium_americanum","hellebore, false_hellebore","white_hellebore, american_hellebore, indian_poke, bugbane, veratrum_viride","squaw_grass, bear_grass, xerophyllum_tenax","death_camas, zigadene","alkali_grass, zigadenus_elegans","white_camas, zigadenus_glaucus","poison_camas, zigadenus_nuttalli","grassy_death_camas, zigadenus_venenosus, zigadenus_venenosus_gramineus","prairie_wake-robin, prairie_trillium, trillium_recurvatum","dwarf-white_trillium, snow_trillium, early_wake-robin","herb_paris, paris_quadrifolia","sarsaparilla","bullbrier, greenbrier, catbrier, horse_brier, horse-brier, brier, briar, smilax_rotundifolia","rough_bindweed, smilax_aspera","clintonia, clinton's_lily","false_lily_of_the_valley, maianthemum_canadense","false_lily_of_the_valley, maianthemum_bifolium","solomon's-seal","great_solomon's-seal, polygonatum_biflorum, polygonatum_commutatum","bellwort, merry_bells, wild_oats","strawflower, cornflower, uvularia_grandiflora","pia, indian_arrowroot, tacca_leontopetaloides, tacca_pinnatifida","agave, century_plant, american_aloe","american_agave, agave_americana","sisal, agave_sisalana","maguey, cantala, agave_cantala","maguey, agave_atrovirens","agave_tequilana","cabbage_tree, grass_tree, cordyline_australis","dracaena","tuberose, polianthes_tuberosa","sansevieria, bowstring_hemp","african_bowstring_hemp, african_hemp, sansevieria_guineensis","ceylon_bowstring_hemp, sansevieria_zeylanica","mother-in-law's_tongue, snake_plant, sansevieria_trifasciata","spanish_bayonet, yucca_aloifolia","spanish_bayonet, yucca_baccata","joshua_tree, yucca_brevifolia","soapweed, soap-weed, soap_tree, yucca_elata","adam's_needle, adam's_needle-and-thread, spoonleaf_yucca, needle_palm, yucca_filamentosa","bear_grass, yucca_glauca","spanish_dagger, yucca_gloriosa","our_lord's_candle, yucca_whipplei","water_shamrock, buckbean, bogbean, bog_myrtle, marsh_trefoil, menyanthes_trifoliata","butterfly_bush, buddleia","yellow_jasmine, yellow_jessamine, carolina_jasmine, evening_trumpet_flower, gelsemium_sempervirens","flax","calabar_bean, ordeal_bean","bonduc, bonduc_tree, caesalpinia_bonduc, caesalpinia_bonducella","divi-divi, caesalpinia_coriaria","mysore_thorn, caesalpinia_decapetala, caesalpinia_sepiaria","brazilian_ironwood, caesalpinia_ferrea","bird_of_paradise, poinciana, caesalpinia_gilliesii, poinciana_gilliesii","shingle_tree, acrocarpus_fraxinifolius","mountain_ebony, orchid_tree, bauhinia_variegata","msasa, brachystegia_speciformis","cassia","golden_shower_tree, drumstick_tree, purging_cassia, pudding_pipe_tree, canafistola, canafistula, cassia_fistula","pink_shower, pink_shower_tree, horse_cassia, cassia_grandis","rainbow_shower, cassia_javonica","horse_cassia, cassia_roxburghii, cassia_marginata","carob, carob_tree, carob_bean_tree, algarroba, ceratonia_siliqua","carob, carob_bean, algarroba_bean, algarroba, locust_bean, locust_pod","paloverde","royal_poinciana, flamboyant, flame_tree, peacock_flower, delonix_regia, poinciana_regia","locust_tree, locust","water_locust, swamp_locust, gleditsia_aquatica","honey_locust, gleditsia_triacanthos","kentucky_coffee_tree, bonduc, chicot, gymnocladus_dioica","logwood, logwood_tree, campeachy, bloodwood_tree, haematoxylum_campechianum","jerusalem_thorn, horsebean, parkinsonia_aculeata","palo_verde, parkinsonia_florida, cercidium_floridum","dalmatian_laburnum, petteria_ramentacea, cytisus_ramentaceus","senna","avaram, tanner's_cassia, senna_auriculata, cassia_auriculata","alexandria_senna, alexandrian_senna, true_senna, tinnevelly_senna, indian_senna, senna_alexandrina, cassia_acutifolia, cassia_augustifolia","wild_senna, senna_marilandica, cassia_marilandica","sicklepod, senna_obtusifolia, cassia_tora","coffee_senna, mogdad_coffee, styptic_weed, stinking_weed, senna_occidentalis, cassia_occidentalis","tamarind, tamarind_tree, tamarindo, tamarindus_indica","false_indigo, bastard_indigo, amorpha_californica","false_indigo, bastard_indigo, amorpha_fruticosa","hog_peanut, wild_peanut, amphicarpaea_bracteata, amphicarpa_bracteata","angelim, andelmin","cabbage_bark, cabbage-bark_tree, cabbage_tree, andira_inermis","kidney_vetch, anthyllis_vulneraria","groundnut, groundnut_vine, indian_potato, potato_bean, wild_bean, apios_americana, apios_tuberosa","rooibos, aspalathus_linearis, aspalathus_cedcarbergensis","milk_vetch, milk-vetch","alpine_milk_vetch, astragalus_alpinus","purple_milk_vetch, astragalus_danicus","camwood, african_sandalwood, baphia_nitida","wild_indigo, false_indigo","blue_false_indigo, baptisia_australis","white_false_indigo, baptisia_lactea","indigo_broom, horsefly_weed, rattle_weed, baptisia_tinctoria","dhak, dak, palas, butea_frondosa, butea_monosperma","pigeon_pea, pigeon-pea_plant, cajan_pea, catjang_pea, red_gram, dhal, dahl, cajanus_cajan","sword_bean, canavalia_gladiata","pea_tree, caragana","siberian_pea_tree, caragana_arborescens","chinese_pea_tree, caragana_sinica","moreton_bay_chestnut, australian_chestnut","butterfly_pea, centrosema_virginianum","judas_tree, love_tree, circis_siliquastrum","redbud, cercis_canadensis","western_redbud, california_redbud, cercis_occidentalis","tagasaste, chamaecytisus_palmensis, cytesis_proliferus","weeping_tree_broom","flame_pea","chickpea, chickpea_plant, egyptian_pea, cicer_arietinum","chickpea, garbanzo","kentucky_yellowwood, gopherwood, cladrastis_lutea, cladrastis_kentukea","glory_pea, clianthus","desert_pea, sturt_pea, sturt's_desert_pea, clianthus_formosus, clianthus_speciosus","parrot's_beak, parrot's_bill, clianthus_puniceus","butterfly_pea, clitoria_mariana","blue_pea, butterfly_pea, clitoria_turnatea","telegraph_plant, semaphore_plant, codariocalyx_motorius, desmodium_motorium, desmodium_gyrans","bladder_senna, colutea_arborescens","axseed, crown_vetch, coronilla_varia","crotalaria, rattlebox","guar, cluster_bean, cyamopsis_tetragonolobus, cyamopsis_psoraloides","white_broom, white_spanish_broom, cytisus_albus, cytisus_multiflorus","common_broom, scotch_broom, green_broom, cytisus_scoparius","rosewood, rosewood_tree","indian_blackwood, east_indian_rosewood, east_india_rosewood, indian_rosewood, dalbergia_latifolia","sissoo, sissu, sisham, dalbergia_sissoo","kingwood, kingwood_tree, dalbergia_cearensis","brazilian_rosewood, caviuna_wood, jacaranda, dalbergia_nigra","cocobolo, dalbergia_retusa","blackwood, blackwood_tree","bitter_pea","derris","derris_root, tuba_root, derris_elliptica","prairie_mimosa, prickle-weed, desmanthus_ilinoensis","tick_trefoil, beggar_lice, beggar's_lice","beggarweed, desmodium_tortuosum, desmodium_purpureum","australian_pea, dipogon_lignosus, dolichos_lignosus","coral_tree, erythrina","kaffir_boom, cape_kafferboom, erythrina_caffra","coral_bean_tree, erythrina_corallodendrum","ceibo, crybaby_tree, cry-baby_tree, common_coral_tree, erythrina_crista-galli","kaffir_boom, transvaal_kafferboom, erythrina_lysistemon","indian_coral_tree, erythrina_variegata, erythrina_indica","cork_tree, erythrina_vespertilio","goat's_rue, goat_rue, galega_officinalis","poison_bush, poison_pea, gastrolobium","spanish_broom, spanish_gorse, genista_hispanica","woodwaxen, dyer's_greenweed, dyer's-broom, dyeweed, greenweed, whin, woadwaxen, genista_tinctoria","chanar, chanal, geoffroea_decorticans","gliricidia","soy, soybean, soya_bean","licorice, liquorice, glycyrrhiza_glabra","wild_licorice, wild_liquorice, american_licorice, american_liquorice, glycyrrhiza_lepidota","licorice_root","western_australia_coral_pea, hardenbergia_comnptoniana","sweet_vetch, hedysarum_boreale","french_honeysuckle, sulla, hedysarum_coronarium","anil, indigofera_suffruticosa, indigofera_anil","scarlet_runner, running_postman, kennedia_prostrata","hyacinth_bean, bonavist, indian_bean, egyptian_bean, lablab_purpureus, dolichos_lablab","scotch_laburnum, alpine_golden_chain, laburnum_alpinum","vetchling","wild_pea","everlasting_pea","beach_pea, sea_pea, lathyrus_maritimus, lathyrus_japonicus","grass_vetch, grass_vetchling, lathyrus_nissolia","marsh_pea, lathyrus_palustris","common_vetchling, meadow_pea, yellow_vetchling, lathyrus_pratensis","grass_pea, indian_pea, khesari, lathyrus_sativus","tangier_pea, tangier_peavine, lalthyrus_tingitanus","heath_pea, earth-nut_pea, earthnut_pea, tuberous_vetch, lathyrus_tuberosus","bicolor_lespediza, ezo-yama-hagi, lespedeza_bicolor","japanese_clover, japan_clover, jap_clover, lespedeza_striata","korean_lespedeza, lespedeza_stipulacea","sericea_lespedeza, lespedeza_sericea, lespedeza_cuneata","lentil, lentil_plant, lens_culinaris","lentil","prairie_bird's-foot_trefoil, compass_plant, prairie_lotus, prairie_trefoil, lotus_americanus","bird's_foot_trefoil, bird's_foot_clover, babies'_slippers, bacon_and_eggs, lotus_corniculatus","winged_pea, asparagus_pea, lotus_tetragonolobus","lupine, lupin","white_lupine, field_lupine, wolf_bean, egyptian_lupine, lupinus_albus","tree_lupine, lupinus_arboreus","wild_lupine, sundial_lupine, indian_beet, old-maid's_bonnet, lupinus_perennis","bluebonnet, buffalo_clover, texas_bluebonnet, lupinus_subcarnosus","texas_bluebonnet, lupinus_texensis","medic, medick, trefoil","moon_trefoil, medicago_arborea","sickle_alfalfa, sickle_lucerne, sickle_medick, medicago_falcata","calvary_clover, medicago_intertexta, medicago_echinus","black_medick, hop_clover, yellow_trefoil, nonesuch_clover, medicago_lupulina","alfalfa, lucerne, medicago_sativa","millettia","mucuna","cowage, velvet_bean, bengal_bean, benghal_bean, florida_bean, mucuna_pruriens_utilis, mucuna_deeringiana, mucuna_aterrima, stizolobium_deeringiana","tolu_tree, tolu_balsam_tree, myroxylon_balsamum, myroxylon_toluiferum","peruvian_balsam, myroxylon_pereirae, myroxylon_balsamum_pereirae","sainfoin, sanfoin, holy_clover, esparcet, onobrychis_viciifolia, onobrychis_viciaefolia","restharrow, rest-harrow, ononis_repens","bead_tree, jumby_bean, jumby_tree, ormosia_monosperma","jumby_bead, jumbie_bead, ormosia_coarctata","locoweed, crazyweed, crazy_weed","purple_locoweed, purple_loco, oxytropis_lambertii","tumbleweed","yam_bean, pachyrhizus_erosus","shamrock_pea, parochetus_communis","pole_bean","kidney_bean, frijol, frijole","haricot","wax_bean","scarlet_runner, scarlet_runner_bean, dutch_case-knife_bean, runner_bean, phaseolus_coccineus, phaseolus_multiflorus","lima_bean, lima_bean_plant, phaseolus_limensis","sieva_bean, butter_bean, butter-bean_plant, lima_bean, phaseolus_lunatus","tepary_bean, phaseolus_acutifolius_latifolius","chaparral_pea, stingaree-bush, pickeringia_montana","jamaica_dogwood, fish_fuddle, piscidia_piscipula, piscidia_erythrina","pea","garden_pea","edible-pod_pea, edible-podded_pea, pisum_sativum_macrocarpon","sugar_snap_pea, snap_pea","field_pea, field-pea_plant, austrian_winter_pea, pisum_sativum_arvense, pisum_arvense","field_pea","common_flat_pea, native_holly, playlobium_obtusangulum","quira","roble, platymiscium_trinitatis","panama_redwood_tree, panama_redwood, platymiscium_pinnatum","indian_beech, pongamia_glabra","winged_bean, winged_pea, goa_bean, goa_bean_vine, manila_bean, psophocarpus_tetragonolobus","breadroot, indian_breadroot, pomme_blanche, pomme_de_prairie, psoralea_esculenta","bloodwood_tree, kiaat, pterocarpus_angolensis","kino, pterocarpus_marsupium","red_sandalwood, red_sanders, red_sanderswood, red_saunders, pterocarpus_santalinus","kudzu, kudzu_vine, pueraria_lobata","bristly_locust, rose_acacia, moss_locust, robinia_hispida","black_locust, yellow_locust, robinia_pseudoacacia","clammy_locust, robinia_viscosa","carib_wood, sabinea_carinalis","colorado_river_hemp, sesbania_exaltata","scarlet_wisteria_tree, vegetable_hummingbird, sesbania_grandiflora","japanese_pagoda_tree, chinese_scholartree, chinese_scholar_tree, sophora_japonica, sophora_sinensis","mescal_bean, coral_bean, frijolito, frijolillo, sophora_secundiflora","kowhai, sophora_tetraptera","jade_vine, emerald_creeper, strongylodon_macrobotrys","hoary_pea","bastard_indigo, tephrosia_purpurea","catgut, goat's_rue, wild_sweet_pea, tephrosia_virginiana","bush_pea","false_lupine, golden_pea, yellow_pea, thermopsis_macrophylla","carolina_lupine, thermopsis_villosa","tipu, tipu_tree, yellow_jacaranda, pride_of_bolivia","bird's_foot_trefoil, trigonella_ornithopodioides","fenugreek, greek_clover, trigonella_foenumgraecum","gorse, furze, whin, irish_gorse, ulex_europaeus","vetch","tufted_vetch, bird_vetch, calnada_pea, vicia_cracca","broad_bean, fava_bean, horsebean","bitter_betch, vicia_orobus","bush_vetch, vicia_sepium","moth_bean, vigna_aconitifolia, phaseolus_aconitifolius","snailflower, snail-flower, snail_flower, snail_bean, corkscrew_flower, vigna_caracalla, phaseolus_caracalla","mung, mung_bean, green_gram, golden_gram, vigna_radiata, phaseolus_aureus","cowpea, cowpea_plant, black-eyed_pea, vigna_unguiculata, vigna_sinensis","cowpea, black-eyed_pea","asparagus_bean, yard-long_bean, vigna_unguiculata_sesquipedalis, vigna_sesquipedalis","swamp_oak, viminaria_juncea, viminaria_denudata","keurboom, virgilia_capensis, virgilia_oroboides","keurboom, virgilia_divaricata","japanese_wistaria, wisteria_floribunda","chinese_wistaria, wisteria_chinensis","american_wistaria, american_wisteria, wisteria_frutescens","silky_wisteria, wisteria_venusta","palm, palm_tree","sago_palm","feather_palm","fan_palm","palmetto","coyol, coyol_palm, acrocomia_vinifera","grugru, gri-gri, grugru_palm, macamba, acrocomia_aculeata","areca","betel_palm, areca_catechu","sugar_palm, gomuti, gomuti_palm, arenga_pinnata","piassava_palm, pissaba_palm, bahia_piassava, bahia_coquilla, attalea_funifera","coquilla_nut","palmyra, palmyra_palm, toddy_palm, wine_palm, lontar, longar_palm, borassus_flabellifer","calamus","rattan, rattan_palm, calamus_rotang","lawyer_cane, calamus_australis","fishtail_palm","wine_palm, jaggery_palm, kitul, kittul, kitul_tree, toddy_palm, caryota_urens","wax_palm, ceroxylon_andicola, ceroxylon_alpinum","coconut, coconut_palm, coco_palm, coco, cocoa_palm, coconut_tree, cocos_nucifera","carnauba, carnauba_palm, wax_palm, copernicia_prunifera, copernicia_cerifera","caranday, caranda, caranda_palm, wax_palm, copernicia_australis, copernicia_alba","corozo, corozo_palm","gebang_palm, corypha_utan, corypha_gebanga","latanier, latanier_palm","talipot, talipot_palm, corypha_umbraculifera","oil_palm","african_oil_palm, elaeis_guineensis","american_oil_palm, elaeis_oleifera","palm_nut, palm_kernel","cabbage_palm, euterpe_oleracea","cabbage_palm, cabbage_tree, livistona_australis","true_sago_palm, metroxylon_sagu","nipa_palm, nipa_fruticans","babassu, babassu_palm, coco_de_macao, orbignya_phalerata, orbignya_spesiosa, orbignya_martiana","babassu_nut","cohune_palm, orbignya_cohune, cohune","cohune_nut","date_palm, phoenix_dactylifera","ivory_palm, ivory-nut_palm, ivory_plant, phytelephas_macrocarpa","raffia_palm, raffia_farinifera, raffia_ruffia","bamboo_palm, raffia_vinifera","lady_palm","miniature_fan_palm, bamboo_palm, fern_rhapis, rhapis_excelsa","reed_rhapis, slender_lady_palm, rhapis_humilis","royal_palm, roystonea_regia","cabbage_palm, roystonea_oleracea","cabbage_palmetto, cabbage_palm, sabal_palmetto","saw_palmetto, scrub_palmetto, serenoa_repens","thatch_palm, thatch_tree, silver_thatch, broom_palm, thrinax_parviflora","key_palm, silvertop_palmetto, silver_thatch, thrinax_microcarpa, thrinax_morrisii, thrinax_keyensis","english_plantain, narrow-leaved_plantain, ribgrass, ribwort, ripple-grass, buckthorn, plantago_lanceolata","broad-leaved_plantain, common_plantain, white-man's_foot, whiteman's_foot, cart-track_plant, plantago_major","hoary_plantain, plantago_media","fleawort, psyllium, spanish_psyllium, plantago_psyllium","rugel's_plantain, broad-leaved_plantain, plantago_rugelii","hoary_plantain, plantago_virginica","buckwheat, polygonum_fagopyrum, fagopyrum_esculentum","prince's-feather, princess_feather, kiss-me-over-the-garden-gate, prince's-plume, polygonum_orientale","eriogonum","umbrella_plant, eriogonum_allenii","wild_buckwheat, california_buckwheat, erigonum_fasciculatum","rhubarb, rhubarb_plant","himalayan_rhubarb, indian_rhubarb, red-veined_pie_plant, rheum_australe, rheum_emodi","pie_plant, garden_rhubarb, rheum_cultorum, rheum_rhabarbarum, rheum_rhaponticum","chinese_rhubarb, rheum_palmatum","sour_dock, garden_sorrel, rumex_acetosa","sheep_sorrel, sheep's_sorrel, rumex_acetosella","bitter_dock, broad-leaved_dock, yellow_dock, rumex_obtusifolius","french_sorrel, garden_sorrel, rumex_scutatus","yellow-eyed_grass","commelina","spiderwort, dayflower","pineapple, pineapple_plant, ananas_comosus","pipewort, eriocaulon_aquaticum","water_hyacinth, water_orchid, eichhornia_crassipes, eichhornia_spesiosa","water_star_grass, mud_plantain, heteranthera_dubia","naiad, water_nymph","water_plantain, alisma_plantago-aquatica","narrow-leaved_water_plantain","hydrilla, hydrilla_verticillata","american_frogbit, limnodium_spongia","waterweed","canadian_pondweed, elodea_canadensis","tape_grass, eelgrass, wild_celery, vallisneria_spiralis","pondweed","curled_leaf_pondweed, curly_pondweed, potamogeton_crispus","loddon_pondweed, potamogeton_nodosus, potamogeton_americanus","frog's_lettuce","arrow_grass, triglochin_maritima","horned_pondweed, zannichellia_palustris","eelgrass, grass_wrack, sea_wrack, zostera_marina","rose, rosebush","hip, rose_hip, rosehip","banksia_rose, rosa_banksia","damask_rose, summer_damask_rose, rosa_damascena","sweetbrier, sweetbriar, brier, briar, eglantine, rosa_eglanteria","cherokee_rose, rosa_laevigata","musk_rose, rosa_moschata","agrimonia, agrimony","harvest-lice, agrimonia_eupatoria","fragrant_agrimony, agrimonia_procera","alderleaf_juneberry, alder-leaved_serviceberry, amelanchier_alnifolia","flowering_quince","japonica, maule's_quince, chaenomeles_japonica","coco_plum, coco_plum_tree, cocoa_plum, icaco, chrysobalanus_icaco","cotoneaster","cotoneaster_dammeri","cotoneaster_horizontalis","parsley_haw, parsley-leaved_thorn, crataegus_apiifolia, crataegus_marshallii","scarlet_haw, crataegus_biltmoreana","blackthorn, pear_haw, pear_hawthorn, crataegus_calpodendron, crataegus_tomentosa","cockspur_thorn, cockspur_hawthorn, crataegus_crus-galli","mayhaw, summer_haw, crataegus_aestivalis","red_haw, downy_haw, crataegus_mollis, crataegus_coccinea_mollis","red_haw, crataegus_pedicellata, crataegus_coccinea","quince, quince_bush, cydonia_oblonga","mountain_avens, dryas_octopetala","loquat, loquat_tree, japanese_medlar, japanese_plum, eriobotrya_japonica","beach_strawberry, chilean_strawberry, fragaria_chiloensis","virginia_strawberry, scarlet_strawberry, fragaria_virginiana","avens","yellow_avens, geum_alleppicum_strictum, geum_strictum","yellow_avens, geum_macrophyllum","prairie_smoke, purple_avens, geum_triflorum","bennet, white_avens, geum_virginianum","toyon, tollon, christmasberry, christmas_berry, heteromeles_arbutifolia, photinia_arbutifolia","apple_tree","apple, orchard_apple_tree, malus_pumila","wild_apple, crab_apple, crabapple","crab_apple, crabapple, cultivated_crab_apple","siberian_crab, siberian_crab_apple, cherry_apple, cherry_crab, malus_baccata","wild_crab, malus_sylvestris","american_crab_apple, garland_crab, malus_coronaria","oregon_crab_apple, malus_fusca","southern_crab_apple, flowering_crab, malus_angustifolia","iowa_crab, iowa_crab_apple, prairie_crab, western_crab_apple, malus_ioensis","bechtel_crab, flowering_crab","medlar, medlar_tree, mespilus_germanica","cinquefoil, five-finger","silverweed, goose-tansy, goose_grass, potentilla_anserina","salad_burnet, burnet_bloodwort, pimpernel, poterium_sanguisorba","plum, plum_tree","wild_plum, wild_plum_tree","allegheny_plum, alleghany_plum, sloe, prunus_alleghaniensis","american_red_plum, august_plum, goose_plum, prunus_americana","chickasaw_plum, hog_plum, hog_plum_bush, prunus_angustifolia","beach_plum, beach_plum_bush, prunus_maritima","common_plum, prunus_domestica","bullace, prunus_insititia","damson_plum, damson_plum_tree, prunus_domestica_insititia","big-tree_plum, prunus_mexicana","canada_plum, prunus_nigra","plumcot, plumcot_tree","apricot, apricot_tree","japanese_apricot, mei, prunus_mume","common_apricot, prunus_armeniaca","purple_apricot, black_apricot, prunus_dasycarpa","cherry, cherry_tree","wild_cherry, wild_cherry_tree","wild_cherry","sweet_cherry, prunus_avium","heart_cherry, oxheart, oxheart_cherry","gean, mazzard, mazzard_cherry","capulin, capulin_tree, prunus_capuli","cherry_laurel, laurel_cherry, mock_orange, wild_orange, prunus_caroliniana","cherry_plum, myrobalan, myrobalan_plum, prunus_cerasifera","sour_cherry, sour_cherry_tree, prunus_cerasus","amarelle, prunus_cerasus_caproniana","morello, prunus_cerasus_austera","marasca","almond_tree","almond, sweet_almond, prunus_dulcis, prunus_amygdalus, amygdalus_communis","bitter_almond, prunus_dulcis_amara, amygdalus_communis_amara","jordan_almond","dwarf_flowering_almond, prunus_glandulosa","holly-leaved_cherry, holly-leaf_cherry, evergreen_cherry, islay, prunus_ilicifolia","fuji, fuji_cherry, prunus_incisa","flowering_almond, oriental_bush_cherry, prunus_japonica","cherry_laurel, laurel_cherry, prunus_laurocerasus","catalina_cherry, prunus_lyonii","bird_cherry, bird_cherry_tree","hagberry_tree, european_bird_cherry, common_bird_cherry, prunus_padus","hagberry","pin_cherry, prunus_pensylvanica","peach, peach_tree, prunus_persica","nectarine, nectarine_tree, prunus_persica_nectarina","sand_cherry, prunus_pumila, prunus_pumilla_susquehanae, prunus_susquehanae, prunus_cuneata","japanese_plum, prunus_salicina","black_cherry, black_cherry_tree, rum_cherry, prunus_serotina","flowering_cherry","oriental_cherry, japanese_cherry, japanese_flowering_cherry, prunus_serrulata","japanese_flowering_cherry, prunus_sieboldii","sierra_plum, pacific_plum, prunus_subcordata","rosebud_cherry, winter_flowering_cherry, prunus_subhirtella","russian_almond, dwarf_russian_almond, prunus_tenella","flowering_almond, prunus_triloba","chokecherry, chokecherry_tree, prunus_virginiana","chokecherry","western_chokecherry, prunus_virginiana_demissa, prunus_demissa","pyracantha, pyracanth, fire_thorn, firethorn","pear, pear_tree, pyrus_communis","fruit_tree","bramble_bush","lawyerbush, lawyer_bush, bush_lawyer, rubus_cissoides, rubus_australis","stone_bramble, rubus_saxatilis","sand_blackberry, rubus_cuneifolius","boysenberry, boysenberry_bush","loganberry, rubus_loganobaccus, rubus_ursinus_loganobaccus","american_dewberry, rubus_canadensis","northern_dewberry, american_dewberry, rubus_flagellaris","southern_dewberry, rubus_trivialis","swamp_dewberry, swamp_blackberry, rubus_hispidus","european_dewberry, rubus_caesius","raspberry, raspberry_bush","wild_raspberry, european_raspberry, framboise, rubus_idaeus","american_raspberry, rubus_strigosus, rubus_idaeus_strigosus","black_raspberry, blackcap, blackcap_raspberry, thimbleberry, rubus_occidentalis","salmonberry, rubus_spectabilis","salmonberry, salmon_berry, thimbleberry, rubus_parviflorus","wineberry, rubus_phoenicolasius","mountain_ash","rowan, rowan_tree, european_mountain_ash, sorbus_aucuparia","rowanberry","american_mountain_ash, sorbus_americana","western_mountain_ash, sorbus_sitchensis","service_tree, sorb_apple, sorb_apple_tree, sorbus_domestica","wild_service_tree, sorbus_torminalis","spirea, spiraea","bridal_wreath, bridal-wreath, saint_peter's_wreath, st._peter's_wreath, spiraea_prunifolia","madderwort, rubiaceous_plant","indian_madder, munjeet, rubia_cordifolia","madder, rubia_tinctorum","woodruff","dagame, lemonwood_tree, calycophyllum_candidissimum","blolly, west_indian_snowberry, chiococca_alba","coffee, coffee_tree","arabian_coffee, coffea_arabica","liberian_coffee, coffea_liberica","robusta_coffee, rio_nunez_coffee, coffea_robusta, coffea_canephora","cinchona, chinchona","cartagena_bark, cinchona_cordifolia, cinchona_lancifolia","calisaya, cinchona_officinalis, cinchona_ledgeriana, cinchona_calisaya","cinchona_tree, cinchona_pubescens","cinchona, cinchona_bark, peruvian_bark, jesuit's_bark","bedstraw","sweet_woodruff, waldmeister, woodruff, fragrant_bedstraw, galium_odoratum, asperula_odorata","northern_bedstraw, northern_snow_bedstraw, galium_boreale","yellow_bedstraw, yellow_cleavers, our_lady's_bedstraw, galium_verum","wild_licorice, galium_lanceolatum","cleavers, clivers, goose_grass, catchweed, spring_cleavers, galium_aparine","wild_madder, white_madder, white_bedstraw, infant's-breath, false_baby's_breath, galium_mollugo","cape_jasmine, cape_jessamine, gardenia_jasminoides, gardenia_augusta","genipa","genipap_fruit, jagua, marmalade_box, genipa_americana","hamelia","scarlet_bush, scarlet_hamelia, coloradillo, hamelia_patens, hamelia_erecta","lemonwood, lemon-wood, lemonwood_tree, lemon-wood_tree, psychotria_capensis","negro_peach, sarcocephalus_latifolius, sarcocephalus_esculentus","wild_medlar, wild_medlar_tree, medlar, vangueria_infausta","spanish_tamarind, vangueria_madagascariensis","abelia","bush_honeysuckle, diervilla_sessilifolia","american_twinflower, linnaea_borealis_americana","honeysuckle","american_fly_honeysuckle, fly_honeysuckle, lonicera_canadensis","italian_honeysuckle, italian_woodbine, lonicera_caprifolium","yellow_honeysuckle, lonicera_flava","hairy_honeysuckle, lonicera_hirsuta","japanese_honeysuckle, lonicera_japonica","hall's_honeysuckle, lonicera_japonica_halliana","morrow's_honeysuckle, lonicera_morrowii","woodbine, lonicera_periclymenum","trumpet_honeysuckle, coral_honeysuckle, trumpet_flower, trumpet_vine, lonicera_sempervirens","european_fly_honeysuckle, european_honeysuckle, lonicera_xylosteum","swamp_fly_honeysuckle","snowberry, common_snowberry, waxberry, symphoricarpos_alba","coralberry, indian_currant, symphoricarpos_orbiculatus","blue_elder, blue_elderberry, sambucus_caerulea","dwarf_elder, danewort, sambucus_ebulus","american_red_elder, red-berried_elder, stinking_elder, sambucus_pubens","european_red_elder, red-berried_elder, sambucus_racemosa","feverroot, horse_gentian, tinker's_root, wild_coffee, triostium_perfoliatum","cranberry_bush, cranberry_tree, american_cranberry_bush, highbush_cranberry, viburnum_trilobum","wayfaring_tree, twist_wood, twistwood, viburnum_lantana","guelder_rose, european_cranberrybush, european_cranberry_bush, crampbark, cranberry_tree, viburnum_opulus","arrow_wood, viburnum_recognitum","black_haw, viburnum_prunifolium","weigela, weigela_florida","teasel, teazel, teasle","common_teasel, dipsacus_fullonum","fuller's_teasel, dipsacus_sativus","wild_teasel, dipsacus_sylvestris","scabious, scabiosa","sweet_scabious, pincushion_flower, mournful_widow, scabiosa_atropurpurea","field_scabious, scabiosa_arvensis","jewelweed, lady's_earrings, orange_balsam, celandine, touch-me-not, impatiens_capensis","geranium","cranesbill, crane's_bill","wild_geranium, spotted_cranesbill, geranium_maculatum","meadow_cranesbill, geranium_pratense","richardson's_geranium, geranium_richardsonii","herb_robert, herbs_robert, herb_roberts, geranium_robertianum","sticky_geranium, geranium_viscosissimum","dove's_foot_geranium, geranium_molle","rose_geranium, sweet-scented_geranium, pelargonium_graveolens","fish_geranium, bedding_geranium, zonal_pelargonium, pelargonium_hortorum","ivy_geranium, ivy-leaved_geranium, hanging_geranium, pelargonium_peltatum","apple_geranium, nutmeg_geranium, pelargonium_odoratissimum","lemon_geranium, pelargonium_limoneum","storksbill, heron's_bill","musk_clover, muskus_grass, white-stemmed_filaree, erodium_moschatum","incense_tree","elephant_tree, bursera_microphylla","gumbo-limbo, bursera_simaruba","boswellia_carteri","salai, boswellia_serrata","balm_of_gilead, commiphora_meccanensis","myrrh_tree, commiphora_myrrha","protium_heptaphyllum","protium_guianense","water_starwort","barbados_cherry, acerola, surinam_cherry, west_indian_cherry, malpighia_glabra","mahogany, mahogany_tree","chinaberry, chinaberry_tree, china_tree, persian_lilac, pride-of-india, azederach, azedarach, melia_azederach, melia_azedarach","neem, neem_tree, nim_tree, margosa, arishth, azadirachta_indica, melia_azadirachta","neem_seed","spanish_cedar, spanish_cedar_tree, cedrela_odorata","satinwood, satinwood_tree, chloroxylon_swietenia","african_scented_mahogany, cedar_mahogany, sapele_mahogany, entandrophragma_cylindricum","silver_ash","native_beech, flindosa, flindosy, flindersia_australis","bunji-bunji, flindersia_schottiana","african_mahogany","lanseh_tree, langsat, langset, lansium_domesticum","true_mahogany, cuban_mahogany, dominican_mahogany, swietinia_mahogani","honduras_mahogany, swietinia_macrophylla","philippine_mahogany, philippine_cedar, kalantas, toona_calantas, cedrela_calantas","caracolito, ruptiliocarpon_caracolito","common_wood_sorrel, cuckoo_bread, shamrock, oxalis_acetosella","bermuda_buttercup, english-weed, oxalis_pes-caprae, oxalis_cernua","creeping_oxalis, creeping_wood_sorrel, oxalis_corniculata","goatsfoot, goat's_foot, oxalis_caprina","violet_wood_sorrel, oxalis_violacea","oca, oka, oxalis_tuberosa, oxalis_crenata","carambola, carambola_tree, averrhoa_carambola","bilimbi, averrhoa_bilimbi","milkwort","senega, polygala_alba","orange_milkwort, yellow_milkwort, candyweed, yellow_bachelor's_button, polygala_lutea","flowering_wintergreen, gaywings, bird-on-the-wing, fringed_polygala, polygala_paucifolia","seneca_snakeroot, seneka_snakeroot, senga_root, senega_root, senega_snakeroot, polygala_senega","common_milkwort, gand_flower, polygala_vulgaris","rue, herb_of_grace, ruta_graveolens","citrus, citrus_tree","orange, orange_tree","sour_orange, seville_orange, bitter_orange, bitter_orange_tree, bigarade, marmalade_orange, citrus_aurantium","bergamot, bergamot_orange, citrus_bergamia","pomelo, pomelo_tree, pummelo, shaddock, citrus_maxima, citrus_grandis, citrus_decumana","citron, citron_tree, citrus_medica","grapefruit, citrus_paradisi","mandarin, mandarin_orange, mandarin_orange_tree, citrus_reticulata","tangerine, tangerine_tree","clementine, clementine_tree","satsuma, satsuma_tree","sweet_orange, sweet_orange_tree, citrus_sinensis","temple_orange, temple_orange_tree, tangor, king_orange, citrus_nobilis","tangelo, tangelo_tree, ugli_fruit, citrus_tangelo","rangpur, rangpur_lime, lemanderin, citrus_limonia","lemon, lemon_tree, citrus_limon","sweet_lemon, sweet_lime, citrus_limetta","lime, lime_tree, citrus_aurantifolia","citrange, citrange_tree, citroncirus_webberi","fraxinella, dittany, burning_bush, gas_plant, dictamnus_alba","kumquat, cumquat, kumquat_tree","marumi, marumi_kumquat, round_kumquat, fortunella_japonica","nagami, nagami_kumquat, oval_kumquat, fortunella_margarita","cork_tree, phellodendron_amurense","trifoliate_orange, trifoliata, wild_orange, poncirus_trifoliata","prickly_ash","toothache_tree, sea_ash, zanthoxylum_americanum, zanthoxylum_fraxineum","hercules'-club, hercules'-clubs, hercules-club, zanthoxylum_clava-herculis","bitterwood_tree","marupa, simarouba_amara","paradise_tree, bitterwood, simarouba_glauca","ailanthus","tree_of_heaven, tree_of_the_gods, ailanthus_altissima","wild_mango, dika, wild_mango_tree, irvingia_gabonensis","pepper_tree, kirkia_wilmsii","jamaica_quassia, bitterwood, picrasma_excelsa, picrasma_excelsum","quassia, bitterwood, quassia_amara","nasturtium","garden_nasturtium, indian_cress, tropaeolum_majus","bush_nasturtium, tropaeolum_minus","canarybird_flower, canarybird_vine, canary_creeper, tropaeolum_peregrinum","bean_caper, syrian_bean_caper, zygophyllum_fabago","palo_santo, bulnesia_sarmienti","lignum_vitae, guaiacum_officinale","creosote_bush, coville, hediondilla, larrea_tridentata","caltrop, devil's_weed, tribulus_terestris","willow, willow_tree","osier","white_willow, huntingdon_willow, salix_alba","silver_willow, silky_willow, salix_alba_sericea, salix_sericea","golden_willow, salix_alba_vitellina, salix_vitellina","cricket-bat_willow, salix_alba_caerulea","arctic_willow, salix_arctica","weeping_willow, babylonian_weeping_willow, salix_babylonica","wisconsin_weeping_willow, salix_pendulina, salix_blanda, salix_pendulina_blanda","pussy_willow, salix_discolor","sallow","goat_willow, florist's_willow, pussy_willow, salix_caprea","peachleaf_willow, peach-leaved_willow, almond-leaves_willow, salix_amygdaloides","almond_willow, black_hollander, salix_triandra, salix_amygdalina","hoary_willow, sage_willow, salix_candida","crack_willow, brittle_willow, snap_willow, salix_fragilis","prairie_willow, salix_humilis","dwarf_willow, salix_herbacea","grey_willow, gray_willow, salix_cinerea","arroyo_willow, salix_lasiolepis","shining_willow, salix_lucida","swamp_willow, black_willow, salix_nigra","bay_willow, laurel_willow, salix_pentandra","purple_willow, red_willow, red_osier, basket_willow, purple_osier, salix_purpurea","balsam_willow, salix_pyrifolia","creeping_willow, salix_repens","sitka_willow, silky_willow, salix_sitchensis","dwarf_grey_willow, dwarf_gray_willow, sage_willow, salix_tristis","bearberry_willow, salix_uva-ursi","common_osier, hemp_willow, velvet_osier, salix_viminalis","poplar, poplar_tree","balsam_poplar, hackmatack, tacamahac, populus_balsamifera","white_poplar, white_aspen, abele, aspen_poplar, silver-leaved_poplar, populus_alba","grey_poplar, gray_poplar, populus_canescens","black_poplar, populus_nigra","lombardy_poplar, populus_nigra_italica","cottonwood","eastern_cottonwood, necklace_poplar, populus_deltoides","black_cottonwood, western_balsam_poplar, populus_trichocarpa","swamp_cottonwood, black_cottonwood, downy_poplar, swamp_poplar, populus_heterophylla","aspen","quaking_aspen, european_quaking_aspen, populus_tremula","american_quaking_aspen, american_aspen, populus_tremuloides","canadian_aspen, bigtooth_aspen, bigtoothed_aspen, big-toothed_aspen, large-toothed_aspen, large_tooth_aspen, populus_grandidentata","sandalwood_tree, true_sandalwood, santalum_album","quandong, quandang, quandong_tree, eucarya_acuminata, fusanus_acuminatus","rabbitwood, buffalo_nut, pyrularia_pubera","loranthaceae, family_loranthaceae, mistletoe_family","mistletoe, loranthus_europaeus","american_mistletoe, arceuthobium_pusillum","mistletoe, viscum_album, old_world_mistletoe","american_mistletoe, phoradendron_serotinum, phoradendron_flavescens","aalii","soapberry, soapberry_tree","wild_china_tree, sapindus_drumondii, sapindus_marginatus","china_tree, false_dogwood, jaboncillo, chinaberry, sapindus_saponaria","akee, akee_tree, blighia_sapida","soapberry_vine","heartseed, cardiospermum_grandiflorum","balloon_vine, heart_pea, cardiospermum_halicacabum","longan, lungen, longanberry, dimocarpus_longan, euphorbia_litchi, nephelium_longana","harpullia","harpulla, harpullia_cupanioides","moreton_bay_tulipwood, harpullia_pendula","litchi, lichee, litchi_tree, litchi_chinensis, nephelium_litchi","spanish_lime, spanish_lime_tree, honey_berry, mamoncillo, genip, ginep, melicocca_bijuga, melicocca_bijugatus","rambutan, rambotan, rambutan_tree, nephelium_lappaceum","pulasan, pulassan, pulasan_tree, nephelium_mutabile","pachysandra","allegheny_spurge, allegheny_mountain_spurge, pachysandra_procumbens","bittersweet, american_bittersweet, climbing_bittersweet, false_bittersweet, staff_vine, waxwork, shrubby_bittersweet, celastrus_scandens","spindle_tree, spindleberry, spindleberry_tree","winged_spindle_tree, euonymous_alatus","wahoo, burning_bush, euonymus_atropurpureus","strawberry_bush, wahoo, euonymus_americanus","evergreen_bittersweet, euonymus_fortunei_radicans, euonymus_radicans_vegetus","cyrilla, leatherwood, white_titi, cyrilla_racemiflora","titi, buckwheat_tree, cliftonia_monophylla","crowberry","maple","silver_maple, acer_saccharinum","sugar_maple, rock_maple, acer_saccharum","red_maple, scarlet_maple, swamp_maple, acer_rubrum","moosewood, moose-wood, striped_maple, striped_dogwood, goosefoot_maple, acer_pennsylvanicum","oregon_maple, big-leaf_maple, acer_macrophyllum","dwarf_maple, rocky-mountain_maple, acer_glabrum","mountain_maple, mountain_alder, acer_spicatum","vine_maple, acer_circinatum","hedge_maple, field_maple, acer_campestre","norway_maple, acer_platanoides","sycamore, great_maple, scottish_maple, acer_pseudoplatanus","box_elder, ash-leaved_maple, acer_negundo","california_box_elder, acer_negundo_californicum","pointed-leaf_maple, acer_argutum","japanese_maple, full_moon_maple, acer_japonicum","japanese_maple, acer_palmatum","holly","chinese_holly, ilex_cornuta","bearberry, possum_haw, winterberry, ilex_decidua","inkberry, gallberry, gall-berry, evergreen_winterberry, ilex_glabra","mate, paraguay_tea, ilex_paraguariensis","american_holly, christmas_holly","low_gallberry_holly","tall_gallberry_holly","yaupon_holly","deciduous_holly","juneberry_holly","largeleaf_holly","geogia_holly","common_winterberry_holly","smooth_winterberry_holly","cashew, cashew_tree, anacardium_occidentale","goncalo_alves, astronium_fraxinifolium","venetian_sumac, wig_tree, cotinus_coggygria","laurel_sumac, malosma_laurina, rhus_laurina","mango, mango_tree, mangifera_indica","pistachio, pistacia_vera, pistachio_tree","terebinth, pistacia_terebinthus","mastic, mastic_tree, lentisk, pistacia_lentiscus","australian_sumac, rhodosphaera_rhodanthema, rhus_rhodanthema","sumac, sumach, shumac","smooth_sumac, scarlet_sumac, vinegar_tree, rhus_glabra","sugar-bush, sugar_sumac, rhus_ovata","staghorn_sumac, velvet_sumac, virginian_sumac, vinegar_tree, rhus_typhina","squawbush, squaw-bush, skunkbush, rhus_trilobata","aroeira_blanca, schinus_chichita","pepper_tree, molle, peruvian_mastic_tree, schinus_molle","brazilian_pepper_tree, schinus_terebinthifolius","hog_plum, yellow_mombin, yellow_mombin_tree, spondias_mombin","mombin, mombin_tree, jocote, spondias_purpurea","poison_ash, poison_dogwood, poison_sumac, toxicodendron_vernix, rhus_vernix","poison_ivy, markweed, poison_mercury, poison_oak, toxicodendron_radicans, rhus_radicans","western_poison_oak, toxicodendron_diversilobum, rhus_diversiloba","eastern_poison_oak, toxicodendron_quercifolium, rhus_quercifolia, rhus_toxicodenedron","varnish_tree, lacquer_tree, chinese_lacquer_tree, japanese_lacquer_tree, japanese_varnish_tree, japanese_sumac, toxicodendron_vernicifluum, rhus_verniciflua","horse_chestnut, buckeye, aesculus_hippocastanum","buckeye, horse_chestnut, conker","sweet_buckeye","ohio_buckeye","dwarf_buckeye, bottlebrush_buckeye","red_buckeye","particolored_buckeye","ebony, ebony_tree, diospyros_ebenum","marblewood, marble-wood, andaman_marble, diospyros_kurzii","marblewood, marble-wood","persimmon, persimmon_tree","japanese_persimmon, kaki, diospyros_kaki","american_persimmon, possumwood, diospyros_virginiana","date_plum, diospyros_lotus","buckthorn","southern_buckthorn, shittimwood, shittim, mock_orange, bumelia_lycioides","false_buckthorn, chittamwood, chittimwood, shittimwood, black_haw, bumelia_lanuginosa","star_apple, caimito, chrysophyllum_cainito","satinleaf, satin_leaf, caimitillo, damson_plum, chrysophyllum_oliviforme","balata, balata_tree, beefwood, bully_tree, manilkara_bidentata","sapodilla, sapodilla_tree, manilkara_zapota, achras_zapota","gutta-percha_tree, palaquium_gutta","gutta-percha_tree","canistel, canistel_tree, pouteria_campechiana_nervosa","marmalade_tree, mammee, sapote, pouteria_zapota, calocarpum_zapota","sweetleaf, symplocus_tinctoria","asiatic_sweetleaf, sapphire_berry, symplocus_paniculata","styrax","snowbell, styrax_obassia","japanese_snowbell, styrax_japonicum","texas_snowbell, texas_snowbells, styrax_texana","silver-bell_tree, silverbell_tree, snowdrop_tree, opossum_wood, halesia_carolina, halesia_tetraptera","carnivorous_plant","pitcher_plant","common_pitcher_plant, huntsman's_cup, huntsman's_cups, sarracenia_purpurea","hooded_pitcher_plant, sarracenia_minor","huntsman's_horn, huntsman's_horns, yellow_trumpet, yellow_pitcher_plant, trumpets, sarracenia_flava","tropical_pitcher_plant","sundew, sundew_plant, daily_dew","venus's_flytrap, venus's_flytraps, dionaea_muscipula","waterwheel_plant, aldrovanda_vesiculosa","drosophyllum_lusitanicum","roridula","australian_pitcher_plant, cephalotus_follicularis","sedum","stonecrop","rose-root, midsummer-men, sedum_rosea","orpine, orpin, livelong, live-forever, sedum_telephium","pinwheel, aeonium_haworthii","christmas_bush, christmas_tree, ceratopetalum_gummiferum","hortensia, hydrangea_macrophylla_hortensis","fall-blooming_hydrangea, hydrangea_paniculata","carpenteria, carpenteria_californica","decumary, decumaria_barbata, decumaria_barbara","deutzia","philadelphus","mock_orange, syringa, philadelphus_coronarius","saxifrage, breakstone, rockfoil","yellow_mountain_saxifrage, saxifraga_aizoides","meadow_saxifrage, fair-maids-of-france, saxifraga_granulata","mossy_saxifrage, saxifraga_hypnoides","western_saxifrage, saxifraga_occidentalis","purple_saxifrage, saxifraga_oppositifolia","star_saxifrage, starry_saxifrage, saxifraga_stellaris","strawberry_geranium, strawberry_saxifrage, mother-of-thousands, saxifraga_stolonifera, saxifraga_sarmentosam","astilbe","false_goatsbeard, astilbe_biternata","dwarf_astilbe, astilbe_chinensis_pumila","spirea, spiraea, astilbe_japonica","bergenia","coast_boykinia, boykinia_elata, boykinia_occidentalis","golden_saxifrage, golden_spleen","umbrella_plant, indian_rhubarb, darmera_peltata, peltiphyllum_peltatum","bridal_wreath, bridal-wreath, francoa_ramosa","alumroot, alumbloom","coralbells, heuchera_sanguinea","leatherleaf_saxifrage, leptarrhena_pyrolifolia","woodland_star, lithophragma_affine, lithophragma_affinis, tellima_affinis","prairie_star, lithophragma_parviflorum","miterwort, mitrewort, bishop's_cap","five-point_bishop's_cap, mitella_pentandra","parnassia, grass-of-parnassus","bog_star, parnassia_palustris","fringed_grass_of_parnassus, parnassia_fimbriata","false_alumroot, fringe_cups, tellima_grandiflora","foamflower, coolwart, false_miterwort, false_mitrewort, tiarella_cordifolia","false_miterwort, false_mitrewort, tiarella_unifoliata","pickaback_plant, piggyback_plant, youth-on-age, tolmiea_menziesii","currant, currant_bush","black_currant, european_black_currant, ribes_nigrum","white_currant, ribes_sativum","gooseberry, gooseberry_bush, ribes_uva-crispa, ribes_grossularia","plane_tree, sycamore, platan","london_plane, platanus_acerifolia","american_sycamore, american_plane, buttonwood, platanus_occidentalis","oriental_plane, platanus_orientalis","california_sycamore, platanus_racemosa","arizona_sycamore, platanus_wrightii","greek_valerian, polemonium_reptans","northern_jacob's_ladder, polemonium_boreale","skunkweed, skunk-weed, polemonium_viscosum","phlox","moss_pink, mountain_phlox, moss_phlox, dwarf_phlox, phlox_subulata","evening-snow, linanthus_dichotomus","acanthus","bear's_breech, bear's_breeches, sea_holly, acanthus_mollis","caricature_plant, graptophyllum_pictum","black-eyed_susan, black-eyed_susan_vine, thunbergia_alata","catalpa, indian_bean","catalpa_bignioides","catalpa_speciosa","desert_willow, chilopsis_linearis","calabash, calabash_tree, crescentia_cujete","calabash","borage, tailwort, borago_officinalis","common_amsinckia, amsinckia_intermedia","anchusa","bugloss, alkanet, anchusa_officinalis","cape_forget-me-not, anchusa_capensis","cape_forget-me-not, anchusa_riparia","spanish_elm, equador_laurel, salmwood, cypre, princewood, cordia_alliodora","princewood, spanish_elm, cordia_gerascanthus","chinese_forget-me-not, cynoglossum_amabile","hound's-tongue, cynoglossum_officinale","hound's-tongue, cynoglossum_virginaticum","blueweed, blue_devil, blue_thistle, viper's_bugloss, echium_vulgare","beggar's_lice, beggar_lice","gromwell, lithospermum_officinale","puccoon, lithospermum_caroliniense","virginia_bluebell, virginia_cowslip, mertensia_virginica","garden_forget-me-not, myosotis_sylvatica","forget-me-not, mouse_ear, myosotis_scorpiodes","false_gromwell","comfrey, cumfrey","common_comfrey, boneset, symphytum_officinale","convolvulus","bindweed","field_bindweed, wild_morning-glory, convolvulus_arvensis","scammony, convolvulus_scammonia","silverweed","dodder","dichondra, dichondra_micrantha","cypress_vine, star-glory, indian_pink, ipomoea_quamoclit, quamoclit_pennata","moonflower, belle_de_nuit, ipomoea_alba","wild_potato_vine, wild_sweet_potato_vine, man-of-the-earth, manroot, scammonyroot, ipomoea_panurata, ipomoea_fastigiata","red_morning-glory, star_ipomoea, ipomoea_coccinea","man-of-the-earth, ipomoea_leptophylla","scammony, ipomoea_orizabensis","japanese_morning_glory, ipomoea_nil","imperial_japanese_morning_glory, ipomoea_imperialis","gesneriad","gesneria","achimenes, hot_water_plant","aeschynanthus","lace-flower_vine, alsobia_dianthiflora, episcia_dianthiflora","columnea","episcia","gloxinia","canterbury_bell, gloxinia_perennis","kohleria","african_violet, saintpaulia_ionantha","streptocarpus","cape_primrose","waterleaf","virginia_waterleaf, shawnee_salad, shawny, indian_salad, john's_cabbage, hydrophyllum_virginianum","yellow_bells, california_yellow_bells, whispering_bells, emmanthe_penduliflora","yerba_santa, eriodictyon_californicum","nemophila","baby_blue-eyes, nemophila_menziesii","five-spot, nemophila_maculata","scorpionweed, scorpion_weed, phacelia","california_bluebell, phacelia_campanularia","california_bluebell, whitlavia, phacelia_minor, phacelia_whitlavia","fiddleneck, phacelia_tanacetifolia","fiesta_flower, pholistoma_auritum, nemophila_aurita","basil_thyme, basil_balm, mother_of_thyme, acinos_arvensis, satureja_acinos","giant_hyssop","yellow_giant_hyssop, agastache_nepetoides","anise_hyssop, agastache_foeniculum","mexican_hyssop, agastache_mexicana","bugle, bugleweed","creeping_bugle, ajuga_reptans","erect_bugle, blue_bugle, ajuga_genevensis","pyramid_bugle, ajuga_pyramidalis","wood_mint","hairy_wood_mint, blephilia_hirsuta","downy_wood_mint, blephilia_celiata","calamint","common_calamint, calamintha_sylvatica, satureja_calamintha_officinalis","large-flowered_calamint, calamintha_grandiflora, clinopodium_grandiflorum, satureja_grandiflora","lesser_calamint, field_balm, calamintha_nepeta, calamintha_nepeta_glantulosa, satureja_nepeta, satureja_calamintha_glandulosa","wild_basil, cushion_calamint, clinopodium_vulgare, satureja_vulgaris","horse_balm, horseweed, stoneroot, stone-root, richweed, stone_root, collinsonia_canadensis","coleus, flame_nettle","country_borage, coleus_aromaticus, coleus_amboinicus, plectranthus_amboinicus","painted_nettle, joseph's_coat, coleus_blumei, solenostemon_blumei, solenostemon_scutellarioides","apalachicola_rosemary, conradina_glabra","dragonhead, dragon's_head, dracocephalum_parviflorum","elsholtzia","hemp_nettle, dead_nettle, galeopsis_tetrahit","ground_ivy, alehoof, field_balm, gill-over-the-ground, runaway_robin, glechoma_hederaceae, nepeta_hederaceae","pennyroyal, american_pennyroyal, hedeoma_pulegioides","hyssop, hyssopus_officinalis","dead_nettle","white_dead_nettle, lamium_album","henbit, lamium_amplexicaule","english_lavender, lavandula_angustifolia, lavandula_officinalis","french_lavender, lavandula_stoechas","spike_lavender, french_lavender, lavandula_latifolia","dagga, cape_dagga, red_dagga, wilde_dagga, leonotis_leonurus","lion's-ear, leonotis_nepetaefolia, leonotis_nepetifolia","motherwort, leonurus_cardiaca","pitcher_sage, lepechinia_calycina, sphacele_calycina","bugleweed, lycopus_virginicus","water_horehound, lycopus_americanus","gipsywort, gypsywort, lycopus_europaeus","origanum","oregano, marjoram, pot_marjoram, wild_marjoram, winter_sweet, origanum_vulgare","sweet_marjoram, knotted_marjoram, origanum_majorana, majorana_hortensis","horehound","common_horehound, white_horehound, marrubium_vulgare","lemon_balm, garden_balm, sweet_balm, bee_balm, beebalm, melissa_officinalis","corn_mint, field_mint, mentha_arvensis","water-mint, water_mint, mentha_aquatica","bergamot_mint, lemon_mint, eau_de_cologne_mint, mentha_citrata","horsemint, mentha_longifolia","peppermint, mentha_piperita","spearmint, mentha_spicata","apple_mint, applemint, mentha_rotundifolia, mentha_suaveolens","pennyroyal, mentha_pulegium","yerba_buena, micromeria_chamissonis, micromeria_douglasii, satureja_douglasii","molucca_balm, bells_of_ireland, molucella_laevis","monarda, wild_bergamot","bee_balm, beebalm, bergamot_mint, oswego_tea, monarda_didyma","horsemint, monarda_punctata","bee_balm, beebalm, monarda_fistulosa","lemon_mint, horsemint, monarda_citriodora","plains_lemon_monarda, monarda_pectinata","basil_balm, monarda_clinopodia","mustang_mint, monardella_lanceolata","catmint, catnip, nepeta_cataria","basil","beefsteak_plant, perilla_frutescens_crispa","phlomis","jerusalem_sage, phlomis_fruticosa","physostegia","plectranthus","patchouli, patchouly, pachouli, pogostemon_cablin","self-heal, heal_all, prunella_vulgaris","mountain_mint","rosemary, rosmarinus_officinalis","clary_sage, salvia_clarea","purple_sage, chaparral_sage, salvia_leucophylla","cancerweed, cancer_weed, salvia_lyrata","common_sage, ramona, salvia_officinalis","meadow_clary, salvia_pratensis","clary, salvia_sclarea","pitcher_sage, salvia_spathacea","mexican_mint, salvia_divinorum","wild_sage, wild_clary, vervain_sage, salvia_verbenaca","savory","summer_savory, satureja_hortensis, satureia_hortensis","winter_savory, satureja_montana, satureia_montana","skullcap, helmetflower","blue_pimpernel, blue_skullcap, mad-dog_skullcap, mad-dog_weed, scutellaria_lateriflora","hedge_nettle, dead_nettle, stachys_sylvatica","hedge_nettle, stachys_palustris","germander","american_germander, wood_sage, teucrium_canadense","cat_thyme, marum, teucrium_marum","wood_sage, teucrium_scorodonia","thyme","common_thyme, thymus_vulgaris","wild_thyme, creeping_thyme, thymus_serpyllum","blue_curls","turpentine_camphor_weed, camphorweed, vinegarweed, trichostema_lanceolatum","bastard_pennyroyal, trichostema_dichotomum","bladderwort","butterwort","genlisea","martynia, martynia_annua","common_unicorn_plant, devil's_claw, common_devil's_claw, elephant-tusk, proboscis_flower, ram's_horn, proboscidea_louisianica","sand_devil's_claw, proboscidea_arenaria, martynia_arenaria","sweet_unicorn_plant, proboscidea_fragrans, martynia_fragrans","figwort","snapdragon","white_snapdragon, antirrhinum_coulterianum","yellow_twining_snapdragon, antirrhinum_filipes","mediterranean_snapdragon, antirrhinum_majus","kitten-tails","alpine_besseya, besseya_alpina","false_foxglove, aureolaria_pedicularia, gerardia_pedicularia","false_foxglove, aureolaria_virginica, gerardia_virginica","calceolaria, slipperwort","indian_paintbrush, painted_cup","desert_paintbrush, castilleja_chromosa","giant_red_paintbrush, castilleja_miniata","great_plains_paintbrush, castilleja_sessiliflora","sulfur_paintbrush, castilleja_sulphurea","shellflower, shell-flower, turtlehead, snakehead, snake-head, chelone_glabra","maiden_blue-eyed_mary, collinsia_parviflora","blue-eyed_mary, collinsia_verna","foxglove, digitalis","common_foxglove, fairy_bell, fingerflower, finger-flower, fingerroot, finger-root, digitalis_purpurea","yellow_foxglove, straw_foxglove, digitalis_lutea","gerardia","blue_toadflax, old-field_toadflax, linaria_canadensis","toadflax, butter-and-eggs, wild_snapdragon, devil's_flax, linaria_vulgaris","golden-beard_penstemon, penstemon_barbatus","scarlet_bugler, penstemon_centranthifolius","red_shrubby_penstemon, redwood_penstemon","platte_river_penstemon, penstemon_cyananthus","hot-rock_penstemon, penstemon_deustus","jones'_penstemon, penstemon_dolius","shrubby_penstemon, lowbush_penstemon, penstemon_fruticosus","narrow-leaf_penstemon, penstemon_linarioides","balloon_flower, scented_penstemon, penstemon_palmeri","parry's_penstemon, penstemon_parryi","rock_penstemon, cliff_penstemon, penstemon_rupicola","rydberg's_penstemon, penstemon_rydbergii","cascade_penstemon, penstemon_serrulatus","whipple's_penstemon, penstemon_whippleanus","moth_mullein, verbascum_blattaria","white_mullein, verbascum_lychnitis","purple_mullein, verbascum_phoeniceum","common_mullein, great_mullein, aaron's_rod, flannel_mullein, woolly_mullein, torch, verbascum_thapsus","veronica, speedwell","field_speedwell, veronica_agrestis","brooklime, american_brooklime, veronica_americana","corn_speedwell, veronica_arvensis","brooklime, european_brooklime, veronica_beccabunga","germander_speedwell, bird's_eye, veronica_chamaedrys","water_speedwell, veronica_michauxii, veronica_anagallis-aquatica","common_speedwell, gypsyweed, veronica_officinalis","purslane_speedwell, veronica_peregrina","thyme-leaved_speedwell, veronica_serpyllifolia","nightshade","horse_nettle, ball_nettle, bull_nettle, ball_nightshade, solanum_carolinense","african_holly, solanum_giganteum","potato_vine, solanum_jasmoides","garden_huckleberry, wonderberry, sunberry, solanum_nigrum_guineese, solanum_melanocerasum, solanum_burbankii","naranjilla, solanum_quitoense","potato_vine, giant_potato_creeper, solanum_wendlandii","potato_tree, brazilian_potato_tree, solanum_wrightii, solanum_macranthum","belladonna, belladonna_plant, deadly_nightshade, atropa_belladonna","bush_violet, browallia","lady-of-the-night, brunfelsia_americana","angel's_trumpet, maikoa, brugmansia_arborea, datura_arborea","angel's_trumpet, brugmansia_suaveolens, datura_suaveolens","red_angel's_trumpet, brugmansia_sanguinea, datura_sanguinea","cone_pepper, capsicum_annuum_conoides","bird_pepper, capsicum_frutescens_baccatum, capsicum_baccatum","day_jessamine, cestrum_diurnum","night_jasmine, night_jessamine, cestrum_nocturnum","tree_tomato, tamarillo","thorn_apple","jimsonweed, jimson_weed, jamestown_weed, common_thorn_apple, apple_of_peru, datura_stramonium","pichi, fabiana_imbricata","henbane, black_henbane, stinking_nightshade, hyoscyamus_niger","egyptian_henbane, hyoscyamus_muticus","matrimony_vine, boxthorn","common_matrimony_vine, duke_of_argyll's_tea_tree, lycium_barbarum, lycium_halimifolium","christmasberry, christmas_berry, lycium_carolinianum","plum_tomato","mandrake, devil's_apples, mandragora_officinarum","mandrake_root, mandrake","apple_of_peru, shoo_fly, nicandra_physaloides","flowering_tobacco, jasmine_tobacco, nicotiana_alata","common_tobacco, nicotiana_tabacum","wild_tobacco, indian_tobacco, nicotiana_rustica","cupflower, nierembergia","whitecup, nierembergia_repens, nierembergia_rivularis","petunia","large_white_petunia, petunia_axillaris","violet-flowered_petunia, petunia_integrifolia","hybrid_petunia, petunia_hybrida","cape_gooseberry, purple_ground_cherry, physalis_peruviana","strawberry_tomato, dwarf_cape_gooseberry, physalis_pruinosa","tomatillo, jamberry, mexican_husk_tomato, physalis_ixocarpa","tomatillo, miltomate, purple_ground_cherry, jamberry, physalis_philadelphica","yellow_henbane, physalis_viscosa","cock's_eggs, salpichroa_organifolia, salpichroa_rhomboidea","salpiglossis","painted_tongue, salpiglossis_sinuata","butterfly_flower, poor_man's_orchid, schizanthus","scopolia_carniolica","chalice_vine, trumpet_flower, cupflower, solandra_guttata","verbena, vervain","lantana","black_mangrove, avicennia_marina","white_mangrove, avicennia_officinalis","black_mangrove, aegiceras_majus","teak, tectona_grandis","spurge","sun_spurge, wartweed, wartwort, devil's_milk, euphorbia_helioscopia","petty_spurge, devil's_milk, euphorbia_peplus","medusa's_head, euphorbia_medusae, euphorbia_caput-medusae","wild_spurge, flowering_spurge, tramp's_spurge, euphorbia_corollata","snow-on-the-mountain, snow-in-summer, ghost_weed, euphorbia_marginata","cypress_spurge, euphorbia_cyparissias","leafy_spurge, wolf's_milk, euphorbia_esula","hairy_spurge, euphorbia_hirsuta","poinsettia, christmas_star, christmas_flower, lobster_plant, mexican_flameleaf, painted_leaf, euphorbia_pulcherrima","japanese_poinsettia, mole_plant, paint_leaf, euphorbia_heterophylla","fire-on-the-mountain, painted_leaf, mexican_fire_plant, euphorbia_cyathophora","wood_spurge, euphorbia_amygdaloides","dwarf_spurge, euphorbia_exigua","scarlet_plume, euphorbia_fulgens","naboom, cactus_euphorbia, euphorbia_ingens","crown_of_thorns, christ_thorn, christ_plant, euphorbia_milii","toothed_spurge, euphorbia_dentata","three-seeded_mercury, acalypha_virginica","croton, croton_tiglium","cascarilla, croton_eluteria","cascarilla_bark, eleuthera_bark, sweetwood_bark","castor-oil_plant, castor_bean_plant, palma_christi, palma_christ, ricinus_communis","spurge_nettle, tread-softly, devil_nettle, pica-pica, cnidoscolus_urens, jatropha_urens, jatropha_stimulosus","physic_nut, jatropha_curcus","para_rubber_tree, caoutchouc_tree, hevea_brasiliensis","cassava, casava","bitter_cassava, manioc, mandioc, mandioca, tapioca_plant, gari, manihot_esculenta, manihot_utilissima","cassava, manioc","sweet_cassava, manihot_dulcis","candlenut, varnish_tree, aleurites_moluccana","tung_tree, tung, tung-oil_tree, aleurites_fordii","slipper_spurge, slipper_plant","candelilla, pedilanthus_bracteatus, pedilanthus_pavonis","jewbush, jew-bush, jew_bush, redbird_cactus, redbird_flower, pedilanthus_tithymaloides","jumping_bean, jumping_seed, mexican_jumping_bean","camellia, camelia","japonica, camellia_japonica","umbellifer, umbelliferous_plant","wild_parsley","fool's_parsley, lesser_hemlock, aethusa_cynapium","dill, anethum_graveolens","angelica, angelique","garden_angelica, archangel, angelica_archangelica","wild_angelica, angelica_sylvestris","chervil, beaked_parsley, anthriscus_cereifolium","cow_parsley, wild_chervil, anthriscus_sylvestris","wild_celery, apium_graveolens","astrantia, masterwort","greater_masterwort, astrantia_major","caraway, carum_carvi","whorled_caraway","water_hemlock, cicuta_verosa","spotted_cowbane, spotted_hemlock, spotted_water_hemlock","hemlock, poison_hemlock, poison_parsley, california_fern, nebraska_fern, winter_fern, conium_maculatum","earthnut, conopodium_denudatum","cumin, cuminum_cyminum","wild_carrot, queen_anne's_lace, daucus_carota","eryngo, eringo","sea_holly, sea_holm, sea_eryngium, eryngium_maritimum","button_snakeroot, eryngium_aquaticum","rattlesnake_master, rattlesnake's_master, button_snakeroot, eryngium_yuccifolium","fennel","common_fennel, foeniculum_vulgare","florence_fennel, foeniculum_dulce, foeniculum_vulgare_dulce","cow_parsnip, hogweed, heracleum_sphondylium","lovage, levisticum_officinale","sweet_cicely, myrrhis_odorata","water_fennel, oenanthe_aquatica","parsnip, pastinaca_sativa","cultivated_parsnip","wild_parsnip, madnep","parsley, petroselinum_crispum","italian_parsley, flat-leaf_parsley, petroselinum_crispum_neapolitanum","hamburg_parsley, turnip-rooted_parsley, petroselinum_crispum_tuberosum","anise, anise_plant, pimpinella_anisum","sanicle, snakeroot","purple_sanicle, sanicula_bipinnatifida","european_sanicle, sanicula_europaea","water_parsnip, sium_suave","greater_water_parsnip, sium_latifolium","skirret, sium_sisarum","dogwood, dogwood_tree, cornel","common_white_dogwood, eastern_flowering_dogwood, cornus_florida","red_osier, red_osier_dogwood, red_dogwood, american_dogwood, redbrush, cornus_stolonifera","silky_dogwood, cornus_obliqua","silky_cornel, silky_dogwood, cornus_amomum","common_european_dogwood, red_dogwood, blood-twig, pedwood, cornus_sanguinea","bunchberry, dwarf_cornel, crackerberry, pudding_berry, cornus_canadensis","cornelian_cherry, cornus_mas","puka, griselinia_lucida","kapuka, griselinia_littoralis","valerian","common_valerian, garden_heliotrope, valeriana_officinalis","common_corn_salad, lamb's_lettuce, valerianella_olitoria, valerianella_locusta","red_valerian, french_honeysuckle, centranthus_ruber","filmy_fern, film_fern","bristle_fern, filmy_fern","hare's-foot_bristle_fern, trichomanes_boschianum","killarney_fern, trichomanes_speciosum","kidney_fern, trichomanes_reniforme","flowering_fern, osmund","royal_fern, royal_osmund, king_fern, ditch_fern, french_bracken, osmunda_regalis","interrupted_fern, osmunda_clatonia","crape_fern, prince-of-wales_fern, prince-of-wales_feather, prince-of-wales_plume, leptopteris_superba, todea_superba","crepe_fern, king_fern, todea_barbara","curly_grass, curly_grass_fern, schizaea_pusilla","pine_fern, anemia_adiantifolia","climbing_fern","creeping_fern, hartford_fern, lygodium_palmatum","climbing_maidenhair, climbing_maidenhair_fern, snake_fern, lygodium_microphyllum","scented_fern, mohria_caffrorum","clover_fern, pepperwort","nardoo, nardo, common_nardoo, marsilea_drummondii","water_clover, marsilea_quadrifolia","pillwort, pilularia_globulifera","regnellidium, regnellidium_diphyllum","floating-moss, salvinia_rotundifolia, salvinia_auriculata","mosquito_fern, floating_fern, carolina_pond_fern, azolla_caroliniana","adder's_tongue, adder's_tongue_fern","ribbon_fern, ophioglossum_pendulum","grape_fern","daisyleaf_grape_fern, daisy-leaved_grape_fern, botrychium_matricariifolium","leathery_grape_fern, botrychium_multifidum","rattlesnake_fern, botrychium_virginianum","flowering_fern, helminthostachys_zeylanica","powdery_mildew","dutch_elm_fungus, ceratostomella_ulmi","ergot, claviceps_purpurea","rye_ergot","black_root_rot_fungus, xylaria_mali","dead-man's-fingers, dead-men's-fingers, xylaria_polymorpha","sclerotinia","brown_cup","earthball, false_truffle, puffball, hard-skinned_puffball","scleroderma_citrinum, scleroderma_aurantium","scleroderma_flavidium, star_earthball","scleroderma_bovista, smooth_earthball","podaxaceae","stalked_puffball","stalked_puffball","false_truffle","rhizopogon_idahoensis","truncocolumella_citrina","mucor","rhizopus","bread_mold, rhizopus_nigricans","slime_mold, slime_mould","true_slime_mold, acellular_slime_mold, plasmodial_slime_mold, myxomycete","cellular_slime_mold","dictostylium","pond-scum_parasite","potato_wart_fungus, synchytrium_endobioticum","white_fungus, saprolegnia_ferax","water_mold","downy_mildew, false_mildew","blue_mold_fungus, peronospora_tabacina","onion_mildew, peronospora_destructor","tobacco_mildew, peronospora_hyoscyami","white_rust","pythium","damping_off_fungus, pythium_debaryanum","phytophthora_citrophthora","phytophthora_infestans","clubroot_fungus, plasmodiophora_brassicae","geglossaceae","sarcosomataceae","rufous_rubber_cup","devil's_cigar","devil's_urn","truffle, earthnut, earth-ball","club_fungus","coral_fungus","tooth_fungus","lichen","ascolichen","basidiolichen","lecanora","manna_lichen","archil, orchil","roccella, roccella_tinctoria","beard_lichen, beard_moss, usnea_barbata","horsehair_lichen, horsetail_lichen","reindeer_moss, reindeer_lichen, arctic_moss, cladonia_rangiferina","crottle, crottal, crotal","iceland_moss, iceland_lichen, cetraria_islandica","fungus","promycelium","true_fungus","basidiomycete, basidiomycetous_fungi","mushroom","agaric","mushroom","mushroom","toadstool","horse_mushroom, agaricus_arvensis","meadow_mushroom, field_mushroom, agaricus_campestris","shiitake, shiitake_mushroom, chinese_black_mushroom, golden_oak_mushroom, oriental_black_mushroom, lentinus_edodes","scaly_lentinus, lentinus_lepideus","royal_agaric, caesar's_agaric, amanita_caesarea","false_deathcap, amanita_mappa","fly_agaric, amanita_muscaria","death_cap, death_cup, death_angel, destroying_angel, amanita_phalloides","blushing_mushroom, blusher, amanita_rubescens","destroying_angel, amanita_verna","chanterelle, chantarelle, cantharellus_cibarius","floccose_chanterelle, cantharellus_floccosus","pig's_ears, cantharellus_clavatus","cinnabar_chanterelle, cantharellus_cinnabarinus","jack-o-lantern_fungus, jack-o-lantern, jack-a-lantern, omphalotus_illudens","inky_cap, inky-cap_mushroom, coprinus_atramentarius","shaggymane, shaggy_cap, shaggymane_mushroom, coprinus_comatus","milkcap, lactarius_delicioso","fairy-ring_mushroom, marasmius_oreades","fairy_ring, fairy_circle","oyster_mushroom, oyster_fungus, oyster_agaric, pleurotus_ostreatus","olive-tree_agaric, pleurotus_phosphoreus","pholiota_astragalina","pholiota_aurea, golden_pholiota","pholiota_destruens","pholiota_flammans","pholiota_flavida","nameko, viscid_mushroom, pholiota_nameko","pholiota_squarrosa-adiposa","pholiota_squarrosa, scaly_pholiota","pholiota_squarrosoides","stropharia_ambigua","stropharia_hornemannii","stropharia_rugoso-annulata","gill_fungus","entoloma_lividum, entoloma_sinuatum","entoloma_aprile","chlorophyllum_molybdites","lepiota","parasol_mushroom, lepiota_procera","poisonous_parasol, lepiota_morgani","lepiota_naucina","lepiota_rhacodes","american_parasol, lepiota_americana","lepiota_rubrotincta","lepiota_clypeolaria","onion_stem, lepiota_cepaestipes","pink_disease_fungus, corticium_salmonicolor","bottom_rot_fungus, corticium_solani","potato_fungus, pellicularia_filamentosa, rhizoctinia_solani","coffee_fungus, pellicularia_koleroga","blewits, clitocybe_nuda","sandy_mushroom, tricholoma_populinum","tricholoma_pessundatum","tricholoma_sejunctum","man-on-a-horse, tricholoma_flavovirens","tricholoma_venenata","tricholoma_pardinum","tricholoma_vaccinum","tricholoma_aurantium","volvaria_bombycina","pluteus_aurantiorugosus","pluteus_magnus, sawdust_mushroom","deer_mushroom, pluteus_cervinus","straw_mushroom, chinese_mushroom, volvariella_volvacea","volvariella_bombycina","clitocybe_clavipes","clitocybe_dealbata","clitocybe_inornata","clitocybe_robusta, clytocybe_alba","clitocybe_irina, tricholoma_irinum, lepista_irina","clitocybe_subconnexa","winter_mushroom, flammulina_velutipes","mycelium","sclerotium","sac_fungus","ascomycete, ascomycetous_fungus","clavicipitaceae, grainy_club_mushrooms","grainy_club","yeast","baker's_yeast, brewer's_yeast, saccharomyces_cerevisiae","wine-maker's_yeast, saccharomyces_ellipsoides","aspergillus_fumigatus","brown_root_rot_fungus, thielavia_basicola","discomycete, cup_fungus","leotia_lubrica","mitrula_elegans","sarcoscypha_coccinea, scarlet_cup","caloscypha_fulgens","aleuria_aurantia, orange_peel_fungus","elf_cup","peziza_domicilina","blood_cup, fairy_cup, peziza_coccinea","urnula_craterium, urn_fungus","galiella_rufa","jafnea_semitosta","morel","common_morel, morchella_esculenta, sponge_mushroom, sponge_morel","disciotis_venosa, cup_morel","verpa, bell_morel","verpa_bohemica, early_morel","verpa_conica, conic_verpa","black_morel, morchella_conica, conic_morel, morchella_angusticeps, narrowhead_morel","morchella_crassipes, thick-footed_morel","morchella_semilibera, half-free_morel, cow's_head","wynnea_americana","wynnea_sparassoides","false_morel","lorchel","helvella","helvella_crispa, miter_mushroom","helvella_acetabulum","helvella_sulcata","discina","gyromitra","gyromitra_californica, california_false_morel","gyromitra_sphaerospora, round-spored_gyromitra","gyromitra_esculenta, brain_mushroom, beefsteak_morel","gyromitra_infula, saddled-shaped_false_morel","gyromitra_fastigiata, gyromitra_brunnea","gyromitra_gigas","gasteromycete, gastromycete","stinkhorn, carrion_fungus","common_stinkhorn, phallus_impudicus","phallus_ravenelii","dog_stinkhorn, mutinus_caninus","calostoma_lutescens","calostoma_cinnabarina","calostoma_ravenelii","stinky_squid, pseudocolus_fusiformis","puffball, true_puffball","giant_puffball, calvatia_gigantea","earthstar","geastrum_coronatum","radiigera_fuscogleba","astreus_pteridis","astreus_hygrometricus","bird's-nest_fungus","gastrocybe_lateritia","macowanites_americanus","polypore, pore_fungus, pore_mushroom","bracket_fungus, shelf_fungus","albatrellus_dispansus","albatrellus_ovinus, sheep_polypore","neolentinus_ponderosus","oligoporus_leucospongia","polyporus_tenuiculus","hen-of-the-woods, hen_of_the_woods, polyporus_frondosus, grifola_frondosa","polyporus_squamosus, scaly_polypore","beefsteak_fungus, fistulina_hepatica","agaric, fomes_igniarius","bolete","boletus_chrysenteron","boletus_edulis","frost's_bolete, boletus_frostii","boletus_luridus","boletus_mirabilis","boletus_pallidus","boletus_pulcherrimus","boletus_pulverulentus","boletus_roxanae","boletus_subvelutipes","boletus_variipes","boletus_zelleri","fuscoboletinus_paluster","fuscoboletinus_serotinus","leccinum_fibrillosum","suillus_albivelatus","old-man-of-the-woods, strobilomyces_floccopus","boletellus_russellii","jelly_fungus","snow_mushroom, tremella_fuciformis","witches'_butter, tremella_lutescens","tremella_foliacea","tremella_reticulata","jew's-ear, jew's-ears, ear_fungus, auricularia_auricula","rust, rust_fungus","aecium","flax_rust, flax_rust_fungus, melampsora_lini","blister_rust, cronartium_ribicola","wheat_rust, puccinia_graminis","apple_rust, cedar-apple_rust, gymnosporangium_juniperi-virginianae","smut, smut_fungus","covered_smut","loose_smut","cornsmut, corn_smut","boil_smut, ustilago_maydis","sphacelotheca, genus_sphacelotheca","head_smut, sphacelotheca_reiliana","bunt, tilletia_caries","bunt, stinking_smut, tilletia_foetida","onion_smut, urocystis_cepulae","flag_smut_fungus","wheat_flag_smut, urocystis_tritici","felt_fungus, septobasidium_pseudopedicellatum","waxycap","hygrocybe_acutoconica, conic_waxycap","hygrophorus_borealis","hygrophorus_caeruleus","hygrophorus_inocybiformis","hygrophorus_kauffmanii","hygrophorus_marzuolus","hygrophorus_purpurascens","hygrophorus_russula","hygrophorus_sordidus","hygrophorus_tennesseensis","hygrophorus_turundus","neohygrophorus_angelesianus","cortinarius_armillatus","cortinarius_atkinsonianus","cortinarius_corrugatus","cortinarius_gentilis","cortinarius_mutabilis, purple-staining_cortinarius","cortinarius_semisanguineus","cortinarius_subfoetidus","cortinarius_violaceus","gymnopilus_spectabilis","gymnopilus_validipes","gymnopilus_ventricosus","mold, mould","mildew","verticillium","monilia","candida","candida_albicans, monilia_albicans","blastomycete","yellow_spot_fungus, cercospora_kopkei","green_smut_fungus, ustilaginoidea_virens","dry_rot","rhizoctinia","houseplant","bedder, bedding_plant","succulent","cultivar","weed","wort","brier","aril","sporophyll, sporophyl","sporangium, spore_case, spore_sac","sporangiophore","ascus","ascospore","arthrospore","eusporangium","tetrasporangium","gametangium","sorus","sorus","partial_veil","lignum","vascular_ray, medullary_ray","phloem, bast","evergreen, evergreen_plant","deciduous_plant","poisonous_plant","vine","creeper","tendril","root_climber","lignosae","arborescent_plant","snag","tree","timber_tree","treelet","arbor","bean_tree","pollard","sapling","shade_tree","gymnospermous_tree","conifer, coniferous_tree","angiospermous_tree, flowering_tree","nut_tree","spice_tree","fever_tree","stump, tree_stump","bonsai","ming_tree","ming_tree","undershrub","subshrub, suffrutex","bramble","liana","geophyte","desert_plant, xerophyte, xerophytic_plant, xerophile, xerophilous_plant","mesophyte, mesophytic_plant","marsh_plant, bog_plant, swamp_plant","hemiepiphyte, semiepiphyte","strangler, strangler_tree","lithophyte, lithophytic_plant","saprobe","autophyte, autophytic_plant, autotroph, autotrophic_organism","root","taproot","prop_root","prophyll","rootstock","quickset","stolon, runner, offset","tuberous_plant","rhizome, rootstock, rootstalk","rachis","caudex","cladode, cladophyll, phylloclad, phylloclade","receptacle","scape, flower_stalk","umbel","petiole, leafstalk","peduncle","pedicel, pedicle","flower_cluster","raceme","panicle","thyrse, thyrsus","cyme","cymule","glomerule","scorpioid_cyme","ear, spike, capitulum","spadix","bulbous_plant","bulbil, bulblet","cormous_plant","fruit","fruitlet","seed","bean","nut","nutlet","kernel, meat","syconium","berry","aggregate_fruit, multiple_fruit, syncarp","simple_fruit, bacca","acinus","drupe, stone_fruit","drupelet","pome, false_fruit","pod, seedpod","loment","pyxidium, pyxis","husk","cornhusk","pod, cod, seedcase","accessory_fruit, pseudocarp","buckthorn","buckthorn_berry, yellow_berry","cascara_buckthorn, bearberry, bearwood, chittamwood, chittimwood, rhamnus_purshianus","cascara, cascara_sagrada, chittam_bark, chittem_bark","carolina_buckthorn, indian_cherry, rhamnus_carolinianus","coffeeberry, california_buckthorn, california_coffee, rhamnus_californicus","redberry, red-berry, rhamnus_croceus","nakedwood","jujube, jujube_bush, christ's-thorn, jerusalem_thorn, ziziphus_jujuba","christ's-thorn, jerusalem_thorn, paliurus_spina-christi","hazel, hazel_tree, pomaderris_apetala","fox_grape, vitis_labrusca","muscadine, vitis_rotundifolia","vinifera, vinifera_grape, common_grape_vine, vitis_vinifera","pinot_blanc","sauvignon_grape","sauvignon_blanc","muscadet","riesling","zinfandel","chenin_blanc","malvasia","verdicchio","boston_ivy, japanese_ivy, parthenocissus_tricuspidata","virginia_creeper, american_ivy, woodbine, parthenocissus_quinquefolia","true_pepper, pepper_vine","betel, betel_pepper, piper_betel","cubeb","schizocarp","peperomia","watermelon_begonia, peperomia_argyreia, peperomia_sandersii","yerba_mansa, anemopsis_californica","pinna, pinnule","frond","bract","bracteole, bractlet","involucre","glume","palmate_leaf","pinnate_leaf","bijugate_leaf, bijugous_leaf, twice-pinnate","decompound_leaf","acuminate_leaf","deltoid_leaf","ensiform_leaf","linear_leaf, elongate_leaf","lyrate_leaf","obtuse_leaf","oblanceolate_leaf","pandurate_leaf, panduriform_leaf","reniform_leaf","spatulate_leaf","even-pinnate_leaf, abruptly-pinnate_leaf","odd-pinnate_leaf","pedate_leaf","crenate_leaf","dentate_leaf","denticulate_leaf","erose_leaf","runcinate_leaf","prickly-edged_leaf","deadwood","haulm, halm","branchlet, twig, sprig","osier","giant_scrambling_fern, diplopterygium_longissimum","umbrella_fern, fan_fern, sticherus_flabellatus, gleichenia_flabellata","floating_fern, water_sprite, ceratopteris_pteridioides","polypody","licorice_fern, polypodium_glycyrrhiza","grey_polypody, gray_polypody, resurrection_fern, polypodium_polypodioides","leatherleaf, leathery_polypody, coast_polypody, polypodium_scouleri","rock_polypody, rock_brake, american_wall_fern, polypodium_virgianum","common_polypody, adder's_fern, wall_fern, golden_maidenhair, golden_polypody, sweet_fern, polypodium_vulgare","bear's-paw_fern, aglaomorpha_meyeniana","strap_fern","florida_strap_fern, cow-tongue_fern, hart's-tongue_fern","basket_fern, drynaria_rigidula","snake_polypody, microgramma-piloselloides","climbing_bird's_nest_fern, microsorium_punctatum","golden_polypody, serpent_fern, rabbit's-foot_fern, phlebodium_aureum, polypodium_aureum","staghorn_fern","south_american_staghorn, platycerium_andinum","common_staghorn_fern, elkhorn_fern, platycerium_bifurcatum, platycerium_alcicorne","felt_fern, tongue_fern, pyrrosia_lingua, cyclophorus_lingua","potato_fern, solanopteris_bifrons","myrmecophyte","grass_fern, ribbon_fern, vittaria_lineata","spleenwort","black_spleenwort, asplenium_adiantum-nigrum","bird's_nest_fern, asplenium_nidus","ebony_spleenwort, scott's_spleenwort, asplenium_platyneuron","black-stem_spleenwort, black-stemmed_spleenwort, little_ebony_spleenwort","walking_fern, walking_leaf, asplenium_rhizophyllum, camptosorus_rhizophyllus","green_spleenwort, asplenium_viride","mountain_spleenwort, asplenium_montanum","lobed_spleenwort, asplenium_pinnatifidum","lanceolate_spleenwort, asplenium_billotii","hart's-tongue, hart's-tongue_fern, asplenium_scolopendrium, phyllitis_scolopendrium","scale_fern, scaly_fern, asplenium_ceterach, ceterach_officinarum","scolopendrium","deer_fern, blechnum_spicant","doodia, rasp_fern","chain_fern","virginia_chain_fern, woodwardia_virginica","silver_tree_fern, sago_fern, black_tree_fern, cyathea_medullaris","davallia","hare's-foot_fern","canary_island_hare's_foot_fern, davallia_canariensis","squirrel's-foot_fern, ball_fern, davalia_bullata, davalia_bullata_mariesii, davallia_mariesii","bracken, pteridium_esculentum","soft_tree_fern, dicksonia_antarctica","scythian_lamb, cibotium_barometz","false_bracken, culcita_dubia","thyrsopteris, thyrsopteris_elegans","shield_fern, buckler_fern","broad_buckler-fern, dryopteris_dilatata","fragrant_cliff_fern, fragrant_shield_fern, fragrant_wood_fern, dryopteris_fragrans","goldie's_fern, goldie's_shield_fern, goldie's_wood_fern, dryopteris_goldiana","wood_fern, wood-fern, woodfern","male_fern, dryopteris_filix-mas","marginal_wood_fern, evergreen_wood_fern, leatherleaf_wood_fern, dryopteris_marginalis","mountain_male_fern, dryopteris_oreades","lady_fern, athyrium_filix-femina","alpine_lady_fern, athyrium_distentifolium","silvery_spleenwort, glade_fern, narrow-leaved_spleenwort, athyrium_pycnocarpon, diplazium_pycnocarpon","holly_fern, cyrtomium_aculeatum, polystichum_aculeatum","bladder_fern","brittle_bladder_fern, brittle_fern, fragile_fern, cystopteris_fragilis","mountain_bladder_fern, cystopteris_montana","bulblet_fern, bulblet_bladder_fern, berry_fern, cystopteris_bulbifera","silvery_spleenwort, deparia_acrostichoides, athyrium_thelypteroides","oak_fern, gymnocarpium_dryopteris, thelypteris_dryopteris","limestone_fern, northern_oak_fern, gymnocarpium_robertianum","ostrich_fern, shuttlecock_fern, fiddlehead, matteuccia_struthiopteris, pteretis_struthiopteris, onoclea_struthiopteris","hart's-tongue, hart's-tongue_fern, olfersia_cervina, polybotrya_cervina, polybotria_cervina","sensitive_fern, bead_fern, onoclea_sensibilis","christmas_fern, canker_brake, dagger_fern, evergreen_wood_fern, polystichum_acrostichoides","holly_fern","braun's_holly_fern, prickly_shield_fern, polystichum_braunii","western_holly_fern, polystichum_scopulinum","soft_shield_fern, polystichum_setiferum","leather_fern, leatherleaf_fern, ten-day_fern, rumohra_adiantiformis, polystichum_adiantiformis","button_fern, tectaria_cicutaria","indian_button_fern, tectaria_macrodonta","woodsia","rusty_woodsia, fragrant_woodsia, oblong_woodsia, woodsia_ilvensis","alpine_woodsia, northern_woodsia, flower-cup_fern, woodsia_alpina","smooth_woodsia, woodsia_glabella","boston_fern, nephrolepis_exaltata, nephrolepis_exaltata_bostoniensis","basket_fern, toothed_sword_fern, nephrolepis_pectinata","golden_fern, leather_fern, acrostichum_aureum","maidenhair, maidenhair_fern","common_maidenhair, venushair, venus'-hair_fern, southern_maidenhair, venus_maidenhair, adiantum_capillus-veneris","american_maidenhair_fern, five-fingered_maidenhair_fern, adiantum_pedatum","bermuda_maidenhair, bermuda_maidenhair_fern, adiantum_bellum","brittle_maidenhair, brittle_maidenhair_fern, adiantum_tenerum","farley_maidenhair, farley_maidenhair_fern, barbados_maidenhair, glory_fern, adiantum_tenerum_farleyense","annual_fern, jersey_fern, anogramma_leptophylla","lip_fern, lipfern","smooth_lip_fern, alabama_lip_fern, cheilanthes_alabamensis","lace_fern, cheilanthes_gracillima","wooly_lip_fern, hairy_lip_fern, cheilanthes_lanosa","southwestern_lip_fern, cheilanthes_eatonii","bamboo_fern, coniogramme_japonica","american_rock_brake, american_parsley_fern, cryptogramma_acrostichoides","european_parsley_fern, mountain_parsley_fern, cryptogramma_crispa","hand_fern, doryopteris_pedata","cliff_brake, cliff-brake, rock_brake","coffee_fern, pellaea_andromedifolia","purple_rock_brake, pellaea_atropurpurea","bird's-foot_fern, pellaea_mucronata, pellaea_ornithopus","button_fern, pellaea_rotundifolia","silver_fern, pityrogramma_argentea","golden_fern, pityrogramma_calomelanos_aureoflava","gold_fern, pityrogramma_chrysophylla","pteris_cretica","spider_brake, spider_fern, pteris_multifida","ribbon_fern, spider_fern, pteris_serrulata","potato_fern, marattia_salicina","angiopteris, giant_fern, angiopteris_evecta","skeleton_fork_fern, psilotum_nudum","horsetail","common_horsetail, field_horsetail, equisetum_arvense","swamp_horsetail, water_horsetail, equisetum_fluviatile","scouring_rush, rough_horsetail, equisetum_hyemale, equisetum_hyemale_robustum, equisetum_robustum","marsh_horsetail, equisetum_palustre","wood_horsetail, equisetum_sylvaticum","variegated_horsetail, variegated_scouring_rush, equisetum_variegatum","club_moss, club-moss, lycopod","shining_clubmoss, lycopodium_lucidulum","alpine_clubmoss, lycopodium_alpinum","fir_clubmoss, mountain_clubmoss, little_clubmoss, lycopodium_selago","ground_cedar, staghorn_moss, lycopodium_complanatum","ground_fir, princess_pine, tree_clubmoss, lycopodium_obscurum","foxtail_grass, lycopodium_alopecuroides","spikemoss, spike_moss, little_club_moss","meadow_spikemoss, basket_spikemoss, selaginella_apoda","desert_selaginella, selaginella_eremophila","resurrection_plant, rose_of_jericho, selaginella_lepidophylla","florida_selaginella, selaginella_eatonii","quillwort","earthtongue, earth-tongue","snuffbox_fern, meadow_fern, thelypteris_palustris_pubescens, dryopteris_thelypteris_pubescens","christella","mountain_fern, oreopteris_limbosperma, dryopteris_oreopteris","new_york_fern, parathelypteris_novae-boracensis, dryopteris_noveboracensis","massachusetts_fern, parathelypteris_simulata, thelypteris_simulata","beech_fern","broad_beech_fern, southern_beech_fern, phegopteris_hexagonoptera, dryopteris_hexagonoptera, thelypteris_hexagonoptera","long_beech_fern, narrow_beech_fern, northern_beech_fern, phegopteris_connectilis, dryopteris_phegopteris, thelypteris_phegopteris","shoestring_fungus","armillaria_caligata, booted_armillaria","armillaria_ponderosa, white_matsutake","armillaria_zelleri","honey_mushroom, honey_fungus, armillariella_mellea","milkweed, silkweed","white_milkweed, asclepias_albicans","poke_milkweed, asclepias_exaltata","swamp_milkweed, asclepias_incarnata","mead's_milkweed, asclepias_meadii, asclepia_meadii","purple_silkweed, asclepias_purpurascens","showy_milkweed, asclepias_speciosa","poison_milkweed, horsetail_milkweed, asclepias_subverticillata","butterfly_weed, orange_milkweed, chigger_flower, chiggerflower, pleurisy_root, tuber_root, indian_paintbrush, asclepias_tuberosa","whorled_milkweed, asclepias_verticillata","cruel_plant, araujia_sericofera","wax_plant, hoya_carnosa","silk_vine, periploca_graeca","stapelia, carrion_flower, starfish_flower","stapelias_asterias","stephanotis","madagascar_jasmine, waxflower, stephanotis_floribunda","negro_vine, vincetoxicum_hirsutum, vincetoxicum_negrum","zygospore","tree_of_knowledge","orangery","pocketbook","shit, dump","cordage","yard, pace","extremum, peak","leaf_shape, leaf_form","equilateral","figure","pencil","plane_figure, two-dimensional_figure","solid_figure, three-dimensional_figure","line","bulb","convex_shape, convexity","concave_shape, concavity, incurvation, incurvature","cylinder","round_shape","heart","polygon, polygonal_shape","convex_polygon","concave_polygon","reentrant_polygon, reentering_polygon","amorphous_shape","closed_curve","simple_closed_curve, jordan_curve","s-shape","wave, undulation","extrados","hook, crotchet","envelope","bight","diameter","cone, conoid, cone_shape","funnel, funnel_shape","oblong","circle","circle","equator","scallop, crenation, crenature, crenel, crenelle","ring, halo, annulus, doughnut, anchor_ring","loop","bight","helix, spiral","element_of_a_cone","element_of_a_cylinder","ellipse, oval","quadrate","triangle, trigon, trilateral","acute_triangle, acute-angled_triangle","isosceles_triangle","obtuse_triangle, obtuse-angled_triangle","right_triangle, right-angled_triangle","scalene_triangle","parallel","trapezoid","star","pentagon","hexagon","heptagon","octagon","nonagon","decagon","rhombus, rhomb, diamond","spherical_polygon","spherical_triangle","convex_polyhedron","concave_polyhedron","cuboid","quadrangular_prism","bell, bell_shape, campana","angular_distance","true_anomaly","spherical_angle","angle_of_refraction","acute_angle","groove, channel","rut","bulge, bump, hump, swelling, gibbosity, gibbousness, jut, prominence, protuberance, protrusion, extrusion, excrescence","belly","bow, arc","crescent","ellipsoid","hypotenuse","balance, equilibrium, equipoise, counterbalance","conformation","symmetry, proportion","spheroid, ellipsoid_of_revolution","spherule","toroid","column, tower, pillar","barrel, drum","pipe, tube","pellet","bolus","dewdrop","ridge","rim","taper","boundary, edge, bound","incisure, incisura","notch","wrinkle, furrow, crease, crinkle, seam, line","dermatoglyphic","frown_line","line_of_life, life_line, lifeline","line_of_heart, heart_line, love_line, mensal_line","crevice, cranny, crack, fissure, chap","cleft","roulette, line_roulette","node","tree, tree_diagram","stemma","brachium","fork, crotch","block, cube","ovoid","tetrahedron","pentahedron","hexahedron","regular_polyhedron, regular_convex_solid, regular_convex_polyhedron, platonic_body, platonic_solid, ideal_solid","polyhedral_angle","cube, regular_hexahedron","truncated_pyramid","truncated_cone","tail, tail_end","tongue, knife","trapezohedron","wedge, wedge_shape, cuneus","keel","place, shoes","herpes","chlamydia","wall","micronutrient","chyme","ragweed_pollen","pina_cloth","chlorobenzylidenemalononitrile, cs_gas","carbon, c, atomic_number_6","charcoal, wood_coal","rock, stone","gravel, crushed_rock","aflatoxin","alpha-tocopheral","leopard","bricks_and_mortar","lagging","hydraulic_cement, portland_cement","choline","concrete","glass_wool","soil, dirt","high_explosive","litter","fish_meal","greek_fire","culture_medium, medium","agar, nutrient_agar","blood_agar","hip_tile, hipped_tile","hyacinth, jacinth","hydroxide_ion, hydroxyl_ion","ice, water_ice","inositol","linoleum, lino","lithia_water","lodestone, loadstone","pantothenic_acid, pantothen","paper","papyrus","pantile","blacktop, blacktopping","tarmacadam, tarmac","paving, pavement, paving_material","plaster","poison_gas","ridge_tile","roughcast","sand","spackle, spackling_compound","render","wattle_and_daub","stucco","tear_gas, teargas, lacrimator, lachrymator","toilet_tissue, toilet_paper, bathroom_tissue","linseed, flaxseed","vitamin","fat-soluble_vitamin","water-soluble_vitamin","vitamin_a, antiophthalmic_factor, axerophthol, a","vitamin_a1, retinol","vitamin_a2, dehydroretinol","b-complex_vitamin, b_complex, vitamin_b_complex, vitamin_b, b_vitamin, b","vitamin_b1, thiamine, thiamin, aneurin, antiberiberi_factor","vitamin_b12, cobalamin, cyanocobalamin, antipernicious_anemia_factor","vitamin_b2, vitamin_g, riboflavin, lactoflavin, ovoflavin, hepatoflavin","vitamin_b6, pyridoxine, pyridoxal, pyridoxamine, adermin","vitamin_bc, vitamin_m, folate, folic_acid, folacin, pteroylglutamic_acid, pteroylmonoglutamic_acid","niacin, nicotinic_acid","vitamin_d, calciferol, viosterol, ergocalciferol, cholecalciferol, d","vitamin_e, tocopherol, e","biotin, vitamin_h","vitamin_k, naphthoquinone, antihemorrhagic_factor","vitamin_k1, phylloquinone, phytonadione","vitamin_k3, menadione","vitamin_p, bioflavinoid, citrin","vitamin_c, c, ascorbic_acid","planking","chipboard, hardboard","knothole"],"string":"[\n \"organism, being\",\n \"benthos\",\n \"heterotroph\",\n \"cell\",\n \"person, individual, someone, somebody, mortal, soul\",\n \"animal, animate_being, beast, brute, creature, fauna\",\n \"plant, flora, plant_life\",\n \"food, nutrient\",\n \"artifact, artefact\",\n \"hop\",\n \"check-in\",\n \"dressage\",\n \"curvet, vaulting\",\n \"piaffe\",\n \"funambulism, tightrope_walking\",\n \"rock_climbing\",\n \"contact_sport\",\n \"outdoor_sport, field_sport\",\n \"gymnastics, gymnastic_exercise\",\n \"acrobatics, tumbling\",\n \"track_and_field\",\n \"track, running\",\n \"jumping\",\n \"broad_jump, long_jump\",\n \"high_jump\",\n \"fosbury_flop\",\n \"skiing\",\n \"cross-country_skiing\",\n \"ski_jumping\",\n \"water_sport, aquatics\",\n \"swimming, swim\",\n \"bathe\",\n \"dip, plunge\",\n \"dive, diving\",\n \"floating, natation\",\n \"dead-man's_float, prone_float\",\n \"belly_flop, belly_flopper, belly_whop, belly_whopper\",\n \"cliff_diving\",\n \"flip\",\n \"gainer, full_gainer\",\n \"half_gainer\",\n \"jackknife\",\n \"swan_dive, swallow_dive\",\n \"skin_diving, skin-dive\",\n \"scuba_diving\",\n \"snorkeling, snorkel_diving\",\n \"surfing, surfboarding, surfriding\",\n \"water-skiing\",\n \"rowing, row\",\n \"sculling\",\n \"boxing, pugilism, fisticuffs\",\n \"professional_boxing\",\n \"in-fighting\",\n \"fight\",\n \"rope-a-dope\",\n \"spar, sparring\",\n \"archery\",\n \"sledding\",\n \"tobogganing\",\n \"luging\",\n \"bobsledding\",\n \"wrestling, rassling, grappling\",\n \"greco-roman_wrestling\",\n \"professional_wrestling\",\n \"sumo\",\n \"skating\",\n \"ice_skating\",\n \"figure_skating\",\n \"rollerblading\",\n \"roller_skating\",\n \"skateboarding\",\n \"speed_skating\",\n \"racing\",\n \"auto_racing, car_racing\",\n \"boat_racing\",\n \"hydroplane_racing\",\n \"camel_racing\",\n \"greyhound_racing\",\n \"horse_racing\",\n \"riding, horseback_riding, equitation\",\n \"equestrian_sport\",\n \"pony-trekking\",\n \"showjumping, stadium_jumping\",\n \"cross-country_riding, cross-country_jumping\",\n \"cycling\",\n \"bicycling\",\n \"motorcycling\",\n \"dune_cycling\",\n \"blood_sport\",\n \"bullfighting, tauromachy\",\n \"cockfighting\",\n \"hunt, hunting\",\n \"battue\",\n \"beagling\",\n \"coursing\",\n \"deer_hunting, deer_hunt\",\n \"ducking, duck_hunting\",\n \"fox_hunting, foxhunt\",\n \"pigsticking\",\n \"fishing, sportfishing\",\n \"angling\",\n \"fly-fishing\",\n \"troll, trolling\",\n \"casting, cast\",\n \"bait_casting\",\n \"fly_casting\",\n \"overcast\",\n \"surf_casting, surf_fishing\",\n \"day_game\",\n \"athletic_game\",\n \"ice_hockey, hockey, hockey_game\",\n \"tetherball\",\n \"water_polo\",\n \"outdoor_game\",\n \"golf, golf_game\",\n \"professional_golf\",\n \"round_of_golf, round\",\n \"medal_play, stroke_play\",\n \"match_play\",\n \"miniature_golf\",\n \"croquet\",\n \"quoits, horseshoes\",\n \"shuffleboard, shovelboard\",\n \"field_game\",\n \"field_hockey, hockey\",\n \"shinny, shinney\",\n \"football, football_game\",\n \"american_football, american_football_game\",\n \"professional_football\",\n \"touch_football\",\n \"hurling\",\n \"rugby, rugby_football, rugger\",\n \"ball_game, ballgame\",\n \"baseball, baseball_game\",\n \"ball\",\n \"professional_baseball\",\n \"hardball\",\n \"perfect_game\",\n \"no-hit_game, no-hitter\",\n \"one-hitter, 1-hitter\",\n \"two-hitter, 2-hitter\",\n \"three-hitter, 3-hitter\",\n \"four-hitter, 4-hitter\",\n \"five-hitter, 5-hitter\",\n \"softball, softball_game\",\n \"rounders\",\n \"stickball, stickball_game\",\n \"cricket\",\n \"lacrosse\",\n \"polo\",\n \"pushball\",\n \"soccer, association_football\",\n \"court_game\",\n \"handball\",\n \"racquetball\",\n \"fives\",\n \"squash, squash_racquets, squash_rackets\",\n \"volleyball, volleyball_game\",\n \"jai_alai, pelota\",\n \"badminton\",\n \"battledore, battledore_and_shuttlecock\",\n \"basketball, basketball_game, hoops\",\n \"professional_basketball\",\n \"deck_tennis\",\n \"netball\",\n \"tennis, lawn_tennis\",\n \"professional_tennis\",\n \"singles\",\n \"singles\",\n \"doubles\",\n \"doubles\",\n \"royal_tennis, real_tennis, court_tennis\",\n \"pallone\",\n \"sport, athletics\",\n \"clasp, clench, clutch, clutches, grasp, grip, hold\",\n \"judo\",\n \"team_sport\",\n \"last_supper, lord's_supper\",\n \"seder, passover_supper\",\n \"camping, encampment, bivouacking, tenting\",\n \"pest\",\n \"critter\",\n \"creepy-crawly\",\n \"darter\",\n \"peeper\",\n \"homeotherm, homoiotherm, homotherm\",\n \"poikilotherm, ectotherm\",\n \"range_animal\",\n \"scavenger\",\n \"bottom-feeder, bottom-dweller\",\n \"bottom-feeder\",\n \"work_animal\",\n \"beast_of_burden, jument\",\n \"draft_animal\",\n \"pack_animal, sumpter\",\n \"domestic_animal, domesticated_animal\",\n \"feeder\",\n \"feeder\",\n \"stocker\",\n \"hatchling\",\n \"head\",\n \"migrator\",\n \"molter, moulter\",\n \"pet\",\n \"stayer\",\n \"stunt\",\n \"marine_animal, marine_creature, sea_animal, sea_creature\",\n \"by-catch, bycatch\",\n \"female\",\n \"hen\",\n \"male\",\n \"adult\",\n \"young, offspring\",\n \"orphan\",\n \"young_mammal\",\n \"baby\",\n \"pup, whelp\",\n \"wolf_pup, wolf_cub\",\n \"puppy\",\n \"cub, young_carnivore\",\n \"lion_cub\",\n \"bear_cub\",\n \"tiger_cub\",\n \"kit\",\n \"suckling\",\n \"sire\",\n \"dam\",\n \"thoroughbred, purebred, pureblood\",\n \"giant\",\n \"mutant\",\n \"carnivore\",\n \"herbivore\",\n \"insectivore\",\n \"acrodont\",\n \"pleurodont\",\n \"microorganism, micro-organism\",\n \"monohybrid\",\n \"arbovirus, arborvirus\",\n \"adenovirus\",\n \"arenavirus\",\n \"marburg_virus\",\n \"arenaviridae\",\n \"vesiculovirus\",\n \"reoviridae\",\n \"variola_major, variola_major_virus\",\n \"viroid, virusoid\",\n \"coliphage\",\n \"paramyxovirus\",\n \"poliovirus\",\n \"herpes, herpes_virus\",\n \"herpes_simplex_1, hs1, hsv-1, hsv-i\",\n \"herpes_zoster, herpes_zoster_virus\",\n \"herpes_varicella_zoster, herpes_varicella_zoster_virus\",\n \"cytomegalovirus, cmv\",\n \"varicella_zoster_virus\",\n \"polyoma, polyoma_virus\",\n \"lyssavirus\",\n \"reovirus\",\n \"rotavirus\",\n \"moneran, moneron\",\n \"archaebacteria, archaebacterium, archaeobacteria, archeobacteria\",\n \"bacteroid\",\n \"bacillus_anthracis, anthrax_bacillus\",\n \"yersinia_pestis\",\n \"brucella\",\n \"spirillum, spirilla\",\n \"botulinus, botulinum, clostridium_botulinum\",\n \"clostridium_perfringens\",\n \"cyanobacteria, blue-green_algae\",\n \"trichodesmium\",\n \"nitric_bacteria, nitrobacteria\",\n \"spirillum\",\n \"francisella, genus_francisella\",\n \"gonococcus, neisseria_gonorrhoeae\",\n \"corynebacterium_diphtheriae, c._diphtheriae, klebs-loeffler_bacillus\",\n \"enteric_bacteria, enterobacteria, enterics, entric\",\n \"klebsiella\",\n \"salmonella_typhimurium\",\n \"typhoid_bacillus, salmonella_typhosa, salmonella_typhi\",\n \"nitrate_bacterium, nitric_bacterium\",\n \"nitrite_bacterium, nitrous_bacterium\",\n \"actinomycete\",\n \"streptomyces\",\n \"streptomyces_erythreus\",\n \"streptomyces_griseus\",\n \"tubercle_bacillus, mycobacterium_tuberculosis\",\n \"pus-forming_bacteria\",\n \"streptobacillus\",\n \"myxobacteria, myxobacterium, myxobacter, gliding_bacteria, slime_bacteria\",\n \"staphylococcus, staphylococci, staph\",\n \"diplococcus\",\n \"pneumococcus, diplococcus_pneumoniae\",\n \"streptococcus, streptococci, strep\",\n \"spirochete, spirochaete\",\n \"planktonic_algae\",\n \"zooplankton\",\n \"parasite\",\n \"endoparasite, entoparasite, entozoan, entozoon, endozoan\",\n \"ectoparasite, ectozoan, ectozoon, epizoan, epizoon\",\n \"pathogen\",\n \"commensal\",\n \"myrmecophile\",\n \"protoctist\",\n \"protozoan, protozoon\",\n \"sarcodinian, sarcodine\",\n \"heliozoan\",\n \"endameba\",\n \"ameba, amoeba\",\n \"globigerina\",\n \"testacean\",\n \"arcella\",\n \"difflugia\",\n \"ciliate, ciliated_protozoan, ciliophoran\",\n \"paramecium, paramecia\",\n \"stentor\",\n \"alga, algae\",\n \"arame\",\n \"seagrass\",\n \"golden_algae\",\n \"yellow-green_algae\",\n \"brown_algae\",\n \"kelp\",\n \"fucoid, fucoid_algae\",\n \"fucoid\",\n \"fucus\",\n \"bladderwrack, ascophyllum_nodosum\",\n \"green_algae, chlorophyte\",\n \"pond_scum\",\n \"chlorella\",\n \"stonewort\",\n \"desmid\",\n \"sea_moss\",\n \"eukaryote, eucaryote\",\n \"prokaryote, procaryote\",\n \"zooid\",\n \"leishmania, genus_leishmania\",\n \"zoomastigote, zooflagellate\",\n \"polymastigote\",\n \"costia, costia_necatrix\",\n \"giardia\",\n \"cryptomonad, cryptophyte\",\n \"sporozoan\",\n \"sporozoite\",\n \"trophozoite\",\n \"merozoite\",\n \"coccidium, eimeria\",\n \"gregarine\",\n \"plasmodium, plasmodium_vivax, malaria_parasite\",\n \"leucocytozoan, leucocytozoon\",\n \"microsporidian\",\n \"ostariophysi, order_ostariophysi\",\n \"cypriniform_fish\",\n \"loach\",\n \"cyprinid, cyprinid_fish\",\n \"carp\",\n \"domestic_carp, cyprinus_carpio\",\n \"leather_carp\",\n \"mirror_carp\",\n \"european_bream, abramis_brama\",\n \"tench, tinca_tinca\",\n \"dace, leuciscus_leuciscus\",\n \"chub, leuciscus_cephalus\",\n \"shiner\",\n \"common_shiner, silversides, notropis_cornutus\",\n \"roach, rutilus_rutilus\",\n \"rudd, scardinius_erythrophthalmus\",\n \"minnow, phoxinus_phoxinus\",\n \"gudgeon, gobio_gobio\",\n \"goldfish, carassius_auratus\",\n \"crucian_carp, carassius_carassius, carassius_vulgaris\",\n \"electric_eel, electrophorus_electric\",\n \"catostomid\",\n \"buffalo_fish, buffalofish\",\n \"black_buffalo, ictiobus_niger\",\n \"hog_sucker, hog_molly, hypentelium_nigricans\",\n \"redhorse, redhorse_sucker\",\n \"cyprinodont\",\n \"killifish\",\n \"mummichog, fundulus_heteroclitus\",\n \"striped_killifish, mayfish, may_fish, fundulus_majalis\",\n \"rivulus\",\n \"flagfish, american_flagfish, jordanella_floridae\",\n \"swordtail, helleri, topminnow, xyphophorus_helleri\",\n \"guppy, rainbow_fish, lebistes_reticulatus\",\n \"topminnow, poeciliid_fish, poeciliid, live-bearer\",\n \"mosquitofish, gambusia_affinis\",\n \"platy, platypoecilus_maculatus\",\n \"mollie, molly\",\n \"squirrelfish\",\n \"reef_squirrelfish, holocentrus_coruscus\",\n \"deepwater_squirrelfish, holocentrus_bullisi\",\n \"holocentrus_ascensionis\",\n \"soldierfish, soldier-fish\",\n \"anomalops, flashlight_fish\",\n \"flashlight_fish, photoblepharon_palpebratus\",\n \"john_dory, zeus_faber\",\n \"boarfish, capros_aper\",\n \"boarfish\",\n \"cornetfish\",\n \"stickleback, prickleback\",\n \"three-spined_stickleback, gasterosteus_aculeatus\",\n \"ten-spined_stickleback, gasterosteus_pungitius\",\n \"pipefish, needlefish\",\n \"dwarf_pipefish, syngnathus_hildebrandi\",\n \"deepwater_pipefish, cosmocampus_profundus\",\n \"seahorse, sea_horse\",\n \"snipefish, bellows_fish\",\n \"shrimpfish, shrimp-fish\",\n \"trumpetfish, aulostomus_maculatus\",\n \"pellicle\",\n \"embryo, conceptus, fertilized_egg\",\n \"fetus, foetus\",\n \"abortus\",\n \"spawn\",\n \"blastula, blastosphere\",\n \"blastocyst, blastodermic_vessicle\",\n \"gastrula\",\n \"morula\",\n \"yolk, vitellus\",\n \"chordate\",\n \"cephalochordate\",\n \"lancelet, amphioxus\",\n \"tunicate, urochordate, urochord\",\n \"ascidian\",\n \"sea_squirt\",\n \"salp, salpa\",\n \"doliolum\",\n \"larvacean\",\n \"appendicularia\",\n \"ascidian_tadpole\",\n \"vertebrate, craniate\",\n \"amniota\",\n \"amniote\",\n \"aquatic_vertebrate\",\n \"jawless_vertebrate, jawless_fish, agnathan\",\n \"ostracoderm\",\n \"heterostracan\",\n \"anaspid\",\n \"conodont\",\n \"cyclostome\",\n \"lamprey, lamprey_eel, lamper_eel\",\n \"sea_lamprey, petromyzon_marinus\",\n \"hagfish, hag, slime_eels\",\n \"myxine_glutinosa\",\n \"eptatretus\",\n \"gnathostome\",\n \"placoderm\",\n \"cartilaginous_fish, chondrichthian\",\n \"holocephalan, holocephalian\",\n \"chimaera\",\n \"rabbitfish, chimaera_monstrosa\",\n \"elasmobranch, selachian\",\n \"shark\",\n \"cow_shark, six-gilled_shark, hexanchus_griseus\",\n \"mackerel_shark\",\n \"porbeagle, lamna_nasus\",\n \"mako, mako_shark\",\n \"shortfin_mako, isurus_oxyrhincus\",\n \"longfin_mako, isurus_paucus\",\n \"bonito_shark, blue_pointed, isurus_glaucus\",\n \"great_white_shark, white_shark, man-eater, man-eating_shark, carcharodon_carcharias\",\n \"basking_shark, cetorhinus_maximus\",\n \"thresher, thrasher, thresher_shark, fox_shark, alopius_vulpinus\",\n \"carpet_shark, orectolobus_barbatus\",\n \"nurse_shark, ginglymostoma_cirratum\",\n \"sand_tiger, sand_shark, carcharias_taurus, odontaspis_taurus\",\n \"whale_shark, rhincodon_typus\",\n \"requiem_shark\",\n \"bull_shark, cub_shark, carcharhinus_leucas\",\n \"sandbar_shark, carcharhinus_plumbeus\",\n \"blacktip_shark, sandbar_shark, carcharhinus_limbatus\",\n \"whitetip_shark, oceanic_whitetip_shark, white-tipped_shark, carcharinus_longimanus\",\n \"dusky_shark, carcharhinus_obscurus\",\n \"lemon_shark, negaprion_brevirostris\",\n \"blue_shark, great_blue_shark, prionace_glauca\",\n \"tiger_shark, galeocerdo_cuvieri\",\n \"soupfin_shark, soupfin, soup-fin, galeorhinus_zyopterus\",\n \"dogfish\",\n \"smooth_dogfish\",\n \"smoothhound, smoothhound_shark, mustelus_mustelus\",\n \"american_smooth_dogfish, mustelus_canis\",\n \"florida_smoothhound, mustelus_norrisi\",\n \"whitetip_shark, reef_whitetip_shark, triaenodon_obseus\",\n \"spiny_dogfish\",\n \"atlantic_spiny_dogfish, squalus_acanthias\",\n \"pacific_spiny_dogfish, squalus_suckleyi\",\n \"hammerhead, hammerhead_shark\",\n \"smooth_hammerhead, sphyrna_zygaena\",\n \"smalleye_hammerhead, sphyrna_tudes\",\n \"shovelhead, bonnethead, bonnet_shark, sphyrna_tiburo\",\n \"angel_shark, angelfish, squatina_squatina, monkfish\",\n \"ray\",\n \"electric_ray, crampfish, numbfish, torpedo\",\n \"sawfish\",\n \"smalltooth_sawfish, pristis_pectinatus\",\n \"guitarfish\",\n \"stingray\",\n \"roughtail_stingray, dasyatis_centroura\",\n \"butterfly_ray\",\n \"eagle_ray\",\n \"spotted_eagle_ray, spotted_ray, aetobatus_narinari\",\n \"cownose_ray, cow-nosed_ray, rhinoptera_bonasus\",\n \"manta, manta_ray, devilfish\",\n \"atlantic_manta, manta_birostris\",\n \"devil_ray, mobula_hypostoma\",\n \"skate\",\n \"grey_skate, gray_skate, raja_batis\",\n \"little_skate, raja_erinacea\",\n \"thorny_skate, raja_radiata\",\n \"barndoor_skate, raja_laevis\",\n \"bird\",\n \"dickeybird, dickey-bird, dickybird, dicky-bird\",\n \"fledgling, fledgeling\",\n \"nestling, baby_bird\",\n \"cock\",\n \"gamecock, fighting_cock\",\n \"hen\",\n \"nester\",\n \"night_bird\",\n \"night_raven\",\n \"bird_of_passage\",\n \"archaeopteryx, archeopteryx, archaeopteryx_lithographica\",\n \"archaeornis\",\n \"ratite, ratite_bird, flightless_bird\",\n \"carinate, carinate_bird, flying_bird\",\n \"ostrich, struthio_camelus\",\n \"cassowary\",\n \"emu, dromaius_novaehollandiae, emu_novaehollandiae\",\n \"kiwi, apteryx\",\n \"rhea, rhea_americana\",\n \"rhea, nandu, pterocnemia_pennata\",\n \"elephant_bird, aepyornis\",\n \"moa\",\n \"passerine, passeriform_bird\",\n \"nonpasserine_bird\",\n \"oscine, oscine_bird\",\n \"songbird, songster\",\n \"honey_eater, honeysucker\",\n \"accentor\",\n \"hedge_sparrow, sparrow, dunnock, prunella_modularis\",\n \"lark\",\n \"skylark, alauda_arvensis\",\n \"wagtail\",\n \"pipit, titlark, lark\",\n \"meadow_pipit, anthus_pratensis\",\n \"finch\",\n \"chaffinch, fringilla_coelebs\",\n \"brambling, fringilla_montifringilla\",\n \"goldfinch, carduelis_carduelis\",\n \"linnet, lintwhite, carduelis_cannabina\",\n \"siskin, carduelis_spinus\",\n \"red_siskin, carduelis_cucullata\",\n \"redpoll, carduelis_flammea\",\n \"redpoll, carduelis_hornemanni\",\n \"new_world_goldfinch, goldfinch, yellowbird, spinus_tristis\",\n \"pine_siskin, pine_finch, spinus_pinus\",\n \"house_finch, linnet, carpodacus_mexicanus\",\n \"purple_finch, carpodacus_purpureus\",\n \"canary, canary_bird\",\n \"common_canary, serinus_canaria\",\n \"serin\",\n \"crossbill, loxia_curvirostra\",\n \"bullfinch, pyrrhula_pyrrhula\",\n \"junco, snowbird\",\n \"dark-eyed_junco, slate-colored_junco, junco_hyemalis\",\n \"new_world_sparrow\",\n \"vesper_sparrow, grass_finch, pooecetes_gramineus\",\n \"white-throated_sparrow, whitethroat, zonotrichia_albicollis\",\n \"white-crowned_sparrow, zonotrichia_leucophrys\",\n \"chipping_sparrow, spizella_passerina\",\n \"field_sparrow, spizella_pusilla\",\n \"tree_sparrow, spizella_arborea\",\n \"song_sparrow, melospiza_melodia\",\n \"swamp_sparrow, melospiza_georgiana\",\n \"bunting\",\n \"indigo_bunting, indigo_finch, indigo_bird, passerina_cyanea\",\n \"ortolan, ortolan_bunting, emberiza_hortulana\",\n \"reed_bunting, emberiza_schoeniclus\",\n \"yellowhammer, yellow_bunting, emberiza_citrinella\",\n \"yellow-breasted_bunting, emberiza_aureola\",\n \"snow_bunting, snowbird, snowflake, plectrophenax_nivalis\",\n \"honeycreeper\",\n \"banana_quit\",\n \"sparrow, true_sparrow\",\n \"english_sparrow, house_sparrow, passer_domesticus\",\n \"tree_sparrow, passer_montanus\",\n \"grosbeak, grossbeak\",\n \"evening_grosbeak, hesperiphona_vespertina\",\n \"hawfinch, coccothraustes_coccothraustes\",\n \"pine_grosbeak, pinicola_enucleator\",\n \"cardinal, cardinal_grosbeak, richmondena_cardinalis, cardinalis_cardinalis, redbird\",\n \"pyrrhuloxia, pyrrhuloxia_sinuata\",\n \"towhee\",\n \"chewink, cheewink, pipilo_erythrophthalmus\",\n \"green-tailed_towhee, chlorura_chlorura\",\n \"weaver, weaverbird, weaver_finch\",\n \"baya, ploceus_philippinus\",\n \"whydah, whidah, widow_bird\",\n \"java_sparrow, java_finch, ricebird, padda_oryzivora\",\n \"avadavat, amadavat\",\n \"grassfinch, grass_finch\",\n \"zebra_finch, poephila_castanotis\",\n \"honeycreeper, hawaiian_honeycreeper\",\n \"lyrebird\",\n \"scrubbird, scrub-bird, scrub_bird\",\n \"broadbill\",\n \"tyrannid\",\n \"new_world_flycatcher, flycatcher, tyrant_flycatcher, tyrant_bird\",\n \"kingbird, tyrannus_tyrannus\",\n \"arkansas_kingbird, western_kingbird\",\n \"cassin's_kingbird, tyrannus_vociferans\",\n \"eastern_kingbird\",\n \"grey_kingbird, gray_kingbird, petchary, tyrannus_domenicensis_domenicensis\",\n \"pewee, peewee, peewit, pewit, wood_pewee, contopus_virens\",\n \"western_wood_pewee, contopus_sordidulus\",\n \"phoebe, phoebe_bird, sayornis_phoebe\",\n \"vermillion_flycatcher, firebird, pyrocephalus_rubinus_mexicanus\",\n \"cotinga, chatterer\",\n \"cock_of_the_rock, rupicola_rupicola\",\n \"cock_of_the_rock, rupicola_peruviana\",\n \"manakin\",\n \"bellbird\",\n \"umbrella_bird, cephalopterus_ornatus\",\n \"ovenbird\",\n \"antbird, ant_bird\",\n \"ant_thrush\",\n \"ant_shrike\",\n \"spotted_antbird, hylophylax_naevioides\",\n \"woodhewer, woodcreeper, wood-creeper, tree_creeper\",\n \"pitta\",\n \"scissortail, scissortailed_flycatcher, muscivora-forficata\",\n \"old_world_flycatcher, true_flycatcher, flycatcher\",\n \"spotted_flycatcher, muscicapa_striata, muscicapa_grisola\",\n \"thickhead, whistler\",\n \"thrush\",\n \"missel_thrush, mistle_thrush, mistletoe_thrush, turdus_viscivorus\",\n \"song_thrush, mavis, throstle, turdus_philomelos\",\n \"fieldfare, snowbird, turdus_pilaris\",\n \"redwing, turdus_iliacus\",\n \"blackbird, merl, merle, ouzel, ousel, european_blackbird, turdus_merula\",\n \"ring_ouzel, ring_blackbird, ring_thrush, turdus_torquatus\",\n \"robin, american_robin, turdus_migratorius\",\n \"clay-colored_robin, turdus_greyi\",\n \"hermit_thrush, hylocichla_guttata\",\n \"veery, wilson's_thrush, hylocichla_fuscescens\",\n \"wood_thrush, hylocichla_mustelina\",\n \"nightingale, luscinia_megarhynchos\",\n \"thrush_nightingale, luscinia_luscinia\",\n \"bulbul\",\n \"old_world_chat, chat\",\n \"stonechat, saxicola_torquata\",\n \"whinchat, saxicola_rubetra\",\n \"solitaire\",\n \"redstart, redtail\",\n \"wheatear\",\n \"bluebird\",\n \"robin, redbreast, robin_redbreast, old_world_robin, erithacus_rubecola\",\n \"bluethroat, erithacus_svecicus\",\n \"warbler\",\n \"gnatcatcher\",\n \"kinglet\",\n \"goldcrest, golden-crested_kinglet, regulus_regulus\",\n \"gold-crowned_kinglet, regulus_satrata\",\n \"ruby-crowned_kinglet, ruby-crowned_wren, regulus_calendula\",\n \"old_world_warbler, true_warbler\",\n \"blackcap, silvia_atricapilla\",\n \"greater_whitethroat, whitethroat, sylvia_communis\",\n \"lesser_whitethroat, whitethroat, sylvia_curruca\",\n \"wood_warbler, phylloscopus_sibilatrix\",\n \"sedge_warbler, sedge_bird, sedge_wren, reedbird, acrocephalus_schoenobaenus\",\n \"wren_warbler\",\n \"tailorbird, orthotomus_sutorius\",\n \"babbler, cackler\",\n \"new_world_warbler, wood_warbler\",\n \"parula_warbler, northern_parula, parula_americana\",\n \"wilson's_warbler, wilson's_blackcap, wilsonia_pusilla\",\n \"flycatching_warbler\",\n \"american_redstart, redstart, setophaga_ruticilla\",\n \"cape_may_warbler, dendroica_tigrina\",\n \"yellow_warbler, golden_warbler, yellowbird, dendroica_petechia\",\n \"blackburn, blackburnian_warbler, dendroica_fusca\",\n \"audubon's_warbler, audubon_warbler, dendroica_auduboni\",\n \"myrtle_warbler, myrtle_bird, dendroica_coronata\",\n \"blackpoll, dendroica_striate\",\n \"new_world_chat, chat\",\n \"yellow-breasted_chat, icteria_virens\",\n \"ovenbird, seiurus_aurocapillus\",\n \"water_thrush\",\n \"yellowthroat\",\n \"common_yellowthroat, maryland_yellowthroat, geothlypis_trichas\",\n \"riflebird, ptloris_paradisea\",\n \"new_world_oriole, american_oriole, oriole\",\n \"northern_oriole, icterus_galbula\",\n \"baltimore_oriole, baltimore_bird, hangbird, firebird, icterus_galbula_galbula\",\n \"bullock's_oriole, icterus_galbula_bullockii\",\n \"orchard_oriole, icterus_spurius\",\n \"meadowlark, lark\",\n \"eastern_meadowlark, sturnella_magna\",\n \"western_meadowlark, sturnella_neglecta\",\n \"cacique, cazique\",\n \"bobolink, ricebird, reedbird, dolichonyx_oryzivorus\",\n \"new_world_blackbird, blackbird\",\n \"grackle, crow_blackbird\",\n \"purple_grackle, quiscalus_quiscula\",\n \"rusty_blackbird, rusty_grackle, euphagus_carilonus\",\n \"cowbird\",\n \"red-winged_blackbird, redwing, agelaius_phoeniceus\",\n \"old_world_oriole, oriole\",\n \"golden_oriole, oriolus_oriolus\",\n \"fig-bird\",\n \"starling\",\n \"common_starling, sturnus_vulgaris\",\n \"rose-colored_starling, rose-colored_pastor, pastor_sturnus, pastor_roseus\",\n \"myna, mynah, mina, minah, myna_bird, mynah_bird\",\n \"crested_myna, acridotheres_tristis\",\n \"hill_myna, indian_grackle, grackle, gracula_religiosa\",\n \"corvine_bird\",\n \"crow\",\n \"american_crow, corvus_brachyrhyncos\",\n \"raven, corvus_corax\",\n \"rook, corvus_frugilegus\",\n \"jackdaw, daw, corvus_monedula\",\n \"chough\",\n \"jay\",\n \"old_world_jay\",\n \"common_european_jay, garullus_garullus\",\n \"new_world_jay\",\n \"blue_jay, jaybird, cyanocitta_cristata\",\n \"canada_jay, grey_jay, gray_jay, camp_robber, whisker_jack, perisoreus_canadensis\",\n \"rocky_mountain_jay, perisoreus_canadensis_capitalis\",\n \"nutcracker\",\n \"common_nutcracker, nucifraga_caryocatactes\",\n \"clark's_nutcracker, nucifraga_columbiana\",\n \"magpie\",\n \"european_magpie, pica_pica\",\n \"american_magpie, pica_pica_hudsonia\",\n \"australian_magpie\",\n \"butcherbird\",\n \"currawong, bell_magpie\",\n \"piping_crow, piping_crow-shrike, gymnorhina_tibicen\",\n \"wren, jenny_wren\",\n \"winter_wren, troglodytes_troglodytes\",\n \"house_wren, troglodytes_aedon\",\n \"marsh_wren\",\n \"long-billed_marsh_wren, cistothorus_palustris\",\n \"sedge_wren, short-billed_marsh_wren, cistothorus_platensis\",\n \"rock_wren, salpinctes_obsoletus\",\n \"carolina_wren, thryothorus_ludovicianus\",\n \"cactus_wren\",\n \"mockingbird, mocker, mimus_polyglotktos\",\n \"blue_mockingbird, melanotis_caerulescens\",\n \"catbird, grey_catbird, gray_catbird, dumetella_carolinensis\",\n \"thrasher, mocking_thrush\",\n \"brown_thrasher, brown_thrush, toxostoma_rufums\",\n \"new_zealand_wren\",\n \"rock_wren, xenicus_gilviventris\",\n \"rifleman_bird, acanthisitta_chloris\",\n \"creeper, tree_creeper\",\n \"brown_creeper, american_creeper, certhia_americana\",\n \"european_creeper, certhia_familiaris\",\n \"wall_creeper, tichodrome, tichodroma_muriaria\",\n \"european_nuthatch, sitta_europaea\",\n \"red-breasted_nuthatch, sitta_canadensis\",\n \"white-breasted_nuthatch, sitta_carolinensis\",\n \"titmouse, tit\",\n \"chickadee\",\n \"black-capped_chickadee, blackcap, parus_atricapillus\",\n \"tufted_titmouse, parus_bicolor\",\n \"carolina_chickadee, parus_carolinensis\",\n \"blue_tit, tomtit, parus_caeruleus\",\n \"bushtit, bush_tit\",\n \"wren-tit, chamaea_fasciata\",\n \"verdin, auriparus_flaviceps\",\n \"fairy_bluebird, bluebird\",\n \"swallow\",\n \"barn_swallow, chimney_swallow, hirundo_rustica\",\n \"cliff_swallow, hirundo_pyrrhonota\",\n \"tree_swallow, tree_martin, hirundo_nigricans\",\n \"white-bellied_swallow, tree_swallow, iridoprocne_bicolor\",\n \"martin\",\n \"house_martin, delichon_urbica\",\n \"bank_martin, bank_swallow, sand_martin, riparia_riparia\",\n \"purple_martin, progne_subis\",\n \"wood_swallow, swallow_shrike\",\n \"tanager\",\n \"scarlet_tanager, piranga_olivacea, redbird, firebird\",\n \"western_tanager, piranga_ludoviciana\",\n \"summer_tanager, summer_redbird, piranga_rubra\",\n \"hepatic_tanager, piranga_flava_hepatica\",\n \"shrike\",\n \"butcherbird\",\n \"european_shrike, lanius_excubitor\",\n \"northern_shrike, lanius_borealis\",\n \"white-rumped_shrike, lanius_ludovicianus_excubitorides\",\n \"loggerhead_shrike, lanius_lucovicianus\",\n \"migrant_shrike, lanius_ludovicianus_migrans\",\n \"bush_shrike\",\n \"black-fronted_bush_shrike, chlorophoneus_nigrifrons\",\n \"bowerbird, catbird\",\n \"satin_bowerbird, satin_bird, ptilonorhynchus_violaceus\",\n \"great_bowerbird, chlamydera_nuchalis\",\n \"water_ouzel, dipper\",\n \"european_water_ouzel, cinclus_aquaticus\",\n \"american_water_ouzel, cinclus_mexicanus\",\n \"vireo\",\n \"red-eyed_vireo, vireo_olivaceous\",\n \"solitary_vireo, vireo_solitarius\",\n \"blue-headed_vireo, vireo_solitarius_solitarius\",\n \"waxwing\",\n \"cedar_waxwing, cedarbird, bombycilla_cedrorun\",\n \"bohemian_waxwing, bombycilla_garrulus\",\n \"bird_of_prey, raptor, raptorial_bird\",\n \"accipitriformes, order_accipitriformes\",\n \"hawk\",\n \"eyas\",\n \"tiercel, tercel, tercelet\",\n \"goshawk, accipiter_gentilis\",\n \"sparrow_hawk, accipiter_nisus\",\n \"cooper's_hawk, blue_darter, accipiter_cooperii\",\n \"chicken_hawk, hen_hawk\",\n \"buteonine\",\n \"redtail, red-tailed_hawk, buteo_jamaicensis\",\n \"rough-legged_hawk, roughleg, buteo_lagopus\",\n \"red-shouldered_hawk, buteo_lineatus\",\n \"buzzard, buteo_buteo\",\n \"honey_buzzard, pernis_apivorus\",\n \"kite\",\n \"black_kite, milvus_migrans\",\n \"swallow-tailed_kite, swallow-tailed_hawk, elanoides_forficatus\",\n \"white-tailed_kite, elanus_leucurus\",\n \"harrier\",\n \"marsh_harrier, circus_aeruginosus\",\n \"montagu's_harrier, circus_pygargus\",\n \"marsh_hawk, northern_harrier, hen_harrier, circus_cyaneus\",\n \"harrier_eagle, short-toed_eagle\",\n \"falcon\",\n \"peregrine, peregrine_falcon, falco_peregrinus\",\n \"falcon-gentle, falcon-gentil\",\n \"gyrfalcon, gerfalcon, falco_rusticolus\",\n \"kestrel, falco_tinnunculus\",\n \"sparrow_hawk, american_kestrel, kestrel, falco_sparverius\",\n \"pigeon_hawk, merlin, falco_columbarius\",\n \"hobby, falco_subbuteo\",\n \"caracara\",\n \"audubon's_caracara, polyborus_cheriway_audubonii\",\n \"carancha, polyborus_plancus\",\n \"eagle, bird_of_jove\",\n \"young_bird\",\n \"eaglet\",\n \"harpy, harpy_eagle, harpia_harpyja\",\n \"golden_eagle, aquila_chrysaetos\",\n \"tawny_eagle, aquila_rapax\",\n \"bald_eagle, american_eagle, haliaeetus_leucocephalus\",\n \"sea_eagle\",\n \"kamchatkan_sea_eagle, stellar's_sea_eagle, haliaeetus_pelagicus\",\n \"ern, erne, grey_sea_eagle, gray_sea_eagle, european_sea_eagle, white-tailed_sea_eagle, haliatus_albicilla\",\n \"fishing_eagle, haliaeetus_leucorhyphus\",\n \"osprey, fish_hawk, fish_eagle, sea_eagle, pandion_haliaetus\",\n \"vulture\",\n \"aegypiidae, family_aegypiidae\",\n \"old_world_vulture\",\n \"griffon_vulture, griffon, gyps_fulvus\",\n \"bearded_vulture, lammergeier, lammergeyer, gypaetus_barbatus\",\n \"egyptian_vulture, pharaoh's_chicken, neophron_percnopterus\",\n \"black_vulture, aegypius_monachus\",\n \"secretary_bird, sagittarius_serpentarius\",\n \"new_world_vulture, cathartid\",\n \"buzzard, turkey_buzzard, turkey_vulture, cathartes_aura\",\n \"condor\",\n \"andean_condor, vultur_gryphus\",\n \"california_condor, gymnogyps_californianus\",\n \"black_vulture, carrion_crow, coragyps_atratus\",\n \"king_vulture, sarcorhamphus_papa\",\n \"owl, bird_of_minerva, bird_of_night, hooter\",\n \"owlet\",\n \"little_owl, athene_noctua\",\n \"horned_owl\",\n \"great_horned_owl, bubo_virginianus\",\n \"great_grey_owl, great_gray_owl, strix_nebulosa\",\n \"tawny_owl, strix_aluco\",\n \"barred_owl, strix_varia\",\n \"screech_owl, otus_asio\",\n \"screech_owl\",\n \"scops_owl\",\n \"spotted_owl, strix_occidentalis\",\n \"old_world_scops_owl, otus_scops\",\n \"oriental_scops_owl, otus_sunia\",\n \"hoot_owl\",\n \"hawk_owl, surnia_ulula\",\n \"long-eared_owl, asio_otus\",\n \"laughing_owl, laughing_jackass, sceloglaux_albifacies\",\n \"barn_owl, tyto_alba\",\n \"amphibian\",\n \"ichyostega\",\n \"urodele, caudate\",\n \"salamander\",\n \"european_fire_salamander, salamandra_salamandra\",\n \"spotted_salamander, fire_salamander, salamandra_maculosa\",\n \"alpine_salamander, salamandra_atra\",\n \"newt, triton\",\n \"common_newt, triturus_vulgaris\",\n \"red_eft, notophthalmus_viridescens\",\n \"pacific_newt\",\n \"rough-skinned_newt, taricha_granulosa\",\n \"california_newt, taricha_torosa\",\n \"eft\",\n \"ambystomid, ambystomid_salamander\",\n \"mole_salamander, ambystoma_talpoideum\",\n \"spotted_salamander, ambystoma_maculatum\",\n \"tiger_salamander, ambystoma_tigrinum\",\n \"axolotl, mud_puppy, ambystoma_mexicanum\",\n \"waterdog\",\n \"hellbender, mud_puppy, cryptobranchus_alleganiensis\",\n \"giant_salamander, megalobatrachus_maximus\",\n \"olm, proteus_anguinus\",\n \"mud_puppy, necturus_maculosus\",\n \"dicamptodon, dicamptodontid\",\n \"pacific_giant_salamander, dicamptodon_ensatus\",\n \"olympic_salamander, rhyacotriton_olympicus\",\n \"lungless_salamander, plethodont\",\n \"eastern_red-backed_salamander, plethodon_cinereus\",\n \"western_red-backed_salamander, plethodon_vehiculum\",\n \"dusky_salamander\",\n \"climbing_salamander\",\n \"arboreal_salamander, aneides_lugubris\",\n \"slender_salamander, worm_salamander\",\n \"web-toed_salamander\",\n \"shasta_salamander, hydromantes_shastae\",\n \"limestone_salamander, hydromantes_brunus\",\n \"amphiuma, congo_snake, congo_eel, blind_eel\",\n \"siren\",\n \"frog, toad, toad_frog, anuran, batrachian, salientian\",\n \"true_frog, ranid\",\n \"wood-frog, wood_frog, rana_sylvatica\",\n \"leopard_frog, spring_frog, rana_pipiens\",\n \"bullfrog, rana_catesbeiana\",\n \"green_frog, spring_frog, rana_clamitans\",\n \"cascades_frog, rana_cascadae\",\n \"goliath_frog, rana_goliath\",\n \"pickerel_frog, rana_palustris\",\n \"tarahumara_frog, rana_tarahumarae\",\n \"grass_frog, rana_temporaria\",\n \"leptodactylid_frog, leptodactylid\",\n \"robber_frog\",\n \"barking_frog, robber_frog, hylactophryne_augusti\",\n \"crapaud, south_american_bullfrog, leptodactylus_pentadactylus\",\n \"tree_frog, tree-frog\",\n \"tailed_frog, bell_toad, ribbed_toad, tailed_toad, ascaphus_trui\",\n \"liopelma_hamiltoni\",\n \"true_toad\",\n \"bufo\",\n \"agua, agua_toad, bufo_marinus\",\n \"european_toad, bufo_bufo\",\n \"natterjack, bufo_calamita\",\n \"american_toad, bufo_americanus\",\n \"eurasian_green_toad, bufo_viridis\",\n \"american_green_toad, bufo_debilis\",\n \"yosemite_toad, bufo_canorus\",\n \"texas_toad, bufo_speciosus\",\n \"southwestern_toad, bufo_microscaphus\",\n \"western_toad, bufo_boreas\",\n \"obstetrical_toad, midwife_toad, alytes_obstetricans\",\n \"midwife_toad, alytes_cisternasi\",\n \"fire-bellied_toad, bombina_bombina\",\n \"spadefoot, spadefoot_toad\",\n \"western_spadefoot, scaphiopus_hammondii\",\n \"southern_spadefoot, scaphiopus_multiplicatus\",\n \"plains_spadefoot, scaphiopus_bombifrons\",\n \"tree_toad, tree_frog, tree-frog\",\n \"spring_peeper, hyla_crucifer\",\n \"pacific_tree_toad, hyla_regilla\",\n \"canyon_treefrog, hyla_arenicolor\",\n \"chameleon_tree_frog\",\n \"cricket_frog\",\n \"northern_cricket_frog, acris_crepitans\",\n \"eastern_cricket_frog, acris_gryllus\",\n \"chorus_frog\",\n \"lowland_burrowing_treefrog, northern_casque-headed_frog, pternohyla_fodiens\",\n \"western_narrow-mouthed_toad, gastrophryne_olivacea\",\n \"eastern_narrow-mouthed_toad, gastrophryne_carolinensis\",\n \"sheep_frog\",\n \"tongueless_frog\",\n \"surinam_toad, pipa_pipa, pipa_americana\",\n \"african_clawed_frog, xenopus_laevis\",\n \"south_american_poison_toad\",\n \"caecilian, blindworm\",\n \"reptile, reptilian\",\n \"anapsid, anapsid_reptile\",\n \"diapsid, diapsid_reptile\",\n \"diapsida, subclass_diapsida\",\n \"chelonian, chelonian_reptile\",\n \"turtle\",\n \"sea_turtle, marine_turtle\",\n \"green_turtle, chelonia_mydas\",\n \"loggerhead, loggerhead_turtle, caretta_caretta\",\n \"ridley\",\n \"atlantic_ridley, bastard_ridley, bastard_turtle, lepidochelys_kempii\",\n \"pacific_ridley, olive_ridley, lepidochelys_olivacea\",\n \"hawksbill_turtle, hawksbill, hawkbill, tortoiseshell_turtle, eretmochelys_imbricata\",\n \"leatherback_turtle, leatherback, leathery_turtle, dermochelys_coriacea\",\n \"snapping_turtle\",\n \"common_snapping_turtle, snapper, chelydra_serpentina\",\n \"alligator_snapping_turtle, alligator_snapper, macroclemys_temmincki\",\n \"mud_turtle\",\n \"musk_turtle, stinkpot\",\n \"terrapin\",\n \"diamondback_terrapin, malaclemys_centrata\",\n \"red-bellied_terrapin, red-bellied_turtle, redbelly, pseudemys_rubriventris\",\n \"slider, yellow-bellied_terrapin, pseudemys_scripta\",\n \"cooter, river_cooter, pseudemys_concinna\",\n \"box_turtle, box_tortoise\",\n \"western_box_turtle, terrapene_ornata\",\n \"painted_turtle, painted_terrapin, painted_tortoise, chrysemys_picta\",\n \"tortoise\",\n \"european_tortoise, testudo_graeca\",\n \"giant_tortoise\",\n \"gopher_tortoise, gopher_turtle, gopher, gopherus_polypemus\",\n \"desert_tortoise, gopherus_agassizii\",\n \"texas_tortoise\",\n \"soft-shelled_turtle, pancake_turtle\",\n \"spiny_softshell, trionyx_spiniferus\",\n \"smooth_softshell, trionyx_muticus\",\n \"tuatara, sphenodon_punctatum\",\n \"saurian\",\n \"lizard\",\n \"gecko\",\n \"flying_gecko, fringed_gecko, ptychozoon_homalocephalum\",\n \"banded_gecko\",\n \"iguanid, iguanid_lizard\",\n \"common_iguana, iguana, iguana_iguana\",\n \"marine_iguana, amblyrhynchus_cristatus\",\n \"desert_iguana, dipsosaurus_dorsalis\",\n \"chuckwalla, sauromalus_obesus\",\n \"zebra-tailed_lizard, gridiron-tailed_lizard, callisaurus_draconoides\",\n \"fringe-toed_lizard, uma_notata\",\n \"earless_lizard\",\n \"collared_lizard\",\n \"leopard_lizard\",\n \"spiny_lizard\",\n \"fence_lizard\",\n \"western_fence_lizard, swift, blue-belly, sceloporus_occidentalis\",\n \"eastern_fence_lizard, pine_lizard, sceloporus_undulatus\",\n \"sagebrush_lizard, sceloporus_graciosus\",\n \"side-blotched_lizard, sand_lizard, uta_stansburiana\",\n \"tree_lizard, urosaurus_ornatus\",\n \"horned_lizard, horned_toad, horny_frog\",\n \"texas_horned_lizard, phrynosoma_cornutum\",\n \"basilisk\",\n \"american_chameleon, anole, anolis_carolinensis\",\n \"worm_lizard\",\n \"night_lizard\",\n \"skink, scincid, scincid_lizard\",\n \"western_skink, eumeces_skiltonianus\",\n \"mountain_skink, eumeces_callicephalus\",\n \"teiid_lizard, teiid\",\n \"whiptail, whiptail_lizard\",\n \"racerunner, race_runner, six-lined_racerunner, cnemidophorus_sexlineatus\",\n \"plateau_striped_whiptail, cnemidophorus_velox\",\n \"chihuahuan_spotted_whiptail, cnemidophorus_exsanguis\",\n \"western_whiptail, cnemidophorus_tigris\",\n \"checkered_whiptail, cnemidophorus_tesselatus\",\n \"teju\",\n \"caiman_lizard\",\n \"agamid, agamid_lizard\",\n \"agama\",\n \"frilled_lizard, chlamydosaurus_kingi\",\n \"moloch\",\n \"mountain_devil, spiny_lizard, moloch_horridus\",\n \"anguid_lizard\",\n \"alligator_lizard\",\n \"blindworm, slowworm, anguis_fragilis\",\n \"glass_lizard, glass_snake, joint_snake\",\n \"legless_lizard\",\n \"lanthanotus_borneensis\",\n \"venomous_lizard\",\n \"gila_monster, heloderma_suspectum\",\n \"beaded_lizard, mexican_beaded_lizard, heloderma_horridum\",\n \"lacertid_lizard, lacertid\",\n \"sand_lizard, lacerta_agilis\",\n \"green_lizard, lacerta_viridis\",\n \"chameleon, chamaeleon\",\n \"african_chameleon, chamaeleo_chamaeleon\",\n \"horned_chameleon, chamaeleo_oweni\",\n \"monitor, monitor_lizard, varan\",\n \"african_monitor, varanus_niloticus\",\n \"komodo_dragon, komodo_lizard, dragon_lizard, giant_lizard, varanus_komodoensis\",\n \"crocodilian_reptile, crocodilian\",\n \"crocodile\",\n \"african_crocodile, nile_crocodile, crocodylus_niloticus\",\n \"asian_crocodile, crocodylus_porosus\",\n \"morlett's_crocodile\",\n \"false_gavial, tomistoma_schlegeli\",\n \"alligator, gator\",\n \"american_alligator, alligator_mississipiensis\",\n \"chinese_alligator, alligator_sinensis\",\n \"caiman, cayman\",\n \"spectacled_caiman, caiman_sclerops\",\n \"gavial, gavialis_gangeticus\",\n \"armored_dinosaur\",\n \"stegosaur, stegosaurus, stegosaur_stenops\",\n \"ankylosaur, ankylosaurus\",\n \"edmontonia\",\n \"bone-headed_dinosaur\",\n \"pachycephalosaur, pachycephalosaurus\",\n \"ceratopsian, horned_dinosaur\",\n \"protoceratops\",\n \"triceratops\",\n \"styracosaur, styracosaurus\",\n \"psittacosaur, psittacosaurus\",\n \"ornithopod, ornithopod_dinosaur\",\n \"hadrosaur, hadrosaurus, duck-billed_dinosaur\",\n \"trachodon, trachodont\",\n \"saurischian, saurischian_dinosaur\",\n \"sauropod, sauropod_dinosaur\",\n \"apatosaur, apatosaurus, brontosaur, brontosaurus, thunder_lizard, apatosaurus_excelsus\",\n \"barosaur, barosaurus\",\n \"diplodocus\",\n \"argentinosaur\",\n \"theropod, theropod_dinosaur, bird-footed_dinosaur\",\n \"ceratosaur, ceratosaurus\",\n \"coelophysis\",\n \"tyrannosaur, tyrannosaurus, tyrannosaurus_rex\",\n \"allosaur, allosaurus\",\n \"ornithomimid\",\n \"maniraptor\",\n \"oviraptorid\",\n \"velociraptor\",\n \"deinonychus\",\n \"utahraptor, superslasher\",\n \"synapsid, synapsid_reptile\",\n \"dicynodont\",\n \"pelycosaur\",\n \"dimetrodon\",\n \"pterosaur, flying_reptile\",\n \"pterodactyl\",\n \"ichthyosaur\",\n \"ichthyosaurus\",\n \"stenopterygius, stenopterygius_quadrisicissus\",\n \"plesiosaur, plesiosaurus\",\n \"nothosaur\",\n \"snake, serpent, ophidian\",\n \"colubrid_snake, colubrid\",\n \"hoop_snake\",\n \"thunder_snake, worm_snake, carphophis_amoenus\",\n \"ringneck_snake, ring-necked_snake, ring_snake\",\n \"hognose_snake, puff_adder, sand_viper\",\n \"leaf-nosed_snake\",\n \"green_snake, grass_snake\",\n \"smooth_green_snake, opheodrys_vernalis\",\n \"rough_green_snake, opheodrys_aestivus\",\n \"green_snake\",\n \"racer\",\n \"blacksnake, black_racer, coluber_constrictor\",\n \"blue_racer, coluber_constrictor_flaviventris\",\n \"horseshoe_whipsnake, coluber_hippocrepis\",\n \"whip-snake, whip_snake, whipsnake\",\n \"coachwhip, coachwhip_snake, masticophis_flagellum\",\n \"california_whipsnake, striped_racer, masticophis_lateralis\",\n \"sonoran_whipsnake, masticophis_bilineatus\",\n \"rat_snake\",\n \"corn_snake, red_rat_snake, elaphe_guttata\",\n \"black_rat_snake, blacksnake, pilot_blacksnake, mountain_blacksnake, elaphe_obsoleta\",\n \"chicken_snake\",\n \"indian_rat_snake, ptyas_mucosus\",\n \"glossy_snake, arizona_elegans\",\n \"bull_snake, bull-snake\",\n \"gopher_snake, pituophis_melanoleucus\",\n \"pine_snake\",\n \"king_snake, kingsnake\",\n \"common_kingsnake, lampropeltis_getulus\",\n \"milk_snake, house_snake, milk_adder, checkered_adder, lampropeltis_triangulum\",\n \"garter_snake, grass_snake\",\n \"common_garter_snake, thamnophis_sirtalis\",\n \"ribbon_snake, thamnophis_sauritus\",\n \"western_ribbon_snake, thamnophis_proximus\",\n \"lined_snake, tropidoclonion_lineatum\",\n \"ground_snake, sonora_semiannulata\",\n \"eastern_ground_snake, potamophis_striatula, haldea_striatula\",\n \"water_snake\",\n \"common_water_snake, banded_water_snake, natrix_sipedon, nerodia_sipedon\",\n \"water_moccasin\",\n \"grass_snake, ring_snake, ringed_snake, natrix_natrix\",\n \"viperine_grass_snake, natrix_maura\",\n \"red-bellied_snake, storeria_occipitamaculata\",\n \"sand_snake\",\n \"banded_sand_snake, chilomeniscus_cinctus\",\n \"black-headed_snake\",\n \"vine_snake\",\n \"lyre_snake\",\n \"sonoran_lyre_snake, trimorphodon_lambda\",\n \"night_snake, hypsiglena_torquata\",\n \"blind_snake, worm_snake\",\n \"western_blind_snake, leptotyphlops_humilis\",\n \"indigo_snake, gopher_snake, drymarchon_corais\",\n \"eastern_indigo_snake, drymarchon_corais_couperi\",\n \"constrictor\",\n \"boa\",\n \"boa_constrictor, constrictor_constrictor\",\n \"rubber_boa, tow-headed_snake, charina_bottae\",\n \"rosy_boa, lichanura_trivirgata\",\n \"anaconda, eunectes_murinus\",\n \"python\",\n \"carpet_snake, python_variegatus, morelia_spilotes_variegatus\",\n \"reticulated_python, python_reticulatus\",\n \"indian_python, python_molurus\",\n \"rock_python, rock_snake, python_sebae\",\n \"amethystine_python\",\n \"elapid, elapid_snake\",\n \"coral_snake, harlequin-snake, new_world_coral_snake\",\n \"eastern_coral_snake, micrurus_fulvius\",\n \"western_coral_snake, micruroides_euryxanthus\",\n \"coral_snake, old_world_coral_snake\",\n \"african_coral_snake, aspidelaps_lubricus\",\n \"australian_coral_snake, rhynchoelaps_australis\",\n \"copperhead, denisonia_superba\",\n \"cobra\",\n \"indian_cobra, naja_naja\",\n \"asp, egyptian_cobra, naja_haje\",\n \"black-necked_cobra, spitting_cobra, naja_nigricollis\",\n \"hamadryad, king_cobra, ophiophagus_hannah, naja_hannah\",\n \"ringhals, rinkhals, spitting_snake, hemachatus_haemachatus\",\n \"mamba\",\n \"black_mamba, dendroaspis_augusticeps\",\n \"green_mamba\",\n \"death_adder, acanthophis_antarcticus\",\n \"tiger_snake, notechis_scutatus\",\n \"australian_blacksnake, pseudechis_porphyriacus\",\n \"krait\",\n \"banded_krait, banded_adder, bungarus_fasciatus\",\n \"taipan, oxyuranus_scutellatus\",\n \"sea_snake\",\n \"viper\",\n \"adder, common_viper, vipera_berus\",\n \"asp, asp_viper, vipera_aspis\",\n \"puff_adder, bitis_arietans\",\n \"gaboon_viper, bitis_gabonica\",\n \"horned_viper, cerastes, sand_viper, horned_asp, cerastes_cornutus\",\n \"pit_viper\",\n \"copperhead, agkistrodon_contortrix\",\n \"water_moccasin, cottonmouth, cottonmouth_moccasin, agkistrodon_piscivorus\",\n \"rattlesnake, rattler\",\n \"diamondback, diamondback_rattlesnake, crotalus_adamanteus\",\n \"timber_rattlesnake, banded_rattlesnake, crotalus_horridus_horridus\",\n \"canebrake_rattlesnake, canebrake_rattler, crotalus_horridus_atricaudatus\",\n \"prairie_rattlesnake, prairie_rattler, western_rattlesnake, crotalus_viridis\",\n \"sidewinder, horned_rattlesnake, crotalus_cerastes\",\n \"western_diamondback, western_diamondback_rattlesnake, crotalus_atrox\",\n \"rock_rattlesnake, crotalus_lepidus\",\n \"tiger_rattlesnake, crotalus_tigris\",\n \"mojave_rattlesnake, crotalus_scutulatus\",\n \"speckled_rattlesnake, crotalus_mitchellii\",\n \"massasauga, massasauga_rattler, sistrurus_catenatus\",\n \"ground_rattler, massasauga, sistrurus_miliaris\",\n \"fer-de-lance, bothrops_atrops\",\n \"carcase, carcass\",\n \"carrion\",\n \"arthropod\",\n \"trilobite\",\n \"arachnid, arachnoid\",\n \"harvestman, daddy_longlegs, phalangium_opilio\",\n \"scorpion\",\n \"false_scorpion, pseudoscorpion\",\n \"book_scorpion, chelifer_cancroides\",\n \"whip-scorpion, whip_scorpion\",\n \"vinegarroon, mastigoproctus_giganteus\",\n \"spider\",\n \"orb-weaving_spider\",\n \"black_and_gold_garden_spider, argiope_aurantia\",\n \"barn_spider, araneus_cavaticus\",\n \"garden_spider, aranea_diademata\",\n \"comb-footed_spider, theridiid\",\n \"black_widow, latrodectus_mactans\",\n \"tarantula\",\n \"wolf_spider, hunting_spider\",\n \"european_wolf_spider, tarantula, lycosa_tarentula\",\n \"trap-door_spider\",\n \"acarine\",\n \"tick\",\n \"hard_tick, ixodid\",\n \"ixodes_dammini, deer_tick\",\n \"ixodes_neotomae\",\n \"ixodes_pacificus, western_black-legged_tick\",\n \"ixodes_scapularis, black-legged_tick\",\n \"sheep-tick, sheep_tick, ixodes_ricinus\",\n \"ixodes_persulcatus\",\n \"ixodes_dentatus\",\n \"ixodes_spinipalpis\",\n \"wood_tick, american_dog_tick, dermacentor_variabilis\",\n \"soft_tick, argasid\",\n \"mite\",\n \"web-spinning_mite\",\n \"acarid\",\n \"trombidiid\",\n \"trombiculid\",\n \"harvest_mite, chigger, jigger, redbug\",\n \"acarus, genus_acarus\",\n \"itch_mite, sarcoptid\",\n \"rust_mite\",\n \"spider_mite, tetranychid\",\n \"red_spider, red_spider_mite, panonychus_ulmi\",\n \"myriapod\",\n \"garden_centipede, garden_symphilid, symphilid, scutigerella_immaculata\",\n \"tardigrade\",\n \"centipede\",\n \"house_centipede, scutigera_coleoptrata\",\n \"millipede, millepede, milliped\",\n \"sea_spider, pycnogonid\",\n \"merostomata, class_merostomata\",\n \"horseshoe_crab, king_crab, limulus_polyphemus, xiphosurus_polyphemus\",\n \"asian_horseshoe_crab\",\n \"eurypterid\",\n \"tongue_worm, pentastomid\",\n \"gallinaceous_bird, gallinacean\",\n \"domestic_fowl, fowl, poultry\",\n \"dorking\",\n \"plymouth_rock\",\n \"cornish, cornish_fowl\",\n \"rock_cornish\",\n \"game_fowl\",\n \"cochin, cochin_china\",\n \"jungle_fowl, gallina\",\n \"jungle_cock\",\n \"jungle_hen\",\n \"red_jungle_fowl, gallus_gallus\",\n \"chicken, gallus_gallus\",\n \"bantam\",\n \"chick, biddy\",\n \"cock, rooster\",\n \"cockerel\",\n \"capon\",\n \"hen, biddy\",\n \"cackler\",\n \"brood_hen, broody, broody_hen, setting_hen, sitter\",\n \"mother_hen\",\n \"layer\",\n \"pullet\",\n \"spring_chicken\",\n \"rhode_island_red\",\n \"dominique, dominick\",\n \"orpington\",\n \"turkey, meleagris_gallopavo\",\n \"turkey_cock, gobbler, tom, tom_turkey\",\n \"ocellated_turkey, agriocharis_ocellata\",\n \"grouse\",\n \"black_grouse\",\n \"european_black_grouse, heathfowl, lyrurus_tetrix\",\n \"asian_black_grouse, lyrurus_mlokosiewiczi\",\n \"blackcock, black_cock\",\n \"greyhen, grayhen, grey_hen, gray_hen, heath_hen\",\n \"ptarmigan\",\n \"red_grouse, moorfowl, moorbird, moor-bird, moorgame, lagopus_scoticus\",\n \"moorhen\",\n \"capercaillie, capercailzie, horse_of_the_wood, tetrao_urogallus\",\n \"spruce_grouse, canachites_canadensis\",\n \"sage_grouse, sage_hen, centrocercus_urophasianus\",\n \"ruffed_grouse, partridge, bonasa_umbellus\",\n \"sharp-tailed_grouse, sprigtail, sprig_tail, pedioecetes_phasianellus\",\n \"prairie_chicken, prairie_grouse, prairie_fowl\",\n \"greater_prairie_chicken, tympanuchus_cupido\",\n \"lesser_prairie_chicken, tympanuchus_pallidicinctus\",\n \"heath_hen, tympanuchus_cupido_cupido\",\n \"guan\",\n \"curassow\",\n \"piping_guan\",\n \"chachalaca\",\n \"texas_chachalaca, ortilis_vetula_macalli\",\n \"megapode, mound_bird, mound-bird, mound_builder, scrub_fowl\",\n \"mallee_fowl, leipoa, lowan, leipoa_ocellata\",\n \"mallee_hen\",\n \"brush_turkey, alectura_lathami\",\n \"maleo, macrocephalon_maleo\",\n \"phasianid\",\n \"pheasant\",\n \"ring-necked_pheasant, phasianus_colchicus\",\n \"afropavo, congo_peafowl, afropavo_congensis\",\n \"argus, argus_pheasant\",\n \"golden_pheasant, chrysolophus_pictus\",\n \"bobwhite, bobwhite_quail, partridge\",\n \"northern_bobwhite, colinus_virginianus\",\n \"old_world_quail\",\n \"migratory_quail, coturnix_coturnix, coturnix_communis\",\n \"monal, monaul\",\n \"peafowl, bird_of_juno\",\n \"peachick, pea-chick\",\n \"peacock\",\n \"peahen\",\n \"blue_peafowl, pavo_cristatus\",\n \"green_peafowl, pavo_muticus\",\n \"quail\",\n \"california_quail, lofortyx_californicus\",\n \"tragopan\",\n \"partridge\",\n \"hungarian_partridge, grey_partridge, gray_partridge, perdix_perdix\",\n \"red-legged_partridge, alectoris_ruffa\",\n \"greek_partridge, rock_partridge, alectoris_graeca\",\n \"mountain_quail, mountain_partridge, oreortyx_picta_palmeri\",\n \"guinea_fowl, guinea, numida_meleagris\",\n \"guinea_hen\",\n \"hoatzin, hoactzin, stinkbird, opisthocomus_hoazin\",\n \"tinamou, partridge\",\n \"columbiform_bird\",\n \"dodo, raphus_cucullatus\",\n \"pigeon\",\n \"pouter_pigeon, pouter\",\n \"dove\",\n \"rock_dove, rock_pigeon, columba_livia\",\n \"band-tailed_pigeon, band-tail_pigeon, bandtail, columba_fasciata\",\n \"wood_pigeon, ringdove, cushat, columba_palumbus\",\n \"turtledove\",\n \"streptopelia_turtur\",\n \"ringdove, streptopelia_risoria\",\n \"australian_turtledove, turtledove, stictopelia_cuneata\",\n \"mourning_dove, zenaidura_macroura\",\n \"domestic_pigeon\",\n \"squab\",\n \"fairy_swallow\",\n \"roller, tumbler, tumbler_pigeon\",\n \"homing_pigeon, homer\",\n \"carrier_pigeon\",\n \"passenger_pigeon, ectopistes_migratorius\",\n \"sandgrouse, sand_grouse\",\n \"painted_sandgrouse, pterocles_indicus\",\n \"pin-tailed_sandgrouse, pin-tailed_grouse, pterocles_alchata\",\n \"pallas's_sandgrouse, syrrhaptes_paradoxus\",\n \"parrot\",\n \"popinjay\",\n \"poll, poll_parrot\",\n \"african_grey, african_gray, psittacus_erithacus\",\n \"amazon\",\n \"macaw\",\n \"kea, nestor_notabilis\",\n \"cockatoo\",\n \"sulphur-crested_cockatoo, kakatoe_galerita, cacatua_galerita\",\n \"pink_cockatoo, kakatoe_leadbeateri\",\n \"cockateel, cockatiel, cockatoo_parrot, nymphicus_hollandicus\",\n \"lovebird\",\n \"lory\",\n \"lorikeet\",\n \"varied_lorikeet, glossopsitta_versicolor\",\n \"rainbow_lorikeet, trichoglossus_moluccanus\",\n \"parakeet, parrakeet, parroket, paraquet, paroquet, parroquet\",\n \"carolina_parakeet, conuropsis_carolinensis\",\n \"budgerigar, budgereegah, budgerygah, budgie, grass_parakeet, lovebird, shell_parakeet, melopsittacus_undulatus\",\n \"ring-necked_parakeet, psittacula_krameri\",\n \"cuculiform_bird\",\n \"cuckoo\",\n \"european_cuckoo, cuculus_canorus\",\n \"black-billed_cuckoo, coccyzus_erythropthalmus\",\n \"roadrunner, chaparral_cock, geococcyx_californianus\",\n \"ani\",\n \"coucal\",\n \"crow_pheasant, centropus_sinensis\",\n \"touraco, turaco, turacou, turakoo\",\n \"coraciiform_bird\",\n \"roller\",\n \"european_roller, coracias_garrulus\",\n \"ground_roller\",\n \"kingfisher\",\n \"eurasian_kingfisher, alcedo_atthis\",\n \"belted_kingfisher, ceryle_alcyon\",\n \"kookaburra, laughing_jackass, dacelo_gigas\",\n \"bee_eater\",\n \"hornbill\",\n \"hoopoe, hoopoo\",\n \"euopean_hoopoe, upupa_epops\",\n \"wood_hoopoe\",\n \"motmot, momot\",\n \"tody\",\n \"apodiform_bird\",\n \"swift\",\n \"european_swift, apus_apus\",\n \"chimney_swift, chimney_swallow, chateura_pelagica\",\n \"swiftlet, collocalia_inexpectata\",\n \"tree_swift, crested_swift\",\n \"hummingbird\",\n \"archilochus_colubris\",\n \"thornbill\",\n \"goatsucker, nightjar, caprimulgid\",\n \"european_goatsucker, european_nightjar, caprimulgus_europaeus\",\n \"chuck-will's-widow, caprimulgus_carolinensis\",\n \"whippoorwill, caprimulgus_vociferus\",\n \"poorwill, phalaenoptilus_nuttallii\",\n \"frogmouth\",\n \"oilbird, guacharo, steatornis_caripensis\",\n \"piciform_bird\",\n \"woodpecker, peckerwood, pecker\",\n \"green_woodpecker, picus_viridis\",\n \"downy_woodpecker\",\n \"flicker\",\n \"yellow-shafted_flicker, colaptes_auratus, yellowhammer\",\n \"gilded_flicker, colaptes_chrysoides\",\n \"red-shafted_flicker, colaptes_caper_collaris\",\n \"ivorybill, ivory-billed_woodpecker, campephilus_principalis\",\n \"redheaded_woodpecker, redhead, melanerpes_erythrocephalus\",\n \"sapsucker\",\n \"yellow-bellied_sapsucker, sphyrapicus_varius\",\n \"red-breasted_sapsucker, sphyrapicus_varius_ruber\",\n \"wryneck\",\n \"piculet\",\n \"barbet\",\n \"puffbird\",\n \"honey_guide\",\n \"jacamar\",\n \"toucan\",\n \"toucanet\",\n \"trogon\",\n \"quetzal, quetzal_bird\",\n \"resplendent_quetzel, resplendent_trogon, pharomacrus_mocino\",\n \"aquatic_bird\",\n \"waterfowl, water_bird, waterbird\",\n \"anseriform_bird\",\n \"duck\",\n \"drake\",\n \"quack-quack\",\n \"duckling\",\n \"diving_duck\",\n \"dabbling_duck, dabbler\",\n \"mallard, anas_platyrhynchos\",\n \"black_duck, anas_rubripes\",\n \"teal\",\n \"greenwing, green-winged_teal, anas_crecca\",\n \"bluewing, blue-winged_teal, anas_discors\",\n \"garganey, anas_querquedula\",\n \"widgeon, wigeon, anas_penelope\",\n \"american_widgeon, baldpate, anas_americana\",\n \"shoveler, shoveller, broadbill, anas_clypeata\",\n \"pintail, pin-tailed_duck, anas_acuta\",\n \"sheldrake\",\n \"shelduck\",\n \"ruddy_duck, oxyura_jamaicensis\",\n \"bufflehead, butterball, dipper, bucephela_albeola\",\n \"goldeneye, whistler, bucephela_clangula\",\n \"barrow's_goldeneye, bucephala_islandica\",\n \"canvasback, canvasback_duck, aythya_valisineria\",\n \"pochard, aythya_ferina\",\n \"redhead, aythya_americana\",\n \"scaup, scaup_duck, bluebill, broadbill\",\n \"greater_scaup, aythya_marila\",\n \"lesser_scaup, lesser_scaup_duck, lake_duck, aythya_affinis\",\n \"wild_duck\",\n \"wood_duck, summer_duck, wood_widgeon, aix_sponsa\",\n \"wood_drake\",\n \"mandarin_duck, aix_galericulata\",\n \"muscovy_duck, musk_duck, cairina_moschata\",\n \"sea_duck\",\n \"eider, eider_duck\",\n \"scoter, scooter\",\n \"common_scoter, melanitta_nigra\",\n \"old_squaw, oldwife, clangula_hyemalis\",\n \"merganser, fish_duck, sawbill, sheldrake\",\n \"goosander, mergus_merganser\",\n \"american_merganser, mergus_merganser_americanus\",\n \"red-breasted_merganser, mergus_serrator\",\n \"smew, mergus_albellus\",\n \"hooded_merganser, hooded_sheldrake, lophodytes_cucullatus\",\n \"goose\",\n \"gosling\",\n \"gander\",\n \"chinese_goose, anser_cygnoides\",\n \"greylag, graylag, greylag_goose, graylag_goose, anser_anser\",\n \"blue_goose, chen_caerulescens\",\n \"snow_goose\",\n \"brant, brant_goose, brent, brent_goose\",\n \"common_brant_goose, branta_bernicla\",\n \"honker, canada_goose, canadian_goose, branta_canadensis\",\n \"barnacle_goose, barnacle, branta_leucopsis\",\n \"coscoroba\",\n \"swan\",\n \"cob\",\n \"pen\",\n \"cygnet\",\n \"mute_swan, cygnus_olor\",\n \"whooper, whooper_swan, cygnus_cygnus\",\n \"tundra_swan, cygnus_columbianus\",\n \"whistling_swan, cygnus_columbianus_columbianus\",\n \"bewick's_swan, cygnus_columbianus_bewickii\",\n \"trumpeter, trumpeter_swan, cygnus_buccinator\",\n \"black_swan, cygnus_atratus\",\n \"screamer\",\n \"horned_screamer, anhima_cornuta\",\n \"crested_screamer\",\n \"chaja, chauna_torquata\",\n \"mammal, mammalian\",\n \"female_mammal\",\n \"tusker\",\n \"prototherian\",\n \"monotreme, egg-laying_mammal\",\n \"echidna, spiny_anteater, anteater\",\n \"echidna, spiny_anteater, anteater\",\n \"platypus, duckbill, duckbilled_platypus, duck-billed_platypus, ornithorhynchus_anatinus\",\n \"marsupial, pouched_mammal\",\n \"opossum, possum\",\n \"common_opossum, didelphis_virginiana, didelphis_marsupialis\",\n \"crab-eating_opossum\",\n \"opossum_rat\",\n \"bandicoot\",\n \"rabbit-eared_bandicoot, rabbit_bandicoot, bilby, macrotis_lagotis\",\n \"kangaroo\",\n \"giant_kangaroo, great_grey_kangaroo, macropus_giganteus\",\n \"wallaby, brush_kangaroo\",\n \"common_wallaby, macropus_agiles\",\n \"hare_wallaby, kangaroo_hare\",\n \"nail-tailed_wallaby, nail-tailed_kangaroo\",\n \"rock_wallaby, rock_kangaroo\",\n \"pademelon, paddymelon\",\n \"tree_wallaby, tree_kangaroo\",\n \"musk_kangaroo, hypsiprymnodon_moschatus\",\n \"rat_kangaroo, kangaroo_rat\",\n \"potoroo\",\n \"bettong\",\n \"jerboa_kangaroo, kangaroo_jerboa\",\n \"phalanger, opossum, possum\",\n \"cuscus\",\n \"brush-tailed_phalanger, trichosurus_vulpecula\",\n \"flying_phalanger, flying_opossum, flying_squirrel\",\n \"koala, koala_bear, kangaroo_bear, native_bear, phascolarctos_cinereus\",\n \"wombat\",\n \"dasyurid_marsupial, dasyurid\",\n \"dasyure\",\n \"eastern_dasyure, dasyurus_quoll\",\n \"native_cat, dasyurus_viverrinus\",\n \"thylacine, tasmanian_wolf, tasmanian_tiger, thylacinus_cynocephalus\",\n \"tasmanian_devil, ursine_dasyure, sarcophilus_hariisi\",\n \"pouched_mouse, marsupial_mouse, marsupial_rat\",\n \"numbat, banded_anteater, anteater, myrmecobius_fasciatus\",\n \"pouched_mole, marsupial_mole, notoryctus_typhlops\",\n \"placental, placental_mammal, eutherian, eutherian_mammal\",\n \"livestock, stock, farm_animal\",\n \"bull\",\n \"cow\",\n \"calf\",\n \"calf\",\n \"yearling\",\n \"buck\",\n \"doe\",\n \"insectivore\",\n \"mole\",\n \"starnose_mole, star-nosed_mole, condylura_cristata\",\n \"brewer's_mole, hair-tailed_mole, parascalops_breweri\",\n \"golden_mole\",\n \"shrew_mole\",\n \"asiatic_shrew_mole, uropsilus_soricipes\",\n \"american_shrew_mole, neurotrichus_gibbsii\",\n \"shrew, shrewmouse\",\n \"common_shrew, sorex_araneus\",\n \"masked_shrew, sorex_cinereus\",\n \"short-tailed_shrew, blarina_brevicauda\",\n \"water_shrew\",\n \"american_water_shrew, sorex_palustris\",\n \"european_water_shrew, neomys_fodiens\",\n \"mediterranean_water_shrew, neomys_anomalus\",\n \"least_shrew, cryptotis_parva\",\n \"hedgehog, erinaceus_europaeus, erinaceus_europeaeus\",\n \"tenrec, tendrac\",\n \"tailless_tenrec, tenrec_ecaudatus\",\n \"otter_shrew, potamogale, potamogale_velox\",\n \"eiderdown\",\n \"aftershaft\",\n \"sickle_feather\",\n \"contour_feather\",\n \"bastard_wing, alula, spurious_wing\",\n \"saddle_hackle, saddle_feather\",\n \"encolure\",\n \"hair\",\n \"squama\",\n \"scute\",\n \"sclerite\",\n \"plastron\",\n \"scallop_shell\",\n \"oyster_shell\",\n \"theca\",\n \"invertebrate\",\n \"sponge, poriferan, parazoan\",\n \"choanocyte, collar_cell\",\n \"glass_sponge\",\n \"venus's_flower_basket\",\n \"metazoan\",\n \"coelenterate, cnidarian\",\n \"planula\",\n \"polyp\",\n \"medusa, medusoid, medusan\",\n \"jellyfish\",\n \"scyphozoan\",\n \"chrysaora_quinquecirrha\",\n \"hydrozoan, hydroid\",\n \"hydra\",\n \"siphonophore\",\n \"nanomia\",\n \"portuguese_man-of-war, man-of-war, jellyfish\",\n \"praya\",\n \"apolemia\",\n \"anthozoan, actinozoan\",\n \"sea_anemone, anemone\",\n \"actinia, actinian, actiniarian\",\n \"sea_pen\",\n \"coral\",\n \"gorgonian, gorgonian_coral\",\n \"sea_feather\",\n \"sea_fan\",\n \"red_coral\",\n \"stony_coral, madrepore, madriporian_coral\",\n \"brain_coral\",\n \"staghorn_coral, stag's-horn_coral\",\n \"mushroom_coral\",\n \"ctenophore, comb_jelly\",\n \"beroe\",\n \"platyctenean\",\n \"sea_gooseberry\",\n \"venus's_girdle, cestum_veneris\",\n \"worm\",\n \"helminth, parasitic_worm\",\n \"woodworm\",\n \"woodborer, borer\",\n \"acanthocephalan, spiny-headed_worm\",\n \"arrowworm, chaetognath\",\n \"bladder_worm\",\n \"flatworm, platyhelminth\",\n \"planarian, planaria\",\n \"fluke, trematode, trematode_worm\",\n \"cercaria\",\n \"liver_fluke, fasciola_hepatica\",\n \"fasciolopsis_buski\",\n \"schistosome, blood_fluke\",\n \"tapeworm, cestode\",\n \"echinococcus\",\n \"taenia\",\n \"ribbon_worm, nemertean, nemertine, proboscis_worm\",\n \"beard_worm, pogonophoran\",\n \"rotifer\",\n \"nematode, nematode_worm, roundworm\",\n \"common_roundworm, ascaris_lumbricoides\",\n \"chicken_roundworm, ascaridia_galli\",\n \"pinworm, threadworm, enterobius_vermicularis\",\n \"eelworm\",\n \"vinegar_eel, vinegar_worm, anguillula_aceti, turbatrix_aceti\",\n \"trichina, trichinella_spiralis\",\n \"hookworm\",\n \"filaria\",\n \"guinea_worm, dracunculus_medinensis\",\n \"annelid, annelid_worm, segmented_worm\",\n \"archiannelid\",\n \"oligochaete, oligochaete_worm\",\n \"earthworm, angleworm, fishworm, fishing_worm, wiggler, nightwalker, nightcrawler, crawler, dew_worm, red_worm\",\n \"polychaete, polychete, polychaete_worm, polychete_worm\",\n \"lugworm, lug, lobworm\",\n \"sea_mouse\",\n \"bloodworm\",\n \"leech, bloodsucker, hirudinean\",\n \"medicinal_leech, hirudo_medicinalis\",\n \"horseleech\",\n \"mollusk, mollusc, shellfish\",\n \"scaphopod\",\n \"tooth_shell, tusk_shell\",\n \"gastropod, univalve\",\n \"abalone, ear-shell\",\n \"ormer, sea-ear, haliotis_tuberculata\",\n \"scorpion_shell\",\n \"conch\",\n \"giant_conch, strombus_gigas\",\n \"snail\",\n \"edible_snail, helix_pomatia\",\n \"garden_snail\",\n \"brown_snail, helix_aspersa\",\n \"helix_hortensis\",\n \"slug\",\n \"seasnail\",\n \"neritid, neritid_gastropod\",\n \"nerita\",\n \"bleeding_tooth, nerita_peloronta\",\n \"neritina\",\n \"whelk\",\n \"moon_shell, moonshell\",\n \"periwinkle, winkle\",\n \"limpet\",\n \"common_limpet, patella_vulgata\",\n \"keyhole_limpet, fissurella_apertura, diodora_apertura\",\n \"river_limpet, freshwater_limpet, ancylus_fluviatilis\",\n \"sea_slug, nudibranch\",\n \"sea_hare, aplysia_punctata\",\n \"hermissenda_crassicornis\",\n \"bubble_shell\",\n \"physa\",\n \"cowrie, cowry\",\n \"money_cowrie, cypraea_moneta\",\n \"tiger_cowrie, cypraea_tigris\",\n \"solenogaster, aplacophoran\",\n \"chiton, coat-of-mail_shell, sea_cradle, polyplacophore\",\n \"bivalve, pelecypod, lamellibranch\",\n \"spat\",\n \"clam\",\n \"seashell\",\n \"soft-shell_clam, steamer, steamer_clam, long-neck_clam, mya_arenaria\",\n \"quahog, quahaug, hard-shell_clam, hard_clam, round_clam, venus_mercenaria, mercenaria_mercenaria\",\n \"littleneck, littleneck_clam\",\n \"cherrystone, cherrystone_clam\",\n \"geoduck\",\n \"razor_clam, jackknife_clam, knife-handle\",\n \"giant_clam, tridacna_gigas\",\n \"cockle\",\n \"edible_cockle, cardium_edule\",\n \"oyster\",\n \"japanese_oyster, ostrea_gigas\",\n \"virginia_oyster\",\n \"pearl_oyster, pinctada_margaritifera\",\n \"saddle_oyster, anomia_ephippium\",\n \"window_oyster, windowpane_oyster, capiz, placuna_placenta\",\n \"ark_shell\",\n \"blood_clam\",\n \"mussel\",\n \"marine_mussel, mytilid\",\n \"edible_mussel, mytilus_edulis\",\n \"freshwater_mussel, freshwater_clam\",\n \"pearly-shelled_mussel\",\n \"thin-shelled_mussel\",\n \"zebra_mussel, dreissena_polymorpha\",\n \"scallop, scollop, escallop\",\n \"bay_scallop, pecten_irradians\",\n \"sea_scallop, giant_scallop, pecten_magellanicus\",\n \"shipworm, teredinid\",\n \"teredo\",\n \"piddock\",\n \"cephalopod, cephalopod_mollusk\",\n \"chambered_nautilus, pearly_nautilus, nautilus\",\n \"octopod\",\n \"octopus, devilfish\",\n \"paper_nautilus, nautilus, argonaut, argonauta_argo\",\n \"decapod\",\n \"squid\",\n \"loligo\",\n \"ommastrephes\",\n \"architeuthis, giant_squid\",\n \"cuttlefish, cuttle\",\n \"spirula, spirula_peronii\",\n \"crustacean\",\n \"malacostracan_crustacean\",\n \"decapod_crustacean, decapod\",\n \"brachyuran\",\n \"crab\",\n \"stone_crab, menippe_mercenaria\",\n \"hard-shell_crab\",\n \"soft-shell_crab, soft-shelled_crab\",\n \"dungeness_crab, cancer_magister\",\n \"rock_crab, cancer_irroratus\",\n \"jonah_crab, cancer_borealis\",\n \"swimming_crab\",\n \"english_lady_crab, portunus_puber\",\n \"american_lady_crab, lady_crab, calico_crab, ovalipes_ocellatus\",\n \"blue_crab, callinectes_sapidus\",\n \"fiddler_crab\",\n \"pea_crab\",\n \"king_crab, alaska_crab, alaskan_king_crab, alaska_king_crab, paralithodes_camtschatica\",\n \"spider_crab\",\n \"european_spider_crab, king_crab, maja_squinado\",\n \"giant_crab, macrocheira_kaempferi\",\n \"lobster\",\n \"true_lobster\",\n \"american_lobster, northern_lobster, maine_lobster, homarus_americanus\",\n \"european_lobster, homarus_vulgaris\",\n \"cape_lobster, homarus_capensis\",\n \"norway_lobster, nephrops_norvegicus\",\n \"spiny_lobster, langouste, rock_lobster, crawfish, crayfish, sea_crawfish\",\n \"crayfish, crawfish, crawdad, crawdaddy\",\n \"old_world_crayfish, ecrevisse\",\n \"american_crayfish\",\n \"hermit_crab\",\n \"shrimp\",\n \"snapping_shrimp, pistol_shrimp\",\n \"prawn\",\n \"long-clawed_prawn, river_prawn, palaemon_australis\",\n \"tropical_prawn\",\n \"krill\",\n \"euphausia_pacifica\",\n \"opossum_shrimp\",\n \"stomatopod, stomatopod_crustacean\",\n \"mantis_shrimp, mantis_crab\",\n \"squilla, mantis_prawn\",\n \"isopod\",\n \"woodlouse, slater\",\n \"pill_bug\",\n \"sow_bug\",\n \"sea_louse, sea_slater\",\n \"amphipod\",\n \"skeleton_shrimp\",\n \"whale_louse\",\n \"daphnia, water_flea\",\n \"fairy_shrimp\",\n \"brine_shrimp, artemia_salina\",\n \"tadpole_shrimp\",\n \"copepod, copepod_crustacean\",\n \"cyclops, water_flea\",\n \"seed_shrimp, mussel_shrimp, ostracod\",\n \"barnacle, cirriped, cirripede\",\n \"acorn_barnacle, rock_barnacle, balanus_balanoides\",\n \"goose_barnacle, gooseneck_barnacle, lepas_fascicularis\",\n \"onychophoran, velvet_worm, peripatus\",\n \"wading_bird, wader\",\n \"stork\",\n \"white_stork, ciconia_ciconia\",\n \"black_stork, ciconia_nigra\",\n \"adjutant_bird, adjutant, adjutant_stork, leptoptilus_dubius\",\n \"marabou, marabout, marabou_stork, leptoptilus_crumeniferus\",\n \"openbill\",\n \"jabiru, jabiru_mycteria\",\n \"saddlebill, jabiru, ephippiorhynchus_senegalensis\",\n \"policeman_bird, black-necked_stork, jabiru, xenorhyncus_asiaticus\",\n \"wood_ibis, wood_stork, flinthead, mycteria_americana\",\n \"shoebill, shoebird, balaeniceps_rex\",\n \"ibis\",\n \"wood_ibis, wood_stork, ibis_ibis\",\n \"sacred_ibis, threskiornis_aethiopica\",\n \"spoonbill\",\n \"common_spoonbill, platalea_leucorodia\",\n \"roseate_spoonbill, ajaia_ajaja\",\n \"flamingo\",\n \"heron\",\n \"great_blue_heron, ardea_herodius\",\n \"great_white_heron, ardea_occidentalis\",\n \"egret\",\n \"little_blue_heron, egretta_caerulea\",\n \"snowy_egret, snowy_heron, egretta_thula\",\n \"little_egret, egretta_garzetta\",\n \"great_white_heron, casmerodius_albus\",\n \"american_egret, great_white_heron, egretta_albus\",\n \"cattle_egret, bubulcus_ibis\",\n \"night_heron, night_raven\",\n \"black-crowned_night_heron, nycticorax_nycticorax\",\n \"yellow-crowned_night_heron, nyctanassa_violacea\",\n \"boatbill, boat-billed_heron, broadbill, cochlearius_cochlearius\",\n \"bittern\",\n \"american_bittern, stake_driver, botaurus_lentiginosus\",\n \"european_bittern, botaurus_stellaris\",\n \"least_bittern, ixobrychus_exilis\",\n \"crane\",\n \"whooping_crane, whooper, grus_americana\",\n \"courlan, aramus_guarauna\",\n \"limpkin, aramus_pictus\",\n \"crested_cariama, seriema, cariama_cristata\",\n \"chunga, seriema, chunga_burmeisteri\",\n \"rail\",\n \"weka, maori_hen, wood_hen\",\n \"crake\",\n \"corncrake, land_rail, crex_crex\",\n \"spotted_crake, porzana_porzana\",\n \"gallinule, marsh_hen, water_hen, swamphen\",\n \"florida_gallinule, gallinula_chloropus_cachinnans\",\n \"moorhen, gallinula_chloropus\",\n \"purple_gallinule\",\n \"european_gallinule, porphyrio_porphyrio\",\n \"american_gallinule, porphyrula_martinica\",\n \"notornis, takahe, notornis_mantelli\",\n \"coot\",\n \"american_coot, marsh_hen, mud_hen, water_hen, fulica_americana\",\n \"old_world_coot, fulica_atra\",\n \"bustard\",\n \"great_bustard, otis_tarda\",\n \"plain_turkey, choriotis_australis\",\n \"button_quail, button-quail, bustard_quail, hemipode\",\n \"striped_button_quail, turnix_sylvatica\",\n \"plain_wanderer, pedionomus_torquatus\",\n \"trumpeter\",\n \"brazilian_trumpeter, psophia_crepitans\",\n \"seabird, sea_bird, seafowl\",\n \"shorebird, shore_bird, limicoline_bird\",\n \"plover\",\n \"piping_plover, charadrius_melodus\",\n \"killdeer, kildeer, killdeer_plover, charadrius_vociferus\",\n \"dotterel, dotrel, charadrius_morinellus, eudromias_morinellus\",\n \"golden_plover\",\n \"lapwing, green_plover, peewit, pewit\",\n \"turnstone\",\n \"ruddy_turnstone, arenaria_interpres\",\n \"black_turnstone, arenaria-melanocephala\",\n \"sandpiper\",\n \"surfbird, aphriza_virgata\",\n \"european_sandpiper, actitis_hypoleucos\",\n \"spotted_sandpiper, actitis_macularia\",\n \"least_sandpiper, stint, erolia_minutilla\",\n \"red-backed_sandpiper, dunlin, erolia_alpina\",\n \"greenshank, tringa_nebularia\",\n \"redshank, tringa_totanus\",\n \"yellowlegs\",\n \"greater_yellowlegs, tringa_melanoleuca\",\n \"lesser_yellowlegs, tringa_flavipes\",\n \"pectoral_sandpiper, jacksnipe, calidris_melanotos\",\n \"knot, greyback, grayback, calidris_canutus\",\n \"curlew_sandpiper, calidris_ferruginea\",\n \"sanderling, crocethia_alba\",\n \"upland_sandpiper, upland_plover, bartramian_sandpiper, bartramia_longicauda\",\n \"ruff, philomachus_pugnax\",\n \"reeve\",\n \"tattler\",\n \"polynesian_tattler, heteroscelus_incanus\",\n \"willet, catoptrophorus_semipalmatus\",\n \"woodcock\",\n \"eurasian_woodcock, scolopax_rusticola\",\n \"american_woodcock, woodcock_snipe, philohela_minor\",\n \"snipe\",\n \"whole_snipe, gallinago_gallinago\",\n \"wilson's_snipe, gallinago_gallinago_delicata\",\n \"great_snipe, woodcock_snipe, gallinago_media\",\n \"jacksnipe, half_snipe, limnocryptes_minima\",\n \"dowitcher\",\n \"greyback, grayback, limnodromus_griseus\",\n \"red-breasted_snipe, limnodromus_scolopaceus\",\n \"curlew\",\n \"european_curlew, numenius_arquata\",\n \"eskimo_curlew, numenius_borealis\",\n \"godwit\",\n \"hudsonian_godwit, limosa_haemastica\",\n \"stilt, stiltbird, longlegs, long-legs, stilt_plover, himantopus_stilt\",\n \"black-necked_stilt, himantopus_mexicanus\",\n \"black-winged_stilt, himantopus_himantopus\",\n \"white-headed_stilt, himantopus_himantopus_leucocephalus\",\n \"kaki, himantopus_novae-zelandiae\",\n \"stilt, australian_stilt\",\n \"banded_stilt, cladorhyncus_leucocephalum\",\n \"avocet\",\n \"oystercatcher, oyster_catcher\",\n \"phalarope\",\n \"red_phalarope, phalaropus_fulicarius\",\n \"northern_phalarope, lobipes_lobatus\",\n \"wilson's_phalarope, steganopus_tricolor\",\n \"pratincole, glareole\",\n \"courser\",\n \"cream-colored_courser, cursorius_cursor\",\n \"crocodile_bird, pluvianus_aegyptius\",\n \"stone_curlew, thick-knee, burhinus_oedicnemus\",\n \"coastal_diving_bird\",\n \"larid\",\n \"gull, seagull, sea_gull\",\n \"mew, mew_gull, sea_mew, larus_canus\",\n \"black-backed_gull, great_black-backed_gull, cob, larus_marinus\",\n \"herring_gull, larus_argentatus\",\n \"laughing_gull, blackcap, pewit, pewit_gull, larus_ridibundus\",\n \"ivory_gull, pagophila_eburnea\",\n \"kittiwake\",\n \"tern\",\n \"sea_swallow, sterna_hirundo\",\n \"skimmer\",\n \"jaeger\",\n \"parasitic_jaeger, arctic_skua, stercorarius_parasiticus\",\n \"skua, bonxie\",\n \"great_skua, catharacta_skua\",\n \"auk\",\n \"auklet\",\n \"razorbill, razor-billed_auk, alca_torda\",\n \"little_auk, dovekie, plautus_alle\",\n \"guillemot\",\n \"black_guillemot, cepphus_grylle\",\n \"pigeon_guillemot, cepphus_columba\",\n \"murre\",\n \"common_murre, uria_aalge\",\n \"thick-billed_murre, uria_lomvia\",\n \"puffin\",\n \"atlantic_puffin, fratercula_arctica\",\n \"horned_puffin, fratercula_corniculata\",\n \"tufted_puffin, lunda_cirrhata\",\n \"gaviiform_seabird\",\n \"loon, diver\",\n \"podicipitiform_seabird\",\n \"grebe\",\n \"great_crested_grebe, podiceps_cristatus\",\n \"red-necked_grebe, podiceps_grisegena\",\n \"black-necked_grebe, eared_grebe, podiceps_nigricollis\",\n \"dabchick, little_grebe, podiceps_ruficollis\",\n \"pied-billed_grebe, podilymbus_podiceps\",\n \"pelecaniform_seabird\",\n \"pelican\",\n \"white_pelican, pelecanus_erythrorhynchos\",\n \"old_world_white_pelican, pelecanus_onocrotalus\",\n \"frigate_bird, man-of-war_bird\",\n \"gannet\",\n \"solan, solan_goose, solant_goose, sula_bassana\",\n \"booby\",\n \"cormorant, phalacrocorax_carbo\",\n \"snakebird, anhinga, darter\",\n \"water_turkey, anhinga_anhinga\",\n \"tropic_bird, tropicbird, boatswain_bird\",\n \"sphenisciform_seabird\",\n \"penguin\",\n \"adelie, adelie_penguin, pygoscelis_adeliae\",\n \"king_penguin, aptenodytes_patagonica\",\n \"emperor_penguin, aptenodytes_forsteri\",\n \"jackass_penguin, spheniscus_demersus\",\n \"rock_hopper, crested_penguin\",\n \"pelagic_bird, oceanic_bird\",\n \"procellariiform_seabird\",\n \"albatross, mollymawk\",\n \"wandering_albatross, diomedea_exulans\",\n \"black-footed_albatross, gooney, gooney_bird, goonie, goony, diomedea_nigripes\",\n \"petrel\",\n \"white-chinned_petrel, procellaria_aequinoctialis\",\n \"giant_petrel, giant_fulmar, macronectes_giganteus\",\n \"fulmar, fulmar_petrel, fulmarus_glacialis\",\n \"shearwater\",\n \"manx_shearwater, puffinus_puffinus\",\n \"storm_petrel\",\n \"stormy_petrel, northern_storm_petrel, hydrobates_pelagicus\",\n \"mother_carey's_chicken, mother_carey's_hen, oceanites_oceanicus\",\n \"diving_petrel\",\n \"aquatic_mammal\",\n \"cetacean, cetacean_mammal, blower\",\n \"whale\",\n \"baleen_whale, whalebone_whale\",\n \"right_whale\",\n \"bowhead, bowhead_whale, greenland_whale, balaena_mysticetus\",\n \"rorqual, razorback\",\n \"blue_whale, sulfur_bottom, balaenoptera_musculus\",\n \"finback, finback_whale, fin_whale, common_rorqual, balaenoptera_physalus\",\n \"sei_whale, balaenoptera_borealis\",\n \"lesser_rorqual, piked_whale, minke_whale, balaenoptera_acutorostrata\",\n \"humpback, humpback_whale, megaptera_novaeangliae\",\n \"grey_whale, gray_whale, devilfish, eschrichtius_gibbosus, eschrichtius_robustus\",\n \"toothed_whale\",\n \"sperm_whale, cachalot, black_whale, physeter_catodon\",\n \"pygmy_sperm_whale, kogia_breviceps\",\n \"dwarf_sperm_whale, kogia_simus\",\n \"beaked_whale\",\n \"bottle-nosed_whale, bottlenose_whale, bottlenose, hyperoodon_ampullatus\",\n \"dolphin\",\n \"common_dolphin, delphinus_delphis\",\n \"bottlenose_dolphin, bottle-nosed_dolphin, bottlenose\",\n \"atlantic_bottlenose_dolphin, tursiops_truncatus\",\n \"pacific_bottlenose_dolphin, tursiops_gilli\",\n \"porpoise\",\n \"harbor_porpoise, herring_hog, phocoena_phocoena\",\n \"vaquita, phocoena_sinus\",\n \"grampus, grampus_griseus\",\n \"killer_whale, killer, orca, grampus, sea_wolf, orcinus_orca\",\n \"pilot_whale, black_whale, common_blackfish, blackfish, globicephala_melaena\",\n \"river_dolphin\",\n \"narwhal, narwal, narwhale, monodon_monoceros\",\n \"white_whale, beluga, delphinapterus_leucas\",\n \"sea_cow, sirenian_mammal, sirenian\",\n \"manatee, trichechus_manatus\",\n \"dugong, dugong_dugon\",\n \"steller's_sea_cow, hydrodamalis_gigas\",\n \"carnivore\",\n \"omnivore\",\n \"pinniped_mammal, pinniped, pinnatiped\",\n \"seal\",\n \"crabeater_seal, crab-eating_seal\",\n \"eared_seal\",\n \"fur_seal\",\n \"guadalupe_fur_seal, arctocephalus_philippi\",\n \"fur_seal\",\n \"alaska_fur_seal, callorhinus_ursinus\",\n \"sea_lion\",\n \"south_american_sea_lion, otaria_byronia\",\n \"california_sea_lion, zalophus_californianus, zalophus_californicus\",\n \"australian_sea_lion, zalophus_lobatus\",\n \"steller_sea_lion, steller's_sea_lion, eumetopias_jubatus\",\n \"earless_seal, true_seal, hair_seal\",\n \"harbor_seal, common_seal, phoca_vitulina\",\n \"harp_seal, pagophilus_groenlandicus\",\n \"elephant_seal, sea_elephant\",\n \"bearded_seal, squareflipper_square_flipper, erignathus_barbatus\",\n \"hooded_seal, bladdernose, cystophora_cristata\",\n \"walrus, seahorse, sea_horse\",\n \"atlantic_walrus, odobenus_rosmarus\",\n \"pacific_walrus, odobenus_divergens\",\n \"fissipedia\",\n \"fissiped_mammal, fissiped\",\n \"aardvark, ant_bear, anteater, orycteropus_afer\",\n \"canine, canid\",\n \"bitch\",\n \"brood_bitch\",\n \"dog, domestic_dog, canis_familiaris\",\n \"pooch, doggie, doggy, barker, bow-wow\",\n \"cur, mongrel, mutt\",\n \"feist, fice\",\n \"pariah_dog, pye-dog, pie-dog\",\n \"lapdog\",\n \"toy_dog, toy\",\n \"chihuahua\",\n \"japanese_spaniel\",\n \"maltese_dog, maltese_terrier, maltese\",\n \"pekinese, pekingese, peke\",\n \"shih-tzu\",\n \"toy_spaniel\",\n \"english_toy_spaniel\",\n \"blenheim_spaniel\",\n \"king_charles_spaniel\",\n \"papillon\",\n \"toy_terrier\",\n \"hunting_dog\",\n \"courser\",\n \"rhodesian_ridgeback\",\n \"hound, hound_dog\",\n \"afghan_hound, afghan\",\n \"basset, basset_hound\",\n \"beagle\",\n \"bloodhound, sleuthhound\",\n \"bluetick\",\n \"boarhound\",\n \"coonhound\",\n \"coondog\",\n \"black-and-tan_coonhound\",\n \"dachshund, dachsie, badger_dog\",\n \"sausage_dog, sausage_hound\",\n \"foxhound\",\n \"american_foxhound\",\n \"walker_hound, walker_foxhound\",\n \"english_foxhound\",\n \"harrier\",\n \"plott_hound\",\n \"redbone\",\n \"wolfhound\",\n \"borzoi, russian_wolfhound\",\n \"irish_wolfhound\",\n \"greyhound\",\n \"italian_greyhound\",\n \"whippet\",\n \"ibizan_hound, ibizan_podenco\",\n \"norwegian_elkhound, elkhound\",\n \"otterhound, otter_hound\",\n \"saluki, gazelle_hound\",\n \"scottish_deerhound, deerhound\",\n \"staghound\",\n \"weimaraner\",\n \"terrier\",\n \"bullterrier, bull_terrier\",\n \"staffordshire_bullterrier, staffordshire_bull_terrier\",\n \"american_staffordshire_terrier, staffordshire_terrier, american_pit_bull_terrier, pit_bull_terrier\",\n \"bedlington_terrier\",\n \"border_terrier\",\n \"kerry_blue_terrier\",\n \"irish_terrier\",\n \"norfolk_terrier\",\n \"norwich_terrier\",\n \"yorkshire_terrier\",\n \"rat_terrier, ratter\",\n \"manchester_terrier, black-and-tan_terrier\",\n \"toy_manchester, toy_manchester_terrier\",\n \"fox_terrier\",\n \"smooth-haired_fox_terrier\",\n \"wire-haired_fox_terrier\",\n \"wirehair, wirehaired_terrier, wire-haired_terrier\",\n \"lakeland_terrier\",\n \"welsh_terrier\",\n \"sealyham_terrier, sealyham\",\n \"airedale, airedale_terrier\",\n \"cairn, cairn_terrier\",\n \"australian_terrier\",\n \"dandie_dinmont, dandie_dinmont_terrier\",\n \"boston_bull, boston_terrier\",\n \"schnauzer\",\n \"miniature_schnauzer\",\n \"giant_schnauzer\",\n \"standard_schnauzer\",\n \"scotch_terrier, scottish_terrier, scottie\",\n \"tibetan_terrier, chrysanthemum_dog\",\n \"silky_terrier, sydney_silky\",\n \"skye_terrier\",\n \"clydesdale_terrier\",\n \"soft-coated_wheaten_terrier\",\n \"west_highland_white_terrier\",\n \"lhasa, lhasa_apso\",\n \"sporting_dog, gun_dog\",\n \"bird_dog\",\n \"water_dog\",\n \"retriever\",\n \"flat-coated_retriever\",\n \"curly-coated_retriever\",\n \"golden_retriever\",\n \"labrador_retriever\",\n \"chesapeake_bay_retriever\",\n \"pointer, spanish_pointer\",\n \"german_short-haired_pointer\",\n \"setter\",\n \"vizsla, hungarian_pointer\",\n \"english_setter\",\n \"irish_setter, red_setter\",\n \"gordon_setter\",\n \"spaniel\",\n \"brittany_spaniel\",\n \"clumber, clumber_spaniel\",\n \"field_spaniel\",\n \"springer_spaniel, springer\",\n \"english_springer, english_springer_spaniel\",\n \"welsh_springer_spaniel\",\n \"cocker_spaniel, english_cocker_spaniel, cocker\",\n \"sussex_spaniel\",\n \"water_spaniel\",\n \"american_water_spaniel\",\n \"irish_water_spaniel\",\n \"griffon, wire-haired_pointing_griffon\",\n \"working_dog\",\n \"watchdog, guard_dog\",\n \"kuvasz\",\n \"attack_dog\",\n \"housedog\",\n \"schipperke\",\n \"shepherd_dog, sheepdog, sheep_dog\",\n \"belgian_sheepdog, belgian_shepherd\",\n \"groenendael\",\n \"malinois\",\n \"briard\",\n \"kelpie\",\n \"komondor\",\n \"old_english_sheepdog, bobtail\",\n \"shetland_sheepdog, shetland_sheep_dog, shetland\",\n \"collie\",\n \"border_collie\",\n \"bouvier_des_flandres, bouviers_des_flandres\",\n \"rottweiler\",\n \"german_shepherd, german_shepherd_dog, german_police_dog, alsatian\",\n \"police_dog\",\n \"pinscher\",\n \"doberman, doberman_pinscher\",\n \"miniature_pinscher\",\n \"sennenhunde\",\n \"greater_swiss_mountain_dog\",\n \"bernese_mountain_dog\",\n \"appenzeller\",\n \"entlebucher\",\n \"boxer\",\n \"mastiff\",\n \"bull_mastiff\",\n \"tibetan_mastiff\",\n \"bulldog, english_bulldog\",\n \"french_bulldog\",\n \"great_dane\",\n \"guide_dog\",\n \"seeing_eye_dog\",\n \"hearing_dog\",\n \"saint_bernard, st_bernard\",\n \"seizure-alert_dog\",\n \"sled_dog, sledge_dog\",\n \"eskimo_dog, husky\",\n \"malamute, malemute, alaskan_malamute\",\n \"siberian_husky\",\n \"dalmatian, coach_dog, carriage_dog\",\n \"liver-spotted_dalmatian\",\n \"affenpinscher, monkey_pinscher, monkey_dog\",\n \"basenji\",\n \"pug, pug-dog\",\n \"leonberg\",\n \"newfoundland, newfoundland_dog\",\n \"great_pyrenees\",\n \"spitz\",\n \"samoyed, samoyede\",\n \"pomeranian\",\n \"chow, chow_chow\",\n \"keeshond\",\n \"griffon, brussels_griffon, belgian_griffon\",\n \"brabancon_griffon\",\n \"corgi, welsh_corgi\",\n \"pembroke, pembroke_welsh_corgi\",\n \"cardigan, cardigan_welsh_corgi\",\n \"poodle, poodle_dog\",\n \"toy_poodle\",\n \"miniature_poodle\",\n \"standard_poodle\",\n \"large_poodle\",\n \"mexican_hairless\",\n \"wolf\",\n \"timber_wolf, grey_wolf, gray_wolf, canis_lupus\",\n \"white_wolf, arctic_wolf, canis_lupus_tundrarum\",\n \"red_wolf, maned_wolf, canis_rufus, canis_niger\",\n \"coyote, prairie_wolf, brush_wolf, canis_latrans\",\n \"coydog\",\n \"jackal, canis_aureus\",\n \"wild_dog\",\n \"dingo, warrigal, warragal, canis_dingo\",\n \"dhole, cuon_alpinus\",\n \"crab-eating_dog, crab-eating_fox, dusicyon_cancrivorus\",\n \"raccoon_dog, nyctereutes_procyonides\",\n \"african_hunting_dog, hyena_dog, cape_hunting_dog, lycaon_pictus\",\n \"hyena, hyaena\",\n \"striped_hyena, hyaena_hyaena\",\n \"brown_hyena, strand_wolf, hyaena_brunnea\",\n \"spotted_hyena, laughing_hyena, crocuta_crocuta\",\n \"aardwolf, proteles_cristata\",\n \"fox\",\n \"vixen\",\n \"reynard\",\n \"red_fox, vulpes_vulpes\",\n \"black_fox\",\n \"silver_fox\",\n \"red_fox, vulpes_fulva\",\n \"kit_fox, prairie_fox, vulpes_velox\",\n \"kit_fox, vulpes_macrotis\",\n \"arctic_fox, white_fox, alopex_lagopus\",\n \"blue_fox\",\n \"grey_fox, gray_fox, urocyon_cinereoargenteus\",\n \"feline, felid\",\n \"cat, true_cat\",\n \"domestic_cat, house_cat, felis_domesticus, felis_catus\",\n \"kitty, kitty-cat, puss, pussy, pussycat\",\n \"mouser\",\n \"alley_cat\",\n \"stray\",\n \"tom, tomcat\",\n \"gib\",\n \"tabby, queen\",\n \"kitten, kitty\",\n \"tabby, tabby_cat\",\n \"tiger_cat\",\n \"tortoiseshell, tortoiseshell-cat, calico_cat\",\n \"persian_cat\",\n \"angora, angora_cat\",\n \"siamese_cat, siamese\",\n \"blue_point_siamese\",\n \"burmese_cat\",\n \"egyptian_cat\",\n \"maltese, maltese_cat\",\n \"abyssinian, abyssinian_cat\",\n \"manx, manx_cat\",\n \"wildcat\",\n \"sand_cat\",\n \"european_wildcat, catamountain, felis_silvestris\",\n \"cougar, puma, catamount, mountain_lion, painter, panther, felis_concolor\",\n \"ocelot, panther_cat, felis_pardalis\",\n \"jaguarundi, jaguarundi_cat, jaguarondi, eyra, felis_yagouaroundi\",\n \"kaffir_cat, caffer_cat, felis_ocreata\",\n \"jungle_cat, felis_chaus\",\n \"serval, felis_serval\",\n \"leopard_cat, felis_bengalensis\",\n \"margay, margay_cat, felis_wiedi\",\n \"manul, pallas's_cat, felis_manul\",\n \"lynx, catamount\",\n \"common_lynx, lynx_lynx\",\n \"canada_lynx, lynx_canadensis\",\n \"bobcat, bay_lynx, lynx_rufus\",\n \"spotted_lynx, lynx_pardina\",\n \"caracal, desert_lynx, lynx_caracal\",\n \"big_cat, cat\",\n \"leopard, panthera_pardus\",\n \"leopardess\",\n \"panther\",\n \"snow_leopard, ounce, panthera_uncia\",\n \"jaguar, panther, panthera_onca, felis_onca\",\n \"lion, king_of_beasts, panthera_leo\",\n \"lioness\",\n \"lionet\",\n \"tiger, panthera_tigris\",\n \"bengal_tiger\",\n \"tigress\",\n \"liger\",\n \"tiglon, tigon\",\n \"cheetah, chetah, acinonyx_jubatus\",\n \"saber-toothed_tiger, sabertooth\",\n \"smiledon_californicus\",\n \"bear\",\n \"brown_bear, bruin, ursus_arctos\",\n \"bruin\",\n \"syrian_bear, ursus_arctos_syriacus\",\n \"grizzly, grizzly_bear, silvertip, silver-tip, ursus_horribilis, ursus_arctos_horribilis\",\n \"alaskan_brown_bear, kodiak_bear, kodiak, ursus_middendorffi, ursus_arctos_middendorffi\",\n \"american_black_bear, black_bear, ursus_americanus, euarctos_americanus\",\n \"cinnamon_bear\",\n \"asiatic_black_bear, black_bear, ursus_thibetanus, selenarctos_thibetanus\",\n \"ice_bear, polar_bear, ursus_maritimus, thalarctos_maritimus\",\n \"sloth_bear, melursus_ursinus, ursus_ursinus\",\n \"viverrine, viverrine_mammal\",\n \"civet, civet_cat\",\n \"large_civet, viverra_zibetha\",\n \"small_civet, viverricula_indica, viverricula_malaccensis\",\n \"binturong, bearcat, arctictis_bintourong\",\n \"cryptoprocta, genus_cryptoprocta\",\n \"fossa, fossa_cat, cryptoprocta_ferox\",\n \"fanaloka, fossa_fossa\",\n \"genet, genetta_genetta\",\n \"banded_palm_civet, hemigalus_hardwickii\",\n \"mongoose\",\n \"indian_mongoose, herpestes_nyula\",\n \"ichneumon, herpestes_ichneumon\",\n \"palm_cat, palm_civet\",\n \"meerkat, mierkat\",\n \"slender-tailed_meerkat, suricata_suricatta\",\n \"suricate, suricata_tetradactyla\",\n \"bat, chiropteran\",\n \"fruit_bat, megabat\",\n \"flying_fox\",\n \"pteropus_capestratus\",\n \"pteropus_hypomelanus\",\n \"harpy, harpy_bat, tube-nosed_bat, tube-nosed_fruit_bat\",\n \"cynopterus_sphinx\",\n \"carnivorous_bat, microbat\",\n \"mouse-eared_bat\",\n \"leafnose_bat, leaf-nosed_bat\",\n \"macrotus, macrotus_californicus\",\n \"spearnose_bat\",\n \"phyllostomus_hastatus\",\n \"hognose_bat, choeronycteris_mexicana\",\n \"horseshoe_bat\",\n \"horseshoe_bat\",\n \"orange_bat, orange_horseshoe_bat, rhinonicteris_aurantius\",\n \"false_vampire, false_vampire_bat\",\n \"big-eared_bat, megaderma_lyra\",\n \"vespertilian_bat, vespertilionid\",\n \"frosted_bat, vespertilio_murinus\",\n \"red_bat, lasiurus_borealis\",\n \"brown_bat\",\n \"little_brown_bat, little_brown_myotis, myotis_leucifugus\",\n \"cave_myotis, myotis_velifer\",\n \"big_brown_bat, eptesicus_fuscus\",\n \"serotine, european_brown_bat, eptesicus_serotinus\",\n \"pallid_bat, cave_bat, antrozous_pallidus\",\n \"pipistrelle, pipistrel, pipistrellus_pipistrellus\",\n \"eastern_pipistrel, pipistrellus_subflavus\",\n \"jackass_bat, spotted_bat, euderma_maculata\",\n \"long-eared_bat\",\n \"western_big-eared_bat, plecotus_townsendi\",\n \"freetail, free-tailed_bat, freetailed_bat\",\n \"guano_bat, mexican_freetail_bat, tadarida_brasiliensis\",\n \"pocketed_bat, pocketed_freetail_bat, tadirida_femorosacca\",\n \"mastiff_bat\",\n \"vampire_bat, true_vampire_bat\",\n \"desmodus_rotundus\",\n \"hairy-legged_vampire_bat, diphylla_ecaudata\",\n \"predator, predatory_animal\",\n \"prey, quarry\",\n \"game\",\n \"big_game\",\n \"game_bird\",\n \"fossorial_mammal\",\n \"tetrapod\",\n \"quadruped\",\n \"hexapod\",\n \"biped\",\n \"insect\",\n \"social_insect\",\n \"holometabola, metabola\",\n \"defoliator\",\n \"pollinator\",\n \"gallfly\",\n \"scorpion_fly\",\n \"hanging_fly\",\n \"collembolan, springtail\",\n \"beetle\",\n \"tiger_beetle\",\n \"ladybug, ladybeetle, lady_beetle, ladybird, ladybird_beetle\",\n \"two-spotted_ladybug, adalia_bipunctata\",\n \"mexican_bean_beetle, bean_beetle, epilachna_varivestis\",\n \"hippodamia_convergens\",\n \"vedalia, rodolia_cardinalis\",\n \"ground_beetle, carabid_beetle\",\n \"bombardier_beetle\",\n \"calosoma\",\n \"searcher, searcher_beetle, calosoma_scrutator\",\n \"firefly, lightning_bug\",\n \"glowworm\",\n \"long-horned_beetle, longicorn, longicorn_beetle\",\n \"sawyer, sawyer_beetle\",\n \"pine_sawyer\",\n \"leaf_beetle, chrysomelid\",\n \"flea_beetle\",\n \"colorado_potato_beetle, colorado_beetle, potato_bug, potato_beetle, leptinotarsa_decemlineata\",\n \"carpet_beetle, carpet_bug\",\n \"buffalo_carpet_beetle, anthrenus_scrophulariae\",\n \"black_carpet_beetle\",\n \"clerid_beetle, clerid\",\n \"bee_beetle\",\n \"lamellicorn_beetle\",\n \"scarabaeid_beetle, scarabaeid, scarabaean\",\n \"dung_beetle\",\n \"scarab, scarabaeus, scarabaeus_sacer\",\n \"tumblebug\",\n \"dorbeetle\",\n \"june_beetle, june_bug, may_bug, may_beetle\",\n \"green_june_beetle, figeater\",\n \"japanese_beetle, popillia_japonica\",\n \"oriental_beetle, asiatic_beetle, anomala_orientalis\",\n \"rhinoceros_beetle\",\n \"melolonthid_beetle\",\n \"cockchafer, may_bug, may_beetle, melolontha_melolontha\",\n \"rose_chafer, rose_bug, macrodactylus_subspinosus\",\n \"rose_chafer, rose_beetle, cetonia_aurata\",\n \"stag_beetle\",\n \"elaterid_beetle, elater, elaterid\",\n \"click_beetle, skipjack, snapping_beetle\",\n \"firefly, fire_beetle, pyrophorus_noctiluca\",\n \"wireworm\",\n \"water_beetle\",\n \"whirligig_beetle\",\n \"deathwatch_beetle, deathwatch, xestobium_rufovillosum\",\n \"weevil\",\n \"snout_beetle\",\n \"boll_weevil, anthonomus_grandis\",\n \"blister_beetle, meloid\",\n \"oil_beetle\",\n \"spanish_fly\",\n \"dutch-elm_beetle, scolytus_multistriatus\",\n \"bark_beetle\",\n \"spruce_bark_beetle, dendroctonus_rufipennis\",\n \"rove_beetle\",\n \"darkling_beetle, darkling_groung_beetle, tenebrionid\",\n \"mealworm\",\n \"flour_beetle, flour_weevil\",\n \"seed_beetle, seed_weevil\",\n \"pea_weevil, bruchus_pisorum\",\n \"bean_weevil, acanthoscelides_obtectus\",\n \"rice_weevil, black_weevil, sitophylus_oryzae\",\n \"asian_longhorned_beetle, anoplophora_glabripennis\",\n \"web_spinner\",\n \"louse, sucking_louse\",\n \"common_louse, pediculus_humanus\",\n \"head_louse, pediculus_capitis\",\n \"body_louse, cootie, pediculus_corporis\",\n \"crab_louse, pubic_louse, crab, phthirius_pubis\",\n \"bird_louse, biting_louse, louse\",\n \"flea\",\n \"pulex_irritans\",\n \"dog_flea, ctenocephalides_canis\",\n \"cat_flea, ctenocephalides_felis\",\n \"chigoe, chigger, chigoe_flea, tunga_penetrans\",\n \"sticktight, sticktight_flea, echidnophaga_gallinacea\",\n \"dipterous_insect, two-winged_insects, dipteran, dipteron\",\n \"gall_midge, gallfly, gall_gnat\",\n \"hessian_fly, mayetiola_destructor\",\n \"fly\",\n \"housefly, house_fly, musca_domestica\",\n \"tsetse_fly, tsetse, tzetze_fly, tzetze, glossina\",\n \"blowfly, blow_fly\",\n \"bluebottle, calliphora_vicina\",\n \"greenbottle, greenbottle_fly\",\n \"flesh_fly, sarcophaga_carnaria\",\n \"tachina_fly\",\n \"gadfly\",\n \"botfly\",\n \"human_botfly, dermatobia_hominis\",\n \"sheep_botfly, sheep_gadfly, oestrus_ovis\",\n \"warble_fly\",\n \"horsefly, cleg, clegg, horse_fly\",\n \"bee_fly\",\n \"robber_fly, bee_killer\",\n \"fruit_fly, pomace_fly\",\n \"apple_maggot, railroad_worm, rhagoletis_pomonella\",\n \"mediterranean_fruit_fly, medfly, ceratitis_capitata\",\n \"drosophila, drosophila_melanogaster\",\n \"vinegar_fly\",\n \"leaf_miner, leaf-miner\",\n \"louse_fly, hippoboscid\",\n \"horse_tick, horsefly, hippobosca_equina\",\n \"sheep_ked, sheep-tick, sheep_tick, melophagus_ovinus\",\n \"horn_fly, haematobia_irritans\",\n \"mosquito\",\n \"wiggler, wriggler\",\n \"gnat\",\n \"yellow-fever_mosquito, aedes_aegypti\",\n \"asian_tiger_mosquito, aedes_albopictus\",\n \"anopheline\",\n \"malarial_mosquito, malaria_mosquito\",\n \"common_mosquito, culex_pipiens\",\n \"culex_quinquefasciatus, culex_fatigans\",\n \"gnat\",\n \"punkie, punky, punkey, no-see-um, biting_midge\",\n \"midge\",\n \"fungus_gnat\",\n \"psychodid\",\n \"sand_fly, sandfly, phlebotomus_papatasii\",\n \"fungus_gnat, sciara, sciarid\",\n \"armyworm\",\n \"crane_fly, daddy_longlegs\",\n \"blackfly, black_fly, buffalo_gnat\",\n \"hymenopterous_insect, hymenopteran, hymenopteron, hymenopter\",\n \"bee\",\n \"drone\",\n \"queen_bee\",\n \"worker\",\n \"soldier\",\n \"worker_bee\",\n \"honeybee, apis_mellifera\",\n \"africanized_bee, africanized_honey_bee, killer_bee, apis_mellifera_scutellata, apis_mellifera_adansonii\",\n \"black_bee, german_bee\",\n \"carniolan_bee\",\n \"italian_bee\",\n \"carpenter_bee\",\n \"bumblebee, humblebee\",\n \"cuckoo-bumblebee\",\n \"andrena, andrenid, mining_bee\",\n \"nomia_melanderi, alkali_bee\",\n \"leaf-cutting_bee, leaf-cutter, leaf-cutter_bee\",\n \"mason_bee\",\n \"potter_bee\",\n \"wasp\",\n \"vespid, vespid_wasp\",\n \"paper_wasp\",\n \"hornet\",\n \"giant_hornet, vespa_crabro\",\n \"common_wasp, vespula_vulgaris\",\n \"bald-faced_hornet, white-faced_hornet, vespula_maculata\",\n \"yellow_jacket, yellow_hornet, vespula_maculifrons\",\n \"polistes_annularis\",\n \"mason_wasp\",\n \"potter_wasp\",\n \"mutillidae, family_mutillidae\",\n \"velvet_ant\",\n \"sphecoid_wasp, sphecoid\",\n \"mason_wasp\",\n \"digger_wasp\",\n \"cicada_killer, sphecius_speciosis\",\n \"mud_dauber\",\n \"gall_wasp, gallfly, cynipid_wasp, cynipid_gall_wasp\",\n \"chalcid_fly, chalcidfly, chalcid, chalcid_wasp\",\n \"strawworm, jointworm\",\n \"chalcis_fly\",\n \"ichneumon_fly\",\n \"sawfly\",\n \"birch_leaf_miner, fenusa_pusilla\",\n \"ant, emmet, pismire\",\n \"pharaoh_ant, pharaoh's_ant, monomorium_pharaonis\",\n \"little_black_ant, monomorium_minimum\",\n \"army_ant, driver_ant, legionary_ant\",\n \"carpenter_ant\",\n \"fire_ant\",\n \"wood_ant, formica_rufa\",\n \"slave_ant\",\n \"formica_fusca\",\n \"slave-making_ant, slave-maker\",\n \"sanguinary_ant, formica_sanguinea\",\n \"bulldog_ant\",\n \"amazon_ant, polyergus_rufescens\",\n \"termite, white_ant\",\n \"dry-wood_termite\",\n \"reticulitermes_lucifugus\",\n \"mastotermes_darwiniensis\",\n \"mastotermes_electrodominicus\",\n \"powder-post_termite, cryptotermes_brevis\",\n \"orthopterous_insect, orthopteron, orthopteran\",\n \"grasshopper, hopper\",\n \"short-horned_grasshopper, acridid\",\n \"locust\",\n \"migratory_locust, locusta_migratoria\",\n \"migratory_grasshopper\",\n \"long-horned_grasshopper, tettigoniid\",\n \"katydid\",\n \"mormon_cricket, anabrus_simplex\",\n \"sand_cricket, jerusalem_cricket, stenopelmatus_fuscus\",\n \"cricket\",\n \"mole_cricket\",\n \"european_house_cricket, acheta_domestica\",\n \"field_cricket, acheta_assimilis\",\n \"tree_cricket\",\n \"snowy_tree_cricket, oecanthus_fultoni\",\n \"phasmid, phasmid_insect\",\n \"walking_stick, walkingstick, stick_insect\",\n \"diapheromera, diapheromera_femorata\",\n \"walking_leaf, leaf_insect\",\n \"cockroach, roach\",\n \"oriental_cockroach, oriental_roach, asiatic_cockroach, blackbeetle, blatta_orientalis\",\n \"american_cockroach, periplaneta_americana\",\n \"australian_cockroach, periplaneta_australasiae\",\n \"german_cockroach, croton_bug, crotonbug, water_bug, blattella_germanica\",\n \"giant_cockroach\",\n \"mantis, mantid\",\n \"praying_mantis, praying_mantid, mantis_religioso\",\n \"bug\",\n \"hemipterous_insect, bug, hemipteran, hemipteron\",\n \"leaf_bug, plant_bug\",\n \"mirid_bug, mirid, capsid\",\n \"four-lined_plant_bug, four-lined_leaf_bug, poecilocapsus_lineatus\",\n \"lygus_bug\",\n \"tarnished_plant_bug, lygus_lineolaris\",\n \"lace_bug\",\n \"lygaeid, lygaeid_bug\",\n \"chinch_bug, blissus_leucopterus\",\n \"coreid_bug, coreid\",\n \"squash_bug, anasa_tristis\",\n \"leaf-footed_bug, leaf-foot_bug\",\n \"bedbug, bed_bug, chinch, cimex_lectularius\",\n \"backswimmer, notonecta_undulata\",\n \"true_bug\",\n \"heteropterous_insect\",\n \"water_bug\",\n \"giant_water_bug\",\n \"water_scorpion\",\n \"water_boatman, boat_bug\",\n \"water_strider, pond-skater, water_skater\",\n \"common_pond-skater, gerris_lacustris\",\n \"assassin_bug, reduviid\",\n \"conenose, cone-nosed_bug, conenose_bug, big_bedbug, kissing_bug\",\n \"wheel_bug, arilus_cristatus\",\n \"firebug\",\n \"cotton_stainer\",\n \"homopterous_insect, homopteran\",\n \"whitefly\",\n \"citrus_whitefly, dialeurodes_citri\",\n \"greenhouse_whitefly, trialeurodes_vaporariorum\",\n \"sweet-potato_whitefly\",\n \"superbug, bemisia_tabaci, poinsettia_strain\",\n \"cotton_strain\",\n \"coccid_insect\",\n \"scale_insect\",\n \"soft_scale\",\n \"brown_soft_scale, coccus_hesperidum\",\n \"armored_scale\",\n \"san_jose_scale, aspidiotus_perniciosus\",\n \"cochineal_insect, cochineal, dactylopius_coccus\",\n \"mealybug, mealy_bug\",\n \"citrophilous_mealybug, citrophilus_mealybug, pseudococcus_fragilis\",\n \"comstock_mealybug, comstock's_mealybug, pseudococcus_comstocki\",\n \"citrus_mealybug, planococcus_citri\",\n \"plant_louse, louse\",\n \"aphid\",\n \"apple_aphid, green_apple_aphid, aphis_pomi\",\n \"blackfly, bean_aphid, aphis_fabae\",\n \"greenfly\",\n \"green_peach_aphid\",\n \"ant_cow\",\n \"woolly_aphid, woolly_plant_louse\",\n \"woolly_apple_aphid, american_blight, eriosoma_lanigerum\",\n \"woolly_alder_aphid, prociphilus_tessellatus\",\n \"adelgid\",\n \"balsam_woolly_aphid, adelges_piceae\",\n \"spruce_gall_aphid, adelges_abietis\",\n \"woolly_adelgid\",\n \"jumping_plant_louse, psylla, psyllid\",\n \"cicada, cicala\",\n \"dog-day_cicada, harvest_fly\",\n \"seventeen-year_locust, periodical_cicada, magicicada_septendecim\",\n \"spittle_insect, spittlebug\",\n \"froghopper\",\n \"meadow_spittlebug, philaenus_spumarius\",\n \"pine_spittlebug\",\n \"saratoga_spittlebug, aphrophora_saratogensis\",\n \"leafhopper\",\n \"plant_hopper, planthopper\",\n \"treehopper\",\n \"lantern_fly, lantern-fly\",\n \"psocopterous_insect\",\n \"psocid\",\n \"bark-louse, bark_louse\",\n \"booklouse, book_louse, deathwatch, liposcelis_divinatorius\",\n \"common_booklouse, trogium_pulsatorium\",\n \"ephemerid, ephemeropteran\",\n \"mayfly, dayfly, shadfly\",\n \"stonefly, stone_fly, plecopteran\",\n \"neuropteron, neuropteran, neuropterous_insect\",\n \"ant_lion, antlion, antlion_fly\",\n \"doodlebug, ant_lion, antlion\",\n \"lacewing, lacewing_fly\",\n \"aphid_lion, aphis_lion\",\n \"green_lacewing, chrysopid, stink_fly\",\n \"brown_lacewing, hemerobiid, hemerobiid_fly\",\n \"dobson, dobsonfly, dobson_fly, corydalus_cornutus\",\n \"hellgrammiate, dobson\",\n \"fish_fly, fish-fly\",\n \"alderfly, alder_fly, sialis_lutaria\",\n \"snakefly\",\n \"mantispid\",\n \"odonate\",\n \"dragonfly, darning_needle, devil's_darning_needle, sewing_needle, snake_feeder, snake_doctor, mosquito_hawk, skeeter_hawk\",\n \"damselfly\",\n \"trichopterous_insect, trichopteran, trichopteron\",\n \"caddis_fly, caddis-fly, caddice_fly, caddice-fly\",\n \"caseworm\",\n \"caddisworm, strawworm\",\n \"thysanuran_insect, thysanuron\",\n \"bristletail\",\n \"silverfish, lepisma_saccharina\",\n \"firebrat, thermobia_domestica\",\n \"jumping_bristletail, machilid\",\n \"thysanopter, thysanopteron, thysanopterous_insect\",\n \"thrips, thrip, thripid\",\n \"tobacco_thrips, frankliniella_fusca\",\n \"onion_thrips, onion_louse, thrips_tobaci\",\n \"earwig\",\n \"common_european_earwig, forficula_auricularia\",\n \"lepidopterous_insect, lepidopteron, lepidopteran\",\n \"butterfly\",\n \"nymphalid, nymphalid_butterfly, brush-footed_butterfly, four-footed_butterfly\",\n \"mourning_cloak, mourning_cloak_butterfly, camberwell_beauty, nymphalis_antiopa\",\n \"tortoiseshell, tortoiseshell_butterfly\",\n \"painted_beauty, vanessa_virginiensis\",\n \"admiral\",\n \"red_admiral, vanessa_atalanta\",\n \"white_admiral, limenitis_camilla\",\n \"banded_purple, white_admiral, limenitis_arthemis\",\n \"red-spotted_purple, limenitis_astyanax\",\n \"viceroy, limenitis_archippus\",\n \"anglewing\",\n \"ringlet, ringlet_butterfly\",\n \"comma, comma_butterfly, polygonia_comma\",\n \"fritillary\",\n \"silverspot\",\n \"emperor_butterfly, emperor\",\n \"purple_emperor, apatura_iris\",\n \"peacock, peacock_butterfly, inachis_io\",\n \"danaid, danaid_butterfly\",\n \"monarch, monarch_butterfly, milkweed_butterfly, danaus_plexippus\",\n \"pierid, pierid_butterfly\",\n \"cabbage_butterfly\",\n \"small_white, pieris_rapae\",\n \"large_white, pieris_brassicae\",\n \"southern_cabbage_butterfly, pieris_protodice\",\n \"sulphur_butterfly, sulfur_butterfly\",\n \"lycaenid, lycaenid_butterfly\",\n \"blue\",\n \"copper\",\n \"american_copper, lycaena_hypophlaeas\",\n \"hairstreak, hairstreak_butterfly\",\n \"strymon_melinus\",\n \"moth\",\n \"moth_miller, miller\",\n \"tortricid, tortricid_moth\",\n \"leaf_roller, leaf-roller\",\n \"tea_tortrix, tortrix, homona_coffearia\",\n \"orange_tortrix, tortrix, argyrotaenia_citrana\",\n \"codling_moth, codlin_moth, carpocapsa_pomonella\",\n \"lymantriid, tussock_moth\",\n \"tussock_caterpillar\",\n \"gypsy_moth, gipsy_moth, lymantria_dispar\",\n \"browntail, brown-tail_moth, euproctis_phaeorrhoea\",\n \"gold-tail_moth, euproctis_chrysorrhoea\",\n \"geometrid, geometrid_moth\",\n \"paleacrita_vernata\",\n \"alsophila_pometaria\",\n \"cankerworm\",\n \"spring_cankerworm\",\n \"fall_cankerworm\",\n \"measuring_worm, inchworm, looper\",\n \"pyralid, pyralid_moth\",\n \"bee_moth, wax_moth, galleria_mellonella\",\n \"corn_borer, european_corn_borer_moth, corn_borer_moth, pyrausta_nubilalis\",\n \"mediterranean_flour_moth, anagasta_kuehniella\",\n \"tobacco_moth, cacao_moth, ephestia_elutella\",\n \"almond_moth, fig_moth, cadra_cautella\",\n \"raisin_moth, cadra_figulilella\",\n \"tineoid, tineoid_moth\",\n \"tineid, tineid_moth\",\n \"clothes_moth\",\n \"casemaking_clothes_moth, tinea_pellionella\",\n \"webbing_clothes_moth, webbing_moth, tineola_bisselliella\",\n \"carpet_moth, tapestry_moth, trichophaga_tapetzella\",\n \"gelechiid, gelechiid_moth\",\n \"grain_moth\",\n \"angoumois_moth, angoumois_grain_moth, sitotroga_cerealella\",\n \"potato_moth, potato_tuber_moth, splitworm, phthorimaea_operculella\",\n \"potato_tuberworm, phthorimaea_operculella\",\n \"noctuid_moth, noctuid, owlet_moth\",\n \"cutworm\",\n \"underwing\",\n \"red_underwing, catocala_nupta\",\n \"antler_moth, cerapteryx_graminis\",\n \"heliothis_moth, heliothis_zia\",\n \"army_cutworm, chorizagrotis_auxiliaris\",\n \"armyworm, pseudaletia_unipuncta\",\n \"armyworm, army_worm, pseudaletia_unipuncta\",\n \"spodoptera_exigua\",\n \"beet_armyworm, spodoptera_exigua\",\n \"spodoptera_frugiperda\",\n \"fall_armyworm, spodoptera_frugiperda\",\n \"hawkmoth, hawk_moth, sphingid, sphinx_moth, hummingbird_moth\",\n \"manduca_sexta\",\n \"tobacco_hornworm, tomato_worm, manduca_sexta\",\n \"manduca_quinquemaculata\",\n \"tomato_hornworm, potato_worm, manduca_quinquemaculata\",\n \"death's-head_moth, acherontia_atropos\",\n \"bombycid, bombycid_moth, silkworm_moth\",\n \"domestic_silkworm_moth, domesticated_silkworm_moth, bombyx_mori\",\n \"silkworm\",\n \"saturniid, saturniid_moth\",\n \"emperor, emperor_moth, saturnia_pavonia\",\n \"imperial_moth, eacles_imperialis\",\n \"giant_silkworm_moth, silkworm_moth\",\n \"silkworm, giant_silkworm, wild_wilkworm\",\n \"luna_moth, actias_luna\",\n \"cecropia, cecropia_moth, hyalophora_cecropia\",\n \"cynthia_moth, samia_cynthia, samia_walkeri\",\n \"ailanthus_silkworm, samia_cynthia\",\n \"io_moth, automeris_io\",\n \"polyphemus_moth, antheraea_polyphemus\",\n \"pernyi_moth, antheraea_pernyi\",\n \"tussah, tusseh, tussur, tussore, tusser, antheraea_mylitta\",\n \"atlas_moth, atticus_atlas\",\n \"arctiid, arctiid_moth\",\n \"tiger_moth\",\n \"cinnabar, cinnabar_moth, callimorpha_jacobeae\",\n \"lasiocampid, lasiocampid_moth\",\n \"eggar, egger\",\n \"tent-caterpillar_moth, malacosoma_americana\",\n \"tent_caterpillar\",\n \"tent-caterpillar_moth, malacosoma_disstria\",\n \"forest_tent_caterpillar, malacosoma_disstria\",\n \"lappet, lappet_moth\",\n \"lappet_caterpillar\",\n \"webworm\",\n \"webworm_moth\",\n \"hyphantria_cunea\",\n \"fall_webworm, hyphantria_cunea\",\n \"garden_webworm, loxostege_similalis\",\n \"instar\",\n \"caterpillar\",\n \"corn_borer, pyrausta_nubilalis\",\n \"bollworm\",\n \"pink_bollworm, gelechia_gossypiella\",\n \"corn_earworm, cotton_bollworm, tomato_fruitworm, tobacco_budworm, vetchworm, heliothis_zia\",\n \"cabbageworm, pieris_rapae\",\n \"woolly_bear, woolly_bear_caterpillar\",\n \"woolly_bear_moth\",\n \"larva\",\n \"nymph\",\n \"leptocephalus\",\n \"grub\",\n \"maggot\",\n \"leatherjacket\",\n \"pupa\",\n \"chrysalis\",\n \"imago\",\n \"queen\",\n \"phoronid\",\n \"bryozoan, polyzoan, sea_mat, sea_moss, moss_animal\",\n \"brachiopod, lamp_shell, lampshell\",\n \"peanut_worm, sipunculid\",\n \"echinoderm\",\n \"starfish, sea_star\",\n \"brittle_star, brittle-star, serpent_star\",\n \"basket_star, basket_fish\",\n \"astrophyton_muricatum\",\n \"sea_urchin\",\n \"edible_sea_urchin, echinus_esculentus\",\n \"sand_dollar\",\n \"heart_urchin\",\n \"crinoid\",\n \"sea_lily\",\n \"feather_star, comatulid\",\n \"sea_cucumber, holothurian\",\n \"trepang, holothuria_edulis\",\n \"duplicidentata\",\n \"lagomorph, gnawing_mammal\",\n \"leporid, leporid_mammal\",\n \"rabbit, coney, cony\",\n \"rabbit_ears\",\n \"lapin\",\n \"bunny, bunny_rabbit\",\n \"european_rabbit, old_world_rabbit, oryctolagus_cuniculus\",\n \"wood_rabbit, cottontail, cottontail_rabbit\",\n \"eastern_cottontail, sylvilagus_floridanus\",\n \"swamp_rabbit, canecutter, swamp_hare, sylvilagus_aquaticus\",\n \"marsh_hare, swamp_rabbit, sylvilagus_palustris\",\n \"hare\",\n \"leveret\",\n \"european_hare, lepus_europaeus\",\n \"jackrabbit\",\n \"white-tailed_jackrabbit, whitetail_jackrabbit, lepus_townsendi\",\n \"blacktail_jackrabbit, lepus_californicus\",\n \"polar_hare, arctic_hare, lepus_arcticus\",\n \"snowshoe_hare, snowshoe_rabbit, varying_hare, lepus_americanus\",\n \"belgian_hare, leporide\",\n \"angora, angora_rabbit\",\n \"pika, mouse_hare, rock_rabbit, coney, cony\",\n \"little_chief_hare, ochotona_princeps\",\n \"collared_pika, ochotona_collaris\",\n \"rodent, gnawer\",\n \"mouse\",\n \"rat\",\n \"pocket_rat\",\n \"murine\",\n \"house_mouse, mus_musculus\",\n \"harvest_mouse, micromyx_minutus\",\n \"field_mouse, fieldmouse\",\n \"nude_mouse\",\n \"european_wood_mouse, apodemus_sylvaticus\",\n \"brown_rat, norway_rat, rattus_norvegicus\",\n \"wharf_rat\",\n \"sewer_rat\",\n \"black_rat, roof_rat, rattus_rattus\",\n \"bandicoot_rat, mole_rat\",\n \"jerboa_rat\",\n \"kangaroo_mouse\",\n \"water_rat\",\n \"beaver_rat\",\n \"new_world_mouse\",\n \"american_harvest_mouse, harvest_mouse\",\n \"wood_mouse\",\n \"white-footed_mouse, vesper_mouse, peromyscus_leucopus\",\n \"deer_mouse, peromyscus_maniculatus\",\n \"cactus_mouse, peromyscus_eremicus\",\n \"cotton_mouse, peromyscus_gossypinus\",\n \"pygmy_mouse, baiomys_taylori\",\n \"grasshopper_mouse\",\n \"muskrat, musquash, ondatra_zibethica\",\n \"round-tailed_muskrat, florida_water_rat, neofiber_alleni\",\n \"cotton_rat, sigmodon_hispidus\",\n \"wood_rat, wood-rat\",\n \"dusky-footed_wood_rat\",\n \"vole, field_mouse\",\n \"packrat, pack_rat, trade_rat, bushytail_woodrat, neotoma_cinerea\",\n \"dusky-footed_woodrat, neotoma_fuscipes\",\n \"eastern_woodrat, neotoma_floridana\",\n \"rice_rat, oryzomys_palustris\",\n \"pine_vole, pine_mouse, pitymys_pinetorum\",\n \"meadow_vole, meadow_mouse, microtus_pennsylvaticus\",\n \"water_vole, richardson_vole, microtus_richardsoni\",\n \"prairie_vole, microtus_ochrogaster\",\n \"water_vole, water_rat, arvicola_amphibius\",\n \"red-backed_mouse, redback_vole\",\n \"phenacomys\",\n \"hamster\",\n \"eurasian_hamster, cricetus_cricetus\",\n \"golden_hamster, syrian_hamster, mesocricetus_auratus\",\n \"gerbil, gerbille\",\n \"jird\",\n \"tamarisk_gerbil, meriones_unguiculatus\",\n \"sand_rat, meriones_longifrons\",\n \"lemming\",\n \"european_lemming, lemmus_lemmus\",\n \"brown_lemming, lemmus_trimucronatus\",\n \"grey_lemming, gray_lemming, red-backed_lemming\",\n \"pied_lemming\",\n \"hudson_bay_collared_lemming, dicrostonyx_hudsonius\",\n \"southern_bog_lemming, synaptomys_cooperi\",\n \"northern_bog_lemming, synaptomys_borealis\",\n \"porcupine, hedgehog\",\n \"old_world_porcupine\",\n \"brush-tailed_porcupine, brush-tail_porcupine\",\n \"long-tailed_porcupine, trichys_lipura\",\n \"new_world_porcupine\",\n \"canada_porcupine, erethizon_dorsatum\",\n \"pocket_mouse\",\n \"silky_pocket_mouse, perognathus_flavus\",\n \"plains_pocket_mouse, perognathus_flavescens\",\n \"hispid_pocket_mouse, perognathus_hispidus\",\n \"mexican_pocket_mouse, liomys_irroratus\",\n \"kangaroo_rat, desert_rat, dipodomys_phillipsii\",\n \"ord_kangaroo_rat, dipodomys_ordi\",\n \"kangaroo_mouse, dwarf_pocket_rat\",\n \"jumping_mouse\",\n \"meadow_jumping_mouse, zapus_hudsonius\",\n \"jerboa\",\n \"typical_jerboa\",\n \"jaculus_jaculus\",\n \"dormouse\",\n \"loir, glis_glis\",\n \"hazel_mouse, muscardinus_avellanarius\",\n \"lerot\",\n \"gopher, pocket_gopher, pouched_rat\",\n \"plains_pocket_gopher, geomys_bursarius\",\n \"southeastern_pocket_gopher, geomys_pinetis\",\n \"valley_pocket_gopher, thomomys_bottae\",\n \"northern_pocket_gopher, thomomys_talpoides\",\n \"squirrel\",\n \"tree_squirrel\",\n \"eastern_grey_squirrel, eastern_gray_squirrel, cat_squirrel, sciurus_carolinensis\",\n \"western_grey_squirrel, western_gray_squirrel, sciurus_griseus\",\n \"fox_squirrel, eastern_fox_squirrel, sciurus_niger\",\n \"black_squirrel\",\n \"red_squirrel, cat_squirrel, sciurus_vulgaris\",\n \"american_red_squirrel, spruce_squirrel, red_squirrel, sciurus_hudsonicus, tamiasciurus_hudsonicus\",\n \"chickeree, douglas_squirrel, tamiasciurus_douglasi\",\n \"antelope_squirrel, whitetail_antelope_squirrel, antelope_chipmunk, citellus_leucurus\",\n \"ground_squirrel, gopher, spermophile\",\n \"mantled_ground_squirrel, citellus_lateralis\",\n \"suslik, souslik, citellus_citellus\",\n \"flickertail, richardson_ground_squirrel, citellus_richardsoni\",\n \"rock_squirrel, citellus_variegatus\",\n \"arctic_ground_squirrel, parka_squirrel, citellus_parryi\",\n \"prairie_dog, prairie_marmot\",\n \"blacktail_prairie_dog, cynomys_ludovicianus\",\n \"whitetail_prairie_dog, cynomys_gunnisoni\",\n \"eastern_chipmunk, hackee, striped_squirrel, ground_squirrel, tamias_striatus\",\n \"chipmunk\",\n \"baronduki, baranduki, barunduki, burunduki, eutamius_asiaticus, eutamius_sibiricus\",\n \"american_flying_squirrel\",\n \"southern_flying_squirrel, glaucomys_volans\",\n \"northern_flying_squirrel, glaucomys_sabrinus\",\n \"marmot\",\n \"groundhog, woodchuck, marmota_monax\",\n \"hoary_marmot, whistler, whistling_marmot, marmota_caligata\",\n \"yellowbelly_marmot, rockchuck, marmota_flaviventris\",\n \"asiatic_flying_squirrel\",\n \"beaver\",\n \"old_world_beaver, castor_fiber\",\n \"new_world_beaver, castor_canadensis\",\n \"mountain_beaver, sewellel, aplodontia_rufa\",\n \"cavy\",\n \"guinea_pig, cavia_cobaya\",\n \"aperea, wild_cavy, cavia_porcellus\",\n \"mara, dolichotis_patagonum\",\n \"capybara, capibara, hydrochoerus_hydrochaeris\",\n \"agouti, dasyprocta_aguti\",\n \"paca, cuniculus_paca\",\n \"mountain_paca\",\n \"coypu, nutria, myocastor_coypus\",\n \"chinchilla, chinchilla_laniger\",\n \"mountain_chinchilla, mountain_viscacha\",\n \"viscacha, chinchillon, lagostomus_maximus\",\n \"abrocome, chinchilla_rat, rat_chinchilla\",\n \"mole_rat\",\n \"mole_rat\",\n \"sand_rat\",\n \"naked_mole_rat\",\n \"queen, queen_mole_rat\",\n \"damaraland_mole_rat\",\n \"ungulata\",\n \"ungulate, hoofed_mammal\",\n \"unguiculate, unguiculate_mammal\",\n \"dinoceras, uintathere\",\n \"hyrax, coney, cony, dassie, das\",\n \"rock_hyrax, rock_rabbit, procavia_capensis\",\n \"odd-toed_ungulate, perissodactyl, perissodactyl_mammal\",\n \"equine, equid\",\n \"horse, equus_caballus\",\n \"roan\",\n \"stablemate, stable_companion\",\n \"gee-gee\",\n \"eohippus, dawn_horse\",\n \"foal\",\n \"filly\",\n \"colt\",\n \"male_horse\",\n \"ridgeling, ridgling, ridgel, ridgil\",\n \"stallion, entire\",\n \"stud, studhorse\",\n \"gelding\",\n \"mare, female_horse\",\n \"broodmare, stud_mare\",\n \"saddle_horse, riding_horse, mount\",\n \"remount\",\n \"palfrey\",\n \"warhorse\",\n \"cavalry_horse\",\n \"charger, courser\",\n \"steed\",\n \"prancer\",\n \"hack\",\n \"cow_pony\",\n \"quarter_horse\",\n \"morgan\",\n \"tennessee_walker, tennessee_walking_horse, walking_horse, plantation_walking_horse\",\n \"american_saddle_horse\",\n \"appaloosa\",\n \"arabian, arab\",\n \"lippizan, lipizzan, lippizaner\",\n \"pony\",\n \"polo_pony\",\n \"mustang\",\n \"bronco, bronc, broncho\",\n \"bucking_bronco\",\n \"buckskin\",\n \"crowbait, crow-bait\",\n \"dun\",\n \"grey, gray\",\n \"wild_horse\",\n \"tarpan, equus_caballus_gomelini\",\n \"przewalski's_horse, przevalski's_horse, equus_caballus_przewalskii, equus_caballus_przevalskii\",\n \"cayuse, indian_pony\",\n \"hack\",\n \"hack, jade, nag, plug\",\n \"plow_horse, plough_horse\",\n \"pony\",\n \"shetland_pony\",\n \"welsh_pony\",\n \"exmoor\",\n \"racehorse, race_horse, bangtail\",\n \"thoroughbred\",\n \"steeplechaser\",\n \"racer\",\n \"finisher\",\n \"pony\",\n \"yearling\",\n \"dark_horse\",\n \"mudder\",\n \"nonstarter\",\n \"stalking-horse\",\n \"harness_horse\",\n \"cob\",\n \"hackney\",\n \"workhorse\",\n \"draft_horse, draught_horse, dray_horse\",\n \"packhorse\",\n \"carthorse, cart_horse, drayhorse\",\n \"clydesdale\",\n \"percheron\",\n \"farm_horse, dobbin\",\n \"shire, shire_horse\",\n \"pole_horse, poler\",\n \"post_horse, post-horse, poster\",\n \"coach_horse\",\n \"pacer\",\n \"pacer, pacemaker, pacesetter\",\n \"trotting_horse, trotter\",\n \"pole_horse\",\n \"stepper, high_stepper\",\n \"chestnut\",\n \"liver_chestnut\",\n \"bay\",\n \"sorrel\",\n \"palomino\",\n \"pinto\",\n \"ass\",\n \"domestic_ass, donkey, equus_asinus\",\n \"burro\",\n \"moke\",\n \"jack, jackass\",\n \"jennet, jenny, jenny_ass\",\n \"mule\",\n \"hinny\",\n \"wild_ass\",\n \"african_wild_ass, equus_asinus\",\n \"kiang, equus_kiang\",\n \"onager, equus_hemionus\",\n \"chigetai, dziggetai, equus_hemionus_hemionus\",\n \"zebra\",\n \"common_zebra, burchell's_zebra, equus_burchelli\",\n \"mountain_zebra, equus_zebra_zebra\",\n \"grevy's_zebra, equus_grevyi\",\n \"quagga, equus_quagga\",\n \"rhinoceros, rhino\",\n \"indian_rhinoceros, rhinoceros_unicornis\",\n \"woolly_rhinoceros, rhinoceros_antiquitatis\",\n \"white_rhinoceros, ceratotherium_simum, diceros_simus\",\n \"black_rhinoceros, diceros_bicornis\",\n \"tapir\",\n \"new_world_tapir, tapirus_terrestris\",\n \"malayan_tapir, indian_tapir, tapirus_indicus\",\n \"even-toed_ungulate, artiodactyl, artiodactyl_mammal\",\n \"swine\",\n \"hog, pig, grunter, squealer, sus_scrofa\",\n \"piglet, piggy, shoat, shote\",\n \"sucking_pig\",\n \"porker\",\n \"boar\",\n \"sow\",\n \"razorback, razorback_hog, razorbacked_hog\",\n \"wild_boar, boar, sus_scrofa\",\n \"babirusa, babiroussa, babirussa, babyrousa_babyrussa\",\n \"warthog\",\n \"peccary, musk_hog\",\n \"collared_peccary, javelina, tayassu_angulatus, tayassu_tajacu, peccari_angulatus\",\n \"white-lipped_peccary, tayassu_pecari\",\n \"hippopotamus, hippo, river_horse, hippopotamus_amphibius\",\n \"ruminant\",\n \"bovid\",\n \"bovine\",\n \"ox, wild_ox\",\n \"cattle, cows, kine, oxen, bos_taurus\",\n \"ox\",\n \"stirk\",\n \"bullock, steer\",\n \"bull\",\n \"cow, moo-cow\",\n \"heifer\",\n \"bullock\",\n \"dogie, dogy, leppy\",\n \"maverick\",\n \"beef, beef_cattle\",\n \"longhorn, texas_longhorn\",\n \"brahman, brahma, brahmin, bos_indicus\",\n \"zebu\",\n \"aurochs, urus, bos_primigenius\",\n \"yak, bos_grunniens\",\n \"banteng, banting, tsine, bos_banteng\",\n \"welsh, welsh_black\",\n \"red_poll\",\n \"santa_gertrudis\",\n \"aberdeen_angus, angus, black_angus\",\n \"africander\",\n \"dairy_cattle, dairy_cow, milch_cow, milk_cow, milcher, milker\",\n \"ayrshire\",\n \"brown_swiss\",\n \"charolais\",\n \"jersey\",\n \"devon\",\n \"grade\",\n \"durham, shorthorn\",\n \"milking_shorthorn\",\n \"galloway\",\n \"friesian, holstein, holstein-friesian\",\n \"guernsey\",\n \"hereford, whiteface\",\n \"cattalo, beefalo\",\n \"old_world_buffalo, buffalo\",\n \"water_buffalo, water_ox, asiatic_buffalo, bubalus_bubalis\",\n \"indian_buffalo\",\n \"carabao\",\n \"anoa, dwarf_buffalo, anoa_depressicornis\",\n \"tamarau, tamarao, bubalus_mindorensis, anoa_mindorensis\",\n \"cape_buffalo, synercus_caffer\",\n \"asian_wild_ox\",\n \"gaur, bibos_gaurus\",\n \"gayal, mithan, bibos_frontalis\",\n \"bison\",\n \"american_bison, american_buffalo, buffalo, bison_bison\",\n \"wisent, aurochs, bison_bonasus\",\n \"musk_ox, musk_sheep, ovibos_moschatus\",\n \"sheep\",\n \"ewe\",\n \"ram, tup\",\n \"wether\",\n \"lamb\",\n \"lambkin\",\n \"baa-lamb\",\n \"hog, hogget, hogg\",\n \"teg\",\n \"persian_lamb\",\n \"black_sheep\",\n \"domestic_sheep, ovis_aries\",\n \"cotswold\",\n \"hampshire, hampshire_down\",\n \"lincoln\",\n \"exmoor\",\n \"cheviot\",\n \"broadtail, caracul, karakul\",\n \"longwool\",\n \"merino, merino_sheep\",\n \"rambouillet\",\n \"wild_sheep\",\n \"argali, argal, ovis_ammon\",\n \"marco_polo_sheep, marco_polo's_sheep, ovis_poli\",\n \"urial, ovis_vignei\",\n \"dall_sheep, dall's_sheep, white_sheep, ovis_montana_dalli\",\n \"mountain_sheep\",\n \"bighorn, bighorn_sheep, cimarron, rocky_mountain_bighorn, rocky_mountain_sheep, ovis_canadensis\",\n \"mouflon, moufflon, ovis_musimon\",\n \"aoudad, arui, audad, barbary_sheep, maned_sheep, ammotragus_lervia\",\n \"goat, caprine_animal\",\n \"kid\",\n \"billy, billy_goat, he-goat\",\n \"nanny, nanny-goat, she-goat\",\n \"domestic_goat, capra_hircus\",\n \"cashmere_goat, kashmir_goat\",\n \"angora, angora_goat\",\n \"wild_goat\",\n \"bezoar_goat, pasang, capra_aegagrus\",\n \"markhor, markhoor, capra_falconeri\",\n \"ibex, capra_ibex\",\n \"goat_antelope\",\n \"mountain_goat, rocky_mountain_goat, oreamnos_americanus\",\n \"goral, naemorhedus_goral\",\n \"serow\",\n \"chamois, rupicapra_rupicapra\",\n \"takin, gnu_goat, budorcas_taxicolor\",\n \"antelope\",\n \"blackbuck, black_buck, antilope_cervicapra\",\n \"gerenuk, litocranius_walleri\",\n \"addax, addax_nasomaculatus\",\n \"gnu, wildebeest\",\n \"dik-dik\",\n \"hartebeest\",\n \"sassaby, topi, damaliscus_lunatus\",\n \"impala, aepyceros_melampus\",\n \"gazelle\",\n \"thomson's_gazelle, gazella_thomsoni\",\n \"gazella_subgutturosa\",\n \"springbok, springbuck, antidorcas_marsupialis, antidorcas_euchore\",\n \"bongo, tragelaphus_eurycerus, boocercus_eurycerus\",\n \"kudu, koodoo, koudou\",\n \"greater_kudu, tragelaphus_strepsiceros\",\n \"lesser_kudu, tragelaphus_imberbis\",\n \"harnessed_antelope\",\n \"nyala, tragelaphus_angasi\",\n \"mountain_nyala, tragelaphus_buxtoni\",\n \"bushbuck, guib, tragelaphus_scriptus\",\n \"nilgai, nylghai, nylghau, blue_bull, boselaphus_tragocamelus\",\n \"sable_antelope, hippotragus_niger\",\n \"saiga, saiga_tatarica\",\n \"steenbok, steinbok, raphicerus_campestris\",\n \"eland\",\n \"common_eland, taurotragus_oryx\",\n \"giant_eland, taurotragus_derbianus\",\n \"kob, kobus_kob\",\n \"lechwe, kobus_leche\",\n \"waterbuck\",\n \"puku, adenota_vardoni\",\n \"oryx, pasang\",\n \"gemsbok, gemsbuck, oryx_gazella\",\n \"forest_goat, spindle_horn, pseudoryx_nghetinhensis\",\n \"pronghorn, prongbuck, pronghorn_antelope, american_antelope, antilocapra_americana\",\n \"deer, cervid\",\n \"stag\",\n \"royal, royal_stag\",\n \"pricket\",\n \"fawn\",\n \"red_deer, elk, american_elk, wapiti, cervus_elaphus\",\n \"hart, stag\",\n \"hind\",\n \"brocket\",\n \"sambar, sambur, cervus_unicolor\",\n \"wapiti, elk, american_elk, cervus_elaphus_canadensis\",\n \"japanese_deer, sika, cervus_nipon, cervus_sika\",\n \"virginia_deer, white_tail, whitetail, white-tailed_deer, whitetail_deer, odocoileus_virginianus\",\n \"mule_deer, burro_deer, odocoileus_hemionus\",\n \"black-tailed_deer, blacktail_deer, blacktail, odocoileus_hemionus_columbianus\",\n \"elk, european_elk, moose, alces_alces\",\n \"fallow_deer, dama_dama\",\n \"roe_deer, capreolus_capreolus\",\n \"roebuck\",\n \"caribou, reindeer, greenland_caribou, rangifer_tarandus\",\n \"woodland_caribou, rangifer_caribou\",\n \"barren_ground_caribou, rangifer_arcticus\",\n \"brocket\",\n \"muntjac, barking_deer\",\n \"musk_deer, moschus_moschiferus\",\n \"pere_david's_deer, elaphure, elaphurus_davidianus\",\n \"chevrotain, mouse_deer\",\n \"kanchil, tragulus_kanchil\",\n \"napu, tragulus_javanicus\",\n \"water_chevrotain, water_deer, hyemoschus_aquaticus\",\n \"camel\",\n \"arabian_camel, dromedary, camelus_dromedarius\",\n \"bactrian_camel, camelus_bactrianus\",\n \"llama\",\n \"domestic_llama, lama_peruana\",\n \"guanaco, lama_guanicoe\",\n \"alpaca, lama_pacos\",\n \"vicuna, vicugna_vicugna\",\n \"giraffe, camelopard, giraffa_camelopardalis\",\n \"okapi, okapia_johnstoni\",\n \"musteline_mammal, mustelid, musteline\",\n \"weasel\",\n \"ermine, shorttail_weasel, mustela_erminea\",\n \"stoat\",\n \"new_world_least_weasel, mustela_rixosa\",\n \"old_world_least_weasel, mustela_nivalis\",\n \"longtail_weasel, long-tailed_weasel, mustela_frenata\",\n \"mink\",\n \"american_mink, mustela_vison\",\n \"polecat, fitch, foulmart, foumart, mustela_putorius\",\n \"ferret\",\n \"black-footed_ferret, ferret, mustela_nigripes\",\n \"muishond\",\n \"snake_muishond, poecilogale_albinucha\",\n \"striped_muishond, ictonyx_striata\",\n \"otter\",\n \"river_otter, lutra_canadensis\",\n \"eurasian_otter, lutra_lutra\",\n \"sea_otter, enhydra_lutris\",\n \"skunk, polecat, wood_pussy\",\n \"striped_skunk, mephitis_mephitis\",\n \"hooded_skunk, mephitis_macroura\",\n \"hog-nosed_skunk, hognosed_skunk, badger_skunk, rooter_skunk, conepatus_leuconotus\",\n \"spotted_skunk, little_spotted_skunk, spilogale_putorius\",\n \"badger\",\n \"american_badger, taxidea_taxus\",\n \"eurasian_badger, meles_meles\",\n \"ratel, honey_badger, mellivora_capensis\",\n \"ferret_badger\",\n \"hog_badger, hog-nosed_badger, sand_badger, arctonyx_collaris\",\n \"wolverine, carcajou, skunk_bear, gulo_luscus\",\n \"glutton, gulo_gulo, wolverine\",\n \"grison, grison_vittatus, galictis_vittatus\",\n \"marten, marten_cat\",\n \"pine_marten, martes_martes\",\n \"sable, martes_zibellina\",\n \"american_marten, american_sable, martes_americana\",\n \"stone_marten, beech_marten, martes_foina\",\n \"fisher, pekan, fisher_cat, black_cat, martes_pennanti\",\n \"yellow-throated_marten, charronia_flavigula\",\n \"tayra, taira, eira_barbara\",\n \"fictional_animal\",\n \"pachyderm\",\n \"edentate\",\n \"armadillo\",\n \"peba, nine-banded_armadillo, texas_armadillo, dasypus_novemcinctus\",\n \"apar, three-banded_armadillo, tolypeutes_tricinctus\",\n \"tatouay, cabassous, cabassous_unicinctus\",\n \"peludo, poyou, euphractus_sexcinctus\",\n \"giant_armadillo, tatou, tatu, priodontes_giganteus\",\n \"pichiciago, pichiciego, fairy_armadillo, chlamyphore, chlamyphorus_truncatus\",\n \"sloth, tree_sloth\",\n \"three-toed_sloth, ai, bradypus_tridactylus\",\n \"two-toed_sloth, unau, unai, choloepus_didactylus\",\n \"two-toed_sloth, unau, unai, choloepus_hoffmanni\",\n \"megatherian, megatheriid, megatherian_mammal\",\n \"mylodontid\",\n \"anteater, new_world_anteater\",\n \"ant_bear, giant_anteater, great_anteater, tamanoir, myrmecophaga_jubata\",\n \"silky_anteater, two-toed_anteater, cyclopes_didactylus\",\n \"tamandua, tamandu, lesser_anteater, tamandua_tetradactyla\",\n \"pangolin, scaly_anteater, anteater\",\n \"coronet\",\n \"scapular\",\n \"tadpole, polliwog, pollywog\",\n \"primate\",\n \"simian\",\n \"ape\",\n \"anthropoid\",\n \"anthropoid_ape\",\n \"hominoid\",\n \"hominid\",\n \"homo, man, human_being, human\",\n \"world, human_race, humanity, humankind, human_beings, humans, mankind, man\",\n \"homo_erectus\",\n \"pithecanthropus, pithecanthropus_erectus, genus_pithecanthropus\",\n \"java_man, trinil_man\",\n \"peking_man\",\n \"sinanthropus, genus_sinanthropus\",\n \"homo_soloensis\",\n \"javanthropus, genus_javanthropus\",\n \"homo_habilis\",\n \"homo_sapiens\",\n \"neandertal_man, neanderthal_man, neandertal, neanderthal, homo_sapiens_neanderthalensis\",\n \"cro-magnon\",\n \"homo_sapiens_sapiens, modern_man\",\n \"australopithecine\",\n \"australopithecus_afarensis\",\n \"australopithecus_africanus\",\n \"australopithecus_boisei\",\n \"zinjanthropus, genus_zinjanthropus\",\n \"australopithecus_robustus\",\n \"paranthropus, genus_paranthropus\",\n \"sivapithecus\",\n \"rudapithecus, dryopithecus_rudapithecus_hungaricus\",\n \"proconsul\",\n \"aegyptopithecus\",\n \"great_ape, pongid\",\n \"orangutan, orang, orangutang, pongo_pygmaeus\",\n \"gorilla, gorilla_gorilla\",\n \"western_lowland_gorilla, gorilla_gorilla_gorilla\",\n \"eastern_lowland_gorilla, gorilla_gorilla_grauri\",\n \"mountain_gorilla, gorilla_gorilla_beringei\",\n \"silverback\",\n \"chimpanzee, chimp, pan_troglodytes\",\n \"western_chimpanzee, pan_troglodytes_verus\",\n \"eastern_chimpanzee, pan_troglodytes_schweinfurthii\",\n \"central_chimpanzee, pan_troglodytes_troglodytes\",\n \"pygmy_chimpanzee, bonobo, pan_paniscus\",\n \"lesser_ape\",\n \"gibbon, hylobates_lar\",\n \"siamang, hylobates_syndactylus, symphalangus_syndactylus\",\n \"monkey\",\n \"old_world_monkey, catarrhine\",\n \"guenon, guenon_monkey\",\n \"talapoin, cercopithecus_talapoin\",\n \"grivet, cercopithecus_aethiops\",\n \"vervet, vervet_monkey, cercopithecus_aethiops_pygerythrus\",\n \"green_monkey, african_green_monkey, cercopithecus_aethiops_sabaeus\",\n \"mangabey\",\n \"patas, hussar_monkey, erythrocebus_patas\",\n \"baboon\",\n \"chacma, chacma_baboon, papio_ursinus\",\n \"mandrill, mandrillus_sphinx\",\n \"drill, mandrillus_leucophaeus\",\n \"macaque\",\n \"rhesus, rhesus_monkey, macaca_mulatta\",\n \"bonnet_macaque, bonnet_monkey, capped_macaque, crown_monkey, macaca_radiata\",\n \"barbary_ape, macaca_sylvana\",\n \"crab-eating_macaque, croo_monkey, macaca_irus\",\n \"langur\",\n \"entellus, hanuman, presbytes_entellus, semnopithecus_entellus\",\n \"colobus, colobus_monkey\",\n \"guereza, colobus_guereza\",\n \"proboscis_monkey, nasalis_larvatus\",\n \"new_world_monkey, platyrrhine, platyrrhinian\",\n \"marmoset\",\n \"true_marmoset\",\n \"pygmy_marmoset, cebuella_pygmaea\",\n \"tamarin, lion_monkey, lion_marmoset, leoncita\",\n \"silky_tamarin, leontocebus_rosalia\",\n \"pinche, leontocebus_oedipus\",\n \"capuchin, ringtail, cebus_capucinus\",\n \"douroucouli, aotus_trivirgatus\",\n \"howler_monkey, howler\",\n \"saki\",\n \"uakari\",\n \"titi, titi_monkey\",\n \"spider_monkey, ateles_geoffroyi\",\n \"squirrel_monkey, saimiri_sciureus\",\n \"woolly_monkey\",\n \"tree_shrew\",\n \"prosimian\",\n \"lemur\",\n \"madagascar_cat, ring-tailed_lemur, lemur_catta\",\n \"aye-aye, daubentonia_madagascariensis\",\n \"slender_loris, loris_gracilis\",\n \"slow_loris, nycticebus_tardigradua, nycticebus_pygmaeus\",\n \"potto, kinkajou, perodicticus_potto\",\n \"angwantibo, golden_potto, arctocebus_calabarensis\",\n \"galago, bushbaby, bush_baby\",\n \"indri, indris, indri_indri, indri_brevicaudatus\",\n \"woolly_indris, avahi_laniger\",\n \"tarsier\",\n \"tarsius_syrichta\",\n \"tarsius_glis\",\n \"flying_lemur, flying_cat, colugo\",\n \"cynocephalus_variegatus\",\n \"proboscidean, proboscidian\",\n \"elephant\",\n \"rogue_elephant\",\n \"indian_elephant, elephas_maximus\",\n \"african_elephant, loxodonta_africana\",\n \"mammoth\",\n \"woolly_mammoth, northern_mammoth, mammuthus_primigenius\",\n \"columbian_mammoth, mammuthus_columbi\",\n \"imperial_mammoth, imperial_elephant, archidiskidon_imperator\",\n \"mastodon, mastodont\",\n \"plantigrade_mammal, plantigrade\",\n \"digitigrade_mammal, digitigrade\",\n \"procyonid\",\n \"raccoon, racoon\",\n \"common_raccoon, common_racoon, coon, ringtail, procyon_lotor\",\n \"crab-eating_raccoon, procyon_cancrivorus\",\n \"bassarisk, cacomistle, cacomixle, coon_cat, raccoon_fox, ringtail, ring-tailed_cat, civet_cat, miner's_cat, bassariscus_astutus\",\n \"kinkajou, honey_bear, potto, potos_flavus, potos_caudivolvulus\",\n \"coati, coati-mondi, coati-mundi, coon_cat, nasua_narica\",\n \"lesser_panda, red_panda, panda, bear_cat, cat_bear, ailurus_fulgens\",\n \"giant_panda, panda, panda_bear, coon_bear, ailuropoda_melanoleuca\",\n \"twitterer\",\n \"fish\",\n \"fingerling\",\n \"game_fish, sport_fish\",\n \"food_fish\",\n \"rough_fish\",\n \"groundfish, bottom_fish\",\n \"young_fish\",\n \"parr\",\n \"mouthbreeder\",\n \"spawner\",\n \"barracouta, snoek\",\n \"crossopterygian, lobefin, lobe-finned_fish\",\n \"coelacanth, latimeria_chalumnae\",\n \"lungfish\",\n \"ceratodus\",\n \"catfish, siluriform_fish\",\n \"silurid, silurid_fish\",\n \"european_catfish, sheatfish, silurus_glanis\",\n \"electric_catfish, malopterurus_electricus\",\n \"bullhead, bullhead_catfish\",\n \"horned_pout, hornpout, pout, ameiurus_melas\",\n \"brown_bullhead\",\n \"channel_catfish, channel_cat, ictalurus_punctatus\",\n \"blue_catfish, blue_cat, blue_channel_catfish, blue_channel_cat\",\n \"flathead_catfish, mudcat, goujon, shovelnose_catfish, spoonbill_catfish, pylodictus_olivaris\",\n \"armored_catfish\",\n \"sea_catfish\",\n \"gadoid, gadoid_fish\",\n \"cod, codfish\",\n \"codling\",\n \"atlantic_cod, gadus_morhua\",\n \"pacific_cod, alaska_cod, gadus_macrocephalus\",\n \"whiting, merlangus_merlangus, gadus_merlangus\",\n \"burbot, eelpout, ling, cusk, lota_lota\",\n \"haddock, melanogrammus_aeglefinus\",\n \"pollack, pollock, pollachius_pollachius\",\n \"hake\",\n \"silver_hake, merluccius_bilinearis, whiting\",\n \"ling\",\n \"cusk, torsk, brosme_brosme\",\n \"grenadier, rattail, rattail_fish\",\n \"eel\",\n \"elver\",\n \"common_eel, freshwater_eel\",\n \"tuna, anguilla_sucklandii\",\n \"moray, moray_eel\",\n \"conger, conger_eel\",\n \"teleost_fish, teleost, teleostan\",\n \"beaked_salmon, sandfish, gonorhynchus_gonorhynchus\",\n \"clupeid_fish, clupeid\",\n \"whitebait\",\n \"brit, britt\",\n \"shad\",\n \"common_american_shad, alosa_sapidissima\",\n \"river_shad, alosa_chrysocloris\",\n \"allice_shad, allis_shad, allice, allis, alosa_alosa\",\n \"alewife, alosa_pseudoharengus, pomolobus_pseudoharengus\",\n \"menhaden, brevoortia_tyrannis\",\n \"herring, clupea_harangus\",\n \"atlantic_herring, clupea_harengus_harengus\",\n \"pacific_herring, clupea_harengus_pallasii\",\n \"sardine\",\n \"sild\",\n \"brisling, sprat, clupea_sprattus\",\n \"pilchard, sardine, sardina_pilchardus\",\n \"pacific_sardine, sardinops_caerulea\",\n \"anchovy\",\n \"mediterranean_anchovy, engraulis_encrasicholus\",\n \"salmonid\",\n \"salmon\",\n \"parr\",\n \"blackfish\",\n \"redfish\",\n \"atlantic_salmon, salmo_salar\",\n \"landlocked_salmon, lake_salmon\",\n \"sockeye, sockeye_salmon, red_salmon, blueback_salmon, oncorhynchus_nerka\",\n \"chinook, chinook_salmon, king_salmon, quinnat_salmon, oncorhynchus_tshawytscha\",\n \"coho, cohoe, coho_salmon, blue_jack, silver_salmon, oncorhynchus_kisutch\",\n \"trout\",\n \"brown_trout, salmon_trout, salmo_trutta\",\n \"rainbow_trout, salmo_gairdneri\",\n \"sea_trout\",\n \"lake_trout, salmon_trout, salvelinus_namaycush\",\n \"brook_trout, speckled_trout, salvelinus_fontinalis\",\n \"char, charr\",\n \"arctic_char, salvelinus_alpinus\",\n \"whitefish\",\n \"lake_whitefish, coregonus_clupeaformis\",\n \"cisco, lake_herring, coregonus_artedi\",\n \"round_whitefish, menominee_whitefish, prosopium_cylindraceum\",\n \"smelt\",\n \"sparling, european_smelt, osmerus_eperlanus\",\n \"capelin, capelan, caplin\",\n \"tarpon, tarpon_atlanticus\",\n \"ladyfish, tenpounder, elops_saurus\",\n \"bonefish, albula_vulpes\",\n \"argentine\",\n \"lanternfish\",\n \"lizardfish, snakefish, snake-fish\",\n \"lancetfish, lancet_fish, wolffish\",\n \"opah, moonfish, lampris_regius\",\n \"new_world_opah, lampris_guttatus\",\n \"ribbonfish\",\n \"dealfish, trachipterus_arcticus\",\n \"oarfish, king_of_the_herring, ribbonfish, regalecus_glesne\",\n \"batfish\",\n \"goosefish, angler, anglerfish, angler_fish, monkfish, lotte, allmouth, lophius_americanus\",\n \"toadfish, opsanus_tau\",\n \"oyster_fish, oyster-fish, oysterfish\",\n \"frogfish\",\n \"sargassum_fish\",\n \"needlefish, gar, billfish\",\n \"timucu\",\n \"flying_fish\",\n \"monoplane_flying_fish, two-wing_flying_fish\",\n \"halfbeak\",\n \"saury, billfish, scomberesox_saurus\",\n \"spiny-finned_fish, acanthopterygian\",\n \"lingcod, ophiodon_elongatus\",\n \"percoid_fish, percoid, percoidean\",\n \"perch\",\n \"climbing_perch, anabas_testudineus, a._testudineus\",\n \"perch\",\n \"yellow_perch, perca_flavescens\",\n \"european_perch, perca_fluviatilis\",\n \"pike-perch, pike_perch\",\n \"walleye, walleyed_pike, jack_salmon, dory, stizostedion_vitreum\",\n \"blue_pike, blue_pickerel, blue_pikeperch, blue_walleye, strizostedion_vitreum_glaucum\",\n \"snail_darter, percina_tanasi\",\n \"cusk-eel\",\n \"brotula\",\n \"pearlfish, pearl-fish\",\n \"robalo\",\n \"snook\",\n \"pike\",\n \"northern_pike, esox_lucius\",\n \"muskellunge, esox_masquinongy\",\n \"pickerel\",\n \"chain_pickerel, chain_pike, esox_niger\",\n \"redfin_pickerel, barred_pickerel, esox_americanus\",\n \"sunfish, centrarchid\",\n \"crappie\",\n \"black_crappie, pomoxis_nigromaculatus\",\n \"white_crappie, pomoxis_annularis\",\n \"freshwater_bream, bream\",\n \"pumpkinseed, lepomis_gibbosus\",\n \"bluegill, lepomis_macrochirus\",\n \"spotted_sunfish, stumpknocker, lepomis_punctatus\",\n \"freshwater_bass\",\n \"rock_bass, rock_sunfish, ambloplites_rupestris\",\n \"black_bass\",\n \"kentucky_black_bass, spotted_black_bass, micropterus_pseudoplites\",\n \"smallmouth, smallmouth_bass, smallmouthed_bass, smallmouth_black_bass, smallmouthed_black_bass, micropterus_dolomieu\",\n \"largemouth, largemouth_bass, largemouthed_bass, largemouth_black_bass, largemouthed_black_bass, micropterus_salmoides\",\n \"bass\",\n \"serranid_fish, serranid\",\n \"white_perch, silver_perch, morone_americana\",\n \"yellow_bass, morone_interrupta\",\n \"blackmouth_bass, synagrops_bellus\",\n \"rock_sea_bass, rock_bass, centropristis_philadelphica\",\n \"striped_bass, striper, roccus_saxatilis, rockfish\",\n \"stone_bass, wreckfish, polyprion_americanus\",\n \"grouper\",\n \"hind\",\n \"rock_hind, epinephelus_adscensionis\",\n \"creole-fish, paranthias_furcifer\",\n \"jewfish, mycteroperca_bonaci\",\n \"soapfish\",\n \"surfperch, surffish, surf_fish\",\n \"rainbow_seaperch, rainbow_perch, hipsurus_caryi\",\n \"bigeye\",\n \"catalufa, priacanthus_arenatus\",\n \"cardinalfish\",\n \"flame_fish, flamefish, apogon_maculatus\",\n \"tilefish, lopholatilus_chamaeleonticeps\",\n \"bluefish, pomatomus_saltatrix\",\n \"cobia, rachycentron_canadum, sergeant_fish\",\n \"remora, suckerfish, sucking_fish\",\n \"sharksucker, echeneis_naucrates\",\n \"whale_sucker, whalesucker, remilegia_australis\",\n \"carangid_fish, carangid\",\n \"jack\",\n \"crevalle_jack, jack_crevalle, caranx_hippos\",\n \"yellow_jack, caranx_bartholomaei\",\n \"runner, blue_runner, caranx_crysos\",\n \"rainbow_runner, elagatis_bipinnulata\",\n \"leatherjacket, leatherjack\",\n \"threadfish, thread-fish, alectis_ciliaris\",\n \"moonfish, atlantic_moonfish, horsefish, horsehead, horse-head, dollarfish, selene_setapinnis\",\n \"lookdown, lookdown_fish, selene_vomer\",\n \"amberjack, amberfish\",\n \"yellowtail, seriola_dorsalis\",\n \"kingfish, seriola_grandis\",\n \"pompano\",\n \"florida_pompano, trachinotus_carolinus\",\n \"permit, trachinotus_falcatus\",\n \"scad\",\n \"horse_mackerel, jack_mackerel, spanish_mackerel, saurel, trachurus_symmetricus\",\n \"horse_mackerel, saurel, trachurus_trachurus\",\n \"bigeye_scad, big-eyed_scad, goggle-eye, selar_crumenophthalmus\",\n \"mackerel_scad, mackerel_shad, decapterus_macarellus\",\n \"round_scad, cigarfish, quiaquia, decapterus_punctatus\",\n \"dolphinfish, dolphin, mahimahi\",\n \"coryphaena_hippurus\",\n \"coryphaena_equisetis\",\n \"pomfret, brama_raii\",\n \"characin, characin_fish, characid\",\n \"tetra\",\n \"cardinal_tetra, paracheirodon_axelrodi\",\n \"piranha, pirana, caribe\",\n \"cichlid, cichlid_fish\",\n \"bolti, tilapia_nilotica\",\n \"snapper\",\n \"red_snapper, lutjanus_blackfordi\",\n \"grey_snapper, gray_snapper, mangrove_snapper, lutjanus_griseus\",\n \"mutton_snapper, muttonfish, lutjanus_analis\",\n \"schoolmaster, lutjanus_apodus\",\n \"yellowtail, yellowtail_snapper, ocyurus_chrysurus\",\n \"grunt\",\n \"margate, haemulon_album\",\n \"spanish_grunt, haemulon_macrostomum\",\n \"tomtate, haemulon_aurolineatum\",\n \"cottonwick, haemulon_malanurum\",\n \"sailor's-choice, sailors_choice, haemulon_parra\",\n \"porkfish, pork-fish, anisotremus_virginicus\",\n \"pompon, black_margate, anisotremus_surinamensis\",\n \"pigfish, hogfish, orthopristis_chrysopterus\",\n \"sparid, sparid_fish\",\n \"sea_bream, bream\",\n \"porgy\",\n \"red_porgy, pagrus_pagrus\",\n \"european_sea_bream, pagellus_centrodontus\",\n \"atlantic_sea_bream, archosargus_rhomboidalis\",\n \"sheepshead, archosargus_probatocephalus\",\n \"pinfish, sailor's-choice, squirrelfish, lagodon_rhomboides\",\n \"sheepshead_porgy, calamus_penna\",\n \"snapper, chrysophrys_auratus\",\n \"black_bream, chrysophrys_australis\",\n \"scup, northern_porgy, northern_scup, stenotomus_chrysops\",\n \"scup, southern_porgy, southern_scup, stenotomus_aculeatus\",\n \"sciaenid_fish, sciaenid\",\n \"striped_drum, equetus_pulcher\",\n \"jackknife-fish, equetus_lanceolatus\",\n \"silver_perch, mademoiselle, bairdiella_chrysoura\",\n \"red_drum, channel_bass, redfish, sciaenops_ocellatus\",\n \"mulloway, jewfish, sciaena_antarctica\",\n \"maigre, maiger, sciaena_aquila\",\n \"croaker\",\n \"atlantic_croaker, micropogonias_undulatus\",\n \"yellowfin_croaker, surffish, surf_fish, umbrina_roncador\",\n \"whiting\",\n \"kingfish\",\n \"king_whiting, menticirrhus_americanus\",\n \"northern_whiting, menticirrhus_saxatilis\",\n \"corbina, menticirrhus_undulatus\",\n \"white_croaker, chenfish, kingfish, genyonemus_lineatus\",\n \"white_croaker, queenfish, seriphus_politus\",\n \"sea_trout\",\n \"weakfish, cynoscion_regalis\",\n \"spotted_weakfish, spotted_sea_trout, spotted_squeateague, cynoscion_nebulosus\",\n \"mullet\",\n \"goatfish, red_mullet, surmullet, mullus_surmuletus\",\n \"red_goatfish, mullus_auratus\",\n \"yellow_goatfish, mulloidichthys_martinicus\",\n \"mullet, grey_mullet, gray_mullet\",\n \"striped_mullet, mugil_cephalus\",\n \"white_mullet, mugil_curema\",\n \"liza, mugil_liza\",\n \"silversides, silverside\",\n \"jacksmelt, atherinopsis_californiensis\",\n \"barracuda\",\n \"great_barracuda, sphyraena_barracuda\",\n \"sweeper\",\n \"sea_chub\",\n \"bermuda_chub, rudderfish, kyphosus_sectatrix\",\n \"spadefish, angelfish, chaetodipterus_faber\",\n \"butterfly_fish\",\n \"chaetodon\",\n \"angelfish\",\n \"rock_beauty, holocanthus_tricolor\",\n \"damselfish, demoiselle\",\n \"beaugregory, pomacentrus_leucostictus\",\n \"anemone_fish\",\n \"clown_anemone_fish, amphiprion_percula\",\n \"sergeant_major, abudefduf_saxatilis\",\n \"wrasse\",\n \"pigfish, giant_pigfish, achoerodus_gouldii\",\n \"hogfish, hog_snapper, lachnolaimus_maximus\",\n \"slippery_dick, halicoeres_bivittatus\",\n \"puddingwife, pudding-wife, halicoeres_radiatus\",\n \"bluehead, thalassoma_bifasciatum\",\n \"pearly_razorfish, hemipteronatus_novacula\",\n \"tautog, blackfish, tautoga_onitis\",\n \"cunner, bergall, tautogolabrus_adspersus\",\n \"parrotfish, polly_fish, pollyfish\",\n \"threadfin\",\n \"jawfish\",\n \"stargazer\",\n \"sand_stargazer\",\n \"blenny, combtooth_blenny\",\n \"shanny, blennius_pholis\",\n \"molly_miller, scartella_cristata\",\n \"clinid, clinid_fish\",\n \"pikeblenny\",\n \"bluethroat_pikeblenny, chaenopsis_ocellata\",\n \"gunnel, bracketed_blenny\",\n \"rock_gunnel, butterfish, pholis_gunnellus\",\n \"eelblenny\",\n \"wrymouth, ghostfish, cryptacanthodes_maculatus\",\n \"wolffish, wolf_fish, catfish\",\n \"viviparous_eelpout, zoarces_viviparus\",\n \"ocean_pout, macrozoarces_americanus\",\n \"sand_lance, sand_launce, sand_eel, launce\",\n \"dragonet\",\n \"goby, gudgeon\",\n \"mudskipper, mudspringer\",\n \"sleeper, sleeper_goby\",\n \"flathead\",\n \"archerfish, toxotes_jaculatrix\",\n \"surgeonfish\",\n \"gempylid\",\n \"snake_mackerel, gempylus_serpens\",\n \"escolar, lepidocybium_flavobrunneum\",\n \"oilfish, ruvettus_pretiosus\",\n \"cutlassfish, frost_fish, hairtail\",\n \"scombroid, scombroid_fish\",\n \"mackerel\",\n \"common_mackerel, shiner, scomber_scombrus\",\n \"spanish_mackerel, scomber_colias\",\n \"chub_mackerel, tinker, scomber_japonicus\",\n \"wahoo, acanthocybium_solandri\",\n \"spanish_mackerel\",\n \"king_mackerel, cavalla, cero, scomberomorus_cavalla\",\n \"scomberomorus_maculatus\",\n \"cero, pintado, kingfish, scomberomorus_regalis\",\n \"sierra, scomberomorus_sierra\",\n \"tuna, tunny\",\n \"albacore, long-fin_tunny, thunnus_alalunga\",\n \"bluefin, bluefin_tuna, horse_mackerel, thunnus_thynnus\",\n \"yellowfin, yellowfin_tuna, thunnus_albacares\",\n \"bonito\",\n \"skipjack, atlantic_bonito, sarda_sarda\",\n \"chile_bonito, chilean_bonito, pacific_bonito, sarda_chiliensis\",\n \"skipjack, skipjack_tuna, euthynnus_pelamis\",\n \"bonito, oceanic_bonito, katsuwonus_pelamis\",\n \"swordfish, xiphias_gladius\",\n \"sailfish\",\n \"atlantic_sailfish, istiophorus_albicans\",\n \"billfish\",\n \"marlin\",\n \"blue_marlin, makaira_nigricans\",\n \"black_marlin, makaira_mazara, makaira_marlina\",\n \"striped_marlin, makaira_mitsukurii\",\n \"white_marlin, makaira_albida\",\n \"spearfish\",\n \"louvar, luvarus_imperialis\",\n \"dollarfish, poronotus_triacanthus\",\n \"palometa, california_pompano, palometa_simillima\",\n \"harvestfish, paprilus_alepidotus\",\n \"driftfish\",\n \"barrelfish, black_rudderfish, hyperglyphe_perciformis\",\n \"clingfish\",\n \"tripletail\",\n \"atlantic_tripletail, lobotes_surinamensis\",\n \"pacific_tripletail, lobotes_pacificus\",\n \"mojarra\",\n \"yellowfin_mojarra, gerres_cinereus\",\n \"silver_jenny, eucinostomus_gula\",\n \"whiting\",\n \"ganoid, ganoid_fish\",\n \"bowfin, grindle, dogfish, amia_calva\",\n \"paddlefish, duckbill, polyodon_spathula\",\n \"chinese_paddlefish, psephurus_gladis\",\n \"sturgeon\",\n \"pacific_sturgeon, white_sturgeon, sacramento_sturgeon, acipenser_transmontanus\",\n \"beluga, hausen, white_sturgeon, acipenser_huso\",\n \"gar, garfish, garpike, billfish, lepisosteus_osseus\",\n \"scorpaenoid, scorpaenoid_fish\",\n \"scorpaenid, scorpaenid_fish\",\n \"scorpionfish, scorpion_fish, sea_scorpion\",\n \"plumed_scorpionfish, scorpaena_grandicornis\",\n \"lionfish\",\n \"stonefish, synanceja_verrucosa\",\n \"rockfish\",\n \"copper_rockfish, sebastodes_caurinus\",\n \"vermillion_rockfish, rasher, sebastodes_miniatus\",\n \"red_rockfish, sebastodes_ruberrimus\",\n \"rosefish, ocean_perch, sebastodes_marinus\",\n \"bullhead\",\n \"miller's-thumb\",\n \"sea_raven, hemitripterus_americanus\",\n \"lumpfish, cyclopterus_lumpus\",\n \"lumpsucker\",\n \"pogge, armed_bullhead, agonus_cataphractus\",\n \"greenling\",\n \"kelp_greenling, hexagrammos_decagrammus\",\n \"painted_greenling, convict_fish, convictfish, oxylebius_pictus\",\n \"flathead\",\n \"gurnard\",\n \"tub_gurnard, yellow_gurnard, trigla_lucerna\",\n \"sea_robin, searobin\",\n \"northern_sea_robin, prionotus_carolinus\",\n \"flying_gurnard, flying_robin, butterflyfish\",\n \"plectognath, plectognath_fish\",\n \"triggerfish\",\n \"queen_triggerfish, bessy_cerca, oldwench, oldwife, balistes_vetula\",\n \"filefish\",\n \"leatherjacket, leatherfish\",\n \"boxfish, trunkfish\",\n \"cowfish, lactophrys_quadricornis\",\n \"puffer, pufferfish, blowfish, globefish\",\n \"spiny_puffer\",\n \"porcupinefish, porcupine_fish, diodon_hystrix\",\n \"balloonfish, diodon_holocanthus\",\n \"burrfish\",\n \"ocean_sunfish, sunfish, mola, headfish\",\n \"sharptail_mola, mola_lanceolata\",\n \"flatfish\",\n \"flounder\",\n \"righteye_flounder, righteyed_flounder\",\n \"plaice, pleuronectes_platessa\",\n \"european_flatfish, platichthys_flesus\",\n \"yellowtail_flounder, limanda_ferruginea\",\n \"winter_flounder, blackback_flounder, lemon_sole, pseudopleuronectes_americanus\",\n \"lemon_sole, microstomus_kitt\",\n \"american_plaice, hippoglossoides_platessoides\",\n \"halibut, holibut\",\n \"atlantic_halibut, hippoglossus_hippoglossus\",\n \"pacific_halibut, hippoglossus_stenolepsis\",\n \"lefteye_flounder, lefteyed_flounder\",\n \"southern_flounder, paralichthys_lethostigmus\",\n \"summer_flounder, paralichthys_dentatus\",\n \"whiff\",\n \"horned_whiff, citharichthys_cornutus\",\n \"sand_dab\",\n \"windowpane, scophthalmus_aquosus\",\n \"brill, scophthalmus_rhombus\",\n \"turbot, psetta_maxima\",\n \"tonguefish, tongue-fish\",\n \"sole\",\n \"european_sole, solea_solea\",\n \"english_sole, lemon_sole, parophrys_vitulus\",\n \"hogchoker, trinectes_maculatus\",\n \"aba\",\n \"abacus\",\n \"abandoned_ship, derelict\",\n \"a_battery\",\n \"abattoir, butchery, shambles, slaughterhouse\",\n \"abaya\",\n \"abbe_condenser\",\n \"abbey\",\n \"abbey\",\n \"abbey\",\n \"abney_level\",\n \"abrader, abradant\",\n \"abrading_stone\",\n \"abutment\",\n \"abutment_arch\",\n \"academic_costume\",\n \"academic_gown, academic_robe, judge's_robe\",\n \"accelerator, throttle, throttle_valve\",\n \"accelerator, particle_accelerator, atom_smasher\",\n \"accelerator, accelerator_pedal, gas_pedal, gas, throttle, gun\",\n \"accelerometer\",\n \"accessory, accoutrement, accouterment\",\n \"accommodating_lens_implant, accommodating_iol\",\n \"accommodation\",\n \"accordion, piano_accordion, squeeze_box\",\n \"acetate_disk, phonograph_recording_disk\",\n \"acetate_rayon, acetate\",\n \"achromatic_lens\",\n \"acoustic_delay_line, sonic_delay_line\",\n \"acoustic_device\",\n \"acoustic_guitar\",\n \"acoustic_modem\",\n \"acropolis\",\n \"acrylic\",\n \"acrylic, acrylic_paint\",\n \"actinometer\",\n \"action, action_mechanism\",\n \"active_matrix_screen\",\n \"actuator\",\n \"adapter, adaptor\",\n \"adder\",\n \"adding_machine, totalizer, totaliser\",\n \"addressing_machine, addressograph\",\n \"adhesive_bandage\",\n \"adit\",\n \"adjoining_room\",\n \"adjustable_wrench, adjustable_spanner\",\n \"adobe, adobe_brick\",\n \"adz, adze\",\n \"aeolian_harp, aeolian_lyre, wind_harp\",\n \"aerator\",\n \"aerial_torpedo\",\n \"aerosol, aerosol_container, aerosol_can, aerosol_bomb, spray_can\",\n \"aertex\",\n \"afghan\",\n \"afro-wig\",\n \"afterburner\",\n \"after-shave, after-shave_lotion\",\n \"agateware\",\n \"agglomerator\",\n \"aglet, aiglet, aiguilette\",\n \"aglet, aiglet\",\n \"agora, public_square\",\n \"aigrette, aigret\",\n \"aileron\",\n \"air_bag\",\n \"airbrake\",\n \"airbrush\",\n \"airbus\",\n \"air_compressor\",\n \"air_conditioner, air_conditioning\",\n \"aircraft\",\n \"aircraft_carrier, carrier, flattop, attack_aircraft_carrier\",\n \"aircraft_engine\",\n \"air_cushion, air_spring\",\n \"airdock, hangar, repair_shed\",\n \"airfield, landing_field, flying_field, field\",\n \"air_filter, air_cleaner\",\n \"airfoil, aerofoil, control_surface, surface\",\n \"airframe\",\n \"air_gun, airgun, air_rifle\",\n \"air_hammer, jackhammer, pneumatic_hammer\",\n \"air_horn\",\n \"airing_cupboard\",\n \"airliner\",\n \"airmailer\",\n \"airplane, aeroplane, plane\",\n \"airplane_propeller, airscrew, prop\",\n \"airport, airdrome, aerodrome, drome\",\n \"air_pump, vacuum_pump\",\n \"air_search_radar\",\n \"airship, dirigible\",\n \"air_terminal, airport_terminal\",\n \"air-to-air_missile\",\n \"air-to-ground_missile, air-to-surface_missile\",\n \"aisle\",\n \"aladdin's_lamp\",\n \"alarm, warning_device, alarm_system\",\n \"alarm_clock, alarm\",\n \"alb\",\n \"alcazar\",\n \"alcohol_thermometer, alcohol-in-glass_thermometer\",\n \"alehouse\",\n \"alembic\",\n \"algometer\",\n \"alidade, alidad\",\n \"alidade, alidad\",\n \"a-line\",\n \"allen_screw\",\n \"allen_wrench\",\n \"alligator_wrench\",\n \"alms_dish, alms_tray\",\n \"alpaca\",\n \"alpenstock\",\n \"altar\",\n \"altar, communion_table, lord's_table\",\n \"altarpiece, reredos\",\n \"altazimuth\",\n \"alternator\",\n \"altimeter\",\n \"amati\",\n \"ambulance\",\n \"amen_corner\",\n \"american_organ\",\n \"ammeter\",\n \"ammonia_clock\",\n \"ammunition, ammo\",\n \"amphibian, amphibious_aircraft\",\n \"amphibian, amphibious_vehicle\",\n \"amphitheater, amphitheatre, coliseum\",\n \"amphitheater, amphitheatre\",\n \"amphora\",\n \"amplifier\",\n \"ampulla\",\n \"amusement_arcade\",\n \"analog_clock\",\n \"analog_computer, analogue_computer\",\n \"analog_watch\",\n \"analytical_balance, chemical_balance\",\n \"analyzer, analyser\",\n \"anamorphosis, anamorphism\",\n \"anastigmat\",\n \"anchor, ground_tackle\",\n \"anchor_chain, anchor_rope\",\n \"anchor_light, riding_light, riding_lamp\",\n \"and_circuit, and_gate\",\n \"andiron, firedog, dog, dog-iron\",\n \"android, humanoid, mechanical_man\",\n \"anechoic_chamber\",\n \"anemometer, wind_gauge, wind_gage\",\n \"aneroid_barometer, aneroid\",\n \"angiocardiogram\",\n \"angioscope\",\n \"angle_bracket, angle_iron\",\n \"angledozer\",\n \"ankle_brace\",\n \"anklet, anklets, bobbysock, bobbysocks\",\n \"anklet\",\n \"ankus\",\n \"anode\",\n \"anode\",\n \"answering_machine\",\n \"antenna, aerial, transmitting_aerial\",\n \"anteroom, antechamber, entrance_hall, hall, foyer, lobby, vestibule\",\n \"antiaircraft, antiaircraft_gun, flak, flack, pom-pom, ack-ack, ack-ack_gun\",\n \"antiballistic_missile, abm\",\n \"antifouling_paint\",\n \"anti-g_suit, g_suit\",\n \"antimacassar\",\n \"antiperspirant\",\n \"anti-submarine_rocket\",\n \"anvil\",\n \"ao_dai\",\n \"apadana\",\n \"apartment, flat\",\n \"apartment_building, apartment_house\",\n \"aperture\",\n \"aperture\",\n \"apiary, bee_house\",\n \"apparatus, setup\",\n \"apparel, wearing_apparel, dress, clothes\",\n \"applecart\",\n \"appliance\",\n \"appliance, contraption, contrivance, convenience, gadget, gizmo, gismo, widget\",\n \"applicator, applier\",\n \"appointment, fitting\",\n \"apron\",\n \"apron_string\",\n \"apse, apsis\",\n \"aqualung, aqua-lung, scuba\",\n \"aquaplane\",\n \"aquarium, fish_tank, marine_museum\",\n \"arabesque\",\n \"arbor, arbour, bower, pergola\",\n \"arcade, colonnade\",\n \"arch\",\n \"architecture\",\n \"architrave\",\n \"arch_support\",\n \"arc_lamp, arc_light\",\n \"arctic, galosh, golosh, rubber, gumshoe\",\n \"area\",\n \"areaway\",\n \"argyle, argyll\",\n \"ark\",\n \"arm\",\n \"armament\",\n \"armature\",\n \"armband\",\n \"armchair\",\n \"armet\",\n \"arm_guard, arm_pad\",\n \"armhole\",\n \"armilla\",\n \"armlet, arm_band\",\n \"armoire\",\n \"armor, armour\",\n \"armored_car, armoured_car\",\n \"armored_car, armoured_car\",\n \"armored_personnel_carrier, armoured_personnel_carrier, apc\",\n \"armored_vehicle, armoured_vehicle\",\n \"armor_plate, armour_plate, armor_plating, plate_armor, plate_armour\",\n \"armory, armoury, arsenal\",\n \"armrest\",\n \"arquebus, harquebus, hackbut, hagbut\",\n \"array\",\n \"array, raiment, regalia\",\n \"arrester, arrester_hook\",\n \"arrow\",\n \"arsenal, armory, armoury\",\n \"arterial_road\",\n \"arthrogram\",\n \"arthroscope\",\n \"artificial_heart\",\n \"artificial_horizon, gyro_horizon, flight_indicator\",\n \"artificial_joint\",\n \"artificial_kidney, hemodialyzer\",\n \"artificial_skin\",\n \"artillery, heavy_weapon, gun, ordnance\",\n \"artillery_shell\",\n \"artist's_loft\",\n \"art_school\",\n \"ascot\",\n \"ashcan, trash_can, garbage_can, wastebin, ash_bin, ash-bin, ashbin, dustbin, trash_barrel, trash_bin\",\n \"ash-pan\",\n \"ashtray\",\n \"aspergill, aspersorium\",\n \"aspersorium\",\n \"aspirator\",\n \"aspirin_powder, headache_powder\",\n \"assault_gun\",\n \"assault_rifle, assault_gun\",\n \"assegai, assagai\",\n \"assembly\",\n \"assembly\",\n \"assembly_hall\",\n \"assembly_plant\",\n \"astatic_coils\",\n \"astatic_galvanometer\",\n \"astrodome\",\n \"astrolabe\",\n \"astronomical_telescope\",\n \"astronomy_satellite\",\n \"athenaeum, atheneum\",\n \"athletic_sock, sweat_sock, varsity_sock\",\n \"athletic_supporter, supporter, suspensor, jockstrap, jock\",\n \"atlas, telamon\",\n \"atmometer, evaporometer\",\n \"atom_bomb, atomic_bomb, a-bomb, fission_bomb, plutonium_bomb\",\n \"atomic_clock\",\n \"atomic_pile, atomic_reactor, pile, chain_reactor\",\n \"atomizer, atomiser, spray, sprayer, nebulizer, nebuliser\",\n \"atrium\",\n \"attache_case, attache\",\n \"attachment, bond\",\n \"attack_submarine\",\n \"attenuator\",\n \"attic\",\n \"attic_fan\",\n \"attire, garb, dress\",\n \"audio_amplifier\",\n \"audiocassette\",\n \"audio_cd, audio_compact_disc\",\n \"audiometer, sonometer\",\n \"audio_system, sound_system\",\n \"audiotape\",\n \"audiotape\",\n \"audiovisual, audiovisual_aid\",\n \"auditorium\",\n \"auger, gimlet, screw_auger, wimble\",\n \"autobahn\",\n \"autoclave, sterilizer, steriliser\",\n \"autofocus\",\n \"autogiro, autogyro, gyroplane\",\n \"autoinjector\",\n \"autoloader, self-loader\",\n \"automat\",\n \"automat\",\n \"automatic_choke\",\n \"automatic_firearm, automatic_gun, automatic_weapon\",\n \"automatic_pistol, automatic\",\n \"automatic_rifle, automatic, machine_rifle\",\n \"automatic_transmission, automatic_drive\",\n \"automation\",\n \"automaton, robot, golem\",\n \"automobile_engine\",\n \"automobile_factory, auto_factory, car_factory\",\n \"automobile_horn, car_horn, motor_horn, horn, hooter\",\n \"autopilot, automatic_pilot, robot_pilot\",\n \"autoradiograph\",\n \"autostrada\",\n \"auxiliary_boiler, donkey_boiler\",\n \"auxiliary_engine, donkey_engine\",\n \"auxiliary_pump, donkey_pump\",\n \"auxiliary_research_submarine\",\n \"auxiliary_storage, external_storage, secondary_storage\",\n \"aviary, bird_sanctuary, volary\",\n \"awl\",\n \"awning, sunshade, sunblind\",\n \"ax, axe\",\n \"ax_handle, axe_handle\",\n \"ax_head, axe_head\",\n \"axis, axis_of_rotation\",\n \"axle\",\n \"axle_bar\",\n \"axletree\",\n \"babushka\",\n \"baby_bed, baby's_bed\",\n \"baby_buggy, baby_carriage, carriage, perambulator, pram, stroller, go-cart, pushchair, pusher\",\n \"baby_grand, baby_grand_piano, parlor_grand, parlor_grand_piano, parlour_grand, parlour_grand_piano\",\n \"baby_powder\",\n \"baby_shoe\",\n \"back, backrest\",\n \"back\",\n \"backbench\",\n \"backboard\",\n \"backboard, basketball_backboard\",\n \"backbone\",\n \"back_brace\",\n \"backgammon_board\",\n \"background, desktop, screen_background\",\n \"backhoe\",\n \"backlighting\",\n \"backpack, back_pack, knapsack, packsack, rucksack, haversack\",\n \"backpacking_tent, pack_tent\",\n \"backplate\",\n \"back_porch\",\n \"backsaw, back_saw\",\n \"backscratcher\",\n \"backseat\",\n \"backspace_key, backspace, backspacer\",\n \"backstairs\",\n \"backstay\",\n \"backstop\",\n \"backsword\",\n \"backup_system\",\n \"badminton_court\",\n \"badminton_equipment\",\n \"badminton_racket, badminton_racquet, battledore\",\n \"bag\",\n \"bag, traveling_bag, travelling_bag, grip, suitcase\",\n \"bag, handbag, pocketbook, purse\",\n \"baggage, luggage\",\n \"baggage\",\n \"baggage_car, luggage_van\",\n \"baggage_claim\",\n \"bagpipe\",\n \"bailey\",\n \"bailey\",\n \"bailey_bridge\",\n \"bain-marie\",\n \"bait, decoy, lure\",\n \"baize\",\n \"bakery, bakeshop, bakehouse\",\n \"balaclava, balaclava_helmet\",\n \"balalaika\",\n \"balance\",\n \"balance_beam, beam\",\n \"balance_wheel, balance\",\n \"balbriggan\",\n \"balcony\",\n \"balcony\",\n \"baldachin\",\n \"baldric, baldrick\",\n \"bale\",\n \"baling_wire\",\n \"ball\",\n \"ball\",\n \"ball_and_chain\",\n \"ball-and-socket_joint\",\n \"ballast, light_ballast\",\n \"ball_bearing, needle_bearing, roller_bearing\",\n \"ball_cartridge\",\n \"ballcock, ball_cock\",\n \"balldress\",\n \"ballet_skirt, tutu\",\n \"ball_gown\",\n \"ballistic_galvanometer\",\n \"ballistic_missile\",\n \"ballistic_pendulum\",\n \"ballistocardiograph, cardiograph\",\n \"balloon\",\n \"balloon_bomb, fugo\",\n \"balloon_sail\",\n \"ballot_box\",\n \"ballpark, park\",\n \"ball-peen_hammer\",\n \"ballpoint, ballpoint_pen, ballpen, biro\",\n \"ballroom, dance_hall, dance_palace\",\n \"ball_valve\",\n \"balsa_raft, kon_tiki\",\n \"baluster\",\n \"banana_boat\",\n \"band\",\n \"bandage, patch\",\n \"band_aid\",\n \"bandanna, bandana\",\n \"bandbox\",\n \"banderilla\",\n \"bandoleer, bandolier\",\n \"bandoneon\",\n \"bandsaw, band_saw\",\n \"bandwagon\",\n \"bangalore_torpedo\",\n \"bangle, bauble, gaud, gewgaw, novelty, fallal, trinket\",\n \"banjo\",\n \"banner, streamer\",\n \"bannister, banister, balustrade, balusters, handrail\",\n \"banquette\",\n \"banyan, banian\",\n \"baptismal_font, baptistry, baptistery, font\",\n \"bar\",\n \"bar\",\n \"barbecue, barbeque\",\n \"barbed_wire, barbwire\",\n \"barbell\",\n \"barber_chair\",\n \"barbershop\",\n \"barbette_carriage\",\n \"barbican, barbacan\",\n \"bar_bit\",\n \"bareboat\",\n \"barge, flatboat, hoy, lighter\",\n \"barge_pole\",\n \"baritone, baritone_horn\",\n \"bark, barque\",\n \"bar_magnet\",\n \"bar_mask\",\n \"barn\",\n \"barndoor\",\n \"barn_door\",\n \"barnyard\",\n \"barograph\",\n \"barometer\",\n \"barong\",\n \"barouche\",\n \"bar_printer\",\n \"barrack\",\n \"barrage_balloon\",\n \"barrel, cask\",\n \"barrel, gun_barrel\",\n \"barrelhouse, honky-tonk\",\n \"barrel_knot, blood_knot\",\n \"barrel_organ, grind_organ, hand_organ, hurdy_gurdy, hurdy-gurdy, street_organ\",\n \"barrel_vault\",\n \"barrette\",\n \"barricade\",\n \"barrier\",\n \"barroom, bar, saloon, ginmill, taproom\",\n \"barrow, garden_cart, lawn_cart, wheelbarrow\",\n \"bascule\",\n \"base, pedestal, stand\",\n \"base, bag\",\n \"baseball\",\n \"baseball_bat, lumber\",\n \"baseball_cap, jockey_cap, golf_cap\",\n \"baseball_equipment\",\n \"baseball_glove, glove, baseball_mitt, mitt\",\n \"basement, cellar\",\n \"basement\",\n \"basic_point_defense_missile_system\",\n \"basilica, roman_basilica\",\n \"basilica\",\n \"basilisk\",\n \"basin\",\n \"basinet\",\n \"basket, handbasket\",\n \"basket, basketball_hoop, hoop\",\n \"basketball\",\n \"basketball_court\",\n \"basketball_equipment\",\n \"basket_weave\",\n \"bass\",\n \"bass_clarinet\",\n \"bass_drum, gran_casa\",\n \"basset_horn\",\n \"bass_fiddle, bass_viol, bull_fiddle, double_bass, contrabass, string_bass\",\n \"bass_guitar\",\n \"bass_horn, sousaphone, tuba\",\n \"bassinet\",\n \"bassinet\",\n \"bassoon\",\n \"baster\",\n \"bastinado\",\n \"bastion\",\n \"bastion, citadel\",\n \"bat\",\n \"bath\",\n \"bath_chair\",\n \"bathhouse, bagnio\",\n \"bathhouse, bathing_machine\",\n \"bathing_cap, swimming_cap\",\n \"bath_oil\",\n \"bathrobe\",\n \"bathroom, bath\",\n \"bath_salts\",\n \"bath_towel\",\n \"bathtub, bathing_tub, bath, tub\",\n \"bathyscaphe, bathyscaph, bathyscape\",\n \"bathysphere\",\n \"batik\",\n \"batiste\",\n \"baton, wand\",\n \"baton\",\n \"baton\",\n \"baton\",\n \"battering_ram\",\n \"batter's_box\",\n \"battery, electric_battery\",\n \"battery, stamp_battery\",\n \"batting_cage, cage\",\n \"batting_glove\",\n \"batting_helmet\",\n \"battle-ax, battle-axe\",\n \"battle_cruiser\",\n \"battle_dress\",\n \"battlement, crenelation, crenellation\",\n \"battleship, battlewagon\",\n \"battle_sight, battlesight\",\n \"bay\",\n \"bay\",\n \"bayonet\",\n \"bay_rum\",\n \"bay_window, bow_window\",\n \"bazaar, bazar\",\n \"bazaar, bazar\",\n \"bazooka\",\n \"b_battery\",\n \"bb_gun\",\n \"beach_house\",\n \"beach_towel\",\n \"beach_wagon, station_wagon, wagon, estate_car, beach_waggon, station_waggon, waggon\",\n \"beachwear\",\n \"beacon, lighthouse, beacon_light, pharos\",\n \"beading_plane\",\n \"beaker\",\n \"beaker\",\n \"beam\",\n \"beam_balance\",\n \"beanbag\",\n \"beanie, beany\",\n \"bearing\",\n \"bearing_rein, checkrein\",\n \"bearing_wall\",\n \"bearskin, busby, shako\",\n \"beater\",\n \"beating-reed_instrument, reed_instrument, reed\",\n \"beaver, castor\",\n \"beaver\",\n \"beckman_thermometer\",\n \"bed\",\n \"bed\",\n \"bed_and_breakfast, bed-and-breakfast\",\n \"bedclothes, bed_clothing, bedding\",\n \"bedford_cord\",\n \"bed_jacket\",\n \"bedpan\",\n \"bedpost\",\n \"bedroll\",\n \"bedroom, sleeping_room, sleeping_accommodation, chamber, bedchamber\",\n \"bedroom_furniture\",\n \"bedsitting_room, bedsitter, bedsit\",\n \"bedspread, bedcover, bed_cover, bed_covering, counterpane, spread\",\n \"bedspring\",\n \"bedstead, bedframe\",\n \"beefcake\",\n \"beehive, hive\",\n \"beeper, pager\",\n \"beer_barrel, beer_keg\",\n \"beer_bottle\",\n \"beer_can\",\n \"beer_garden\",\n \"beer_glass\",\n \"beer_hall\",\n \"beer_mat\",\n \"beer_mug, stein\",\n \"belaying_pin\",\n \"belfry\",\n \"bell\",\n \"bell_arch\",\n \"bellarmine, longbeard, long-beard, greybeard\",\n \"bellbottom_trousers, bell-bottoms, bellbottom_pants\",\n \"bell_cote, bell_cot\",\n \"bell_foundry\",\n \"bell_gable\",\n \"bell_jar, bell_glass\",\n \"bellows\",\n \"bellpull\",\n \"bell_push\",\n \"bell_seat, balloon_seat\",\n \"bell_tent\",\n \"bell_tower\",\n \"bellyband\",\n \"belt\",\n \"belt, belt_ammunition, belted_ammunition\",\n \"belt_buckle\",\n \"belting\",\n \"bench\",\n \"bench_clamp\",\n \"bench_hook\",\n \"bench_lathe\",\n \"bench_press\",\n \"bender\",\n \"beret\",\n \"berlin\",\n \"bermuda_shorts, jamaica_shorts\",\n \"berth, bunk, built_in_bed\",\n \"besom\",\n \"bessemer_converter\",\n \"bethel\",\n \"betting_shop\",\n \"bevatron\",\n \"bevel, bevel_square\",\n \"bevel_gear, pinion_and_crown_wheel, pinion_and_ring_gear\",\n \"b-flat_clarinet, licorice_stick\",\n \"bib\",\n \"bib-and-tucker\",\n \"bicorn, bicorne\",\n \"bicycle, bike, wheel, cycle\",\n \"bicycle-built-for-two, tandem_bicycle, tandem\",\n \"bicycle_chain\",\n \"bicycle_clip, trouser_clip\",\n \"bicycle_pump\",\n \"bicycle_rack\",\n \"bicycle_seat, saddle\",\n \"bicycle_wheel\",\n \"bidet\",\n \"bier\",\n \"bier\",\n \"bi-fold_door\",\n \"bifocals\",\n \"big_blue, blu-82\",\n \"big_board\",\n \"bight\",\n \"bikini, two-piece\",\n \"bikini_pants\",\n \"bilge\",\n \"bilge_keel\",\n \"bilge_pump\",\n \"bilge_well\",\n \"bill, peak, eyeshade, visor, vizor\",\n \"bill, billhook\",\n \"billboard, hoarding\",\n \"billiard_ball\",\n \"billiard_room, billiard_saloon, billiard_parlor, billiard_parlour, billiard_hall\",\n \"bin\",\n \"binder, ligature\",\n \"binder, ring-binder\",\n \"bindery\",\n \"binding, book_binding, cover, back\",\n \"bin_liner\",\n \"binnacle\",\n \"binoculars, field_glasses, opera_glasses\",\n \"binocular_microscope\",\n \"biochip\",\n \"biohazard_suit\",\n \"bioscope\",\n \"biplane\",\n \"birch, birch_rod\",\n \"birchbark_canoe, birchbark, birch_bark\",\n \"birdbath\",\n \"birdcage\",\n \"birdcall\",\n \"bird_feeder, birdfeeder, feeder\",\n \"birdhouse\",\n \"bird_shot, buckshot, duck_shot\",\n \"biretta, berretta, birretta\",\n \"bishop\",\n \"bistro\",\n \"bit\",\n \"bit\",\n \"bite_plate, biteplate\",\n \"bitewing\",\n \"bitumastic\",\n \"black\",\n \"black\",\n \"blackboard, chalkboard\",\n \"blackboard_eraser\",\n \"black_box\",\n \"blackface\",\n \"blackjack, cosh, sap\",\n \"black_tie\",\n \"blackwash\",\n \"bladder\",\n \"blade\",\n \"blade, vane\",\n \"blade\",\n \"blank, dummy, blank_shell\",\n \"blanket, cover\",\n \"blast_furnace\",\n \"blasting_cap\",\n \"blazer, sport_jacket, sport_coat, sports_jacket, sports_coat\",\n \"blender, liquidizer, liquidiser\",\n \"blimp, sausage_balloon, sausage\",\n \"blind, screen\",\n \"blind_curve, blind_bend\",\n \"blindfold\",\n \"bling, bling_bling\",\n \"blinker, flasher\",\n \"blister_pack, bubble_pack\",\n \"block\",\n \"blockade\",\n \"blockade-runner\",\n \"block_and_tackle\",\n \"blockbuster\",\n \"blockhouse\",\n \"block_plane\",\n \"bloodmobile\",\n \"bloomers, pants, drawers, knickers\",\n \"blouse\",\n \"blower\",\n \"blowtorch, torch, blowlamp\",\n \"blucher\",\n \"bludgeon\",\n \"blue\",\n \"blue_chip\",\n \"blunderbuss\",\n \"blunt_file\",\n \"boarding\",\n \"boarding_house, boardinghouse\",\n \"boardroom, council_chamber\",\n \"boards\",\n \"boat\",\n \"boater, leghorn, panama, panama_hat, sailor, skimmer, straw_hat\",\n \"boat_hook\",\n \"boathouse\",\n \"boatswain's_chair, bosun's_chair\",\n \"boat_train\",\n \"boatyard\",\n \"bobbin, spool, reel\",\n \"bobby_pin, hairgrip, grip\",\n \"bobsled, bobsleigh, bob\",\n \"bobsled, bobsleigh\",\n \"bocce_ball, bocci_ball, boccie_ball\",\n \"bodega\",\n \"bodice\",\n \"bodkin, threader\",\n \"bodkin\",\n \"bodkin\",\n \"body\",\n \"body_armor, body_armour, suit_of_armor, suit_of_armour, coat_of_mail, cataphract\",\n \"body_lotion\",\n \"body_stocking\",\n \"body_plethysmograph\",\n \"body_pad\",\n \"bodywork\",\n \"bofors_gun\",\n \"bogy, bogie, bogey\",\n \"boiler, steam_boiler\",\n \"boiling_water_reactor, bwr\",\n \"bolero\",\n \"bollard, bitt\",\n \"bolo, bolo_knife\",\n \"bolo_tie, bolo, bola_tie, bola\",\n \"bolt\",\n \"bolt, deadbolt\",\n \"bolt\",\n \"bolt_cutter\",\n \"bomb\",\n \"bombazine\",\n \"bomb_calorimeter, bomb\",\n \"bomber\",\n \"bomber_jacket\",\n \"bomblet, cluster_bomblet\",\n \"bomb_rack\",\n \"bombshell\",\n \"bomb_shelter, air-raid_shelter, bombproof\",\n \"bone-ash_cup, cupel, refractory_pot\",\n \"bone_china\",\n \"bones, castanets, clappers, finger_cymbals\",\n \"boneshaker\",\n \"bongo, bongo_drum\",\n \"bonnet, poke_bonnet\",\n \"book\",\n \"book_bag\",\n \"bookbindery\",\n \"bookcase\",\n \"bookend\",\n \"bookmark, bookmarker\",\n \"bookmobile\",\n \"bookshelf\",\n \"bookshop, bookstore, bookstall\",\n \"boom\",\n \"boom, microphone_boom\",\n \"boomerang, throwing_stick, throw_stick\",\n \"booster, booster_rocket, booster_unit, takeoff_booster, takeoff_rocket\",\n \"booster, booster_amplifier, booster_station, relay_link, relay_station, relay_transmitter\",\n \"boot\",\n \"boot\",\n \"boot_camp\",\n \"bootee, bootie\",\n \"booth, cubicle, stall, kiosk\",\n \"booth\",\n \"booth\",\n \"boothose\",\n \"bootjack\",\n \"bootlace\",\n \"bootleg\",\n \"bootstrap\",\n \"bore_bit, borer, rock_drill, stone_drill\",\n \"boron_chamber\",\n \"borstal\",\n \"bosom\",\n \"boston_rocker\",\n \"bota\",\n \"bottle\",\n \"bottle, feeding_bottle, nursing_bottle\",\n \"bottle_bank\",\n \"bottlebrush\",\n \"bottlecap\",\n \"bottle_opener\",\n \"bottling_plant\",\n \"bottom, freighter, merchantman, merchant_ship\",\n \"boucle\",\n \"boudoir\",\n \"boulle, boule, buhl\",\n \"bouncing_betty\",\n \"bouquet, corsage, posy, nosegay\",\n \"boutique, dress_shop\",\n \"boutonniere\",\n \"bow\",\n \"bow\",\n \"bow, bowknot\",\n \"bow_and_arrow\",\n \"bowed_stringed_instrument, string\",\n \"bowie_knife\",\n \"bowl\",\n \"bowl\",\n \"bowl\",\n \"bowler_hat, bowler, derby_hat, derby, plug_hat\",\n \"bowline, bowline_knot\",\n \"bowling_alley\",\n \"bowling_ball, bowl\",\n \"bowling_equipment\",\n \"bowling_pin, pin\",\n \"bowling_shoe\",\n \"bowsprit\",\n \"bowstring\",\n \"bow_tie, bow-tie, bowtie\",\n \"box\",\n \"box, loge\",\n \"box, box_seat\",\n \"box_beam, box_girder\",\n \"box_camera, box_kodak\",\n \"boxcar\",\n \"box_coat\",\n \"boxing_equipment\",\n \"boxing_glove, glove\",\n \"box_office, ticket_office, ticket_booth\",\n \"box_spring\",\n \"box_wrench, box_end_wrench\",\n \"brace, bracing\",\n \"brace, braces, orthodontic_braces\",\n \"brace\",\n \"brace, suspender, gallus\",\n \"brace_and_bit\",\n \"bracelet, bangle\",\n \"bracer, armguard\",\n \"brace_wrench\",\n \"bracket, wall_bracket\",\n \"bradawl, pricker\",\n \"brake\",\n \"brake\",\n \"brake_band\",\n \"brake_cylinder, hydraulic_brake_cylinder, master_cylinder\",\n \"brake_disk\",\n \"brake_drum, drum\",\n \"brake_lining\",\n \"brake_pad\",\n \"brake_pedal\",\n \"brake_shoe, shoe, skid\",\n \"brake_system, brakes\",\n \"brass, brass_instrument\",\n \"brass, memorial_tablet, plaque\",\n \"brass\",\n \"brassard\",\n \"brasserie\",\n \"brassie\",\n \"brassiere, bra, bandeau\",\n \"brass_knucks, knucks, brass_knuckles, knuckles, knuckle_duster\",\n \"brattice\",\n \"brazier, brasier\",\n \"breadbasket\",\n \"bread-bin, breadbox\",\n \"bread_knife\",\n \"breakable\",\n \"breakfast_area, breakfast_nook\",\n \"breakfast_table\",\n \"breakwater, groin, groyne, mole, bulwark, seawall, jetty\",\n \"breast_drill\",\n \"breast_implant\",\n \"breastplate, aegis, egis\",\n \"breast_pocket\",\n \"breathalyzer, breathalyser\",\n \"breechblock, breech_closer\",\n \"breechcloth, breechclout, loincloth\",\n \"breeches, knee_breeches, knee_pants, knickerbockers, knickers\",\n \"breeches_buoy\",\n \"breechloader\",\n \"breeder_reactor\",\n \"bren, bren_gun\",\n \"brewpub\",\n \"brick\",\n \"brickkiln\",\n \"bricklayer's_hammer\",\n \"brick_trowel, mason's_trowel\",\n \"brickwork\",\n \"bridal_gown, wedding_gown, wedding_dress\",\n \"bridge, span\",\n \"bridge, nosepiece\",\n \"bridle\",\n \"bridle_path, bridle_road\",\n \"bridoon\",\n \"briefcase\",\n \"briefcase_bomb\",\n \"briefcase_computer\",\n \"briefs, jockey_shorts\",\n \"brig\",\n \"brig\",\n \"brigandine\",\n \"brigantine, hermaphrodite_brig\",\n \"brilliantine\",\n \"brilliant_pebble\",\n \"brim\",\n \"bristle_brush\",\n \"britches\",\n \"broad_arrow\",\n \"broadax, broadaxe\",\n \"brochette\",\n \"broadcaster, spreader\",\n \"broadcloth\",\n \"broadcloth\",\n \"broad_hatchet\",\n \"broadloom\",\n \"broadside\",\n \"broadsword\",\n \"brocade\",\n \"brogan, brogue, clodhopper, work_shoe\",\n \"broiler\",\n \"broken_arch\",\n \"bronchoscope\",\n \"broom\",\n \"broom_closet\",\n \"broomstick, broom_handle\",\n \"brougham\",\n \"browning_automatic_rifle, bar\",\n \"browning_machine_gun, peacemaker\",\n \"brownstone\",\n \"brunch_coat\",\n \"brush\",\n \"brussels_carpet\",\n \"brussels_lace\",\n \"bubble\",\n \"bubble_chamber\",\n \"bubble_jet_printer, bubble-jet_printer, bubblejet\",\n \"buckboard\",\n \"bucket, pail\",\n \"bucket_seat\",\n \"bucket_shop\",\n \"buckle\",\n \"buckram\",\n \"bucksaw\",\n \"buckskins\",\n \"buff, buffer\",\n \"buffer, polisher\",\n \"buffer, buffer_storage, buffer_store\",\n \"buffet, counter, sideboard\",\n \"buffing_wheel\",\n \"buggy, roadster\",\n \"bugle\",\n \"building, edifice\",\n \"building_complex, complex\",\n \"bulldog_clip, alligator_clip\",\n \"bulldog_wrench\",\n \"bulldozer, dozer\",\n \"bullet, slug\",\n \"bulletproof_vest\",\n \"bullet_train, bullet\",\n \"bullhorn, loud_hailer, loud-hailer\",\n \"bullion\",\n \"bullnose, bullnosed_plane\",\n \"bullpen, detention_cell, detention_centre\",\n \"bullpen\",\n \"bullring\",\n \"bulwark\",\n \"bumboat\",\n \"bumper\",\n \"bumper\",\n \"bumper_car, dodgem\",\n \"bumper_guard\",\n \"bumper_jack\",\n \"bundle, sheaf\",\n \"bung, spile\",\n \"bungalow, cottage\",\n \"bungee, bungee_cord\",\n \"bunghole\",\n \"bunk\",\n \"bunk, feed_bunk\",\n \"bunk_bed, bunk\",\n \"bunker, sand_trap, trap\",\n \"bunker, dugout\",\n \"bunker\",\n \"bunsen_burner, bunsen, etna\",\n \"bunting\",\n \"bur, burr\",\n \"burberry\",\n \"burette, buret\",\n \"burglar_alarm\",\n \"burial_chamber, sepulcher, sepulchre, sepulture\",\n \"burial_garment\",\n \"burial_mound, grave_mound, barrow, tumulus\",\n \"burin\",\n \"burqa, burka\",\n \"burlap, gunny\",\n \"burn_bag\",\n \"burner\",\n \"burnous, burnoose, burnouse\",\n \"burp_gun, machine_pistol\",\n \"burr\",\n \"bus, autobus, coach, charabanc, double-decker, jitney, motorbus, motorcoach, omnibus, passenger_vehicle\",\n \"bushel_basket\",\n \"bushing, cylindrical_lining\",\n \"bush_jacket\",\n \"business_suit\",\n \"buskin, combat_boot, desert_boot, half_boot, top_boot\",\n \"bustier\",\n \"bustle\",\n \"butcher_knife\",\n \"butcher_shop, meat_market\",\n \"butter_dish\",\n \"butterfly_valve\",\n \"butter_knife\",\n \"butt_hinge\",\n \"butt_joint, butt\",\n \"button\",\n \"buttonhook\",\n \"buttress, buttressing\",\n \"butt_shaft\",\n \"butt_weld, butt-weld\",\n \"buzz_bomb, robot_bomb, flying_bomb, doodlebug, v-1\",\n \"buzzer\",\n \"bvd, bvd's\",\n \"bypass_condenser, bypass_capacitor\",\n \"byway, bypath, byroad\",\n \"cab, hack, taxi, taxicab\",\n \"cab, cabriolet\",\n \"cab\",\n \"cabana\",\n \"cabaret, nightclub, night_club, club, nightspot\",\n \"caber\",\n \"cabin\",\n \"cabin\",\n \"cabin_car, caboose\",\n \"cabin_class, second_class, economy_class\",\n \"cabin_cruiser, cruiser, pleasure_boat, pleasure_craft\",\n \"cabinet\",\n \"cabinet, console\",\n \"cabinet, locker, storage_locker\",\n \"cabinetwork\",\n \"cabin_liner\",\n \"cable, cable_television, cable_system, cable_television_service\",\n \"cable, line, transmission_line\",\n \"cable_car, car\",\n \"cache, memory_cache\",\n \"caddy, tea_caddy\",\n \"caesium_clock\",\n \"cafe, coffeehouse, coffee_shop, coffee_bar\",\n \"cafeteria\",\n \"cafeteria_tray\",\n \"caff\",\n \"caftan, kaftan\",\n \"caftan, kaftan\",\n \"cage, coop\",\n \"cage\",\n \"cagoule\",\n \"caisson\",\n \"calash, caleche, calash_top\",\n \"calceus\",\n \"calcimine\",\n \"calculator, calculating_machine\",\n \"caldron, cauldron\",\n \"calico\",\n \"caliper, calliper\",\n \"call-board\",\n \"call_center, call_centre\",\n \"caller_id\",\n \"calliope, steam_organ\",\n \"calorimeter\",\n \"calpac, calpack, kalpac\",\n \"camail, aventail, ventail\",\n \"camber_arch\",\n \"cambric\",\n \"camcorder\",\n \"camel's_hair, camelhair\",\n \"camera, photographic_camera\",\n \"camera_lens, optical_lens\",\n \"camera_lucida\",\n \"camera_obscura\",\n \"camera_tripod\",\n \"camise\",\n \"camisole\",\n \"camisole, underbodice\",\n \"camlet\",\n \"camouflage\",\n \"camouflage, camo\",\n \"camp, encampment, cantonment, bivouac\",\n \"camp\",\n \"camp, refugee_camp\",\n \"campaign_hat\",\n \"campanile, belfry\",\n \"camp_chair\",\n \"camper, camping_bus, motor_home\",\n \"camper_trailer\",\n \"campstool\",\n \"camshaft\",\n \"can, tin, tin_can\",\n \"canal\",\n \"canal_boat, narrow_boat, narrowboat\",\n \"candelabrum, candelabra\",\n \"candid_camera\",\n \"candle, taper, wax_light\",\n \"candlepin\",\n \"candlesnuffer\",\n \"candlestick, candle_holder\",\n \"candlewick\",\n \"candy_thermometer\",\n \"cane\",\n \"cane\",\n \"cangue\",\n \"canister, cannister, tin\",\n \"cannery\",\n \"cannikin\",\n \"cannikin\",\n \"cannon\",\n \"cannon\",\n \"cannon\",\n \"cannon\",\n \"cannonball, cannon_ball, round_shot\",\n \"canoe\",\n \"can_opener, tin_opener\",\n \"canopic_jar, canopic_vase\",\n \"canopy\",\n \"canopy\",\n \"canopy\",\n \"canteen\",\n \"canteen\",\n \"canteen\",\n \"canteen, mobile_canteen\",\n \"canteen\",\n \"cant_hook\",\n \"cantilever\",\n \"cantilever_bridge\",\n \"cantle\",\n \"canton_crepe\",\n \"canvas, canvass\",\n \"canvas, canvass\",\n \"canvas_tent, canvas, canvass\",\n \"cap\",\n \"cap\",\n \"cap\",\n \"capacitor, capacitance, condenser, electrical_condenser\",\n \"caparison, trapping, housing\",\n \"cape, mantle\",\n \"capital_ship\",\n \"capitol\",\n \"cap_opener\",\n \"capote, hooded_cloak\",\n \"capote, hooded_coat\",\n \"cap_screw\",\n \"capstan\",\n \"capstone, copestone, coping_stone, stretcher\",\n \"capsule\",\n \"captain's_chair\",\n \"car, auto, automobile, machine, motorcar\",\n \"car, railcar, railway_car, railroad_car\",\n \"car, elevator_car\",\n \"carabiner, karabiner, snap_ring\",\n \"carafe, decanter\",\n \"caravansary, caravanserai, khan, caravan_inn\",\n \"car_battery, automobile_battery\",\n \"carbine\",\n \"car_bomb\",\n \"carbon_arc_lamp, carbon_arc\",\n \"carboy\",\n \"carburetor, carburettor\",\n \"car_carrier\",\n \"cardcase\",\n \"cardiac_monitor, heart_monitor\",\n \"cardigan\",\n \"card_index, card_catalog, card_catalogue\",\n \"cardiograph, electrocardiograph\",\n \"cardioid_microphone\",\n \"car_door\",\n \"cardroom\",\n \"card_table\",\n \"card_table\",\n \"car-ferry\",\n \"cargo_area, cargo_deck, cargo_hold, hold, storage_area\",\n \"cargo_container\",\n \"cargo_door\",\n \"cargo_hatch\",\n \"cargo_helicopter\",\n \"cargo_liner\",\n \"cargo_ship, cargo_vessel\",\n \"carillon\",\n \"car_mirror\",\n \"caroche\",\n \"carousel, carrousel, merry-go-round, roundabout, whirligig\",\n \"carpenter's_hammer, claw_hammer, clawhammer\",\n \"carpenter's_kit, tool_kit\",\n \"carpenter's_level\",\n \"carpenter's_mallet\",\n \"carpenter's_rule\",\n \"carpenter's_square\",\n \"carpetbag\",\n \"carpet_beater, rug_beater\",\n \"carpet_loom\",\n \"carpet_pad, rug_pad, underlay, underlayment\",\n \"carpet_sweeper, sweeper\",\n \"carpet_tack\",\n \"carport, car_port\",\n \"carrack, carack\",\n \"carrel, carrell, cubicle, stall\",\n \"carriage, equipage, rig\",\n \"carriage\",\n \"carriage_bolt\",\n \"carriageway\",\n \"carriage_wrench\",\n \"carrick_bend\",\n \"carrier\",\n \"carryall, holdall, tote, tote_bag\",\n \"carrycot\",\n \"car_seat\",\n \"cart\",\n \"car_tire, automobile_tire, auto_tire, rubber_tire\",\n \"carton\",\n \"cartouche, cartouch\",\n \"car_train\",\n \"cartridge\",\n \"cartridge, pickup\",\n \"cartridge_belt\",\n \"cartridge_extractor, cartridge_remover, extractor\",\n \"cartridge_fuse\",\n \"cartridge_holder, cartridge_clip, clip, magazine\",\n \"cartwheel\",\n \"carving_fork\",\n \"carving_knife\",\n \"car_wheel\",\n \"caryatid\",\n \"cascade_liquefier\",\n \"cascade_transformer\",\n \"case\",\n \"case, display_case, showcase, vitrine\",\n \"case, compositor's_case, typesetter's_case\",\n \"casein_paint, casein\",\n \"case_knife, sheath_knife\",\n \"case_knife\",\n \"casement\",\n \"casement_window\",\n \"casern\",\n \"case_shot, canister, canister_shot\",\n \"cash_bar\",\n \"cashbox, money_box, till\",\n \"cash_machine, cash_dispenser, automated_teller_machine, automatic_teller_machine, automated_teller, automatic_teller, atm\",\n \"cashmere\",\n \"cash_register, register\",\n \"casing, case\",\n \"casino, gambling_casino\",\n \"casket, jewel_casket\",\n \"casque\",\n \"casquet, casquetel\",\n \"cassegrainian_telescope, gregorian_telescope\",\n \"casserole\",\n \"cassette\",\n \"cassette_deck\",\n \"cassette_player\",\n \"cassette_recorder\",\n \"cassette_tape\",\n \"cassock\",\n \"cast, plaster_cast, plaster_bandage\",\n \"caster, castor\",\n \"caster, castor\",\n \"castle\",\n \"castle, rook\",\n \"catacomb\",\n \"catafalque\",\n \"catalytic_converter\",\n \"catalytic_cracker, cat_cracker\",\n \"catamaran\",\n \"catapult, arbalest, arbalist, ballista, bricole, mangonel, onager, trebuchet, trebucket\",\n \"catapult, launcher\",\n \"catboat\",\n \"cat_box\",\n \"catch\",\n \"catchall\",\n \"catcher's_mask\",\n \"catchment\",\n \"caterpillar, cat\",\n \"cathedra, bishop's_throne\",\n \"cathedral\",\n \"cathedral, duomo\",\n \"catheter\",\n \"cathode\",\n \"cathode-ray_tube, crt\",\n \"cat-o'-nine-tails, cat\",\n \"cat's-paw\",\n \"catsup_bottle, ketchup_bottle\",\n \"cattle_car\",\n \"cattle_guard, cattle_grid\",\n \"cattleship, cattle_boat\",\n \"cautery, cauterant\",\n \"cavalier_hat, slouch_hat\",\n \"cavalry_sword, saber, sabre\",\n \"cavetto\",\n \"cavity_wall\",\n \"c_battery\",\n \"c-clamp\",\n \"cd_drive\",\n \"cd_player\",\n \"cd-r, compact_disc_recordable, cd-wo, compact_disc_write-once\",\n \"cd-rom, compact_disc_read-only_memory\",\n \"cd-rom_drive\",\n \"cedar_chest\",\n \"ceiling\",\n \"celesta\",\n \"cell, electric_cell\",\n \"cell, jail_cell, prison_cell\",\n \"cellar, wine_cellar\",\n \"cellblock, ward\",\n \"cello, violoncello\",\n \"cellophane\",\n \"cellular_telephone, cellular_phone, cellphone, cell, mobile_phone\",\n \"cellulose_tape, scotch_tape, sellotape\",\n \"cenotaph, empty_tomb\",\n \"censer, thurible\",\n \"center, centre\",\n \"center_punch\",\n \"centigrade_thermometer\",\n \"central_processing_unit, cpu, c.p.u., central_processor, processor, mainframe\",\n \"centrifugal_pump\",\n \"centrifuge, extractor, separator\",\n \"ceramic\",\n \"ceramic_ware\",\n \"cereal_bowl\",\n \"cereal_box\",\n \"cerecloth\",\n \"cesspool, cesspit, sink, sump\",\n \"chachka, tsatske, tshatshke, tchotchke\",\n \"chador, chadar, chaddar, chuddar\",\n \"chafing_dish\",\n \"chain\",\n \"chain\",\n \"chainlink_fence\",\n \"chain_mail, ring_mail, mail, chain_armor, chain_armour, ring_armor, ring_armour\",\n \"chain_printer\",\n \"chain_saw, chainsaw\",\n \"chain_store\",\n \"chain_tongs\",\n \"chain_wrench\",\n \"chair\",\n \"chair\",\n \"chair_of_state\",\n \"chairlift, chair_lift\",\n \"chaise, shay\",\n \"chaise_longue, chaise, daybed\",\n \"chalet\",\n \"chalice, goblet\",\n \"chalk\",\n \"challis\",\n \"chamberpot, potty, thunder_mug\",\n \"chambray\",\n \"chamfer_bit\",\n \"chamfer_plane\",\n \"chamois_cloth\",\n \"chancel, sanctuary, bema\",\n \"chancellery\",\n \"chancery\",\n \"chandelier, pendant, pendent\",\n \"chandlery\",\n \"chanfron, chamfron, testiere, frontstall, front-stall\",\n \"chanter, melody_pipe\",\n \"chantry\",\n \"chap\",\n \"chapel\",\n \"chapterhouse, fraternity_house, frat_house\",\n \"chapterhouse\",\n \"character_printer, character-at-a-time_printer, serial_printer\",\n \"charcuterie\",\n \"charge-exchange_accelerator\",\n \"charger, battery_charger\",\n \"chariot\",\n \"chariot\",\n \"charnel_house, charnel\",\n \"chassis\",\n \"chassis\",\n \"chasuble\",\n \"chateau\",\n \"chatelaine\",\n \"checker, chequer\",\n \"checkout, checkout_counter\",\n \"cheekpiece\",\n \"cheeseboard, cheese_tray\",\n \"cheesecloth\",\n \"cheese_cutter\",\n \"cheese_press\",\n \"chemical_bomb, gas_bomb\",\n \"chemical_plant\",\n \"chemical_reactor\",\n \"chemise, sack, shift\",\n \"chemise, shimmy, shift, slip, teddy\",\n \"chenille\",\n \"chessman, chess_piece\",\n \"chest\",\n \"chesterfield\",\n \"chest_of_drawers, chest, bureau, dresser\",\n \"chest_protector\",\n \"cheval-de-frise, chevaux-de-frise\",\n \"cheval_glass\",\n \"chicane\",\n \"chicken_coop, coop, hencoop, henhouse\",\n \"chicken_wire\",\n \"chicken_yard, hen_yard, chicken_run, fowl_run\",\n \"chiffon\",\n \"chiffonier, commode\",\n \"child's_room\",\n \"chime, bell, gong\",\n \"chimney_breast\",\n \"chimney_corner, inglenook\",\n \"china\",\n \"china_cabinet, china_closet\",\n \"chinchilla\",\n \"chinese_lantern\",\n \"chinese_puzzle\",\n \"chinning_bar\",\n \"chino\",\n \"chino\",\n \"chin_rest\",\n \"chin_strap\",\n \"chintz\",\n \"chip, microchip, micro_chip, silicon_chip, microprocessor_chip\",\n \"chip, poker_chip\",\n \"chisel\",\n \"chlamys\",\n \"choir\",\n \"choir_loft\",\n \"choke\",\n \"choke, choke_coil, choking_coil\",\n \"chokey, choky\",\n \"choo-choo\",\n \"chopine, platform\",\n \"chordophone\",\n \"christmas_stocking\",\n \"chronograph\",\n \"chronometer\",\n \"chronoscope\",\n \"chuck\",\n \"chuck_wagon\",\n \"chukka, chukka_boot\",\n \"church, church_building\",\n \"church_bell\",\n \"church_hat\",\n \"church_key\",\n \"church_tower\",\n \"churidars\",\n \"churn, butter_churn\",\n \"ciderpress\",\n \"cigar_band\",\n \"cigar_box\",\n \"cigar_cutter\",\n \"cigarette_butt\",\n \"cigarette_case\",\n \"cigarette_holder\",\n \"cigar_lighter, cigarette_lighter, pocket_lighter\",\n \"cinch, girth\",\n \"cinema, movie_theater, movie_theatre, movie_house, picture_palace\",\n \"cinquefoil\",\n \"circle, round\",\n \"circlet\",\n \"circuit, electrical_circuit, electric_circuit\",\n \"circuit_board, circuit_card, board, card, plug-in, add-in\",\n \"circuit_breaker, breaker\",\n \"circuitry\",\n \"circular_plane, compass_plane\",\n \"circular_saw, buzz_saw\",\n \"circus_tent, big_top, round_top, top\",\n \"cistern\",\n \"cistern, water_tank\",\n \"cittern, cithern, cither, citole, gittern\",\n \"city_hall\",\n \"cityscape\",\n \"city_university\",\n \"civies, civvies\",\n \"civilian_clothing, civilian_dress, civilian_garb, plain_clothes\",\n \"clack_valve, clack, clapper_valve\",\n \"clamp, clinch\",\n \"clamshell, grapple\",\n \"clapper, tongue\",\n \"clapperboard\",\n \"clarence\",\n \"clarinet\",\n \"clark_cell, clark_standard_cell\",\n \"clasp\",\n \"clasp_knife, jackknife\",\n \"classroom, schoolroom\",\n \"clavichord\",\n \"clavier, klavier\",\n \"clay_pigeon\",\n \"claymore_mine, claymore\",\n \"claymore\",\n \"cleaners, dry_cleaners\",\n \"cleaning_implement, cleaning_device, cleaning_equipment\",\n \"cleaning_pad\",\n \"clean_room, white_room\",\n \"clearway\",\n \"cleat\",\n \"cleat\",\n \"cleats\",\n \"cleaver, meat_cleaver, chopper\",\n \"clerestory, clearstory\",\n \"clevis\",\n \"clews\",\n \"cliff_dwelling\",\n \"climbing_frame\",\n \"clinch\",\n \"clinch, clench\",\n \"clincher\",\n \"clinic\",\n \"clinical_thermometer, mercury-in-glass_clinical_thermometer\",\n \"clinker, clinker_brick\",\n \"clinometer, inclinometer\",\n \"clip\",\n \"clip_lead\",\n \"clip-on\",\n \"clipper\",\n \"clipper\",\n \"clipper, clipper_ship\",\n \"cloak\",\n \"cloak\",\n \"cloakroom, coatroom\",\n \"cloche\",\n \"cloche\",\n \"clock\",\n \"clock_pendulum\",\n \"clock_radio\",\n \"clock_tower\",\n \"clockwork\",\n \"clog, geta, patten, sabot\",\n \"cloisonne\",\n \"cloister\",\n \"closed_circuit, loop\",\n \"closed-circuit_television\",\n \"closed_loop, closed-loop_system\",\n \"closet\",\n \"closeup_lens\",\n \"cloth_cap, flat_cap\",\n \"cloth_covering\",\n \"clothesbrush\",\n \"clothes_closet, clothespress\",\n \"clothes_dryer, clothes_drier\",\n \"clothes_hamper, laundry_basket, clothes_basket, voider\",\n \"clotheshorse\",\n \"clothespin, clothes_pin, clothes_peg\",\n \"clothes_tree, coat_tree, coat_stand\",\n \"clothing, article_of_clothing, vesture, wear, wearable, habiliment\",\n \"clothing_store, haberdashery, haberdashery_store, mens_store\",\n \"clout_nail, clout\",\n \"clove_hitch\",\n \"club_car, lounge_car\",\n \"clubroom\",\n \"cluster_bomb\",\n \"clutch\",\n \"clutch, clutch_pedal\",\n \"clutch_bag, clutch\",\n \"coach, four-in-hand, coach-and-four\",\n \"coach_house, carriage_house, remise\",\n \"coal_car\",\n \"coal_chute\",\n \"coal_house\",\n \"coal_shovel\",\n \"coaming\",\n \"coaster_brake\",\n \"coat\",\n \"coat_button\",\n \"coat_closet\",\n \"coatdress\",\n \"coatee\",\n \"coat_hanger, clothes_hanger, dress_hanger\",\n \"coating, coat\",\n \"coating\",\n \"coat_of_paint\",\n \"coatrack, coat_rack, hatrack\",\n \"coattail\",\n \"coaxial_cable, coax, coax_cable\",\n \"cobweb\",\n \"cobweb\",\n \"cockcroft_and_walton_accelerator, cockcroft-walton_accelerator, cockcroft_and_walton_voltage_multiplier, cockcroft-walton_voltage_multiplier\",\n \"cocked_hat\",\n \"cockhorse\",\n \"cockleshell\",\n \"cockpit\",\n \"cockpit\",\n \"cockpit\",\n \"cockscomb, coxcomb\",\n \"cocktail_dress, sheath\",\n \"cocktail_lounge\",\n \"cocktail_shaker\",\n \"cocotte\",\n \"codpiece\",\n \"coelostat\",\n \"coffee_can\",\n \"coffee_cup\",\n \"coffee_filter\",\n \"coffee_maker\",\n \"coffee_mill, coffee_grinder\",\n \"coffee_mug\",\n \"coffeepot\",\n \"coffee_stall\",\n \"coffee_table, cocktail_table\",\n \"coffee_urn\",\n \"coffer\",\n \"coffey_still\",\n \"coffin, casket\",\n \"cog, sprocket\",\n \"coif\",\n \"coil, spiral, volute, whorl, helix\",\n \"coil\",\n \"coil\",\n \"coil_spring, volute_spring\",\n \"coin_box\",\n \"colander, cullender\",\n \"cold_cathode\",\n \"cold_chisel, set_chisel\",\n \"cold_cream, coldcream, face_cream, vanishing_cream\",\n \"cold_frame\",\n \"collar, neckband\",\n \"collar\",\n \"college\",\n \"collet, collet_chuck\",\n \"collider\",\n \"colliery, pit\",\n \"collimator\",\n \"collimator\",\n \"cologne, cologne_water, eau_de_cologne\",\n \"colonnade\",\n \"colonoscope\",\n \"colorimeter, tintometer\",\n \"colors, colours\",\n \"color_television, colour_television, color_television_system, colour_television_system, color_tv, colour_tv\",\n \"color_tube, colour_tube, color_television_tube, colour_television_tube, color_tv_tube, colour_tv_tube\",\n \"color_wash, colour_wash\",\n \"colt\",\n \"colter, coulter\",\n \"columbarium\",\n \"columbarium, cinerarium\",\n \"column, pillar\",\n \"column, pillar\",\n \"comb\",\n \"comb\",\n \"comber\",\n \"combination_lock\",\n \"combination_plane\",\n \"combine\",\n \"comforter, pacifier, baby's_dummy, teething_ring\",\n \"command_module\",\n \"commissary\",\n \"commissary\",\n \"commodity, trade_good, good\",\n \"common_ax, common_axe, dayton_ax, dayton_axe\",\n \"common_room\",\n \"communications_satellite\",\n \"communication_system\",\n \"community_center, civic_center\",\n \"commutator\",\n \"commuter, commuter_train\",\n \"compact, powder_compact\",\n \"compact, compact_car\",\n \"compact_disk, compact_disc, cd\",\n \"compact-disk_burner, cd_burner\",\n \"companionway\",\n \"compartment\",\n \"compartment\",\n \"compass\",\n \"compass\",\n \"compass_card, mariner's_compass\",\n \"compass_saw\",\n \"compound\",\n \"compound_lens\",\n \"compound_lever\",\n \"compound_microscope\",\n \"compress\",\n \"compression_bandage, tourniquet\",\n \"compressor\",\n \"computer, computing_machine, computing_device, data_processor, electronic_computer, information_processing_system\",\n \"computer_circuit\",\n \"computerized_axial_tomography_scanner, cat_scanner\",\n \"computer_keyboard, keypad\",\n \"computer_monitor\",\n \"computer_network\",\n \"computer_screen, computer_display\",\n \"computer_store\",\n \"computer_system, computing_system, automatic_data_processing_system, adp_system, adps\",\n \"concentration_camp, stockade\",\n \"concert_grand, concert_piano\",\n \"concert_hall\",\n \"concertina\",\n \"concertina\",\n \"concrete_mixer, cement_mixer\",\n \"condensation_pump, diffusion_pump\",\n \"condenser, optical_condenser\",\n \"condenser\",\n \"condenser\",\n \"condenser_microphone, capacitor_microphone\",\n \"condominium\",\n \"condominium, condo\",\n \"conductor\",\n \"cone_clutch, cone_friction_clutch\",\n \"confectionery, confectionary, candy_store\",\n \"conference_center, conference_house\",\n \"conference_room\",\n \"conference_table, council_table, council_board\",\n \"confessional\",\n \"conformal_projection, orthomorphic_projection\",\n \"congress_boot, congress_shoe, congress_gaiter\",\n \"conic_projection, conical_projection\",\n \"connecting_rod\",\n \"connecting_room\",\n \"connection, connexion, connector, connecter, connective\",\n \"conning_tower\",\n \"conning_tower\",\n \"conservatory, hothouse, indoor_garden\",\n \"conservatory, conservatoire\",\n \"console\",\n \"console\",\n \"console_table, console\",\n \"consulate\",\n \"contact, tangency\",\n \"contact, contact_lens\",\n \"container\",\n \"container_ship, containership, container_vessel\",\n \"containment\",\n \"contrabassoon, contrafagotto, double_bassoon\",\n \"control, controller\",\n \"control_center\",\n \"control_circuit, negative_feedback_circuit\",\n \"control_key, command_key\",\n \"control_panel, instrument_panel, control_board, board, panel\",\n \"control_rod\",\n \"control_room\",\n \"control_system\",\n \"control_tower\",\n \"convector\",\n \"convenience_store\",\n \"convent\",\n \"conventicle, meetinghouse\",\n \"converging_lens, convex_lens\",\n \"converter, convertor\",\n \"convertible\",\n \"convertible, sofa_bed\",\n \"conveyance, transport\",\n \"conveyer_belt, conveyor_belt, conveyer, conveyor, transporter\",\n \"cooker\",\n \"cookfire\",\n \"cookhouse\",\n \"cookie_cutter\",\n \"cookie_jar, cooky_jar\",\n \"cookie_sheet, baking_tray\",\n \"cooking_utensil, cookware\",\n \"cookstove\",\n \"coolant_system\",\n \"cooler, ice_chest\",\n \"cooling_system, cooling\",\n \"cooling_system, engine_cooling_system\",\n \"cooling_tower\",\n \"coonskin_cap, coonskin\",\n \"cope\",\n \"coping_saw\",\n \"copperware\",\n \"copyholder\",\n \"coquille\",\n \"coracle\",\n \"corbel, truss\",\n \"corbel_arch\",\n \"corbel_step, corbie-step, corbiestep, crow_step\",\n \"corbie_gable\",\n \"cord, corduroy\",\n \"cord, electric_cord\",\n \"cordage\",\n \"cords, corduroys\",\n \"core\",\n \"core_bit\",\n \"core_drill\",\n \"corer\",\n \"cork, bottle_cork\",\n \"corker\",\n \"corkscrew, bottle_screw\",\n \"corncrib\",\n \"corner, quoin\",\n \"corner, nook\",\n \"corner_post\",\n \"cornet, horn, trumpet, trump\",\n \"cornice\",\n \"cornice\",\n \"cornice, valance, valance_board, pelmet\",\n \"correctional_institution\",\n \"corrugated_fastener, wiggle_nail\",\n \"corselet, corslet\",\n \"corset, girdle, stays\",\n \"cosmetic\",\n \"cosmotron\",\n \"costume\",\n \"costume\",\n \"costume\",\n \"costume\",\n \"cosy, tea_cosy, cozy, tea_cozy\",\n \"cot, camp_bed\",\n \"cottage_tent\",\n \"cotter, cottar\",\n \"cotter_pin\",\n \"cotton\",\n \"cotton_flannel, canton_flannel\",\n \"cotton_mill\",\n \"couch\",\n \"couch\",\n \"couchette\",\n \"coude_telescope, coude_system\",\n \"counter\",\n \"counter, tabulator\",\n \"counter\",\n \"counterbore, countersink, countersink_bit\",\n \"counter_tube\",\n \"country_house\",\n \"country_store, general_store, trading_post\",\n \"coupe\",\n \"coupling, coupler\",\n \"court, courtyard\",\n \"court\",\n \"court, courtroom\",\n \"court\",\n \"courtelle\",\n \"courthouse\",\n \"courthouse\",\n \"coverall\",\n \"covered_bridge\",\n \"covered_couch\",\n \"covered_wagon, conestoga_wagon, conestoga, prairie_wagon, prairie_schooner\",\n \"covering\",\n \"coverlet\",\n \"cover_plate\",\n \"cowbarn, cowshed, cow_barn, cowhouse, byre\",\n \"cowbell\",\n \"cowboy_boot\",\n \"cowboy_hat, ten-gallon_hat\",\n \"cowhide\",\n \"cowl\",\n \"cow_pen, cattle_pen, corral\",\n \"cpu_board, mother_board\",\n \"crackle, crackleware, crackle_china\",\n \"cradle\",\n \"craft\",\n \"cramp, cramp_iron\",\n \"crampon, crampoon, climbing_iron, climber\",\n \"crampon, crampoon\",\n \"crane\",\n \"craniometer\",\n \"crank, starter\",\n \"crankcase\",\n \"crankshaft\",\n \"crash_barrier\",\n \"crash_helmet\",\n \"crate\",\n \"cravat\",\n \"crayon, wax_crayon\",\n \"crazy_quilt\",\n \"cream, ointment, emollient\",\n \"cream_pitcher, creamer\",\n \"creche, foundling_hospital\",\n \"creche\",\n \"credenza, credence\",\n \"creel\",\n \"crematory, crematorium, cremation_chamber\",\n \"crematory, crematorium\",\n \"crepe, crape\",\n \"crepe_de_chine\",\n \"crescent_wrench\",\n \"cretonne\",\n \"crib, cot\",\n \"crib\",\n \"cricket_ball\",\n \"cricket_bat, bat\",\n \"cricket_equipment\",\n \"cringle, eyelet, loop, grommet, grummet\",\n \"crinoline\",\n \"crinoline\",\n \"crochet_needle, crochet_hook\",\n \"crock, earthenware_jar\",\n \"crock_pot\",\n \"crook, shepherd's_crook\",\n \"crookes_radiometer\",\n \"crookes_tube\",\n \"croquet_ball\",\n \"croquet_equipment\",\n \"croquet_mallet\",\n \"cross\",\n \"crossbar\",\n \"crossbar\",\n \"crossbar\",\n \"crossbench\",\n \"cross_bit\",\n \"crossbow\",\n \"crosscut_saw, crosscut_handsaw, cutoff_saw\",\n \"crossjack, mizzen_course\",\n \"crosspiece\",\n \"crotchet\",\n \"croupier's_rake\",\n \"crowbar, wrecking_bar, pry, pry_bar\",\n \"crown, diadem\",\n \"crown, crownwork, jacket, jacket_crown, cap\",\n \"crown_jewels\",\n \"crown_lens\",\n \"crow's_nest\",\n \"crucible, melting_pot\",\n \"crucifix, rood, rood-tree\",\n \"cruet, crewet\",\n \"cruet-stand\",\n \"cruise_control\",\n \"cruise_missile\",\n \"cruiser\",\n \"cruiser, police_cruiser, patrol_car, police_car, prowl_car, squad_car\",\n \"cruise_ship, cruise_liner\",\n \"crupper\",\n \"cruse\",\n \"crusher\",\n \"crutch\",\n \"cryometer\",\n \"cryoscope\",\n \"cryostat\",\n \"crypt\",\n \"crystal, watch_crystal, watch_glass\",\n \"crystal_detector\",\n \"crystal_microphone\",\n \"crystal_oscillator, quartz_oscillator\",\n \"crystal_set\",\n \"cubitiere\",\n \"cucking_stool, ducking_stool\",\n \"cuckoo_clock\",\n \"cuddy\",\n \"cudgel\",\n \"cue, cue_stick, pool_cue, pool_stick\",\n \"cue_ball\",\n \"cuff, turnup\",\n \"cuirass\",\n \"cuisse\",\n \"cul, cul_de_sac, dead_end\",\n \"culdoscope\",\n \"cullis\",\n \"culotte\",\n \"cultivator, tiller\",\n \"culverin\",\n \"culverin\",\n \"culvert\",\n \"cup\",\n \"cupboard, closet\",\n \"cup_hook\",\n \"cupola\",\n \"cupola\",\n \"curb, curb_bit\",\n \"curb_roof\",\n \"curbstone, kerbstone\",\n \"curette, curet\",\n \"curler, hair_curler, roller, crimper\",\n \"curling_iron\",\n \"currycomb\",\n \"cursor, pointer\",\n \"curtain, drape, drapery, mantle, pall\",\n \"customhouse, customshouse\",\n \"cutaway, cutaway_drawing, cutaway_model\",\n \"cutlas, cutlass\",\n \"cutoff\",\n \"cutout\",\n \"cutter, cutlery, cutting_tool\",\n \"cutter\",\n \"cutting_implement\",\n \"cutting_room\",\n \"cutty_stool\",\n \"cutwork\",\n \"cybercafe\",\n \"cyclopean_masonry\",\n \"cyclostyle\",\n \"cyclotron\",\n \"cylinder\",\n \"cylinder, piston_chamber\",\n \"cylinder_lock\",\n \"cymbal\",\n \"dacha\",\n \"dacron, terylene\",\n \"dado\",\n \"dado_plane\",\n \"dagger, sticker\",\n \"dairy, dairy_farm\",\n \"dais, podium, pulpit, rostrum, ambo, stump, soapbox\",\n \"daisy_print_wheel, daisy_wheel\",\n \"daisywheel_printer\",\n \"dam, dike, dyke\",\n \"damask\",\n \"dampener, moistener\",\n \"damper, muffler\",\n \"damper_block, piano_damper\",\n \"dark_lantern, bull's-eye\",\n \"darkroom\",\n \"darning_needle, embroidery_needle\",\n \"dart\",\n \"dart\",\n \"dashboard, fascia\",\n \"dashiki, daishiki\",\n \"dash-pot\",\n \"data_converter\",\n \"data_input_device, input_device\",\n \"data_multiplexer\",\n \"data_system, information_system\",\n \"davenport\",\n \"davenport\",\n \"davit\",\n \"daybed, divan_bed\",\n \"daybook, ledger\",\n \"day_nursery, day_care_center\",\n \"day_school\",\n \"dead_axle\",\n \"deadeye\",\n \"deadhead\",\n \"deanery\",\n \"deathbed\",\n \"death_camp\",\n \"death_house, death_row\",\n \"death_knell, death_bell\",\n \"death_seat\",\n \"deck\",\n \"deck\",\n \"deck_chair, beach_chair\",\n \"deck-house\",\n \"deckle\",\n \"deckle_edge, deckle\",\n \"declinometer, transit_declinometer\",\n \"decoder\",\n \"decolletage\",\n \"decoupage\",\n \"dedicated_file_server\",\n \"deep-freeze, deepfreeze, deep_freezer, freezer\",\n \"deerstalker\",\n \"defense_system, defence_system\",\n \"defensive_structure, defense, defence\",\n \"defibrillator\",\n \"defilade\",\n \"deflector\",\n \"delayed_action\",\n \"delay_line\",\n \"delft\",\n \"delicatessen, deli, food_shop\",\n \"delivery_truck, delivery_van, panel_truck\",\n \"delta_wing\",\n \"demijohn\",\n \"demitasse\",\n \"den\",\n \"denim, dungaree, jean\",\n \"densimeter, densitometer\",\n \"densitometer\",\n \"dental_appliance\",\n \"dental_floss, floss\",\n \"dental_implant\",\n \"dentist's_drill, burr_drill\",\n \"denture, dental_plate, plate\",\n \"deodorant, deodourant\",\n \"department_store, emporium\",\n \"departure_lounge\",\n \"depilatory, depilator, epilator\",\n \"depressor\",\n \"depth_finder\",\n \"depth_gauge, depth_gage\",\n \"derrick\",\n \"derrick\",\n \"derringer\",\n \"desk\",\n \"desk_phone\",\n \"desktop_computer\",\n \"dessert_spoon\",\n \"destroyer, guided_missile_destroyer\",\n \"destroyer_escort\",\n \"detached_house, single_dwelling\",\n \"detector, sensor, sensing_element\",\n \"detector\",\n \"detention_home, detention_house, house_of_detention, detention_camp\",\n \"detonating_fuse\",\n \"detonator, detonating_device, cap\",\n \"developer\",\n \"device\",\n \"dewar_flask, dewar\",\n \"dhoti\",\n \"dhow\",\n \"dial, telephone_dial\",\n \"dial\",\n \"dial\",\n \"dialog_box, panel\",\n \"dial_telephone, dial_phone\",\n \"dialyzer, dialysis_machine\",\n \"diamante\",\n \"diaper, nappy, napkin\",\n \"diaper\",\n \"diaphone\",\n \"diaphragm, stop\",\n \"diaphragm\",\n \"diathermy_machine\",\n \"dibble, dibber\",\n \"dice_cup, dice_box\",\n \"dicer\",\n \"dickey, dickie, dicky, shirtfront\",\n \"dickey, dickie, dicky, dickey-seat, dickie-seat, dicky-seat\",\n \"dictaphone\",\n \"die\",\n \"diesel, diesel_engine, diesel_motor\",\n \"diesel-electric_locomotive, diesel-electric\",\n \"diesel-hydraulic_locomotive, diesel-hydraulic\",\n \"diesel_locomotive\",\n \"diestock\",\n \"differential_analyzer\",\n \"differential_gear, differential\",\n \"diffuser, diffusor\",\n \"diffuser, diffusor\",\n \"digester\",\n \"diggings, digs, domiciliation, lodgings, pad\",\n \"digital-analog_converter, digital-to-analog_converter\",\n \"digital_audiotape, dat\",\n \"digital_camera\",\n \"digital_clock\",\n \"digital_computer\",\n \"digital_display, alphanumeric_display\",\n \"digital_subscriber_line, dsl\",\n \"digital_voltmeter\",\n \"digital_watch\",\n \"digitizer, digitiser, analog-digital_converter, analog-to-digital_converter\",\n \"dilator, dilater\",\n \"dildo\",\n \"dimity\",\n \"dimmer\",\n \"diner\",\n \"dinette\",\n \"dinghy, dory, rowboat\",\n \"dining_area\",\n \"dining_car, diner, dining_compartment, buffet_car\",\n \"dining-hall\",\n \"dining_room, dining-room\",\n \"dining-room_furniture\",\n \"dining-room_table\",\n \"dining_table, board\",\n \"dinner_bell\",\n \"dinner_dress, dinner_gown, formal, evening_gown\",\n \"dinner_jacket, tux, tuxedo, black_tie\",\n \"dinner_napkin\",\n \"dinner_pail, dinner_bucket\",\n \"dinner_table\",\n \"dinner_theater, dinner_theatre\",\n \"diode, semiconductor_diode, junction_rectifier, crystal_rectifier\",\n \"diode, rectifying_tube, rectifying_valve\",\n \"dip\",\n \"diplomatic_building\",\n \"dipole, dipole_antenna\",\n \"dipper\",\n \"dipstick\",\n \"dip_switch, dual_inline_package_switch\",\n \"directional_antenna\",\n \"directional_microphone\",\n \"direction_finder\",\n \"dirk\",\n \"dirndl\",\n \"dirndl\",\n \"dirty_bomb\",\n \"discharge_lamp\",\n \"discharge_pipe\",\n \"disco, discotheque\",\n \"discount_house, discount_store, discounter, wholesale_house\",\n \"discus, saucer\",\n \"disguise\",\n \"dish\",\n \"dish, dish_aerial, dish_antenna, saucer\",\n \"dishpan\",\n \"dish_rack\",\n \"dishrag, dishcloth\",\n \"dishtowel, dish_towel, tea_towel\",\n \"dishwasher, dish_washer, dishwashing_machine\",\n \"disk, disc\",\n \"disk_brake, disc_brake\",\n \"disk_clutch\",\n \"disk_controller\",\n \"disk_drive, disc_drive, hard_drive, winchester_drive\",\n \"diskette, floppy, floppy_disk\",\n \"disk_harrow, disc_harrow\",\n \"dispatch_case, dispatch_box\",\n \"dispensary\",\n \"dispenser\",\n \"display, video_display\",\n \"display_adapter, display_adaptor\",\n \"display_panel, display_board, board\",\n \"display_window, shop_window, shopwindow, show_window\",\n \"disposal, electric_pig, garbage_disposal\",\n \"disrupting_explosive, bursting_explosive\",\n \"distaff\",\n \"distillery, still\",\n \"distributor, distributer, electrical_distributor\",\n \"distributor_cam\",\n \"distributor_cap\",\n \"distributor_housing\",\n \"distributor_point, breaker_point, point\",\n \"ditch\",\n \"ditch_spade, long-handled_spade\",\n \"ditty_bag\",\n \"divan\",\n \"divan, diwan\",\n \"dive_bomber\",\n \"diverging_lens, concave_lens\",\n \"divided_highway, dual_carriageway\",\n \"divider\",\n \"diving_bell\",\n \"divining_rod, dowser, dowsing_rod, waterfinder, water_finder\",\n \"diving_suit, diving_dress\",\n \"dixie\",\n \"dixie_cup, paper_cup\",\n \"dock, dockage, docking_facility\",\n \"doeskin\",\n \"dogcart\",\n \"doggie_bag, doggy_bag\",\n \"dogsled, dog_sled, dog_sleigh\",\n \"dog_wrench\",\n \"doily, doyley, doyly\",\n \"doll, dolly\",\n \"dollhouse, doll's_house\",\n \"dolly\",\n \"dolman\",\n \"dolman, dolman_jacket\",\n \"dolman_sleeve\",\n \"dolmen, cromlech, portal_tomb\",\n \"dome\",\n \"dome, domed_stadium, covered_stadium\",\n \"domino, half_mask, eye_mask\",\n \"dongle\",\n \"donkey_jacket\",\n \"door\",\n \"door\",\n \"door\",\n \"doorbell, bell, buzzer\",\n \"doorframe, doorcase\",\n \"doorjamb, doorpost\",\n \"doorlock\",\n \"doormat, welcome_mat\",\n \"doornail\",\n \"doorplate\",\n \"doorsill, doorstep, threshold\",\n \"doorstop, doorstopper\",\n \"doppler_radar\",\n \"dormer, dormer_window\",\n \"dormer_window\",\n \"dormitory, dorm, residence_hall, hall, student_residence\",\n \"dormitory, dormitory_room, dorm_room\",\n \"dosemeter, dosimeter\",\n \"dossal, dossel\",\n \"dot_matrix_printer, matrix_printer, dot_printer\",\n \"double_bed\",\n \"double-bitted_ax, double-bitted_axe, western_ax, western_axe\",\n \"double_boiler, double_saucepan\",\n \"double-breasted_jacket\",\n \"double-breasted_suit\",\n \"double_door\",\n \"double_glazing\",\n \"double-hung_window\",\n \"double_knit\",\n \"doubler\",\n \"double_reed\",\n \"double-reed_instrument, double_reed\",\n \"doublet\",\n \"doubletree\",\n \"douche, douche_bag\",\n \"dovecote, columbarium, columbary\",\n \"dover's_powder\",\n \"dovetail, dovetail_joint\",\n \"dovetail_plane\",\n \"dowel, dowel_pin, joggle\",\n \"downstage\",\n \"drafting_instrument\",\n \"drafting_table, drawing_table\",\n \"dragunov\",\n \"drainage_ditch\",\n \"drainage_system\",\n \"drain_basket\",\n \"drainplug\",\n \"drape\",\n \"drapery\",\n \"drawbar\",\n \"drawbridge, lift_bridge\",\n \"drawer\",\n \"drawers, underdrawers, shorts, boxers, boxershorts\",\n \"drawing_chalk\",\n \"drawing_room, withdrawing_room\",\n \"drawing_room\",\n \"drawknife, drawshave\",\n \"drawstring_bag\",\n \"dray, camion\",\n \"dreadnought, dreadnaught\",\n \"dredge\",\n \"dredger\",\n \"dredging_bucket\",\n \"dress, frock\",\n \"dress_blues, dress_whites\",\n \"dresser\",\n \"dress_hat, high_hat, opera_hat, silk_hat, stovepipe, top_hat, topper, beaver\",\n \"dressing, medical_dressing\",\n \"dressing_case\",\n \"dressing_gown, robe-de-chambre, lounging_robe\",\n \"dressing_room\",\n \"dressing_sack, dressing_sacque\",\n \"dressing_table, dresser, vanity, toilet_table\",\n \"dress_rack\",\n \"dress_shirt, evening_shirt\",\n \"dress_suit, full_dress, tailcoat, tail_coat, tails, white_tie, white_tie_and_tails\",\n \"dress_uniform\",\n \"drift_net\",\n \"drill\",\n \"electric_drill\",\n \"drilling_platform, offshore_rig\",\n \"drill_press\",\n \"drill_rig, drilling_rig, oilrig, oil_rig\",\n \"drinking_fountain, water_fountain, bubbler\",\n \"drinking_vessel\",\n \"drip_loop\",\n \"drip_mat\",\n \"drip_pan\",\n \"dripping_pan, drip_pan\",\n \"drip_pot\",\n \"drive\",\n \"drive\",\n \"drive_line, drive_line_system\",\n \"driver, number_one_wood\",\n \"driveshaft\",\n \"driveway, drive, private_road\",\n \"driving_iron, one_iron\",\n \"driving_wheel\",\n \"drogue, drogue_chute, drogue_parachute\",\n \"drogue_parachute\",\n \"drone, drone_pipe, bourdon\",\n \"drone, pilotless_aircraft, radio-controlled_aircraft\",\n \"drop_arch\",\n \"drop_cloth\",\n \"drop_curtain, drop_cloth, drop\",\n \"drop_forge, drop_hammer, drop_press\",\n \"drop-leaf_table\",\n \"dropper, eye_dropper\",\n \"droshky, drosky\",\n \"drove, drove_chisel\",\n \"drugget\",\n \"drugstore, apothecary's_shop, chemist's, chemist's_shop, pharmacy\",\n \"drum, membranophone, tympan\",\n \"drum, metal_drum\",\n \"drum_brake\",\n \"drumhead, head\",\n \"drum_printer\",\n \"drum_sander, electric_sander, sander, smoother\",\n \"drumstick\",\n \"dry_battery\",\n \"dry-bulb_thermometer\",\n \"dry_cell\",\n \"dry_dock, drydock, graving_dock\",\n \"dryer, drier\",\n \"dry_fly\",\n \"dry_kiln\",\n \"dry_masonry\",\n \"dry_point\",\n \"dry_wall, dry-stone_wall\",\n \"dual_scan_display\",\n \"duck\",\n \"duckboard\",\n \"duckpin\",\n \"dudeen\",\n \"duffel, duffle\",\n \"duffel_bag, duffle_bag, duffel, duffle\",\n \"duffel_coat, duffle_coat\",\n \"dugout\",\n \"dugout_canoe, dugout, pirogue\",\n \"dulciana\",\n \"dulcimer\",\n \"dulcimer\",\n \"dumbbell\",\n \"dumb_bomb, gravity_bomb\",\n \"dumbwaiter, food_elevator\",\n \"dumdum, dumdum_bullet\",\n \"dumpcart\",\n \"dumpster\",\n \"dump_truck, dumper, tipper_truck, tipper_lorry, tip_truck, tipper\",\n \"dumpy_level\",\n \"dunce_cap, dunce's_cap, fool's_cap\",\n \"dune_buggy, beach_buggy\",\n \"dungeon\",\n \"duplex_apartment, duplex\",\n \"duplex_house, duplex, semidetached_house\",\n \"duplicator, copier\",\n \"dust_bag, vacuum_bag\",\n \"dustcloth, dustrag, duster\",\n \"dust_cover\",\n \"dust_cover, dust_sheet\",\n \"dustmop, dust_mop, dry_mop\",\n \"dustpan\",\n \"dutch_oven\",\n \"dutch_oven\",\n \"dwelling, home, domicile, abode, habitation, dwelling_house\",\n \"dye-works\",\n \"dynamo\",\n \"dynamometer, ergometer\",\n \"eames_chair\",\n \"earflap, earlap\",\n \"early_warning_radar\",\n \"early_warning_system\",\n \"earmuff\",\n \"earphone, earpiece, headphone, phone\",\n \"earplug\",\n \"earplug\",\n \"earthenware\",\n \"earthwork\",\n \"easel\",\n \"easy_chair, lounge_chair, overstuffed_chair\",\n \"eaves\",\n \"ecclesiastical_attire, ecclesiastical_robe\",\n \"echinus\",\n \"echocardiograph\",\n \"edger\",\n \"edge_tool\",\n \"efficiency_apartment\",\n \"egg-and-dart, egg-and-anchor, egg-and-tongue\",\n \"eggbeater, eggwhisk\",\n \"egg_timer\",\n \"eiderdown, duvet, continental_quilt\",\n \"eight_ball\",\n \"ejection_seat, ejector_seat, capsule\",\n \"elastic\",\n \"elastic_bandage\",\n \"elastoplast\",\n \"elbow\",\n \"elbow_pad\",\n \"electric, electric_automobile, electric_car\",\n \"electrical_cable\",\n \"electrical_contact\",\n \"electrical_converter\",\n \"electrical_device\",\n \"electrical_system\",\n \"electric_bell\",\n \"electric_blanket\",\n \"electric_chair, chair, death_chair, hot_seat\",\n \"electric_clock\",\n \"electric-discharge_lamp, gas-discharge_lamp\",\n \"electric_fan, blower\",\n \"electric_frying_pan\",\n \"electric_furnace\",\n \"electric_guitar\",\n \"electric_hammer\",\n \"electric_heater, electric_fire\",\n \"electric_lamp\",\n \"electric_locomotive\",\n \"electric_meter, power_meter\",\n \"electric_mixer\",\n \"electric_motor\",\n \"electric_organ, electronic_organ, hammond_organ, organ\",\n \"electric_range\",\n \"electric_refrigerator, fridge\",\n \"electric_toothbrush\",\n \"electric_typewriter\",\n \"electro-acoustic_transducer\",\n \"electrode\",\n \"electrodynamometer\",\n \"electroencephalograph\",\n \"electrograph\",\n \"electrolytic, electrolytic_capacitor, electrolytic_condenser\",\n \"electrolytic_cell\",\n \"electromagnet\",\n \"electrometer\",\n \"electromyograph\",\n \"electron_accelerator\",\n \"electron_gun\",\n \"electronic_balance\",\n \"electronic_converter\",\n \"electronic_device\",\n \"electronic_equipment\",\n \"electronic_fetal_monitor, electronic_foetal_monitor, fetal_monitor, foetal_monitor\",\n \"electronic_instrument, electronic_musical_instrument\",\n \"electronic_voltmeter\",\n \"electron_microscope\",\n \"electron_multiplier\",\n \"electrophorus\",\n \"electroscope\",\n \"electrostatic_generator, electrostatic_machine, wimshurst_machine, van_de_graaff_generator\",\n \"electrostatic_printer\",\n \"elevator, lift\",\n \"elevator\",\n \"elevator_shaft\",\n \"embankment\",\n \"embassy\",\n \"embellishment\",\n \"emergency_room, er\",\n \"emesis_basin\",\n \"emitter\",\n \"empty\",\n \"emulsion, photographic_emulsion\",\n \"enamel\",\n \"enamel\",\n \"enamelware\",\n \"encaustic\",\n \"encephalogram, pneumoencephalogram\",\n \"enclosure\",\n \"endoscope\",\n \"energizer, energiser\",\n \"engine\",\n \"engine\",\n \"engineering, engine_room\",\n \"enginery\",\n \"english_horn, cor_anglais\",\n \"english_saddle, english_cavalry_saddle\",\n \"enlarger\",\n \"ensemble\",\n \"ensign\",\n \"entablature\",\n \"entertainment_center\",\n \"entrenching_tool, trenching_spade\",\n \"entrenchment, intrenchment\",\n \"envelope\",\n \"envelope\",\n \"envelope, gasbag\",\n \"eolith\",\n \"epauliere\",\n \"epee\",\n \"epergne\",\n \"epicyclic_train, epicyclic_gear_train\",\n \"epidiascope\",\n \"epilating_wax\",\n \"equalizer, equaliser\",\n \"equatorial\",\n \"equipment\",\n \"erasable_programmable_read-only_memory, eprom\",\n \"eraser\",\n \"erecting_prism\",\n \"erection\",\n \"erlenmeyer_flask\",\n \"escape_hatch\",\n \"escapement\",\n \"escape_wheel\",\n \"escarpment, escarp, scarp, protective_embankment\",\n \"escutcheon, scutcheon\",\n \"esophagoscope, oesophagoscope\",\n \"espadrille\",\n \"espalier\",\n \"espresso_maker\",\n \"espresso_shop\",\n \"establishment\",\n \"estaminet\",\n \"estradiol_patch\",\n \"etagere\",\n \"etamine, etamin\",\n \"etching\",\n \"ethernet\",\n \"ethernet_cable\",\n \"eton_jacket\",\n \"etui\",\n \"eudiometer\",\n \"euphonium\",\n \"evaporative_cooler\",\n \"evening_bag\",\n \"exercise_bike, exercycle\",\n \"exercise_device\",\n \"exhaust, exhaust_system\",\n \"exhaust_fan\",\n \"exhaust_valve\",\n \"exhibition_hall, exhibition_area\",\n \"exocet\",\n \"expansion_bit, expansive_bit\",\n \"expansion_bolt\",\n \"explosive_detection_system, eds\",\n \"explosive_device\",\n \"explosive_trace_detection, etd\",\n \"express, limited\",\n \"extension, telephone_extension, extension_phone\",\n \"extension_cord\",\n \"external-combustion_engine\",\n \"external_drive\",\n \"extractor\",\n \"eyebrow_pencil\",\n \"eyecup, eyebath, eye_cup\",\n \"eyeliner\",\n \"eyepatch, patch\",\n \"eyepiece, ocular\",\n \"eyeshadow\",\n \"fabric, cloth, material, textile\",\n \"facade, frontage, frontal\",\n \"face_guard\",\n \"face_mask\",\n \"faceplate\",\n \"face_powder\",\n \"face_veil\",\n \"facing, cladding\",\n \"facing\",\n \"facing, veneer\",\n \"facsimile, facsimile_machine, fax\",\n \"factory, mill, manufacturing_plant, manufactory\",\n \"factory_ship\",\n \"fagot, faggot\",\n \"fagot_stitch, faggot_stitch\",\n \"fahrenheit_thermometer\",\n \"faience\",\n \"faille\",\n \"fairlead\",\n \"fairy_light\",\n \"falchion\",\n \"fallboard, fall-board\",\n \"fallout_shelter\",\n \"false_face\",\n \"false_teeth\",\n \"family_room\",\n \"fan\",\n \"fan_belt\",\n \"fan_blade\",\n \"fancy_dress, masquerade, masquerade_costume\",\n \"fanion\",\n \"fanlight\",\n \"fanjet, fan-jet, fanjet_engine, turbojet, turbojet_engine, turbofan, turbofan_engine\",\n \"fanjet, fan-jet, turbofan, turbojet\",\n \"fanny_pack, butt_pack\",\n \"fan_tracery\",\n \"fan_vaulting\",\n \"farm_building\",\n \"farmer's_market, green_market, greenmarket\",\n \"farmhouse\",\n \"farm_machine\",\n \"farmplace, farm-place, farmstead\",\n \"farmyard\",\n \"farthingale\",\n \"fastener, fastening, holdfast, fixing\",\n \"fast_reactor\",\n \"fat_farm\",\n \"fatigues\",\n \"faucet, spigot\",\n \"fauld\",\n \"fauteuil\",\n \"feather_boa, boa\",\n \"featheredge\",\n \"fedora, felt_hat, homburg, stetson, trilby\",\n \"feedback_circuit, feedback_loop\",\n \"feedlot\",\n \"fell, felled_seam\",\n \"felloe, felly\",\n \"felt\",\n \"felt-tip_pen, felt-tipped_pen, felt_tip, magic_marker\",\n \"felucca\",\n \"fence, fencing\",\n \"fencing_mask, fencer's_mask\",\n \"fencing_sword\",\n \"fender, wing\",\n \"fender, buffer, cowcatcher, pilot\",\n \"ferris_wheel\",\n \"ferrule, collet\",\n \"ferry, ferryboat\",\n \"ferule\",\n \"festoon\",\n \"fetoscope, foetoscope\",\n \"fetter, hobble\",\n \"fez, tarboosh\",\n \"fiber, fibre, vulcanized_fiber\",\n \"fiber_optic_cable, fibre_optic_cable\",\n \"fiberscope\",\n \"fichu\",\n \"fiddlestick, violin_bow\",\n \"field_artillery, field_gun\",\n \"field_coil, field_winding\",\n \"field-effect_transistor, fet\",\n \"field-emission_microscope\",\n \"field_glass, glass, spyglass\",\n \"field_hockey_ball\",\n \"field_hospital\",\n \"field_house, sports_arena\",\n \"field_lens\",\n \"field_magnet\",\n \"field-sequential_color_television, field-sequential_color_tv, field-sequential_color_television_system, field-sequential_color_tv_system\",\n \"field_tent\",\n \"fieldwork\",\n \"fife\",\n \"fifth_wheel, spare\",\n \"fighter, fighter_aircraft, attack_aircraft\",\n \"fighting_chair\",\n \"fig_leaf\",\n \"figure_eight, figure_of_eight\",\n \"figure_loom, figured-fabric_loom\",\n \"figure_skate\",\n \"filament\",\n \"filature\",\n \"file\",\n \"file, file_cabinet, filing_cabinet\",\n \"file_folder\",\n \"file_server\",\n \"filigree, filagree, fillagree\",\n \"filling\",\n \"film, photographic_film\",\n \"film, plastic_film\",\n \"film_advance\",\n \"filter\",\n \"filter\",\n \"finder, viewfinder, view_finder\",\n \"finery\",\n \"fine-tooth_comb, fine-toothed_comb\",\n \"finger\",\n \"fingerboard\",\n \"finger_bowl\",\n \"finger_paint, fingerpaint\",\n \"finger-painting\",\n \"finger_plate, escutcheon, scutcheon\",\n \"fingerstall, cot\",\n \"finish_coat, finishing_coat\",\n \"finish_coat, finishing_coat\",\n \"finisher\",\n \"fin_keel\",\n \"fipple\",\n \"fipple_flute, fipple_pipe, recorder, vertical_flute\",\n \"fire\",\n \"fire_alarm, smoke_alarm\",\n \"firearm, piece, small-arm\",\n \"fire_bell\",\n \"fireboat\",\n \"firebox\",\n \"firebrick\",\n \"fire_control_radar\",\n \"fire_control_system\",\n \"fire_engine, fire_truck\",\n \"fire_extinguisher, extinguisher, asphyxiator\",\n \"fire_iron\",\n \"fireman's_ax, fireman's_axe\",\n \"fireplace, hearth, open_fireplace\",\n \"fire_screen, fireguard\",\n \"fire_tongs, coal_tongs\",\n \"fire_tower\",\n \"firewall\",\n \"firing_chamber, gun_chamber\",\n \"firing_pin\",\n \"firkin\",\n \"firmer_chisel\",\n \"first-aid_kit\",\n \"first-aid_station\",\n \"first_base\",\n \"first_class\",\n \"fishbowl, fish_bowl, goldfish_bowl\",\n \"fisherman's_bend\",\n \"fisherman's_knot, true_lover's_knot, truelove_knot\",\n \"fisherman's_lure, fish_lure\",\n \"fishhook\",\n \"fishing_boat, fishing_smack, fishing_vessel\",\n \"fishing_gear, tackle, fishing_tackle, fishing_rig, rig\",\n \"fishing_rod, fishing_pole\",\n \"fish_joint\",\n \"fish_knife\",\n \"fishnet, fishing_net\",\n \"fish_slice\",\n \"fitment\",\n \"fixative\",\n \"fixer-upper\",\n \"flag\",\n \"flageolet, treble_recorder, shepherd's_pipe\",\n \"flagon\",\n \"flagpole, flagstaff\",\n \"flagship\",\n \"flail\",\n \"flambeau\",\n \"flamethrower\",\n \"flange, rim\",\n \"flannel\",\n \"flannel, gabardine, tweed, white\",\n \"flannelette\",\n \"flap, flaps\",\n \"flash, photoflash, flash_lamp, flashgun, flashbulb, flash_bulb\",\n \"flash\",\n \"flash_camera\",\n \"flasher\",\n \"flashlight, torch\",\n \"flashlight_battery\",\n \"flash_memory\",\n \"flask\",\n \"flat_arch, straight_arch\",\n \"flatbed\",\n \"flatbed_press, cylinder_press\",\n \"flat_bench\",\n \"flatcar, flatbed, flat\",\n \"flat_file\",\n \"flatlet\",\n \"flat_panel_display, fpd\",\n \"flats\",\n \"flat_tip_screwdriver\",\n \"fleece\",\n \"fleet_ballistic_missile_submarine\",\n \"fleur-de-lis, fleur-de-lys\",\n \"flight_simulator, trainer\",\n \"flintlock\",\n \"flintlock, firelock\",\n \"flip-flop, thong\",\n \"flipper, fin\",\n \"float, plasterer's_float\",\n \"floating_dock, floating_dry_dock\",\n \"floatplane, pontoon_plane\",\n \"flood, floodlight, flood_lamp, photoflood\",\n \"floor, flooring\",\n \"floor, level, storey, story\",\n \"floor\",\n \"floorboard\",\n \"floor_cover, floor_covering\",\n \"floor_joist\",\n \"floor_lamp\",\n \"flophouse, dosshouse\",\n \"florist, florist_shop, flower_store\",\n \"floss\",\n \"flotsam, jetsam\",\n \"flour_bin\",\n \"flour_mill\",\n \"flowerbed, flower_bed, bed_of_flowers\",\n \"flugelhorn, fluegelhorn\",\n \"fluid_drive\",\n \"fluid_flywheel\",\n \"flume\",\n \"fluorescent_lamp\",\n \"fluoroscope, roentgenoscope\",\n \"flush_toilet, lavatory\",\n \"flute, transverse_flute\",\n \"flute, flute_glass, champagne_flute\",\n \"flux_applicator\",\n \"fluxmeter\",\n \"fly\",\n \"flying_boat\",\n \"flying_buttress, arc-boutant\",\n \"flying_carpet\",\n \"flying_jib\",\n \"fly_rod\",\n \"fly_tent\",\n \"flytrap\",\n \"flywheel\",\n \"fob, watch_chain, watch_guard\",\n \"foghorn\",\n \"foglamp\",\n \"foil\",\n \"fold, sheepfold, sheep_pen, sheepcote\",\n \"folder\",\n \"folding_chair\",\n \"folding_door, accordion_door\",\n \"folding_saw\",\n \"food_court\",\n \"food_processor\",\n \"food_hamper\",\n \"foot\",\n \"footage\",\n \"football\",\n \"football_helmet\",\n \"football_stadium\",\n \"footbath\",\n \"foot_brake\",\n \"footbridge, overcrossing, pedestrian_bridge\",\n \"foothold, footing\",\n \"footlocker, locker\",\n \"foot_rule\",\n \"footstool, footrest, ottoman, tuffet\",\n \"footwear, footgear\",\n \"footwear\",\n \"forceps\",\n \"force_pump\",\n \"fore-and-after\",\n \"fore-and-aft_sail\",\n \"forecastle, fo'c'sle\",\n \"forecourt\",\n \"foredeck\",\n \"fore_edge, foredge\",\n \"foreground\",\n \"foremast\",\n \"fore_plane\",\n \"foresail\",\n \"forestay\",\n \"foretop\",\n \"fore-topmast\",\n \"fore-topsail\",\n \"forge\",\n \"fork\",\n \"forklift\",\n \"formalwear, eveningwear, evening_dress, evening_clothes\",\n \"formica\",\n \"fortification, munition\",\n \"fortress, fort\",\n \"forty-five\",\n \"foucault_pendulum\",\n \"foulard\",\n \"foul-weather_gear\",\n \"foundation_garment, foundation\",\n \"foundry, metalworks\",\n \"fountain\",\n \"fountain_pen\",\n \"four-in-hand\",\n \"four-poster\",\n \"four-pounder\",\n \"four-stroke_engine, four-stroke_internal-combustion_engine\",\n \"four-wheel_drive, 4wd\",\n \"four-wheel_drive, 4wd\",\n \"four-wheeler\",\n \"fowling_piece\",\n \"foxhole, fox_hole\",\n \"fragmentation_bomb, antipersonnel_bomb, anti-personnel_bomb, daisy_cutter\",\n \"frail\",\n \"fraise\",\n \"frame, framing\",\n \"frame\",\n \"frame_buffer\",\n \"framework\",\n \"francis_turbine\",\n \"franking_machine\",\n \"free_house\",\n \"free-reed\",\n \"free-reed_instrument\",\n \"freewheel\",\n \"freight_car\",\n \"freight_elevator, service_elevator\",\n \"freight_liner, liner_train\",\n \"freight_train, rattler\",\n \"french_door\",\n \"french_horn, horn\",\n \"french_polish, french_polish_shellac\",\n \"french_roof\",\n \"french_window\",\n \"fresnel_lens\",\n \"fret\",\n \"friary\",\n \"friction_clutch\",\n \"frieze\",\n \"frieze\",\n \"frigate\",\n \"frigate\",\n \"frill, flounce, ruffle, furbelow\",\n \"frisbee\",\n \"frock\",\n \"frock_coat\",\n \"frontlet, frontal\",\n \"front_porch\",\n \"front_projector\",\n \"fruit_machine\",\n \"frying_pan, frypan, skillet\",\n \"fuel_filter\",\n \"fuel_gauge, fuel_indicator\",\n \"fuel_injection, fuel_injection_system\",\n \"fuel_system\",\n \"full-dress_uniform\",\n \"full_metal_jacket\",\n \"full_skirt\",\n \"fumigator\",\n \"funeral_home, funeral_parlor, funeral_parlour, funeral_chapel, funeral_church, funeral-residence\",\n \"funnel\",\n \"funny_wagon\",\n \"fur\",\n \"fur_coat\",\n \"fur_hat\",\n \"furnace\",\n \"furnace_lining, refractory\",\n \"furnace_room\",\n \"furnishing\",\n \"furnishing, trappings\",\n \"furniture, piece_of_furniture, article_of_furniture\",\n \"fur-piece\",\n \"furrow\",\n \"fuse, electrical_fuse, safety_fuse\",\n \"fusee_drive, fusee\",\n \"fuselage\",\n \"fusil\",\n \"fustian\",\n \"futon\",\n \"gabardine\",\n \"gable, gable_end, gable_wall\",\n \"gable_roof, saddle_roof, saddleback, saddleback_roof\",\n \"gadgetry\",\n \"gaff\",\n \"gaff\",\n \"gaff\",\n \"gaffsail, gaff-headed_sail\",\n \"gaff_topsail, fore-and-aft_topsail\",\n \"gag, muzzle\",\n \"gaiter\",\n \"gaiter\",\n \"galilean_telescope\",\n \"galleon\",\n \"gallery\",\n \"gallery, art_gallery, picture_gallery\",\n \"galley, ship's_galley, caboose, cookhouse\",\n \"galley\",\n \"galley\",\n \"gallows\",\n \"gallows_tree, gallows-tree, gibbet, gallous\",\n \"galvanometer\",\n \"gambling_house, gambling_den, gambling_hell, gaming_house\",\n \"gambrel, gambrel_roof\",\n \"game\",\n \"gamebag\",\n \"game_equipment\",\n \"gaming_table\",\n \"gamp, brolly\",\n \"gangplank, gangboard, gangway\",\n \"gangsaw\",\n \"gangway\",\n \"gantlet\",\n \"gantry, gauntry\",\n \"garage\",\n \"garage, service_department\",\n \"garand_rifle, garand, m-1, m-1_rifle\",\n \"garbage\",\n \"garbage_truck, dustcart\",\n \"garboard, garboard_plank, garboard_strake\",\n \"garden\",\n \"garden\",\n \"garden_rake\",\n \"garden_spade\",\n \"garden_tool, lawn_tool\",\n \"garden_trowel\",\n \"gargoyle\",\n \"garibaldi\",\n \"garlic_press\",\n \"garment\",\n \"garment_bag\",\n \"garrison_cap, overseas_cap\",\n \"garrote, garotte, garrotte, iron_collar\",\n \"garter, supporter\",\n \"garter_belt, suspender_belt\",\n \"garter_stitch\",\n \"gas_guzzler\",\n \"gas_shell\",\n \"gas_bracket\",\n \"gas_burner, gas_jet\",\n \"gas-cooled_reactor\",\n \"gas-discharge_tube\",\n \"gas_engine\",\n \"gas_fixture\",\n \"gas_furnace\",\n \"gas_gun\",\n \"gas_heater\",\n \"gas_holder, gasometer\",\n \"gasket\",\n \"gas_lamp\",\n \"gas_maser\",\n \"gasmask, respirator, gas_helmet\",\n \"gas_meter, gasometer\",\n \"gasoline_engine, petrol_engine\",\n \"gasoline_gauge, gasoline_gage, gas_gauge, gas_gage, petrol_gauge, petrol_gage\",\n \"gas_oven\",\n \"gas_oven\",\n \"gas_pump, gasoline_pump, petrol_pump, island_dispenser\",\n \"gas_range, gas_stove, gas_cooker\",\n \"gas_ring\",\n \"gas_tank, gasoline_tank, petrol_tank\",\n \"gas_thermometer, air_thermometer\",\n \"gastroscope\",\n \"gas_turbine\",\n \"gas-turbine_ship\",\n \"gat, rod\",\n \"gate\",\n \"gatehouse\",\n \"gateleg_table\",\n \"gatepost\",\n \"gathered_skirt\",\n \"gatling_gun\",\n \"gauge, gage\",\n \"gauntlet, gantlet\",\n \"gauntlet, gantlet, metal_glove\",\n \"gauze, netting, veiling\",\n \"gauze, gauze_bandage\",\n \"gavel\",\n \"gazebo, summerhouse\",\n \"gear, gear_wheel, geared_wheel, cogwheel\",\n \"gear, paraphernalia, appurtenance\",\n \"gear, gear_mechanism\",\n \"gearbox, gear_box, gear_case\",\n \"gearing, gear, geartrain, power_train, train\",\n \"gearset\",\n \"gearshift, gearstick, shifter, gear_lever\",\n \"geiger_counter, geiger-muller_counter\",\n \"geiger_tube, geiger-muller_tube\",\n \"gene_chip, dna_chip\",\n \"general-purpose_bomb, gp_bomb\",\n \"generator\",\n \"generator\",\n \"generator\",\n \"geneva_gown\",\n \"geodesic_dome\",\n \"georgette\",\n \"gharry\",\n \"ghat\",\n \"ghetto_blaster, boom_box\",\n \"gift_shop, novelty_shop\",\n \"gift_wrapping\",\n \"gig\",\n \"gig\",\n \"gig\",\n \"gig\",\n \"gildhall\",\n \"gill_net\",\n \"gilt, gilding\",\n \"gimbal\",\n \"gingham\",\n \"girandole, girandola\",\n \"girder\",\n \"girdle, cincture, sash, waistband, waistcloth\",\n \"glass, drinking_glass\",\n \"glass\",\n \"glass_cutter\",\n \"glasses_case\",\n \"glebe_house\",\n \"glengarry\",\n \"glider, sailplane\",\n \"global_positioning_system, gps\",\n \"glockenspiel, orchestral_bells\",\n \"glory_hole, lazaretto\",\n \"glove\",\n \"glove_compartment\",\n \"glow_lamp\",\n \"glow_tube\",\n \"glyptic_art, glyptography\",\n \"glyptics, lithoglyptics\",\n \"gnomon\",\n \"goal\",\n \"goalmouth\",\n \"goalpost\",\n \"goblet\",\n \"godown\",\n \"goggles\",\n \"go-kart\",\n \"gold_plate\",\n \"golf_bag\",\n \"golf_ball\",\n \"golfcart, golf_cart\",\n \"golf_club, golf-club, club\",\n \"golf-club_head, club_head, club-head, clubhead\",\n \"golf_equipment\",\n \"golf_glove\",\n \"golliwog, golliwogg\",\n \"gondola\",\n \"gong, tam-tam\",\n \"goniometer\",\n \"gordian_knot\",\n \"gorget\",\n \"gossamer\",\n \"gothic_arch\",\n \"gouache\",\n \"gouge\",\n \"gourd, calabash\",\n \"government_building\",\n \"government_office\",\n \"gown\",\n \"gown, robe\",\n \"gown, surgical_gown, scrubs\",\n \"grab\",\n \"grab_bag\",\n \"grab_bar\",\n \"grace_cup\",\n \"grade_separation\",\n \"graduated_cylinder\",\n \"graffito, graffiti\",\n \"gramophone, acoustic_gramophone\",\n \"granary, garner\",\n \"grandfather_clock, longcase_clock\",\n \"grand_piano, grand\",\n \"graniteware\",\n \"granny_knot, granny\",\n \"grape_arbor, grape_arbour\",\n \"grapnel, grapnel_anchor\",\n \"grapnel, grapple, grappler, grappling_hook, grappling_iron\",\n \"grass_skirt\",\n \"grate, grating\",\n \"grate, grating\",\n \"grater\",\n \"graver, graving_tool, pointel, pointrel\",\n \"gravestone, headstone, tombstone\",\n \"gravimeter, gravity_meter\",\n \"gravure, photogravure, heliogravure\",\n \"gravy_boat, gravy_holder, sauceboat, boat\",\n \"grey, gray\",\n \"grease-gun, gun\",\n \"greasepaint\",\n \"greasy_spoon\",\n \"greatcoat, overcoat, topcoat\",\n \"great_hall\",\n \"greave, jambeau\",\n \"greengrocery\",\n \"greenhouse, nursery, glasshouse\",\n \"grenade\",\n \"grid, gridiron\",\n \"griddle\",\n \"grill, grille, grillwork\",\n \"grille, radiator_grille\",\n \"grillroom, grill\",\n \"grinder\",\n \"grinding_wheel, emery_wheel\",\n \"grindstone\",\n \"gripsack\",\n \"gristmill\",\n \"grocery_bag\",\n \"grocery_store, grocery, food_market, market\",\n \"grogram\",\n \"groined_vault\",\n \"groover\",\n \"grosgrain\",\n \"gros_point\",\n \"ground, earth\",\n \"ground_bait\",\n \"ground_control\",\n \"ground_floor, first_floor, ground_level\",\n \"groundsheet, ground_cloth\",\n \"g-string, thong\",\n \"guard, safety, safety_device\",\n \"guard_boat\",\n \"guardroom\",\n \"guardroom\",\n \"guard_ship\",\n \"guard's_van\",\n \"gueridon\",\n \"guarnerius\",\n \"guesthouse\",\n \"guestroom\",\n \"guidance_system, guidance_device\",\n \"guided_missile\",\n \"guided_missile_cruiser\",\n \"guided_missile_frigate\",\n \"guildhall\",\n \"guilloche\",\n \"guillotine\",\n \"guimpe\",\n \"guimpe\",\n \"guitar\",\n \"guitar_pick\",\n \"gulag\",\n \"gun\",\n \"gunboat\",\n \"gun_carriage\",\n \"gun_case\",\n \"gun_emplacement, weapons_emplacement\",\n \"gun_enclosure, gun_turret, turret\",\n \"gunlock, firing_mechanism\",\n \"gunnery\",\n \"gunnysack, gunny_sack, burlap_bag\",\n \"gun_pendulum\",\n \"gun_room\",\n \"gunsight, gun-sight\",\n \"gun_trigger, trigger\",\n \"gurney\",\n \"gusher\",\n \"gusset, inset\",\n \"gusset, gusset_plate\",\n \"guy, guy_cable, guy_wire, guy_rope\",\n \"gymnastic_apparatus, exerciser\",\n \"gym_shoe, sneaker, tennis_shoe\",\n \"gym_suit\",\n \"gymslip\",\n \"gypsy_cab\",\n \"gyrocompass\",\n \"gyroscope, gyro\",\n \"gyrostabilizer, gyrostabiliser\",\n \"habergeon\",\n \"habit\",\n \"habit, riding_habit\",\n \"hacienda\",\n \"hacksaw, hack_saw, metal_saw\",\n \"haft, helve\",\n \"hairbrush\",\n \"haircloth, hair\",\n \"hairdressing, hair_tonic, hair_oil, hair_grease\",\n \"hairnet\",\n \"hairpiece, false_hair, postiche\",\n \"hairpin\",\n \"hair_shirt\",\n \"hair_slide\",\n \"hair_spray\",\n \"hairspring\",\n \"hair_trigger\",\n \"halberd\",\n \"half_binding\",\n \"half_hatchet\",\n \"half_hitch\",\n \"half_track\",\n \"hall\",\n \"hall\",\n \"hall\",\n \"hall_of_fame\",\n \"hall_of_residence\",\n \"hallstand\",\n \"halter\",\n \"halter, hackamore\",\n \"hame\",\n \"hammer\",\n \"hammer, power_hammer\",\n \"hammer\",\n \"hammerhead\",\n \"hammock, sack\",\n \"hamper\",\n \"hand\",\n \"handball\",\n \"handbarrow\",\n \"handbell\",\n \"hand_blower, blow_dryer, blow_drier, hair_dryer, hair_drier\",\n \"handbow\",\n \"hand_brake, emergency, emergency_brake, parking_brake\",\n \"hand_calculator, pocket_calculator\",\n \"handcar\",\n \"handcart, pushcart, cart, go-cart\",\n \"hand_cream\",\n \"handcuff, cuff, handlock, manacle\",\n \"hand_drill, handheld_drill\",\n \"hand_glass, simple_microscope, magnifying_glass\",\n \"hand_glass, hand_mirror\",\n \"hand_grenade\",\n \"hand-held_computer, hand-held_microcomputer\",\n \"handhold\",\n \"handkerchief, hankie, hanky, hankey\",\n \"handlebar\",\n \"handloom\",\n \"hand_lotion\",\n \"hand_luggage\",\n \"hand-me-down\",\n \"hand_mower\",\n \"hand_pump\",\n \"handrest\",\n \"handsaw, hand_saw, carpenter's_saw\",\n \"handset, french_telephone\",\n \"hand_shovel\",\n \"handspike\",\n \"handstamp, rubber_stamp\",\n \"hand_throttle\",\n \"hand_tool\",\n \"hand_towel, face_towel\",\n \"hand_truck, truck\",\n \"handwear, hand_wear\",\n \"handwheel\",\n \"handwheel\",\n \"hangar_queen\",\n \"hanger\",\n \"hang_glider\",\n \"hangman's_rope, hangman's_halter, halter, hemp, hempen_necktie\",\n \"hank\",\n \"hansom, hansom_cab\",\n \"harbor, harbour\",\n \"hard_disc, hard_disk, fixed_disk\",\n \"hard_hat, tin_hat, safety_hat\",\n \"hardtop\",\n \"hardware, ironware\",\n \"hardware_store, ironmonger, ironmonger's_shop\",\n \"harmonica, mouth_organ, harp, mouth_harp\",\n \"harmonium, organ, reed_organ\",\n \"harness\",\n \"harness\",\n \"harp\",\n \"harp\",\n \"harpoon\",\n \"harpoon_gun\",\n \"harpoon_log\",\n \"harpsichord, cembalo\",\n \"harris_tweed\",\n \"harrow\",\n \"harvester, reaper\",\n \"hash_house\",\n \"hasp\",\n \"hat, chapeau, lid\",\n \"hatbox\",\n \"hatch\",\n \"hatchback, hatchback_door\",\n \"hatchback\",\n \"hatchel, heckle\",\n \"hatchet\",\n \"hatpin\",\n \"hauberk, byrnie\",\n \"hawaiian_guitar, steel_guitar\",\n \"hawse, hawsehole, hawsepipe\",\n \"hawser\",\n \"hawser_bend\",\n \"hay_bale\",\n \"hayfork\",\n \"hayloft, haymow, mow\",\n \"haymaker, hay_conditioner\",\n \"hayrack, hayrig\",\n \"hayrack\",\n \"hazard\",\n \"head\",\n \"head\",\n \"head\",\n \"headboard\",\n \"head_covering, veil\",\n \"headdress, headgear\",\n \"header\",\n \"header\",\n \"header, coping, cope\",\n \"header, lintel\",\n \"headfast\",\n \"head_gasket\",\n \"head_gate\",\n \"headgear\",\n \"headlight, headlamp\",\n \"headpiece\",\n \"headpin, kingpin\",\n \"headquarters, central_office, main_office, home_office, home_base\",\n \"headrace\",\n \"headrest\",\n \"headsail\",\n \"headscarf\",\n \"headset\",\n \"head_shop\",\n \"headstall, headpiece\",\n \"headstock\",\n \"health_spa, spa, health_club\",\n \"hearing_aid, ear_trumpet\",\n \"hearing_aid, deaf-aid\",\n \"hearse\",\n \"hearth, fireside\",\n \"hearthrug\",\n \"heart-lung_machine\",\n \"heat_engine\",\n \"heater, warmer\",\n \"heat_exchanger\",\n \"heating_pad, hot_pad\",\n \"heat_lamp, infrared_lamp\",\n \"heat_pump\",\n \"heat-seeking_missile\",\n \"heat_shield\",\n \"heat_sink\",\n \"heaume\",\n \"heaver\",\n \"heavier-than-air_craft\",\n \"heckelphone, basset_oboe\",\n \"hectograph, heliotype\",\n \"hedge, hedgerow\",\n \"hedge_trimmer\",\n \"helicon, bombardon\",\n \"helicopter, chopper, whirlybird, eggbeater\",\n \"heliograph\",\n \"heliometer\",\n \"helm\",\n \"helmet\",\n \"helmet\",\n \"hematocrit, haematocrit\",\n \"hemming-stitch\",\n \"hemostat, haemostat\",\n \"hemstitch, hemstitching\",\n \"henroost\",\n \"heraldry\",\n \"hermitage\",\n \"herringbone\",\n \"herringbone, herringbone_pattern\",\n \"herschelian_telescope, off-axis_reflector\",\n \"hessian_boot, hessian, jackboot, wellington, wellington_boot\",\n \"heterodyne_receiver, superheterodyne_receiver, superhet\",\n \"hibachi\",\n \"hideaway, retreat\",\n \"hi-fi, high_fidelity_sound_system\",\n \"high_altar\",\n \"high-angle_gun\",\n \"highball_glass\",\n \"highboard\",\n \"highboy, tallboy\",\n \"highchair, feeding_chair\",\n \"high_gear, high\",\n \"high-hat_cymbal, high_hat\",\n \"highlighter\",\n \"highlighter\",\n \"high-pass_filter\",\n \"high-rise, tower_block\",\n \"high_table\",\n \"high-warp_loom\",\n \"hijab\",\n \"hinge, flexible_joint\",\n \"hinging_post, swinging_post\",\n \"hip_boot, thigh_boot\",\n \"hipflask, pocket_flask\",\n \"hip_pad\",\n \"hip_pocket\",\n \"hippodrome\",\n \"hip_roof, hipped_roof\",\n \"hitch\",\n \"hitch\",\n \"hitching_post\",\n \"hitchrack, hitching_bar\",\n \"hob\",\n \"hobble_skirt\",\n \"hockey_skate\",\n \"hockey_stick\",\n \"hod\",\n \"hodoscope\",\n \"hoe\",\n \"hoe_handle\",\n \"hogshead\",\n \"hoist\",\n \"hold, keep\",\n \"holder\",\n \"holding_cell\",\n \"holding_device\",\n \"holding_pen, holding_paddock, holding_yard\",\n \"hollowware, holloware\",\n \"holster\",\n \"holster\",\n \"holy_of_holies, sanctum_sanctorum\",\n \"home, nursing_home, rest_home\",\n \"home_appliance, household_appliance\",\n \"home_computer\",\n \"home_plate, home_base, home, plate\",\n \"home_room, homeroom\",\n \"homespun\",\n \"homestead\",\n \"home_theater, home_theatre\",\n \"homing_torpedo\",\n \"hone\",\n \"honeycomb\",\n \"hood, bonnet, cowl, cowling\",\n \"hood\",\n \"hood\",\n \"hood, exhaust_hood\",\n \"hood\",\n \"hood_latch\",\n \"hook\",\n \"hook, claw\",\n \"hook\",\n \"hookah, narghile, nargileh, sheesha, shisha, chicha, calean, kalian, water_pipe, hubble-bubble, hubbly-bubbly\",\n \"hook_and_eye\",\n \"hookup, assemblage\",\n \"hookup\",\n \"hook_wrench, hook_spanner\",\n \"hoopskirt, crinoline\",\n \"hoosegow, hoosgow\",\n \"hoover\",\n \"hope_chest, wedding_chest\",\n \"hopper\",\n \"hopsacking, hopsack\",\n \"horizontal_bar, high_bar\",\n \"horizontal_stabilizer, horizontal_stabiliser, tailplane\",\n \"horizontal_tail\",\n \"horn\",\n \"horn\",\n \"horn\",\n \"horn_button\",\n \"hornpipe, pibgorn, stockhorn\",\n \"horse, gymnastic_horse\",\n \"horsebox\",\n \"horsecar\",\n \"horse_cart, horse-cart\",\n \"horsecloth\",\n \"horse-drawn_vehicle\",\n \"horsehair\",\n \"horsehair_wig\",\n \"horseless_carriage\",\n \"horse_pistol, horse-pistol\",\n \"horseshoe, shoe\",\n \"horseshoe\",\n \"horse-trail\",\n \"horsewhip\",\n \"hose\",\n \"hosiery, hose\",\n \"hospice\",\n \"hospital, infirmary\",\n \"hospital_bed\",\n \"hospital_room\",\n \"hospital_ship\",\n \"hospital_train\",\n \"hostel, youth_hostel, student_lodging\",\n \"hostel, hostelry, inn, lodge, auberge\",\n \"hot-air_balloon\",\n \"hotel\",\n \"hotel-casino, casino-hotel\",\n \"hotel-casino, casino-hotel\",\n \"hotel_room\",\n \"hot_line\",\n \"hot_pants\",\n \"hot_plate, hotplate\",\n \"hot_rod, hot-rod\",\n \"hot_spot, hotspot\",\n \"hot_tub\",\n \"hot-water_bottle, hot-water_bag\",\n \"houndstooth_check, hound's-tooth_check, dogstooth_check, dogs-tooth_check, dog's-tooth_check\",\n \"hourglass\",\n \"hour_hand, little_hand\",\n \"house\",\n \"house\",\n \"houseboat\",\n \"houselights\",\n \"house_of_cards, cardhouse, card-house, cardcastle\",\n \"house_of_correction\",\n \"house_paint, housepaint\",\n \"housetop\",\n \"housing, lodging, living_accommodations\",\n \"hovel, hut, hutch, shack, shanty\",\n \"hovercraft, ground-effect_machine\",\n \"howdah, houdah\",\n \"huarache, huaraches\",\n \"hub-and-spoke, hub-and-spoke_system\",\n \"hubcap\",\n \"huck, huckaback\",\n \"hug-me-tight\",\n \"hula-hoop\",\n \"hulk\",\n \"hull\",\n \"humeral_veil, veil\",\n \"humvee, hum-vee\",\n \"hunter, hunting_watch\",\n \"hunting_knife\",\n \"hurdle\",\n \"hurricane_deck, hurricane_roof, promenade_deck, awning_deck\",\n \"hurricane_lamp, hurricane_lantern, tornado_lantern, storm_lantern, storm_lamp\",\n \"hut, army_hut, field_hut\",\n \"hutch\",\n \"hutment\",\n \"hydraulic_brake, hydraulic_brakes\",\n \"hydraulic_press\",\n \"hydraulic_pump, hydraulic_ram\",\n \"hydraulic_system\",\n \"hydraulic_transmission, hydraulic_transmission_system\",\n \"hydroelectric_turbine\",\n \"hydrofoil, hydroplane\",\n \"hydrofoil, foil\",\n \"hydrogen_bomb, h-bomb, fusion_bomb, thermonuclear_bomb\",\n \"hydrometer, gravimeter\",\n \"hygrodeik\",\n \"hygrometer\",\n \"hygroscope\",\n \"hyperbaric_chamber\",\n \"hypercoaster\",\n \"hypermarket\",\n \"hypodermic_needle\",\n \"hypodermic_syringe, hypodermic, hypo\",\n \"hypsometer\",\n \"hysterosalpingogram\",\n \"i-beam\",\n \"ice_ax, ice_axe, piolet\",\n \"iceboat, ice_yacht, scooter\",\n \"icebreaker, iceboat\",\n \"iced-tea_spoon\",\n \"ice_hockey_rink, ice-hockey_rink\",\n \"ice_machine\",\n \"ice_maker\",\n \"ice_pack, ice_bag\",\n \"icepick, ice_pick\",\n \"ice_rink, ice-skating_rink, ice\",\n \"ice_skate\",\n \"ice_tongs\",\n \"icetray\",\n \"iconoscope\",\n \"identikit, identikit_picture\",\n \"idle_pulley, idler_pulley, idle_wheel\",\n \"igloo, iglu\",\n \"ignition_coil\",\n \"ignition_key\",\n \"ignition_switch\",\n \"imaret\",\n \"immovable_bandage\",\n \"impact_printer\",\n \"impeller\",\n \"implant\",\n \"implement\",\n \"impression\",\n \"imprint\",\n \"improvised_explosive_device, i.e.d., ied\",\n \"impulse_turbine\",\n \"in-basket, in-tray\",\n \"incendiary_bomb, incendiary, firebomb\",\n \"incinerator\",\n \"inclined_plane\",\n \"inclinometer, dip_circle\",\n \"inclinometer\",\n \"incrustation, encrustation\",\n \"incubator, brooder\",\n \"index_register\",\n \"indiaman\",\n \"indian_club\",\n \"indicator\",\n \"induction_coil\",\n \"inductor, inductance\",\n \"industrial_watercourse\",\n \"inertial_guidance_system, inertial_navigation_system\",\n \"inflater, inflator\",\n \"inhaler, inhalator\",\n \"injector\",\n \"ink_bottle, inkpot\",\n \"ink_eraser\",\n \"ink-jet_printer\",\n \"inkle\",\n \"inkstand\",\n \"inkwell, inkstand\",\n \"inlay\",\n \"inside_caliper\",\n \"insole, innersole\",\n \"instep\",\n \"instillator\",\n \"institution\",\n \"instrument\",\n \"instrument_of_punishment\",\n \"instrument_of_torture\",\n \"intaglio, diaglyph\",\n \"intake_valve\",\n \"integrated_circuit, microcircuit\",\n \"integrator, planimeter\",\n \"intelnet\",\n \"interceptor\",\n \"interchange\",\n \"intercommunication_system, intercom\",\n \"intercontinental_ballistic_missile, icbm\",\n \"interface, port\",\n \"interferometer\",\n \"interior_door\",\n \"internal-combustion_engine, ice\",\n \"internal_drive\",\n \"internet, net, cyberspace\",\n \"interphone\",\n \"interrupter\",\n \"intersection, crossroad, crossway, crossing, carrefour\",\n \"interstice\",\n \"intraocular_lens\",\n \"intravenous_pyelogram, ivp\",\n \"inverter\",\n \"ion_engine\",\n \"ionization_chamber, ionization_tube\",\n \"ipod\",\n \"video_ipod\",\n \"iron, smoothing_iron\",\n \"iron\",\n \"iron, branding_iron\",\n \"irons, chains\",\n \"ironclad\",\n \"iron_foundry\",\n \"iron_horse\",\n \"ironing\",\n \"iron_lung\",\n \"ironmongery\",\n \"ironworks\",\n \"irrigation_ditch\",\n \"izar\",\n \"jabot\",\n \"jack\",\n \"jack, jackstones\",\n \"jack\",\n \"jack\",\n \"jacket\",\n \"jacket\",\n \"jacket\",\n \"jack-in-the-box\",\n \"jack-o'-lantern\",\n \"jack_plane\",\n \"jacob's_ladder, jack_ladder, pilot_ladder\",\n \"jaconet\",\n \"jacquard_loom, jacquard\",\n \"jacquard\",\n \"jag, dag\",\n \"jail, jailhouse, gaol, clink, slammer, poky, pokey\",\n \"jalousie\",\n \"jamb\",\n \"jammer\",\n \"jampot, jamjar\",\n \"japan\",\n \"jar\",\n \"jarvik_heart, jarvik_artificial_heart\",\n \"jaunting_car, jaunty_car\",\n \"javelin\",\n \"jaw\",\n \"jaws_of_life\",\n \"jean, blue_jean, denim\",\n \"jeep, landrover\",\n \"jellaba\",\n \"jerkin\",\n \"jeroboam, double-magnum\",\n \"jersey\",\n \"jersey, t-shirt, tee_shirt\",\n \"jet, jet_plane, jet-propelled_plane\",\n \"jet_bridge\",\n \"jet_engine\",\n \"jetliner\",\n \"jeweler's_glass\",\n \"jewelled_headdress, jeweled_headdress\",\n \"jew's_harp, jews'_harp, mouth_bow\",\n \"jib\",\n \"jibboom\",\n \"jig\",\n \"jig\",\n \"jiggermast, jigger\",\n \"jigsaw, scroll_saw, fretsaw\",\n \"jigsaw_puzzle\",\n \"jinrikisha, ricksha, rickshaw\",\n \"jobcentre\",\n \"jodhpurs, jodhpur_breeches, riding_breeches\",\n \"jodhpur, jodhpur_boot, jodhpur_shoe\",\n \"joinery\",\n \"joint\",\n \"joint_direct_attack_munition, jdam\",\n \"jointer, jointer_plane, jointing_plane, long_plane\",\n \"joist\",\n \"jolly_boat, jolly\",\n \"jorum\",\n \"joss_house\",\n \"journal_bearing\",\n \"journal_box\",\n \"joystick\",\n \"jungle_gym\",\n \"junk\",\n \"jug\",\n \"jukebox, nickelodeon\",\n \"jumbojet, jumbo_jet\",\n \"jumper, pinafore, pinny\",\n \"jumper\",\n \"jumper\",\n \"jumper\",\n \"jumper_cable, jumper_lead, lead, booster_cable\",\n \"jump_seat\",\n \"jump_suit\",\n \"jump_suit, jumpsuit\",\n \"junction\",\n \"junction, conjunction\",\n \"junction_barrier, barrier_strip\",\n \"junk_shop\",\n \"jury_box\",\n \"jury_mast\",\n \"kachina\",\n \"kaffiyeh\",\n \"kalansuwa\",\n \"kalashnikov\",\n \"kameez\",\n \"kanzu\",\n \"katharometer\",\n \"kayak\",\n \"kazoo\",\n \"keel\",\n \"keelboat\",\n \"keelson\",\n \"keep, donjon, dungeon\",\n \"keg\",\n \"kennel, doghouse, dog_house\",\n \"kepi, peaked_cap, service_cap, yachting_cap\",\n \"keratoscope\",\n \"kerchief\",\n \"ketch\",\n \"kettle, boiler\",\n \"kettle, kettledrum, tympanum, tympani, timpani\",\n \"key\",\n \"key\",\n \"keyboard\",\n \"keyboard_buffer\",\n \"keyboard_instrument\",\n \"keyhole\",\n \"keyhole_saw\",\n \"khadi, khaddar\",\n \"khaki\",\n \"khakis\",\n \"khimar\",\n \"khukuri\",\n \"kick_pleat\",\n \"kicksorter, pulse_height_analyzer\",\n \"kickstand\",\n \"kick_starter, kick_start\",\n \"kid_glove, suede_glove\",\n \"kiln\",\n \"kilt\",\n \"kimono\",\n \"kinescope, picture_tube, television_tube\",\n \"kinetoscope\",\n \"king\",\n \"king\",\n \"kingbolt, kingpin, swivel_pin\",\n \"king_post\",\n \"kipp's_apparatus\",\n \"kirk\",\n \"kirpan\",\n \"kirtle\",\n \"kirtle\",\n \"kit, outfit\",\n \"kit\",\n \"kitbag, kit_bag\",\n \"kitchen\",\n \"kitchen_appliance\",\n \"kitchenette\",\n \"kitchen_table\",\n \"kitchen_utensil\",\n \"kitchenware\",\n \"kite_balloon\",\n \"klaxon, claxon\",\n \"klieg_light\",\n \"klystron\",\n \"knee_brace\",\n \"knee-high, knee-hi\",\n \"knee_pad\",\n \"knee_piece\",\n \"knife\",\n \"knife\",\n \"knife_blade\",\n \"knight, horse\",\n \"knit\",\n \"knitting_machine\",\n \"knitting_needle\",\n \"knitwear\",\n \"knob, boss\",\n \"knob, pommel\",\n \"knobble\",\n \"knobkerrie, knobkerry\",\n \"knocker, doorknocker, rapper\",\n \"knot\",\n \"knuckle_joint, hinge_joint\",\n \"kohl\",\n \"koto\",\n \"kraal\",\n \"kremlin\",\n \"kris, creese, crease\",\n \"krummhorn, crumhorn, cromorne\",\n \"kundt's_tube\",\n \"kurdistan\",\n \"kurta\",\n \"kylix, cylix\",\n \"kymograph, cymograph\",\n \"lab_bench, laboratory_bench\",\n \"lab_coat, laboratory_coat\",\n \"lace\",\n \"lacquer\",\n \"lacquerware\",\n \"lacrosse_ball\",\n \"ladder-back\",\n \"ladder-back, ladder-back_chair\",\n \"ladder_truck, aerial_ladder_truck\",\n \"ladies'_room, powder_room\",\n \"ladle\",\n \"lady_chapel\",\n \"lagerphone\",\n \"lag_screw, lag_bolt\",\n \"lake_dwelling, pile_dwelling\",\n \"lally, lally_column\",\n \"lamasery\",\n \"lambrequin\",\n \"lame\",\n \"laminar_flow_clean_room\",\n \"laminate\",\n \"lamination\",\n \"lamp\",\n \"lamp\",\n \"lamp_house, lamphouse, lamp_housing\",\n \"lamppost\",\n \"lampshade, lamp_shade\",\n \"lanai\",\n \"lancet_arch, lancet\",\n \"lancet_window\",\n \"landau\",\n \"lander\",\n \"landing_craft\",\n \"landing_flap\",\n \"landing_gear\",\n \"landing_net\",\n \"landing_skid\",\n \"land_line, landline\",\n \"land_mine, ground-emplaced_mine, booby_trap\",\n \"land_office\",\n \"lanolin\",\n \"lantern\",\n \"lanyard, laniard\",\n \"lap, lap_covering\",\n \"laparoscope\",\n \"lapboard\",\n \"lapel\",\n \"lap_joint, splice\",\n \"laptop, laptop_computer\",\n \"laryngoscope\",\n \"laser, optical_maser\",\n \"laser-guided_bomb, lgb\",\n \"laser_printer\",\n \"lash, thong\",\n \"lashing\",\n \"lasso, lariat, riata, reata\",\n \"latch\",\n \"latch, door_latch\",\n \"latchet\",\n \"latchkey\",\n \"lateen, lateen_sail\",\n \"latex_paint, latex, rubber-base_paint\",\n \"lath\",\n \"lathe\",\n \"latrine\",\n \"lattice, latticework, fretwork\",\n \"launch\",\n \"launcher, rocket_launcher\",\n \"laundry, wash, washing, washables\",\n \"laundry_cart\",\n \"laundry_truck\",\n \"lavalava\",\n \"lavaliere, lavalier, lavalliere\",\n \"laver\",\n \"lawn_chair, garden_chair\",\n \"lawn_furniture\",\n \"lawn_mower, mower\",\n \"layette\",\n \"lead-acid_battery, lead-acid_accumulator\",\n \"lead-in\",\n \"leading_rein\",\n \"lead_pencil\",\n \"leaf_spring\",\n \"lean-to\",\n \"lean-to_tent\",\n \"leash, tether, lead\",\n \"leatherette, imitation_leather\",\n \"leather_strip\",\n \"leclanche_cell\",\n \"lectern, reading_desk\",\n \"lecture_room\",\n \"lederhosen\",\n \"ledger_board\",\n \"leg\",\n \"leg\",\n \"legging, leging, leg_covering\",\n \"leiden_jar, leyden_jar\",\n \"leisure_wear\",\n \"lens, lense, lens_system\",\n \"lens, electron_lens\",\n \"lens_cap, lens_cover\",\n \"lens_implant, interocular_lens_implant, iol\",\n \"leotard, unitard, body_suit, cat_suit\",\n \"letter_case\",\n \"letter_opener, paper_knife, paperknife\",\n \"levee\",\n \"level, spirit_level\",\n \"lever\",\n \"lever, lever_tumbler\",\n \"lever\",\n \"lever_lock\",\n \"levi's, levis\",\n \"liberty_ship\",\n \"library\",\n \"library\",\n \"lid\",\n \"liebig_condenser\",\n \"lie_detector\",\n \"lifeboat\",\n \"life_buoy, lifesaver, life_belt, life_ring\",\n \"life_jacket, life_vest, cork_jacket\",\n \"life_office\",\n \"life_preserver, preserver, flotation_device\",\n \"life-support_system, life_support\",\n \"life-support_system, life_support\",\n \"lifting_device\",\n \"lift_pump\",\n \"ligament\",\n \"ligature\",\n \"light, light_source\",\n \"light_arm\",\n \"light_bulb, lightbulb, bulb, incandescent_lamp, electric_light, electric-light_bulb\",\n \"light_circuit, lighting_circuit\",\n \"light-emitting_diode, led\",\n \"lighter, light, igniter, ignitor\",\n \"lighter-than-air_craft\",\n \"light_filter, diffusing_screen\",\n \"lighting\",\n \"light_machine_gun\",\n \"light_meter, exposure_meter, photometer\",\n \"light_microscope\",\n \"lightning_rod, lightning_conductor\",\n \"light_pen, electronic_stylus\",\n \"lightship\",\n \"lilo\",\n \"limber\",\n \"limekiln\",\n \"limiter, clipper\",\n \"limousine, limo\",\n \"linear_accelerator, linac\",\n \"linen\",\n \"line_printer, line-at-a-time_printer\",\n \"liner, ocean_liner\",\n \"liner, lining\",\n \"lingerie, intimate_apparel\",\n \"lining, liner\",\n \"link, data_link\",\n \"linkage\",\n \"link_trainer\",\n \"linocut\",\n \"linoleum_knife, linoleum_cutter\",\n \"linotype, linotype_machine\",\n \"linsey-woolsey\",\n \"linstock\",\n \"lion-jaw_forceps\",\n \"lip-gloss\",\n \"lipstick, lip_rouge\",\n \"liqueur_glass\",\n \"liquid_crystal_display, lcd\",\n \"liquid_metal_reactor\",\n \"lisle\",\n \"lister, lister_plow, lister_plough, middlebreaker, middle_buster\",\n \"litterbin, litter_basket, litter-basket\",\n \"little_theater, little_theatre\",\n \"live_axle, driving_axle\",\n \"living_quarters, quarters\",\n \"living_room, living-room, sitting_room, front_room, parlor, parlour\",\n \"load\",\n \"loafer\",\n \"loaner\",\n \"lobe\",\n \"lobster_pot\",\n \"local\",\n \"local_area_network, lan\",\n \"local_oscillator, heterodyne_oscillator\",\n \"lochaber_ax\",\n \"lock\",\n \"lock, ignition_lock\",\n \"lock, lock_chamber\",\n \"lock\",\n \"lockage\",\n \"locker\",\n \"locker_room\",\n \"locket\",\n \"lock-gate\",\n \"locking_pliers\",\n \"lockring, lock_ring, lock_washer\",\n \"lockstitch\",\n \"lockup\",\n \"locomotive, engine, locomotive_engine, railway_locomotive\",\n \"lodge, indian_lodge\",\n \"lodge, hunting_lodge\",\n \"lodge\",\n \"lodging_house, rooming_house\",\n \"loft, attic, garret\",\n \"loft, pigeon_loft\",\n \"loft\",\n \"log_cabin\",\n \"loggia\",\n \"longbow\",\n \"long_iron\",\n \"long_johns\",\n \"long_sleeve\",\n \"long_tom\",\n \"long_trousers, long_pants\",\n \"long_underwear, union_suit\",\n \"looking_glass, glass\",\n \"lookout, observation_tower, lookout_station, observatory\",\n \"loom\",\n \"loop_knot\",\n \"lorgnette\",\n \"lorraine_cross, cross_of_lorraine\",\n \"lorry, camion\",\n \"lota\",\n \"lotion\",\n \"loudspeaker, speaker, speaker_unit, loudspeaker_system, speaker_system\",\n \"lounge, waiting_room, waiting_area\",\n \"lounger\",\n \"lounging_jacket, smoking_jacket\",\n \"lounging_pajama, lounging_pyjama\",\n \"loungewear\",\n \"loupe, jeweler's_loupe\",\n \"louvered_window, jalousie\",\n \"love_knot, lovers'_knot, lover's_knot, true_lovers'_knot, true_lover's_knot\",\n \"love_seat, loveseat, tete-a-tete, vis-a-vis\",\n \"loving_cup\",\n \"lowboy\",\n \"low-pass_filter\",\n \"low-warp-loom\",\n \"lp, l-p\",\n \"l-plate\",\n \"lubber's_hole\",\n \"lubricating_system, force-feed_lubricating_system, force_feed, pressure-feed_lubricating_system, pressure_feed\",\n \"luff\",\n \"lug\",\n \"luge\",\n \"luger\",\n \"luggage_carrier\",\n \"luggage_compartment, automobile_trunk, trunk\",\n \"luggage_rack, roof_rack\",\n \"lugger\",\n \"lugsail, lug\",\n \"lug_wrench\",\n \"lumberjack, lumber_jacket\",\n \"lumbermill, sawmill\",\n \"lunar_excursion_module, lunar_module, lem\",\n \"lunchroom\",\n \"lunette\",\n \"lungi, lungyi, longyi\",\n \"lunula\",\n \"lusterware\",\n \"lute\",\n \"luxury_liner, express_luxury_liner\",\n \"lyceum\",\n \"lychgate, lichgate\",\n \"lyre\",\n \"machete, matchet, panga\",\n \"machicolation\",\n \"machine\",\n \"machine, simple_machine\",\n \"machine_bolt\",\n \"machine_gun\",\n \"machinery\",\n \"machine_screw\",\n \"machine_tool\",\n \"machinist's_vise, metalworking_vise\",\n \"machmeter\",\n \"mackinaw\",\n \"mackinaw, mackinaw_boat\",\n \"mackinaw, mackinaw_coat\",\n \"mackintosh, macintosh\",\n \"macrame\",\n \"madras\",\n \"mae_west, air_jacket\",\n \"magazine_rack\",\n \"magic_lantern\",\n \"magnet\",\n \"magnetic_bottle\",\n \"magnetic_compass\",\n \"magnetic_core_memory, core_memory\",\n \"magnetic_disk, magnetic_disc, disk, disc\",\n \"magnetic_head\",\n \"magnetic_mine\",\n \"magnetic_needle\",\n \"magnetic_recorder\",\n \"magnetic_stripe\",\n \"magnetic_tape, mag_tape, tape\",\n \"magneto, magnetoelectric_machine\",\n \"magnetometer, gaussmeter\",\n \"magnetron\",\n \"magnifier\",\n \"magnum\",\n \"magnus_hitch\",\n \"mail\",\n \"mailbag, postbag\",\n \"mailbag, mail_pouch\",\n \"mailboat, mail_boat, packet, packet_boat\",\n \"mailbox, letter_box\",\n \"mail_car\",\n \"maildrop\",\n \"mailer\",\n \"maillot\",\n \"maillot, tank_suit\",\n \"mailsorter\",\n \"mail_train\",\n \"mainframe, mainframe_computer\",\n \"mainmast\",\n \"main_rotor\",\n \"mainsail\",\n \"mainspring\",\n \"main-topmast\",\n \"main-topsail\",\n \"main_yard\",\n \"maisonette, maisonnette\",\n \"majolica, maiolica\",\n \"makeup, make-up, war_paint\",\n \"maksutov_telescope\",\n \"malacca, malacca_cane\",\n \"mallet, beetle\",\n \"mallet, hammer\",\n \"mallet\",\n \"mammogram\",\n \"mandola\",\n \"mandolin\",\n \"manger, trough\",\n \"mangle\",\n \"manhole\",\n \"manhole_cover\",\n \"man-of-war, ship_of_the_line\",\n \"manometer\",\n \"manor, manor_house\",\n \"manor_hall, hall\",\n \"manpad\",\n \"mansard, mansard_roof\",\n \"manse\",\n \"mansion, mansion_house, manse, hall, residence\",\n \"mantel, mantelpiece, mantle, mantlepiece, chimneypiece\",\n \"mantelet, mantilla\",\n \"mantilla\",\n \"mao_jacket\",\n \"map\",\n \"maquiladora\",\n \"maraca\",\n \"marble\",\n \"marching_order\",\n \"marimba, xylophone\",\n \"marina\",\n \"marker\",\n \"marketplace, market_place, mart, market\",\n \"marlinespike, marlinspike, marlingspike\",\n \"marocain, crepe_marocain\",\n \"marquee, marquise\",\n \"marquetry, marqueterie\",\n \"marriage_bed\",\n \"martello_tower\",\n \"martingale\",\n \"mascara\",\n \"maser\",\n \"masher\",\n \"mashie, five_iron\",\n \"mashie_niblick, seven_iron\",\n \"masjid, musjid\",\n \"mask\",\n \"mask\",\n \"masonite\",\n \"mason_jar\",\n \"masonry\",\n \"mason's_level\",\n \"massage_parlor\",\n \"massage_parlor\",\n \"mass_spectrograph\",\n \"mass_spectrometer, spectrometer\",\n \"mast\",\n \"mast\",\n \"mastaba, mastabah\",\n \"master_bedroom\",\n \"masterpiece, chef-d'oeuvre\",\n \"mat\",\n \"mat, gym_mat\",\n \"match, lucifer, friction_match\",\n \"match\",\n \"matchboard\",\n \"matchbook\",\n \"matchbox\",\n \"matchlock\",\n \"match_plane, tonguing_and_grooving_plane\",\n \"matchstick\",\n \"material\",\n \"materiel, equipage\",\n \"maternity_hospital\",\n \"maternity_ward\",\n \"matrix\",\n \"matthew_walker, matthew_walker_knot\",\n \"matting\",\n \"mattock\",\n \"mattress_cover\",\n \"maul, sledge, sledgehammer\",\n \"maulstick, mahlstick\",\n \"mauser\",\n \"mausoleum\",\n \"maxi\",\n \"maxim_gun\",\n \"maximum_and_minimum_thermometer\",\n \"maypole\",\n \"maze, labyrinth\",\n \"mazer\",\n \"means\",\n \"measure\",\n \"measuring_cup\",\n \"measuring_instrument, measuring_system, measuring_device\",\n \"measuring_stick, measure, measuring_rod\",\n \"meat_counter\",\n \"meat_grinder\",\n \"meat_hook\",\n \"meat_house\",\n \"meat_safe\",\n \"meat_thermometer\",\n \"mechanical_device\",\n \"mechanical_piano, pianola, player_piano\",\n \"mechanical_system\",\n \"mechanism\",\n \"medical_building, health_facility, healthcare_facility\",\n \"medical_instrument\",\n \"medicine_ball\",\n \"medicine_chest, medicine_cabinet\",\n \"medline\",\n \"megalith, megalithic_structure\",\n \"megaphone\",\n \"memorial, monument\",\n \"memory, computer_memory, storage, computer_storage, store, memory_board\",\n \"memory_chip\",\n \"memory_device, storage_device\",\n \"menagerie, zoo, zoological_garden\",\n \"mending\",\n \"menhir, standing_stone\",\n \"menorah\",\n \"menorah\",\n \"man's_clothing\",\n \"men's_room, men's\",\n \"mercantile_establishment, retail_store, sales_outlet, outlet\",\n \"mercury_barometer\",\n \"mercury_cell\",\n \"mercury_thermometer, mercury-in-glass_thermometer\",\n \"mercury-vapor_lamp\",\n \"mercy_seat\",\n \"merlon\",\n \"mess, mess_hall\",\n \"mess_jacket, monkey_jacket, shell_jacket\",\n \"mess_kit\",\n \"messuage\",\n \"metal_detector\",\n \"metallic\",\n \"metal_screw\",\n \"metal_wood\",\n \"meteorological_balloon\",\n \"meter\",\n \"meterstick, metrestick\",\n \"metronome\",\n \"mezzanine, mezzanine_floor, entresol\",\n \"mezzanine, first_balcony\",\n \"microbalance\",\n \"microbrewery\",\n \"microfiche\",\n \"microfilm\",\n \"micrometer, micrometer_gauge, micrometer_caliper\",\n \"microphone, mike\",\n \"microprocessor\",\n \"microscope\",\n \"microtome\",\n \"microwave, microwave_oven\",\n \"microwave_diathermy_machine\",\n \"microwave_linear_accelerator\",\n \"middy, middy_blouse\",\n \"midiron, two_iron\",\n \"mihrab\",\n \"mihrab\",\n \"military_hospital\",\n \"military_quarters\",\n \"military_uniform\",\n \"military_vehicle\",\n \"milk_bar\",\n \"milk_can\",\n \"milk_float\",\n \"milking_machine\",\n \"milking_stool\",\n \"milk_wagon, milkwagon\",\n \"mill, grinder, milling_machinery\",\n \"milldam\",\n \"miller, milling_machine\",\n \"milliammeter\",\n \"millinery, woman's_hat\",\n \"millinery, hat_shop\",\n \"milling\",\n \"millivoltmeter\",\n \"millstone\",\n \"millstone\",\n \"millwheel, mill_wheel\",\n \"mimeograph, mimeo, mimeograph_machine, roneo, roneograph\",\n \"minaret\",\n \"mincer, mincing_machine\",\n \"mine\",\n \"mine_detector\",\n \"minelayer\",\n \"mineshaft\",\n \"minibar, cellaret\",\n \"minibike, motorbike\",\n \"minibus\",\n \"minicar\",\n \"minicomputer\",\n \"ministry\",\n \"miniskirt, mini\",\n \"minisub, minisubmarine\",\n \"minivan\",\n \"miniver\",\n \"mink, mink_coat\",\n \"minster\",\n \"mint\",\n \"minute_hand, big_hand\",\n \"minuteman\",\n \"mirror\",\n \"missile\",\n \"missile_defense_system, missile_defence_system\",\n \"miter_box, mitre_box\",\n \"miter_joint, mitre_joint, miter, mitre\",\n \"mitten\",\n \"mixer\",\n \"mixer\",\n \"mixing_bowl\",\n \"mixing_faucet\",\n \"mizzen, mizen\",\n \"mizzenmast, mizenmast, mizzen, mizen\",\n \"mobcap\",\n \"mobile_home, manufactured_home\",\n \"moccasin, mocassin\",\n \"mock-up\",\n \"mod_con\",\n \"model_t\",\n \"modem\",\n \"modillion\",\n \"module\",\n \"module\",\n \"mohair\",\n \"moire, watered-silk\",\n \"mold, mould, cast\",\n \"moldboard, mouldboard\",\n \"moldboard_plow, mouldboard_plough\",\n \"moleskin\",\n \"molotov_cocktail, petrol_bomb, gasoline_bomb\",\n \"monastery\",\n \"monastic_habit\",\n \"moneybag\",\n \"money_belt\",\n \"monitor\",\n \"monitor\",\n \"monitor, monitoring_device\",\n \"monkey-wrench, monkey_wrench\",\n \"monk's_cloth\",\n \"monochrome\",\n \"monocle, eyeglass\",\n \"monofocal_lens_implant, monofocal_iol\",\n \"monoplane\",\n \"monotype\",\n \"monstrance, ostensorium\",\n \"mooring_tower, mooring_mast\",\n \"moorish_arch, horseshoe_arch\",\n \"moped\",\n \"mop_handle\",\n \"moquette\",\n \"morgue, mortuary, dead_room\",\n \"morion, cabasset\",\n \"morning_dress\",\n \"morning_dress\",\n \"morning_room\",\n \"morris_chair\",\n \"mortar, howitzer, trench_mortar\",\n \"mortar\",\n \"mortarboard\",\n \"mortise_joint, mortise-and-tenon_joint\",\n \"mosaic\",\n \"mosque\",\n \"mosquito_net\",\n \"motel\",\n \"motel_room\",\n \"mother_hubbard, muumuu\",\n \"motion-picture_camera, movie_camera, cine-camera\",\n \"motion-picture_film, movie_film, cine-film\",\n \"motley\",\n \"motley\",\n \"motor\",\n \"motorboat, powerboat\",\n \"motorcycle, bike\",\n \"motor_hotel, motor_inn, motor_lodge, tourist_court, court\",\n \"motorized_wheelchair\",\n \"motor_scooter, scooter\",\n \"motor_vehicle, automotive_vehicle\",\n \"mound, hill\",\n \"mound, hill, pitcher's_mound\",\n \"mount, setting\",\n \"mountain_bike, all-terrain_bike, off-roader\",\n \"mountain_tent\",\n \"mouse, computer_mouse\",\n \"mouse_button\",\n \"mousetrap\",\n \"mousse, hair_mousse, hair_gel\",\n \"mouthpiece, embouchure\",\n \"mouthpiece\",\n \"mouthpiece, gumshield\",\n \"movement\",\n \"movie_projector, cine_projector, film_projector\",\n \"moving-coil_galvanometer\",\n \"moving_van\",\n \"mud_brick\",\n \"mudguard, splash_guard, splash-guard\",\n \"mudhif\",\n \"muff\",\n \"muffle\",\n \"muffler\",\n \"mufti\",\n \"mug\",\n \"mulch\",\n \"mule, scuff\",\n \"multichannel_recorder\",\n \"multiengine_airplane, multiengine_plane\",\n \"multiplex\",\n \"multiplexer\",\n \"multiprocessor\",\n \"multistage_rocket, step_rocket\",\n \"munition, ordnance, ordnance_store\",\n \"murphy_bed\",\n \"musette, shepherd's_pipe\",\n \"musette_pipe\",\n \"museum\",\n \"mushroom_anchor\",\n \"musical_instrument, instrument\",\n \"music_box, musical_box\",\n \"music_hall, vaudeville_theater, vaudeville_theatre\",\n \"music_school\",\n \"music_stand, music_rack\",\n \"music_stool, piano_stool\",\n \"musket\",\n \"musket_ball, ball\",\n \"muslin\",\n \"mustache_cup, moustache_cup\",\n \"mustard_plaster, sinapism\",\n \"mute\",\n \"muzzle_loader\",\n \"muzzle\",\n \"myelogram\",\n \"nacelle\",\n \"nail\",\n \"nailbrush\",\n \"nailfile\",\n \"nailhead\",\n \"nailhead\",\n \"nail_polish, nail_enamel, nail_varnish\",\n \"nainsook\",\n \"napier's_bones, napier's_rods\",\n \"nard, spikenard\",\n \"narrowbody_aircraft, narrow-body_aircraft, narrow-body\",\n \"narrow_wale\",\n \"narthex\",\n \"narthex\",\n \"nasotracheal_tube\",\n \"national_monument\",\n \"nautilus, nuclear_submarine, nuclear-powered_submarine\",\n \"navigational_system\",\n \"naval_equipment\",\n \"naval_gun\",\n \"naval_missile\",\n \"naval_radar\",\n \"naval_tactical_data_system\",\n \"naval_weaponry\",\n \"nave\",\n \"navigational_instrument\",\n \"nebuchadnezzar\",\n \"neckband\",\n \"neck_brace\",\n \"neckcloth, stock\",\n \"neckerchief\",\n \"necklace\",\n \"necklet\",\n \"neckline\",\n \"neckpiece\",\n \"necktie, tie\",\n \"neckwear\",\n \"needle\",\n \"needle\",\n \"needlenose_pliers\",\n \"needlework, needlecraft\",\n \"negative\",\n \"negative_magnetic_pole, negative_pole, south-seeking_pole\",\n \"negative_pole\",\n \"negligee, neglige, peignoir, wrapper, housecoat\",\n \"neolith\",\n \"neon_lamp, neon_induction_lamp, neon_tube\",\n \"nephoscope\",\n \"nest\",\n \"nest_egg\",\n \"net, network, mesh, meshing, meshwork\",\n \"net\",\n \"net\",\n \"net\",\n \"network, electronic_network\",\n \"network\",\n \"neutron_bomb\",\n \"newel\",\n \"newel_post, newel\",\n \"newspaper, paper\",\n \"newsroom\",\n \"newsroom\",\n \"newsstand\",\n \"newtonian_telescope, newtonian_reflector\",\n \"nib, pen_nib\",\n \"niblick, nine_iron\",\n \"nicad, nickel-cadmium_accumulator\",\n \"nickel-iron_battery, nickel-iron_accumulator\",\n \"nicol_prism\",\n \"night_bell\",\n \"nightcap\",\n \"nightgown, gown, nightie, night-robe, nightdress\",\n \"night_latch\",\n \"night-light\",\n \"nightshirt\",\n \"nightwear, sleepwear, nightclothes\",\n \"ninepin, skittle, skittle_pin\",\n \"ninepin_ball, skittle_ball\",\n \"ninon\",\n \"nipple\",\n \"nipple_shield\",\n \"niqab\",\n \"nissen_hut, quonset_hut\",\n \"nogging\",\n \"noisemaker\",\n \"nonsmoker, nonsmoking_car\",\n \"non-volatile_storage, nonvolatile_storage\",\n \"norfolk_jacket\",\n \"noria\",\n \"nosebag, feedbag\",\n \"noseband, nosepiece\",\n \"nose_flute\",\n \"nosewheel\",\n \"notebook, notebook_computer\",\n \"nuclear-powered_ship\",\n \"nuclear_reactor, reactor\",\n \"nuclear_rocket\",\n \"nuclear_weapon, atomic_weapon\",\n \"nude, nude_painting\",\n \"numdah, numdah_rug, nammad\",\n \"nun's_habit\",\n \"nursery, baby's_room\",\n \"nut_and_bolt\",\n \"nutcracker\",\n \"nylon\",\n \"nylons, nylon_stocking, rayons, rayon_stocking, silk_stocking\",\n \"oar\",\n \"oast\",\n \"oast_house\",\n \"obelisk\",\n \"object_ball\",\n \"objective, objective_lens, object_lens, object_glass\",\n \"oblique_bandage\",\n \"oboe, hautboy, hautbois\",\n \"oboe_da_caccia\",\n \"oboe_d'amore\",\n \"observation_dome\",\n \"observatory\",\n \"obstacle\",\n \"obturator\",\n \"ocarina, sweet_potato\",\n \"octant\",\n \"odd-leg_caliper\",\n \"odometer, hodometer, mileometer, milometer\",\n \"oeil_de_boeuf\",\n \"office, business_office\",\n \"office_building, office_block\",\n \"office_furniture\",\n \"officer's_mess\",\n \"off-line_equipment, auxiliary_equipment\",\n \"ogee, cyma_reversa\",\n \"ogee_arch, keel_arch\",\n \"ohmmeter\",\n \"oil, oil_color, oil_colour\",\n \"oilcan\",\n \"oilcloth\",\n \"oil_filter\",\n \"oil_heater, oilstove, kerosene_heater, kerosine_heater\",\n \"oil_lamp, kerosene_lamp, kerosine_lamp\",\n \"oil_paint\",\n \"oil_pump\",\n \"oil_refinery, petroleum_refinery\",\n \"oilskin, slicker\",\n \"oil_slick\",\n \"oilstone\",\n \"oil_tanker, oiler, tanker, tank_ship\",\n \"old_school_tie\",\n \"olive_drab\",\n \"olive_drab, olive-drab_uniform\",\n \"olympian_zeus\",\n \"omelet_pan, omelette_pan\",\n \"omnidirectional_antenna, nondirectional_antenna\",\n \"omnirange, omnidirectional_range, omnidirectional_radio_range\",\n \"onion_dome\",\n \"open-air_market, open-air_marketplace, market_square\",\n \"open_circuit\",\n \"open-end_wrench, tappet_wrench\",\n \"opener\",\n \"open-hearth_furnace\",\n \"openside_plane, rabbet_plane\",\n \"open_sight\",\n \"openwork\",\n \"opera, opera_house\",\n \"opera_cloak, opera_hood\",\n \"operating_microscope\",\n \"operating_room, or, operating_theater, operating_theatre, surgery\",\n \"operating_table\",\n \"ophthalmoscope\",\n \"optical_device\",\n \"optical_disk, optical_disc\",\n \"optical_instrument\",\n \"optical_pyrometer, pyroscope\",\n \"optical_telescope\",\n \"orchestra_pit, pit\",\n \"ordinary, ordinary_bicycle\",\n \"organ, pipe_organ\",\n \"organdy, organdie\",\n \"organic_light-emitting_diode, oled\",\n \"organ_loft\",\n \"organ_pipe, pipe, pipework\",\n \"organza\",\n \"oriel, oriel_window\",\n \"oriflamme\",\n \"o_ring\",\n \"orlon\",\n \"orlop_deck, orlop, fourth_deck\",\n \"orphanage, orphans'_asylum\",\n \"orphrey\",\n \"orrery\",\n \"orthicon, image_orthicon\",\n \"orthochromatic_film\",\n \"orthopter, ornithopter\",\n \"orthoscope\",\n \"oscillograph\",\n \"oscilloscope, scope, cathode-ray_oscilloscope, cro\",\n \"ossuary\",\n \"otoscope, auriscope, auroscope\",\n \"ottoman, pouf, pouffe, puff, hassock\",\n \"oubliette\",\n \"out-basket, out-tray\",\n \"outboard_motor, outboard\",\n \"outboard_motorboat, outboard\",\n \"outbuilding\",\n \"outerwear, overclothes\",\n \"outfall\",\n \"outfit, getup, rig, turnout\",\n \"outfitter\",\n \"outhouse, privy, earth-closet, jakes\",\n \"output_device\",\n \"outrigger\",\n \"outrigger_canoe\",\n \"outside_caliper\",\n \"outside_mirror\",\n \"outwork\",\n \"oven\",\n \"oven_thermometer\",\n \"overall\",\n \"overall, boilersuit, boilers_suit\",\n \"overcoat, overcoating\",\n \"overdrive\",\n \"overgarment, outer_garment\",\n \"overhand_knot\",\n \"overhang\",\n \"overhead_projector\",\n \"overmantel\",\n \"overnighter, overnight_bag, overnight_case\",\n \"overpass, flyover\",\n \"override\",\n \"overshoe\",\n \"overskirt\",\n \"oxbow\",\n \"oxbridge\",\n \"oxcart\",\n \"oxeye\",\n \"oxford\",\n \"oximeter\",\n \"oxyacetylene_torch\",\n \"oxygen_mask\",\n \"oyster_bar\",\n \"oyster_bed, oyster_bank, oyster_park\",\n \"pace_car\",\n \"pacemaker, artificial_pacemaker\",\n \"pack\",\n \"pack\",\n \"pack, face_pack\",\n \"package, parcel\",\n \"package_store, liquor_store, off-licence\",\n \"packaging\",\n \"packet\",\n \"packing_box, packing_case\",\n \"packinghouse, packing_plant\",\n \"packinghouse\",\n \"packing_needle\",\n \"packsaddle\",\n \"paddle, boat_paddle\",\n \"paddle\",\n \"paddle\",\n \"paddle_box, paddle-box\",\n \"paddle_steamer, paddle-wheeler\",\n \"paddlewheel, paddle_wheel\",\n \"paddock\",\n \"padlock\",\n \"page_printer, page-at-a-time_printer\",\n \"paint, pigment\",\n \"paintball\",\n \"paintball_gun\",\n \"paintbox\",\n \"paintbrush\",\n \"paisley\",\n \"pajama, pyjama, pj's, jammies\",\n \"pajama, pyjama\",\n \"palace\",\n \"palace, castle\",\n \"palace\",\n \"palanquin, palankeen\",\n \"paleolith\",\n \"palestra, palaestra\",\n \"palette, pallet\",\n \"palette_knife\",\n \"palisade\",\n \"pallet\",\n \"pallette, palette\",\n \"pallium\",\n \"pallium\",\n \"pan\",\n \"pan, cooking_pan\",\n \"pancake_turner\",\n \"panchromatic_film\",\n \"panda_car\",\n \"paneling, panelling, pane\",\n \"panhandle\",\n \"panic_button\",\n \"pannier\",\n \"pannier\",\n \"pannikin\",\n \"panopticon\",\n \"panopticon\",\n \"panpipe, pandean_pipe, syrinx\",\n \"pantaloon\",\n \"pantechnicon\",\n \"pantheon\",\n \"pantheon\",\n \"pantie, panty, scanty, step-in\",\n \"panting, trousering\",\n \"pant_leg, trouser_leg\",\n \"pantograph\",\n \"pantry, larder, buttery\",\n \"pants_suit, pantsuit\",\n \"panty_girdle\",\n \"pantyhose\",\n \"panzer\",\n \"paper_chain\",\n \"paper_clip, paperclip, gem_clip\",\n \"paper_cutter\",\n \"paper_fastener\",\n \"paper_feed\",\n \"paper_mill\",\n \"paper_towel\",\n \"parabolic_mirror\",\n \"parabolic_reflector, paraboloid_reflector\",\n \"parachute, chute\",\n \"parallel_bars, bars\",\n \"parallel_circuit, shunt_circuit\",\n \"parallel_interface, parallel_port\",\n \"parang\",\n \"parapet, breastwork\",\n \"parapet\",\n \"parasail\",\n \"parasol, sunshade\",\n \"parer, paring_knife\",\n \"parfait_glass\",\n \"pargeting, pargetting, pargetry\",\n \"pari-mutuel_machine, totalizer, totaliser, totalizator, totalisator\",\n \"parka, windbreaker, windcheater, anorak\",\n \"park_bench\",\n \"parking_meter\",\n \"parlor, parlour\",\n \"parquet, parquet_floor\",\n \"parquetry, parqueterie\",\n \"parsonage, vicarage, rectory\",\n \"parsons_table\",\n \"partial_denture\",\n \"particle_detector\",\n \"partition, divider\",\n \"parts_bin\",\n \"party_line\",\n \"party_wall\",\n \"parvis\",\n \"passenger_car, coach, carriage\",\n \"passenger_ship\",\n \"passenger_train\",\n \"passenger_van\",\n \"passe-partout\",\n \"passive_matrix_display\",\n \"passkey, passe-partout, master_key, master\",\n \"pass-through\",\n \"pastry_cart\",\n \"patch\",\n \"patchcord\",\n \"patchouli, patchouly, pachouli\",\n \"patch_pocket\",\n \"patchwork, patchwork_quilt\",\n \"patent_log, screw_log, taffrail_log\",\n \"paternoster\",\n \"patina\",\n \"patio, terrace\",\n \"patisserie\",\n \"patka\",\n \"patrol_boat, patrol_ship\",\n \"patty-pan\",\n \"pave\",\n \"pavilion, marquee\",\n \"pavior, paviour, paving_machine\",\n \"pavis, pavise\",\n \"pawn\",\n \"pawnbroker's_shop, pawnshop, loan_office\",\n \"pay-phone, pay-station\",\n \"pc_board\",\n \"peach_orchard\",\n \"pea_jacket, peacoat\",\n \"peavey, peavy, cant_dog, dog_hook\",\n \"pectoral, pectoral_medallion\",\n \"pedal, treadle, foot_pedal, foot_lever\",\n \"pedal_pusher, toreador_pants\",\n \"pedestal, plinth, footstall\",\n \"pedestal_table\",\n \"pedestrian_crossing, zebra_crossing\",\n \"pedicab, cycle_rickshaw\",\n \"pediment\",\n \"pedometer\",\n \"peeler\",\n \"peep_sight\",\n \"peg, nog\",\n \"peg, pin, thole, tholepin, rowlock, oarlock\",\n \"peg\",\n \"peg, wooden_leg, leg, pegleg\",\n \"pegboard\",\n \"pelham\",\n \"pelican_crossing\",\n \"pelisse\",\n \"pelvimeter\",\n \"pen\",\n \"penal_colony\",\n \"penal_institution, penal_facility\",\n \"penalty_box\",\n \"pen-and-ink\",\n \"pencil\",\n \"pencil\",\n \"pencil_box, pencil_case\",\n \"pencil_sharpener\",\n \"pendant_earring, drop_earring, eardrop\",\n \"pendulum\",\n \"pendulum_clock\",\n \"pendulum_watch\",\n \"penetration_bomb\",\n \"penile_implant\",\n \"penitentiary, pen\",\n \"penknife\",\n \"penlight\",\n \"pennant, pennon, streamer, waft\",\n \"pennywhistle, tin_whistle, whistle\",\n \"penthouse\",\n \"pentode\",\n \"peplos, peplus, peplum\",\n \"peplum\",\n \"pepper_mill, pepper_grinder\",\n \"pepper_shaker, pepper_box, pepper_pot\",\n \"pepper_spray\",\n \"percale\",\n \"percolator\",\n \"percussion_cap\",\n \"percussion_instrument, percussive_instrument\",\n \"perforation\",\n \"perfume, essence\",\n \"perfumery\",\n \"perfumery\",\n \"perfumery\",\n \"peripheral, computer_peripheral, peripheral_device\",\n \"periscope\",\n \"peristyle\",\n \"periwig, peruke\",\n \"permanent_press, durable_press\",\n \"perpetual_motion_machine\",\n \"personal_computer, pc, microcomputer\",\n \"personal_digital_assistant, pda, personal_organizer, personal_organiser, organizer, organiser\",\n \"personnel_carrier\",\n \"pestle\",\n \"pestle, muller, pounder\",\n \"petcock\",\n \"petri_dish\",\n \"petrolatum_gauze\",\n \"pet_shop\",\n \"petticoat, half-slip, underskirt\",\n \"pew, church_bench\",\n \"phial, vial, ampule, ampul, ampoule\",\n \"phillips_screw\",\n \"phillips_screwdriver\",\n \"phonograph_needle, needle\",\n \"phonograph_record, phonograph_recording, record, disk, disc, platter\",\n \"photocathode\",\n \"photocoagulator\",\n \"photocopier\",\n \"photographic_equipment\",\n \"photographic_paper, photographic_material\",\n \"photometer\",\n \"photomicrograph\",\n \"photostat, photostat_machine\",\n \"photostat\",\n \"physical_pendulum, compound_pendulum\",\n \"piano, pianoforte, forte-piano\",\n \"piano_action\",\n \"piano_keyboard, fingerboard, clavier\",\n \"piano_wire\",\n \"piccolo\",\n \"pick, pickax, pickaxe\",\n \"pick\",\n \"pick, plectrum, plectron\",\n \"pickelhaube\",\n \"picket_boat\",\n \"picket_fence, paling\",\n \"picket_ship\",\n \"pickle_barrel\",\n \"pickup, pickup_truck\",\n \"picture_frame\",\n \"picture_hat\",\n \"picture_rail\",\n \"picture_window\",\n \"piece_of_cloth, piece_of_material\",\n \"pied-a-terre\",\n \"pier\",\n \"pier\",\n \"pier_arch\",\n \"pier_glass, pier_mirror\",\n \"pier_table\",\n \"pieta\",\n \"piezometer\",\n \"pig_bed, pig\",\n \"piggery, pig_farm\",\n \"piggy_bank, penny_bank\",\n \"pilaster\",\n \"pile, spile, piling, stilt\",\n \"pile_driver\",\n \"pill_bottle\",\n \"pillbox, toque, turban\",\n \"pillion\",\n \"pillory\",\n \"pillow\",\n \"pillow_block\",\n \"pillow_lace, bobbin_lace\",\n \"pillow_sham\",\n \"pilot_bit\",\n \"pilot_boat\",\n \"pilot_burner, pilot_light, pilot\",\n \"pilot_cloth\",\n \"pilot_engine\",\n \"pilothouse, wheelhouse\",\n \"pilot_light, pilot_lamp, indicator_lamp\",\n \"pin\",\n \"pin, flag\",\n \"pin, pin_tumbler\",\n \"pinata\",\n \"pinball_machine, pin_table\",\n \"pince-nez\",\n \"pincer, pair_of_pincers, tweezer, pair_of_tweezers\",\n \"pinch_bar\",\n \"pincurl_clip\",\n \"pinfold\",\n \"ping-pong_ball\",\n \"pinhead\",\n \"pinion\",\n \"pinnacle\",\n \"pinprick\",\n \"pinstripe\",\n \"pinstripe\",\n \"pinstripe\",\n \"pintle\",\n \"pinwheel, pinwheel_wind_collector\",\n \"pinwheel\",\n \"tabor_pipe\",\n \"pipe\",\n \"pipe_bomb\",\n \"pipe_cleaner\",\n \"pipe_cutter\",\n \"pipefitting, pipe_fitting\",\n \"pipet, pipette\",\n \"pipe_vise, pipe_clamp\",\n \"pipe_wrench, tube_wrench\",\n \"pique\",\n \"pirate, pirate_ship\",\n \"piste\",\n \"pistol, handgun, side_arm, shooting_iron\",\n \"pistol_grip\",\n \"piston, plunger\",\n \"piston_ring\",\n \"piston_rod\",\n \"pit\",\n \"pitcher, ewer\",\n \"pitchfork\",\n \"pitching_wedge\",\n \"pitch_pipe\",\n \"pith_hat, pith_helmet, sun_helmet, topee, topi\",\n \"piton\",\n \"pitot-static_tube, pitot_head, pitot_tube\",\n \"pitot_tube, pitot\",\n \"pitsaw\",\n \"pivot, pin\",\n \"pivoting_window\",\n \"pizzeria, pizza_shop, pizza_parlor\",\n \"place_of_business, business_establishment\",\n \"place_of_worship, house_of_prayer, house_of_god, house_of_worship\",\n \"placket\",\n \"planchet, coin_blank\",\n \"plane, carpenter's_plane, woodworking_plane\",\n \"plane, planer, planing_machine\",\n \"plane_seat\",\n \"planetarium\",\n \"planetarium\",\n \"planetarium\",\n \"planetary_gear, epicyclic_gear, planet_wheel, planet_gear\",\n \"plank-bed\",\n \"planking\",\n \"planner\",\n \"plant, works, industrial_plant\",\n \"planter\",\n \"plaster, adhesive_plaster, sticking_plaster\",\n \"plasterboard, gypsum_board\",\n \"plastering_trowel\",\n \"plastic_bag\",\n \"plastic_bomb\",\n \"plastic_laminate\",\n \"plastic_wrap\",\n \"plastron\",\n \"plastron\",\n \"plastron\",\n \"plate, scale, shell\",\n \"plate, collection_plate\",\n \"plate\",\n \"platen\",\n \"platen\",\n \"plate_rack\",\n \"plate_rail\",\n \"platform\",\n \"platform, weapons_platform\",\n \"platform\",\n \"platform_bed\",\n \"platform_rocker\",\n \"plating, metal_plating\",\n \"platter\",\n \"playback\",\n \"playbox, play-box\",\n \"playground\",\n \"playpen, pen\",\n \"playsuit\",\n \"plaza, mall, center, shopping_mall, shopping_center, shopping_centre\",\n \"pleat, plait\",\n \"plenum\",\n \"plethysmograph\",\n \"pleximeter, plessimeter\",\n \"plexor, plessor, percussor\",\n \"pliers, pair_of_pliers, plyers\",\n \"plimsoll\",\n \"plotter\",\n \"plow, plough\",\n \"plug, stopper, stopple\",\n \"plug, male_plug\",\n \"plug_fuse\",\n \"plughole\",\n \"plumb_bob, plumb, plummet\",\n \"plumb_level\",\n \"plunger, plumber's_helper\",\n \"plus_fours\",\n \"plush\",\n \"plywood, plyboard\",\n \"pneumatic_drill\",\n \"p-n_junction\",\n \"p-n-p_transistor\",\n \"poacher\",\n \"pocket\",\n \"pocket_battleship\",\n \"pocketcomb, pocket_comb\",\n \"pocket_flap\",\n \"pocket-handkerchief\",\n \"pocketknife, pocket_knife\",\n \"pocket_watch\",\n \"pod, fuel_pod\",\n \"pogo_stick\",\n \"point-and-shoot_camera\",\n \"pointed_arch\",\n \"pointing_trowel\",\n \"point_lace, needlepoint\",\n \"poker, stove_poker, fire_hook, salamander\",\n \"polarimeter, polariscope\",\n \"polaroid\",\n \"polaroid_camera, polaroid_land_camera\",\n \"pole\",\n \"pole\",\n \"poleax, poleaxe\",\n \"poleax, poleaxe\",\n \"police_boat\",\n \"police_van, police_wagon, paddy_wagon, patrol_wagon, wagon, black_maria\",\n \"polling_booth\",\n \"polo_ball\",\n \"polo_mallet, polo_stick\",\n \"polonaise\",\n \"polo_shirt, sport_shirt\",\n \"polyester\",\n \"polygraph\",\n \"pomade, pomatum\",\n \"pommel_horse, side_horse\",\n \"poncho\",\n \"pongee\",\n \"poniard, bodkin\",\n \"pontifical\",\n \"pontoon\",\n \"pontoon_bridge, bateau_bridge, floating_bridge\",\n \"pony_cart, ponycart, donkey_cart, tub-cart\",\n \"pool_ball\",\n \"poolroom\",\n \"pool_table, billiard_table, snooker_table\",\n \"poop_deck\",\n \"poor_box, alms_box, mite_box\",\n \"poorhouse\",\n \"pop_bottle, soda_bottle\",\n \"popgun\",\n \"poplin\",\n \"popper\",\n \"poppet, poppet_valve\",\n \"pop_tent\",\n \"porcelain\",\n \"porch\",\n \"porkpie, porkpie_hat\",\n \"porringer\",\n \"portable\",\n \"portable_computer\",\n \"portable_circular_saw, portable_saw\",\n \"portcullis\",\n \"porte-cochere\",\n \"porte-cochere\",\n \"portfolio\",\n \"porthole\",\n \"portico\",\n \"portiere\",\n \"portmanteau, gladstone, gladstone_bag\",\n \"portrait_camera\",\n \"portrait_lens\",\n \"positive_pole, positive_magnetic_pole, north-seeking_pole\",\n \"positive_pole\",\n \"positron_emission_tomography_scanner, pet_scanner\",\n \"post\",\n \"postage_meter\",\n \"post_and_lintel\",\n \"post_chaise\",\n \"postern\",\n \"post_exchange, px\",\n \"posthole_digger, post-hole_digger\",\n \"post_horn\",\n \"posthouse, post_house\",\n \"pot\",\n \"pot, flowerpot\",\n \"potbelly, potbelly_stove\",\n \"potemkin_village\",\n \"potential_divider, voltage_divider\",\n \"potentiometer, pot\",\n \"potentiometer\",\n \"potpourri\",\n \"potsherd\",\n \"potter's_wheel\",\n \"pottery, clayware\",\n \"pottle\",\n \"potty_seat, potty_chair\",\n \"pouch\",\n \"poultice, cataplasm, plaster\",\n \"pound, dog_pound\",\n \"pound_net\",\n \"powder\",\n \"powder_and_shot\",\n \"powdered_mustard, dry_mustard\",\n \"powder_horn, powder_flask\",\n \"powder_keg\",\n \"power_brake\",\n \"power_cord\",\n \"power_drill\",\n \"power_line, power_cable\",\n \"power_loom\",\n \"power_mower, motor_mower\",\n \"power_pack\",\n \"power_saw, saw, sawing_machine\",\n \"power_shovel, excavator, digger, shovel\",\n \"power_steering, power-assisted_steering\",\n \"power_takeoff, pto\",\n \"power_tool\",\n \"praetorium, pretorium\",\n \"prayer_rug, prayer_mat\",\n \"prayer_shawl, tallith, tallis\",\n \"precipitator, electrostatic_precipitator, cottrell_precipitator\",\n \"prefab\",\n \"presbytery\",\n \"presence_chamber\",\n \"press, mechanical_press\",\n \"press, printing_press\",\n \"press\",\n \"press_box\",\n \"press_gallery\",\n \"press_of_sail, press_of_canvas\",\n \"pressure_cabin\",\n \"pressure_cooker\",\n \"pressure_dome\",\n \"pressure_gauge, pressure_gage\",\n \"pressurized_water_reactor, pwr\",\n \"pressure_suit\",\n \"pricket\",\n \"prie-dieu\",\n \"primary_coil, primary_winding, primary\",\n \"primus_stove, primus\",\n \"prince_albert\",\n \"print\",\n \"print_buffer\",\n \"printed_circuit\",\n \"printer, printing_machine\",\n \"printer\",\n \"printer_cable\",\n \"priory\",\n \"prison, prison_house\",\n \"prison_camp, internment_camp, prisoner_of_war_camp, pow_camp\",\n \"privateer\",\n \"private_line\",\n \"privet_hedge\",\n \"probe\",\n \"proctoscope\",\n \"prod, goad\",\n \"production_line, assembly_line, line\",\n \"projectile, missile\",\n \"projector\",\n \"projector\",\n \"prolonge\",\n \"prolonge_knot, sailor's_breastplate\",\n \"prompter, autocue\",\n \"prong\",\n \"propeller, propellor\",\n \"propeller_plane\",\n \"propjet, turboprop, turbo-propeller_plane\",\n \"proportional_counter_tube, proportional_counter\",\n \"propulsion_system\",\n \"proscenium, proscenium_wall\",\n \"proscenium_arch\",\n \"prosthesis, prosthetic_device\",\n \"protective_covering, protective_cover, protection\",\n \"protective_garment\",\n \"proton_accelerator\",\n \"protractor\",\n \"pruner, pruning_hook, lopper\",\n \"pruning_knife\",\n \"pruning_saw\",\n \"pruning_shears\",\n \"psaltery\",\n \"psychrometer\",\n \"pt_boat, mosquito_boat, mosquito_craft, motor_torpedo_boat\",\n \"public_address_system, p.a._system, pa_system, p.a., pa\",\n \"public_house, pub, saloon, pothouse, gin_mill, taphouse\",\n \"public_toilet, comfort_station, public_convenience, convenience, public_lavatory, restroom, toilet_facility, wash_room\",\n \"public_transport\",\n \"public_works\",\n \"puck, hockey_puck\",\n \"pull\",\n \"pullback, tieback\",\n \"pull_chain\",\n \"pulley, pulley-block, pulley_block, block\",\n \"pull-off, rest_area, rest_stop, layby, lay-by\",\n \"pullman, pullman_car\",\n \"pullover, slipover\",\n \"pull-through\",\n \"pulse_counter\",\n \"pulse_generator\",\n \"pulse_timing_circuit\",\n \"pump\",\n \"pump\",\n \"pump_action, slide_action\",\n \"pump_house, pumping_station\",\n \"pump_room\",\n \"pump-type_pliers\",\n \"pump_well\",\n \"punch, puncher\",\n \"punchboard\",\n \"punch_bowl\",\n \"punching_bag, punch_bag, punching_ball, punchball\",\n \"punch_pliers\",\n \"punch_press\",\n \"punnet\",\n \"punt\",\n \"pup_tent, shelter_tent\",\n \"purdah\",\n \"purifier\",\n \"purl, purl_stitch\",\n \"purse\",\n \"push-bike\",\n \"push_broom\",\n \"push_button, push, button\",\n \"push-button_radio\",\n \"pusher, zori\",\n \"put-put\",\n \"puttee\",\n \"putter, putting_iron\",\n \"putty_knife\",\n \"puzzle\",\n \"pylon, power_pylon\",\n \"pylon\",\n \"pyramidal_tent\",\n \"pyrograph\",\n \"pyrometer\",\n \"pyrometric_cone\",\n \"pyrostat\",\n \"pyx, pix\",\n \"pyx, pix, pyx_chest, pix_chest\",\n \"pyxis\",\n \"quad, quadrangle\",\n \"quadrant\",\n \"quadraphony, quadraphonic_system, quadriphonic_system\",\n \"quartering\",\n \"quarterstaff\",\n \"quartz_battery, quartz_mill\",\n \"quartz_lamp\",\n \"queen\",\n \"queen\",\n \"queen_post\",\n \"quern\",\n \"quill, quill_pen\",\n \"quilt, comforter, comfort, puff\",\n \"quilted_bedspread\",\n \"quilting\",\n \"quipu\",\n \"quirk_molding, quirk_moulding\",\n \"quirt\",\n \"quiver\",\n \"quoin, coign, coigne\",\n \"quoit\",\n \"qwerty_keyboard\",\n \"rabbet, rebate\",\n \"rabbet_joint\",\n \"rabbit_ears\",\n \"rabbit_hutch\",\n \"raceabout\",\n \"racer, race_car, racing_car\",\n \"raceway, race\",\n \"racing_boat\",\n \"racing_gig\",\n \"racing_skiff, single_shell\",\n \"rack, stand\",\n \"rack\",\n \"rack, wheel\",\n \"rack_and_pinion\",\n \"racket, racquet\",\n \"racquetball\",\n \"radar, microwave_radar, radio_detection_and_ranging, radiolocation\",\n \"radial, radial_tire, radial-ply_tire\",\n \"radial_engine, rotary_engine\",\n \"radiation_pyrometer\",\n \"radiator\",\n \"radiator\",\n \"radiator_cap\",\n \"radiator_hose\",\n \"radio, wireless\",\n \"radio_antenna, radio_aerial\",\n \"radio_chassis\",\n \"radio_compass\",\n \"radiogram, radiograph, shadowgraph, skiagraph, skiagram\",\n \"radio_interferometer\",\n \"radio_link, link\",\n \"radiometer\",\n \"radiomicrometer\",\n \"radio-phonograph, radio-gramophone\",\n \"radio_receiver, receiving_set, radio_set, radio, tuner, wireless\",\n \"radiotelegraph, radiotelegraphy, wireless_telegraph, wireless_telegraphy\",\n \"radiotelephone, radiophone, wireless_telephone\",\n \"radio_telescope, radio_reflector\",\n \"radiotherapy_equipment\",\n \"radio_transmitter\",\n \"radome, radar_dome\",\n \"raft\",\n \"rafter, balk, baulk\",\n \"raft_foundation\",\n \"rag, shred, tag, tag_end, tatter\",\n \"ragbag\",\n \"raglan\",\n \"raglan_sleeve\",\n \"rail\",\n \"rail_fence\",\n \"railhead\",\n \"railing, rail\",\n \"railing\",\n \"railroad_bed\",\n \"railroad_tunnel\",\n \"rain_barrel\",\n \"raincoat, waterproof\",\n \"rain_gauge, rain_gage, pluviometer, udometer\",\n \"rain_stick\",\n \"rake\",\n \"rake_handle\",\n \"ram_disk\",\n \"ramekin, ramequin\",\n \"ramjet, ramjet_engine, atherodyde, athodyd, flying_drainpipe\",\n \"rammer\",\n \"ramp, incline\",\n \"rampant_arch\",\n \"rampart, bulwark, wall\",\n \"ramrod\",\n \"ramrod\",\n \"ranch, spread, cattle_ranch, cattle_farm\",\n \"ranch_house\",\n \"random-access_memory, random_access_memory, random_memory, ram, read/write_memory\",\n \"rangefinder, range_finder\",\n \"range_hood\",\n \"range_pole, ranging_pole, flagpole\",\n \"rapier, tuck\",\n \"rariora\",\n \"rasp, wood_file\",\n \"ratchet, rachet, ratch\",\n \"ratchet_wheel\",\n \"rathskeller\",\n \"ratline, ratlin\",\n \"rat-tail_file\",\n \"rattan, ratan\",\n \"rattrap\",\n \"rayon\",\n \"razor\",\n \"razorblade\",\n \"reaction-propulsion_engine, reaction_engine\",\n \"reaction_turbine\",\n \"reactor\",\n \"reading_lamp\",\n \"reading_room\",\n \"read-only_memory, rom, read-only_storage, fixed_storage\",\n \"read-only_memory_chip\",\n \"readout, read-out\",\n \"read/write_head, head\",\n \"ready-to-wear\",\n \"real_storage\",\n \"reamer\",\n \"reamer, juicer, juice_reamer\",\n \"rearview_mirror\",\n \"reaumur_thermometer\",\n \"rebozo\",\n \"receiver, receiving_system\",\n \"receptacle\",\n \"reception_desk\",\n \"reception_room\",\n \"recess, niche\",\n \"reciprocating_engine\",\n \"recliner, reclining_chair, lounger\",\n \"reconnaissance_plane\",\n \"reconnaissance_vehicle, scout_car\",\n \"record_changer, auto-changer, changer\",\n \"recorder, recording_equipment, recording_machine\",\n \"recording\",\n \"recording_system\",\n \"record_player, phonograph\",\n \"record_sleeve, record_cover\",\n \"recovery_room\",\n \"recreational_vehicle, rv, r.v.\",\n \"recreation_room, rec_room\",\n \"recycling_bin\",\n \"recycling_plant\",\n \"redbrick_university\",\n \"red_carpet\",\n \"redoubt\",\n \"redoubt\",\n \"reduction_gear\",\n \"reed_pipe\",\n \"reed_stop\",\n \"reef_knot, flat_knot\",\n \"reel\",\n \"reel\",\n \"refectory\",\n \"refectory_table\",\n \"refinery\",\n \"reflecting_telescope, reflector\",\n \"reflectometer\",\n \"reflector\",\n \"reflex_camera\",\n \"reflux_condenser\",\n \"reformatory, reform_school, training_school\",\n \"reformer\",\n \"refracting_telescope\",\n \"refractometer\",\n \"refrigeration_system\",\n \"refrigerator, icebox\",\n \"refrigerator_car\",\n \"refuge, sanctuary, asylum\",\n \"regalia\",\n \"regimentals\",\n \"regulator\",\n \"rein\",\n \"relay, electrical_relay\",\n \"release, button\",\n \"religious_residence, cloister\",\n \"reliquary\",\n \"remote_control, remote\",\n \"remote_terminal, link-attached_terminal, remote_station, link-attached_station\",\n \"removable_disk\",\n \"rendering\",\n \"rep, repp\",\n \"repair_shop, fix-it_shop\",\n \"repeater\",\n \"repeating_firearm, repeater\",\n \"repository, monument\",\n \"reproducer\",\n \"rerebrace, upper_cannon\",\n \"rescue_equipment\",\n \"research_center, research_facility\",\n \"reseau\",\n \"reservoir\",\n \"reset\",\n \"reset_button\",\n \"residence\",\n \"resistance_pyrometer\",\n \"resistor, resistance\",\n \"resonator\",\n \"resonator, cavity_resonator, resonating_chamber\",\n \"resort_hotel, spa\",\n \"respirator, inhalator\",\n \"restaurant, eating_house, eating_place, eatery\",\n \"rest_house\",\n \"restraint, constraint\",\n \"resuscitator\",\n \"retainer\",\n \"retaining_wall\",\n \"reticle, reticule, graticule\",\n \"reticulation\",\n \"reticule\",\n \"retort\",\n \"retractor\",\n \"return_key, return\",\n \"reverberatory_furnace\",\n \"revers, revere\",\n \"reverse, reverse_gear\",\n \"reversible\",\n \"revetment, revetement, stone_facing\",\n \"revetment\",\n \"revolver, six-gun, six-shooter\",\n \"revolving_door, revolver\",\n \"rheometer\",\n \"rheostat, variable_resistor\",\n \"rhinoscope\",\n \"rib\",\n \"riband, ribband\",\n \"ribbed_vault\",\n \"ribbing\",\n \"ribbon_development\",\n \"rib_joint_pliers\",\n \"ricer\",\n \"riddle\",\n \"ride\",\n \"ridge, ridgepole, rooftree\",\n \"ridge_rope\",\n \"riding_boot\",\n \"riding_crop, hunting_crop\",\n \"riding_mower\",\n \"rifle\",\n \"rifle_ball\",\n \"rifle_grenade\",\n \"rig\",\n \"rigger, rigger_brush\",\n \"rigger\",\n \"rigging, tackle\",\n \"rigout\",\n \"ringlet\",\n \"rings\",\n \"rink, skating_rink\",\n \"riot_gun\",\n \"ripcord\",\n \"ripcord\",\n \"ripping_bar\",\n \"ripping_chisel\",\n \"ripsaw, splitsaw\",\n \"riser\",\n \"riser, riser_pipe, riser_pipeline, riser_main\",\n \"ritz\",\n \"river_boat\",\n \"rivet\",\n \"riveting_machine, riveter, rivetter\",\n \"roach_clip, roach_holder\",\n \"road, route\",\n \"roadbed\",\n \"roadblock, barricade\",\n \"roadhouse\",\n \"roadster, runabout, two-seater\",\n \"roadway\",\n \"roaster\",\n \"robe\",\n \"robotics_equipment\",\n \"rochon_prism, wollaston_prism\",\n \"rock_bit, roller_bit\",\n \"rocker\",\n \"rocker, cradle\",\n \"rocker_arm, valve_rocker\",\n \"rocket, rocket_engine\",\n \"rocket, projectile\",\n \"rocking_chair, rocker\",\n \"rod\",\n \"rodeo\",\n \"roll\",\n \"roller\",\n \"roller\",\n \"roller_bandage\",\n \"in-line_skate\",\n \"rollerblade\",\n \"roller_blind\",\n \"roller_coaster, big_dipper, chute-the-chute\",\n \"roller_skate\",\n \"roller_towel\",\n \"roll_film\",\n \"rolling_hitch\",\n \"rolling_mill\",\n \"rolling_pin\",\n \"rolling_stock\",\n \"roll-on\",\n \"roll-on\",\n \"roll-on_roll-off\",\n \"rolodex\",\n \"roman_arch, semicircular_arch\",\n \"roman_building\",\n \"romper, romper_suit\",\n \"rood_screen\",\n \"roof\",\n \"roof\",\n \"roofing\",\n \"room\",\n \"roomette\",\n \"room_light\",\n \"roost\",\n \"rope\",\n \"rope_bridge\",\n \"rope_tow\",\n \"rose_water\",\n \"rose_window, rosette\",\n \"rosin_bag\",\n \"rotary_actuator, positioner\",\n \"rotary_engine\",\n \"rotary_press\",\n \"rotating_mechanism\",\n \"rotating_shaft, shaft\",\n \"rotisserie\",\n \"rotisserie\",\n \"rotor\",\n \"rotor, rotor_coil\",\n \"rotor\",\n \"rotor_blade, rotary_wing\",\n \"rotor_head, rotor_shaft\",\n \"rotunda\",\n \"rotunda\",\n \"rouge, paint, blusher\",\n \"roughcast\",\n \"rouleau\",\n \"roulette, toothed_wheel\",\n \"roulette_ball\",\n \"roulette_wheel, wheel\",\n \"round, unit_of_ammunition, one_shot\",\n \"round_arch\",\n \"round-bottom_flask\",\n \"roundel\",\n \"round_file\",\n \"roundhouse\",\n \"router\",\n \"router\",\n \"router_plane\",\n \"rowel\",\n \"row_house, town_house\",\n \"rowing_boat\",\n \"rowlock_arch\",\n \"royal\",\n \"royal_mast\",\n \"rubber_band, elastic_band, elastic\",\n \"rubber_boot, gum_boot\",\n \"rubber_bullet\",\n \"rubber_eraser, rubber, pencil_eraser\",\n \"rudder\",\n \"rudder\",\n \"rudder_blade\",\n \"rug, carpet, carpeting\",\n \"rugby_ball\",\n \"ruin\",\n \"rule, ruler\",\n \"rumble\",\n \"rumble_seat\",\n \"rummer\",\n \"rumpus_room, playroom, game_room\",\n \"runcible_spoon\",\n \"rundle, spoke, rung\",\n \"running_shoe\",\n \"running_suit\",\n \"runway\",\n \"rushlight, rush_candle\",\n \"russet\",\n \"rya, rya_rug\",\n \"saber, sabre\",\n \"saber_saw, jigsaw, reciprocating_saw\",\n \"sable\",\n \"sable, sable_brush, sable's_hair_pencil\",\n \"sable_coat\",\n \"sabot, wooden_shoe\",\n \"sachet\",\n \"sack, poke, paper_bag, carrier_bag\",\n \"sack, sacque\",\n \"sackbut\",\n \"sackcloth\",\n \"sackcloth\",\n \"sack_coat\",\n \"sacking, bagging\",\n \"saddle\",\n \"saddlebag\",\n \"saddle_blanket, saddlecloth, horse_blanket\",\n \"saddle_oxford, saddle_shoe\",\n \"saddlery\",\n \"saddle_seat\",\n \"saddle_stitch\",\n \"safe\",\n \"safe\",\n \"safe-deposit, safe-deposit_box, safety-deposit, safety_deposit_box, deposit_box, lockbox\",\n \"safe_house\",\n \"safety_arch\",\n \"safety_belt, life_belt, safety_harness\",\n \"safety_bicycle, safety_bike\",\n \"safety_bolt, safety_lock\",\n \"safety_curtain\",\n \"safety_fuse\",\n \"safety_lamp, davy_lamp\",\n \"safety_match, book_matches\",\n \"safety_net\",\n \"safety_pin\",\n \"safety_rail, guardrail\",\n \"safety_razor\",\n \"safety_valve, relief_valve, escape_valve, escape_cock, escape\",\n \"sail, canvas, canvass, sheet\",\n \"sail\",\n \"sailboat, sailing_boat\",\n \"sailcloth\",\n \"sailing_vessel, sailing_ship\",\n \"sailing_warship\",\n \"sailor_cap\",\n \"sailor_suit\",\n \"salad_bar\",\n \"salad_bowl\",\n \"salinometer\",\n \"sallet, salade\",\n \"salon\",\n \"salon\",\n \"salon, beauty_salon, beauty_parlor, beauty_parlour, beauty_shop\",\n \"saltbox\",\n \"saltcellar\",\n \"saltshaker, salt_shaker\",\n \"saltworks\",\n \"salver\",\n \"salwar, shalwar\",\n \"sam_browne_belt\",\n \"samisen, shamisen\",\n \"samite\",\n \"samovar\",\n \"sampan\",\n \"sandal\",\n \"sandbag\",\n \"sandblaster\",\n \"sandbox\",\n \"sandglass\",\n \"sand_wedge\",\n \"sandwich_board\",\n \"sanitary_napkin, sanitary_towel, kotex\",\n \"cling_film, clingfilm, saran_wrap\",\n \"sarcenet, sarsenet\",\n \"sarcophagus\",\n \"sari, saree\",\n \"sarong\",\n \"sash, window_sash\",\n \"sash_fastener, sash_lock, window_lock\",\n \"sash_window\",\n \"satchel\",\n \"sateen\",\n \"satellite, artificial_satellite, orbiter\",\n \"satellite_receiver\",\n \"satellite_television, satellite_tv\",\n \"satellite_transmitter\",\n \"satin\",\n \"saturday_night_special\",\n \"saucepan\",\n \"saucepot\",\n \"sauna, sweat_room\",\n \"savings_bank, coin_bank, money_box, bank\",\n \"saw\",\n \"sawed-off_shotgun\",\n \"sawhorse, horse, sawbuck, buck\",\n \"sawmill\",\n \"saw_set\",\n \"sax, saxophone\",\n \"saxhorn\",\n \"scabbard\",\n \"scaffolding, staging\",\n \"scale\",\n \"scale, weighing_machine\",\n \"scaler\",\n \"scaling_ladder\",\n \"scalpel\",\n \"scanner, electronic_scanner\",\n \"scanner\",\n \"scanner, digital_scanner, image_scanner\",\n \"scantling, stud\",\n \"scarf\",\n \"scarf_joint, scarf\",\n \"scatter_rug, throw_rug\",\n \"scauper, scorper\",\n \"schmidt_telescope, schmidt_camera\",\n \"school, schoolhouse\",\n \"schoolbag\",\n \"school_bell\",\n \"school_bus\",\n \"school_ship, training_ship\",\n \"school_system\",\n \"schooner\",\n \"schooner\",\n \"scientific_instrument\",\n \"scimitar\",\n \"scintillation_counter\",\n \"scissors, pair_of_scissors\",\n \"sclerometer\",\n \"scoinson_arch, sconcheon_arch\",\n \"sconce\",\n \"sconce\",\n \"scoop\",\n \"scooter\",\n \"scoreboard\",\n \"scouring_pad\",\n \"scow\",\n \"scow\",\n \"scraper\",\n \"scratcher\",\n \"screen\",\n \"screen, cover, covert, concealment\",\n \"screen\",\n \"screen, crt_screen\",\n \"screen_door, screen\",\n \"screening\",\n \"screw\",\n \"screw, screw_propeller\",\n \"screw\",\n \"screwdriver\",\n \"screw_eye\",\n \"screw_key\",\n \"screw_thread, thread\",\n \"screwtop\",\n \"screw_wrench\",\n \"scriber, scribe, scratch_awl\",\n \"scrim\",\n \"scrimshaw\",\n \"scriptorium\",\n \"scrubber\",\n \"scrub_brush, scrubbing_brush, scrubber\",\n \"scrub_plane\",\n \"scuffer\",\n \"scuffle, scuffle_hoe, dutch_hoe\",\n \"scull\",\n \"scull\",\n \"scullery\",\n \"sculpture\",\n \"scuttle, coal_scuttle\",\n \"scyphus\",\n \"scythe\",\n \"seabag\",\n \"sea_boat\",\n \"sea_chest\",\n \"sealing_wax, seal\",\n \"sealskin\",\n \"seam\",\n \"seaplane, hydroplane\",\n \"searchlight\",\n \"searing_iron\",\n \"seat\",\n \"seat\",\n \"seat\",\n \"seat_belt, seatbelt\",\n \"secateurs\",\n \"secondary_coil, secondary_winding, secondary\",\n \"second_balcony, family_circle, upper_balcony, peanut_gallery\",\n \"second_base\",\n \"second_hand\",\n \"secretary, writing_table, escritoire, secretaire\",\n \"sectional\",\n \"security_blanket\",\n \"security_system, security_measure, security\",\n \"security_system\",\n \"sedan, saloon\",\n \"sedan, sedan_chair\",\n \"seeder\",\n \"seeker\",\n \"seersucker\",\n \"segmental_arch\",\n \"segway, segway_human_transporter, segway_ht\",\n \"seidel\",\n \"seine\",\n \"seismograph\",\n \"selector, selector_switch\",\n \"selenium_cell\",\n \"self-propelled_vehicle\",\n \"self-registering_thermometer\",\n \"self-starter\",\n \"selsyn, synchro\",\n \"selvage, selvedge\",\n \"semaphore\",\n \"semiautomatic_firearm\",\n \"semiautomatic_pistol, semiautomatic\",\n \"semiconductor_device, semiconductor_unit, semiconductor\",\n \"semi-detached_house\",\n \"semigloss\",\n \"semitrailer, semi\",\n \"sennit\",\n \"sensitometer\",\n \"sentry_box\",\n \"separate\",\n \"septic_tank\",\n \"sequence, episode\",\n \"sequencer, sequenator\",\n \"serape, sarape\",\n \"serge\",\n \"serger\",\n \"serial_port\",\n \"serpent\",\n \"serration\",\n \"server\",\n \"server, host\",\n \"service_club\",\n \"serving_cart\",\n \"serving_dish\",\n \"servo, servomechanism, servosystem\",\n \"set\",\n \"set_gun, spring_gun\",\n \"setscrew\",\n \"setscrew\",\n \"set_square\",\n \"settee\",\n \"settle, settee\",\n \"settlement_house\",\n \"seventy-eight, 78\",\n \"seven_wonders_of_the_ancient_world, seven_wonders_of_the_world\",\n \"sewage_disposal_plant, disposal_plant\",\n \"sewer, sewerage, cloaca\",\n \"sewing_basket\",\n \"sewing_kit\",\n \"sewing_machine\",\n \"sewing_needle\",\n \"sewing_room\",\n \"sextant\",\n \"sgraffito\",\n \"shackle, bond, hamper, trammel\",\n \"shackle\",\n \"shade\",\n \"shadow_box\",\n \"shaft\",\n \"shag_rug\",\n \"shaker\",\n \"shank\",\n \"shank, stem\",\n \"shantung\",\n \"shaper, shaping_machine\",\n \"shaping_tool\",\n \"sharkskin\",\n \"sharpener\",\n \"sharpie\",\n \"shaver, electric_shaver, electric_razor\",\n \"shaving_brush\",\n \"shaving_cream, shaving_soap\",\n \"shaving_foam\",\n \"shawl\",\n \"shawm\",\n \"shears\",\n \"sheath\",\n \"sheathing, overlay, overlayer\",\n \"shed\",\n \"sheep_bell\",\n \"sheepshank\",\n \"sheepskin_coat, afghan\",\n \"sheepwalk, sheeprun\",\n \"sheet, bed_sheet\",\n \"sheet_bend, becket_bend, weaver's_knot, weaver's_hitch\",\n \"sheeting\",\n \"sheet_pile, sheath_pile, sheet_piling\",\n \"sheetrock\",\n \"shelf\",\n \"shelf_bracket\",\n \"shell\",\n \"shell, case, casing\",\n \"shell, racing_shell\",\n \"shellac, shellac_varnish\",\n \"shelter\",\n \"shelter\",\n \"shelter\",\n \"sheltered_workshop\",\n \"sheraton\",\n \"shield, buckler\",\n \"shield\",\n \"shielding\",\n \"shift_key, shift\",\n \"shillelagh, shillalah\",\n \"shim\",\n \"shingle\",\n \"shin_guard, shinpad\",\n \"ship\",\n \"shipboard_system\",\n \"shipping, cargo_ships, merchant_marine, merchant_vessels\",\n \"shipping_room\",\n \"ship-towed_long-range_acoustic_detection_system\",\n \"shipwreck\",\n \"shirt\",\n \"shirt_button\",\n \"shirtdress\",\n \"shirtfront\",\n \"shirting\",\n \"shirtsleeve\",\n \"shirttail\",\n \"shirtwaist, shirtwaister\",\n \"shiv\",\n \"shock_absorber, shock, cushion\",\n \"shoe\",\n \"shoe\",\n \"shoebox\",\n \"shoehorn\",\n \"shoe_shop, shoe-shop, shoe_store\",\n \"shoetree\",\n \"shofar, shophar\",\n \"shoji\",\n \"shooting_brake\",\n \"shooting_lodge, shooting_box\",\n \"shooting_stick\",\n \"shop, store\",\n \"shop_bell\",\n \"shopping_bag\",\n \"shopping_basket\",\n \"shopping_cart\",\n \"short_circuit, short\",\n \"short_iron\",\n \"short_pants, shorts, trunks\",\n \"short_sleeve\",\n \"shortwave_diathermy_machine\",\n \"shot\",\n \"shot_glass, jigger, pony\",\n \"shotgun, scattergun\",\n \"shotgun_shell\",\n \"shot_tower\",\n \"shoulder\",\n \"shoulder_bag\",\n \"shouldered_arch\",\n \"shoulder_holster\",\n \"shoulder_pad\",\n \"shoulder_patch\",\n \"shovel\",\n \"shovel\",\n \"shovel_hat\",\n \"showboat\",\n \"shower\",\n \"shower_cap\",\n \"shower_curtain\",\n \"shower_room\",\n \"shower_stall, shower_bath\",\n \"showroom, salesroom, saleroom\",\n \"shrapnel\",\n \"shredder\",\n \"shrimper\",\n \"shrine\",\n \"shrink-wrap\",\n \"shunt\",\n \"shunt, electrical_shunt, bypass\",\n \"shunter\",\n \"shutter\",\n \"shutter\",\n \"shuttle\",\n \"shuttle\",\n \"shuttle_bus\",\n \"shuttlecock, bird, birdie, shuttle\",\n \"shuttle_helicopter\",\n \"sibley_tent\",\n \"sickbay, sick_berth\",\n \"sickbed\",\n \"sickle, reaping_hook, reap_hook\",\n \"sickroom\",\n \"sideboard\",\n \"sidecar\",\n \"side_chapel\",\n \"sidelight, running_light\",\n \"sidesaddle\",\n \"sidewalk, pavement\",\n \"sidewall\",\n \"side-wheeler\",\n \"sidewinder\",\n \"sieve, screen\",\n \"sifter\",\n \"sights\",\n \"sigmoidoscope, flexible_sigmoidoscope\",\n \"signal_box, signal_tower\",\n \"signaling_device\",\n \"signboard, sign\",\n \"silencer, muffler\",\n \"silent_butler\",\n \"silex\",\n \"silk\",\n \"silks\",\n \"silo\",\n \"silver_plate\",\n \"silverpoint\",\n \"simple_pendulum\",\n \"simulator\",\n \"single_bed\",\n \"single-breasted_jacket\",\n \"single-breasted_suit\",\n \"single_prop, single-propeller_plane\",\n \"single-reed_instrument, single-reed_woodwind\",\n \"single-rotor_helicopter\",\n \"singlestick, fencing_stick, backsword\",\n \"singlet, vest, undershirt\",\n \"siren\",\n \"sister_ship\",\n \"sitar\",\n \"sitz_bath, hip_bath\",\n \"six-pack, six_pack, sixpack\",\n \"skate\",\n \"skateboard\",\n \"skeg\",\n \"skein\",\n \"skeleton, skeletal_frame, frame, underframe\",\n \"skeleton_key\",\n \"skep\",\n \"skep\",\n \"sketch, study\",\n \"sketcher\",\n \"skew_arch\",\n \"skewer\",\n \"ski\",\n \"ski_binding, binding\",\n \"skibob\",\n \"ski_boot\",\n \"ski_cap, stocking_cap, toboggan_cap\",\n \"skidder\",\n \"skid_lid\",\n \"skiff\",\n \"ski_jump\",\n \"ski_lodge\",\n \"ski_mask\",\n \"skimmer\",\n \"ski_parka, ski_jacket\",\n \"ski-plane\",\n \"ski_pole\",\n \"ski_rack\",\n \"skirt\",\n \"skirt\",\n \"ski_tow, ski_lift, lift\",\n \"skivvies\",\n \"skullcap\",\n \"skybox\",\n \"skyhook\",\n \"skylight, fanlight\",\n \"skysail\",\n \"skyscraper\",\n \"skywalk\",\n \"slacks\",\n \"slack_suit\",\n \"slasher\",\n \"slash_pocket\",\n \"slat, spline\",\n \"slate\",\n \"slate_pencil\",\n \"slate_roof\",\n \"sled, sledge, sleigh\",\n \"sleeper\",\n \"sleeper\",\n \"sleeping_bag\",\n \"sleeping_car, sleeper, wagon-lit\",\n \"sleeve, arm\",\n \"sleeve\",\n \"sleigh_bed\",\n \"sleigh_bell, cascabel\",\n \"slice_bar\",\n \"slicer\",\n \"slicer\",\n \"slide, playground_slide, sliding_board\",\n \"slide_fastener, zip, zipper, zip_fastener\",\n \"slide_projector\",\n \"slide_rule, slipstick\",\n \"slide_valve\",\n \"sliding_door\",\n \"sliding_seat\",\n \"sliding_window\",\n \"sling, scarf_bandage, triangular_bandage\",\n \"sling\",\n \"slingback, sling\",\n \"slinger_ring\",\n \"slip_clutch, slip_friction_clutch\",\n \"slipcover\",\n \"slip-joint_pliers\",\n \"slipknot\",\n \"slip-on\",\n \"slipper, carpet_slipper\",\n \"slip_ring\",\n \"slit_lamp\",\n \"slit_trench\",\n \"sloop\",\n \"sloop_of_war\",\n \"slop_basin, slop_bowl\",\n \"slop_pail, slop_jar\",\n \"slops\",\n \"slopshop, slopseller's_shop\",\n \"slot, one-armed_bandit\",\n \"slot_machine, coin_machine\",\n \"sluice, sluiceway, penstock\",\n \"smack\",\n \"small_boat\",\n \"small_computer_system_interface, scsi\",\n \"small_ship\",\n \"small_stores\",\n \"smart_bomb\",\n \"smelling_bottle\",\n \"smocking\",\n \"smoke_bomb, smoke_grenade\",\n \"smokehouse, meat_house\",\n \"smoker, smoking_car, smoking_carriage, smoking_compartment\",\n \"smoke_screen, smokescreen\",\n \"smoking_room\",\n \"smoothbore\",\n \"smooth_plane, smoothing_plane\",\n \"snack_bar, snack_counter, buffet\",\n \"snaffle, snaffle_bit\",\n \"snap, snap_fastener, press_stud\",\n \"snap_brim\",\n \"snap-brim_hat\",\n \"snare, gin, noose\",\n \"snare_drum, snare, side_drum\",\n \"snatch_block\",\n \"snifter, brandy_snifter, brandy_glass\",\n \"sniper_rifle, precision_rifle\",\n \"snips, tinsnips\",\n \"sno-cat\",\n \"snood\",\n \"snorkel, schnorkel, schnorchel, snorkel_breather, breather\",\n \"snorkel\",\n \"snowbank, snow_bank\",\n \"snowboard\",\n \"snowmobile\",\n \"snowplow, snowplough\",\n \"snowshoe\",\n \"snowsuit\",\n \"snow_thrower, snow_blower\",\n \"snuffbox\",\n \"snuffer\",\n \"snuffers\",\n \"soapbox\",\n \"soap_dish\",\n \"soap_dispenser\",\n \"soap_pad\",\n \"soccer_ball\",\n \"sock\",\n \"socket\",\n \"socket_wrench\",\n \"socle\",\n \"soda_can\",\n \"soda_fountain\",\n \"soda_fountain\",\n \"sod_house, soddy, adobe_house\",\n \"sodium-vapor_lamp, sodium-vapour_lamp\",\n \"sofa, couch, lounge\",\n \"soffit\",\n \"softball, playground_ball\",\n \"soft_pedal\",\n \"soil_pipe\",\n \"solar_array, solar_battery, solar_panel\",\n \"solar_cell, photovoltaic_cell\",\n \"solar_dish, solar_collector, solar_furnace\",\n \"solar_heater\",\n \"solar_house\",\n \"solar_telescope\",\n \"solar_thermal_system\",\n \"soldering_iron\",\n \"solenoid\",\n \"solleret, sabaton\",\n \"sombrero\",\n \"sonic_depth_finder, fathometer\",\n \"sonogram, echogram\",\n \"sonograph\",\n \"sorter\",\n \"souk\",\n \"sound_bow\",\n \"soundbox, body\",\n \"sound_camera\",\n \"sounder\",\n \"sound_film\",\n \"sounding_board, soundboard\",\n \"sounding_rocket\",\n \"sound_recording, audio_recording, audio\",\n \"sound_spectrograph\",\n \"soup_bowl\",\n \"soup_ladle\",\n \"soupspoon, soup_spoon\",\n \"source_of_illumination\",\n \"sourdine\",\n \"soutache\",\n \"soutane\",\n \"sou'wester\",\n \"soybean_future\",\n \"space_bar\",\n \"space_capsule, capsule\",\n \"spacecraft, ballistic_capsule, space_vehicle\",\n \"space_heater\",\n \"space_helmet\",\n \"space_rocket\",\n \"space_shuttle\",\n \"space_station, space_platform, space_laboratory\",\n \"spacesuit\",\n \"spade\",\n \"spade_bit\",\n \"spaghetti_junction\",\n \"spandau\",\n \"spandex\",\n \"spandrel, spandril\",\n \"spanker\",\n \"spar\",\n \"sparge_pipe\",\n \"spark_arrester, sparker\",\n \"spark_arrester\",\n \"spark_chamber, spark_counter\",\n \"spark_coil\",\n \"spark_gap\",\n \"spark_lever\",\n \"spark_plug, sparking_plug, plug\",\n \"sparkplug_wrench\",\n \"spark_transmitter\",\n \"spat, gaiter\",\n \"spatula\",\n \"spatula\",\n \"speakerphone\",\n \"speaking_trumpet\",\n \"spear, lance, shaft\",\n \"spear, gig, fizgig, fishgig, lance\",\n \"specialty_store\",\n \"specimen_bottle\",\n \"spectacle\",\n \"spectacles, specs, eyeglasses, glasses\",\n \"spectator_pump, spectator\",\n \"spectrograph\",\n \"spectrophotometer\",\n \"spectroscope, prism_spectroscope\",\n \"speculum\",\n \"speedboat\",\n \"speed_bump\",\n \"speedometer, speed_indicator\",\n \"speed_skate, racing_skate\",\n \"spherometer\",\n \"sphygmomanometer\",\n \"spicemill\",\n \"spice_rack\",\n \"spider\",\n \"spider_web, spider's_web\",\n \"spike\",\n \"spike\",\n \"spindle\",\n \"spindle, mandrel, mandril, arbor\",\n \"spindle\",\n \"spin_dryer, spin_drier\",\n \"spinet\",\n \"spinet\",\n \"spinnaker\",\n \"spinner\",\n \"spinning_frame\",\n \"spinning_jenny\",\n \"spinning_machine\",\n \"spinning_rod\",\n \"spinning_wheel\",\n \"spiral_bandage\",\n \"spiral_ratchet_screwdriver, ratchet_screwdriver\",\n \"spiral_spring\",\n \"spirit_lamp\",\n \"spirit_stove\",\n \"spirometer\",\n \"spit\",\n \"spittoon, cuspidor\",\n \"splashboard, splasher, dashboard\",\n \"splasher\",\n \"splice, splicing\",\n \"splicer\",\n \"splint\",\n \"split_rail, fence_rail\",\n \"spode\",\n \"spoiler\",\n \"spoiler\",\n \"spoke, wheel_spoke, radius\",\n \"spokeshave\",\n \"sponge_cloth\",\n \"sponge_mop\",\n \"spoon\",\n \"spoon\",\n \"spork\",\n \"sporran\",\n \"sport_kite, stunt_kite\",\n \"sports_car, sport_car\",\n \"sports_equipment\",\n \"sports_implement\",\n \"sportswear, athletic_wear, activewear\",\n \"sport_utility, sport_utility_vehicle, s.u.v., suv\",\n \"spot\",\n \"spotlight, spot\",\n \"spot_weld, spot-weld\",\n \"spouter\",\n \"sprag\",\n \"spray_gun\",\n \"spray_paint\",\n \"spreader\",\n \"sprig\",\n \"spring\",\n \"spring_balance, spring_scale\",\n \"springboard\",\n \"sprinkler\",\n \"sprinkler_system\",\n \"sprit\",\n \"spritsail\",\n \"sprocket, sprocket_wheel\",\n \"sprocket\",\n \"spun_yarn\",\n \"spur, gad\",\n \"spur_gear, spur_wheel\",\n \"sputnik\",\n \"spy_satellite\",\n \"squad_room\",\n \"square\",\n \"square_knot\",\n \"square-rigger\",\n \"square_sail\",\n \"squash_ball\",\n \"squash_racket, squash_racquet, bat\",\n \"squawk_box, squawker, intercom_speaker\",\n \"squeegee\",\n \"squeezer\",\n \"squelch_circuit, squelch, squelcher\",\n \"squinch\",\n \"stabilizer, stabiliser\",\n \"stabilizer\",\n \"stabilizer_bar, anti-sway_bar\",\n \"stable, stalls, horse_barn\",\n \"stable_gear, saddlery, tack\",\n \"stabling\",\n \"stacks\",\n \"staddle\",\n \"stadium, bowl, arena, sports_stadium\",\n \"stage\",\n \"stagecoach, stage\",\n \"stained-glass_window\",\n \"stair-carpet\",\n \"stair-rod\",\n \"stairwell\",\n \"stake\",\n \"stall, stand, sales_booth\",\n \"stall\",\n \"stamp\",\n \"stamp_mill, stamping_mill\",\n \"stamping_machine, stamper\",\n \"stanchion\",\n \"stand\",\n \"standard\",\n \"standard_cell\",\n \"standard_transmission, stick_shift\",\n \"standing_press\",\n \"stanhope\",\n \"stanley_steamer\",\n \"staple\",\n \"staple\",\n \"staple_gun, staplegun, tacker\",\n \"stapler, stapling_machine\",\n \"starship, spaceship\",\n \"starter, starter_motor, starting_motor\",\n \"starting_gate, starting_stall\",\n \"stassano_furnace, electric-arc_furnace\",\n \"statehouse\",\n \"stately_home\",\n \"state_prison\",\n \"stateroom\",\n \"static_tube\",\n \"station\",\n \"stator, stator_coil\",\n \"statue\",\n \"stay\",\n \"staysail\",\n \"steakhouse, chophouse\",\n \"steak_knife\",\n \"stealth_aircraft\",\n \"stealth_bomber\",\n \"stealth_fighter\",\n \"steam_bath, steam_room, vapor_bath, vapour_bath\",\n \"steamboat\",\n \"steam_chest\",\n \"steam_engine\",\n \"steamer, steamship\",\n \"steamer\",\n \"steam_iron\",\n \"steam_locomotive\",\n \"steamroller, road_roller\",\n \"steam_shovel\",\n \"steam_turbine\",\n \"steam_whistle\",\n \"steel\",\n \"steel_arch_bridge\",\n \"steel_drum\",\n \"steel_mill, steelworks, steel_plant, steel_factory\",\n \"steel-wool_pad\",\n \"steelyard, lever_scale, beam_scale\",\n \"steeple, spire\",\n \"steerage\",\n \"steering_gear\",\n \"steering_linkage\",\n \"steering_system, steering_mechanism\",\n \"steering_wheel, wheel\",\n \"stele, stela\",\n \"stem-winder\",\n \"stencil\",\n \"sten_gun\",\n \"stenograph\",\n \"step, stair\",\n \"step-down_transformer\",\n \"step_stool\",\n \"step-up_transformer\",\n \"stereo, stereophony, stereo_system, stereophonic_system\",\n \"stereoscope\",\n \"stern_chaser\",\n \"sternpost\",\n \"sternwheeler\",\n \"stethoscope\",\n \"stewing_pan, stewpan\",\n \"stick\",\n \"stick\",\n \"stick, control_stick, joystick\",\n \"stick\",\n \"stile\",\n \"stiletto\",\n \"still\",\n \"stillroom, still_room\",\n \"stillson_wrench\",\n \"stilt\",\n \"stinger\",\n \"stink_bomb, stench_bomb\",\n \"stirrer\",\n \"stirrup, stirrup_iron\",\n \"stirrup_pump\",\n \"stob\",\n \"stock, gunstock\",\n \"stockade\",\n \"stockcar\",\n \"stock_car\",\n \"stockinet, stockinette\",\n \"stocking\",\n \"stock-in-trade\",\n \"stockpot\",\n \"stockroom, stock_room\",\n \"stocks\",\n \"stock_saddle, western_saddle\",\n \"stockyard\",\n \"stole\",\n \"stomacher\",\n \"stomach_pump\",\n \"stone_wall\",\n \"stoneware\",\n \"stonework\",\n \"stool\",\n \"stoop, stoep\",\n \"stop_bath, short-stop, short-stop_bath\",\n \"stopcock, cock, turncock\",\n \"stopper_knot\",\n \"stopwatch, stop_watch\",\n \"storage_battery, accumulator\",\n \"storage_cell, secondary_cell\",\n \"storage_ring\",\n \"storage_space\",\n \"storeroom, storage_room, stowage\",\n \"storm_cellar, cyclone_cellar, tornado_cellar\",\n \"storm_door\",\n \"storm_window, storm_sash\",\n \"stoup, stoop\",\n \"stoup\",\n \"stove\",\n \"stove, kitchen_stove, range, kitchen_range, cooking_stove\",\n \"stove_bolt\",\n \"stovepipe\",\n \"stovepipe_iron\",\n \"stradavarius, strad\",\n \"straight_chair, side_chair\",\n \"straightedge\",\n \"straightener\",\n \"straight_flute, straight-fluted_drill\",\n \"straight_pin\",\n \"straight_razor\",\n \"strainer\",\n \"straitjacket, straightjacket\",\n \"strap\",\n \"strap\",\n \"strap_hinge, joint_hinge\",\n \"strapless\",\n \"streamer_fly\",\n \"streamliner\",\n \"street\",\n \"street\",\n \"streetcar, tram, tramcar, trolley, trolley_car\",\n \"street_clothes\",\n \"streetlight, street_lamp\",\n \"stretcher\",\n \"stretcher\",\n \"stretch_pants\",\n \"strickle\",\n \"strickle\",\n \"stringed_instrument\",\n \"stringer\",\n \"stringer\",\n \"string_tie\",\n \"strip\",\n \"strip_lighting\",\n \"strip_mall\",\n \"stroboscope, strobe, strobe_light\",\n \"strongbox, deedbox\",\n \"stronghold, fastness\",\n \"strongroom\",\n \"strop\",\n \"structural_member\",\n \"structure, construction\",\n \"student_center\",\n \"student_lamp\",\n \"student_union\",\n \"stud_finder\",\n \"studio_apartment, studio\",\n \"studio_couch, day_bed\",\n \"study\",\n \"study_hall\",\n \"stuffing_nut, packing_nut\",\n \"stump\",\n \"stun_gun, stun_baton\",\n \"stupa, tope\",\n \"sty, pigsty, pigpen\",\n \"stylus, style\",\n \"stylus\",\n \"sub-assembly\",\n \"subcompact, subcompact_car\",\n \"submachine_gun\",\n \"submarine, pigboat, sub, u-boat\",\n \"submarine_torpedo\",\n \"submersible, submersible_warship\",\n \"submersible\",\n \"subtracter\",\n \"subway_token\",\n \"subway_train\",\n \"subwoofer\",\n \"suction_cup\",\n \"suction_pump\",\n \"sudatorium, sudatory\",\n \"suede_cloth, suede\",\n \"sugar_bowl\",\n \"sugar_refinery\",\n \"sugar_spoon, sugar_shell\",\n \"suit, suit_of_clothes\",\n \"suite, rooms\",\n \"suiting\",\n \"sulky\",\n \"summer_house\",\n \"sumo_ring\",\n \"sump\",\n \"sump_pump\",\n \"sunbonnet\",\n \"sunday_best, sunday_clothes\",\n \"sun_deck\",\n \"sundial\",\n \"sundress\",\n \"sundries\",\n \"sun_gear\",\n \"sunglass\",\n \"sunglasses, dark_glasses, shades\",\n \"sunhat, sun_hat\",\n \"sunlamp, sun_lamp, sunray_lamp, sun-ray_lamp\",\n \"sun_parlor, sun_parlour, sun_porch, sunporch, sunroom, sun_lounge, solarium\",\n \"sunroof, sunshine-roof\",\n \"sunscreen, sunblock, sun_blocker\",\n \"sunsuit\",\n \"supercharger\",\n \"supercomputer\",\n \"superconducting_supercollider\",\n \"superhighway, information_superhighway\",\n \"supermarket\",\n \"superstructure\",\n \"supertanker\",\n \"supper_club\",\n \"supplejack\",\n \"supply_chamber\",\n \"supply_closet\",\n \"support\",\n \"support\",\n \"support_column\",\n \"support_hose, support_stocking\",\n \"supporting_structure\",\n \"supporting_tower\",\n \"surcoat\",\n \"surface_gauge, surface_gage, scribing_block\",\n \"surface_lift\",\n \"surface_search_radar\",\n \"surface_ship\",\n \"surface-to-air_missile, sam\",\n \"surface-to-air_missile_system\",\n \"surfboat\",\n \"surcoat\",\n \"surgeon's_knot\",\n \"surgery\",\n \"surge_suppressor, surge_protector, spike_suppressor, spike_arrester, lightning_arrester\",\n \"surgical_dressing\",\n \"surgical_instrument\",\n \"surgical_knife\",\n \"surplice\",\n \"surrey\",\n \"surtout\",\n \"surveillance_system\",\n \"surveying_instrument, surveyor's_instrument\",\n \"surveyor's_level\",\n \"sushi_bar\",\n \"suspension, suspension_system\",\n \"suspension_bridge\",\n \"suspensory, suspensory_bandage\",\n \"sustaining_pedal, loud_pedal\",\n \"suture, surgical_seam\",\n \"swab, swob, mop\",\n \"swab\",\n \"swaddling_clothes, swaddling_bands\",\n \"swag\",\n \"swage_block\",\n \"swagger_stick\",\n \"swallow-tailed_coat, swallowtail, morning_coat\",\n \"swamp_buggy, marsh_buggy\",\n \"swan's_down\",\n \"swathe, wrapping\",\n \"swatter, flyswatter, flyswat\",\n \"sweat_bag\",\n \"sweatband\",\n \"sweater, jumper\",\n \"sweat_pants, sweatpants\",\n \"sweatshirt\",\n \"sweatshop\",\n \"sweat_suit, sweatsuit, sweats, workout_suit\",\n \"sweep, sweep_oar\",\n \"sweep_hand, sweep-second\",\n \"swimming_trunks, bathing_trunks\",\n \"swimsuit, swimwear, bathing_suit, swimming_costume, bathing_costume\",\n \"swing\",\n \"swing_door, swinging_door\",\n \"switch, electric_switch, electrical_switch\",\n \"switchblade, switchblade_knife, flick-knife, flick_knife\",\n \"switch_engine, donkey_engine\",\n \"swivel\",\n \"swivel_chair\",\n \"swizzle_stick\",\n \"sword, blade, brand, steel\",\n \"sword_cane, sword_stick\",\n \"s_wrench\",\n \"synagogue, temple, tabernacle\",\n \"synchrocyclotron\",\n \"synchroflash\",\n \"synchromesh\",\n \"synchronous_converter, rotary, rotary_converter\",\n \"synchronous_motor\",\n \"synchrotron\",\n \"synchroscope, synchronoscope, synchronizer, synchroniser\",\n \"synthesizer, synthesiser\",\n \"syringe\",\n \"system\",\n \"tabard\",\n \"tabernacle\",\n \"tabi, tabis\",\n \"tab_key, tab\",\n \"table\",\n \"table\",\n \"tablefork\",\n \"table_knife\",\n \"table_lamp\",\n \"table_saw\",\n \"tablespoon\",\n \"tablet-armed_chair\",\n \"table-tennis_table, ping-pong_table, pingpong_table\",\n \"table-tennis_racquet, table-tennis_bat, pingpong_paddle\",\n \"tabletop\",\n \"tableware\",\n \"tabor, tabour\",\n \"taboret, tabouret\",\n \"tachistoscope, t-scope\",\n \"tachograph\",\n \"tachometer, tach\",\n \"tachymeter, tacheometer\",\n \"tack\",\n \"tack_hammer\",\n \"taffeta\",\n \"taffrail\",\n \"tailgate, tailboard\",\n \"taillight, tail_lamp, rear_light, rear_lamp\",\n \"tailor-made\",\n \"tailor's_chalk\",\n \"tailpipe\",\n \"tail_rotor, anti-torque_rotor\",\n \"tailstock\",\n \"take-up\",\n \"talaria\",\n \"talcum, talcum_powder\",\n \"tam, tam-o'-shanter, tammy\",\n \"tambour\",\n \"tambour, embroidery_frame, embroidery_hoop\",\n \"tambourine\",\n \"tammy\",\n \"tamp, tamper, tamping_bar\",\n \"tampax\",\n \"tampion, tompion\",\n \"tampon\",\n \"tandoor\",\n \"tangram\",\n \"tank, storage_tank\",\n \"tank, army_tank, armored_combat_vehicle, armoured_combat_vehicle\",\n \"tankard\",\n \"tank_car, tank\",\n \"tank_destroyer\",\n \"tank_engine, tank_locomotive\",\n \"tanker_plane\",\n \"tank_shell\",\n \"tank_top\",\n \"tannoy\",\n \"tap, spigot\",\n \"tapa, tappa\",\n \"tape, tape_recording, taping\",\n \"tape, tapeline, tape_measure\",\n \"tape_deck\",\n \"tape_drive, tape_transport, transport\",\n \"tape_player\",\n \"tape_recorder, tape_machine\",\n \"taper_file\",\n \"tapestry, tapis\",\n \"tappet\",\n \"tap_wrench\",\n \"tare\",\n \"target, butt\",\n \"target_acquisition_system\",\n \"tarmacadam, tarmac, macadam\",\n \"tarpaulin, tarp\",\n \"tartan, plaid\",\n \"tasset, tasse\",\n \"tattoo\",\n \"tavern, tap_house\",\n \"tawse\",\n \"taximeter\",\n \"t-bar_lift, t-bar, alpine_lift\",\n \"tea_bag\",\n \"tea_ball\",\n \"tea_cart, teacart, tea_trolley, tea_wagon\",\n \"tea_chest\",\n \"teaching_aid\",\n \"teacup\",\n \"tea_gown\",\n \"teakettle\",\n \"tea_maker\",\n \"teapot\",\n \"teashop, teahouse, tearoom, tea_parlor, tea_parlour\",\n \"teaspoon\",\n \"tea-strainer\",\n \"tea_table\",\n \"tea_tray\",\n \"tea_urn\",\n \"tee, golf_tee\",\n \"tee_hinge, t_hinge\",\n \"telecom_hotel, telco_building\",\n \"telecommunication_system, telecom_system, telecommunication_equipment, telecom_equipment\",\n \"telegraph, telegraphy\",\n \"telegraph_key\",\n \"telemeter\",\n \"telephone, phone, telephone_set\",\n \"telephone_bell\",\n \"telephone_booth, phone_booth, call_box, telephone_box, telephone_kiosk\",\n \"telephone_cord, phone_cord\",\n \"telephone_jack, phone_jack\",\n \"telephone_line, phone_line, telephone_circuit, subscriber_line, line\",\n \"telephone_plug, phone_plug\",\n \"telephone_pole, telegraph_pole, telegraph_post\",\n \"telephone_receiver, receiver\",\n \"telephone_system, phone_system\",\n \"telephone_wire, telephone_line, telegraph_wire, telegraph_line\",\n \"telephoto_lens, zoom_lens\",\n \"teleprompter\",\n \"telescope, scope\",\n \"telescopic_sight, telescope_sight\",\n \"telethermometer\",\n \"teletypewriter, teleprinter, teletype_machine, telex, telex_machine\",\n \"television, television_system\",\n \"television_antenna, tv-antenna\",\n \"television_camera, tv_camera, camera\",\n \"television_equipment, video_equipment\",\n \"television_monitor, tv_monitor\",\n \"television_receiver, television, television_set, tv, tv_set, idiot_box, boob_tube, telly, goggle_box\",\n \"television_room, tv_room\",\n \"television_transmitter\",\n \"telpher, telfer\",\n \"telpherage, telferage\",\n \"tempera, poster_paint, poster_color, poster_colour\",\n \"temple\",\n \"temple\",\n \"temporary_hookup, patch\",\n \"tender, supply_ship\",\n \"tender, ship's_boat, pinnace, cutter\",\n \"tender\",\n \"tenement, tenement_house\",\n \"tennis_ball\",\n \"tennis_camp\",\n \"tennis_racket, tennis_racquet\",\n \"tenon\",\n \"tenor_drum, tom-tom\",\n \"tenoroon\",\n \"tenpenny_nail\",\n \"tenpin\",\n \"tensimeter\",\n \"tensiometer\",\n \"tensiometer\",\n \"tensiometer\",\n \"tent, collapsible_shelter\",\n \"tenter\",\n \"tenterhook\",\n \"tent-fly, rainfly, fly_sheet, fly, tent_flap\",\n \"tent_peg\",\n \"tepee, tipi, teepee\",\n \"terminal, pole\",\n \"terminal\",\n \"terraced_house\",\n \"terra_cotta\",\n \"terrarium\",\n \"terra_sigillata, samian_ware\",\n \"terry, terry_cloth, terrycloth\",\n \"tesla_coil\",\n \"tessera\",\n \"test_equipment\",\n \"test_rocket, research_rocket, test_instrument_vehicle\",\n \"test_room, testing_room\",\n \"testudo\",\n \"tetraskelion, tetraskele\",\n \"tetrode\",\n \"textile_machine\",\n \"textile_mill\",\n \"thatch, thatched_roof\",\n \"theater, theatre, house\",\n \"theater_curtain, theatre_curtain\",\n \"theater_light\",\n \"theodolite, transit\",\n \"theremin\",\n \"thermal_printer\",\n \"thermal_reactor\",\n \"thermocouple, thermocouple_junction\",\n \"thermoelectric_thermometer, thermel, electric_thermometer\",\n \"thermograph, thermometrograph\",\n \"thermograph\",\n \"thermohydrometer, thermogravimeter\",\n \"thermojunction\",\n \"thermometer\",\n \"thermonuclear_reactor, fusion_reactor\",\n \"thermopile\",\n \"thermos, thermos_bottle, thermos_flask\",\n \"thermostat, thermoregulator\",\n \"thigh_pad\",\n \"thill\",\n \"thimble\",\n \"thinning_shears\",\n \"third_base, third\",\n \"third_gear, third\",\n \"third_rail\",\n \"thong\",\n \"thong\",\n \"three-centered_arch, basket-handle_arch\",\n \"three-decker\",\n \"three-dimensional_radar, 3d_radar\",\n \"three-piece_suit\",\n \"three-quarter_binding\",\n \"three-way_switch, three-point_switch\",\n \"thresher, thrasher, threshing_machine\",\n \"threshing_floor\",\n \"thriftshop, second-hand_store\",\n \"throat_protector\",\n \"throne\",\n \"thrust_bearing\",\n \"thruster\",\n \"thumb\",\n \"thumbhole\",\n \"thumbscrew\",\n \"thumbstall\",\n \"thumbtack, drawing_pin, pushpin\",\n \"thunderer\",\n \"thwart, cross_thwart\",\n \"tiara\",\n \"ticking\",\n \"tickler_coil\",\n \"tie, tie_beam\",\n \"tie, railroad_tie, crosstie, sleeper\",\n \"tie_rack\",\n \"tie_rod\",\n \"tights, leotards\",\n \"tile\",\n \"tile_cutter\",\n \"tile_roof\",\n \"tiller\",\n \"tilter\",\n \"tilt-top_table, tip-top_table, tip_table\",\n \"timber\",\n \"timber\",\n \"timber_hitch\",\n \"timbrel\",\n \"time_bomb, infernal_machine\",\n \"time_capsule\",\n \"time_clock\",\n \"time-delay_measuring_instrument, time-delay_measuring_system\",\n \"time-fuse\",\n \"timepiece, timekeeper, horologe\",\n \"timer\",\n \"timer\",\n \"time-switch\",\n \"tin\",\n \"tinderbox\",\n \"tine\",\n \"tinfoil, tin_foil\",\n \"tippet\",\n \"tire_chain, snow_chain\",\n \"tire_iron, tire_tool\",\n \"titfer\",\n \"tithe_barn\",\n \"titrator\",\n \"toaster\",\n \"toaster_oven\",\n \"toasting_fork\",\n \"toastrack\",\n \"tobacco_pouch\",\n \"tobacco_shop, tobacconist_shop, tobacconist\",\n \"toboggan\",\n \"toby, toby_jug, toby_fillpot_jug\",\n \"tocsin, warning_bell\",\n \"toe\",\n \"toecap\",\n \"toehold\",\n \"toga\",\n \"toga_virilis\",\n \"toggle\",\n \"toggle_bolt\",\n \"toggle_joint\",\n \"toggle_switch, toggle, on-off_switch, on/off_switch\",\n \"togs, threads, duds\",\n \"toilet, lavatory, lav, can, john, privy, bathroom\",\n \"toilet_bag, sponge_bag\",\n \"toilet_bowl\",\n \"toilet_kit, travel_kit\",\n \"toilet_powder, bath_powder, dusting_powder\",\n \"toiletry, toilet_articles\",\n \"toilet_seat\",\n \"toilet_water, eau_de_toilette\",\n \"tokamak\",\n \"token\",\n \"tollbooth, tolbooth, tollhouse\",\n \"toll_bridge\",\n \"tollgate, tollbar\",\n \"toll_line\",\n \"tomahawk, hatchet\",\n \"tommy_gun, thompson_submachine_gun\",\n \"tomograph\",\n \"tone_arm, pickup, pickup_arm\",\n \"toner\",\n \"tongs, pair_of_tongs\",\n \"tongue\",\n \"tongue_and_groove_joint\",\n \"tongue_depressor\",\n \"tonometer\",\n \"tool\",\n \"tool_bag\",\n \"toolbox, tool_chest, tool_cabinet, tool_case\",\n \"toolshed, toolhouse\",\n \"tooth\",\n \"tooth\",\n \"toothbrush\",\n \"toothpick\",\n \"top\",\n \"top, cover\",\n \"topgallant, topgallant_mast\",\n \"topgallant, topgallant_sail\",\n \"topiary\",\n \"topknot\",\n \"topmast\",\n \"topper\",\n \"topsail\",\n \"toque\",\n \"torch\",\n \"torpedo\",\n \"torpedo\",\n \"torpedo\",\n \"torpedo_boat\",\n \"torpedo-boat_destroyer\",\n \"torpedo_tube\",\n \"torque_converter\",\n \"torque_wrench\",\n \"torture_chamber\",\n \"totem_pole\",\n \"touch_screen, touchscreen\",\n \"toupee, toupe\",\n \"touring_car, phaeton, tourer\",\n \"tourist_class, third_class\",\n \"towel\",\n \"toweling, towelling\",\n \"towel_rack, towel_horse\",\n \"towel_rail, towel_bar\",\n \"tower\",\n \"town_hall\",\n \"towpath, towing_path\",\n \"tow_truck, tow_car, wrecker\",\n \"toy\",\n \"toy_box, toy_chest\",\n \"toyshop\",\n \"trace_detector\",\n \"track, rail, rails, runway\",\n \"track\",\n \"trackball\",\n \"tracked_vehicle\",\n \"tract_house\",\n \"tract_housing\",\n \"traction_engine\",\n \"tractor\",\n \"tractor\",\n \"trail_bike, dirt_bike, scrambler\",\n \"trailer, house_trailer\",\n \"trailer\",\n \"trailer_camp, trailer_park\",\n \"trailer_truck, tractor_trailer, trucking_rig, rig, articulated_lorry, semi\",\n \"trailing_edge\",\n \"train, railroad_train\",\n \"tramline, tramway, streetcar_track\",\n \"trammel\",\n \"trampoline\",\n \"tramp_steamer, tramp\",\n \"tramway, tram, aerial_tramway, cable_tramway, ropeway\",\n \"transdermal_patch, skin_patch\",\n \"transept\",\n \"transformer\",\n \"transistor, junction_transistor, electronic_transistor\",\n \"transit_instrument\",\n \"transmission, transmission_system\",\n \"transmission_shaft\",\n \"transmitter, sender\",\n \"transom, traverse\",\n \"transom, transom_window, fanlight\",\n \"transponder\",\n \"transporter\",\n \"transporter, car_transporter\",\n \"transport_ship\",\n \"trap\",\n \"trap_door\",\n \"trapeze\",\n \"trave, traverse, crossbeam, crosspiece\",\n \"travel_iron\",\n \"trawl, dragnet, trawl_net\",\n \"trawl, trawl_line, spiller, setline, trotline\",\n \"trawler, dragger\",\n \"tray\",\n \"tray_cloth\",\n \"tread\",\n \"tread\",\n \"treadmill, treadwheel, tread-wheel\",\n \"treadmill\",\n \"treasure_chest\",\n \"treasure_ship\",\n \"treenail, trenail, trunnel\",\n \"trefoil_arch\",\n \"trellis, treillage\",\n \"trench\",\n \"trench_coat\",\n \"trench_knife\",\n \"trepan\",\n \"trepan, trephine\",\n \"trestle\",\n \"trestle\",\n \"trestle_bridge\",\n \"trestle_table\",\n \"trestlework\",\n \"trews\",\n \"trial_balloon\",\n \"triangle\",\n \"triangle\",\n \"triclinium\",\n \"triclinium\",\n \"tricorn, tricorne\",\n \"tricot\",\n \"tricycle, trike, velocipede\",\n \"trident\",\n \"trigger\",\n \"trimaran\",\n \"trimmer\",\n \"trimmer_arch\",\n \"triode\",\n \"tripod\",\n \"triptych\",\n \"trip_wire\",\n \"trireme\",\n \"triskelion, triskele\",\n \"triumphal_arch\",\n \"trivet\",\n \"trivet\",\n \"troika\",\n \"troll\",\n \"trolleybus, trolley_coach, trackless_trolley\",\n \"trombone\",\n \"troop_carrier, troop_transport\",\n \"troopship\",\n \"trophy_case\",\n \"trough\",\n \"trouser\",\n \"trouser_cuff\",\n \"trouser_press, pants_presser\",\n \"trouser, pant\",\n \"trousseau\",\n \"trowel\",\n \"truck, motortruck\",\n \"trumpet_arch\",\n \"truncheon, nightstick, baton, billy, billystick, billy_club\",\n \"trundle_bed, trundle, truckle_bed, truckle\",\n \"trunk\",\n \"trunk_hose\",\n \"trunk_lid\",\n \"trunk_line\",\n \"truss\",\n \"truss_bridge\",\n \"try_square\",\n \"t-square\",\n \"tub, vat\",\n \"tube, vacuum_tube, thermionic_vacuum_tube, thermionic_tube, electron_tube, thermionic_valve\",\n \"tuck_box\",\n \"tucker\",\n \"tucker-bag\",\n \"tuck_shop\",\n \"tudor_arch, four-centered_arch\",\n \"tudung\",\n \"tugboat, tug, towboat, tower\",\n \"tulle\",\n \"tumble-dryer, tumble_drier\",\n \"tumbler\",\n \"tumbrel, tumbril\",\n \"tun\",\n \"tunic\",\n \"tuning_fork\",\n \"tupik, tupek, sealskin_tent\",\n \"turban\",\n \"turbine\",\n \"turbogenerator\",\n \"tureen\",\n \"turkish_bath\",\n \"turkish_towel, terry_towel\",\n \"turk's_head\",\n \"turnbuckle\",\n \"turner, food_turner\",\n \"turnery\",\n \"turnpike\",\n \"turnspit\",\n \"turnstile\",\n \"turntable\",\n \"turntable, lazy_susan\",\n \"turret\",\n \"turret_clock\",\n \"turtleneck, turtle, polo-neck\",\n \"tweed\",\n \"tweeter\",\n \"twenty-two, .22\",\n \"twenty-two_pistol\",\n \"twenty-two_rifle\",\n \"twill\",\n \"twill, twill_weave\",\n \"twin_bed\",\n \"twinjet\",\n \"twist_bit, twist_drill\",\n \"two-by-four\",\n \"two-man_tent\",\n \"two-piece, two-piece_suit, lounge_suit\",\n \"typesetting_machine\",\n \"typewriter\",\n \"typewriter_carriage\",\n \"typewriter_keyboard\",\n \"tyrolean, tirolean\",\n \"uke, ukulele\",\n \"ulster\",\n \"ultracentrifuge\",\n \"ultramicroscope, dark-field_microscope\",\n \"ultrasuede\",\n \"ultraviolet_lamp, ultraviolet_source\",\n \"umbrella\",\n \"umbrella_tent\",\n \"undercarriage\",\n \"undercoat, underseal\",\n \"undergarment, unmentionable\",\n \"underpants\",\n \"underwear, underclothes, underclothing\",\n \"undies\",\n \"uneven_parallel_bars, uneven_bars\",\n \"unicycle, monocycle\",\n \"uniform\",\n \"universal_joint, universal\",\n \"university\",\n \"upholstery\",\n \"upholstery_material\",\n \"upholstery_needle\",\n \"uplift\",\n \"upper_berth, upper\",\n \"upright, upright_piano\",\n \"upset, swage\",\n \"upstairs\",\n \"urceole\",\n \"urn\",\n \"urn\",\n \"used-car, secondhand_car\",\n \"utensil\",\n \"uzi\",\n \"vacation_home\",\n \"vacuum, vacuum_cleaner\",\n \"vacuum_chamber\",\n \"vacuum_flask, vacuum_bottle\",\n \"vacuum_gauge, vacuum_gage\",\n \"valenciennes, valenciennes_lace\",\n \"valise\",\n \"valve\",\n \"valve\",\n \"valve-in-head_engine\",\n \"vambrace, lower_cannon\",\n \"van\",\n \"van, caravan\",\n \"vane\",\n \"vaporizer, vaporiser\",\n \"variable-pitch_propeller\",\n \"variometer\",\n \"varnish\",\n \"vase\",\n \"vault\",\n \"vault, bank_vault\",\n \"vaulting_horse, long_horse, buck\",\n \"vehicle\",\n \"velcro\",\n \"velocipede\",\n \"velour, velours\",\n \"velvet\",\n \"velveteen\",\n \"vending_machine\",\n \"veneer, veneering\",\n \"venetian_blind\",\n \"venn_diagram, venn's_diagram\",\n \"ventilation, ventilation_system, ventilating_system\",\n \"ventilation_shaft\",\n \"ventilator\",\n \"veranda, verandah, gallery\",\n \"verdigris\",\n \"vernier_caliper, vernier_micrometer\",\n \"vernier_scale, vernier\",\n \"vertical_file\",\n \"vertical_stabilizer, vertical_stabiliser, vertical_fin, tail_fin, tailfin\",\n \"vertical_tail\",\n \"very_pistol, verey_pistol\",\n \"vessel, watercraft\",\n \"vessel\",\n \"vest, waistcoat\",\n \"vestiture\",\n \"vestment\",\n \"vest_pocket\",\n \"vestry, sacristy\",\n \"viaduct\",\n \"vibraphone, vibraharp, vibes\",\n \"vibrator\",\n \"vibrator\",\n \"victrola\",\n \"vicuna\",\n \"videocassette\",\n \"videocassette_recorder, vcr\",\n \"videodisk, videodisc, dvd\",\n \"video_recording, video\",\n \"videotape\",\n \"videotape\",\n \"vigil_light, vigil_candle\",\n \"villa\",\n \"villa\",\n \"villa\",\n \"viol\",\n \"viola\",\n \"viola_da_braccio\",\n \"viola_da_gamba, gamba, bass_viol\",\n \"viola_d'amore\",\n \"violin, fiddle\",\n \"virginal, pair_of_virginals\",\n \"viscometer, viscosimeter\",\n \"viscose_rayon, viscose\",\n \"vise, bench_vise\",\n \"visor, vizor\",\n \"visual_display_unit, vdu\",\n \"vivarium\",\n \"viyella\",\n \"voile\",\n \"volleyball\",\n \"volleyball_net\",\n \"voltage_regulator\",\n \"voltaic_cell, galvanic_cell, primary_cell\",\n \"voltaic_pile, pile, galvanic_pile\",\n \"voltmeter\",\n \"vomitory\",\n \"von_neumann_machine\",\n \"voting_booth\",\n \"voting_machine\",\n \"voussoir\",\n \"vox_angelica, voix_celeste\",\n \"vox_humana\",\n \"waders\",\n \"wading_pool\",\n \"waffle_iron\",\n \"wagon, waggon\",\n \"wagon, coaster_wagon\",\n \"wagon_tire\",\n \"wagon_wheel\",\n \"wain\",\n \"wainscot, wainscoting, wainscotting\",\n \"wainscoting, wainscotting\",\n \"waist_pack, belt_bag\",\n \"walker, baby-walker, go-cart\",\n \"walker, zimmer, zimmer_frame\",\n \"walker\",\n \"walkie-talkie, walky-talky\",\n \"walk-in\",\n \"walking_shoe\",\n \"walking_stick\",\n \"walkman\",\n \"walk-up_apartment, walk-up\",\n \"wall\",\n \"wall\",\n \"wall_clock\",\n \"wallet, billfold, notecase, pocketbook\",\n \"wall_tent\",\n \"wall_unit\",\n \"wand\",\n \"wankel_engine, wankel_rotary_engine, epitrochoidal_engine\",\n \"ward, hospital_ward\",\n \"wardrobe, closet, press\",\n \"wardroom\",\n \"warehouse, storage_warehouse\",\n \"warming_pan\",\n \"war_paint\",\n \"warplane, military_plane\",\n \"war_room\",\n \"warship, war_vessel, combat_ship\",\n \"wash\",\n \"wash-and-wear\",\n \"washbasin, handbasin, washbowl, lavabo, wash-hand_basin\",\n \"washboard, splashboard\",\n \"washboard\",\n \"washer, automatic_washer, washing_machine\",\n \"washer\",\n \"washhouse\",\n \"washroom\",\n \"washstand, wash-hand_stand\",\n \"washtub\",\n \"wastepaper_basket, waste-paper_basket, wastebasket, waste_basket, circular_file\",\n \"watch, ticker\",\n \"watch_cap\",\n \"watch_case\",\n \"watch_glass\",\n \"watchtower\",\n \"water-base_paint\",\n \"water_bed\",\n \"water_bottle\",\n \"water_butt\",\n \"water_cart\",\n \"water_chute\",\n \"water_closet, closet, w.c., loo\",\n \"watercolor, water-color, watercolour, water-colour\",\n \"water-cooled_reactor\",\n \"water_cooler\",\n \"water_faucet, water_tap, tap, hydrant\",\n \"water_filter\",\n \"water_gauge, water_gage, water_glass\",\n \"water_glass\",\n \"water_hazard\",\n \"water_heater, hot-water_heater, hot-water_tank\",\n \"watering_can, watering_pot\",\n \"watering_cart\",\n \"water_jacket\",\n \"water_jug\",\n \"water_jump\",\n \"water_level\",\n \"water_meter\",\n \"water_mill\",\n \"waterproof\",\n \"waterproofing\",\n \"water_pump\",\n \"water_scooter, sea_scooter, scooter\",\n \"water_ski\",\n \"waterspout\",\n \"water_tower\",\n \"water_wagon, water_waggon\",\n \"waterwheel, water_wheel\",\n \"waterwheel, water_wheel\",\n \"water_wings\",\n \"waterworks\",\n \"wattmeter\",\n \"waxwork, wax_figure\",\n \"ways, shipway, slipway\",\n \"weapon, arm, weapon_system\",\n \"weaponry, arms, implements_of_war, weapons_system, munition\",\n \"weapons_carrier\",\n \"weathercock\",\n \"weatherglass\",\n \"weather_satellite, meteorological_satellite\",\n \"weather_ship\",\n \"weathervane, weather_vane, vane, wind_vane\",\n \"web, entanglement\",\n \"web\",\n \"webbing\",\n \"webcam\",\n \"wedge\",\n \"wedge\",\n \"wedgie\",\n \"wedgwood\",\n \"weeder, weed-whacker\",\n \"weeds, widow's_weeds\",\n \"weekender\",\n \"weighbridge\",\n \"weight, free_weight, exercising_weight\",\n \"weir\",\n \"weir\",\n \"welcome_wagon\",\n \"weld\",\n \"welder's_mask\",\n \"weldment\",\n \"well\",\n \"wellhead\",\n \"welt\",\n \"weston_cell, cadmium_cell\",\n \"wet_bar\",\n \"wet-bulb_thermometer\",\n \"wet_cell\",\n \"wet_fly\",\n \"wet_suit\",\n \"whaleboat\",\n \"whaler, whaling_ship\",\n \"whaling_gun\",\n \"wheel\",\n \"wheel\",\n \"wheel_and_axle\",\n \"wheelchair\",\n \"wheeled_vehicle\",\n \"wheelwork\",\n \"wherry\",\n \"wherry, norfolk_wherry\",\n \"whetstone\",\n \"whiffletree, whippletree, swingletree\",\n \"whip\",\n \"whipcord\",\n \"whipping_post\",\n \"whipstitch, whipping, whipstitching\",\n \"whirler\",\n \"whisk, whisk_broom\",\n \"whisk\",\n \"whiskey_bottle\",\n \"whiskey_jug\",\n \"whispering_gallery, whispering_dome\",\n \"whistle\",\n \"whistle\",\n \"white\",\n \"white_goods\",\n \"whitewash\",\n \"whorehouse, brothel, bordello, bagnio, house_of_prostitution, house_of_ill_repute, bawdyhouse, cathouse, sporting_house\",\n \"wick, taper\",\n \"wicker, wickerwork, caning\",\n \"wicker_basket\",\n \"wicket, hoop\",\n \"wicket\",\n \"wickiup, wikiup\",\n \"wide-angle_lens, fisheye_lens\",\n \"widebody_aircraft, wide-body_aircraft, wide-body, twin-aisle_airplane\",\n \"wide_wale\",\n \"widow's_walk\",\n \"wiffle, wiffle_ball\",\n \"wig\",\n \"wigwam\",\n \"wilton, wilton_carpet\",\n \"wimple\",\n \"wincey\",\n \"winceyette\",\n \"winch, windlass\",\n \"winchester\",\n \"windbreak, shelterbelt\",\n \"winder, key\",\n \"wind_instrument, wind\",\n \"windjammer\",\n \"windmill, aerogenerator, wind_generator\",\n \"windmill\",\n \"window\",\n \"window\",\n \"window_blind\",\n \"window_box\",\n \"window_envelope\",\n \"window_frame\",\n \"window_screen\",\n \"window_seat\",\n \"window_shade\",\n \"windowsill\",\n \"windshield, windscreen\",\n \"windshield_wiper, windscreen_wiper, wiper, wiper_blade\",\n \"windsor_chair\",\n \"windsor_knot\",\n \"windsor_tie\",\n \"wind_tee\",\n \"wind_tunnel\",\n \"wind_turbine\",\n \"wine_bar\",\n \"wine_bottle\",\n \"wine_bucket, wine_cooler\",\n \"wine_cask, wine_barrel\",\n \"wineglass\",\n \"winepress\",\n \"winery, wine_maker\",\n \"wineskin\",\n \"wing\",\n \"wing_chair\",\n \"wing_nut, wing-nut, wing_screw, butterfly_nut, thumbnut\",\n \"wing_tip\",\n \"wing_tip\",\n \"winker, blinker, blinder\",\n \"wiper, wiper_arm, contact_arm\",\n \"wiper_motor\",\n \"wire\",\n \"wire, conducting_wire\",\n \"wire_cloth\",\n \"wire_cutter\",\n \"wire_gauge, wire_gage\",\n \"wireless_local_area_network, wlan, wireless_fidelity, wifi\",\n \"wire_matrix_printer, wire_printer, stylus_printer\",\n \"wire_recorder\",\n \"wire_stripper\",\n \"wirework, grillwork\",\n \"wiring\",\n \"wishing_cap\",\n \"witness_box, witness_stand\",\n \"wok\",\n \"woman's_clothing\",\n \"wood\",\n \"woodcarving\",\n \"wood_chisel\",\n \"woodenware\",\n \"wooden_spoon\",\n \"woodscrew\",\n \"woodshed\",\n \"wood_vise, woodworking_vise, shoulder_vise\",\n \"woodwind, woodwind_instrument, wood\",\n \"woof, weft, filling, pick\",\n \"woofer\",\n \"wool, woolen, woollen\",\n \"workbasket, workbox, workbag\",\n \"workbench, work_bench, bench\",\n \"work-clothing, work-clothes\",\n \"workhouse\",\n \"workhouse\",\n \"workpiece\",\n \"workroom\",\n \"works, workings\",\n \"work-shirt\",\n \"workstation\",\n \"worktable, work_table\",\n \"workwear\",\n \"world_wide_web, www, web\",\n \"worm_fence, snake_fence, snake-rail_fence, virginia_fence\",\n \"worm_gear\",\n \"worm_wheel\",\n \"worsted\",\n \"worsted, worsted_yarn\",\n \"wrap, wrapper\",\n \"wraparound\",\n \"wrapping, wrap, wrapper\",\n \"wreck\",\n \"wrench, spanner\",\n \"wrestling_mat\",\n \"wringer\",\n \"wrist_pad\",\n \"wrist_pin, gudgeon_pin\",\n \"wristwatch, wrist_watch\",\n \"writing_arm\",\n \"writing_desk\",\n \"writing_desk\",\n \"writing_implement\",\n \"xerographic_printer\",\n \"xerox, xerographic_copier, xerox_machine\",\n \"x-ray_film\",\n \"x-ray_machine\",\n \"x-ray_tube\",\n \"yacht, racing_yacht\",\n \"yacht_chair\",\n \"yagi, yagi_aerial\",\n \"yard\",\n \"yard\",\n \"yardarm\",\n \"yard_marker\",\n \"yardstick, yard_measure\",\n \"yarmulke, yarmulka, yarmelke\",\n \"yashmak, yashmac\",\n \"yataghan\",\n \"yawl, dandy\",\n \"yawl\",\n \"yoke\",\n \"yoke\",\n \"yoke, coupling\",\n \"yurt\",\n \"zamboni\",\n \"zero\",\n \"ziggurat, zikkurat, zikurat\",\n \"zill\",\n \"zip_gun\",\n \"zither, cither, zithern\",\n \"zoot_suit\",\n \"shading\",\n \"grain\",\n \"wood_grain, woodgrain, woodiness\",\n \"graining, woodgraining\",\n \"marbleization, marbleisation, marbleizing, marbleising\",\n \"light, lightness\",\n \"aura, aureole, halo, nimbus, glory, gloriole\",\n \"sunniness\",\n \"glint\",\n \"opalescence, iridescence\",\n \"polish, gloss, glossiness, burnish\",\n \"primary_color_for_pigments, primary_colour_for_pigments\",\n \"primary_color_for_light, primary_colour_for_light\",\n \"colorlessness, colourlessness, achromatism, achromaticity\",\n \"mottle\",\n \"achromia\",\n \"shade, tint, tincture, tone\",\n \"chromatic_color, chromatic_colour, spectral_color, spectral_colour\",\n \"black, blackness, inkiness\",\n \"coal_black, ebony, jet_black, pitch_black, sable, soot_black\",\n \"alabaster\",\n \"bone, ivory, pearl, off-white\",\n \"gray, grayness, grey, greyness\",\n \"ash_grey, ash_gray, silver, silver_grey, silver_gray\",\n \"charcoal, charcoal_grey, charcoal_gray, oxford_grey, oxford_gray\",\n \"sanguine\",\n \"turkey_red, alizarine_red\",\n \"crimson, ruby, deep_red\",\n \"dark_red\",\n \"claret\",\n \"fuschia\",\n \"maroon\",\n \"orange, orangeness\",\n \"reddish_orange\",\n \"yellow, yellowness\",\n \"gamboge, lemon, lemon_yellow, maize\",\n \"pale_yellow, straw, wheat\",\n \"green, greenness, viridity\",\n \"greenishness\",\n \"sea_green\",\n \"sage_green\",\n \"bottle_green\",\n \"emerald\",\n \"olive_green, olive-green\",\n \"jade_green, jade\",\n \"blue, blueness\",\n \"azure, cerulean, sapphire, lazuline, sky-blue\",\n \"steel_blue\",\n \"greenish_blue, aqua, aquamarine, turquoise, cobalt_blue, peacock_blue\",\n \"purplish_blue, royal_blue\",\n \"purple, purpleness\",\n \"tyrian_purple\",\n \"indigo\",\n \"lavender\",\n \"reddish_purple, royal_purple\",\n \"pink\",\n \"carnation\",\n \"rose, rosiness\",\n \"chestnut\",\n \"chocolate, coffee, deep_brown, umber, burnt_umber\",\n \"light_brown\",\n \"tan, topaz\",\n \"beige, ecru\",\n \"reddish_brown, sepia, burnt_sienna, venetian_red, mahogany\",\n \"brick_red\",\n \"copper, copper_color\",\n \"indian_red\",\n \"puce\",\n \"olive\",\n \"ultramarine\",\n \"complementary_color, complementary\",\n \"pigmentation\",\n \"complexion, skin_color, skin_colour\",\n \"ruddiness, rosiness\",\n \"nonsolid_color, nonsolid_colour, dithered_color, dithered_colour\",\n \"aposematic_coloration, warning_coloration\",\n \"cryptic_coloration\",\n \"ring\",\n \"center_of_curvature, centre_of_curvature\",\n \"cadaver, corpse, stiff, clay, remains\",\n \"mandibular_notch\",\n \"rib\",\n \"skin, tegument, cutis\",\n \"skin_graft\",\n \"epidermal_cell\",\n \"melanocyte\",\n \"prickle_cell\",\n \"columnar_cell, columnar_epithelial_cell\",\n \"spongioblast\",\n \"squamous_cell\",\n \"amyloid_plaque, amyloid_protein_plaque\",\n \"dental_plaque, bacterial_plaque\",\n \"macule, macula\",\n \"freckle, lentigo\",\n \"bouffant\",\n \"sausage_curl\",\n \"forelock\",\n \"spit_curl, kiss_curl\",\n \"pigtail\",\n \"pageboy\",\n \"pompadour\",\n \"thatch\",\n \"soup-strainer, toothbrush\",\n \"mustachio, moustachio, handle-bars\",\n \"walrus_mustache, walrus_moustache\",\n \"stubble\",\n \"vandyke_beard, vandyke\",\n \"soul_patch, attilio\",\n \"esophageal_smear\",\n \"paraduodenal_smear, duodenal_smear\",\n \"specimen\",\n \"punctum\",\n \"glenoid_fossa, glenoid_cavity\",\n \"diastema\",\n \"marrow, bone_marrow\",\n \"mouth, oral_cavity, oral_fissure, rima_oris\",\n \"canthus\",\n \"milk\",\n \"mother's_milk\",\n \"colostrum, foremilk\",\n \"vein, vena, venous_blood_vessel\",\n \"ganglion_cell, gangliocyte\",\n \"x_chromosome\",\n \"embryonic_cell, formative_cell\",\n \"myeloblast\",\n \"sideroblast\",\n \"osteocyte\",\n \"megalocyte, macrocyte\",\n \"leukocyte, leucocyte, white_blood_cell, white_cell, white_blood_corpuscle, white_corpuscle, wbc\",\n \"histiocyte\",\n \"fixed_phagocyte\",\n \"lymphocyte, lymph_cell\",\n \"monoblast\",\n \"neutrophil, neutrophile\",\n \"microphage\",\n \"sickle_cell\",\n \"siderocyte\",\n \"spherocyte\",\n \"ootid\",\n \"oocyte\",\n \"spermatid\",\n \"leydig_cell, leydig's_cell\",\n \"striated_muscle_cell, striated_muscle_fiber\",\n \"smooth_muscle_cell\",\n \"ranvier's_nodes, nodes_of_ranvier\",\n \"neuroglia, glia\",\n \"astrocyte\",\n \"protoplasmic_astrocyte\",\n \"oligodendrocyte\",\n \"proprioceptor\",\n \"dendrite\",\n \"sensory_fiber, afferent_fiber\",\n \"subarachnoid_space\",\n \"cerebral_cortex, cerebral_mantle, pallium, cortex\",\n \"renal_cortex\",\n \"prepuce, foreskin\",\n \"head, caput\",\n \"scalp\",\n \"frontal_eminence\",\n \"suture, sutura, fibrous_joint\",\n \"foramen_magnum\",\n \"esophagogastric_junction, oesophagogastric_junction\",\n \"heel\",\n \"cuticle\",\n \"hangnail, agnail\",\n \"exoskeleton\",\n \"abdominal_wall\",\n \"lemon\",\n \"coordinate_axis\",\n \"landscape\",\n \"medium\",\n \"vehicle\",\n \"paper\",\n \"channel, transmission_channel\",\n \"film, cinema, celluloid\",\n \"silver_screen\",\n \"free_press\",\n \"press, public_press\",\n \"print_media\",\n \"storage_medium, data-storage_medium\",\n \"magnetic_storage_medium, magnetic_medium, magnetic_storage\",\n \"journalism, news_media\",\n \"fleet_street\",\n \"photojournalism\",\n \"news_photography\",\n \"rotogravure\",\n \"newspaper, paper\",\n \"daily\",\n \"gazette\",\n \"school_newspaper, school_paper\",\n \"tabloid, rag, sheet\",\n \"yellow_journalism, tabloid, tab\",\n \"telecommunication, telecom\",\n \"telephone, telephony\",\n \"voice_mail, voicemail\",\n \"call, phone_call, telephone_call\",\n \"call-back\",\n \"collect_call\",\n \"call_forwarding\",\n \"call-in\",\n \"call_waiting\",\n \"crank_call\",\n \"local_call\",\n \"long_distance, long-distance_call, trunk_call\",\n \"toll_call\",\n \"wake-up_call\",\n \"three-way_calling\",\n \"telegraphy\",\n \"cable, cablegram, overseas_telegram\",\n \"wireless\",\n \"radiotelegraph, radiotelegraphy, wireless_telegraphy\",\n \"radiotelephone, radiotelephony, wireless_telephone\",\n \"broadcasting\",\n \"rediffusion\",\n \"multiplex\",\n \"radio, radiocommunication, wireless\",\n \"television, telecasting, tv, video\",\n \"cable_television, cable\",\n \"high-definition_television, hdtv\",\n \"reception\",\n \"signal_detection, detection\",\n \"hakham\",\n \"web_site, website, internet_site, site\",\n \"chat_room, chatroom\",\n \"portal_site, portal\",\n \"jotter\",\n \"breviary\",\n \"wordbook\",\n \"desk_dictionary, collegiate_dictionary\",\n \"reckoner, ready_reckoner\",\n \"document, written_document, papers\",\n \"album, record_album\",\n \"concept_album\",\n \"rock_opera\",\n \"tribute_album, benefit_album\",\n \"magazine, mag\",\n \"colour_supplement\",\n \"comic_book\",\n \"news_magazine\",\n \"pulp, pulp_magazine\",\n \"slick, slick_magazine, glossy\",\n \"trade_magazine\",\n \"movie, film, picture, moving_picture, moving-picture_show, motion_picture, motion-picture_show, picture_show, pic, flick\",\n \"outtake\",\n \"shoot-'em-up\",\n \"spaghetti_western\",\n \"encyclical, encyclical_letter\",\n \"crossword_puzzle, crossword\",\n \"sign\",\n \"street_sign\",\n \"traffic_light, traffic_signal, stoplight\",\n \"swastika, hakenkreuz\",\n \"concert\",\n \"artwork, art, graphics, nontextual_matter\",\n \"lobe\",\n \"book_jacket, dust_cover, dust_jacket, dust_wrapper\",\n \"cairn\",\n \"three-day_event\",\n \"comfort_food\",\n \"comestible, edible, eatable, pabulum, victual, victuals\",\n \"tuck\",\n \"course\",\n \"dainty, delicacy, goody, kickshaw, treat\",\n \"dish\",\n \"fast_food\",\n \"finger_food\",\n \"ingesta\",\n \"kosher\",\n \"fare\",\n \"diet\",\n \"diet\",\n \"dietary\",\n \"balanced_diet\",\n \"bland_diet, ulcer_diet\",\n \"clear_liquid_diet\",\n \"diabetic_diet\",\n \"dietary_supplement\",\n \"carbohydrate_loading, carbo_loading\",\n \"fad_diet\",\n \"gluten-free_diet\",\n \"high-protein_diet\",\n \"high-vitamin_diet, vitamin-deficiency_diet\",\n \"light_diet\",\n \"liquid_diet\",\n \"low-calorie_diet\",\n \"low-fat_diet\",\n \"low-sodium_diet, low-salt_diet, salt-free_diet\",\n \"macrobiotic_diet\",\n \"reducing_diet, obesity_diet\",\n \"soft_diet, pap, spoon_food\",\n \"vegetarianism\",\n \"menu\",\n \"chow, chuck, eats, grub\",\n \"board, table\",\n \"mess\",\n \"ration\",\n \"field_ration\",\n \"k_ration\",\n \"c-ration\",\n \"foodstuff, food_product\",\n \"starches\",\n \"breadstuff\",\n \"coloring, colouring, food_coloring, food_colouring, food_color, food_colour\",\n \"concentrate\",\n \"tomato_concentrate\",\n \"meal\",\n \"kibble\",\n \"cornmeal, indian_meal\",\n \"farina\",\n \"matzo_meal, matzoh_meal, matzah_meal\",\n \"oatmeal, rolled_oats\",\n \"pea_flour\",\n \"roughage, fiber\",\n \"bran\",\n \"flour\",\n \"plain_flour\",\n \"wheat_flour\",\n \"whole_wheat_flour, graham_flour, graham, whole_meal_flour\",\n \"soybean_meal, soybean_flour, soy_flour\",\n \"semolina\",\n \"corn_gluten_feed\",\n \"nutriment, nourishment, nutrition, sustenance, aliment, alimentation, victuals\",\n \"commissariat, provisions, provender, viands, victuals\",\n \"larder\",\n \"frozen_food, frozen_foods\",\n \"canned_food, canned_foods, canned_goods, tinned_goods\",\n \"canned_meat, tinned_meat\",\n \"spam\",\n \"dehydrated_food, dehydrated_foods\",\n \"square_meal\",\n \"meal, repast\",\n \"potluck\",\n \"refection\",\n \"refreshment\",\n \"breakfast\",\n \"continental_breakfast, petit_dejeuner\",\n \"brunch\",\n \"lunch, luncheon, tiffin, dejeuner\",\n \"business_lunch\",\n \"high_tea\",\n \"tea, afternoon_tea, teatime\",\n \"dinner\",\n \"supper\",\n \"buffet\",\n \"picnic\",\n \"cookout\",\n \"barbecue, barbeque\",\n \"clambake\",\n \"fish_fry\",\n \"bite, collation, snack\",\n \"nosh\",\n \"nosh-up\",\n \"ploughman's_lunch\",\n \"coffee_break, tea_break\",\n \"banquet, feast, spread\",\n \"entree, main_course\",\n \"piece_de_resistance\",\n \"plate\",\n \"adobo\",\n \"side_dish, side_order, entremets\",\n \"special\",\n \"casserole\",\n \"chicken_casserole\",\n \"chicken_cacciatore, chicken_cacciatora, hunter's_chicken\",\n \"antipasto\",\n \"appetizer, appetiser, starter\",\n \"canape\",\n \"cocktail\",\n \"fruit_cocktail\",\n \"crab_cocktail\",\n \"shrimp_cocktail\",\n \"hors_d'oeuvre\",\n \"relish\",\n \"dip\",\n \"bean_dip\",\n \"cheese_dip\",\n \"clam_dip\",\n \"guacamole\",\n \"soup\",\n \"soup_du_jour\",\n \"alphabet_soup\",\n \"consomme\",\n \"madrilene\",\n \"bisque\",\n \"borsch, borsh, borscht, borsht, borshch, bortsch\",\n \"broth\",\n \"barley_water\",\n \"bouillon\",\n \"beef_broth, beef_stock\",\n \"chicken_broth, chicken_stock\",\n \"broth, stock\",\n \"stock_cube\",\n \"chicken_soup\",\n \"cock-a-leekie, cocky-leeky\",\n \"gazpacho\",\n \"gumbo\",\n \"julienne\",\n \"marmite\",\n \"mock_turtle_soup\",\n \"mulligatawny\",\n \"oxtail_soup\",\n \"pea_soup\",\n \"pepper_pot, philadelphia_pepper_pot\",\n \"petite_marmite, minestrone, vegetable_soup\",\n \"potage, pottage\",\n \"pottage\",\n \"turtle_soup, green_turtle_soup\",\n \"eggdrop_soup\",\n \"chowder\",\n \"corn_chowder\",\n \"clam_chowder\",\n \"manhattan_clam_chowder\",\n \"new_england_clam_chowder\",\n \"fish_chowder\",\n \"won_ton, wonton, wonton_soup\",\n \"split-pea_soup\",\n \"green_pea_soup, potage_st._germain\",\n \"lentil_soup\",\n \"scotch_broth\",\n \"vichyssoise\",\n \"stew\",\n \"bigos\",\n \"brunswick_stew\",\n \"burgoo\",\n \"burgoo\",\n \"olla_podrida, spanish_burgoo\",\n \"mulligan_stew, mulligan, irish_burgoo\",\n \"purloo, chicken_purloo, poilu\",\n \"goulash, hungarian_goulash, gulyas\",\n \"hotchpotch\",\n \"hot_pot, hotpot\",\n \"beef_goulash\",\n \"pork-and-veal_goulash\",\n \"porkholt\",\n \"irish_stew\",\n \"oyster_stew\",\n \"lobster_stew\",\n \"lobscouse, lobscuse, scouse\",\n \"fish_stew\",\n \"bouillabaisse\",\n \"matelote\",\n \"paella\",\n \"fricassee\",\n \"chicken_stew\",\n \"turkey_stew\",\n \"beef_stew\",\n \"ragout\",\n \"ratatouille\",\n \"salmi\",\n \"pot-au-feu\",\n \"slumgullion\",\n \"smorgasbord\",\n \"viand\",\n \"ready-mix\",\n \"brownie_mix\",\n \"cake_mix\",\n \"lemonade_mix\",\n \"self-rising_flour, self-raising_flour\",\n \"choice_morsel, tidbit, titbit\",\n \"savory, savoury\",\n \"calf's-foot_jelly\",\n \"caramel, caramelized_sugar\",\n \"lump_sugar\",\n \"cane_sugar\",\n \"castor_sugar, caster_sugar\",\n \"powdered_sugar\",\n \"granulated_sugar\",\n \"icing_sugar\",\n \"corn_sugar\",\n \"brown_sugar\",\n \"demerara, demerara_sugar\",\n \"sweet, confection\",\n \"confectionery\",\n \"confiture\",\n \"sweetmeat\",\n \"candy, confect\",\n \"candy_bar\",\n \"carob_bar\",\n \"hardbake\",\n \"hard_candy\",\n \"barley-sugar, barley_candy\",\n \"brandyball\",\n \"jawbreaker\",\n \"lemon_drop\",\n \"sourball\",\n \"patty\",\n \"peppermint_patty\",\n \"bonbon\",\n \"brittle, toffee, toffy\",\n \"peanut_brittle\",\n \"chewing_gum, gum\",\n \"gum_ball\",\n \"bubble_gum\",\n \"butterscotch\",\n \"candied_fruit, succade, crystallized_fruit\",\n \"candied_apple, candy_apple, taffy_apple, caramel_apple, toffee_apple\",\n \"crystallized_ginger\",\n \"grapefruit_peel\",\n \"lemon_peel\",\n \"orange_peel\",\n \"candied_citrus_peel\",\n \"candy_cane\",\n \"candy_corn\",\n \"caramel\",\n \"center, centre\",\n \"comfit\",\n \"cotton_candy, spun_sugar, candyfloss\",\n \"dragee\",\n \"dragee\",\n \"fondant\",\n \"fudge\",\n \"chocolate_fudge\",\n \"divinity, divinity_fudge\",\n \"penuche, penoche, panoche, panocha\",\n \"gumdrop\",\n \"jujube\",\n \"honey_crisp\",\n \"mint, mint_candy\",\n \"horehound\",\n \"peppermint, peppermint_candy\",\n \"jelly_bean, jelly_egg\",\n \"kiss, candy_kiss\",\n \"molasses_kiss\",\n \"meringue_kiss\",\n \"chocolate_kiss\",\n \"licorice, liquorice\",\n \"life_saver\",\n \"lollipop, sucker, all-day_sucker\",\n \"lozenge\",\n \"cachou\",\n \"cough_drop, troche, pastille, pastil\",\n \"marshmallow\",\n \"marzipan, marchpane\",\n \"nougat\",\n \"nougat_bar\",\n \"nut_bar\",\n \"peanut_bar\",\n \"popcorn_ball\",\n \"praline\",\n \"rock_candy\",\n \"rock_candy, rock\",\n \"sugar_candy\",\n \"sugarplum\",\n \"taffy\",\n \"molasses_taffy\",\n \"truffle, chocolate_truffle\",\n \"turkish_delight\",\n \"dessert, sweet, afters\",\n \"ambrosia, nectar\",\n \"ambrosia\",\n \"baked_alaska\",\n \"blancmange\",\n \"charlotte\",\n \"compote, fruit_compote\",\n \"dumpling\",\n \"flan\",\n \"frozen_dessert\",\n \"junket\",\n \"mousse\",\n \"mousse\",\n \"pavlova\",\n \"peach_melba\",\n \"whip\",\n \"prune_whip\",\n \"pudding\",\n \"pudding, pud\",\n \"syllabub, sillabub\",\n \"tiramisu\",\n \"trifle\",\n \"tipsy_cake\",\n \"jello, jell-o\",\n \"apple_dumpling\",\n \"ice, frappe\",\n \"water_ice, sorbet\",\n \"ice_cream, icecream\",\n \"ice-cream_cone\",\n \"chocolate_ice_cream\",\n \"neapolitan_ice_cream\",\n \"peach_ice_cream\",\n \"sherbert, sherbet\",\n \"strawberry_ice_cream\",\n \"tutti-frutti\",\n \"vanilla_ice_cream\",\n \"ice_lolly, lolly, lollipop, popsicle\",\n \"ice_milk\",\n \"frozen_yogurt\",\n \"snowball\",\n \"snowball\",\n \"parfait\",\n \"ice-cream_sundae, sundae\",\n \"split\",\n \"banana_split\",\n \"frozen_pudding\",\n \"frozen_custard, soft_ice_cream\",\n \"pudding\",\n \"flummery\",\n \"fish_mousse\",\n \"chicken_mousse\",\n \"chocolate_mousse\",\n \"plum_pudding, christmas_pudding\",\n \"carrot_pudding\",\n \"corn_pudding\",\n \"steamed_pudding\",\n \"duff, plum_duff\",\n \"vanilla_pudding\",\n \"chocolate_pudding\",\n \"brown_betty\",\n \"nesselrode, nesselrode_pudding\",\n \"pease_pudding\",\n \"custard\",\n \"creme_caramel\",\n \"creme_anglais\",\n \"creme_brulee\",\n \"fruit_custard\",\n \"tapioca\",\n \"tapioca_pudding\",\n \"roly-poly, roly-poly_pudding\",\n \"suet_pudding\",\n \"bavarian_cream\",\n \"maraschino, maraschino_cherry\",\n \"nonpareil\",\n \"zabaglione, sabayon\",\n \"garnish\",\n \"pastry, pastry_dough\",\n \"turnover\",\n \"apple_turnover\",\n \"knish\",\n \"pirogi, piroshki, pirozhki\",\n \"samosa\",\n \"timbale\",\n \"puff_paste, pate_feuillete\",\n \"phyllo\",\n \"puff_batter, pouf_paste, pate_a_choux\",\n \"ice-cream_cake, icebox_cake\",\n \"doughnut, donut, sinker\",\n \"fish_cake, fish_ball\",\n \"fish_stick, fish_finger\",\n \"conserve, preserve, conserves, preserves\",\n \"apple_butter\",\n \"chowchow\",\n \"jam\",\n \"lemon_curd, lemon_cheese\",\n \"strawberry_jam, strawberry_preserves\",\n \"jelly\",\n \"apple_jelly\",\n \"crabapple_jelly\",\n \"grape_jelly\",\n \"marmalade\",\n \"orange_marmalade\",\n \"gelatin, jelly\",\n \"gelatin_dessert\",\n \"buffalo_wing\",\n \"barbecued_wing\",\n \"mess\",\n \"mince\",\n \"puree\",\n \"barbecue, barbeque\",\n \"biryani, biriani\",\n \"escalope_de_veau_orloff\",\n \"saute\",\n \"patty, cake\",\n \"veal_parmesan, veal_parmigiana\",\n \"veal_cordon_bleu\",\n \"margarine, margarin, oleo, oleomargarine, marge\",\n \"mincemeat\",\n \"stuffing, dressing\",\n \"turkey_stuffing\",\n \"oyster_stuffing, oyster_dressing\",\n \"forcemeat, farce\",\n \"bread, breadstuff, staff_of_life\",\n \"anadama_bread\",\n \"bap\",\n \"barmbrack\",\n \"breadstick, bread-stick\",\n \"grissino\",\n \"brown_bread, boston_brown_bread\",\n \"bun, roll\",\n \"tea_bread\",\n \"caraway_seed_bread\",\n \"challah, hallah\",\n \"cinnamon_bread\",\n \"cracked-wheat_bread\",\n \"cracker\",\n \"crouton\",\n \"dark_bread, whole_wheat_bread, whole_meal_bread, brown_bread\",\n \"english_muffin\",\n \"flatbread\",\n \"garlic_bread\",\n \"gluten_bread\",\n \"graham_bread\",\n \"host\",\n \"flatbrod\",\n \"bannock\",\n \"chapatti, chapati\",\n \"pita, pocket_bread\",\n \"loaf_of_bread, loaf\",\n \"french_loaf\",\n \"matzo, matzoh, matzah, unleavened_bread\",\n \"nan, naan\",\n \"onion_bread\",\n \"raisin_bread\",\n \"quick_bread\",\n \"banana_bread\",\n \"date_bread\",\n \"date-nut_bread\",\n \"nut_bread\",\n \"oatcake\",\n \"irish_soda_bread\",\n \"skillet_bread, fry_bread\",\n \"rye_bread\",\n \"black_bread, pumpernickel\",\n \"jewish_rye_bread, jewish_rye\",\n \"limpa\",\n \"swedish_rye_bread, swedish_rye\",\n \"salt-rising_bread\",\n \"simnel\",\n \"sour_bread, sourdough_bread\",\n \"toast\",\n \"wafer\",\n \"white_bread, light_bread\",\n \"baguet, baguette\",\n \"french_bread\",\n \"italian_bread\",\n \"cornbread\",\n \"corn_cake\",\n \"skillet_corn_bread\",\n \"ashcake, ash_cake, corn_tash\",\n \"hoecake\",\n \"cornpone, pone\",\n \"corn_dab, corn_dodger, dodger\",\n \"hush_puppy, hushpuppy\",\n \"johnnycake, johnny_cake, journey_cake\",\n \"shawnee_cake\",\n \"spoon_bread, batter_bread\",\n \"cinnamon_toast\",\n \"orange_toast\",\n \"melba_toast\",\n \"zwieback, rusk, brussels_biscuit, twice-baked_bread\",\n \"frankfurter_bun, hotdog_bun\",\n \"hamburger_bun, hamburger_roll\",\n \"muffin, gem\",\n \"bran_muffin\",\n \"corn_muffin\",\n \"yorkshire_pudding\",\n \"popover\",\n \"scone\",\n \"drop_scone, griddlecake, scotch_pancake\",\n \"cross_bun, hot_cross_bun\",\n \"brioche\",\n \"crescent_roll, croissant\",\n \"hard_roll, vienna_roll\",\n \"soft_roll\",\n \"kaiser_roll\",\n \"parker_house_roll\",\n \"clover-leaf_roll\",\n \"onion_roll\",\n \"bialy, bialystoker\",\n \"sweet_roll, coffee_roll\",\n \"bear_claw, bear_paw\",\n \"cinnamon_roll, cinnamon_bun, cinnamon_snail\",\n \"honey_bun, sticky_bun, caramel_bun, schnecken\",\n \"pinwheel_roll\",\n \"danish, danish_pastry\",\n \"bagel, beigel\",\n \"onion_bagel\",\n \"biscuit\",\n \"rolled_biscuit\",\n \"baking-powder_biscuit\",\n \"buttermilk_biscuit, soda_biscuit\",\n \"shortcake\",\n \"hardtack, pilot_biscuit, pilot_bread, sea_biscuit, ship_biscuit\",\n \"saltine\",\n \"soda_cracker\",\n \"oyster_cracker\",\n \"water_biscuit\",\n \"graham_cracker\",\n \"pretzel\",\n \"soft_pretzel\",\n \"sandwich\",\n \"sandwich_plate\",\n \"butty\",\n \"ham_sandwich\",\n \"chicken_sandwich\",\n \"club_sandwich, three-decker, triple-decker\",\n \"open-face_sandwich, open_sandwich\",\n \"hamburger, beefburger, burger\",\n \"cheeseburger\",\n \"tunaburger\",\n \"hotdog, hot_dog, red_hot\",\n \"sloppy_joe\",\n \"bomber, grinder, hero, hero_sandwich, hoagie, hoagy, cuban_sandwich, italian_sandwich, poor_boy, sub, submarine, submarine_sandwich, torpedo, wedge, zep\",\n \"gyro\",\n \"bacon-lettuce-tomato_sandwich, blt\",\n \"reuben\",\n \"western, western_sandwich\",\n \"wrap\",\n \"spaghetti\",\n \"hasty_pudding\",\n \"gruel\",\n \"congee, jook\",\n \"skilly\",\n \"edible_fruit\",\n \"vegetable, veggie, veg\",\n \"julienne, julienne_vegetable\",\n \"raw_vegetable, rabbit_food\",\n \"crudites\",\n \"celery_stick\",\n \"legume\",\n \"pulse\",\n \"potherb\",\n \"greens, green, leafy_vegetable\",\n \"chop-suey_greens\",\n \"bean_curd, tofu\",\n \"solanaceous_vegetable\",\n \"root_vegetable\",\n \"potato, white_potato, irish_potato, murphy, spud, tater\",\n \"baked_potato\",\n \"french_fries, french-fried_potatoes, fries, chips\",\n \"home_fries, home-fried_potatoes\",\n \"jacket_potato\",\n \"mashed_potato\",\n \"potato_skin, potato_peel, potato_peelings\",\n \"uruguay_potato\",\n \"yam\",\n \"sweet_potato\",\n \"yam\",\n \"snack_food\",\n \"chip, crisp, potato_chip, saratoga_chip\",\n \"corn_chip\",\n \"tortilla_chip\",\n \"nacho\",\n \"eggplant, aubergine, mad_apple\",\n \"pieplant, rhubarb\",\n \"cruciferous_vegetable\",\n \"mustard, mustard_greens, leaf_mustard, indian_mustard\",\n \"cabbage, chou\",\n \"kale, kail, cole\",\n \"collards, collard_greens\",\n \"chinese_cabbage, celery_cabbage, chinese_celery\",\n \"bok_choy, bok_choi\",\n \"head_cabbage\",\n \"red_cabbage\",\n \"savoy_cabbage, savoy\",\n \"broccoli\",\n \"cauliflower\",\n \"brussels_sprouts\",\n \"broccoli_rabe, broccoli_raab\",\n \"squash\",\n \"summer_squash\",\n \"yellow_squash\",\n \"crookneck, crookneck_squash, summer_crookneck\",\n \"zucchini, courgette\",\n \"marrow, vegetable_marrow\",\n \"cocozelle\",\n \"pattypan_squash\",\n \"spaghetti_squash\",\n \"winter_squash\",\n \"acorn_squash\",\n \"butternut_squash\",\n \"hubbard_squash\",\n \"turban_squash\",\n \"buttercup_squash\",\n \"cushaw\",\n \"winter_crookneck_squash\",\n \"cucumber, cuke\",\n \"gherkin\",\n \"artichoke, globe_artichoke\",\n \"artichoke_heart\",\n \"jerusalem_artichoke, sunchoke\",\n \"asparagus\",\n \"bamboo_shoot\",\n \"sprout\",\n \"bean_sprout\",\n \"alfalfa_sprout\",\n \"beet, beetroot\",\n \"beet_green\",\n \"sugar_beet\",\n \"mangel-wurzel\",\n \"chard, swiss_chard, spinach_beet, leaf_beet\",\n \"pepper\",\n \"sweet_pepper\",\n \"bell_pepper\",\n \"green_pepper\",\n \"globe_pepper\",\n \"pimento, pimiento\",\n \"hot_pepper\",\n \"chili, chili_pepper, chilli, chilly, chile\",\n \"jalapeno, jalapeno_pepper\",\n \"chipotle\",\n \"cayenne, cayenne_pepper\",\n \"tabasco, red_pepper\",\n \"onion\",\n \"bermuda_onion\",\n \"green_onion, spring_onion, scallion\",\n \"vidalia_onion\",\n \"spanish_onion\",\n \"purple_onion, red_onion\",\n \"leek\",\n \"shallot\",\n \"salad_green, salad_greens\",\n \"lettuce\",\n \"butterhead_lettuce\",\n \"buttercrunch\",\n \"bibb_lettuce\",\n \"boston_lettuce\",\n \"crisphead_lettuce, iceberg_lettuce, iceberg\",\n \"cos, cos_lettuce, romaine, romaine_lettuce\",\n \"leaf_lettuce, loose-leaf_lettuce\",\n \"celtuce\",\n \"bean, edible_bean\",\n \"goa_bean\",\n \"lentil\",\n \"pea\",\n \"green_pea, garden_pea\",\n \"marrowfat_pea\",\n \"snow_pea, sugar_pea\",\n \"sugar_snap_pea\",\n \"split-pea\",\n \"chickpea, garbanzo\",\n \"cajan_pea, pigeon_pea, dahl\",\n \"field_pea\",\n \"mushy_peas\",\n \"black-eyed_pea, cowpea\",\n \"common_bean\",\n \"kidney_bean\",\n \"navy_bean, pea_bean, white_bean\",\n \"pinto_bean\",\n \"frijole\",\n \"black_bean, turtle_bean\",\n \"fresh_bean\",\n \"flageolet, haricot\",\n \"green_bean\",\n \"snap_bean, snap\",\n \"string_bean\",\n \"kentucky_wonder, kentucky_wonder_bean\",\n \"scarlet_runner, scarlet_runner_bean, runner_bean, english_runner_bean\",\n \"haricot_vert, haricots_verts, french_bean\",\n \"wax_bean, yellow_bean\",\n \"shell_bean\",\n \"lima_bean\",\n \"fordhooks\",\n \"sieva_bean, butter_bean, butterbean, civet_bean\",\n \"fava_bean, broad_bean\",\n \"soy, soybean, soya, soya_bean\",\n \"green_soybean\",\n \"field_soybean\",\n \"cardoon\",\n \"carrot\",\n \"carrot_stick\",\n \"celery\",\n \"pascal_celery, paschal_celery\",\n \"celeriac, celery_root\",\n \"chicory, curly_endive\",\n \"radicchio\",\n \"coffee_substitute\",\n \"chicory, chicory_root\",\n \"postum\",\n \"chicory_escarole, endive, escarole\",\n \"belgian_endive, french_endive, witloof\",\n \"corn, edible_corn\",\n \"sweet_corn, green_corn\",\n \"hominy\",\n \"lye_hominy\",\n \"pearl_hominy\",\n \"popcorn\",\n \"cress\",\n \"watercress\",\n \"garden_cress\",\n \"winter_cress\",\n \"dandelion_green\",\n \"gumbo, okra\",\n \"kohlrabi, turnip_cabbage\",\n \"lamb's-quarter, pigweed, wild_spinach\",\n \"wild_spinach\",\n \"tomato\",\n \"beefsteak_tomato\",\n \"cherry_tomato\",\n \"plum_tomato\",\n \"tomatillo, husk_tomato, mexican_husk_tomato\",\n \"mushroom\",\n \"stuffed_mushroom\",\n \"salsify\",\n \"oyster_plant, vegetable_oyster\",\n \"scorzonera, black_salsify\",\n \"parsnip\",\n \"pumpkin\",\n \"radish\",\n \"turnip\",\n \"white_turnip\",\n \"rutabaga, swede, swedish_turnip, yellow_turnip\",\n \"turnip_greens\",\n \"sorrel, common_sorrel\",\n \"french_sorrel\",\n \"spinach\",\n \"taro, taro_root, cocoyam, dasheen, edda\",\n \"truffle, earthnut\",\n \"edible_nut\",\n \"bunya_bunya\",\n \"peanut, earthnut, goober, goober_pea, groundnut, monkey_nut\",\n \"freestone\",\n \"cling, clingstone\",\n \"windfall\",\n \"apple\",\n \"crab_apple, crabapple\",\n \"eating_apple, dessert_apple\",\n \"baldwin\",\n \"cortland\",\n \"cox's_orange_pippin\",\n \"delicious\",\n \"golden_delicious, yellow_delicious\",\n \"red_delicious\",\n \"empire\",\n \"grimes'_golden\",\n \"jonathan\",\n \"mcintosh\",\n \"macoun\",\n \"northern_spy\",\n \"pearmain\",\n \"pippin\",\n \"prima\",\n \"stayman\",\n \"winesap\",\n \"stayman_winesap\",\n \"cooking_apple\",\n \"bramley's_seedling\",\n \"granny_smith\",\n \"lane's_prince_albert\",\n \"newtown_wonder\",\n \"rome_beauty\",\n \"berry\",\n \"bilberry, whortleberry, european_blueberry\",\n \"huckleberry\",\n \"blueberry\",\n \"wintergreen, boxberry, checkerberry, teaberry, spiceberry\",\n \"cranberry\",\n \"lingonberry, mountain_cranberry, cowberry, lowbush_cranberry\",\n \"currant\",\n \"gooseberry\",\n \"black_currant\",\n \"red_currant\",\n \"blackberry\",\n \"boysenberry\",\n \"dewberry\",\n \"loganberry\",\n \"raspberry\",\n \"saskatoon, serviceberry, shadberry, juneberry\",\n \"strawberry\",\n \"sugarberry, hackberry\",\n \"persimmon\",\n \"acerola, barbados_cherry, surinam_cherry, west_indian_cherry\",\n \"carambola, star_fruit\",\n \"ceriman, monstera\",\n \"carissa_plum, natal_plum\",\n \"citrus, citrus_fruit, citrous_fruit\",\n \"orange\",\n \"temple_orange\",\n \"mandarin, mandarin_orange\",\n \"clementine\",\n \"satsuma\",\n \"tangerine\",\n \"tangelo, ugli, ugli_fruit\",\n \"bitter_orange, seville_orange, sour_orange\",\n \"sweet_orange\",\n \"jaffa_orange\",\n \"navel_orange\",\n \"valencia_orange\",\n \"kumquat\",\n \"lemon\",\n \"lime\",\n \"key_lime\",\n \"grapefruit\",\n \"pomelo, shaddock\",\n \"citrange\",\n \"citron\",\n \"almond\",\n \"jordan_almond\",\n \"apricot\",\n \"peach\",\n \"nectarine\",\n \"pitahaya\",\n \"plum\",\n \"damson, damson_plum\",\n \"greengage, greengage_plum\",\n \"beach_plum\",\n \"sloe\",\n \"victoria_plum\",\n \"dried_fruit\",\n \"dried_apricot\",\n \"prune\",\n \"raisin\",\n \"seedless_raisin, sultana\",\n \"seeded_raisin\",\n \"currant\",\n \"fig\",\n \"pineapple, ananas\",\n \"anchovy_pear, river_pear\",\n \"banana\",\n \"passion_fruit\",\n \"granadilla\",\n \"sweet_calabash\",\n \"bell_apple, sweet_cup, water_lemon, yellow_granadilla\",\n \"breadfruit\",\n \"jackfruit, jak, jack\",\n \"cacao_bean, cocoa_bean\",\n \"cocoa\",\n \"canistel, eggfruit\",\n \"melon\",\n \"melon_ball\",\n \"muskmelon, sweet_melon\",\n \"cantaloup, cantaloupe\",\n \"winter_melon\",\n \"honeydew, honeydew_melon\",\n \"persian_melon\",\n \"net_melon, netted_melon, nutmeg_melon\",\n \"casaba, casaba_melon\",\n \"watermelon\",\n \"cherry\",\n \"sweet_cherry, black_cherry\",\n \"bing_cherry\",\n \"heart_cherry, oxheart, oxheart_cherry\",\n \"blackheart, blackheart_cherry\",\n \"capulin, mexican_black_cherry\",\n \"sour_cherry\",\n \"amarelle\",\n \"morello\",\n \"cocoa_plum, coco_plum, icaco\",\n \"gherkin\",\n \"grape\",\n \"fox_grape\",\n \"concord_grape\",\n \"catawba\",\n \"muscadine, bullace_grape\",\n \"scuppernong\",\n \"slipskin_grape\",\n \"vinifera_grape\",\n \"emperor\",\n \"muscat, muscatel, muscat_grape\",\n \"ribier\",\n \"sultana\",\n \"tokay\",\n \"flame_tokay\",\n \"thompson_seedless\",\n \"custard_apple\",\n \"cherimoya, cherimolla\",\n \"soursop, guanabana\",\n \"sweetsop, annon, sugar_apple\",\n \"ilama\",\n \"pond_apple\",\n \"papaw, pawpaw\",\n \"papaya\",\n \"kai_apple\",\n \"ketembilla, kitembilla, kitambilla\",\n \"ackee, akee\",\n \"durian\",\n \"feijoa, pineapple_guava\",\n \"genip, spanish_lime\",\n \"genipap, genipap_fruit\",\n \"kiwi, kiwi_fruit, chinese_gooseberry\",\n \"loquat, japanese_plum\",\n \"mangosteen\",\n \"mango\",\n \"sapodilla, sapodilla_plum, sapota\",\n \"sapote, mammee, marmalade_plum\",\n \"tamarind, tamarindo\",\n \"avocado, alligator_pear, avocado_pear, aguacate\",\n \"date\",\n \"elderberry\",\n \"guava\",\n \"mombin\",\n \"hog_plum, yellow_mombin\",\n \"hog_plum, wild_plum\",\n \"jaboticaba\",\n \"jujube, chinese_date, chinese_jujube\",\n \"litchi, litchi_nut, litchee, lichi, leechee, lichee, lychee\",\n \"longanberry, dragon's_eye\",\n \"mamey, mammee, mammee_apple\",\n \"marang\",\n \"medlar\",\n \"medlar\",\n \"mulberry\",\n \"olive\",\n \"black_olive, ripe_olive\",\n \"green_olive\",\n \"pear\",\n \"bosc\",\n \"anjou\",\n \"bartlett, bartlett_pear\",\n \"seckel, seckel_pear\",\n \"plantain\",\n \"plumcot\",\n \"pomegranate\",\n \"prickly_pear\",\n \"barbados_gooseberry, blade_apple\",\n \"quandong, quandang, quantong, native_peach\",\n \"quandong_nut\",\n \"quince\",\n \"rambutan, rambotan\",\n \"pulasan, pulassan\",\n \"rose_apple\",\n \"sorb, sorb_apple\",\n \"sour_gourd, monkey_bread\",\n \"edible_seed\",\n \"pumpkin_seed\",\n \"betel_nut, areca_nut\",\n \"beechnut\",\n \"walnut\",\n \"black_walnut\",\n \"english_walnut\",\n \"brazil_nut, brazil\",\n \"butternut\",\n \"souari_nut\",\n \"cashew, cashew_nut\",\n \"chestnut\",\n \"chincapin, chinkapin, chinquapin\",\n \"hazelnut, filbert, cobnut, cob\",\n \"coconut, cocoanut\",\n \"coconut_milk, coconut_water\",\n \"grugru_nut\",\n \"hickory_nut\",\n \"cola_extract\",\n \"macadamia_nut\",\n \"pecan\",\n \"pine_nut, pignolia, pinon_nut\",\n \"pistachio, pistachio_nut\",\n \"sunflower_seed\",\n \"anchovy_paste\",\n \"rollmops\",\n \"feed, provender\",\n \"cattle_cake\",\n \"creep_feed\",\n \"fodder\",\n \"feed_grain\",\n \"eatage, forage, pasture, pasturage, grass\",\n \"silage, ensilage\",\n \"oil_cake\",\n \"oil_meal\",\n \"alfalfa\",\n \"broad_bean, horse_bean\",\n \"hay\",\n \"timothy\",\n \"stover\",\n \"grain, food_grain, cereal\",\n \"grist\",\n \"groats\",\n \"millet\",\n \"barley, barleycorn\",\n \"pearl_barley\",\n \"buckwheat\",\n \"bulgur, bulghur, bulgur_wheat\",\n \"wheat, wheat_berry\",\n \"cracked_wheat\",\n \"stodge\",\n \"wheat_germ\",\n \"oat\",\n \"rice\",\n \"brown_rice\",\n \"white_rice, polished_rice\",\n \"wild_rice, indian_rice\",\n \"paddy\",\n \"slop, slops, swill, pigswill, pigwash\",\n \"mash\",\n \"chicken_feed, scratch\",\n \"cud, rechewed_food\",\n \"bird_feed, bird_food, birdseed\",\n \"petfood, pet-food, pet_food\",\n \"dog_food\",\n \"cat_food\",\n \"canary_seed\",\n \"salad\",\n \"tossed_salad\",\n \"green_salad\",\n \"caesar_salad\",\n \"salmagundi\",\n \"salad_nicoise\",\n \"combination_salad\",\n \"chef's_salad\",\n \"potato_salad\",\n \"pasta_salad\",\n \"macaroni_salad\",\n \"fruit_salad\",\n \"waldorf_salad\",\n \"crab_louis\",\n \"herring_salad\",\n \"tuna_fish_salad, tuna_salad\",\n \"chicken_salad\",\n \"coleslaw, slaw\",\n \"aspic\",\n \"molded_salad\",\n \"tabbouleh, tabooli\",\n \"ingredient, fixings\",\n \"flavorer, flavourer, flavoring, flavouring, seasoner, seasoning\",\n \"bouillon_cube\",\n \"condiment\",\n \"herb\",\n \"fines_herbes\",\n \"spice\",\n \"spearmint_oil\",\n \"lemon_oil\",\n \"wintergreen_oil, oil_of_wintergreen\",\n \"salt, table_salt, common_salt\",\n \"celery_salt\",\n \"onion_salt\",\n \"seasoned_salt\",\n \"sour_salt\",\n \"five_spice_powder\",\n \"allspice\",\n \"cinnamon\",\n \"stick_cinnamon\",\n \"clove\",\n \"cumin, cumin_seed\",\n \"fennel\",\n \"ginger, gingerroot\",\n \"ginger, powdered_ginger\",\n \"mace\",\n \"nutmeg\",\n \"pepper, peppercorn\",\n \"black_pepper\",\n \"white_pepper\",\n \"sassafras\",\n \"basil, sweet_basil\",\n \"bay_leaf\",\n \"borage\",\n \"hyssop\",\n \"caraway\",\n \"chervil\",\n \"chives\",\n \"comfrey, healing_herb\",\n \"coriander, chinese_parsley, cilantro\",\n \"coriander, coriander_seed\",\n \"costmary\",\n \"fennel, common_fennel\",\n \"fennel, florence_fennel, finocchio\",\n \"fennel_seed\",\n \"fenugreek, fenugreek_seed\",\n \"garlic, ail\",\n \"clove, garlic_clove\",\n \"garlic_chive\",\n \"lemon_balm\",\n \"lovage\",\n \"marjoram, oregano\",\n \"mint\",\n \"mustard_seed\",\n \"mustard, table_mustard\",\n \"chinese_mustard\",\n \"nasturtium\",\n \"parsley\",\n \"salad_burnet\",\n \"rosemary\",\n \"rue\",\n \"sage\",\n \"clary_sage\",\n \"savory, savoury\",\n \"summer_savory, summer_savoury\",\n \"winter_savory, winter_savoury\",\n \"sweet_woodruff, waldmeister\",\n \"sweet_cicely\",\n \"tarragon, estragon\",\n \"thyme\",\n \"turmeric\",\n \"caper\",\n \"catsup, ketchup, cetchup, tomato_ketchup\",\n \"cardamom, cardamon, cardamum\",\n \"cayenne, cayenne_pepper, red_pepper\",\n \"chili_powder\",\n \"chili_sauce\",\n \"chutney, indian_relish\",\n \"steak_sauce\",\n \"taco_sauce\",\n \"salsa\",\n \"mint_sauce\",\n \"cranberry_sauce\",\n \"curry_powder\",\n \"curry\",\n \"lamb_curry\",\n \"duck_sauce, hoisin_sauce\",\n \"horseradish\",\n \"marinade\",\n \"paprika\",\n \"spanish_paprika\",\n \"pickle\",\n \"dill_pickle\",\n \"bread_and_butter_pickle\",\n \"pickle_relish\",\n \"piccalilli\",\n \"sweet_pickle\",\n \"applesauce, apple_sauce\",\n \"soy_sauce, soy\",\n \"tabasco, tabasco_sauce\",\n \"tomato_paste\",\n \"angelica\",\n \"angelica\",\n \"almond_extract\",\n \"anise, aniseed, anise_seed\",\n \"chinese_anise, star_anise, star_aniseed\",\n \"juniper_berries\",\n \"saffron\",\n \"sesame_seed, benniseed\",\n \"caraway_seed\",\n \"poppy_seed\",\n \"dill, dill_weed\",\n \"dill_seed\",\n \"celery_seed\",\n \"lemon_extract\",\n \"monosodium_glutamate, msg\",\n \"vanilla_bean\",\n \"vinegar, acetum\",\n \"cider_vinegar\",\n \"wine_vinegar\",\n \"sauce\",\n \"anchovy_sauce\",\n \"hot_sauce\",\n \"hard_sauce\",\n \"horseradish_sauce, sauce_albert\",\n \"bolognese_pasta_sauce\",\n \"carbonara\",\n \"tomato_sauce\",\n \"tartare_sauce, tartar_sauce\",\n \"wine_sauce\",\n \"marchand_de_vin, mushroom_wine_sauce\",\n \"bread_sauce\",\n \"plum_sauce\",\n \"peach_sauce\",\n \"apricot_sauce\",\n \"pesto\",\n \"ravigote, ravigotte\",\n \"remoulade_sauce\",\n \"dressing, salad_dressing\",\n \"sauce_louis\",\n \"bleu_cheese_dressing, blue_cheese_dressing\",\n \"blue_cheese_dressing, roquefort_dressing\",\n \"french_dressing, vinaigrette, sauce_vinaigrette\",\n \"lorenzo_dressing\",\n \"anchovy_dressing\",\n \"italian_dressing\",\n \"half-and-half_dressing\",\n \"mayonnaise, mayo\",\n \"green_mayonnaise, sauce_verte\",\n \"aioli, aioli_sauce, garlic_sauce\",\n \"russian_dressing, russian_mayonnaise\",\n \"salad_cream\",\n \"thousand_island_dressing\",\n \"barbecue_sauce\",\n \"hollandaise\",\n \"bearnaise\",\n \"bercy, bercy_butter\",\n \"bordelaise\",\n \"bourguignon, bourguignon_sauce, burgundy_sauce\",\n \"brown_sauce, sauce_espagnole\",\n \"espagnole, sauce_espagnole\",\n \"chinese_brown_sauce, brown_sauce\",\n \"blanc\",\n \"cheese_sauce\",\n \"chocolate_sauce, chocolate_syrup\",\n \"hot-fudge_sauce, fudge_sauce\",\n \"cocktail_sauce, seafood_sauce\",\n \"colbert, colbert_butter\",\n \"white_sauce, bechamel_sauce, bechamel\",\n \"cream_sauce\",\n \"mornay_sauce\",\n \"demiglace, demi-glaze\",\n \"gravy, pan_gravy\",\n \"gravy\",\n \"spaghetti_sauce, pasta_sauce\",\n \"marinara\",\n \"mole\",\n \"hunter's_sauce, sauce_chausseur\",\n \"mushroom_sauce\",\n \"mustard_sauce\",\n \"nantua, shrimp_sauce\",\n \"hungarian_sauce, paprika_sauce\",\n \"pepper_sauce, poivrade\",\n \"roux\",\n \"smitane\",\n \"soubise, white_onion_sauce\",\n \"lyonnaise_sauce, brown_onion_sauce\",\n \"veloute\",\n \"allemande, allemande_sauce\",\n \"caper_sauce\",\n \"poulette\",\n \"curry_sauce\",\n \"worcester_sauce, worcestershire, worcestershire_sauce\",\n \"coconut_milk, coconut_cream\",\n \"egg, eggs\",\n \"egg_white, white, albumen, ovalbumin\",\n \"egg_yolk, yolk\",\n \"boiled_egg, coddled_egg\",\n \"hard-boiled_egg, hard-cooked_egg\",\n \"easter_egg\",\n \"easter_egg\",\n \"chocolate_egg\",\n \"candy_egg\",\n \"poached_egg, dropped_egg\",\n \"scrambled_eggs\",\n \"deviled_egg, stuffed_egg\",\n \"shirred_egg, baked_egg, egg_en_cocotte\",\n \"omelet, omelette\",\n \"firm_omelet\",\n \"french_omelet\",\n \"fluffy_omelet\",\n \"western_omelet\",\n \"souffle\",\n \"fried_egg\",\n \"dairy_product\",\n \"milk\",\n \"milk\",\n \"sour_milk\",\n \"soya_milk, soybean_milk, soymilk\",\n \"formula\",\n \"pasteurized_milk\",\n \"cows'_milk\",\n \"yak's_milk\",\n \"goats'_milk\",\n \"acidophilus_milk\",\n \"raw_milk\",\n \"scalded_milk\",\n \"homogenized_milk\",\n \"certified_milk\",\n \"powdered_milk, dry_milk, dried_milk, milk_powder\",\n \"nonfat_dry_milk\",\n \"evaporated_milk\",\n \"condensed_milk\",\n \"skim_milk, skimmed_milk\",\n \"semi-skimmed_milk\",\n \"whole_milk\",\n \"low-fat_milk\",\n \"buttermilk\",\n \"cream\",\n \"clotted_cream, devonshire_cream\",\n \"double_creme, heavy_whipping_cream\",\n \"half-and-half\",\n \"heavy_cream\",\n \"light_cream, coffee_cream, single_cream\",\n \"sour_cream, soured_cream\",\n \"whipping_cream, light_whipping_cream\",\n \"butter\",\n \"clarified_butter, drawn_butter\",\n \"ghee\",\n \"brown_butter, beurre_noisette\",\n \"meuniere_butter, lemon_butter\",\n \"yogurt, yoghurt, yoghourt\",\n \"blueberry_yogurt\",\n \"raita\",\n \"whey\",\n \"curd\",\n \"curd\",\n \"clabber\",\n \"cheese\",\n \"paring\",\n \"cream_cheese\",\n \"double_cream\",\n \"mascarpone\",\n \"triple_cream, triple_creme\",\n \"cottage_cheese, pot_cheese, farm_cheese, farmer's_cheese\",\n \"process_cheese, processed_cheese\",\n \"bleu, blue_cheese\",\n \"stilton\",\n \"roquefort\",\n \"gorgonzola\",\n \"danish_blue\",\n \"bavarian_blue\",\n \"brie\",\n \"brick_cheese\",\n \"camembert\",\n \"cheddar, cheddar_cheese, armerican_cheddar, american_cheese\",\n \"rat_cheese, store_cheese\",\n \"cheshire_cheese\",\n \"double_gloucester\",\n \"edam\",\n \"goat_cheese, chevre\",\n \"gouda, gouda_cheese\",\n \"grated_cheese\",\n \"hand_cheese\",\n \"liederkranz\",\n \"limburger\",\n \"mozzarella\",\n \"muenster\",\n \"parmesan\",\n \"quark_cheese, quark\",\n \"ricotta\",\n \"string_cheese\",\n \"swiss_cheese\",\n \"emmenthal, emmental, emmenthaler, emmentaler\",\n \"gruyere\",\n \"sapsago\",\n \"velveeta\",\n \"nut_butter\",\n \"peanut_butter\",\n \"marshmallow_fluff\",\n \"onion_butter\",\n \"pimento_butter\",\n \"shrimp_butter\",\n \"lobster_butter\",\n \"yak_butter\",\n \"spread, paste\",\n \"cheese_spread\",\n \"anchovy_butter\",\n \"fishpaste\",\n \"garlic_butter\",\n \"miso\",\n \"wasabi\",\n \"snail_butter\",\n \"hummus, humus, hommos, hoummos, humous\",\n \"pate\",\n \"duck_pate\",\n \"foie_gras, pate_de_foie_gras\",\n \"tapenade\",\n \"tahini\",\n \"sweetening, sweetener\",\n \"aspartame\",\n \"honey\",\n \"saccharin\",\n \"sugar, refined_sugar\",\n \"syrup, sirup\",\n \"sugar_syrup\",\n \"molasses\",\n \"sorghum, sorghum_molasses\",\n \"treacle, golden_syrup\",\n \"grenadine\",\n \"maple_syrup\",\n \"corn_syrup\",\n \"miraculous_food, manna, manna_from_heaven\",\n \"batter\",\n \"dough\",\n \"bread_dough\",\n \"pancake_batter\",\n \"fritter_batter\",\n \"coq_au_vin\",\n \"chicken_provencale\",\n \"chicken_and_rice\",\n \"moo_goo_gai_pan\",\n \"arroz_con_pollo\",\n \"bacon_and_eggs\",\n \"barbecued_spareribs, spareribs\",\n \"beef_bourguignonne, boeuf_bourguignonne\",\n \"beef_wellington, filet_de_boeuf_en_croute\",\n \"bitok\",\n \"boiled_dinner, new_england_boiled_dinner\",\n \"boston_baked_beans\",\n \"bubble_and_squeak\",\n \"pasta\",\n \"cannelloni\",\n \"carbonnade_flamande, belgian_beef_stew\",\n \"cheese_souffle\",\n \"chicken_marengo\",\n \"chicken_cordon_bleu\",\n \"maryland_chicken\",\n \"chicken_paprika, chicken_paprikash\",\n \"chicken_tetrazzini\",\n \"tetrazzini\",\n \"chicken_kiev\",\n \"chili, chili_con_carne\",\n \"chili_dog\",\n \"chop_suey\",\n \"chow_mein\",\n \"codfish_ball, codfish_cake\",\n \"coquille\",\n \"coquilles_saint-jacques\",\n \"croquette\",\n \"cottage_pie\",\n \"rissole\",\n \"dolmas, stuffed_grape_leaves\",\n \"egg_foo_yong, egg_fu_yung\",\n \"egg_roll, spring_roll\",\n \"eggs_benedict\",\n \"enchilada\",\n \"falafel, felafel\",\n \"fish_and_chips\",\n \"fondue, fondu\",\n \"cheese_fondue\",\n \"chocolate_fondue\",\n \"fondue, fondu\",\n \"beef_fondue, boeuf_fondu_bourguignon\",\n \"french_toast\",\n \"fried_rice, chinese_fried_rice\",\n \"frittata\",\n \"frog_legs\",\n \"galantine\",\n \"gefilte_fish, fish_ball\",\n \"haggis\",\n \"ham_and_eggs\",\n \"hash\",\n \"corned_beef_hash\",\n \"jambalaya\",\n \"kabob, kebab, shish_kebab\",\n \"kedgeree\",\n \"souvlaki, souvlakia\",\n \"lasagna, lasagne\",\n \"seafood_newburg\",\n \"lobster_newburg, lobster_a_la_newburg\",\n \"shrimp_newburg\",\n \"newburg_sauce\",\n \"lobster_thermidor\",\n \"lutefisk, lutfisk\",\n \"macaroni_and_cheese\",\n \"macedoine\",\n \"meatball\",\n \"porcupine_ball, porcupines\",\n \"swedish_meatball\",\n \"meat_loaf, meatloaf\",\n \"moussaka\",\n \"osso_buco\",\n \"marrow, bone_marrow\",\n \"pheasant_under_glass\",\n \"pigs_in_blankets\",\n \"pilaf, pilaff, pilau, pilaw\",\n \"bulgur_pilaf\",\n \"pizza, pizza_pie\",\n \"sausage_pizza\",\n \"pepperoni_pizza\",\n \"cheese_pizza\",\n \"anchovy_pizza\",\n \"sicilian_pizza\",\n \"poi\",\n \"pork_and_beans\",\n \"porridge\",\n \"oatmeal, burgoo\",\n \"loblolly\",\n \"potpie\",\n \"rijsttaffel, rijstaffel, rijstafel\",\n \"risotto, italian_rice\",\n \"roulade\",\n \"fish_loaf\",\n \"salmon_loaf\",\n \"salisbury_steak\",\n \"sauerbraten\",\n \"sauerkraut\",\n \"scallopine, scallopini\",\n \"veal_scallopini\",\n \"scampi\",\n \"scotch_egg\",\n \"scotch_woodcock\",\n \"scrapple\",\n \"spaghetti_and_meatballs\",\n \"spanish_rice\",\n \"steak_tartare, tartar_steak, cannibal_mound\",\n \"pepper_steak\",\n \"steak_au_poivre, peppered_steak, pepper_steak\",\n \"beef_stroganoff\",\n \"stuffed_cabbage\",\n \"kishke, stuffed_derma\",\n \"stuffed_peppers\",\n \"stuffed_tomato, hot_stuffed_tomato\",\n \"stuffed_tomato, cold_stuffed_tomato\",\n \"succotash\",\n \"sukiyaki\",\n \"sashimi\",\n \"sushi\",\n \"swiss_steak\",\n \"tamale\",\n \"tamale_pie\",\n \"tempura\",\n \"teriyaki\",\n \"terrine\",\n \"welsh_rarebit, welsh_rabbit, rarebit\",\n \"schnitzel, wiener_schnitzel\",\n \"taco\",\n \"chicken_taco\",\n \"burrito\",\n \"beef_burrito\",\n \"quesadilla\",\n \"tostada\",\n \"bean_tostada\",\n \"refried_beans, frijoles_refritos\",\n \"beverage, drink, drinkable, potable\",\n \"wish-wash\",\n \"concoction, mixture, intermixture\",\n \"mix, premix\",\n \"filling\",\n \"lekvar\",\n \"potion\",\n \"elixir\",\n \"elixir_of_life\",\n \"philter, philtre, love-potion, love-philter, love-philtre\",\n \"alcohol, alcoholic_drink, alcoholic_beverage, intoxicant, inebriant\",\n \"proof_spirit\",\n \"home_brew, homebrew\",\n \"hooch, hootch\",\n \"kava, kavakava\",\n \"aperitif\",\n \"brew, brewage\",\n \"beer\",\n \"draft_beer, draught_beer\",\n \"suds\",\n \"munich_beer, munchener\",\n \"bock, bock_beer\",\n \"lager, lager_beer\",\n \"light_beer\",\n \"oktoberfest, octoberfest\",\n \"pilsner, pilsener\",\n \"shebeen\",\n \"weissbier, white_beer, wheat_beer\",\n \"weizenbock\",\n \"malt\",\n \"wort\",\n \"malt, malt_liquor\",\n \"ale\",\n \"bitter\",\n \"burton\",\n \"pale_ale\",\n \"porter, porter's_beer\",\n \"stout\",\n \"guinness\",\n \"kvass\",\n \"mead\",\n \"metheglin\",\n \"hydromel\",\n \"oenomel\",\n \"near_beer\",\n \"ginger_beer\",\n \"sake, saki, rice_beer\",\n \"wine, vino\",\n \"vintage\",\n \"red_wine\",\n \"white_wine\",\n \"blush_wine, pink_wine, rose, rose_wine\",\n \"altar_wine, sacramental_wine\",\n \"sparkling_wine\",\n \"champagne, bubbly\",\n \"cold_duck\",\n \"burgundy, burgundy_wine\",\n \"beaujolais\",\n \"medoc\",\n \"canary_wine\",\n \"chablis, white_burgundy\",\n \"montrachet\",\n \"chardonnay, pinot_chardonnay\",\n \"pinot_noir\",\n \"pinot_blanc\",\n \"bordeaux, bordeaux_wine\",\n \"claret, red_bordeaux\",\n \"chianti\",\n \"cabernet, cabernet_sauvignon\",\n \"merlot\",\n \"sauvignon_blanc\",\n \"california_wine\",\n \"cotes_de_provence\",\n \"dessert_wine\",\n \"dubonnet\",\n \"jug_wine\",\n \"macon, maconnais\",\n \"moselle\",\n \"muscadet\",\n \"plonk\",\n \"retsina\",\n \"rhine_wine, rhenish, hock\",\n \"riesling\",\n \"liebfraumilch\",\n \"rhone_wine\",\n \"rioja\",\n \"sack\",\n \"saint_emilion\",\n \"soave\",\n \"zinfandel\",\n \"sauterne, sauternes\",\n \"straw_wine\",\n \"table_wine\",\n \"tokay\",\n \"vin_ordinaire\",\n \"vermouth\",\n \"sweet_vermouth, italian_vermouth\",\n \"dry_vermouth, french_vermouth\",\n \"chenin_blanc\",\n \"verdicchio\",\n \"vouvray\",\n \"yquem\",\n \"generic, generic_wine\",\n \"varietal, varietal_wine\",\n \"fortified_wine\",\n \"madeira\",\n \"malmsey\",\n \"port, port_wine\",\n \"sherry\",\n \"marsala\",\n \"muscat, muscatel, muscadel, muscadelle\",\n \"liquor, spirits, booze, hard_drink, hard_liquor, john_barleycorn, strong_drink\",\n \"neutral_spirits, ethyl_alcohol\",\n \"aqua_vitae, ardent_spirits\",\n \"eau_de_vie\",\n \"moonshine, bootleg, corn_liquor\",\n \"bathtub_gin\",\n \"aquavit, akvavit\",\n \"arrack, arak\",\n \"bitters\",\n \"brandy\",\n \"applejack\",\n \"calvados\",\n \"armagnac\",\n \"cognac\",\n \"grappa\",\n \"kirsch\",\n \"slivovitz\",\n \"gin\",\n \"sloe_gin\",\n \"geneva, holland_gin, hollands\",\n \"grog\",\n \"ouzo\",\n \"rum\",\n \"demerara, demerara_rum\",\n \"jamaica_rum\",\n \"schnapps, schnaps\",\n \"pulque\",\n \"mescal\",\n \"tequila\",\n \"vodka\",\n \"whiskey, whisky\",\n \"blended_whiskey, blended_whisky\",\n \"bourbon\",\n \"corn_whiskey, corn_whisky, corn\",\n \"firewater\",\n \"irish, irish_whiskey, irish_whisky\",\n \"poteen\",\n \"rye, rye_whiskey, rye_whisky\",\n \"scotch, scotch_whiskey, scotch_whisky, malt_whiskey, malt_whisky, scotch_malt_whiskey, scotch_malt_whisky\",\n \"sour_mash, sour_mash_whiskey\",\n \"liqueur, cordial\",\n \"absinth, absinthe\",\n \"amaretto\",\n \"anisette, anisette_de_bordeaux\",\n \"benedictine\",\n \"chartreuse\",\n \"coffee_liqueur\",\n \"creme_de_cacao\",\n \"creme_de_menthe\",\n \"creme_de_fraise\",\n \"drambuie\",\n \"galliano\",\n \"orange_liqueur\",\n \"curacao, curacoa\",\n \"triple_sec\",\n \"grand_marnier\",\n \"kummel\",\n \"maraschino, maraschino_liqueur\",\n \"pastis\",\n \"pernod\",\n \"pousse-cafe\",\n \"kahlua\",\n \"ratafia, ratafee\",\n \"sambuca\",\n \"mixed_drink\",\n \"cocktail\",\n \"dom_pedro\",\n \"highball\",\n \"mixer\",\n \"bishop\",\n \"bloody_mary\",\n \"virgin_mary, bloody_shame\",\n \"bullshot\",\n \"cobbler\",\n \"collins, tom_collins\",\n \"cooler\",\n \"refresher\",\n \"smoothie\",\n \"daiquiri, rum_cocktail\",\n \"strawberry_daiquiri\",\n \"nada_daiquiri\",\n \"spritzer\",\n \"flip\",\n \"gimlet\",\n \"gin_and_tonic\",\n \"grasshopper\",\n \"harvey_wallbanger\",\n \"julep, mint_julep\",\n \"manhattan\",\n \"rob_roy\",\n \"margarita\",\n \"martini\",\n \"gin_and_it\",\n \"vodka_martini\",\n \"old_fashioned\",\n \"pink_lady\",\n \"sazerac\",\n \"screwdriver\",\n \"sidecar\",\n \"scotch_and_soda\",\n \"sling\",\n \"brandy_sling\",\n \"gin_sling\",\n \"rum_sling\",\n \"sour\",\n \"whiskey_sour, whisky_sour\",\n \"stinger\",\n \"swizzle\",\n \"hot_toddy, toddy\",\n \"zombie, zombi\",\n \"fizz\",\n \"irish_coffee\",\n \"cafe_au_lait\",\n \"cafe_noir, demitasse\",\n \"decaffeinated_coffee, decaf\",\n \"drip_coffee\",\n \"espresso\",\n \"caffe_latte, latte\",\n \"cappuccino, cappuccino_coffee, coffee_cappuccino\",\n \"iced_coffee, ice_coffee\",\n \"instant_coffee\",\n \"mocha, mocha_coffee\",\n \"mocha\",\n \"cassareep\",\n \"turkish_coffee\",\n \"chocolate_milk\",\n \"cider, cyder\",\n \"hard_cider\",\n \"scrumpy\",\n \"sweet_cider\",\n \"mulled_cider\",\n \"perry\",\n \"rotgut\",\n \"slug\",\n \"cocoa, chocolate, hot_chocolate, drinking_chocolate\",\n \"criollo\",\n \"juice\",\n \"fruit_juice, fruit_crush\",\n \"nectar\",\n \"apple_juice\",\n \"cranberry_juice\",\n \"grape_juice\",\n \"must\",\n \"grapefruit_juice\",\n \"orange_juice\",\n \"frozen_orange_juice, orange-juice_concentrate\",\n \"pineapple_juice\",\n \"lemon_juice\",\n \"lime_juice\",\n \"papaya_juice\",\n \"tomato_juice\",\n \"carrot_juice\",\n \"v-8_juice\",\n \"koumiss, kumis\",\n \"fruit_drink, ade\",\n \"lemonade\",\n \"limeade\",\n \"orangeade\",\n \"malted_milk\",\n \"mate\",\n \"mulled_wine\",\n \"negus\",\n \"soft_drink\",\n \"pop, soda, soda_pop, soda_water, tonic\",\n \"birch_beer\",\n \"bitter_lemon\",\n \"cola, dope\",\n \"cream_soda\",\n \"egg_cream\",\n \"ginger_ale, ginger_pop\",\n \"orange_soda\",\n \"phosphate\",\n \"coca_cola, coke\",\n \"pepsi, pepsi_cola\",\n \"root_beer\",\n \"sarsaparilla\",\n \"tonic, tonic_water, quinine_water\",\n \"coffee_bean, coffee_berry, coffee\",\n \"coffee, java\",\n \"cafe_royale, coffee_royal\",\n \"fruit_punch\",\n \"milk_punch\",\n \"mimosa, buck's_fizz\",\n \"pina_colada\",\n \"punch\",\n \"cup\",\n \"champagne_cup\",\n \"claret_cup\",\n \"wassail\",\n \"planter's_punch\",\n \"white_russian\",\n \"fish_house_punch\",\n \"may_wine\",\n \"eggnog\",\n \"cassiri\",\n \"spruce_beer\",\n \"rickey\",\n \"gin_rickey\",\n \"tea, tea_leaf\",\n \"tea_bag\",\n \"tea\",\n \"tea-like_drink\",\n \"cambric_tea\",\n \"cuppa, cupper\",\n \"herb_tea, herbal_tea, herbal\",\n \"tisane\",\n \"camomile_tea\",\n \"ice_tea, iced_tea\",\n \"sun_tea\",\n \"black_tea\",\n \"congou, congo, congou_tea, english_breakfast_tea\",\n \"darjeeling\",\n \"orange_pekoe, pekoe\",\n \"souchong, soochong\",\n \"green_tea\",\n \"hyson\",\n \"oolong\",\n \"water\",\n \"bottled_water\",\n \"branch_water\",\n \"spring_water\",\n \"sugar_water\",\n \"drinking_water\",\n \"ice_water\",\n \"soda_water, carbonated_water, club_soda, seltzer, sparkling_water\",\n \"mineral_water\",\n \"seltzer\",\n \"vichy_water\",\n \"perishable, spoilable\",\n \"couscous\",\n \"ramekin, ramequin\",\n \"multivitamin, multivitamin_pill\",\n \"vitamin_pill\",\n \"soul_food\",\n \"mold, mould\",\n \"people\",\n \"collection, aggregation, accumulation, assemblage\",\n \"book, rule_book\",\n \"library\",\n \"baseball_club, ball_club, club, nine\",\n \"crowd\",\n \"class, form, grade, course\",\n \"core, nucleus, core_group\",\n \"concert_band, military_band\",\n \"dance\",\n \"wedding, wedding_party\",\n \"chain, concatenation\",\n \"power_breakfast\",\n \"aerie, aery, eyrie, eyry\",\n \"agora\",\n \"amusement_park, funfair, pleasure_ground\",\n \"aphelion\",\n \"apron\",\n \"interplanetary_space\",\n \"interstellar_space\",\n \"intergalactic_space\",\n \"bush\",\n \"semidesert\",\n \"beam-ends\",\n \"bridgehead\",\n \"bus_stop\",\n \"campsite, campground, camping_site, camping_ground, bivouac, encampment, camping_area\",\n \"detention_basin\",\n \"cemetery, graveyard, burial_site, burial_ground, burying_ground, memorial_park, necropolis\",\n \"trichion, crinion\",\n \"city, metropolis, urban_center\",\n \"business_district, downtown\",\n \"outskirts\",\n \"borough\",\n \"cow_pasture\",\n \"crest\",\n \"eparchy, exarchate\",\n \"suburb, suburbia, suburban_area\",\n \"stockbroker_belt\",\n \"crawlspace, crawl_space\",\n \"sheikdom, sheikhdom\",\n \"residence, abode\",\n \"domicile, legal_residence\",\n \"dude_ranch\",\n \"farmland, farming_area\",\n \"midfield\",\n \"firebreak, fireguard\",\n \"flea_market\",\n \"battlefront, front, front_line\",\n \"garbage_heap, junk_heap, rubbish_heap, scrapheap, trash_heap, junk_pile, trash_pile, refuse_heap\",\n \"benthos, benthic_division, benthonic_zone\",\n \"goldfield\",\n \"grainfield, grain_field\",\n \"half-mast, half-staff\",\n \"hemline\",\n \"heronry\",\n \"hipline\",\n \"hipline\",\n \"hole-in-the-wall\",\n \"junkyard\",\n \"isoclinic_line, isoclinal\",\n \"littoral, litoral, littoral_zone, sands\",\n \"magnetic_pole\",\n \"grassland\",\n \"mecca\",\n \"observer's_meridian\",\n \"prime_meridian\",\n \"nombril\",\n \"no-parking_zone\",\n \"outdoors, out-of-doors, open_air, open\",\n \"fairground\",\n \"pasture, pastureland, grazing_land, lea, ley\",\n \"perihelion\",\n \"periselene, perilune\",\n \"locus_of_infection\",\n \"kasbah, casbah\",\n \"waterfront\",\n \"resort, resort_hotel, holiday_resort\",\n \"resort_area, playground, vacation_spot\",\n \"rough\",\n \"ashram\",\n \"harborage, harbourage\",\n \"scrubland\",\n \"weald\",\n \"wold\",\n \"schoolyard\",\n \"showplace\",\n \"bedside\",\n \"sideline, out_of_bounds\",\n \"ski_resort\",\n \"soil_horizon\",\n \"geological_horizon\",\n \"coal_seam\",\n \"coalface\",\n \"field\",\n \"oilfield\",\n \"temperate_zone\",\n \"terreplein\",\n \"three-mile_limit\",\n \"desktop\",\n \"top\",\n \"kampong, campong\",\n \"subtropics, semitropics\",\n \"barrio\",\n \"veld, veldt\",\n \"vertex, peak, apex, acme\",\n \"waterline, water_line, water_level\",\n \"high-water_mark\",\n \"low-water_mark\",\n \"continental_divide\",\n \"zodiac\",\n \"aegean_island\",\n \"sultanate\",\n \"swiss_canton\",\n \"abyssal_zone\",\n \"aerie, aery, eyrie, eyry\",\n \"air_bubble\",\n \"alluvial_flat, alluvial_plain\",\n \"alp\",\n \"alpine_glacier, alpine_type_of_glacier\",\n \"anthill, formicary\",\n \"aquifer\",\n \"archipelago\",\n \"arete\",\n \"arroyo\",\n \"ascent, acclivity, rise, raise, climb, upgrade\",\n \"asterism\",\n \"asthenosphere\",\n \"atoll\",\n \"bank\",\n \"bank\",\n \"bar\",\n \"barbecue_pit\",\n \"barrier_reef\",\n \"baryon, heavy_particle\",\n \"basin\",\n \"beach\",\n \"honeycomb\",\n \"belay\",\n \"ben\",\n \"berm\",\n \"bladder_stone, cystolith\",\n \"bluff\",\n \"borrow_pit\",\n \"brae\",\n \"bubble\",\n \"burrow, tunnel\",\n \"butte\",\n \"caldera\",\n \"canyon, canon\",\n \"canyonside\",\n \"cave\",\n \"cavern\",\n \"chasm\",\n \"cirque, corrie, cwm\",\n \"cliff, drop, drop-off\",\n \"cloud\",\n \"coast\",\n \"coastland\",\n \"col, gap\",\n \"collector\",\n \"comet\",\n \"continental_glacier\",\n \"coral_reef\",\n \"cove\",\n \"crag\",\n \"crater\",\n \"cultivated_land, farmland, plowland, ploughland, tilled_land, tillage, tilth\",\n \"dale\",\n \"defile, gorge\",\n \"delta\",\n \"descent, declivity, fall, decline, declination, declension, downslope\",\n \"diapir\",\n \"divot\",\n \"divot\",\n \"down\",\n \"downhill\",\n \"draw\",\n \"drey\",\n \"drumlin\",\n \"dune, sand_dune\",\n \"escarpment, scarp\",\n \"esker\",\n \"fireball\",\n \"flare_star\",\n \"floor\",\n \"fomite, vehicle\",\n \"foothill\",\n \"footwall\",\n \"foreland\",\n \"foreshore\",\n \"gauge_boson\",\n \"geological_formation, formation\",\n \"geyser\",\n \"glacier\",\n \"glen\",\n \"gopher_hole\",\n \"gorge\",\n \"grotto, grot\",\n \"growler\",\n \"gulch, flume\",\n \"gully\",\n \"hail\",\n \"highland, upland\",\n \"hill\",\n \"hillside\",\n \"hole, hollow\",\n \"hollow, holler\",\n \"hot_spring, thermal_spring\",\n \"iceberg, berg\",\n \"icecap, ice_cap\",\n \"ice_field\",\n \"ice_floe, floe\",\n \"ice_mass\",\n \"inclined_fault\",\n \"ion\",\n \"isthmus\",\n \"kidney_stone, urinary_calculus, nephrolith, renal_calculus\",\n \"knoll, mound, hillock, hummock, hammock\",\n \"kopje, koppie\",\n \"kuiper_belt, edgeworth-kuiper_belt\",\n \"lake_bed, lake_bottom\",\n \"lakefront\",\n \"lakeside, lakeshore\",\n \"landfall\",\n \"landfill\",\n \"lather\",\n \"leak\",\n \"ledge, shelf\",\n \"lepton\",\n \"lithosphere, geosphere\",\n \"lowland\",\n \"lunar_crater\",\n \"maar\",\n \"massif\",\n \"meander\",\n \"mesa, table\",\n \"meteorite\",\n \"microfossil\",\n \"midstream\",\n \"molehill\",\n \"monocline\",\n \"mountain, mount\",\n \"mountainside, versant\",\n \"mouth\",\n \"mull\",\n \"natural_depression, depression\",\n \"natural_elevation, elevation\",\n \"nullah\",\n \"ocean\",\n \"ocean_floor, sea_floor, ocean_bottom, seabed, sea_bottom, davy_jones's_locker, davy_jones\",\n \"oceanfront\",\n \"outcrop, outcropping, rock_outcrop\",\n \"oxbow\",\n \"pallasite\",\n \"perforation\",\n \"photosphere\",\n \"piedmont\",\n \"piedmont_glacier, piedmont_type_of_glacier\",\n \"pinetum\",\n \"plage\",\n \"plain, field, champaign\",\n \"point\",\n \"polar_glacier\",\n \"pothole, chuckhole\",\n \"precipice\",\n \"promontory, headland, head, foreland\",\n \"ptyalith\",\n \"pulsar\",\n \"quicksand\",\n \"rabbit_burrow, rabbit_hole\",\n \"radiator\",\n \"rainbow\",\n \"range, mountain_range, range_of_mountains, chain, mountain_chain, chain_of_mountains\",\n \"rangeland\",\n \"ravine\",\n \"reef\",\n \"ridge\",\n \"ridge, ridgeline\",\n \"rift_valley\",\n \"riparian_forest\",\n \"ripple_mark\",\n \"riverbank, riverside\",\n \"riverbed, river_bottom\",\n \"rock, stone\",\n \"roof\",\n \"saltpan\",\n \"sandbank\",\n \"sandbar, sand_bar\",\n \"sandpit\",\n \"sanitary_landfill\",\n \"sawpit\",\n \"scablands\",\n \"seashore, coast, seacoast, sea-coast\",\n \"seaside, seaboard\",\n \"seif_dune\",\n \"shell\",\n \"shiner\",\n \"shoal\",\n \"shore\",\n \"shoreline\",\n \"sinkhole, sink, swallow_hole\",\n \"ski_slope\",\n \"sky\",\n \"slope, incline, side\",\n \"snowcap\",\n \"snowdrift\",\n \"snowfield\",\n \"soapsuds, suds, lather\",\n \"spit, tongue\",\n \"spoor\",\n \"spume\",\n \"star\",\n \"steep\",\n \"steppe\",\n \"strand\",\n \"streambed, creek_bed\",\n \"sun, sun\",\n \"supernova\",\n \"swale\",\n \"swamp, swampland\",\n \"swell\",\n \"tableland, plateau\",\n \"talus, scree\",\n \"tangle\",\n \"tar_pit\",\n \"terrace, bench\",\n \"tidal_basin\",\n \"tideland\",\n \"tor\",\n \"tor\",\n \"trapezium\",\n \"troposphere\",\n \"tundra\",\n \"twinkler\",\n \"uphill\",\n \"urolith\",\n \"valley, vale\",\n \"vehicle-borne_transmission\",\n \"vein, mineral_vein\",\n \"volcanic_crater, crater\",\n \"volcano\",\n \"wadi\",\n \"wall\",\n \"warren, rabbit_warren\",\n \"wasp's_nest, wasps'_nest, hornet's_nest, hornets'_nest\",\n \"watercourse\",\n \"waterside\",\n \"water_table, water_level, groundwater_level\",\n \"whinstone, whin\",\n \"wormcast\",\n \"xenolith\",\n \"circe\",\n \"gryphon, griffin, griffon\",\n \"spiritual_leader\",\n \"messiah, christ\",\n \"rhea_silvia, rea_silvia\",\n \"number_one\",\n \"adventurer, venturer\",\n \"anomaly, unusual_person\",\n \"appointee, appointment\",\n \"argonaut\",\n \"ashkenazi\",\n \"benefactor, helper\",\n \"color-blind_person\",\n \"commoner, common_man, common_person\",\n \"conservator\",\n \"contrarian\",\n \"contadino\",\n \"contestant\",\n \"cosigner, cosignatory\",\n \"discussant\",\n \"enologist, oenologist, fermentologist\",\n \"entertainer\",\n \"eulogist, panegyrist\",\n \"ex-gambler\",\n \"experimenter\",\n \"experimenter\",\n \"exponent\",\n \"ex-president\",\n \"face\",\n \"female, female_person\",\n \"finisher\",\n \"inhabitant, habitant, dweller, denizen, indweller\",\n \"native, indigen, indigene, aborigine, aboriginal\",\n \"native\",\n \"juvenile, juvenile_person\",\n \"lover\",\n \"male, male_person\",\n \"mediator, go-between, intermediator, intermediary, intercessor\",\n \"mediatrix\",\n \"national, subject\",\n \"peer, equal, match, compeer\",\n \"prize_winner, lottery_winner\",\n \"recipient, receiver\",\n \"religionist\",\n \"sensualist\",\n \"traveler, traveller\",\n \"unwelcome_person, persona_non_grata\",\n \"unskilled_person\",\n \"worker\",\n \"wrongdoer, offender\",\n \"black_african\",\n \"afrikaner, afrikander, boer\",\n \"aryan\",\n \"black, black_person, blackamoor, negro, negroid\",\n \"black_woman\",\n \"mulatto\",\n \"white, white_person, caucasian\",\n \"circassian\",\n \"semite\",\n \"chaldean, chaldaean, chaldee\",\n \"elamite\",\n \"white_man\",\n \"wasp, white_anglo-saxon_protestant\",\n \"gook, slant-eye\",\n \"mongol, mongolian\",\n \"tatar, tartar, mongol_tatar\",\n \"nahuatl\",\n \"aztec\",\n \"olmec\",\n \"biloxi\",\n \"blackfoot\",\n \"brule\",\n \"caddo\",\n \"cheyenne\",\n \"chickasaw\",\n \"cocopa, cocopah\",\n \"comanche\",\n \"creek\",\n \"delaware\",\n \"diegueno\",\n \"esselen\",\n \"eyeish\",\n \"havasupai\",\n \"hunkpapa\",\n \"iowa, ioway\",\n \"kalapooia, kalapuya, calapooya, calapuya\",\n \"kamia\",\n \"kekchi\",\n \"kichai\",\n \"kickapoo\",\n \"kiliwa, kiliwi\",\n \"malecite\",\n \"maricopa\",\n \"mohican, mahican\",\n \"muskhogean, muskogean\",\n \"navaho, navajo\",\n \"nootka\",\n \"oglala, ogalala\",\n \"osage\",\n \"oneida\",\n \"paiute, piute\",\n \"passamaquody\",\n \"penobscot\",\n \"penutian\",\n \"potawatomi\",\n \"powhatan\",\n \"kachina\",\n \"salish\",\n \"shahaptian, sahaptin, sahaptino\",\n \"shasta\",\n \"shawnee\",\n \"sihasapa\",\n \"teton, lakota, teton_sioux, teton_dakota\",\n \"taracahitian\",\n \"tarahumara\",\n \"tuscarora\",\n \"tutelo\",\n \"yana\",\n \"yavapai\",\n \"yokuts\",\n \"yuma\",\n \"gadaba\",\n \"kolam\",\n \"kui\",\n \"toda\",\n \"tulu\",\n \"gujarati, gujerati\",\n \"kashmiri\",\n \"punjabi, panjabi\",\n \"slav\",\n \"anabaptist\",\n \"adventist, second_adventist\",\n \"gentile, non-jew, goy\",\n \"gentile\",\n \"catholic\",\n \"old_catholic\",\n \"uniat, uniate, uniate_christian\",\n \"copt\",\n \"jewess\",\n \"jihadist\",\n \"buddhist\",\n \"zen_buddhist\",\n \"mahayanist\",\n \"swami\",\n \"hare_krishna\",\n \"shintoist\",\n \"eurafrican\",\n \"eurasian\",\n \"gael\",\n \"frank\",\n \"afghan, afghanistani\",\n \"albanian\",\n \"algerian\",\n \"altaic\",\n \"andorran\",\n \"angolan\",\n \"anguillan\",\n \"austrian\",\n \"bahamian\",\n \"bahraini, bahreini\",\n \"basotho\",\n \"herero\",\n \"luba, chiluba\",\n \"barbadian\",\n \"bolivian\",\n \"bornean\",\n \"carioca\",\n \"tupi\",\n \"bruneian\",\n \"bulgarian\",\n \"byelorussian, belorussian, white_russian\",\n \"cameroonian\",\n \"canadian\",\n \"french_canadian\",\n \"central_american\",\n \"chilean\",\n \"congolese\",\n \"cypriot, cypriote, cyprian\",\n \"dane\",\n \"djiboutian\",\n \"britisher, briton, brit\",\n \"english_person\",\n \"englishwoman\",\n \"anglo-saxon\",\n \"angle\",\n \"west_saxon\",\n \"lombard, langobard\",\n \"limey, john_bull\",\n \"cantabrigian\",\n \"cornishman\",\n \"cornishwoman\",\n \"lancastrian\",\n \"lancastrian\",\n \"geordie\",\n \"oxonian\",\n \"ethiopian\",\n \"amhara\",\n \"eritrean\",\n \"finn\",\n \"komi\",\n \"livonian\",\n \"lithuanian\",\n \"selkup, ostyak-samoyed\",\n \"parisian\",\n \"parisienne\",\n \"creole\",\n \"creole\",\n \"gabonese\",\n \"greek, hellene\",\n \"dorian\",\n \"athenian\",\n \"laconian\",\n \"guyanese\",\n \"haitian\",\n \"malay, malayan\",\n \"moro\",\n \"netherlander, dutchman, hollander\",\n \"icelander\",\n \"iraqi, iraki\",\n \"irishman\",\n \"irishwoman\",\n \"dubliner\",\n \"italian\",\n \"roman\",\n \"sabine\",\n \"japanese, nipponese\",\n \"jordanian\",\n \"korean\",\n \"kenyan\",\n \"lao, laotian\",\n \"lapp, lapplander, sami, saami, same, saame\",\n \"latin_american, latino\",\n \"lebanese\",\n \"levantine\",\n \"liberian\",\n \"luxemburger, luxembourger\",\n \"macedonian\",\n \"sabahan\",\n \"mexican\",\n \"chicano\",\n \"mexican-american, mexicano\",\n \"namibian\",\n \"nauruan\",\n \"gurkha\",\n \"new_zealander, kiwi\",\n \"nicaraguan\",\n \"nigerian\",\n \"hausa, haussa\",\n \"north_american\",\n \"nova_scotian, bluenose\",\n \"omani\",\n \"pakistani\",\n \"brahui\",\n \"south_american_indian\",\n \"carib, carib_indian\",\n \"filipino\",\n \"polynesian\",\n \"qatari, katari\",\n \"romanian, rumanian\",\n \"muscovite\",\n \"georgian\",\n \"sarawakian\",\n \"scandinavian, norse, northman\",\n \"senegalese\",\n \"slovene\",\n \"south_african\",\n \"south_american\",\n \"sudanese\",\n \"syrian\",\n \"tahitian\",\n \"tanzanian\",\n \"tibetan\",\n \"togolese\",\n \"tuareg\",\n \"turki\",\n \"chuvash\",\n \"turkoman, turkmen, turcoman\",\n \"uzbek, uzbeg, uzbak, usbek, usbeg\",\n \"ugandan\",\n \"ukranian\",\n \"yakut\",\n \"tungus, evenk\",\n \"igbo\",\n \"american\",\n \"anglo-american\",\n \"alaska_native, alaskan_native, native_alaskan\",\n \"arkansan, arkansawyer\",\n \"carolinian\",\n \"coloradan\",\n \"connecticuter\",\n \"delawarean, delawarian\",\n \"floridian\",\n \"german_american\",\n \"illinoisan\",\n \"mainer, down_easter\",\n \"marylander\",\n \"minnesotan, gopher\",\n \"nebraskan, cornhusker\",\n \"new_hampshirite, granite_stater\",\n \"new_jerseyan, new_jerseyite, garden_stater\",\n \"new_yorker\",\n \"north_carolinian, tarheel\",\n \"oregonian, beaver\",\n \"pennsylvanian, keystone_stater\",\n \"texan\",\n \"utahan\",\n \"uruguayan\",\n \"vietnamese, annamese\",\n \"gambian\",\n \"east_german\",\n \"berliner\",\n \"prussian\",\n \"ghanian\",\n \"guinean\",\n \"papuan\",\n \"walloon\",\n \"yemeni\",\n \"yugoslav, jugoslav, yugoslavian, jugoslavian\",\n \"serbian, serb\",\n \"xhosa\",\n \"zairese, zairean\",\n \"zimbabwean\",\n \"zulu\",\n \"gemini, twin\",\n \"sagittarius, archer\",\n \"pisces, fish\",\n \"abbe\",\n \"abbess, mother_superior, prioress\",\n \"abnegator\",\n \"abridger, abbreviator\",\n \"abstractor, abstracter\",\n \"absconder\",\n \"absolver\",\n \"abecedarian\",\n \"aberrant\",\n \"abettor, abetter\",\n \"abhorrer\",\n \"abomination\",\n \"abseiler, rappeller\",\n \"abstainer, ascetic\",\n \"academic_administrator\",\n \"academician\",\n \"accessory_before_the_fact\",\n \"companion\",\n \"accompanist, accompanyist\",\n \"accomplice, confederate\",\n \"account_executive, account_representative, registered_representative, customer's_broker, customer's_man\",\n \"accused\",\n \"accuser\",\n \"acid_head\",\n \"acquaintance, friend\",\n \"acquirer\",\n \"aerialist\",\n \"action_officer\",\n \"active\",\n \"active_citizen\",\n \"actor, histrion, player, thespian, role_player\",\n \"actor, doer, worker\",\n \"addict, nut, freak, junkie, junky\",\n \"adducer\",\n \"adjuster, adjustor, claims_adjuster, claims_adjustor, claim_agent\",\n \"adjutant, aide, aide-de-camp\",\n \"adjutant_general\",\n \"admirer, adorer\",\n \"adoptee\",\n \"adulterer, fornicator\",\n \"adulteress, fornicatress, hussy, jade, loose_woman, slut, strumpet, trollop\",\n \"advertiser, advertizer, adman\",\n \"advisee\",\n \"advocate, advocator, proponent, exponent\",\n \"aeronautical_engineer\",\n \"affiliate\",\n \"affluent\",\n \"aficionado\",\n \"buck_sergeant\",\n \"agent-in-place\",\n \"aggravator, annoyance\",\n \"agitator, fomenter\",\n \"agnostic\",\n \"agnostic, doubter\",\n \"agonist\",\n \"agony_aunt\",\n \"agriculturist, agriculturalist, cultivator, grower, raiser\",\n \"air_attache\",\n \"air_force_officer, commander\",\n \"airhead\",\n \"air_traveler, air_traveller\",\n \"alarmist\",\n \"albino\",\n \"alcoholic, alky, dipsomaniac, boozer, lush, soaker, souse\",\n \"alderman\",\n \"alexic\",\n \"alienee, grantee\",\n \"alienor\",\n \"aliterate, aliterate_person\",\n \"algebraist\",\n \"allegorizer, allegoriser\",\n \"alliterator\",\n \"almoner, medical_social_worker\",\n \"alpinist\",\n \"altar_boy\",\n \"alto\",\n \"ambassador, embassador\",\n \"ambassador\",\n \"ambusher\",\n \"amicus_curiae, friend_of_the_court\",\n \"amoralist\",\n \"amputee\",\n \"analogist\",\n \"analphabet, analphabetic\",\n \"analyst\",\n \"industry_analyst\",\n \"market_strategist\",\n \"anarchist, nihilist, syndicalist\",\n \"anathema, bete_noire\",\n \"ancestor, ascendant, ascendent, antecedent, root\",\n \"anchor, anchorman, anchorperson\",\n \"ancient\",\n \"anecdotist, raconteur\",\n \"angler, troller\",\n \"animator\",\n \"animist\",\n \"annotator\",\n \"announcer\",\n \"announcer\",\n \"anti\",\n \"anti-american\",\n \"anti-semite, jew-baiter\",\n \"anzac\",\n \"ape-man\",\n \"aphakic\",\n \"appellant, plaintiff_in_error\",\n \"appointee\",\n \"apprehender\",\n \"april_fool\",\n \"aspirant, aspirer, hopeful, wannabe, wannabee\",\n \"appreciator\",\n \"appropriator\",\n \"arabist\",\n \"archaist\",\n \"archbishop\",\n \"archer, bowman\",\n \"architect, designer\",\n \"archivist\",\n \"archpriest, hierarch, high_priest, prelate, primate\",\n \"aristotelian, aristotelean, peripatetic\",\n \"armiger\",\n \"army_attache\",\n \"army_engineer, military_engineer\",\n \"army_officer\",\n \"arranger, adapter, transcriber\",\n \"arrival, arriver, comer\",\n \"arthritic\",\n \"articulator\",\n \"artilleryman, cannoneer, gunner, machine_gunner\",\n \"artist's_model, sitter\",\n \"assayer\",\n \"assemblyman\",\n \"assemblywoman\",\n \"assenter\",\n \"asserter, declarer, affirmer, asseverator, avower\",\n \"assignee\",\n \"assistant, helper, help, supporter\",\n \"assistant_professor\",\n \"associate\",\n \"associate\",\n \"associate_professor\",\n \"astronaut, spaceman, cosmonaut\",\n \"cosmographer, cosmographist\",\n \"atheist\",\n \"athlete, jock\",\n \"attendant, attender, tender\",\n \"attorney_general\",\n \"auditor\",\n \"augur, auspex\",\n \"aunt, auntie, aunty\",\n \"au_pair_girl\",\n \"authoritarian, dictator\",\n \"authority\",\n \"authorizer, authoriser\",\n \"automobile_mechanic, auto-mechanic, car-mechanic, mechanic, grease_monkey\",\n \"aviator, aeronaut, airman, flier, flyer\",\n \"aviatrix, airwoman, aviatress\",\n \"ayah\",\n \"babu, baboo\",\n \"baby, babe, sister\",\n \"baby\",\n \"baby_boomer, boomer\",\n \"baby_farmer\",\n \"back\",\n \"backbencher\",\n \"backpacker, packer\",\n \"backroom_boy, brain_truster\",\n \"backscratcher\",\n \"bad_person\",\n \"baggage\",\n \"bag_lady\",\n \"bailee\",\n \"bailiff\",\n \"bailor\",\n \"bairn\",\n \"baker, bread_maker\",\n \"balancer\",\n \"balker, baulker, noncompliant\",\n \"ball-buster, ball-breaker\",\n \"ball_carrier, runner\",\n \"ballet_dancer\",\n \"ballet_master\",\n \"ballet_mistress\",\n \"balletomane\",\n \"ball_hawk\",\n \"balloonist\",\n \"ballplayer, baseball_player\",\n \"bullfighter, toreador\",\n \"banderillero\",\n \"matador\",\n \"picador\",\n \"bandsman\",\n \"banker\",\n \"bank_robber\",\n \"bankrupt, insolvent\",\n \"bantamweight\",\n \"barmaid\",\n \"baron, big_businessman, business_leader, king, magnate, mogul, power, top_executive, tycoon\",\n \"baron\",\n \"baron\",\n \"bartender, barman, barkeep, barkeeper, mixologist\",\n \"baseball_coach, baseball_manager\",\n \"base_runner, runner\",\n \"basketball_player, basketeer, cager\",\n \"basketweaver, basketmaker\",\n \"basket_maker\",\n \"bass, basso\",\n \"bastard, by-blow, love_child, illegitimate_child, illegitimate, whoreson\",\n \"bat_boy\",\n \"bather\",\n \"batman\",\n \"baton_twirler, twirler\",\n \"bavarian\",\n \"beadsman, bedesman\",\n \"beard\",\n \"beatnik, beat\",\n \"beauty_consultant\",\n \"bedouin, beduin\",\n \"bedwetter, bed_wetter, wetter\",\n \"beekeeper, apiarist, apiculturist\",\n \"beer_drinker, ale_drinker\",\n \"beggarman\",\n \"beggarwoman\",\n \"beldam, beldame\",\n \"theist\",\n \"believer, truster\",\n \"bell_founder\",\n \"benedick, benedict\",\n \"berserker, berserk\",\n \"besieger\",\n \"best, topper\",\n \"betrothed\",\n \"big_brother\",\n \"bigot\",\n \"big_shot, big_gun, big_wheel, big_cheese, big_deal, big_enchilada, big_fish, head_honcho\",\n \"big_sister\",\n \"billiard_player\",\n \"biochemist\",\n \"biographer\",\n \"bird_fancier\",\n \"birth\",\n \"birth-control_campaigner, birth-control_reformer\",\n \"bisexual, bisexual_person\",\n \"black_belt\",\n \"blackmailer, extortioner, extortionist\",\n \"black_muslim\",\n \"blacksmith\",\n \"blade\",\n \"blind_date\",\n \"bluecoat\",\n \"bluestocking, bas_bleu\",\n \"boatbuilder\",\n \"boatman, boater, waterman\",\n \"boatswain, bos'n, bo's'n, bosun, bo'sun\",\n \"bobby\",\n \"bodyguard, escort\",\n \"boffin\",\n \"bolshevik, marxist, red, bolshie, bolshy\",\n \"bolshevik, bolshevist\",\n \"bombshell\",\n \"bondman, bondsman\",\n \"bondwoman, bondswoman, bondmaid\",\n \"bondwoman, bondswoman, bondmaid\",\n \"bond_servant\",\n \"book_agent\",\n \"bookbinder\",\n \"bookkeeper\",\n \"bookmaker\",\n \"bookworm\",\n \"booster, shoplifter, lifter\",\n \"bootblack, shoeblack\",\n \"bootlegger, moonshiner\",\n \"bootmaker, boot_maker\",\n \"borderer\",\n \"border_patrolman\",\n \"botanist, phytologist, plant_scientist\",\n \"bottom_feeder\",\n \"boulevardier\",\n \"bounty_hunter\",\n \"bounty_hunter\",\n \"bourbon\",\n \"bowler\",\n \"slugger, slogger\",\n \"cub, lad, laddie, sonny, sonny_boy\",\n \"boy_scout\",\n \"boy_scout\",\n \"boy_wonder\",\n \"bragger, braggart, boaster, blowhard, line-shooter, vaunter\",\n \"brahman, brahmin\",\n \"brawler\",\n \"breadwinner\",\n \"breaststroker\",\n \"breeder, stock_breeder\",\n \"brick\",\n \"bride\",\n \"bridesmaid, maid_of_honor\",\n \"bridge_agent\",\n \"broadcast_journalist\",\n \"brother\",\n \"brother-in-law\",\n \"browser\",\n \"brummie, brummy\",\n \"buddy, brother, chum, crony, pal, sidekick\",\n \"bull\",\n \"bully\",\n \"bunny, bunny_girl\",\n \"burglar\",\n \"bursar\",\n \"busboy, waiter's_assistant\",\n \"business_editor\",\n \"business_traveler\",\n \"buster\",\n \"busybody, nosy-parker, nosey-parker, quidnunc\",\n \"buttinsky\",\n \"cabinetmaker, furniture_maker\",\n \"caddie, golf_caddie\",\n \"cadet, plebe\",\n \"caller, caller-out\",\n \"call_girl\",\n \"calligrapher, calligraphist\",\n \"campaigner, candidate, nominee\",\n \"camper\",\n \"camp_follower\",\n \"candidate, prospect\",\n \"canonist\",\n \"capitalist\",\n \"captain, headwaiter, maitre_d'hotel, maitre_d'\",\n \"captain, senior_pilot\",\n \"captain\",\n \"captain, chieftain\",\n \"captive\",\n \"captive\",\n \"cardinal\",\n \"cardiologist, heart_specialist, heart_surgeon\",\n \"card_player\",\n \"cardsharp, card_sharp, cardsharper, card_sharper, sharper, sharpie, sharpy, card_shark\",\n \"careerist\",\n \"career_man\",\n \"caregiver\",\n \"caretaker\",\n \"caretaker\",\n \"caricaturist\",\n \"carillonneur\",\n \"caroler, caroller\",\n \"carpenter\",\n \"carper, niggler\",\n \"cartesian\",\n \"cashier\",\n \"casualty, injured_party\",\n \"casualty\",\n \"casuist, sophist\",\n \"catechist\",\n \"catechumen, neophyte\",\n \"caterer\",\n \"catholicos\",\n \"cat_fancier\",\n \"cavalier, royalist\",\n \"cavalryman, trooper\",\n \"caveman, cave_man, cave_dweller, troglodyte\",\n \"celebrant\",\n \"celebrant, celebrator, celebrater\",\n \"celebrity, famous_person\",\n \"cellist, violoncellist\",\n \"censor\",\n \"censor\",\n \"centenarian\",\n \"centrist, middle_of_the_roader, moderate, moderationist\",\n \"centurion\",\n \"certified_public_accountant, cpa\",\n \"chachka, tsatske, tshatshke, tchotchke, tchotchkeleh\",\n \"chambermaid, fille_de_chambre\",\n \"chameleon\",\n \"champion, champ, title-holder\",\n \"chandler\",\n \"prison_chaplain\",\n \"charcoal_burner\",\n \"charge_d'affaires\",\n \"charioteer\",\n \"charmer, beguiler\",\n \"chartered_accountant\",\n \"chartist, technical_analyst\",\n \"charwoman, char, cleaning_woman, cleaning_lady, woman\",\n \"male_chauvinist, sexist\",\n \"cheapskate, tightwad\",\n \"chechen\",\n \"checker\",\n \"cheerer\",\n \"cheerleader\",\n \"cheerleader\",\n \"cheops, khufu\",\n \"chess_master\",\n \"chief_executive_officer, ceo, chief_operating_officer\",\n \"chief_of_staff\",\n \"chief_petty_officer\",\n \"chief_secretary\",\n \"child, kid, youngster, minor, shaver, nipper, small_fry, tiddler, tike, tyke, fry, nestling\",\n \"child, kid\",\n \"child, baby\",\n \"child_prodigy, infant_prodigy, wonder_child\",\n \"chimneysweeper, chimneysweep, sweep\",\n \"chiropractor\",\n \"chit\",\n \"choker\",\n \"choragus\",\n \"choreographer\",\n \"chorus_girl, showgirl, chorine\",\n \"chosen\",\n \"cicerone\",\n \"cigar_smoker\",\n \"cipher, cypher, nobody, nonentity\",\n \"circus_acrobat\",\n \"citizen\",\n \"city_editor\",\n \"city_father\",\n \"city_man\",\n \"city_slicker, city_boy\",\n \"civic_leader, civil_leader\",\n \"civil_rights_leader, civil_rights_worker, civil_rights_activist\",\n \"cleaner\",\n \"clergyman, reverend, man_of_the_cloth\",\n \"cleric, churchman, divine, ecclesiastic\",\n \"clerk\",\n \"clever_dick, clever_clogs\",\n \"climatologist\",\n \"climber\",\n \"clinician\",\n \"closer, finisher\",\n \"closet_queen\",\n \"clown, buffoon, goof, goofball, merry_andrew\",\n \"clown, buffoon\",\n \"coach, private_instructor, tutor\",\n \"coach, manager, handler\",\n \"pitching_coach\",\n \"coachman\",\n \"coal_miner, collier, pitman\",\n \"coastguardsman\",\n \"cobber\",\n \"cobbler, shoemaker\",\n \"codger, old_codger\",\n \"co-beneficiary\",\n \"cog\",\n \"cognitive_neuroscientist\",\n \"coiffeur\",\n \"coiner\",\n \"collaborator, cooperator, partner, pardner\",\n \"colleen\",\n \"college_student, university_student\",\n \"collegian, college_man, college_boy\",\n \"colonial\",\n \"colonialist\",\n \"colonizer, coloniser\",\n \"coloratura, coloratura_soprano\",\n \"color_guard\",\n \"colossus, behemoth, giant, heavyweight, titan\",\n \"comedian\",\n \"comedienne\",\n \"comer\",\n \"commander\",\n \"commander_in_chief, generalissimo\",\n \"commanding_officer, commandant, commander\",\n \"commissar, political_commissar\",\n \"commissioned_officer\",\n \"commissioned_military_officer\",\n \"commissioner\",\n \"commissioner\",\n \"committee_member\",\n \"committeewoman\",\n \"commodore\",\n \"communicant\",\n \"communist, commie\",\n \"communist\",\n \"commuter\",\n \"compere\",\n \"complexifier\",\n \"compulsive\",\n \"computational_linguist\",\n \"computer_scientist\",\n \"computer_user\",\n \"comrade\",\n \"concert-goer, music_lover\",\n \"conciliator, make-peace, pacifier, peacemaker, reconciler\",\n \"conductor\",\n \"confectioner, candymaker\",\n \"confederate\",\n \"confessor\",\n \"confidant, intimate\",\n \"confucian, confucianist\",\n \"rep\",\n \"conqueror, vanquisher\",\n \"conservative\",\n \"nonconformist, chapelgoer\",\n \"anglican\",\n \"consignee\",\n \"consigner, consignor\",\n \"constable\",\n \"constructivist\",\n \"contractor\",\n \"contralto\",\n \"contributor\",\n \"control_freak\",\n \"convalescent\",\n \"convener\",\n \"convict, con, inmate, yard_bird, yardbird\",\n \"copilot, co-pilot\",\n \"copycat, imitator, emulator, ape, aper\",\n \"coreligionist\",\n \"cornerback\",\n \"corporatist\",\n \"correspondent, letter_writer\",\n \"cosmetician\",\n \"cosmopolitan, cosmopolite\",\n \"cossack\",\n \"cost_accountant\",\n \"co-star\",\n \"costumier, costumer, costume_designer\",\n \"cotter, cottier\",\n \"cotter, cottar\",\n \"counselor, counsellor\",\n \"counterterrorist\",\n \"counterspy, mole\",\n \"countess\",\n \"compromiser\",\n \"countrywoman\",\n \"county_agent, agricultural_agent, extension_agent\",\n \"courtier\",\n \"cousin, first_cousin, cousin-german, full_cousin\",\n \"cover_girl, pin-up, lovely\",\n \"cow\",\n \"craftsman, artisan, journeyman, artificer\",\n \"craftsman, crafter\",\n \"crapshooter\",\n \"crazy, loony, looney, nutcase, weirdo\",\n \"creature, wight\",\n \"creditor\",\n \"creep, weirdo, weirdie, weirdy, spook\",\n \"criminologist\",\n \"critic\",\n \"croesus\",\n \"cross-examiner, cross-questioner\",\n \"crossover_voter, crossover\",\n \"croupier\",\n \"crown_prince\",\n \"crown_princess\",\n \"cryptanalyst, cryptographer, cryptologist\",\n \"cub_scout\",\n \"cuckold\",\n \"cultist\",\n \"curandera\",\n \"curate, minister_of_religion, minister, parson, pastor, rector\",\n \"curator, conservator\",\n \"customer_agent\",\n \"cutter, carver\",\n \"cyberpunk\",\n \"cyborg, bionic_man, bionic_woman\",\n \"cymbalist\",\n \"cynic\",\n \"cytogeneticist\",\n \"cytologist\",\n \"czar\",\n \"czar, tsar, tzar\",\n \"dad, dada, daddy, pa, papa, pappa, pop\",\n \"dairyman\",\n \"dalai_lama, grand_lama\",\n \"dallier, dillydallier, dilly-dallier, mope, lounger\",\n \"dancer, professional_dancer, terpsichorean\",\n \"dancer, social_dancer\",\n \"clog_dancer\",\n \"dancing-master, dance_master\",\n \"dark_horse\",\n \"darling, favorite, favourite, pet, dearie, deary, ducky\",\n \"date, escort\",\n \"daughter, girl\",\n \"dawdler, drone, laggard, lagger, trailer, poke\",\n \"day_boarder\",\n \"day_laborer, day_labourer\",\n \"deacon, protestant_deacon\",\n \"deaconess\",\n \"deadeye\",\n \"deipnosophist\",\n \"dropout\",\n \"deadhead\",\n \"deaf_person\",\n \"debtor, debitor\",\n \"deckhand, roustabout\",\n \"defamer, maligner, slanderer, vilifier, libeler, backbiter, traducer\",\n \"defense_contractor\",\n \"deist, freethinker\",\n \"delegate\",\n \"deliveryman, delivery_boy, deliverer\",\n \"demagogue, demagog, rabble-rouser\",\n \"demigod, superman, ubermensch\",\n \"demographer, demographist, population_scientist\",\n \"demonstrator, protester\",\n \"den_mother\",\n \"department_head\",\n \"depositor\",\n \"deputy\",\n \"dermatologist, skin_doctor\",\n \"descender\",\n \"designated_hitter\",\n \"designer, intriguer\",\n \"desk_clerk, hotel_desk_clerk, hotel_clerk\",\n \"desk_officer\",\n \"desk_sergeant, deskman, station_keeper\",\n \"detainee, political_detainee\",\n \"detective, investigator, tec, police_detective\",\n \"detective\",\n \"detractor, disparager, depreciator, knocker\",\n \"developer\",\n \"deviationist\",\n \"devisee\",\n \"devisor\",\n \"devourer\",\n \"dialectician\",\n \"diarist, diary_keeper, journalist\",\n \"dietician, dietitian, nutritionist\",\n \"diocesan\",\n \"director, theater_director, theatre_director\",\n \"director\",\n \"dirty_old_man\",\n \"disbeliever, nonbeliever, unbeliever\",\n \"disk_jockey, disc_jockey, dj\",\n \"dispatcher\",\n \"distortionist\",\n \"distributor, distributer\",\n \"district_attorney, da\",\n \"district_manager\",\n \"diver, plunger\",\n \"divorcee, grass_widow\",\n \"ex-wife, ex\",\n \"divorce_lawyer\",\n \"docent\",\n \"doctor, doc, physician, md, dr., medico\",\n \"dodo, fogy, fogey, fossil\",\n \"doge\",\n \"dog_in_the_manger\",\n \"dogmatist, doctrinaire\",\n \"dolichocephalic\",\n \"domestic_partner, significant_other, spousal_equivalent, spouse_equivalent\",\n \"dominican\",\n \"dominus, dominie, domine, dominee\",\n \"don, father\",\n \"donatist\",\n \"donna\",\n \"dosser, street_person\",\n \"double, image, look-alike\",\n \"double-crosser, double-dealer, two-timer, betrayer, traitor\",\n \"down-and-out\",\n \"doyenne\",\n \"draftsman, drawer\",\n \"dramatist, playwright\",\n \"dreamer\",\n \"dressmaker, modiste, needlewoman, seamstress, sempstress\",\n \"dressmaker's_model\",\n \"dribbler, driveller, slobberer, drooler\",\n \"dribbler\",\n \"drinker, imbiber, toper, juicer\",\n \"drinker\",\n \"drug_addict, junkie, junky\",\n \"drug_user, substance_abuser, user\",\n \"druid\",\n \"drum_majorette, majorette\",\n \"drummer\",\n \"drunk\",\n \"drunkard, drunk, rummy, sot, inebriate, wino\",\n \"druze, druse\",\n \"dry, prohibitionist\",\n \"dry_nurse\",\n \"duchess\",\n \"duke\",\n \"duffer\",\n \"dunker\",\n \"dutch_uncle\",\n \"dyspeptic\",\n \"eager_beaver, busy_bee, live_wire, sharpie, sharpy\",\n \"earl\",\n \"earner, wage_earner\",\n \"eavesdropper\",\n \"eccentric, eccentric_person, flake, oddball, geek\",\n \"eclectic, eclecticist\",\n \"econometrician, econometrist\",\n \"economist, economic_expert\",\n \"ectomorph\",\n \"editor, editor_in_chief\",\n \"egocentric, egoist\",\n \"egotist, egoist, swellhead\",\n \"ejaculator\",\n \"elder\",\n \"elder_statesman\",\n \"elected_official\",\n \"electrician, lineman, linesman\",\n \"elegist\",\n \"elocutionist\",\n \"emancipator, manumitter\",\n \"embryologist\",\n \"emeritus\",\n \"emigrant, emigre, emigree, outgoer\",\n \"emissary, envoy\",\n \"empress\",\n \"employee\",\n \"employer\",\n \"enchantress, witch\",\n \"enchantress, temptress, siren, delilah, femme_fatale\",\n \"encyclopedist, encyclopaedist\",\n \"endomorph\",\n \"enemy, foe, foeman, opposition\",\n \"energizer, energiser, vitalizer, vitaliser, animator\",\n \"end_man\",\n \"end_man, corner_man\",\n \"endorser, indorser\",\n \"enjoyer\",\n \"enlisted_woman\",\n \"enophile, oenophile\",\n \"entrant\",\n \"entrant\",\n \"entrepreneur, enterpriser\",\n \"envoy, envoy_extraordinary, minister_plenipotentiary\",\n \"enzymologist\",\n \"eparch\",\n \"epidemiologist\",\n \"epigone, epigon\",\n \"epileptic\",\n \"episcopalian\",\n \"equerry\",\n \"equerry\",\n \"erotic\",\n \"escapee\",\n \"escapist, dreamer, wishful_thinker\",\n \"eskimo, esquimau, inuit\",\n \"espionage_agent\",\n \"esthetician, aesthetician\",\n \"etcher\",\n \"ethnologist\",\n \"etonian\",\n \"etymologist\",\n \"evangelist, revivalist, gospeler, gospeller\",\n \"evangelist\",\n \"event_planner\",\n \"examiner, inspector\",\n \"examiner, tester, quizzer\",\n \"exarch\",\n \"executant\",\n \"executive_secretary\",\n \"executive_vice_president\",\n \"executrix\",\n \"exegete\",\n \"exhibitor, exhibitioner, shower\",\n \"exhibitionist, show-off\",\n \"exile, expatriate, expat\",\n \"existentialist, existentialist_philosopher, existential_philosopher\",\n \"exorcist, exorciser\",\n \"ex-spouse\",\n \"extern, medical_extern\",\n \"extremist\",\n \"extrovert, extravert\",\n \"eyewitness\",\n \"facilitator\",\n \"fairy_godmother\",\n \"falangist, phalangist\",\n \"falconer, hawker\",\n \"falsifier\",\n \"familiar\",\n \"fan, buff, devotee, lover\",\n \"fanatic, fiend\",\n \"fancier, enthusiast\",\n \"farm_boy\",\n \"farmer, husbandman, granger, sodbuster\",\n \"farmhand, fieldhand, field_hand, farm_worker\",\n \"fascist\",\n \"fascista\",\n \"fatalist, determinist, predestinarian, predestinationist\",\n \"father, male_parent, begetter\",\n \"father, padre\",\n \"father-figure\",\n \"father-in-law\",\n \"fauntleroy, little_lord_fauntleroy\",\n \"fauve, fauvist\",\n \"favorite_son\",\n \"featherweight\",\n \"federalist\",\n \"fellow_traveler, fellow_traveller\",\n \"female_aristocrat\",\n \"female_offspring\",\n \"female_child, girl, little_girl\",\n \"fence\",\n \"fiance, groom-to-be\",\n \"fielder, fieldsman\",\n \"field_judge\",\n \"fighter_pilot\",\n \"filer\",\n \"film_director, director\",\n \"finder\",\n \"fire_chief, fire_marshal\",\n \"fire-eater, fire-swallower\",\n \"fire-eater, hothead\",\n \"fireman, firefighter, fire_fighter, fire-eater\",\n \"fire_marshall\",\n \"fire_walker\",\n \"first_baseman, first_sacker\",\n \"firstborn, eldest\",\n \"first_lady\",\n \"first_lieutenant, 1st_lieutenant\",\n \"first_offender\",\n \"first_sergeant, sergeant_first_class\",\n \"fishmonger, fishwife\",\n \"flagellant\",\n \"flag_officer\",\n \"flak_catcher, flak, flack_catcher, flack\",\n \"flanker_back, flanker\",\n \"flapper\",\n \"flatmate\",\n \"flatterer, adulator\",\n \"flibbertigibbet, foolish_woman\",\n \"flight_surgeon\",\n \"floorwalker, shopwalker\",\n \"flop, dud, washout\",\n \"florentine\",\n \"flower_girl\",\n \"flower_girl\",\n \"flutist, flautist, flute_player\",\n \"fly-by-night\",\n \"flyweight\",\n \"flyweight\",\n \"foe, enemy\",\n \"folk_dancer\",\n \"folk_poet\",\n \"follower\",\n \"football_hero\",\n \"football_player, footballer\",\n \"footman\",\n \"forefather, father, sire\",\n \"foremother\",\n \"foreign_agent\",\n \"foreigner, outsider\",\n \"boss\",\n \"foreman\",\n \"forester, tree_farmer, arboriculturist\",\n \"forewoman\",\n \"forger, counterfeiter\",\n \"forward\",\n \"foster-brother, foster_brother\",\n \"foster-father, foster_father\",\n \"foster-mother, foster_mother\",\n \"foster-sister, foster_sister\",\n \"foster-son, foster_son\",\n \"founder, beginner, founding_father, father\",\n \"foundress\",\n \"four-minute_man\",\n \"framer\",\n \"francophobe\",\n \"freak, monster, monstrosity, lusus_naturae\",\n \"free_agent, free_spirit, freewheeler\",\n \"free_agent\",\n \"freedom_rider\",\n \"free-liver\",\n \"freeloader\",\n \"free_trader\",\n \"freudian\",\n \"friar, mendicant\",\n \"monk, monastic\",\n \"frontierswoman\",\n \"front_man, front, figurehead, nominal_head, straw_man, strawman\",\n \"frotteur\",\n \"fucker\",\n \"fucker\",\n \"fuddy-duddy\",\n \"fullback\",\n \"funambulist, tightrope_walker\",\n \"fundamentalist\",\n \"fundraiser\",\n \"futurist\",\n \"gadgeteer\",\n \"gagman, gagster, gagwriter\",\n \"gagman, standup_comedian\",\n \"gainer, weight_gainer\",\n \"gal\",\n \"galoot\",\n \"gambist\",\n \"gambler\",\n \"gamine\",\n \"garbage_man, garbageman, garbage_collector, garbage_carter, garbage_hauler, refuse_collector, dustman\",\n \"gardener\",\n \"garment_cutter\",\n \"garroter, garrotter, strangler, throttler, choker\",\n \"gasman\",\n \"gastroenterologist\",\n \"gatherer\",\n \"gawker\",\n \"gendarme\",\n \"general, full_general\",\n \"generator, source, author\",\n \"geneticist\",\n \"genitor\",\n \"gent\",\n \"geologist\",\n \"geophysicist\",\n \"ghostwriter, ghost\",\n \"gibson_girl\",\n \"girl, miss, missy, young_lady, young_woman, fille\",\n \"girlfriend, girl, lady_friend\",\n \"girlfriend\",\n \"girl_wonder\",\n \"girondist, girondin\",\n \"gitano\",\n \"gladiator\",\n \"glassblower\",\n \"gleaner\",\n \"goat_herder, goatherd\",\n \"godchild\",\n \"godfather\",\n \"godparent\",\n \"godson\",\n \"gofer\",\n \"goffer, gopher\",\n \"goldsmith, goldworker, gold-worker\",\n \"golfer, golf_player, linksman\",\n \"gondolier, gondoliere\",\n \"good_guy\",\n \"good_old_boy, good_ole_boy, good_ol'_boy\",\n \"good_samaritan\",\n \"gossip_columnist\",\n \"gouger\",\n \"governor_general\",\n \"grabber\",\n \"grader\",\n \"graduate_nurse, trained_nurse\",\n \"grammarian, syntactician\",\n \"granddaughter\",\n \"grande_dame\",\n \"grandfather, gramps, granddad, grandad, granddaddy, grandpa\",\n \"grand_inquisitor\",\n \"grandma, grandmother, granny, grannie, gran, nan, nanna\",\n \"grandmaster\",\n \"grandparent\",\n \"grantee\",\n \"granter\",\n \"grass_widower, divorced_man\",\n \"great-aunt, grandaunt\",\n \"great_grandchild\",\n \"great_granddaughter\",\n \"great_grandmother\",\n \"great_grandparent\",\n \"great_grandson\",\n \"great-nephew, grandnephew\",\n \"great-niece, grandniece\",\n \"green_beret\",\n \"grenadier, grenade_thrower\",\n \"greeter, saluter, welcomer\",\n \"gringo\",\n \"grinner\",\n \"grocer\",\n \"groom, bridegroom\",\n \"groom, bridegroom\",\n \"grouch, grump, crank, churl, crosspatch\",\n \"group_captain\",\n \"grunter\",\n \"prison_guard, jailer, jailor, gaoler, screw, turnkey\",\n \"guard\",\n \"guesser\",\n \"guest, invitee\",\n \"guest\",\n \"guest_of_honor\",\n \"guest_worker, guestworker\",\n \"guide\",\n \"guitarist, guitar_player\",\n \"gunnery_sergeant\",\n \"guru\",\n \"guru\",\n \"guvnor\",\n \"guy, cat, hombre, bozo\",\n \"gymnast\",\n \"gym_rat\",\n \"gynecologist, gynaecologist, woman's_doctor\",\n \"gypsy, gipsy, romany, rommany, romani, roma, bohemian\",\n \"hack, drudge, hacker\",\n \"hacker, cyber-terrorist, cyberpunk\",\n \"haggler\",\n \"hairdresser, hairstylist, stylist, styler\",\n \"hakim, hakeem\",\n \"hakka\",\n \"halberdier\",\n \"halfback\",\n \"half_blood\",\n \"hand\",\n \"animal_trainer, handler\",\n \"handyman, jack_of_all_trades, odd-job_man\",\n \"hang_glider\",\n \"hardliner\",\n \"harlequin\",\n \"harmonizer, harmoniser\",\n \"hash_head\",\n \"hatchet_man, iceman\",\n \"hater\",\n \"hatmaker, hatter, milliner, modiste\",\n \"headman, tribal_chief, chieftain, chief\",\n \"headmaster, schoolmaster, master\",\n \"head_nurse\",\n \"hearer, listener, auditor, attender\",\n \"heartbreaker\",\n \"heathen, pagan, gentile, infidel\",\n \"heavyweight\",\n \"heavy\",\n \"heckler, badgerer\",\n \"hedger\",\n \"hedger, equivocator, tergiversator\",\n \"hedonist, pagan, pleasure_seeker\",\n \"heir, inheritor, heritor\",\n \"heir_apparent\",\n \"heiress, inheritress, inheritrix\",\n \"heir_presumptive\",\n \"hellion, heller, devil\",\n \"helmsman, steersman, steerer\",\n \"hire\",\n \"hematologist, haematologist\",\n \"hemiplegic\",\n \"herald, trumpeter\",\n \"herbalist, herb_doctor\",\n \"herder, herdsman, drover\",\n \"hermaphrodite, intersex, gynandromorph, androgyne, epicene, epicene_person\",\n \"heroine\",\n \"heroin_addict\",\n \"hero_worshiper, hero_worshipper\",\n \"herr\",\n \"highbinder\",\n \"highbrow\",\n \"high_commissioner\",\n \"highflier, highflyer\",\n \"highlander, scottish_highlander, highland_scot\",\n \"high-muck-a-muck, pooh-bah\",\n \"high_priest\",\n \"highjacker, hijacker\",\n \"hireling, pensionary\",\n \"historian, historiographer\",\n \"hitchhiker\",\n \"hitter, striker\",\n \"hobbyist\",\n \"holdout\",\n \"holdover, hangover\",\n \"holdup_man, stickup_man\",\n \"homeboy\",\n \"homeboy\",\n \"home_buyer\",\n \"homegirl\",\n \"homeless, homeless_person\",\n \"homeopath, homoeopath\",\n \"honest_woman\",\n \"honor_guard, guard_of_honor\",\n \"hooker\",\n \"hoper\",\n \"hornist\",\n \"horseman, equestrian, horseback_rider\",\n \"horse_trader\",\n \"horsewoman\",\n \"horse_wrangler, wrangler\",\n \"horticulturist, plantsman\",\n \"hospital_chaplain\",\n \"host, innkeeper, boniface\",\n \"host\",\n \"hostess\",\n \"hotelier, hotelkeeper, hotel_manager, hotelman, hosteller\",\n \"housekeeper\",\n \"housemaster\",\n \"housemate\",\n \"house_physician, resident, resident_physician\",\n \"house_sitter\",\n \"housing_commissioner\",\n \"huckster, cheap-jack\",\n \"hugger\",\n \"humanist, humanitarian\",\n \"humanitarian, do-gooder, improver\",\n \"hunk\",\n \"huntress\",\n \"ex-husband, ex\",\n \"hydrologist\",\n \"hyperope\",\n \"hypertensive\",\n \"hypnotist, hypnotizer, hypnotiser, mesmerist, mesmerizer\",\n \"hypocrite, dissembler, dissimulator, phony, phoney, pretender\",\n \"iceman\",\n \"iconoclast\",\n \"ideologist, ideologue\",\n \"idol, matinee_idol\",\n \"idolizer, idoliser\",\n \"imam, imaum\",\n \"imperialist\",\n \"important_person, influential_person, personage\",\n \"inamorato\",\n \"incumbent, officeholder\",\n \"incurable\",\n \"inductee\",\n \"industrialist\",\n \"infanticide\",\n \"inferior\",\n \"infernal\",\n \"infielder\",\n \"infiltrator\",\n \"informer, betrayer, rat, squealer, blabber\",\n \"ingenue\",\n \"ingenue\",\n \"polymath\",\n \"in-law, relative-in-law\",\n \"inquiry_agent\",\n \"inspector\",\n \"inspector_general\",\n \"instigator, initiator\",\n \"insurance_broker, insurance_agent, general_agent, underwriter\",\n \"insurgent, insurrectionist, freedom_fighter, rebel\",\n \"intelligence_analyst\",\n \"interior_designer, designer, interior_decorator, house_decorator, room_decorator, decorator\",\n \"interlocutor, conversational_partner\",\n \"interlocutor, middleman\",\n \"international_grandmaster\",\n \"internationalist\",\n \"internist\",\n \"interpreter, translator\",\n \"interpreter\",\n \"intervenor\",\n \"introvert\",\n \"invader, encroacher\",\n \"invalidator, voider, nullifier\",\n \"investigator\",\n \"investor\",\n \"invigilator\",\n \"irreligionist\",\n \"ivy_leaguer\",\n \"jack_of_all_trades\",\n \"jacksonian\",\n \"jane_doe\",\n \"janissary\",\n \"jat\",\n \"javanese, javan\",\n \"jekyll_and_hyde\",\n \"jester, fool, motley_fool\",\n \"jesuit\",\n \"jezebel\",\n \"jilt\",\n \"jobber, middleman, wholesaler\",\n \"job_candidate\",\n \"job's_comforter\",\n \"jockey\",\n \"john_doe\",\n \"journalist\",\n \"judge, justice, jurist\",\n \"judge_advocate\",\n \"juggler\",\n \"jungian\",\n \"junior\",\n \"junior\",\n \"junior, jr, jnr\",\n \"junior_lightweight\",\n \"junior_middleweight\",\n \"jurist, legal_expert\",\n \"juror, juryman, jurywoman\",\n \"justice_of_the_peace\",\n \"justiciar, justiciary\",\n \"kachina\",\n \"keyboardist\",\n \"khedive\",\n \"kingmaker\",\n \"king, queen, world-beater\",\n \"king's_counsel\",\n \"counsel_to_the_crown\",\n \"kin, kinsperson, family\",\n \"enate, matrikin, matrilineal_kin, matrisib, matrilineal_sib\",\n \"kink\",\n \"kinswoman\",\n \"kisser, osculator\",\n \"kitchen_help\",\n \"kitchen_police, kp\",\n \"klansman, ku_kluxer, kluxer\",\n \"kleptomaniac\",\n \"kneeler\",\n \"knight\",\n \"knocker\",\n \"knower, apprehender\",\n \"know-it-all, know-all\",\n \"kolkhoznik\",\n \"kshatriya\",\n \"labor_coach, birthing_coach, doula, monitrice\",\n \"laborer, manual_laborer, labourer, jack\",\n \"labourite\",\n \"lady\",\n \"lady-in-waiting\",\n \"lady's_maid\",\n \"lama\",\n \"lamb, dear\",\n \"lame_duck\",\n \"lamplighter\",\n \"land_agent\",\n \"landgrave\",\n \"landlubber, lubber, landsman\",\n \"landlubber, landsman, landman\",\n \"landowner, landholder, property_owner\",\n \"landscape_architect, landscape_gardener, landscaper, landscapist\",\n \"langlaufer\",\n \"languisher\",\n \"lapidary, lapidarist\",\n \"lass, lassie, young_girl, jeune_fille\",\n \"latin\",\n \"latin\",\n \"latitudinarian\",\n \"jehovah's_witness\",\n \"law_agent\",\n \"lawgiver, lawmaker\",\n \"lawman, law_officer, peace_officer\",\n \"law_student\",\n \"lawyer, attorney\",\n \"lay_reader\",\n \"lazybones\",\n \"leaker\",\n \"leaseholder, lessee\",\n \"lector, lecturer, reader\",\n \"lector, reader\",\n \"lecturer\",\n \"left-hander, lefty, southpaw\",\n \"legal_representative\",\n \"legate, official_emissary\",\n \"legatee\",\n \"legionnaire, legionary\",\n \"letterman\",\n \"liberator\",\n \"licenser\",\n \"licentiate\",\n \"lieutenant\",\n \"lieutenant_colonel, light_colonel\",\n \"lieutenant_commander\",\n \"lieutenant_junior_grade, lieutenant_jg\",\n \"life\",\n \"lifeguard, lifesaver\",\n \"life_tenant\",\n \"light_flyweight\",\n \"light_heavyweight, cruiserweight\",\n \"light_heavyweight\",\n \"light-o'-love, light-of-love\",\n \"lightweight\",\n \"lightweight\",\n \"lightweight\",\n \"lilliputian\",\n \"limnologist\",\n \"lineman\",\n \"line_officer\",\n \"lion-hunter\",\n \"lisper\",\n \"lister\",\n \"literary_critic\",\n \"literate, literate_person\",\n \"litigant, litigator\",\n \"litterer, litterbug, litter_lout\",\n \"little_brother\",\n \"little_sister\",\n \"lobbyist\",\n \"locksmith\",\n \"locum_tenens, locum\",\n \"lord, noble, nobleman\",\n \"loser\",\n \"loser, also-ran\",\n \"failure, loser, nonstarter, unsuccessful_person\",\n \"lothario\",\n \"loudmouth, blusterer\",\n \"lowerclassman, underclassman\",\n \"lowlander, scottish_lowlander, lowland_scot\",\n \"loyalist, stalwart\",\n \"luddite\",\n \"lumberman, lumberjack, logger, feller, faller\",\n \"lumper\",\n \"bedlamite\",\n \"pyromaniac\",\n \"lutist, lutanist, lutenist\",\n \"lutheran\",\n \"lyricist, lyrist\",\n \"macebearer, mace, macer\",\n \"machinist, mechanic, shop_mechanic\",\n \"madame\",\n \"maenad\",\n \"maestro, master\",\n \"magdalen\",\n \"magician, prestidigitator, conjurer, conjuror, illusionist\",\n \"magus\",\n \"maharani, maharanee\",\n \"mahatma\",\n \"maid, maiden\",\n \"maid, maidservant, housemaid, amah\",\n \"major\",\n \"major\",\n \"major-domo, seneschal\",\n \"maker, shaper\",\n \"malahini\",\n \"malcontent\",\n \"malik\",\n \"malingerer, skulker, shammer\",\n \"malthusian\",\n \"adonis\",\n \"man\",\n \"man\",\n \"manageress\",\n \"mandarin\",\n \"maneuverer, manoeuvrer\",\n \"maniac\",\n \"manichaean, manichean, manichee\",\n \"manicurist\",\n \"manipulator\",\n \"man-at-arms\",\n \"man_of_action, man_of_deeds\",\n \"man_of_letters\",\n \"manufacturer, producer\",\n \"marcher, parader\",\n \"marchioness, marquise\",\n \"margrave\",\n \"margrave\",\n \"marine, devil_dog, leatherneck, shipboard_soldier\",\n \"marquess\",\n \"marquis, marquess\",\n \"marshal, marshall\",\n \"martinet, disciplinarian, moralist\",\n \"mascot\",\n \"masochist\",\n \"mason, stonemason\",\n \"masquerader, masker, masquer\",\n \"masseur\",\n \"masseuse\",\n \"master\",\n \"master, captain, sea_captain, skipper\",\n \"master-at-arms\",\n \"master_of_ceremonies, emcee, host\",\n \"masturbator, onanist\",\n \"matchmaker, matcher, marriage_broker\",\n \"mate, first_mate\",\n \"mate\",\n \"mate\",\n \"mater\",\n \"material\",\n \"materialist\",\n \"matriarch, materfamilias\",\n \"matriarch\",\n \"matriculate\",\n \"matron\",\n \"mayor, city_manager\",\n \"mayoress\",\n \"mechanical_engineer\",\n \"medalist, medallist, medal_winner\",\n \"medical_officer, medic\",\n \"medical_practitioner, medical_man\",\n \"medical_scientist\",\n \"medium, spiritualist, sensitive\",\n \"megalomaniac\",\n \"melancholic, melancholiac\",\n \"melkite, melchite\",\n \"melter\",\n \"nonmember\",\n \"board_member\",\n \"clansman, clanswoman, clan_member\",\n \"memorizer, memoriser\",\n \"mendelian\",\n \"mender, repairer, fixer\",\n \"mesoamerican\",\n \"messmate\",\n \"mestiza\",\n \"meteorologist\",\n \"meter_maid\",\n \"methodist\",\n \"metis\",\n \"metropolitan\",\n \"mezzo-soprano, mezzo\",\n \"microeconomist, microeconomic_expert\",\n \"middle-aged_man\",\n \"middlebrow\",\n \"middleweight\",\n \"midwife, accoucheuse\",\n \"mikado, tenno\",\n \"milanese\",\n \"miler\",\n \"miles_gloriosus\",\n \"military_attache\",\n \"military_chaplain, padre, holy_joe, sky_pilot\",\n \"military_leader\",\n \"military_officer, officer\",\n \"military_policeman, mp\",\n \"mill_agent\",\n \"mill-hand, factory_worker\",\n \"millionairess\",\n \"millwright\",\n \"minder\",\n \"mining_engineer\",\n \"minister, government_minister\",\n \"ministrant\",\n \"minor_leaguer, bush_leaguer\",\n \"minuteman\",\n \"misanthrope, misanthropist\",\n \"misfit\",\n \"mistress\",\n \"mistress, kept_woman, fancy_woman\",\n \"mixed-blood\",\n \"model, poser\",\n \"class_act\",\n \"modeler, modeller\",\n \"modifier\",\n \"molecular_biologist\",\n \"monegasque, monacan\",\n \"monetarist\",\n \"moneygrubber\",\n \"moneymaker\",\n \"mongoloid\",\n \"monolingual\",\n \"monologist\",\n \"moonlighter\",\n \"moralist\",\n \"morosoph\",\n \"morris_dancer\",\n \"mortal_enemy\",\n \"mortgagee, mortgage_holder\",\n \"mortician, undertaker, funeral_undertaker, funeral_director\",\n \"moss-trooper\",\n \"mother, female_parent\",\n \"mother\",\n \"mother\",\n \"mother_figure\",\n \"mother_hen\",\n \"mother-in-law\",\n \"mother's_boy, mamma's_boy, mama's_boy\",\n \"mother's_daughter\",\n \"motorcycle_cop, motorcycle_policeman, speed_cop\",\n \"motorcyclist\",\n \"mound_builder\",\n \"mountebank, charlatan\",\n \"mourner, griever, sorrower, lamenter\",\n \"mouthpiece, mouth\",\n \"mover\",\n \"moviegoer, motion-picture_fan\",\n \"muffin_man\",\n \"mugwump, independent, fencesitter\",\n \"mullah, mollah, mulla\",\n \"muncher\",\n \"murderess\",\n \"murder_suspect\",\n \"musher\",\n \"musician, instrumentalist, player\",\n \"musicologist\",\n \"music_teacher\",\n \"musketeer\",\n \"muslimah\",\n \"mutilator, maimer, mangler\",\n \"mutineer\",\n \"mute, deaf-mute, deaf-and-dumb_person\",\n \"mutterer, mumbler, murmurer\",\n \"muzzler\",\n \"mycenaen\",\n \"mycologist\",\n \"myope\",\n \"myrmidon\",\n \"mystic, religious_mystic\",\n \"mythologist\",\n \"naif\",\n \"nailer\",\n \"namby-pamby\",\n \"name_dropper\",\n \"namer\",\n \"nan\",\n \"nanny, nursemaid, nurse\",\n \"narc, nark, narcotics_agent\",\n \"narcissist, narcist\",\n \"nark, copper's_nark\",\n \"nationalist\",\n \"nautch_girl\",\n \"naval_commander\",\n \"navy_seal, seal\",\n \"obstructionist, obstructor, obstructer, resister, thwarter\",\n \"nazarene\",\n \"nazarene, ebionite\",\n \"nazi, german_nazi\",\n \"nebbish, nebbech\",\n \"necker\",\n \"neonate, newborn, newborn_infant, newborn_baby\",\n \"nephew\",\n \"neurobiologist\",\n \"neurologist, brain_doctor\",\n \"neurosurgeon, brain_surgeon\",\n \"neutral\",\n \"neutralist\",\n \"newcomer, fledgling, fledgeling, starter, neophyte, freshman, newbie, entrant\",\n \"newcomer\",\n \"new_dealer\",\n \"newspaper_editor\",\n \"newsreader, news_reader\",\n \"newtonian\",\n \"niece\",\n \"niggard, skinflint, scrooge, churl\",\n \"night_porter\",\n \"night_rider, nightrider\",\n \"nimby\",\n \"niqaabi\",\n \"nitpicker\",\n \"nobelist, nobel_laureate\",\n \"noc\",\n \"noncandidate\",\n \"noncommissioned_officer, noncom, enlisted_officer\",\n \"nondescript\",\n \"nondriver\",\n \"nonparticipant\",\n \"nonperson, unperson\",\n \"nonresident\",\n \"nonsmoker\",\n \"northern_baptist\",\n \"noticer\",\n \"novelist\",\n \"novitiate, novice\",\n \"nuclear_chemist, radiochemist\",\n \"nudger\",\n \"nullipara\",\n \"number_theorist\",\n \"nurse\",\n \"nursling, nurseling, suckling\",\n \"nymph, houri\",\n \"nymphet\",\n \"nympholept\",\n \"nymphomaniac, nympho\",\n \"oarswoman\",\n \"oboist\",\n \"obscurantist\",\n \"observer, commentator\",\n \"obstetrician, accoucheur\",\n \"occupier\",\n \"occultist\",\n \"wine_lover\",\n \"offerer, offeror\",\n \"office-bearer\",\n \"office_boy\",\n \"officeholder, officer\",\n \"officiant\",\n \"federal, fed, federal_official\",\n \"oilman\",\n \"oil_tycoon\",\n \"old-age_pensioner\",\n \"old_boy\",\n \"old_lady\",\n \"old_man\",\n \"oldster, old_person, senior_citizen, golden_ager\",\n \"old-timer, oldtimer, gaffer, old_geezer, antique\",\n \"old_woman\",\n \"oligarch\",\n \"olympian\",\n \"omnivore\",\n \"oncologist\",\n \"onlooker, looker-on\",\n \"onomancer\",\n \"operator\",\n \"opportunist, self-seeker\",\n \"optimist\",\n \"orangeman\",\n \"orator, speechmaker, rhetorician, public_speaker, speechifier\",\n \"orderly, hospital_attendant\",\n \"orderly\",\n \"orderly_sergeant\",\n \"ordinand\",\n \"ordinary\",\n \"organ-grinder\",\n \"organist\",\n \"organization_man\",\n \"organizer, organiser, arranger\",\n \"organizer, organiser, labor_organizer\",\n \"originator, conceiver, mastermind\",\n \"ornithologist, bird_watcher\",\n \"orphan\",\n \"orphan\",\n \"osteopath, osteopathist\",\n \"out-and-outer\",\n \"outdoorswoman\",\n \"outfielder\",\n \"outfielder\",\n \"right_fielder\",\n \"right-handed_pitcher, right-hander\",\n \"outlier\",\n \"owner-occupier\",\n \"oyabun\",\n \"packrat\",\n \"padrone\",\n \"padrone\",\n \"page, pageboy\",\n \"painter\",\n \"paleo-american, paleo-amerind, paleo-indian\",\n \"paleontologist, palaeontologist, fossilist\",\n \"pallbearer, bearer\",\n \"palmist, palmister, chiromancer\",\n \"pamperer, spoiler, coddler, mollycoddler\",\n \"panchen_lama\",\n \"panelist, panellist\",\n \"panhandler\",\n \"paparazzo\",\n \"paperboy\",\n \"paperhanger, paperer\",\n \"paperhanger\",\n \"papoose, pappoose\",\n \"pardoner\",\n \"paretic\",\n \"parishioner\",\n \"park_commissioner\",\n \"parliamentarian, member_of_parliament\",\n \"parliamentary_agent\",\n \"parodist, lampooner\",\n \"parricide\",\n \"parrot\",\n \"partaker, sharer\",\n \"part-timer\",\n \"party\",\n \"party_man, party_liner\",\n \"passenger, rider\",\n \"passer\",\n \"paster\",\n \"pater\",\n \"patient\",\n \"patriarch\",\n \"patriarch\",\n \"patriarch, paterfamilias\",\n \"patriot, nationalist\",\n \"patron, sponsor, supporter\",\n \"patternmaker\",\n \"pawnbroker\",\n \"payer, remunerator\",\n \"peacekeeper\",\n \"peasant\",\n \"pedant, bookworm, scholastic\",\n \"peddler, pedlar, packman, hawker, pitchman\",\n \"pederast, paederast, child_molester\",\n \"penologist\",\n \"pentathlete\",\n \"pentecostal, pentecostalist\",\n \"percussionist\",\n \"periodontist\",\n \"peshmerga\",\n \"personality\",\n \"personal_representative\",\n \"personage\",\n \"persona_grata\",\n \"persona_non_grata\",\n \"personification\",\n \"perspirer, sweater\",\n \"pervert, deviant, deviate, degenerate\",\n \"pessimist\",\n \"pest, blighter, cuss, pesterer, gadfly\",\n \"peter_pan\",\n \"petitioner, suppliant, supplicant, requester\",\n \"petit_juror, petty_juror\",\n \"pet_sitter, critter_sitter\",\n \"petter, fondler\",\n \"pharaoh, pharaoh_of_egypt\",\n \"pharmacist, druggist, chemist, apothecary, pill_pusher, pill_roller\",\n \"philanthropist, altruist\",\n \"philatelist, stamp_collector\",\n \"philosopher\",\n \"phonetician\",\n \"phonologist\",\n \"photojournalist\",\n \"photometrist, photometrician\",\n \"physical_therapist, physiotherapist\",\n \"physicist\",\n \"piano_maker\",\n \"picker, chooser, selector\",\n \"picnicker, picknicker\",\n \"pilgrim\",\n \"pill\",\n \"pillar, mainstay\",\n \"pill_head\",\n \"pilot\",\n \"piltdown_man, piltdown_hoax\",\n \"pimp, procurer, panderer, pander, pandar, fancy_man, ponce\",\n \"pipe_smoker\",\n \"pip-squeak, squirt, small_fry\",\n \"pisser, urinator\",\n \"pitcher, hurler, twirler\",\n \"pitchman\",\n \"placeman, placeseeker\",\n \"placer_miner\",\n \"plagiarist, plagiarizer, plagiariser, literary_pirate, pirate\",\n \"plainsman\",\n \"planner, contriver, deviser\",\n \"planter, plantation_owner\",\n \"plasterer\",\n \"platinum_blond, platinum_blonde\",\n \"platitudinarian\",\n \"playboy, man-about-town, corinthian\",\n \"player, participant\",\n \"playmate, playfellow\",\n \"pleaser\",\n \"pledger\",\n \"plenipotentiary\",\n \"plier, plyer\",\n \"plodder, slowpoke, stick-in-the-mud, slowcoach\",\n \"plodder, slogger\",\n \"plotter, mapper\",\n \"plumber, pipe_fitter\",\n \"pluralist\",\n \"pluralist\",\n \"poet\",\n \"pointsman\",\n \"point_woman\",\n \"policyholder\",\n \"political_prisoner\",\n \"political_scientist\",\n \"politician, politico, pol, political_leader\",\n \"politician\",\n \"pollster, poll_taker, headcounter, canvasser\",\n \"polluter, defiler\",\n \"pool_player\",\n \"portraitist, portrait_painter, portrayer, limner\",\n \"poseuse\",\n \"positivist, rationalist\",\n \"postdoc, post_doc\",\n \"poster_girl\",\n \"postulator\",\n \"private_citizen\",\n \"problem_solver, solver, convergent_thinker\",\n \"pro-lifer\",\n \"prosthetist\",\n \"postulant\",\n \"potboy, potman\",\n \"poultryman, poulterer\",\n \"power_user\",\n \"power_worker, power-station_worker\",\n \"practitioner, practician\",\n \"prayer, supplicant\",\n \"preceptor, don\",\n \"predecessor\",\n \"preemptor, pre-emptor\",\n \"preemptor, pre-emptor\",\n \"premature_baby, preterm_baby, premature_infant, preterm_infant, preemie, premie\",\n \"presbyter\",\n \"presenter, sponsor\",\n \"presentist\",\n \"preserver\",\n \"president\",\n \"president_of_the_united_states, united_states_president, president, chief_executive\",\n \"president, prexy\",\n \"press_agent, publicity_man, public_relations_man, pr_man\",\n \"press_photographer\",\n \"priest\",\n \"prima_ballerina\",\n \"prima_donna, diva\",\n \"prima_donna\",\n \"primigravida, gravida_i\",\n \"primordial_dwarf, hypoplastic_dwarf, true_dwarf, normal_dwarf\",\n \"prince_charming\",\n \"prince_consort\",\n \"princeling\",\n \"prince_of_wales\",\n \"princess\",\n \"princess_royal\",\n \"principal, dealer\",\n \"principal, school_principal, head_teacher, head\",\n \"print_seller\",\n \"prior\",\n \"private, buck_private, common_soldier\",\n \"probationer, student_nurse\",\n \"processor\",\n \"process-server\",\n \"proconsul\",\n \"proconsul\",\n \"proctologist\",\n \"proctor, monitor\",\n \"procurator\",\n \"procurer, securer\",\n \"profit_taker\",\n \"programmer, computer_programmer, coder, software_engineer\",\n \"promiser, promisor\",\n \"promoter, booster, plugger\",\n \"promulgator\",\n \"propagandist\",\n \"propagator, disseminator\",\n \"property_man, propman, property_master\",\n \"prophetess\",\n \"prophet\",\n \"prosecutor, public_prosecutor, prosecuting_officer, prosecuting_attorney\",\n \"prospector\",\n \"protectionist\",\n \"protegee\",\n \"protozoologist\",\n \"provost_marshal\",\n \"pruner, trimmer\",\n \"psalmist\",\n \"psephologist\",\n \"psychiatrist, head-shrinker, shrink\",\n \"psychic\",\n \"psycholinguist\",\n \"psychophysicist\",\n \"publican, tavern_keeper\",\n \"pudge\",\n \"puerpera\",\n \"punching_bag\",\n \"punter\",\n \"punter\",\n \"puppeteer\",\n \"puppy, pup\",\n \"purchasing_agent\",\n \"puritan\",\n \"puritan\",\n \"pursuer\",\n \"pusher, shover\",\n \"pusher, drug_peddler, peddler, drug_dealer, drug_trafficker\",\n \"pusher, thruster\",\n \"putz\",\n \"pygmy, pigmy\",\n \"qadi\",\n \"quadriplegic\",\n \"quadruplet, quad\",\n \"quaker, trembler\",\n \"quarter\",\n \"quarterback, signal_caller, field_general\",\n \"quartermaster\",\n \"quartermaster_general\",\n \"quebecois\",\n \"queen, queen_regnant, female_monarch\",\n \"queen_of_england\",\n \"queen\",\n \"queen\",\n \"queen_consort\",\n \"queen_mother\",\n \"queen's_counsel\",\n \"question_master, quizmaster\",\n \"quick_study, sponge\",\n \"quietist\",\n \"quitter\",\n \"rabbi\",\n \"racist, racialist\",\n \"radiobiologist\",\n \"radiologic_technologist\",\n \"radiologist, radiotherapist\",\n \"rainmaker\",\n \"raiser\",\n \"raja, rajah\",\n \"rake, rakehell, profligate, rip, blood, roue\",\n \"ramrod\",\n \"ranch_hand\",\n \"ranker\",\n \"ranter, raver\",\n \"rape_suspect\",\n \"rapper\",\n \"rapporteur\",\n \"rare_bird, rara_avis\",\n \"ratepayer\",\n \"raw_recruit\",\n \"reader\",\n \"reading_teacher\",\n \"realist\",\n \"real_estate_broker, real_estate_agent, estate_agent, land_agent, house_agent\",\n \"rear_admiral\",\n \"receiver\",\n \"reciter\",\n \"recruit, enlistee\",\n \"recruit, military_recruit\",\n \"recruiter\",\n \"recruiting-sergeant\",\n \"redcap\",\n \"redhead, redheader, red-header, carrottop\",\n \"redneck, cracker\",\n \"reeler\",\n \"reenactor\",\n \"referral\",\n \"referee, ref\",\n \"refiner\",\n \"reform_jew\",\n \"registered_nurse, rn\",\n \"registrar\",\n \"regius_professor\",\n \"reliever, allayer, comforter\",\n \"anchorite, hermit\",\n \"religious_leader\",\n \"remover\",\n \"renaissance_man, generalist\",\n \"renegade\",\n \"rentier\",\n \"repairman, maintenance_man, service_man\",\n \"reporter, newsman, newsperson\",\n \"newswoman\",\n \"representative\",\n \"reprobate, miscreant\",\n \"rescuer, recoverer, saver\",\n \"reservist\",\n \"resident_commissioner\",\n \"respecter\",\n \"restaurateur, restauranter\",\n \"restrainer, controller\",\n \"retailer, retail_merchant\",\n \"retiree, retired_person\",\n \"returning_officer\",\n \"revenant\",\n \"revisionist\",\n \"revolutionist, revolutionary, subversive, subverter\",\n \"rheumatologist\",\n \"rhodesian_man, homo_rhodesiensis\",\n \"rhymer, rhymester, versifier, poetizer, poetiser\",\n \"rich_person, wealthy_person, have\",\n \"rider\",\n \"riding_master\",\n \"rifleman\",\n \"right-hander, right_hander, righthander\",\n \"right-hand_man, chief_assistant, man_friday\",\n \"ringer\",\n \"ringleader\",\n \"roadman, road_mender\",\n \"roarer, bawler, bellower, screamer, screecher, shouter, yeller\",\n \"rocket_engineer, rocket_scientist\",\n \"rocket_scientist\",\n \"rock_star\",\n \"romanov, romanoff\",\n \"romanticist, romantic\",\n \"ropemaker, rope-maker, roper\",\n \"roper\",\n \"roper\",\n \"ropewalker, ropedancer\",\n \"rosebud\",\n \"rosicrucian\",\n \"mountie\",\n \"rough_rider\",\n \"roundhead\",\n \"civil_authority, civil_officer\",\n \"runner\",\n \"runner\",\n \"runner\",\n \"running_back\",\n \"rusher\",\n \"rustic\",\n \"saboteur, wrecker, diversionist\",\n \"sadist\",\n \"sailing_master, navigator\",\n \"sailor, crewman\",\n \"salesgirl, saleswoman, saleslady\",\n \"salesman\",\n \"salesperson, sales_representative, sales_rep\",\n \"salvager, salvor\",\n \"sandwichman\",\n \"sangoma\",\n \"sannup\",\n \"sapper\",\n \"sassenach\",\n \"satrap\",\n \"saunterer, stroller, ambler\",\n \"savoyard\",\n \"sawyer\",\n \"scalper\",\n \"scandalmonger\",\n \"scapegrace, black_sheep\",\n \"scene_painter\",\n \"schemer, plotter\",\n \"schizophrenic\",\n \"schlemiel, shlemiel\",\n \"schlockmeister, shlockmeister\",\n \"scholar, scholarly_person, bookman, student\",\n \"scholiast\",\n \"schoolchild, school-age_child, pupil\",\n \"schoolfriend\",\n \"schoolman, medieval_schoolman\",\n \"schoolmaster\",\n \"schoolmate, classmate, schoolfellow, class_fellow\",\n \"scientist\",\n \"scion\",\n \"scoffer, flouter, mocker, jeerer\",\n \"scofflaw\",\n \"scorekeeper, scorer\",\n \"scorer\",\n \"scourer\",\n \"scout, talent_scout\",\n \"scoutmaster\",\n \"scrambler\",\n \"scratcher\",\n \"screen_actor, movie_actor\",\n \"scrutineer, canvasser\",\n \"scuba_diver\",\n \"sculptor, sculpturer, carver, statue_maker\",\n \"sea_scout\",\n \"seasonal_worker, seasonal\",\n \"seasoner\",\n \"second_baseman, second_sacker\",\n \"second_cousin\",\n \"seconder\",\n \"second_fiddle, second_banana\",\n \"second-in-command\",\n \"second_lieutenant, 2nd_lieutenant\",\n \"second-rater, mediocrity\",\n \"secretary\",\n \"secretary_of_agriculture, agriculture_secretary\",\n \"secretary_of_health_and_human_services\",\n \"secretary_of_state\",\n \"secretary_of_the_interior, interior_secretary\",\n \"sectarian, sectary, sectarist\",\n \"section_hand\",\n \"secularist\",\n \"security_consultant\",\n \"seeded_player, seed\",\n \"seeder, cloud_seeder\",\n \"seeker, searcher, quester\",\n \"segregate\",\n \"segregator, segregationist\",\n \"selectman\",\n \"selectwoman\",\n \"selfish_person\",\n \"self-starter\",\n \"seller, marketer, vender, vendor, trafficker\",\n \"selling_agent\",\n \"semanticist, semiotician\",\n \"semifinalist\",\n \"seminarian, seminarist\",\n \"senator\",\n \"sendee\",\n \"senior\",\n \"senior_vice_president\",\n \"separatist, separationist\",\n \"septuagenarian\",\n \"serf, helot, villein\",\n \"spree_killer\",\n \"serjeant-at-law, serjeant, sergeant-at-law, sergeant\",\n \"server\",\n \"serviceman, military_man, man, military_personnel\",\n \"settler, colonist\",\n \"settler\",\n \"sex_symbol\",\n \"sexton, sacristan\",\n \"shaheed\",\n \"shakespearian, shakespearean\",\n \"shanghaier, seizer\",\n \"sharecropper, cropper, sharecrop_farmer\",\n \"shaver\",\n \"shavian\",\n \"sheep\",\n \"sheik, tribal_sheik, sheikh, tribal_sheikh, arab_chief\",\n \"shelver\",\n \"shepherd\",\n \"ship-breaker\",\n \"shipmate\",\n \"shipowner\",\n \"shipping_agent\",\n \"shirtmaker\",\n \"shogun\",\n \"shopaholic\",\n \"shop_girl\",\n \"shop_steward, steward\",\n \"shot_putter\",\n \"shrew, termagant\",\n \"shuffler\",\n \"shyster, pettifogger\",\n \"sibling, sib\",\n \"sick_person, diseased_person, sufferer\",\n \"sightreader\",\n \"signaler, signaller\",\n \"signer\",\n \"signor, signior\",\n \"signora\",\n \"signore\",\n \"signorina\",\n \"silent_partner, sleeping_partner\",\n \"addle-head, addlehead, loon, birdbrain\",\n \"simperer\",\n \"singer, vocalist, vocalizer, vocaliser\",\n \"sinologist\",\n \"sipper\",\n \"sirrah\",\n \"sister\",\n \"sister, sis\",\n \"waverer, vacillator, hesitator, hesitater\",\n \"sitar_player\",\n \"sixth-former\",\n \"skateboarder\",\n \"skeptic, sceptic, doubter\",\n \"sketcher\",\n \"skidder\",\n \"skier\",\n \"skinny-dipper\",\n \"skin-diver, aquanaut\",\n \"skinhead\",\n \"slasher\",\n \"slattern, slut, slovenly_woman, trollop\",\n \"sleeper, slumberer\",\n \"sleeper\",\n \"sleeping_beauty\",\n \"sleuth, sleuthhound\",\n \"slob, sloven, pig, slovenly_person\",\n \"sloganeer\",\n \"slopseller, slop-seller\",\n \"smasher, stunner, knockout, beauty, ravisher, sweetheart, peach, lulu, looker, mantrap, dish\",\n \"smirker\",\n \"smith, metalworker\",\n \"smoothie, smoothy, sweet_talker, charmer\",\n \"smuggler, runner, contrabandist, moon_curser, moon-curser\",\n \"sneezer\",\n \"snob, prig, snot, snoot\",\n \"snoop, snooper\",\n \"snorer\",\n \"sob_sister\",\n \"soccer_player\",\n \"social_anthropologist, cultural_anthropologist\",\n \"social_climber, climber\",\n \"socialist\",\n \"socializer, socialiser\",\n \"social_scientist\",\n \"social_secretary\",\n \"socinian\",\n \"sociolinguist\",\n \"sociologist\",\n \"soda_jerk, soda_jerker\",\n \"sodalist\",\n \"sodomite, sodomist, sod, bugger\",\n \"soldier\",\n \"son, boy\",\n \"songster\",\n \"songstress\",\n \"songwriter, songster, ballad_maker\",\n \"sorcerer, magician, wizard, necromancer, thaumaturge, thaumaturgist\",\n \"sorehead\",\n \"soul_mate\",\n \"southern_baptist\",\n \"sovereign, crowned_head, monarch\",\n \"spacewalker\",\n \"spanish_american, hispanic_american, hispanic\",\n \"sparring_partner, sparring_mate\",\n \"spastic\",\n \"speaker, talker, utterer, verbalizer, verbaliser\",\n \"native_speaker\",\n \"speaker\",\n \"speechwriter\",\n \"specialist, medical_specialist\",\n \"specifier\",\n \"spectator, witness, viewer, watcher, looker\",\n \"speech_therapist\",\n \"speedskater, speed_skater\",\n \"spellbinder\",\n \"sphinx\",\n \"spinster, old_maid\",\n \"split_end\",\n \"sport, sportsman, sportswoman\",\n \"sport, summercater\",\n \"sporting_man, outdoor_man\",\n \"sports_announcer, sportscaster, sports_commentator\",\n \"sports_editor\",\n \"sprog\",\n \"square_dancer\",\n \"square_shooter, straight_shooter, straight_arrow\",\n \"squatter\",\n \"squire\",\n \"squire\",\n \"staff_member, staffer\",\n \"staff_sergeant\",\n \"stage_director\",\n \"stainer\",\n \"stakeholder\",\n \"stalker\",\n \"stalking-horse\",\n \"stammerer, stutterer\",\n \"stamper, stomper, tramper, trampler\",\n \"standee\",\n \"stand-in, substitute, relief, reliever, backup, backup_man, fill-in\",\n \"star, principal, lead\",\n \"starlet\",\n \"starter, dispatcher\",\n \"statesman, solon, national_leader\",\n \"state_treasurer\",\n \"stationer, stationery_seller\",\n \"stenographer, amanuensis, shorthand_typist\",\n \"stentor\",\n \"stepbrother, half-brother, half_brother\",\n \"stepmother\",\n \"stepparent\",\n \"stevedore, loader, longshoreman, docker, dockhand, dock_worker, dockworker, dock-walloper, lumper\",\n \"steward\",\n \"steward, flight_attendant\",\n \"steward\",\n \"stickler\",\n \"stiff\",\n \"stifler, smotherer\",\n \"stipendiary, stipendiary_magistrate\",\n \"stitcher\",\n \"stockjobber\",\n \"stock_trader\",\n \"stockist\",\n \"stoker, fireman\",\n \"stooper\",\n \"store_detective\",\n \"strafer\",\n \"straight_man, second_banana\",\n \"stranger, alien, unknown\",\n \"stranger\",\n \"strategist, strategian\",\n \"straw_boss, assistant_foreman\",\n \"streetwalker, street_girl, hooker, hustler, floozy, floozie, slattern\",\n \"stretcher-bearer, litter-bearer\",\n \"struggler\",\n \"stud, he-man, macho-man\",\n \"student, pupil, educatee\",\n \"stumblebum, palooka\",\n \"stylist\",\n \"subaltern\",\n \"subcontractor\",\n \"subduer, surmounter, overcomer\",\n \"subject, case, guinea_pig\",\n \"subordinate, subsidiary, underling, foot_soldier\",\n \"substitute, reserve, second-stringer\",\n \"successor, heir\",\n \"successor, replacement\",\n \"succorer, succourer\",\n \"sufi\",\n \"suffragan, suffragan_bishop\",\n \"suffragette\",\n \"sugar_daddy\",\n \"suicide_bomber\",\n \"suitor, suer, wooer\",\n \"sumo_wrestler\",\n \"sunbather\",\n \"sundowner\",\n \"super_heavyweight\",\n \"superior, higher-up, superordinate\",\n \"supermom\",\n \"supernumerary, spear_carrier, extra\",\n \"supremo\",\n \"surgeon, operating_surgeon, sawbones\",\n \"surgeon_general\",\n \"surgeon_general\",\n \"surpriser\",\n \"surveyor\",\n \"surveyor\",\n \"survivor, subsister\",\n \"sutler, victualer, victualler, provisioner\",\n \"sweeper\",\n \"sweetheart, sweetie, steady, truelove\",\n \"swinger, tramp\",\n \"switcher, whipper\",\n \"swot, grind, nerd, wonk, dweeb\",\n \"sycophant, toady, crawler, lackey, ass-kisser\",\n \"sylph\",\n \"sympathizer, sympathiser, well-wisher\",\n \"symphonist\",\n \"syncopator\",\n \"syndic\",\n \"tactician\",\n \"tagger\",\n \"tailback\",\n \"tallyman, tally_clerk\",\n \"tallyman\",\n \"tanker, tank_driver\",\n \"tapper, wiretapper, phone_tapper\",\n \"tartuffe, tartufe\",\n \"tarzan\",\n \"taster, taste_tester, taste-tester, sampler\",\n \"tax_assessor, assessor\",\n \"taxer\",\n \"taxi_dancer\",\n \"taxonomist, taxonomer, systematist\",\n \"teacher, instructor\",\n \"teaching_fellow\",\n \"tearaway\",\n \"technical_sergeant\",\n \"technician\",\n \"ted, teddy_boy\",\n \"teetotaler, teetotaller, teetotalist\",\n \"television_reporter, television_newscaster, tv_reporter, tv_newsman\",\n \"temporizer, temporiser\",\n \"tempter\",\n \"term_infant\",\n \"toiler\",\n \"tenant, renter\",\n \"tenant\",\n \"tenderfoot\",\n \"tennis_player\",\n \"tennis_pro, professional_tennis_player\",\n \"tenor_saxophonist, tenorist\",\n \"termer\",\n \"terror, scourge, threat\",\n \"tertigravida, gravida_iii\",\n \"testator, testate\",\n \"testatrix\",\n \"testee, examinee\",\n \"test-tube_baby\",\n \"texas_ranger, ranger\",\n \"thane\",\n \"theatrical_producer\",\n \"theologian, theologist, theologizer, theologiser\",\n \"theorist, theoretician, theorizer, theoriser, idealogue\",\n \"theosophist\",\n \"therapist, healer\",\n \"thessalonian\",\n \"thinker, creative_thinker, mind\",\n \"thinker\",\n \"thrower\",\n \"thurifer\",\n \"ticket_collector, ticket_taker\",\n \"tight_end\",\n \"tiler\",\n \"timekeeper, timer\",\n \"timorese\",\n \"tinkerer, fiddler\",\n \"tinsmith, tinner\",\n \"tinter\",\n \"tippler, social_drinker\",\n \"tipster, tout\",\n \"t-man\",\n \"toastmaster, symposiarch\",\n \"toast_mistress\",\n \"tobogganist\",\n \"tomboy, romp, hoyden\",\n \"toolmaker\",\n \"torchbearer\",\n \"tory\",\n \"tory\",\n \"tosser\",\n \"tosser, jerk-off, wanker\",\n \"totalitarian\",\n \"tourist, tourer, holidaymaker\",\n \"tout, touter\",\n \"tout, ticket_tout\",\n \"tovarich, tovarisch\",\n \"towhead\",\n \"town_clerk\",\n \"town_crier, crier\",\n \"townsman, towner\",\n \"toxicologist\",\n \"track_star\",\n \"trader, bargainer, dealer, monger\",\n \"trade_unionist, unionist, union_member\",\n \"traditionalist, diehard\",\n \"traffic_cop\",\n \"tragedian\",\n \"tragedian\",\n \"tragedienne\",\n \"trail_boss\",\n \"trainer\",\n \"traitor, treasonist\",\n \"traitress\",\n \"transactor\",\n \"transcriber\",\n \"transfer, transferee\",\n \"transferee\",\n \"translator, transcriber\",\n \"transvestite, cross-dresser\",\n \"traveling_salesman, travelling_salesman, commercial_traveler, commercial_traveller, roadman, bagman\",\n \"traverser\",\n \"trawler\",\n \"treasury, first_lord_of_the_treasury\",\n \"trencher\",\n \"trend-setter, taste-maker, fashion_arbiter\",\n \"tribesman\",\n \"trier, attempter, essayer\",\n \"trifler\",\n \"trooper\",\n \"trooper, state_trooper\",\n \"trotskyite, trotskyist, trot\",\n \"truant, hooky_player\",\n \"trumpeter, cornetist\",\n \"trusty\",\n \"tudor\",\n \"tumbler\",\n \"tutee\",\n \"twin\",\n \"two-timer\",\n \"tyke\",\n \"tympanist, timpanist\",\n \"typist\",\n \"tyrant, autocrat, despot\",\n \"umpire, ump\",\n \"understudy, standby\",\n \"undesirable\",\n \"unicyclist\",\n \"unilateralist\",\n \"unitarian\",\n \"arminian\",\n \"universal_donor\",\n \"unix_guru\",\n \"unknown_soldier\",\n \"upsetter\",\n \"upstager\",\n \"upstart, parvenu, nouveau-riche, arriviste\",\n \"upstart\",\n \"urchin\",\n \"urologist\",\n \"usherette\",\n \"usher, doorkeeper\",\n \"usurper, supplanter\",\n \"utility_man\",\n \"utilizer, utiliser\",\n \"utopian\",\n \"uxoricide\",\n \"vacationer, vacationist\",\n \"valedictorian, valedictory_speaker\",\n \"valley_girl\",\n \"vaulter, pole_vaulter, pole_jumper\",\n \"vegetarian\",\n \"vegan\",\n \"venerator\",\n \"venture_capitalist\",\n \"venturer, merchant-venturer\",\n \"vermin, varmint\",\n \"very_important_person, vip, high-up, dignitary, panjandrum, high_muckamuck\",\n \"vibist, vibraphonist\",\n \"vicar\",\n \"vicar\",\n \"vicar-general\",\n \"vice_chancellor\",\n \"vicegerent\",\n \"vice_president, v.p.\",\n \"vice-regent\",\n \"victim, dupe\",\n \"victorian\",\n \"victualer, victualler\",\n \"vigilante, vigilance_man\",\n \"villager\",\n \"vintager\",\n \"vintner, wine_merchant\",\n \"violator, debaucher, ravisher\",\n \"violator, lawbreaker, law_offender\",\n \"violist\",\n \"virago\",\n \"virologist\",\n \"visayan, bisayan\",\n \"viscountess\",\n \"viscount\",\n \"visigoth\",\n \"visionary\",\n \"visiting_fireman\",\n \"visiting_professor\",\n \"visualizer, visualiser\",\n \"vixen, harpy, hellcat\",\n \"vizier\",\n \"voicer\",\n \"volunteer, unpaid_worker\",\n \"volunteer, military_volunteer, voluntary\",\n \"votary\",\n \"votary\",\n \"vouchee\",\n \"vower\",\n \"voyager\",\n \"voyeur, peeping_tom, peeper\",\n \"vulcanizer, vulcaniser\",\n \"waffler\",\n \"wagnerian\",\n \"waif, street_child\",\n \"wailer\",\n \"waiter, server\",\n \"waitress\",\n \"walking_delegate\",\n \"walk-on\",\n \"wallah\",\n \"wally\",\n \"waltzer\",\n \"wanderer, roamer, rover, bird_of_passage\",\n \"wandering_jew\",\n \"wanton\",\n \"warrantee\",\n \"warrantee\",\n \"washer\",\n \"washerman, laundryman\",\n \"washwoman, washerwoman, laundrywoman, laundress\",\n \"wassailer, carouser\",\n \"wastrel, waster\",\n \"wave\",\n \"weatherman, weather_forecaster\",\n \"weekend_warrior\",\n \"weeder\",\n \"welder\",\n \"welfare_case, charity_case\",\n \"westerner\",\n \"west-sider\",\n \"wetter\",\n \"whaler\",\n \"whig\",\n \"whiner, complainer, moaner, sniveller, crybaby, bellyacher, grumbler, squawker\",\n \"whipper-in\",\n \"whisperer\",\n \"whiteface\",\n \"carmelite, white_friar\",\n \"augustinian\",\n \"white_hope, great_white_hope\",\n \"white_supremacist\",\n \"whoremaster, whoremonger\",\n \"whoremaster, whoremonger, john, trick\",\n \"widow, widow_woman\",\n \"wife, married_woman\",\n \"wiggler, wriggler, squirmer\",\n \"wimp, chicken, crybaby\",\n \"wing_commander\",\n \"winger\",\n \"winner\",\n \"winner, victor\",\n \"window_dresser, window_trimmer\",\n \"winker\",\n \"wiper\",\n \"wireman, wirer\",\n \"wise_guy, smart_aleck, wiseacre, wisenheimer, weisenheimer\",\n \"witch_doctor\",\n \"withdrawer\",\n \"withdrawer\",\n \"woman, adult_female\",\n \"woman\",\n \"wonder_boy, golden_boy\",\n \"wonderer\",\n \"working_girl\",\n \"workman, workingman, working_man, working_person\",\n \"workmate\",\n \"worldling\",\n \"worshiper, worshipper\",\n \"worthy\",\n \"wrecker\",\n \"wright\",\n \"write-in_candidate, write-in\",\n \"writer, author\",\n \"wykehamist\",\n \"yakuza\",\n \"yard_bird, yardbird\",\n \"yardie\",\n \"yardman\",\n \"yardmaster, trainmaster, train_dispatcher\",\n \"yenta\",\n \"yogi\",\n \"young_buck, young_man\",\n \"young_turk\",\n \"young_turk\",\n \"zionist\",\n \"zoo_keeper\",\n \"genet, edmund_charles_edouard_genet, citizen_genet\",\n \"kennan, george_f._kennan, george_frost_kennan\",\n \"munro, h._h._munro, hector_hugh_munro, saki\",\n \"popper, karl_popper, sir_karl_raimund_popper\",\n \"stoker, bram_stoker, abraham_stoker\",\n \"townes, charles_townes, charles_hard_townes\",\n \"dust_storm, duster, sandstorm, sirocco\",\n \"parhelion, mock_sun, sundog\",\n \"snow, snowfall\",\n \"facula\",\n \"wave\",\n \"microflora\",\n \"wilding\",\n \"semi-climber\",\n \"volva\",\n \"basidiocarp\",\n \"domatium\",\n \"apomict\",\n \"aquatic\",\n \"bryophyte, nonvascular_plant\",\n \"acrocarp, acrocarpous_moss\",\n \"sphagnum, sphagnum_moss, peat_moss, bog_moss\",\n \"liverwort, hepatic\",\n \"hepatica, marchantia_polymorpha\",\n \"pecopteris\",\n \"pteridophyte, nonflowering_plant\",\n \"fern\",\n \"fern_ally\",\n \"spore\",\n \"carpospore\",\n \"chlamydospore\",\n \"conidium, conidiospore\",\n \"oospore\",\n \"tetraspore\",\n \"zoospore\",\n \"cryptogam\",\n \"spermatophyte, phanerogam, seed_plant\",\n \"seedling\",\n \"annual\",\n \"biennial\",\n \"perennial\",\n \"hygrophyte\",\n \"gymnosperm\",\n \"gnetum, gnetum_gnemon\",\n \"catha_edulis\",\n \"ephedra, joint_fir\",\n \"mahuang, ephedra_sinica\",\n \"welwitschia, welwitschia_mirabilis\",\n \"cycad\",\n \"sago_palm, cycas_revoluta\",\n \"false_sago, fern_palm, cycas_circinalis\",\n \"zamia\",\n \"coontie, florida_arrowroot, seminole_bread, zamia_pumila\",\n \"ceratozamia\",\n \"dioon\",\n \"encephalartos\",\n \"kaffir_bread, encephalartos_caffer\",\n \"macrozamia\",\n \"burrawong, macrozamia_communis, macrozamia_spiralis\",\n \"pine, pine_tree, true_pine\",\n \"pinon, pinyon\",\n \"nut_pine\",\n \"pinon_pine, mexican_nut_pine, pinus_cembroides\",\n \"rocky_mountain_pinon, pinus_edulis\",\n \"single-leaf, single-leaf_pine, single-leaf_pinyon, pinus_monophylla\",\n \"bishop_pine, bishop's_pine, pinus_muricata\",\n \"california_single-leaf_pinyon, pinus_californiarum\",\n \"parry's_pinyon, pinus_quadrifolia, pinus_parryana\",\n \"spruce_pine, pinus_glabra\",\n \"black_pine, pinus_nigra\",\n \"pitch_pine, northern_pitch_pine, pinus_rigida\",\n \"pond_pine, pinus_serotina\",\n \"stone_pine, umbrella_pine, european_nut_pine, pinus_pinea\",\n \"swiss_pine, swiss_stone_pine, arolla_pine, cembra_nut_tree, pinus_cembra\",\n \"cembra_nut, cedar_nut\",\n \"swiss_mountain_pine, mountain_pine, dwarf_mountain_pine, mugho_pine, mugo_pine, pinus_mugo\",\n \"ancient_pine, pinus_longaeva\",\n \"white_pine\",\n \"american_white_pine, eastern_white_pine, weymouth_pine, pinus_strobus\",\n \"western_white_pine, silver_pine, mountain_pine, pinus_monticola\",\n \"southwestern_white_pine, pinus_strobiformis\",\n \"limber_pine, pinus_flexilis\",\n \"whitebark_pine, whitebarked_pine, pinus_albicaulis\",\n \"yellow_pine\",\n \"ponderosa, ponderosa_pine, western_yellow_pine, bull_pine, pinus_ponderosa\",\n \"jeffrey_pine, jeffrey's_pine, black_pine, pinus_jeffreyi\",\n \"shore_pine, lodgepole, lodgepole_pine, spruce_pine, pinus_contorta\",\n \"sierra_lodgepole_pine, pinus_contorta_murrayana\",\n \"loblolly_pine, frankincense_pine, pinus_taeda\",\n \"jack_pine, pinus_banksiana\",\n \"swamp_pine\",\n \"longleaf_pine, pitch_pine, southern_yellow_pine, georgia_pine, pinus_palustris\",\n \"shortleaf_pine, short-leaf_pine, shortleaf_yellow_pine, pinus_echinata\",\n \"red_pine, canadian_red_pine, pinus_resinosa\",\n \"scotch_pine, scots_pine, scotch_fir, pinus_sylvestris\",\n \"scrub_pine, virginia_pine, jersey_pine, pinus_virginiana\",\n \"monterey_pine, pinus_radiata\",\n \"bristlecone_pine, rocky_mountain_bristlecone_pine, pinus_aristata\",\n \"table-mountain_pine, prickly_pine, hickory_pine, pinus_pungens\",\n \"knobcone_pine, pinus_attenuata\",\n \"japanese_red_pine, japanese_table_pine, pinus_densiflora\",\n \"japanese_black_pine, black_pine, pinus_thunbergii\",\n \"torrey_pine, torrey's_pine, soledad_pine, grey-leaf_pine, sabine_pine, pinus_torreyana\",\n \"larch, larch_tree\",\n \"american_larch, tamarack, black_larch, larix_laricina\",\n \"western_larch, western_tamarack, oregon_larch, larix_occidentalis\",\n \"subalpine_larch, larix_lyallii\",\n \"european_larch, larix_decidua\",\n \"siberian_larch, larix_siberica, larix_russica\",\n \"golden_larch, pseudolarix_amabilis\",\n \"fir, fir_tree, true_fir\",\n \"silver_fir\",\n \"amabilis_fir, white_fir, pacific_silver_fir, red_silver_fir, christmas_tree, abies_amabilis\",\n \"european_silver_fir, christmas_tree, abies_alba\",\n \"white_fir, colorado_fir, california_white_fir, abies_concolor, abies_lowiana\",\n \"balsam_fir, balm_of_gilead, canada_balsam, abies_balsamea\",\n \"fraser_fir, abies_fraseri\",\n \"lowland_fir, lowland_white_fir, giant_fir, grand_fir, abies_grandis\",\n \"alpine_fir, subalpine_fir, abies_lasiocarpa\",\n \"santa_lucia_fir, bristlecone_fir, abies_bracteata, abies_venusta\",\n \"cedar, cedar_tree, true_cedar\",\n \"cedar_of_lebanon, cedrus_libani\",\n \"deodar, deodar_cedar, himalayan_cedar, cedrus_deodara\",\n \"atlas_cedar, cedrus_atlantica\",\n \"spruce\",\n \"norway_spruce, picea_abies\",\n \"weeping_spruce, brewer's_spruce, picea_breweriana\",\n \"engelmann_spruce, engelmann's_spruce, picea_engelmannii\",\n \"white_spruce, picea_glauca\",\n \"black_spruce, picea_mariana, spruce_pine\",\n \"siberian_spruce, picea_obovata\",\n \"sitka_spruce, picea_sitchensis\",\n \"oriental_spruce, picea_orientalis\",\n \"colorado_spruce, colorado_blue_spruce, silver_spruce, picea_pungens\",\n \"red_spruce, eastern_spruce, yellow_spruce, picea_rubens\",\n \"hemlock, hemlock_tree\",\n \"eastern_hemlock, canadian_hemlock, spruce_pine, tsuga_canadensis\",\n \"carolina_hemlock, tsuga_caroliniana\",\n \"mountain_hemlock, black_hemlock, tsuga_mertensiana\",\n \"western_hemlock, pacific_hemlock, west_coast_hemlock, tsuga_heterophylla\",\n \"douglas_fir\",\n \"green_douglas_fir, douglas_spruce, douglas_pine, douglas_hemlock, oregon_fir, oregon_pine, pseudotsuga_menziesii\",\n \"big-cone_spruce, big-cone_douglas_fir, pseudotsuga_macrocarpa\",\n \"cathaya\",\n \"cedar, cedar_tree\",\n \"cypress, cypress_tree\",\n \"gowen_cypress, cupressus_goveniana\",\n \"pygmy_cypress, cupressus_pigmaea, cupressus_goveniana_pigmaea\",\n \"santa_cruz_cypress, cupressus_abramsiana, cupressus_goveniana_abramsiana\",\n \"arizona_cypress, cupressus_arizonica\",\n \"guadalupe_cypress, cupressus_guadalupensis\",\n \"monterey_cypress, cupressus_macrocarpa\",\n \"mexican_cypress, cedar_of_goa, portuguese_cypress, cupressus_lusitanica\",\n \"italian_cypress, mediterranean_cypress, cupressus_sempervirens\",\n \"king_william_pine, athrotaxis_selaginoides\",\n \"chilean_cedar, austrocedrus_chilensis\",\n \"incense_cedar, red_cedar, calocedrus_decurrens, libocedrus_decurrens\",\n \"southern_white_cedar, coast_white_cedar, atlantic_white_cedar, white_cypress, white_cedar, chamaecyparis_thyoides\",\n \"oregon_cedar, port_orford_cedar, lawson's_cypress, lawson's_cedar, chamaecyparis_lawsoniana\",\n \"yellow_cypress, yellow_cedar, nootka_cypress, alaska_cedar, chamaecyparis_nootkatensis\",\n \"japanese_cedar, japan_cedar, sugi, cryptomeria_japonica\",\n \"juniper_berry\",\n \"incense_cedar\",\n \"kawaka, libocedrus_plumosa\",\n \"pahautea, libocedrus_bidwillii, mountain_pine\",\n \"metasequoia, dawn_redwood, metasequoia_glyptostrodoides\",\n \"arborvitae\",\n \"western_red_cedar, red_cedar, canoe_cedar, thuja_plicata\",\n \"american_arborvitae, northern_white_cedar, white_cedar, thuja_occidentalis\",\n \"oriental_arborvitae, thuja_orientalis, platycladus_orientalis\",\n \"hiba_arborvitae, thujopsis_dolobrata\",\n \"keteleeria\",\n \"wollemi_pine\",\n \"araucaria\",\n \"monkey_puzzle, chile_pine, araucaria_araucana\",\n \"norfolk_island_pine, araucaria_heterophylla, araucaria_excelsa\",\n \"new_caledonian_pine, araucaria_columnaris\",\n \"bunya_bunya, bunya_bunya_tree, araucaria_bidwillii\",\n \"hoop_pine, moreton_bay_pine, araucaria_cunninghamii\",\n \"kauri_pine, dammar_pine\",\n \"kauri, kaury, agathis_australis\",\n \"amboina_pine, amboyna_pine, agathis_dammara, agathis_alba\",\n \"dundathu_pine, queensland_kauri, smooth_bark_kauri, agathis_robusta\",\n \"red_kauri, agathis_lanceolata\",\n \"plum-yew\",\n \"california_nutmeg, nutmeg-yew, torreya_californica\",\n \"stinking_cedar, stinking_yew, torrey_tree, torreya_taxifolia\",\n \"celery_pine\",\n \"celery_top_pine, celery-topped_pine, phyllocladus_asplenifolius\",\n \"tanekaha, phyllocladus_trichomanoides\",\n \"alpine_celery_pine, phyllocladus_alpinus\",\n \"yellowwood, yellowwood_tree\",\n \"gymnospermous_yellowwood\",\n \"podocarp\",\n \"yacca, yacca_podocarp, podocarpus_coriaceus\",\n \"brown_pine, rockingham_podocarp, podocarpus_elatus\",\n \"cape_yellowwood, african_yellowwood, podocarpus_elongatus\",\n \"south-african_yellowwood, podocarpus_latifolius\",\n \"alpine_totara, podocarpus_nivalis\",\n \"totara, podocarpus_totara\",\n \"common_yellowwood, bastard_yellowwood, afrocarpus_falcata\",\n \"kahikatea, new_zealand_dacryberry, new_zealand_white_pine, dacrycarpus_dacrydioides, podocarpus_dacrydioides\",\n \"rimu, imou_pine, red_pine, dacrydium_cupressinum\",\n \"tarwood, tar-wood, dacrydium_colensoi\",\n \"common_sickle_pine, falcatifolium_falciforme\",\n \"yellow-leaf_sickle_pine, falcatifolium_taxoides\",\n \"tarwood, tar-wood, new_zealand_mountain_pine, halocarpus_bidwilli, dacrydium_bidwilli\",\n \"westland_pine, silver_pine, lagarostrobus_colensoi\",\n \"huon_pine, lagarostrobus_franklinii, dacrydium_franklinii\",\n \"chilean_rimu, lepidothamnus_fonkii\",\n \"mountain_rimu, lepidothamnus_laxifolius, dacridium_laxifolius\",\n \"nagi, nageia_nagi\",\n \"miro, black_pine, prumnopitys_ferruginea, podocarpus_ferruginea\",\n \"matai, black_pine, prumnopitys_taxifolia, podocarpus_spicata\",\n \"plum-fruited_yew, prumnopitys_andina, prumnopitys_elegans\",\n \"prince_albert_yew, prince_albert's_yew, saxe-gothea_conspicua\",\n \"sundacarpus_amara, prumnopitys_amara, podocarpus_amara\",\n \"japanese_umbrella_pine, sciadopitys_verticillata\",\n \"yew\",\n \"old_world_yew, english_yew, taxus_baccata\",\n \"pacific_yew, california_yew, western_yew, taxus_brevifolia\",\n \"japanese_yew, taxus_cuspidata\",\n \"florida_yew, taxus_floridana\",\n \"new_caledonian_yew, austrotaxus_spicata\",\n \"white-berry_yew, pseudotaxus_chienii\",\n \"ginkgo, gingko, maidenhair_tree, ginkgo_biloba\",\n \"angiosperm, flowering_plant\",\n \"dicot, dicotyledon, magnoliopsid, exogen\",\n \"monocot, monocotyledon, liliopsid, endogen\",\n \"floret, floweret\",\n \"flower\",\n \"bloomer\",\n \"wildflower, wild_flower\",\n \"apetalous_flower\",\n \"inflorescence\",\n \"rosebud\",\n \"gynostegium\",\n \"pollinium\",\n \"pistil\",\n \"gynobase\",\n \"gynophore\",\n \"stylopodium\",\n \"carpophore\",\n \"cornstalk, corn_stalk\",\n \"petiolule\",\n \"mericarp\",\n \"micropyle\",\n \"germ_tube\",\n \"pollen_tube\",\n \"gemma\",\n \"galbulus\",\n \"nectary, honey_gland\",\n \"pericarp, seed_vessel\",\n \"epicarp, exocarp\",\n \"mesocarp\",\n \"pip\",\n \"silique, siliqua\",\n \"cataphyll\",\n \"perisperm\",\n \"monocarp, monocarpic_plant, monocarpous_plant\",\n \"sporophyte\",\n \"gametophyte\",\n \"megasporangium, macrosporangium\",\n \"microspore\",\n \"microsporangium\",\n \"microsporophyll\",\n \"archespore, archesporium\",\n \"bonduc_nut, nicker_nut, nicker_seed\",\n \"job's_tears\",\n \"oilseed, oil-rich_seed\",\n \"castor_bean\",\n \"cottonseed\",\n \"candlenut\",\n \"peach_pit\",\n \"hypanthium, floral_cup, calyx_tube\",\n \"petal, flower_petal\",\n \"corolla\",\n \"lip\",\n \"perianth, chlamys, floral_envelope, perigone, perigonium\",\n \"thistledown\",\n \"custard_apple, custard_apple_tree\",\n \"cherimoya, cherimoya_tree, annona_cherimola\",\n \"ilama, ilama_tree, annona_diversifolia\",\n \"soursop, prickly_custard_apple, soursop_tree, annona_muricata\",\n \"bullock's_heart, bullock's_heart_tree, bullock_heart, annona_reticulata\",\n \"sweetsop, sweetsop_tree, annona_squamosa\",\n \"pond_apple, pond-apple_tree, annona_glabra\",\n \"pawpaw, papaw, papaw_tree, asimina_triloba\",\n \"ilang-ilang, ylang-ylang, cananga_odorata\",\n \"lancewood, lancewood_tree, oxandra_lanceolata\",\n \"guinea_pepper, negro_pepper, xylopia_aethiopica\",\n \"barberry\",\n \"american_barberry, berberis_canadensis\",\n \"common_barberry, european_barberry, berberis_vulgaris\",\n \"japanese_barberry, berberis_thunbergii\",\n \"oregon_grape, oregon_holly_grape, hollygrape, mountain_grape, holly-leaves_barberry, mahonia_aquifolium\",\n \"oregon_grape, mahonia_nervosa\",\n \"mayapple, may_apple, wild_mandrake, podophyllum_peltatum\",\n \"may_apple\",\n \"allspice\",\n \"carolina_allspice, strawberry_shrub, strawberry_bush, sweet_shrub, calycanthus_floridus\",\n \"spicebush, california_allspice, calycanthus_occidentalis\",\n \"katsura_tree, cercidiphyllum_japonicum\",\n \"laurel\",\n \"true_laurel, bay, bay_laurel, bay_tree, laurus_nobilis\",\n \"camphor_tree, cinnamomum_camphora\",\n \"cinnamon, ceylon_cinnamon, ceylon_cinnamon_tree, cinnamomum_zeylanicum\",\n \"cassia, cassia-bark_tree, cinnamomum_cassia\",\n \"cassia_bark, chinese_cinnamon\",\n \"saigon_cinnamon, cinnamomum_loureirii\",\n \"cinnamon_bark\",\n \"spicebush, spice_bush, american_spicebush, benjamin_bush, lindera_benzoin, benzoin_odoriferum\",\n \"avocado, avocado_tree, persea_americana\",\n \"laurel-tree, red_bay, persea_borbonia\",\n \"sassafras, sassafras_tree, sassafras_albidum\",\n \"california_laurel, california_bay_tree, oregon_myrtle, pepperwood, spice_tree, sassafras_laurel, california_olive, mountain_laurel, umbellularia_californica\",\n \"anise_tree\",\n \"purple_anise, illicium_floridanum\",\n \"star_anise, illicium_anisatum\",\n \"star_anise, chinese_anise, illicium_verum\",\n \"magnolia\",\n \"southern_magnolia, evergreen_magnolia, large-flowering_magnolia, bull_bay, magnolia_grandiflora\",\n \"umbrella_tree, umbrella_magnolia, elkwood, elk-wood, magnolia_tripetala\",\n \"earleaved_umbrella_tree, magnolia_fraseri\",\n \"cucumber_tree, magnolia_acuminata\",\n \"large-leaved_magnolia, large-leaved_cucumber_tree, great-leaved_macrophylla, magnolia_macrophylla\",\n \"saucer_magnolia, chinese_magnolia, magnolia_soulangiana\",\n \"star_magnolia, magnolia_stellata\",\n \"sweet_bay, swamp_bay, swamp_laurel, magnolia_virginiana\",\n \"manglietia, genus_manglietia\",\n \"tulip_tree, tulip_poplar, yellow_poplar, canary_whitewood, liriodendron_tulipifera\",\n \"moonseed\",\n \"common_moonseed, canada_moonseed, yellow_parilla, menispermum_canadense\",\n \"carolina_moonseed, cocculus_carolinus\",\n \"nutmeg, nutmeg_tree, myristica_fragrans\",\n \"water_nymph, fragrant_water_lily, pond_lily, nymphaea_odorata\",\n \"european_white_lily, nymphaea_alba\",\n \"southern_spatterdock, nuphar_sagittifolium\",\n \"lotus, indian_lotus, sacred_lotus, nelumbo_nucifera\",\n \"water_chinquapin, american_lotus, yanquapin, nelumbo_lutea\",\n \"water-shield, fanwort, cabomba_caroliniana\",\n \"water-shield, brasenia_schreberi, water-target\",\n \"peony, paeony\",\n \"buttercup, butterflower, butter-flower, crowfoot, goldcup, kingcup\",\n \"meadow_buttercup, tall_buttercup, tall_crowfoot, tall_field_buttercup, ranunculus_acris\",\n \"water_crowfoot, water_buttercup, ranunculus_aquatilis\",\n \"lesser_celandine, pilewort, ranunculus_ficaria\",\n \"lesser_spearwort, ranunculus_flammula\",\n \"greater_spearwort, ranunculus_lingua\",\n \"western_buttercup, ranunculus_occidentalis\",\n \"creeping_buttercup, creeping_crowfoot, ranunculus_repens\",\n \"cursed_crowfoot, celery-leaved_buttercup, ranunculus_sceleratus\",\n \"aconite\",\n \"monkshood, helmetflower, helmet_flower, aconitum_napellus\",\n \"wolfsbane, wolfbane, wolf's_bane, aconitum_lycoctonum\",\n \"baneberry, cohosh, herb_christopher\",\n \"baneberry\",\n \"red_baneberry, redberry, red-berry, snakeberry, actaea_rubra\",\n \"pheasant's-eye, adonis_annua\",\n \"anemone, windflower\",\n \"alpine_anemone, mountain_anemone, anemone_tetonensis\",\n \"canada_anemone, anemone_canadensis\",\n \"thimbleweed, anemone_cylindrica\",\n \"wood_anemone, anemone_nemorosa\",\n \"wood_anemone, snowdrop, anemone_quinquefolia\",\n \"longheaded_thimbleweed, anemone_riparia\",\n \"snowdrop_anemone, snowdrop_windflower, anemone_sylvestris\",\n \"virginia_thimbleweed, anemone_virginiana\",\n \"rue_anemone, anemonella_thalictroides\",\n \"columbine, aquilegia, aquilege\",\n \"meeting_house, honeysuckle, aquilegia_canadensis\",\n \"blue_columbine, aquilegia_caerulea, aquilegia_scopulorum_calcarea\",\n \"granny's_bonnets, aquilegia_vulgaris\",\n \"marsh_marigold, kingcup, meadow_bright, may_blob, cowslip, water_dragon, caltha_palustris\",\n \"american_bugbane, summer_cohosh, cimicifuga_americana\",\n \"black_cohosh, black_snakeroot, rattle-top, cimicifuga_racemosa\",\n \"fetid_bugbane, foetid_bugbane, cimicifuga_foetida\",\n \"clematis\",\n \"pine_hyacinth, clematis_baldwinii, viorna_baldwinii\",\n \"blue_jasmine, blue_jessamine, curly_clematis, marsh_clematis, clematis_crispa\",\n \"golden_clematis, clematis_tangutica\",\n \"scarlet_clematis, clematis_texensis\",\n \"leather_flower, clematis_versicolor\",\n \"leather_flower, vase-fine, vase_vine, clematis_viorna\",\n \"virgin's_bower, old_man's_beard, devil's_darning_needle, clematis_virginiana\",\n \"purple_clematis, purple_virgin's_bower, mountain_clematis, clematis_verticillaris\",\n \"goldthread, golden_thread, coptis_groenlandica, coptis_trifolia_groenlandica\",\n \"rocket_larkspur, consolida_ambigua, delphinium_ajacis\",\n \"delphinium\",\n \"larkspur\",\n \"winter_aconite, eranthis_hyemalis\",\n \"lenten_rose, black_hellebore, helleborus_orientalis\",\n \"green_hellebore, helleborus_viridis\",\n \"hepatica, liverleaf\",\n \"goldenseal, golden_seal, yellow_root, turmeric_root, hydrastis_canadensis\",\n \"false_rue_anemone, false_rue, isopyrum_biternatum\",\n \"giant_buttercup, laccopetalum_giganteum\",\n \"nigella\",\n \"love-in-a-mist, nigella_damascena\",\n \"fennel_flower, nigella_hispanica\",\n \"black_caraway, nutmeg_flower, roman_coriander, nigella_sativa\",\n \"pasqueflower, pasque_flower\",\n \"meadow_rue\",\n \"false_bugbane, trautvetteria_carolinensis\",\n \"globeflower, globe_flower\",\n \"winter's_bark, winter's_bark_tree, drimys_winteri\",\n \"pepper_shrub, pseudowintera_colorata, wintera_colorata\",\n \"sweet_gale, scotch_gale, myrica_gale\",\n \"wax_myrtle\",\n \"bay_myrtle, puckerbush, myrica_cerifera\",\n \"bayberry, candleberry, swamp_candleberry, waxberry, myrica_pensylvanica\",\n \"sweet_fern, comptonia_peregrina, comptonia_asplenifolia\",\n \"corkwood, corkwood_tree, leitneria_floridana\",\n \"jointed_rush, juncus_articulatus\",\n \"toad_rush, juncus_bufonius\",\n \"slender_rush, juncus_tenuis\",\n \"zebrawood, zebrawood_tree\",\n \"connarus_guianensis\",\n \"legume, leguminous_plant\",\n \"legume\",\n \"peanut\",\n \"granadilla_tree, granadillo, brya_ebenus\",\n \"arariba, centrolobium_robustum\",\n \"tonka_bean, coumara_nut\",\n \"courbaril, hymenaea_courbaril\",\n \"melilotus, melilot, sweet_clover\",\n \"darling_pea, poison_bush\",\n \"smooth_darling_pea, swainsona_galegifolia\",\n \"clover, trefoil\",\n \"alpine_clover, trifolium_alpinum\",\n \"hop_clover, shamrock, lesser_yellow_trefoil, trifolium_dubium\",\n \"crimson_clover, italian_clover, trifolium_incarnatum\",\n \"red_clover, purple_clover, trifolium_pratense\",\n \"buffalo_clover, trifolium_reflexum, trifolium_stoloniferum\",\n \"white_clover, dutch_clover, shamrock, trifolium_repens\",\n \"mimosa\",\n \"acacia\",\n \"shittah, shittah_tree\",\n \"wattle\",\n \"black_wattle, acacia_auriculiformis\",\n \"gidgee, stinking_wattle, acacia_cambegei\",\n \"catechu, jerusalem_thorn, acacia_catechu\",\n \"silver_wattle, mimosa, acacia_dealbata\",\n \"huisache, cassie, mimosa_bush, sweet_wattle, sweet_acacia, scented_wattle, flame_tree, acacia_farnesiana\",\n \"lightwood, acacia_melanoxylon\",\n \"golden_wattle, acacia_pycnantha\",\n \"fever_tree, acacia_xanthophloea\",\n \"coralwood, coral-wood, red_sandalwood, barbados_pride, peacock_flower_fence, adenanthera_pavonina\",\n \"albizzia, albizia\",\n \"silk_tree, albizia_julibrissin, albizzia_julibrissin\",\n \"siris, siris_tree, albizia_lebbeck, albizzia_lebbeck\",\n \"rain_tree, saman, monkeypod, monkey_pod, zaman, zamang, albizia_saman\",\n \"calliandra\",\n \"conacaste, elephant's_ear, enterolobium_cyclocarpa\",\n \"inga\",\n \"ice-cream_bean, inga_edulis\",\n \"guama, inga_laurina\",\n \"lead_tree, white_popinac, leucaena_glauca, leucaena_leucocephala\",\n \"wild_tamarind, lysiloma_latisiliqua, lysiloma_bahamensis\",\n \"sabicu, lysiloma_sabicu\",\n \"nitta_tree\",\n \"parkia_javanica\",\n \"manila_tamarind, camachile, huamachil, wild_tamarind, pithecellobium_dulce\",\n \"cat's-claw, catclaw, black_bead, pithecellodium_unguis-cati\",\n \"honey_mesquite, western_honey_mesquite, prosopis_glandulosa\",\n \"algarroba, algarrobilla, algarobilla\",\n \"screw_bean, screwbean, tornillo, screwbean_mesquite, prosopis_pubescens\",\n \"screw_bean\",\n \"dogbane\",\n \"indian_hemp, rheumatism_weed, apocynum_cannabinum\",\n \"bushman's_poison, ordeal_tree, acocanthera_oppositifolia, acocanthera_venenata\",\n \"impala_lily, mock_azalia, desert_rose, kudu_lily, adenium_obesum, adenium_multiflorum\",\n \"allamanda\",\n \"common_allamanda, golden_trumpet, allamanda_cathartica\",\n \"dita, dita_bark, devil_tree, alstonia_scholaris\",\n \"nepal_trumpet_flower, easter_lily_vine, beaumontia_grandiflora\",\n \"carissa\",\n \"hedge_thorn, natal_plum, carissa_bispinosa\",\n \"natal_plum, amatungulu, carissa_macrocarpa, carissa_grandiflora\",\n \"periwinkle, rose_periwinkle, madagascar_periwinkle, old_maid, cape_periwinkle, red_periwinkle, cayenne_jasmine, catharanthus_roseus, vinca_rosea\",\n \"ivory_tree, conessi, kurchi, kurchee, holarrhena_pubescens, holarrhena_antidysenterica\",\n \"white_dipladenia, mandevilla_boliviensis, dipladenia_boliviensis\",\n \"chilean_jasmine, mandevilla_laxa\",\n \"oleander, rose_bay, nerium_oleander\",\n \"frangipani, frangipanni\",\n \"west_indian_jasmine, pagoda_tree, plumeria_alba\",\n \"rauwolfia, rauvolfia\",\n \"snakewood, rauwolfia_serpentina\",\n \"strophanthus_kombe\",\n \"yellow_oleander, thevetia_peruviana, thevetia_neriifolia\",\n \"myrtle, vinca_minor\",\n \"large_periwinkle, vinca_major\",\n \"arum, aroid\",\n \"cuckoopint, lords-and-ladies, jack-in-the-pulpit, arum_maculatum\",\n \"black_calla, arum_palaestinum\",\n \"calamus\",\n \"alocasia, elephant's_ear, elephant_ear\",\n \"giant_taro, alocasia_macrorrhiza\",\n \"amorphophallus\",\n \"pungapung, telingo_potato, elephant_yam, amorphophallus_paeonifolius, amorphophallus_campanulatus\",\n \"devil's_tongue, snake_palm, umbrella_arum, amorphophallus_rivieri\",\n \"anthurium, tailflower, tail-flower\",\n \"flamingo_flower, flamingo_plant, anthurium_andraeanum, anthurium_scherzerianum\",\n \"jack-in-the-pulpit, indian_turnip, wake-robin, arisaema_triphyllum, arisaema_atrorubens\",\n \"friar's-cowl, arisarum_vulgare\",\n \"caladium\",\n \"caladium_bicolor\",\n \"wild_calla, water_arum, calla_palustris\",\n \"taro, taro_plant, dalo, dasheen, colocasia_esculenta\",\n \"taro, cocoyam, dasheen, eddo\",\n \"cryptocoryne, water_trumpet\",\n \"dracontium\",\n \"golden_pothos, pothos, ivy_arum, epipremnum_aureum, scindapsus_aureus\",\n \"skunk_cabbage, lysichiton_americanum\",\n \"monstera\",\n \"ceriman, monstera_deliciosa\",\n \"nephthytis\",\n \"nephthytis_afzelii\",\n \"arrow_arum\",\n \"green_arrow_arum, tuckahoe, peltandra_virginica\",\n \"philodendron\",\n \"pistia, water_lettuce, water_cabbage, pistia_stratiotes, pistia_stratoites\",\n \"pothos\",\n \"spathiphyllum, peace_lily, spathe_flower\",\n \"skunk_cabbage, polecat_weed, foetid_pothos, symplocarpus_foetidus\",\n \"yautia, tannia, spoonflower, malanga, xanthosoma_sagittifolium, xanthosoma_atrovirens\",\n \"calla_lily, calla, arum_lily, zantedeschia_aethiopica\",\n \"pink_calla, zantedeschia_rehmanii\",\n \"golden_calla\",\n \"duckweed\",\n \"common_duckweed, lesser_duckweed, lemna_minor\",\n \"star-duckweed, lemna_trisulca\",\n \"great_duckweed, water_flaxseed, spirodela_polyrrhiza\",\n \"watermeal\",\n \"common_wolffia, wolffia_columbiana\",\n \"aralia\",\n \"american_angelica_tree, devil's_walking_stick, hercules'-club, aralia_spinosa\",\n \"american_spikenard, petty_morel, life-of-man, aralia_racemosa\",\n \"bristly_sarsaparilla, bristly_sarsparilla, dwarf_elder, aralia_hispida\",\n \"japanese_angelica_tree, aralia_elata\",\n \"chinese_angelica, chinese_angelica_tree, aralia_stipulata\",\n \"ivy, common_ivy, english_ivy, hedera_helix\",\n \"puka, meryta_sinclairii\",\n \"ginseng, nin-sin, panax_ginseng, panax_schinseng, panax_pseudoginseng\",\n \"ginseng\",\n \"umbrella_tree, schefflera_actinophylla, brassaia_actinophylla\",\n \"birthwort, aristolochia_clematitis\",\n \"dutchman's-pipe, pipe_vine, aristolochia_macrophylla, aristolochia_durior\",\n \"virginia_snakeroot, virginia_serpentaria, virginia_serpentary, aristolochia_serpentaria\",\n \"canada_ginger, black_snakeroot, asarum_canadense\",\n \"heartleaf, heart-leaf, asarum_virginicum\",\n \"heartleaf, heart-leaf, asarum_shuttleworthii\",\n \"asarabacca, asarum_europaeum\",\n \"caryophyllaceous_plant\",\n \"corn_cockle, corn_campion, crown-of-the-field, agrostemma_githago\",\n \"sandwort\",\n \"mountain_sandwort, mountain_starwort, mountain_daisy, arenaria_groenlandica\",\n \"pine-barren_sandwort, longroot, arenaria_caroliniana\",\n \"seabeach_sandwort, arenaria_peploides\",\n \"rock_sandwort, arenaria_stricta\",\n \"thyme-leaved_sandwort, arenaria_serpyllifolia\",\n \"mouse-ear_chickweed, mouse_eared_chickweed, mouse_ear, clammy_chickweed, chickweed\",\n \"snow-in-summer, love-in-a-mist, cerastium_tomentosum\",\n \"alpine_mouse-ear, arctic_mouse-ear, cerastium_alpinum\",\n \"pink, garden_pink\",\n \"sweet_william, dianthus_barbatus\",\n \"carnation, clove_pink, gillyflower, dianthus_caryophyllus\",\n \"china_pink, rainbow_pink, dianthus_chinensis\",\n \"japanese_pink, dianthus_chinensis_heddewigii\",\n \"maiden_pink, dianthus_deltoides\",\n \"cheddar_pink, diangus_gratianopolitanus\",\n \"button_pink, dianthus_latifolius\",\n \"cottage_pink, grass_pink, dianthus_plumarius\",\n \"fringed_pink, dianthus_supurbus\",\n \"drypis\",\n \"baby's_breath, babies'-breath, gypsophila_paniculata\",\n \"coral_necklace, illecebrum_verticullatum\",\n \"lychnis, catchfly\",\n \"ragged_robin, cuckoo_flower, lychnis_flos-cuculi, lychins_floscuculi\",\n \"scarlet_lychnis, maltese_cross, lychins_chalcedonica\",\n \"mullein_pink, rose_campion, gardener's_delight, dusty_miller, lychnis_coronaria\",\n \"sandwort, moehringia_lateriflora\",\n \"sandwort, moehringia_mucosa\",\n \"soapwort, hedge_pink, bouncing_bet, bouncing_bess, saponaria_officinalis\",\n \"knawel, knawe, scleranthus_annuus\",\n \"silene, campion, catchfly\",\n \"moss_campion, silene_acaulis\",\n \"wild_pink, silene_caroliniana\",\n \"red_campion, red_bird's_eye, silene_dioica, lychnis_dioica\",\n \"white_campion, evening_lychnis, white_cockle, bladder_campion, silene_latifolia, lychnis_alba\",\n \"fire_pink, silene_virginica\",\n \"bladder_campion, silene_uniflora, silene_vulgaris\",\n \"corn_spurry, corn_spurrey, spergula_arvensis\",\n \"sand_spurry, sea_spurry, spergularia_rubra\",\n \"chickweed\",\n \"common_chickweed, stellaria_media\",\n \"cowherb, cow_cockle, vaccaria_hispanica, vaccaria_pyramidata, saponaria_vaccaria\",\n \"hottentot_fig, hottentot's_fig, sour_fig, carpobrotus_edulis, mesembryanthemum_edule\",\n \"livingstone_daisy, dorotheanthus_bellidiformis\",\n \"fig_marigold, pebble_plant\",\n \"ice_plant, icicle_plant, mesembryanthemum_crystallinum\",\n \"new_zealand_spinach, tetragonia_tetragonioides, tetragonia_expansa\",\n \"amaranth\",\n \"amaranth\",\n \"tumbleweed, amaranthus_albus, amaranthus_graecizans\",\n \"prince's-feather, gentleman's-cane, prince's-plume, red_amaranth, purple_amaranth, amaranthus_cruentus, amaranthus_hybridus_hypochondriacus, amaranthus_hybridus_erythrostachys\",\n \"pigweed, amaranthus_hypochondriacus\",\n \"thorny_amaranth, amaranthus_spinosus\",\n \"alligator_weed, alligator_grass, alternanthera_philoxeroides\",\n \"cockscomb, common_cockscomb, celosia_cristata, celosia_argentea_cristata\",\n \"cottonweed\",\n \"globe_amaranth, bachelor's_button, gomphrena_globosa\",\n \"bloodleaf\",\n \"saltwort, batis_maritima\",\n \"lamb's-quarters, pigweed, wild_spinach, chenopodium_album\",\n \"good-king-henry, allgood, fat_hen, wild_spinach, chenopodium_bonus-henricus\",\n \"jerusalem_oak, feather_geranium, mexican_tea, chenopodium_botrys, atriplex_mexicana\",\n \"oak-leaved_goosefoot, oakleaf_goosefoot, chenopodium_glaucum\",\n \"sowbane, red_goosefoot, chenopodium_hybridum\",\n \"nettle-leaved_goosefoot, nettleleaf_goosefoot, chenopodium_murale\",\n \"red_goosefoot, french_spinach, chenopodium_rubrum\",\n \"stinking_goosefoot, chenopodium_vulvaria\",\n \"orach, orache\",\n \"saltbush\",\n \"garden_orache, mountain_spinach, atriplex_hortensis\",\n \"desert_holly, atriplex_hymenelytra\",\n \"quail_bush, quail_brush, white_thistle, atriplex_lentiformis\",\n \"beet, common_beet, beta_vulgaris\",\n \"beetroot, beta_vulgaris_rubra\",\n \"chard, swiss_chard, spinach_beet, leaf_beet, chard_plant, beta_vulgaris_cicla\",\n \"mangel-wurzel, mangold-wurzel, mangold, beta_vulgaris_vulgaris\",\n \"winged_pigweed, tumbleweed, cycloloma_atriplicifolium\",\n \"halogeton, halogeton_glomeratus\",\n \"glasswort, samphire, salicornia_europaea\",\n \"saltwort, barilla, glasswort, kali, kelpwort, salsola_kali, salsola_soda\",\n \"russian_thistle, russian_tumbleweed, russian_cactus, tumbleweed, salsola_kali_tenuifolia\",\n \"greasewood, black_greasewood, sarcobatus_vermiculatus\",\n \"scarlet_musk_flower, nyctaginia_capitata\",\n \"sand_verbena\",\n \"sweet_sand_verbena, abronia_fragrans\",\n \"yellow_sand_verbena, abronia_latifolia\",\n \"beach_pancake, abronia_maritima\",\n \"beach_sand_verbena, pink_sand_verbena, abronia_umbellata\",\n \"desert_sand_verbena, abronia_villosa\",\n \"trailing_four_o'clock, trailing_windmills, allionia_incarnata\",\n \"bougainvillea\",\n \"umbrellawort\",\n \"four_o'clock\",\n \"common_four-o'clock, marvel-of-peru, mirabilis_jalapa, mirabilis_uniflora\",\n \"california_four_o'clock, mirabilis_laevis, mirabilis_californica\",\n \"sweet_four_o'clock, maravilla, mirabilis_longiflora\",\n \"desert_four_o'clock, colorado_four_o'clock, maravilla, mirabilis_multiflora\",\n \"mountain_four_o'clock, mirabilis_oblongifolia\",\n \"cockspur, pisonia_aculeata\",\n \"rattail_cactus, rat's-tail_cactus, aporocactus_flagelliformis\",\n \"saguaro, sahuaro, carnegiea_gigantea\",\n \"night-blooming_cereus\",\n \"echinocactus, barrel_cactus\",\n \"hedgehog_cactus\",\n \"golden_barrel_cactus, echinocactus_grusonii\",\n \"hedgehog_cereus\",\n \"rainbow_cactus\",\n \"epiphyllum, orchid_cactus\",\n \"barrel_cactus\",\n \"night-blooming_cereus\",\n \"chichipe, lemaireocereus_chichipe\",\n \"mescal, mezcal, peyote, lophophora_williamsii\",\n \"mescal_button, sacred_mushroom, magic_mushroom\",\n \"mammillaria\",\n \"feather_ball, mammillaria_plumosa\",\n \"garambulla, garambulla_cactus, myrtillocactus_geometrizans\",\n \"knowlton's_cactus, pediocactus_knowltonii\",\n \"nopal\",\n \"prickly_pear, prickly_pear_cactus\",\n \"cholla, opuntia_cholla\",\n \"nopal, opuntia_lindheimeri\",\n \"tuna, opuntia_tuna\",\n \"barbados_gooseberry, barbados-gooseberry_vine, pereskia_aculeata\",\n \"mistletoe_cactus\",\n \"christmas_cactus, schlumbergera_buckleyi, schlumbergera_baridgesii\",\n \"night-blooming_cereus\",\n \"crab_cactus, thanksgiving_cactus, zygocactus_truncatus, schlumbergera_truncatus\",\n \"pokeweed\",\n \"indian_poke, phytolacca_acinosa\",\n \"poke, pigeon_berry, garget, scoke, phytolacca_americana\",\n \"ombu, bella_sombra, phytolacca_dioica\",\n \"bloodberry, blood_berry, rougeberry, rouge_plant, rivina_humilis\",\n \"portulaca\",\n \"rose_moss, sun_plant, portulaca_grandiflora\",\n \"common_purslane, pussley, pussly, verdolagas, portulaca_oleracea\",\n \"rock_purslane\",\n \"red_maids, redmaids, calandrinia_ciliata\",\n \"carolina_spring_beauty, claytonia_caroliniana\",\n \"spring_beauty, clatonia_lanceolata\",\n \"virginia_spring_beauty, claytonia_virginica\",\n \"siskiyou_lewisia, lewisia_cotyledon\",\n \"bitterroot, lewisia_rediviva\",\n \"broad-leaved_montia, montia_cordifolia\",\n \"blinks, blinking_chickweed, water_chickweed, montia_lamprosperma\",\n \"toad_lily, montia_chamissoi\",\n \"winter_purslane, miner's_lettuce, cuban_spinach, montia_perfoliata\",\n \"flame_flower, flame-flower, flameflower, talinum_aurantiacum\",\n \"pigmy_talinum, talinum_brevifolium\",\n \"jewels-of-opar, talinum_paniculatum\",\n \"caper\",\n \"native_pomegranate, capparis_arborea\",\n \"caper_tree, jamaica_caper_tree, capparis_cynophallophora\",\n \"caper_tree, bay-leaved_caper, capparis_flexuosa\",\n \"common_caper, capparis_spinosa\",\n \"spiderflower, cleome\",\n \"rocky_mountain_bee_plant, stinking_clover, cleome_serrulata\",\n \"clammyweed, polanisia_graveolens, polanisia_dodecandra\",\n \"crucifer, cruciferous_plant\",\n \"cress, cress_plant\",\n \"watercress\",\n \"stonecress, stone_cress\",\n \"garlic_mustard, hedge_garlic, sauce-alone, jack-by-the-hedge, alliaria_officinalis\",\n \"alyssum, madwort\",\n \"rose_of_jericho, resurrection_plant, anastatica_hierochuntica\",\n \"arabidopsis_thaliana, mouse-ear_cress\",\n \"arabidopsis_lyrata\",\n \"rock_cress, rockcress\",\n \"sicklepod, arabis_canadensis\",\n \"tower_mustard, tower_cress, turritis_glabra, arabis_glabra\",\n \"horseradish, horseradish_root\",\n \"winter_cress, st._barbara's_herb, scurvy_grass\",\n \"yellow_rocket, rockcress, rocket_cress, barbarea_vulgaris, sisymbrium_barbarea\",\n \"hoary_alison, hoary_alyssum, berteroa_incana\",\n \"buckler_mustard, biscutalla_laevigata\",\n \"wild_cabbage, brassica_oleracea\",\n \"cabbage, cultivated_cabbage, brassica_oleracea\",\n \"head_cabbage, head_cabbage_plant, brassica_oleracea_capitata\",\n \"savoy_cabbage\",\n \"brussels_sprout, brassica_oleracea_gemmifera\",\n \"cauliflower, brassica_oleracea_botrytis\",\n \"broccoli, brassica_oleracea_italica\",\n \"collard\",\n \"kohlrabi, brassica_oleracea_gongylodes\",\n \"turnip_plant\",\n \"turnip, white_turnip, brassica_rapa\",\n \"rutabaga, turnip_cabbage, swede, swedish_turnip, rutabaga_plant, brassica_napus_napobrassica\",\n \"broccoli_raab, broccoli_rabe, brassica_rapa_ruvo\",\n \"mustard\",\n \"chinese_mustard, indian_mustard, leaf_mustard, gai_choi, brassica_juncea\",\n \"bok_choy, bok_choi, pakchoi, pak_choi, chinese_white_cabbage, brassica_rapa_chinensis\",\n \"rape, colza, brassica_napus\",\n \"rapeseed\",\n \"shepherd's_purse, shepherd's_pouch, capsella_bursa-pastoris\",\n \"lady's_smock, cuckooflower, cuckoo_flower, meadow_cress, cardamine_pratensis\",\n \"coral-root_bittercress, coralroot, coralwort, cardamine_bulbifera, dentaria_bulbifera\",\n \"crinkleroot, crinkle-root, crinkle_root, pepper_root, toothwort, cardamine_diphylla, dentaria_diphylla\",\n \"american_watercress, mountain_watercress, cardamine_rotundifolia\",\n \"spring_cress, cardamine_bulbosa\",\n \"purple_cress, cardamine_douglasii\",\n \"wallflower, cheiranthus_cheiri, erysimum_cheiri\",\n \"prairie_rocket\",\n \"scurvy_grass, common_scurvy_grass, cochlearia_officinalis\",\n \"sea_kale, sea_cole, crambe_maritima\",\n \"tansy_mustard, descurainia_pinnata\",\n \"draba\",\n \"wallflower\",\n \"prairie_rocket\",\n \"siberian_wall_flower, erysimum_allionii, cheiranthus_allionii\",\n \"western_wall_flower, erysimum_asperum, cheiranthus_asperus, erysimum_arkansanum\",\n \"wormseed_mustard, erysimum_cheiranthoides\",\n \"heliophila\",\n \"damask_violet, dame's_violet, sweet_rocket, hesperis_matronalis\",\n \"tansy-leaved_rocket, hugueninia_tanacetifolia, sisymbrium_tanacetifolia\",\n \"candytuft\",\n \"woad\",\n \"dyer's_woad, isatis_tinctoria\",\n \"bladderpod\",\n \"sweet_alyssum, sweet_alison, lobularia_maritima\",\n \"malcolm_stock, stock\",\n \"virginian_stock, virginia_stock, malcolmia_maritima\",\n \"stock, gillyflower\",\n \"brompton_stock, matthiola_incana\",\n \"bladderpod\",\n \"chamois_cress, pritzelago_alpina, lepidium_alpina\",\n \"radish_plant, radish\",\n \"jointed_charlock, wild_radish, wild_rape, runch, raphanus_raphanistrum\",\n \"radish, raphanus_sativus\",\n \"radish, daikon, japanese_radish, raphanus_sativus_longipinnatus\",\n \"marsh_cress, yellow_watercress, rorippa_islandica\",\n \"great_yellowcress, rorippa_amphibia, nasturtium_amphibium\",\n \"schizopetalon, schizopetalon_walkeri\",\n \"field_mustard, wild_mustard, charlock, chadlock, brassica_kaber, sinapis_arvensis\",\n \"hedge_mustard, sisymbrium_officinale\",\n \"desert_plume, prince's-plume, stanleya_pinnata, cleome_pinnata\",\n \"pennycress\",\n \"field_pennycress, french_weed, fanweed, penny_grass, stinkweed, mithridate_mustard, thlaspi_arvense\",\n \"fringepod, lacepod\",\n \"bladderpod\",\n \"wasabi\",\n \"poppy\",\n \"iceland_poppy, papaver_alpinum\",\n \"western_poppy, papaver_californicum\",\n \"prickly_poppy, papaver_argemone\",\n \"iceland_poppy, arctic_poppy, papaver_nudicaule\",\n \"oriental_poppy, papaver_orientale\",\n \"corn_poppy, field_poppy, flanders_poppy, papaver_rhoeas\",\n \"opium_poppy, papaver_somniferum\",\n \"prickly_poppy, argemone, white_thistle, devil's_fig\",\n \"mexican_poppy, argemone_mexicana\",\n \"bocconia, tree_celandine, bocconia_frutescens\",\n \"celandine, greater_celandine, swallowwort, swallow_wort, chelidonium_majus\",\n \"corydalis\",\n \"climbing_corydalis, corydalis_claviculata, fumaria_claviculata\",\n \"california_poppy, eschscholtzia_californica\",\n \"horn_poppy, horned_poppy, yellow_horned_poppy, sea_poppy, glaucium_flavum\",\n \"golden_cup, mexican_tulip_poppy, hunnemania_fumariifolia\",\n \"plume_poppy, bocconia, macleaya_cordata\",\n \"blue_poppy, meconopsis_betonicifolia\",\n \"welsh_poppy, meconopsis_cambrica\",\n \"creamcups, platystemon_californicus\",\n \"matilija_poppy, california_tree_poppy, romneya_coulteri\",\n \"wind_poppy, flaming_poppy, stylomecon_heterophyllum, papaver_heterophyllum\",\n \"celandine_poppy, wood_poppy, stylophorum_diphyllum\",\n \"climbing_fumitory, allegheny_vine, adlumia_fungosa, fumaria_fungosa\",\n \"bleeding_heart, lyreflower, lyre-flower, dicentra_spectabilis\",\n \"dutchman's_breeches, dicentra_cucullaria\",\n \"squirrel_corn, dicentra_canadensis\",\n \"composite, composite_plant\",\n \"compass_plant, compass_flower\",\n \"everlasting, everlasting_flower\",\n \"achillea\",\n \"yarrow, milfoil, achillea_millefolium\",\n \"pink-and-white_everlasting, pink_paper_daisy, acroclinium_roseum\",\n \"white_snakeroot, white_sanicle, ageratina_altissima, eupatorium_rugosum\",\n \"ageratum\",\n \"common_ageratum, ageratum_houstonianum\",\n \"sweet_sultan, amberboa_moschata, centaurea_moschata\",\n \"ragweed, ambrosia, bitterweed\",\n \"common_ragweed, ambrosia_artemisiifolia\",\n \"great_ragweed, ambrosia_trifida\",\n \"western_ragweed, perennial_ragweed, ambrosia_psilostachya\",\n \"ammobium\",\n \"winged_everlasting, ammobium_alatum\",\n \"pellitory, pellitory-of-spain, anacyclus_pyrethrum\",\n \"pearly_everlasting, cottonweed, anaphalis_margaritacea\",\n \"andryala\",\n \"plantain-leaved_pussytoes\",\n \"field_pussytoes\",\n \"solitary_pussytoes\",\n \"mountain_everlasting\",\n \"mayweed, dog_fennel, stinking_mayweed, stinking_chamomile, anthemis_cotula\",\n \"yellow_chamomile, golden_marguerite, dyers'_chamomile, anthemis_tinctoria\",\n \"corn_chamomile, field_chamomile, corn_mayweed, anthemis_arvensis\",\n \"woolly_daisy, dwarf_daisy, antheropeas_wallacei, eriophyllum_wallacei\",\n \"burdock, clotbur\",\n \"great_burdock, greater_burdock, cocklebur, arctium_lappa\",\n \"african_daisy\",\n \"blue-eyed_african_daisy, arctotis_stoechadifolia, arctotis_venusta\",\n \"marguerite, marguerite_daisy, paris_daisy, chrysanthemum_frutescens, argyranthemum_frutescens\",\n \"silversword, argyroxiphium_sandwicense\",\n \"arnica\",\n \"heartleaf_arnica, arnica_cordifolia\",\n \"arnica_montana\",\n \"lamb_succory, dwarf_nipplewort, arnoseris_minima\",\n \"artemisia\",\n \"mugwort\",\n \"sweet_wormwood, artemisia_annua\",\n \"field_wormwood, artemisia_campestris\",\n \"tarragon, estragon, artemisia_dracunculus\",\n \"sand_sage, silvery_wormwood, artemisia_filifolia\",\n \"wormwood_sage, prairie_sagewort, artemisia_frigida\",\n \"western_mugwort, white_sage, cudweed, prairie_sage, artemisia_ludoviciana, artemisia_gnaphalodes\",\n \"roman_wormwood, artemis_pontica\",\n \"bud_brush, bud_sagebrush, artemis_spinescens\",\n \"common_mugwort, artemisia_vulgaris\",\n \"aster\",\n \"wood_aster\",\n \"whorled_aster, aster_acuminatus\",\n \"heath_aster, aster_arenosus\",\n \"heart-leaved_aster, aster_cordifolius\",\n \"white_wood_aster, aster_divaricatus\",\n \"bushy_aster, aster_dumosus\",\n \"heath_aster, aster_ericoides\",\n \"white_prairie_aster, aster_falcatus\",\n \"stiff_aster, aster_linarifolius\",\n \"goldilocks, goldilocks_aster, aster_linosyris, linosyris_vulgaris\",\n \"large-leaved_aster, aster_macrophyllus\",\n \"new_england_aster, aster_novae-angliae\",\n \"michaelmas_daisy, new_york_aster, aster_novi-belgii\",\n \"upland_white_aster, aster_ptarmicoides\",\n \"short's_aster, aster_shortii\",\n \"sea_aster, sea_starwort, aster_tripolium\",\n \"prairie_aster, aster_turbinellis\",\n \"annual_salt-marsh_aster\",\n \"aromatic_aster\",\n \"arrow_leaved_aster\",\n \"azure_aster\",\n \"bog_aster\",\n \"crooked-stemmed_aster\",\n \"eastern_silvery_aster\",\n \"flat-topped_white_aster\",\n \"late_purple_aster\",\n \"panicled_aster\",\n \"perennial_salt_marsh_aster\",\n \"purple-stemmed_aster\",\n \"rough-leaved_aster\",\n \"rush_aster\",\n \"schreiber's_aster\",\n \"small_white_aster\",\n \"smooth_aster\",\n \"southern_aster\",\n \"starved_aster, calico_aster\",\n \"tradescant's_aster\",\n \"wavy-leaved_aster\",\n \"western_silvery_aster\",\n \"willow_aster\",\n \"ayapana, ayapana_triplinervis, eupatorium_aya-pana\",\n \"mule_fat, baccharis_viminea\",\n \"balsamroot\",\n \"daisy\",\n \"common_daisy, english_daisy, bellis_perennis\",\n \"bur_marigold, burr_marigold, beggar-ticks, beggar's-ticks, sticktight\",\n \"spanish_needles, bidens_bipinnata\",\n \"tickseed_sunflower, bidens_coronata, bidens_trichosperma\",\n \"european_beggar-ticks, trifid_beggar-ticks, trifid_bur_marigold, bidens_tripartita\",\n \"slender_knapweed\",\n \"false_chamomile\",\n \"swan_river_daisy, brachycome_iberidifolia\",\n \"woodland_oxeye, buphthalmum_salicifolium\",\n \"indian_plantain\",\n \"calendula\",\n \"common_marigold, pot_marigold, ruddles, scotch_marigold, calendula_officinalis\",\n \"china_aster, callistephus_chinensis\",\n \"thistle\",\n \"welted_thistle, carduus_crispus\",\n \"musk_thistle, nodding_thistle, carduus_nutans\",\n \"carline_thistle\",\n \"stemless_carline_thistle, carlina_acaulis\",\n \"common_carline_thistle, carlina_vulgaris\",\n \"safflower, false_saffron, carthamus_tinctorius\",\n \"safflower_seed\",\n \"catananche\",\n \"blue_succory, cupid's_dart, catananche_caerulea\",\n \"centaury\",\n \"dusty_miller, centaurea_cineraria, centaurea_gymnocarpa\",\n \"cornflower, bachelor's_button, bluebottle, centaurea_cyanus\",\n \"star-thistle, caltrop, centauria_calcitrapa\",\n \"knapweed\",\n \"sweet_sultan, centaurea_imperialis\",\n \"great_knapweed, greater_knapweed, centaurea_scabiosa\",\n \"barnaby's_thistle, yellow_star-thistle, centaurea_solstitialis\",\n \"chamomile, camomile, chamaemelum_nobilis, anthemis_nobilis\",\n \"chaenactis\",\n \"chrysanthemum\",\n \"corn_marigold, field_marigold, chrysanthemum_segetum\",\n \"crown_daisy, chrysanthemum_coronarium\",\n \"chop-suey_greens, tong_ho, shun_giku, chrysanthemum_coronarium_spatiosum\",\n \"golden_aster\",\n \"maryland_golden_aster, chrysopsis_mariana\",\n \"goldenbush\",\n \"rabbit_brush, rabbit_bush, chrysothamnus_nauseosus\",\n \"chicory, succory, chicory_plant, cichorium_intybus\",\n \"endive, witloof, cichorium_endivia\",\n \"chicory, chicory_root\",\n \"plume_thistle, plumed_thistle\",\n \"canada_thistle, creeping_thistle, cirsium_arvense\",\n \"field_thistle, cirsium_discolor\",\n \"woolly_thistle, cirsium_flodmanii\",\n \"european_woolly_thistle, cirsium_eriophorum\",\n \"melancholy_thistle, cirsium_heterophylum, cirsium_helenioides\",\n \"brook_thistle, cirsium_rivulare\",\n \"bull_thistle, boar_thistle, spear_thistle, cirsium_vulgare, cirsium_lanceolatum\",\n \"blessed_thistle, sweet_sultan, cnicus_benedictus\",\n \"mistflower, mist-flower, ageratum, conoclinium_coelestinum, eupatorium_coelestinum\",\n \"horseweed, canadian_fleabane, fleabane, conyza_canadensis, erigeron_canadensis\",\n \"coreopsis, tickseed, tickweed, tick-weed\",\n \"giant_coreopsis, coreopsis_gigantea\",\n \"sea_dahlia, coreopsis_maritima\",\n \"calliopsis, coreopsis_tinctoria\",\n \"cosmos, cosmea\",\n \"brass_buttons, cotula_coronopifolia\",\n \"billy_buttons\",\n \"hawk's-beard, hawk's-beards\",\n \"artichoke, globe_artichoke, artichoke_plant, cynara_scolymus\",\n \"cardoon, cynara_cardunculus\",\n \"dahlia, dahlia_pinnata\",\n \"german_ivy, delairea_odorata, senecio_milkanioides\",\n \"florist's_chrysanthemum, florists'_chrysanthemum, mum, dendranthema_grandifloruom, chrysanthemum_morifolium\",\n \"cape_marigold, sun_marigold, star_of_the_veldt\",\n \"leopard's-bane, leopardbane\",\n \"coneflower\",\n \"globe_thistle\",\n \"elephant's-foot\",\n \"tassel_flower, emilia_sagitta\",\n \"brittlebush, brittle_bush, incienso, encelia_farinosa\",\n \"sunray, enceliopsis_nudicaulis\",\n \"engelmannia\",\n \"fireweed, erechtites_hieracifolia\",\n \"fleabane\",\n \"blue_fleabane, erigeron_acer\",\n \"daisy_fleabane, erigeron_annuus\",\n \"orange_daisy, orange_fleabane, erigeron_aurantiacus\",\n \"spreading_fleabane, erigeron_divergens\",\n \"seaside_daisy, beach_aster, erigeron_glaucous\",\n \"philadelphia_fleabane, erigeron_philadelphicus\",\n \"robin's_plantain, erigeron_pulchellus\",\n \"showy_daisy, erigeron_speciosus\",\n \"woolly_sunflower\",\n \"golden_yarrow, eriophyllum_lanatum\",\n \"dog_fennel, eupatorium_capillifolium\",\n \"joe-pye_weed, spotted_joe-pye_weed, eupatorium_maculatum\",\n \"boneset, agueweed, thoroughwort, eupatorium_perfoliatum\",\n \"joe-pye_weed, purple_boneset, trumpet_weed, marsh_milkweed, eupatorium_purpureum\",\n \"blue_daisy, blue_marguerite, felicia_amelloides\",\n \"kingfisher_daisy, felicia_bergeriana\",\n \"cotton_rose, cudweed, filago\",\n \"herba_impia, filago_germanica\",\n \"gaillardia\",\n \"gazania\",\n \"treasure_flower, gazania_rigens\",\n \"african_daisy\",\n \"barberton_daisy, transvaal_daisy, gerbera_jamesonii\",\n \"desert_sunflower, gerea_canescens\",\n \"cudweed\",\n \"chafeweed, wood_cudweed, gnaphalium_sylvaticum\",\n \"gumweed, gum_plant, tarweed, rosinweed\",\n \"grindelia_robusta\",\n \"curlycup_gumweed, grindelia_squarrosa\",\n \"little-head_snakeweed, gutierrezia_microcephala\",\n \"rabbitweed, rabbit-weed, snakeweed, broom_snakeweed, broom_snakeroot, turpentine_weed, gutierrezia_sarothrae\",\n \"broomweed, broom-weed, gutierrezia_texana\",\n \"velvet_plant, purple_velvet_plant, royal_velvet_plant, gynura_aurantiaca\",\n \"goldenbush\",\n \"camphor_daisy, haplopappus_phyllocephalus\",\n \"yellow_spiny_daisy, haplopappus_spinulosus\",\n \"hoary_golden_bush, hazardia_cana\",\n \"sneezeweed\",\n \"orange_sneezeweed, owlclaws, helenium_hoopesii\",\n \"rosilla, helenium_puberulum\",\n \"sunflower, helianthus\",\n \"swamp_sunflower, helianthus_angustifolius\",\n \"common_sunflower, mirasol, helianthus_annuus\",\n \"giant_sunflower, tall_sunflower, indian_potato, helianthus_giganteus\",\n \"showy_sunflower, helianthus_laetiflorus\",\n \"maximilian's_sunflower, helianthus_maximilianii\",\n \"prairie_sunflower, helianthus_petiolaris\",\n \"jerusalem_artichoke, girasol, jerusalem_artichoke_sunflower, helianthus_tuberosus\",\n \"jerusalem_artichoke\",\n \"strawflower, golden_everlasting, yellow_paper_daisy, helichrysum_bracteatum\",\n \"heliopsis, oxeye\",\n \"strawflower\",\n \"hairy_golden_aster, prairie_golden_aster, heterotheca_villosa, chrysopsis_villosa\",\n \"hawkweed\",\n \"rattlesnake_weed, hieracium_venosum\",\n \"alpine_coltsfoot, homogyne_alpina, tussilago_alpina\",\n \"alpine_gold, alpine_hulsea, hulsea_algida\",\n \"dwarf_hulsea, hulsea_nana\",\n \"cat's-ear, california_dandelion, capeweed, gosmore, hypochaeris_radicata\",\n \"inula\",\n \"marsh_elder, iva\",\n \"burweed_marsh_elder, false_ragweed, iva_xanthifolia\",\n \"krigia\",\n \"dwarf_dandelion, krigia_dandelion, krigia_bulbosa\",\n \"garden_lettuce, common_lettuce, lactuca_sativa\",\n \"cos_lettuce, romaine_lettuce, lactuca_sativa_longifolia\",\n \"leaf_lettuce, lactuca_sativa_crispa\",\n \"celtuce, stem_lettuce, lactuca_sativa_asparagina\",\n \"prickly_lettuce, horse_thistle, lactuca_serriola, lactuca_scariola\",\n \"goldfields, lasthenia_chrysostoma\",\n \"tidytips, tidy_tips, layia_platyglossa\",\n \"hawkbit\",\n \"fall_dandelion, arnica_bud, leontodon_autumnalis\",\n \"edelweiss, leontopodium_alpinum\",\n \"oxeye_daisy, ox-eyed_daisy, marguerite, moon_daisy, white_daisy, leucanthemum_vulgare, chrysanthemum_leucanthemum\",\n \"oxeye_daisy, leucanthemum_maximum, chrysanthemum_maximum\",\n \"shasta_daisy, leucanthemum_superbum, chrysanthemum_maximum_maximum\",\n \"pyrenees_daisy, leucanthemum_lacustre, chrysanthemum_lacustre\",\n \"north_island_edelweiss, leucogenes_leontopodium\",\n \"blazing_star, button_snakeroot, gayfeather, gay-feather, snakeroot\",\n \"dotted_gayfeather, liatris_punctata\",\n \"dense_blazing_star, liatris_pycnostachya\",\n \"texas_star, lindheimera_texana\",\n \"african_daisy, yellow_ageratum, lonas_inodora, lonas_annua\",\n \"tahoka_daisy, tansy_leaf_aster, machaeranthera_tanacetifolia\",\n \"sticky_aster, machaeranthera_bigelovii\",\n \"mojave_aster, machaeranthera_tortifoloia\",\n \"tarweed\",\n \"sweet_false_chamomile, wild_chamomile, german_chamomile, matricaria_recutita, matricaria_chamomilla\",\n \"pineapple_weed, rayless_chamomile, matricaria_matricarioides\",\n \"climbing_hempweed, climbing_boneset, wild_climbing_hempweed, climbing_hemp-vine, mikania_scandens\",\n \"mutisia\",\n \"rattlesnake_root\",\n \"white_lettuce, cankerweed, nabalus_alba, prenanthes_alba\",\n \"daisybush, daisy-bush, daisy_bush\",\n \"new_zealand_daisybush, olearia_haastii\",\n \"cotton_thistle, woolly_thistle, scotch_thistle, onopordum_acanthium, onopordon_acanthium\",\n \"othonna\",\n \"cascade_everlasting, ozothamnus_secundiflorus, helichrysum_secundiflorum\",\n \"butterweed\",\n \"american_feverfew, wild_quinine, prairie_dock, parthenium_integrifolium\",\n \"cineraria, pericallis_cruenta, senecio_cruentus\",\n \"florest's_cineraria, pericallis_hybrida\",\n \"butterbur, bog_rhubarb, petasites_hybridus, petasites_vulgaris\",\n \"winter_heliotrope, sweet_coltsfoot, petasites_fragrans\",\n \"sweet_coltsfoot, petasites_sagitattus\",\n \"oxtongue, bristly_oxtongue, bitterweed, bugloss, picris_echioides\",\n \"hawkweed\",\n \"mouse-ear_hawkweed, pilosella_officinarum, hieracium_pilocella\",\n \"stevia\",\n \"rattlesnake_root, prenanthes_purpurea\",\n \"fleabane, feabane_mullet, pulicaria_dysenterica\",\n \"sheep_plant, vegetable_sheep, raoulia_lutescens, raoulia_australis\",\n \"coneflower\",\n \"mexican_hat, ratibida_columnaris\",\n \"long-head_coneflower, prairie_coneflower, ratibida_columnifera\",\n \"prairie_coneflower, ratibida_tagetes\",\n \"swan_river_everlasting, rhodanthe, rhodanthe_manglesii, helipterum_manglesii\",\n \"coneflower\",\n \"black-eyed_susan, rudbeckia_hirta, rudbeckia_serotina\",\n \"cutleaved_coneflower, rudbeckia_laciniata\",\n \"golden_glow, double_gold, hortensia, rudbeckia_laciniata_hortensia\",\n \"lavender_cotton, santolina_chamaecyparissus\",\n \"creeping_zinnia, sanvitalia_procumbens\",\n \"golden_thistle\",\n \"spanish_oyster_plant, scolymus_hispanicus\",\n \"nodding_groundsel, senecio_bigelovii\",\n \"dusty_miller, senecio_cineraria, cineraria_maritima\",\n \"butterweed, ragwort, senecio_glabellus\",\n \"ragwort, tansy_ragwort, ragweed, benweed, senecio_jacobaea\",\n \"arrowleaf_groundsel, senecio_triangularis\",\n \"black_salsify, viper's_grass, scorzonera, scorzonera_hispanica\",\n \"white-topped_aster\",\n \"narrow-leaved_white-topped_aster\",\n \"silver_sage, silver_sagebrush, grey_sage, gray_sage, seriphidium_canum, artemisia_cana\",\n \"sea_wormwood, seriphidium_maritimum, artemisia_maritima\",\n \"sawwort, serratula_tinctoria\",\n \"rosinweed, silphium_laciniatum\",\n \"milk_thistle, lady's_thistle, our_lady's_mild_thistle, holy_thistle, blessed_thistle, silybum_marianum\",\n \"goldenrod\",\n \"silverrod, solidago_bicolor\",\n \"meadow_goldenrod, canadian_goldenrod, solidago_canadensis\",\n \"missouri_goldenrod, solidago_missouriensis\",\n \"alpine_goldenrod, solidago_multiradiata\",\n \"grey_goldenrod, gray_goldenrod, solidago_nemoralis\",\n \"blue_mountain_tea, sweet_goldenrod, solidago_odora\",\n \"dyer's_weed, solidago_rugosa\",\n \"seaside_goldenrod, beach_goldenrod, solidago_sempervirens\",\n \"narrow_goldenrod, solidago_spathulata\",\n \"boott's_goldenrod\",\n \"elliott's_goldenrod\",\n \"ohio_goldenrod\",\n \"rough-stemmed_goldenrod\",\n \"showy_goldenrod\",\n \"tall_goldenrod\",\n \"zigzag_goldenrod, broad_leaved_goldenrod\",\n \"sow_thistle, milk_thistle\",\n \"milkweed, sonchus_oleraceus\",\n \"stevia\",\n \"stokes'_aster, cornflower_aster, stokesia_laevis\",\n \"marigold\",\n \"african_marigold, big_marigold, aztec_marigold, tagetes_erecta\",\n \"french_marigold, tagetes_patula\",\n \"painted_daisy, pyrethrum, tanacetum_coccineum, chrysanthemum_coccineum\",\n \"pyrethrum, dalmatian_pyrethrum, dalmatia_pyrethrum, tanacetum_cinerariifolium, chrysanthemum_cinerariifolium\",\n \"northern_dune_tansy, tanacetum_douglasii\",\n \"feverfew, tanacetum_parthenium, chrysanthemum_parthenium\",\n \"dusty_miller, silver-lace, silver_lace, tanacetum_ptarmiciflorum, chrysanthemum_ptarmiciflorum\",\n \"tansy, golden_buttons, scented_fern, tanacetum_vulgare\",\n \"dandelion, blowball\",\n \"common_dandelion, taraxacum_ruderalia, taraxacum_officinale\",\n \"dandelion_green\",\n \"russian_dandelion, kok-saghyz, kok-sagyz, taraxacum_kok-saghyz\",\n \"stemless_hymenoxys, tetraneuris_acaulis, hymenoxys_acaulis\",\n \"mexican_sunflower, tithonia\",\n \"easter_daisy, stemless_daisy, townsendia_exscapa\",\n \"yellow_salsify, tragopogon_dubius\",\n \"salsify, oyster_plant, vegetable_oyster, tragopogon_porrifolius\",\n \"meadow_salsify, goatsbeard, shepherd's_clock, tragopogon_pratensis\",\n \"scentless_camomile, scentless_false_camomile, scentless_mayweed, scentless_hayweed, corn_mayweed, tripleurospermum_inodorum, matricaria_inodorum\",\n \"turfing_daisy, tripleurospermum_tchihatchewii, matricaria_tchihatchewii\",\n \"coltsfoot, tussilago_farfara\",\n \"ursinia\",\n \"crownbeard, crown-beard, crown_beard\",\n \"wingstem, golden_ironweed, yellow_ironweed, golden_honey_plant, verbesina_alternifolia, actinomeris_alternifolia\",\n \"cowpen_daisy, golden_crownbeard, golden_crown_beard, butter_daisy, verbesina_encelioides, ximenesia_encelioides\",\n \"gravelweed, verbesina_helianthoides\",\n \"virginia_crownbeard, frostweed, frost-weed, verbesina_virginica\",\n \"ironweed, vernonia\",\n \"mule's_ears, wyethia_amplexicaulis\",\n \"white-rayed_mule's_ears, wyethia_helianthoides\",\n \"cocklebur, cockle-bur, cockleburr, cockle-burr\",\n \"xeranthemum\",\n \"immortelle, xeranthemum_annuum\",\n \"zinnia, old_maid, old_maid_flower\",\n \"white_zinnia, zinnia_acerosa\",\n \"little_golden_zinnia, zinnia_grandiflora\",\n \"blazing_star, mentzelia_livicaulis, mentzelia_laevicaulis\",\n \"bartonia, mentzelia_lindleyi\",\n \"achene\",\n \"samara, key_fruit, key\",\n \"campanula, bellflower\",\n \"creeping_bellflower, campanula_rapunculoides\",\n \"canterbury_bell, cup_and_saucer, campanula_medium\",\n \"tall_bellflower, campanula_americana\",\n \"marsh_bellflower, campanula_aparinoides\",\n \"clustered_bellflower, campanula_glomerata\",\n \"peach_bells, peach_bell, willow_bell, campanula_persicifolia\",\n \"chimney_plant, chimney_bellflower, campanula_pyramidalis\",\n \"rampion, rampion_bellflower, campanula_rapunculus\",\n \"tussock_bellflower, spreading_bellflower, campanula_carpatica\",\n \"orchid, orchidaceous_plant\",\n \"orchis\",\n \"male_orchis, early_purple_orchid, orchis_mascula\",\n \"butterfly_orchid, butterfly_orchis, orchis_papilionaceae\",\n \"showy_orchis, purple_orchis, purple-hooded_orchis, orchis_spectabilis\",\n \"aerides\",\n \"angrecum\",\n \"jewel_orchid\",\n \"puttyroot, adam-and-eve, aplectrum_hyemale\",\n \"arethusa\",\n \"bog_rose, wild_pink, dragon's_mouth, arethusa_bulbosa\",\n \"bletia\",\n \"bletilla_striata, bletia_striata\",\n \"brassavola\",\n \"spider_orchid, brassia_lawrenceana\",\n \"spider_orchid, brassia_verrucosa\",\n \"caladenia\",\n \"calanthe\",\n \"grass_pink, calopogon_pulchellum, calopogon_tuberosum\",\n \"calypso, fairy-slipper, calypso_bulbosa\",\n \"cattleya\",\n \"helleborine\",\n \"red_helleborine, cephalanthera_rubra\",\n \"spreading_pogonia, funnel-crest_rosebud_orchid, cleistes_divaricata, pogonia_divaricata\",\n \"rosebud_orchid, cleistes_rosea, pogonia_rosea\",\n \"satyr_orchid, coeloglossum_bracteatum\",\n \"frog_orchid, coeloglossum_viride\",\n \"coelogyne\",\n \"coral_root\",\n \"spotted_coral_root, corallorhiza_maculata\",\n \"striped_coral_root, corallorhiza_striata\",\n \"early_coral_root, pale_coral_root, corallorhiza_trifida\",\n \"swan_orchid, swanflower, swan-flower, swanneck, swan-neck\",\n \"cymbid, cymbidium\",\n \"cypripedia\",\n \"lady's_slipper, lady-slipper, ladies'_slipper, slipper_orchid\",\n \"moccasin_flower, nerveroot, cypripedium_acaule\",\n \"common_lady's-slipper, showy_lady's-slipper, showy_lady_slipper, cypripedium_reginae, cypripedium_album\",\n \"ram's-head, ram's-head_lady's_slipper, cypripedium_arietinum\",\n \"yellow_lady's_slipper, yellow_lady-slipper, cypripedium_calceolus, cypripedium_parviflorum\",\n \"large_yellow_lady's_slipper, cypripedium_calceolus_pubescens\",\n \"california_lady's_slipper, cypripedium_californicum\",\n \"clustered_lady's_slipper, cypripedium_fasciculatum\",\n \"mountain_lady's_slipper, cypripedium_montanum\",\n \"marsh_orchid\",\n \"common_spotted_orchid, dactylorhiza_fuchsii, dactylorhiza_maculata_fuchsii\",\n \"dendrobium\",\n \"disa\",\n \"phantom_orchid, snow_orchid, eburophyton_austinae\",\n \"tulip_orchid, encyclia_citrina, cattleya_citrina\",\n \"butterfly_orchid, encyclia_tampensis, epidendrum_tampense\",\n \"butterfly_orchid, butterfly_orchis, epidendrum_venosum, encyclia_venosa\",\n \"epidendron\",\n \"helleborine\",\n \"epipactis_helleborine\",\n \"stream_orchid, chatterbox, giant_helleborine, epipactis_gigantea\",\n \"tongueflower, tongue-flower\",\n \"rattlesnake_plantain, helleborine\",\n \"fragrant_orchid, gymnadenia_conopsea\",\n \"short-spurred_fragrant_orchid, gymnadenia_odoratissima\",\n \"fringed_orchis, fringed_orchid\",\n \"frog_orchid\",\n \"rein_orchid, rein_orchis\",\n \"bog_rein_orchid, bog_candles, habenaria_dilatata\",\n \"white_fringed_orchis, white_fringed_orchid, habenaria_albiflora\",\n \"elegant_habenaria, habenaria_elegans\",\n \"purple-fringed_orchid, purple-fringed_orchis, habenaria_fimbriata\",\n \"coastal_rein_orchid, habenaria_greenei\",\n \"hooker's_orchid, habenaria_hookeri\",\n \"ragged_orchid, ragged_orchis, ragged-fringed_orchid, green_fringed_orchis, habenaria_lacera\",\n \"prairie_orchid, prairie_white-fringed_orchis, habenaria_leucophaea\",\n \"snowy_orchid, habenaria_nivea\",\n \"round-leaved_rein_orchid, habenaria_orbiculata\",\n \"purple_fringeless_orchid, purple_fringeless_orchis, habenaria_peramoena\",\n \"purple-fringed_orchid, purple-fringed_orchis, habenaria_psycodes\",\n \"alaska_rein_orchid, habenaria_unalascensis\",\n \"crested_coral_root, hexalectris_spicata\",\n \"texas_purple_spike, hexalectris_warnockii\",\n \"lizard_orchid, himantoglossum_hircinum\",\n \"laelia\",\n \"liparis\",\n \"twayblade\",\n \"fen_orchid, fen_orchis, liparis_loeselii\",\n \"broad-leaved_twayblade, listera_convallarioides\",\n \"lesser_twayblade, listera_cordata\",\n \"twayblade, listera_ovata\",\n \"green_adder's_mouth, malaxis-unifolia, malaxis_ophioglossoides\",\n \"masdevallia\",\n \"maxillaria\",\n \"pansy_orchid\",\n \"odontoglossum\",\n \"oncidium, dancing_lady_orchid, butterfly_plant, butterfly_orchid\",\n \"bee_orchid, ophrys_apifera\",\n \"fly_orchid, ophrys_insectifera, ophrys_muscifera\",\n \"spider_orchid\",\n \"early_spider_orchid, ophrys_sphegodes\",\n \"venus'_slipper, venus's_slipper, venus's_shoe\",\n \"phaius\",\n \"moth_orchid, moth_plant\",\n \"butterfly_plant, phalaenopsis_amabilis\",\n \"rattlesnake_orchid\",\n \"lesser_butterfly_orchid, platanthera_bifolia, habenaria_bifolia\",\n \"greater_butterfly_orchid, platanthera_chlorantha, habenaria_chlorantha\",\n \"prairie_white-fringed_orchid, platanthera_leucophea\",\n \"tangle_orchid\",\n \"indian_crocus\",\n \"pleurothallis\",\n \"pogonia\",\n \"butterfly_orchid\",\n \"psychopsis_krameriana, oncidium_papilio_kramerianum\",\n \"psychopsis_papilio, oncidium_papilio\",\n \"helmet_orchid, greenhood\",\n \"foxtail_orchid\",\n \"orange-blossom_orchid, sarcochilus_falcatus\",\n \"sobralia\",\n \"ladies'_tresses, lady's_tresses\",\n \"screw_augur, spiranthes_cernua\",\n \"hooded_ladies'_tresses, spiranthes_romanzoffiana\",\n \"western_ladies'_tresses, spiranthes_porrifolia\",\n \"european_ladies'_tresses, spiranthes_spiralis\",\n \"stanhopea\",\n \"stelis\",\n \"fly_orchid\",\n \"vanda\",\n \"blue_orchid, vanda_caerulea\",\n \"vanilla\",\n \"vanilla_orchid, vanilla_planifolia\",\n \"yam, yam_plant\",\n \"yam\",\n \"white_yam, water_yam, dioscorea_alata\",\n \"cinnamon_vine, chinese_yam, dioscorea_batata\",\n \"elephant's-foot, tortoise_plant, hottentot_bread_vine, hottentot's_bread_vine, dioscorea_elephantipes\",\n \"wild_yam, dioscorea_paniculata\",\n \"cush-cush, dioscorea_trifida\",\n \"black_bryony, black_bindweed, tamus_communis\",\n \"primrose, primula\",\n \"english_primrose, primula_vulgaris\",\n \"cowslip, paigle, primula_veris\",\n \"oxlip, paigle, primula_elatior\",\n \"chinese_primrose, primula_sinensis\",\n \"polyanthus, primula_polyantha\",\n \"pimpernel\",\n \"scarlet_pimpernel, red_pimpernel, poor_man's_weatherglass, anagallis_arvensis\",\n \"bog_pimpernel, anagallis_tenella\",\n \"chaffweed, bastard_pimpernel, false_pimpernel\",\n \"cyclamen, cyclamen_purpurascens\",\n \"sowbread, cyclamen_hederifolium, cyclamen_neopolitanum\",\n \"sea_milkwort, sea_trifoly, black_saltwort, glaux_maritima\",\n \"featherfoil, feather-foil\",\n \"water_gillyflower, american_featherfoil, hottonia_inflata\",\n \"water_violet, hottonia_palustris\",\n \"loosestrife\",\n \"gooseneck_loosestrife, lysimachia_clethroides_duby\",\n \"yellow_pimpernel, lysimachia_nemorum\",\n \"fringed_loosestrife, lysimachia_ciliatum\",\n \"moneywort, creeping_jenny, creeping_charlie, lysimachia_nummularia\",\n \"swamp_candles, lysimachia_terrestris\",\n \"whorled_loosestrife, lysimachia_quadrifolia\",\n \"water_pimpernel\",\n \"brookweed, samolus_valerandii\",\n \"brookweed, samolus_parviflorus, samolus_floribundus\",\n \"coralberry, spiceberry, ardisia_crenata\",\n \"marlberry, ardisia_escallonoides, ardisia_paniculata\",\n \"plumbago\",\n \"leadwort, plumbago_europaea\",\n \"thrift\",\n \"sea_lavender, marsh_rosemary, statice\",\n \"barbasco, joewood, jacquinia_keyensis\",\n \"gramineous_plant, graminaceous_plant\",\n \"grass\",\n \"midgrass\",\n \"shortgrass, short-grass\",\n \"sword_grass\",\n \"tallgrass, tall-grass\",\n \"herbage, pasturage\",\n \"goat_grass, aegilops_triuncalis\",\n \"wheatgrass, wheat-grass\",\n \"crested_wheatgrass, crested_wheat_grass, fairway_crested_wheat_grass, agropyron_cristatum\",\n \"bearded_wheatgrass, agropyron_subsecundum\",\n \"western_wheatgrass, bluestem_wheatgrass, agropyron_smithii\",\n \"intermediate_wheatgrass, agropyron_intermedium, elymus_hispidus\",\n \"slender_wheatgrass, agropyron_trachycaulum, agropyron_pauciflorum, elymus_trachycaulos\",\n \"velvet_bent, velvet_bent_grass, brown_bent, rhode_island_bent, dog_bent, agrostis_canina\",\n \"cloud_grass, agrostis_nebulosa\",\n \"meadow_foxtail, alopecurus_pratensis\",\n \"foxtail, foxtail_grass\",\n \"broom_grass\",\n \"broom_sedge, andropogon_virginicus\",\n \"tall_oat_grass, tall_meadow_grass, evergreen_grass, false_oat, french_rye, arrhenatherum_elatius\",\n \"toetoe, toitoi, arundo_conspicua, chionochloa_conspicua\",\n \"oat\",\n \"cereal_oat, avena_sativa\",\n \"wild_oat, wild_oat_grass, avena_fatua\",\n \"slender_wild_oat, avena_barbata\",\n \"wild_red_oat, animated_oat, avene_sterilis\",\n \"brome, bromegrass\",\n \"chess, cheat, bromus_secalinus\",\n \"field_brome, bromus_arvensis\",\n \"grama, grama_grass, gramma, gramma_grass\",\n \"black_grama, bouteloua_eriopoda\",\n \"buffalo_grass, buchloe_dactyloides\",\n \"reed_grass\",\n \"feather_reed_grass, feathertop, calamagrostis_acutiflora\",\n \"australian_reed_grass, calamagrostic_quadriseta\",\n \"burgrass, bur_grass\",\n \"buffel_grass, cenchrus_ciliaris, pennisetum_cenchroides\",\n \"rhodes_grass, chloris_gayana\",\n \"pampas_grass, cortaderia_selloana\",\n \"giant_star_grass, cynodon_plectostachyum\",\n \"orchard_grass, cocksfoot, cockspur, dactylis_glomerata\",\n \"egyptian_grass, crowfoot_grass, dactyloctenium_aegypticum\",\n \"crabgrass, crab_grass, finger_grass\",\n \"smooth_crabgrass, digitaria_ischaemum\",\n \"large_crabgrass, hairy_finger_grass, digitaria_sanguinalis\",\n \"barnyard_grass, barn_grass, barn_millet, echinochloa_crusgalli\",\n \"japanese_millet, billion-dollar_grass, japanese_barnyard_millet, sanwa_millet, echinochloa_frumentacea\",\n \"yardgrass, yard_grass, wire_grass, goose_grass, eleusine_indica\",\n \"finger_millet, ragi, ragee, african_millet, coracan, corakan, kurakkan, eleusine_coracana\",\n \"lyme_grass\",\n \"wild_rye\",\n \"giant_ryegrass, elymus_condensatus, leymus_condensatus\",\n \"sea_lyme_grass, european_dune_grass, elymus_arenarius, leymus_arenaria\",\n \"canada_wild_rye, elymus_canadensis\",\n \"teff, teff_grass, eragrostis_tef, eragrostic_abyssinica\",\n \"weeping_love_grass, african_love_grass, eragrostis_curvula\",\n \"plume_grass\",\n \"ravenna_grass, wool_grass, erianthus_ravennae\",\n \"fescue, fescue_grass, meadow_fescue, festuca_elatior\",\n \"reed_meadow_grass, glyceria_grandis\",\n \"velvet_grass, yorkshire_fog, holcus_lanatus\",\n \"creeping_soft_grass, holcus_mollis\",\n \"barleycorn\",\n \"barley_grass, wall_barley, hordeum_murinum\",\n \"little_barley, hordeum_pusillum\",\n \"rye_grass, ryegrass\",\n \"perennial_ryegrass, english_ryegrass, lolium_perenne\",\n \"italian_ryegrass, italian_rye, lolium_multiflorum\",\n \"darnel, tare, bearded_darnel, cheat, lolium_temulentum\",\n \"nimblewill, nimble_will, muhlenbergia_schreberi\",\n \"cultivated_rice, oryza_sativa\",\n \"ricegrass, rice_grass\",\n \"smilo, smilo_grass, oryzopsis_miliacea\",\n \"switch_grass, panicum_virgatum\",\n \"broomcorn_millet, hog_millet, panicum_miliaceum\",\n \"goose_grass, texas_millet, panicum_texanum\",\n \"dallisgrass, dallis_grass, paspalum, paspalum_dilatatum\",\n \"bahia_grass, paspalum_notatum\",\n \"knotgrass, paspalum_distichum\",\n \"fountain_grass, pennisetum_ruppelii, pennisetum_setaceum\",\n \"reed_canary_grass, gardener's_garters, lady's_laces, ribbon_grass, phalaris_arundinacea\",\n \"canary_grass, birdseed_grass, phalaris_canariensis\",\n \"timothy, herd's_grass, phleum_pratense\",\n \"bluegrass, blue_grass\",\n \"meadowgrass, meadow_grass\",\n \"wood_meadowgrass, poa_nemoralis, agrostis_alba\",\n \"noble_cane\",\n \"munj, munja, saccharum_bengalense, saccharum_munja\",\n \"broom_beard_grass, prairie_grass, wire_grass, andropogon_scoparius, schizachyrium_scoparium\",\n \"bluestem, blue_stem, andropogon_furcatus, andropogon_gerardii\",\n \"rye, secale_cereale\",\n \"bristlegrass, bristle_grass\",\n \"giant_foxtail\",\n \"yellow_bristlegrass, yellow_bristle_grass, yellow_foxtail, glaucous_bristlegrass, setaria_glauca\",\n \"green_bristlegrass, green_foxtail, rough_bristlegrass, bottle-grass, bottle_grass, setaria_viridis\",\n \"siberian_millet, setaria_italica_rubrofructa\",\n \"german_millet, golden_wonder_millet, setaria_italica_stramineofructa\",\n \"millet\",\n \"rattan, rattan_cane\",\n \"malacca\",\n \"reed\",\n \"sorghum\",\n \"grain_sorghum\",\n \"durra, doura, dourah, egyptian_corn, indian_millet, guinea_corn\",\n \"feterita, federita, sorghum_vulgare_caudatum\",\n \"hegari\",\n \"kaoliang\",\n \"milo, milo_maize\",\n \"shallu, sorghum_vulgare_rosburghii\",\n \"broomcorn, sorghum_vulgare_technicum\",\n \"cordgrass, cord_grass\",\n \"salt_reed_grass, spartina_cynosuroides\",\n \"prairie_cordgrass, freshwater_cordgrass, slough_grass, spartina_pectinmata\",\n \"smut_grass, blackseed, carpet_grass, sporobolus_poiretii\",\n \"sand_dropseed, sporobolus_cryptandrus\",\n \"rush_grass, rush-grass\",\n \"st._augustine_grass, stenotaphrum_secundatum, buffalo_grass\",\n \"grain\",\n \"cereal, cereal_grass\",\n \"wheat\",\n \"wheat_berry\",\n \"durum, durum_wheat, hard_wheat, triticum_durum, triticum_turgidum, macaroni_wheat\",\n \"spelt, triticum_spelta, triticum_aestivum_spelta\",\n \"emmer, starch_wheat, two-grain_spelt, triticum_dicoccum\",\n \"wild_wheat, wild_emmer, triticum_dicoccum_dicoccoides\",\n \"corn, maize, indian_corn, zea_mays\",\n \"mealie\",\n \"corn\",\n \"dent_corn, zea_mays_indentata\",\n \"flint_corn, flint_maize, yankee_corn, zea_mays_indurata\",\n \"popcorn, zea_mays_everta\",\n \"zoysia\",\n \"manila_grass, japanese_carpet_grass, zoysia_matrella\",\n \"korean_lawn_grass, japanese_lawn_grass, zoysia_japonica\",\n \"bamboo\",\n \"common_bamboo, bambusa_vulgaris\",\n \"giant_bamboo, kyo-chiku, dendrocalamus_giganteus\",\n \"umbrella_plant, umbrella_sedge, cyperus_alternifolius\",\n \"chufa, yellow_nutgrass, earth_almond, ground_almond, rush_nut, cyperus_esculentus\",\n \"galingale, galangal, cyperus_longus\",\n \"nutgrass, nut_grass, nutsedge, nut_sedge, cyperus_rotundus\",\n \"sand_sedge, sand_reed, carex_arenaria\",\n \"cypress_sedge, carex_pseudocyperus\",\n \"cotton_grass, cotton_rush\",\n \"common_cotton_grass, eriophorum_angustifolium\",\n \"hardstem_bulrush, hardstemmed_bulrush, scirpus_acutus\",\n \"wool_grass, scirpus_cyperinus\",\n \"spike_rush\",\n \"water_chestnut, chinese_water_chestnut, eleocharis_dulcis\",\n \"needle_spike_rush, needle_rush, slender_spike_rush, hair_grass, eleocharis_acicularis\",\n \"creeping_spike_rush, eleocharis_palustris\",\n \"pandanus, screw_pine\",\n \"textile_screw_pine, lauhala, pandanus_tectorius\",\n \"cattail\",\n \"cat's-tail, bullrush, bulrush, nailrod, reed_mace, reedmace, typha_latifolia\",\n \"bur_reed\",\n \"grain, caryopsis\",\n \"kernel\",\n \"rye\",\n \"gourd, gourd_vine\",\n \"gourd\",\n \"pumpkin, pumpkin_vine, autumn_pumpkin, cucurbita_pepo\",\n \"squash, squash_vine\",\n \"summer_squash, summer_squash_vine, cucurbita_pepo_melopepo\",\n \"yellow_squash\",\n \"marrow, marrow_squash, vegetable_marrow\",\n \"zucchini, courgette\",\n \"cocozelle, italian_vegetable_marrow\",\n \"cymling, pattypan_squash\",\n \"spaghetti_squash\",\n \"winter_squash, winter_squash_plant\",\n \"acorn_squash\",\n \"hubbard_squash, cucurbita_maxima\",\n \"turban_squash, cucurbita_maxima_turbaniformis\",\n \"buttercup_squash\",\n \"butternut_squash, cucurbita_maxima\",\n \"winter_crookneck, winter_crookneck_squash, cucurbita_moschata\",\n \"cushaw, cucurbita_mixta, cucurbita_argyrosperma\",\n \"prairie_gourd, prairie_gourd_vine, missouri_gourd, wild_pumpkin, buffalo_gourd, calabazilla, cucurbita_foetidissima\",\n \"prairie_gourd\",\n \"bryony, briony\",\n \"white_bryony, devil's_turnip, bryonia_alba\",\n \"sweet_melon, muskmelon, sweet_melon_vine, cucumis_melo\",\n \"cantaloupe, cantaloup, cantaloupe_vine, cantaloup_vine, cucumis_melo_cantalupensis\",\n \"winter_melon, persian_melon, honeydew_melon, winter_melon_vine, cucumis_melo_inodorus\",\n \"net_melon, netted_melon, nutmeg_melon, cucumis_melo_reticulatus\",\n \"cucumber, cucumber_vine, cucumis_sativus\",\n \"squirting_cucumber, exploding_cucumber, touch-me-not, ecballium_elaterium\",\n \"bottle_gourd, calabash, lagenaria_siceraria\",\n \"luffa, dishcloth_gourd, sponge_gourd, rag_gourd, strainer_vine\",\n \"loofah, vegetable_sponge, luffa_cylindrica\",\n \"angled_loofah, sing-kwa, luffa_acutangula\",\n \"loofa, loofah, luffa, loufah_sponge\",\n \"balsam_apple, momordica_balsamina\",\n \"balsam_pear, momordica_charantia\",\n \"lobelia\",\n \"water_lobelia, lobelia_dortmanna\",\n \"mallow\",\n \"musk_mallow, mus_rose, malva_moschata\",\n \"common_mallow, malva_neglecta\",\n \"okra, gumbo, okra_plant, lady's-finger, abelmoschus_esculentus, hibiscus_esculentus\",\n \"okra\",\n \"abelmosk, musk_mallow, abelmoschus_moschatus, hibiscus_moschatus\",\n \"flowering_maple\",\n \"velvetleaf, velvet-leaf, velvetweed, indian_mallow, butter-print, china_jute, abutilon_theophrasti\",\n \"hollyhock\",\n \"rose_mallow, alcea_rosea, althea_rosea\",\n \"althea, althaea, hollyhock\",\n \"marsh_mallow, white_mallow, althea_officinalis\",\n \"poppy_mallow\",\n \"fringed_poppy_mallow, callirhoe_digitata\",\n \"purple_poppy_mallow, callirhoe_involucrata\",\n \"clustered_poppy_mallow, callirhoe_triangulata\",\n \"sea_island_cotton, tree_cotton, gossypium_barbadense\",\n \"levant_cotton, gossypium_herbaceum\",\n \"upland_cotton, gossypium_hirsutum\",\n \"peruvian_cotton, gossypium_peruvianum\",\n \"wild_cotton, arizona_wild_cotton, gossypium_thurberi\",\n \"kenaf, kanaf, deccan_hemp, bimli, bimli_hemp, indian_hemp, bombay_hemp, hibiscus_cannabinus\",\n \"sorrel_tree, hibiscus_heterophyllus\",\n \"rose_mallow, swamp_mallow, common_rose_mallow, swamp_rose_mallow, hibiscus_moscheutos\",\n \"cotton_rose, confederate_rose, confederate_rose_mallow, hibiscus_mutabilis\",\n \"roselle, rozelle, sorrel, red_sorrel, jamaica_sorrel, hibiscus_sabdariffa\",\n \"mahoe, majagua, mahagua, balibago, purau, hibiscus_tiliaceus\",\n \"flower-of-an-hour, flowers-of-an-hour, bladder_ketmia, black-eyed_susan, hibiscus_trionum\",\n \"lacebark, ribbonwood, houhere, hoheria_populnea\",\n \"wild_hollyhock, iliamna_remota, sphaeralcea_remota\",\n \"mountain_hollyhock, iliamna_ruvularis, iliamna_acerifolia\",\n \"seashore_mallow\",\n \"salt_marsh_mallow, kosteletzya_virginica\",\n \"chaparral_mallow, malacothamnus_fasciculatus, sphaeralcea_fasciculata\",\n \"malope, malope_trifida\",\n \"false_mallow\",\n \"waxmallow, wax_mallow, sleeping_hibiscus\",\n \"glade_mallow, napaea_dioica\",\n \"pavonia\",\n \"ribbon_tree, ribbonwood, plagianthus_regius, plagianthus_betulinus\",\n \"bush_hibiscus, radyera_farragei, hibiscus_farragei\",\n \"virginia_mallow, sida_hermaphrodita\",\n \"queensland_hemp, jellyleaf, sida_rhombifolia\",\n \"indian_mallow, sida_spinosa\",\n \"checkerbloom, wild_hollyhock, sidalcea_malviflora\",\n \"globe_mallow, false_mallow\",\n \"prairie_mallow, red_false_mallow, sphaeralcea_coccinea, malvastrum_coccineum\",\n \"tulipwood_tree\",\n \"portia_tree, bendy_tree, seaside_mahoe, thespesia_populnea\",\n \"red_silk-cotton_tree, simal, bombax_ceiba, bombax_malabarica\",\n \"cream-of-tartar_tree, sour_gourd, adansonia_gregorii\",\n \"baobab, monkey-bread_tree, adansonia_digitata\",\n \"kapok, ceiba_tree, silk-cotton_tree, white_silk-cotton_tree, bombay_ceiba, god_tree, ceiba_pentandra\",\n \"durian, durion, durian_tree, durio_zibethinus\",\n \"montezuma\",\n \"shaving-brush_tree, pseudobombax_ellipticum\",\n \"quandong, quandong_tree, brisbane_quandong, silver_quandong_tree, blue_fig, elaeocarpus_grandis\",\n \"quandong, blue_fig\",\n \"makomako, new_zealand_wine_berry, wineberry, aristotelia_serrata, aristotelia_racemosa\",\n \"jamaican_cherry, calabur_tree, calabura, silk_wood, silkwood, muntingia_calabura\",\n \"breakax, breakaxe, break-axe, sloanea_jamaicensis\",\n \"sterculia\",\n \"panama_tree, sterculia_apetala\",\n \"kalumpang, java_olives, sterculia_foetida\",\n \"bottle-tree, bottle_tree\",\n \"flame_tree, flame_durrajong, brachychiton_acerifolius, sterculia_acerifolia\",\n \"flame_tree, broad-leaved_bottletree, brachychiton_australis\",\n \"kurrajong, currajong, brachychiton_populneus\",\n \"queensland_bottletree, narrow-leaved_bottletree, brachychiton_rupestris, sterculia_rupestris\",\n \"kola, kola_nut, kola_nut_tree, goora_nut, cola_acuminata\",\n \"kola_nut, cola_nut\",\n \"chinese_parasol_tree, chinese_parasol, japanese_varnish_tree, phoenix_tree, firmiana_simplex\",\n \"flannelbush, flannel_bush, california_beauty\",\n \"screw_tree\",\n \"nut-leaved_screw_tree, helicteres_isora\",\n \"red_beech, brown_oak, booyong, crow's_foot, stave_wood, silky_elm, heritiera_trifoliolata, terrietia_trifoliolata\",\n \"looking_glass_tree, heritiera_macrophylla\",\n \"looking-glass_plant, heritiera_littoralis\",\n \"honey_bell, honeybells, hermannia_verticillata, mahernia_verticillata\",\n \"mayeng, maple-leaved_bayur, pterospermum_acerifolium\",\n \"silver_tree, tarrietia_argyrodendron\",\n \"cacao, cacao_tree, chocolate_tree, theobroma_cacao\",\n \"obeche, obechi, arere, samba, triplochiton_scleroxcylon\",\n \"linden, linden_tree, basswood, lime, lime_tree\",\n \"american_basswood, american_lime, tilia_americana\",\n \"small-leaved_linden, small-leaved_lime, tilia_cordata\",\n \"white_basswood, cottonwood, tilia_heterophylla\",\n \"japanese_linden, japanese_lime, tilia_japonica\",\n \"silver_lime, silver_linden, tilia_tomentosa\",\n \"corchorus\",\n \"african_hemp, sparmannia_africana\",\n \"herb, herbaceous_plant\",\n \"protea\",\n \"honeypot, king_protea, protea_cynaroides\",\n \"honeyflower, honey-flower, protea_mellifera\",\n \"banksia\",\n \"honeysuckle, australian_honeysuckle, coast_banksia, banksia_integrifolia\",\n \"smoke_bush\",\n \"chilean_firebush, chilean_flameflower, embothrium_coccineum\",\n \"chilean_nut, chile_nut, chile_hazel, chilean_hazelnut, guevina_heterophylla, guevina_avellana\",\n \"grevillea\",\n \"red-flowered_silky_oak, grevillea_banksii\",\n \"silky_oak, grevillea_robusta\",\n \"beefwood, grevillea_striata\",\n \"cushion_flower, pincushion_hakea, hakea_laurina\",\n \"rewa-rewa, new_zealand_honeysuckle\",\n \"honeyflower, honey-flower, mountain_devil, lambertia_formosa\",\n \"silver_tree, leucadendron_argenteum\",\n \"lomatia\",\n \"macadamia, macadamia_tree\",\n \"macadamia_integrifolia\",\n \"macadamia_nut, macadamia_nut_tree, macadamia_ternifolia\",\n \"queensland_nut, macadamia_tetraphylla\",\n \"prickly_ash, orites_excelsa\",\n \"geebung\",\n \"wheel_tree, firewheel_tree, stenocarpus_sinuatus\",\n \"scrub_beefwood, beefwood, stenocarpus_salignus\",\n \"waratah, telopea_oreades\",\n \"waratah, telopea_speciosissima\",\n \"casuarina\",\n \"she-oak\",\n \"beefwood\",\n \"australian_pine, casuarina_equisetfolia\",\n \"heath\",\n \"tree_heath, briar, brier, erica_arborea\",\n \"briarroot\",\n \"winter_heath, spring_heath, erica_carnea\",\n \"bell_heather, heather_bell, fine-leaved_heath, erica_cinerea\",\n \"cornish_heath, erica_vagans\",\n \"spanish_heath, portuguese_heath, erica_lusitanica\",\n \"prince-of-wales'-heath, prince_of_wales_heath, erica_perspicua\",\n \"bog_rosemary, moorwort, andromeda_glaucophylla\",\n \"marsh_andromeda, common_bog_rosemary, andromeda_polifolia\",\n \"madrona, madrono, manzanita, arbutus_menziesii\",\n \"strawberry_tree, irish_strawberry, arbutus_unedo\",\n \"bearberry\",\n \"alpine_bearberry, black_bearberry, arctostaphylos_alpina\",\n \"heartleaf_manzanita, arctostaphylos_andersonii\",\n \"parry_manzanita, arctostaphylos_manzanita\",\n \"spike_heath, bruckenthalia_spiculifolia\",\n \"bryanthus\",\n \"leatherleaf, chamaedaphne_calyculata\",\n \"connemara_heath, st._dabeoc's_heath, daboecia_cantabrica\",\n \"trailing_arbutus, mayflower, epigaea_repens\",\n \"creeping_snowberry, moxie_plum, maidenhair_berry, gaultheria_hispidula\",\n \"salal, shallon, gaultheria_shallon\",\n \"huckleberry\",\n \"black_huckleberry, gaylussacia_baccata\",\n \"dangleberry, dangle-berry, gaylussacia_frondosa\",\n \"box_huckleberry, gaylussacia_brachycera\",\n \"kalmia\",\n \"mountain_laurel, wood_laurel, american_laurel, calico_bush, kalmia_latifolia\",\n \"swamp_laurel, bog_laurel, bog_kalmia, kalmia_polifolia\",\n \"trapper's_tea, glandular_labrador_tea\",\n \"wild_rosemary, marsh_tea, ledum_palustre\",\n \"sand_myrtle, leiophyllum_buxifolium\",\n \"leucothoe\",\n \"dog_laurel, dog_hobble, switch-ivy, leucothoe_fontanesiana, leucothoe_editorum\",\n \"sweet_bells, leucothoe_racemosa\",\n \"alpine_azalea, mountain_azalea, loiseleuria_procumbens\",\n \"staggerbush, stagger_bush, lyonia_mariana\",\n \"maleberry, male_berry, privet_andromeda, he-huckleberry, lyonia_ligustrina\",\n \"fetterbush, fetter_bush, shiny_lyonia, lyonia_lucida\",\n \"false_azalea, fool's_huckleberry, menziesia_ferruginea\",\n \"minniebush, minnie_bush, menziesia_pilosa\",\n \"sorrel_tree, sourwood, titi, oxydendrum_arboreum\",\n \"mountain_heath, phyllodoce_caerulea, bryanthus_taxifolius\",\n \"purple_heather, brewer's_mountain_heather, phyllodoce_breweri\",\n \"fetterbush, mountain_fetterbush, mountain_andromeda, pieris_floribunda\",\n \"rhododendron\",\n \"coast_rhododendron, rhododendron_californicum\",\n \"rosebay, rhododendron_maxima\",\n \"swamp_azalea, swamp_honeysuckle, white_honeysuckle, rhododendron_viscosum\",\n \"azalea\",\n \"cranberry\",\n \"american_cranberry, large_cranberry, vaccinium_macrocarpon\",\n \"european_cranberry, small_cranberry, vaccinium_oxycoccus\",\n \"blueberry, blueberry_bush\",\n \"farkleberry, sparkleberry, vaccinium_arboreum\",\n \"low-bush_blueberry, low_blueberry, vaccinium_angustifolium, vaccinium_pennsylvanicum\",\n \"rabbiteye_blueberry, rabbit-eye_blueberry, rabbiteye, vaccinium_ashei\",\n \"dwarf_bilberry, dwarf_blueberry, vaccinium_caespitosum\",\n \"evergreen_blueberry, vaccinium_myrsinites\",\n \"evergreen_huckleberry, vaccinium_ovatum\",\n \"bilberry, thin-leaved_bilberry, mountain_blue_berry, viccinium_membranaceum\",\n \"bilberry, whortleberry, whinberry, blaeberry, viccinium_myrtillus\",\n \"bog_bilberry, bog_whortleberry, moor_berry, vaccinium_uliginosum_alpinum\",\n \"dryland_blueberry, dryland_berry, vaccinium_pallidum\",\n \"grouseberry, grouse-berry, grouse_whortleberry, vaccinium_scoparium\",\n \"deerberry, squaw_huckleberry, vaccinium_stamineum\",\n \"cowberry, mountain_cranberry, lingonberry, lingenberry, lingberry, foxberry, vaccinium_vitis-idaea\",\n \"diapensia\",\n \"galax, galaxy, wandflower, beetleweed, coltsfoot, galax_urceolata\",\n \"pyxie, pixie, pixy, pyxidanthera_barbulata\",\n \"shortia\",\n \"oconee_bells, shortia_galacifolia\",\n \"australian_heath\",\n \"epacris\",\n \"common_heath, epacris_impressa\",\n \"common_heath, blunt-leaf_heath, epacris_obtusifolia\",\n \"port_jackson_heath, epacris_purpurascens\",\n \"native_cranberry, groundberry, ground-berry, cranberry_heath, astroloma_humifusum, styphelia_humifusum\",\n \"pink_fivecorner, styphelia_triflora\",\n \"wintergreen, pyrola\",\n \"false_wintergreen, pyrola_americana, pyrola_rotundifolia_americana\",\n \"lesser_wintergreen, pyrola_minor\",\n \"wild_lily_of_the_valley, shinleaf, pyrola_elliptica\",\n \"wild_lily_of_the_valley, pyrola_rotundifolia\",\n \"pipsissewa, prince's_pine\",\n \"love-in-winter, western_prince's_pine, chimaphila_umbellata, chimaphila_corymbosa\",\n \"one-flowered_wintergreen, one-flowered_pyrola, moneses_uniflora, pyrola_uniflora\",\n \"indian_pipe, waxflower, monotropa_uniflora\",\n \"pinesap, false_beachdrops, monotropa_hypopithys\",\n \"beech, beech_tree\",\n \"common_beech, european_beech, fagus_sylvatica\",\n \"copper_beech, purple_beech, fagus_sylvatica_atropunicea, fagus_purpurea, fagus_sylvatica_purpurea\",\n \"american_beech, white_beech, red_beech, fagus_grandifolia, fagus_americana\",\n \"weeping_beech, fagus_pendula, fagus_sylvatica_pendula\",\n \"japanese_beech\",\n \"chestnut, chestnut_tree\",\n \"american_chestnut, american_sweet_chestnut, castanea_dentata\",\n \"european_chestnut, sweet_chestnut, spanish_chestnut, castanea_sativa\",\n \"chinese_chestnut, castanea_mollissima\",\n \"japanese_chestnut, castanea_crenata\",\n \"allegheny_chinkapin, eastern_chinquapin, chinquapin, dwarf_chestnut, castanea_pumila\",\n \"ozark_chinkapin, ozark_chinquapin, chinquapin, castanea_ozarkensis\",\n \"oak_chestnut\",\n \"giant_chinkapin, golden_chinkapin, chrysolepis_chrysophylla, castanea_chrysophylla, castanopsis_chrysophylla\",\n \"dwarf_golden_chinkapin, chrysolepis_sempervirens\",\n \"tanbark_oak, lithocarpus_densiflorus\",\n \"japanese_oak, lithocarpus_glabra, lithocarpus_glaber\",\n \"southern_beech, evergreen_beech\",\n \"myrtle_beech, nothofagus_cuninghamii\",\n \"coigue, nothofagus_dombeyi\",\n \"new_zealand_beech\",\n \"silver_beech, nothofagus_menziesii\",\n \"roble_beech, nothofagus_obliqua\",\n \"rauli_beech, nothofagus_procera\",\n \"black_beech, nothofagus_solanderi\",\n \"hard_beech, nothofagus_truncata\",\n \"acorn\",\n \"cupule, acorn_cup\",\n \"oak, oak_tree\",\n \"live_oak\",\n \"coast_live_oak, california_live_oak, quercus_agrifolia\",\n \"white_oak\",\n \"american_white_oak, quercus_alba\",\n \"arizona_white_oak, quercus_arizonica\",\n \"swamp_white_oak, swamp_oak, quercus_bicolor\",\n \"european_turkey_oak, turkey_oak, quercus_cerris\",\n \"canyon_oak, canyon_live_oak, maul_oak, iron_oak, quercus_chrysolepis\",\n \"scarlet_oak, quercus_coccinea\",\n \"jack_oak, northern_pin_oak, quercus_ellipsoidalis\",\n \"red_oak\",\n \"southern_red_oak, swamp_red_oak, turkey_oak, quercus_falcata\",\n \"oregon_white_oak, oregon_oak, garry_oak, quercus_garryana\",\n \"holm_oak, holm_tree, holly-leaved_oak, evergreen_oak, quercus_ilex\",\n \"bear_oak, quercus_ilicifolia\",\n \"shingle_oak, laurel_oak, quercus_imbricaria\",\n \"bluejack_oak, turkey_oak, quercus_incana\",\n \"california_black_oak, quercus_kelloggii\",\n \"american_turkey_oak, turkey_oak, quercus_laevis\",\n \"laurel_oak, pin_oak, quercus_laurifolia\",\n \"california_white_oak, valley_oak, valley_white_oak, roble, quercus_lobata\",\n \"overcup_oak, quercus_lyrata\",\n \"bur_oak, burr_oak, mossy-cup_oak, mossycup_oak, quercus_macrocarpa\",\n \"scrub_oak\",\n \"blackjack_oak, blackjack, jack_oak, quercus_marilandica\",\n \"swamp_chestnut_oak, quercus_michauxii\",\n \"japanese_oak, quercus_mongolica, quercus_grosseserrata\",\n \"chestnut_oak\",\n \"chinquapin_oak, chinkapin_oak, yellow_chestnut_oak, quercus_muehlenbergii\",\n \"myrtle_oak, seaside_scrub_oak, quercus_myrtifolia\",\n \"water_oak, possum_oak, quercus_nigra\",\n \"nuttall_oak, nuttall's_oak, quercus_nuttalli\",\n \"durmast, quercus_petraea, quercus_sessiliflora\",\n \"basket_oak, cow_oak, quercus_prinus, quercus_montana\",\n \"pin_oak, swamp_oak, quercus_palustris\",\n \"willow_oak, quercus_phellos\",\n \"dwarf_chinkapin_oak, dwarf_chinquapin_oak, dwarf_oak, quercus_prinoides\",\n \"common_oak, english_oak, pedunculate_oak, quercus_robur\",\n \"northern_red_oak, quercus_rubra, quercus_borealis\",\n \"shumard_oak, shumard_red_oak, quercus_shumardii\",\n \"post_oak, box_white_oak, brash_oak, iron_oak, quercus_stellata\",\n \"cork_oak, quercus_suber\",\n \"spanish_oak, quercus_texana\",\n \"huckleberry_oak, quercus_vaccinifolia\",\n \"chinese_cork_oak, quercus_variabilis\",\n \"black_oak, yellow_oak, quercitron, quercitron_oak, quercus_velutina\",\n \"southern_live_oak, quercus_virginiana\",\n \"interior_live_oak, quercus_wislizenii, quercus_wizlizenii\",\n \"mast\",\n \"birch, birch_tree\",\n \"yellow_birch, betula_alleghaniensis, betula_leutea\",\n \"american_white_birch, paper_birch, paperbark_birch, canoe_birch, betula_cordifolia, betula_papyrifera\",\n \"grey_birch, gray_birch, american_grey_birch, american_gray_birch, betula_populifolia\",\n \"silver_birch, common_birch, european_white_birch, betula_pendula\",\n \"downy_birch, white_birch, betula_pubescens\",\n \"black_birch, river_birch, red_birch, betula_nigra\",\n \"sweet_birch, cherry_birch, black_birch, betula_lenta\",\n \"yukon_white_birch, betula_neoalaskana\",\n \"swamp_birch, water_birch, mountain_birch, western_paper_birch, western_birch, betula_fontinalis\",\n \"newfoundland_dwarf_birch, american_dwarf_birch, betula_glandulosa\",\n \"alder, alder_tree\",\n \"common_alder, european_black_alder, alnus_glutinosa, alnus_vulgaris\",\n \"grey_alder, gray_alder, alnus_incana\",\n \"seaside_alder, alnus_maritima\",\n \"white_alder, mountain_alder, alnus_rhombifolia\",\n \"red_alder, oregon_alder, alnus_rubra\",\n \"speckled_alder, alnus_rugosa\",\n \"smooth_alder, hazel_alder, alnus_serrulata\",\n \"green_alder, alnus_veridis\",\n \"green_alder, alnus_veridis_crispa, alnus_crispa\",\n \"hornbeam\",\n \"european_hornbeam, carpinus_betulus\",\n \"american_hornbeam, carpinus_caroliniana\",\n \"hop_hornbeam\",\n \"old_world_hop_hornbeam, ostrya_carpinifolia\",\n \"eastern_hop_hornbeam, ironwood, ironwood_tree, ostrya_virginiana\",\n \"hazelnut, hazel, hazelnut_tree\",\n \"american_hazel, corylus_americana\",\n \"cobnut, filbert, corylus_avellana, corylus_avellana_grandis\",\n \"beaked_hazelnut, corylus_cornuta\",\n \"centaury\",\n \"rosita, centaurium_calycosum\",\n \"lesser_centaury, centaurium_minus\",\n \"seaside_centaury\",\n \"slender_centaury\",\n \"prairie_gentian, tulip_gentian, bluebell, eustoma_grandiflorum\",\n \"persian_violet, exacum_affine\",\n \"columbo, american_columbo, deer's-ear, deer's-ears, pyramid_plant, american_gentian\",\n \"gentian\",\n \"gentianella, gentiana_acaulis\",\n \"closed_gentian, blind_gentian, bottle_gentian, gentiana_andrewsii\",\n \"explorer's_gentian, gentiana_calycosa\",\n \"closed_gentian, blind_gentian, gentiana_clausa\",\n \"great_yellow_gentian, gentiana_lutea\",\n \"marsh_gentian, calathian_violet, gentiana_pneumonanthe\",\n \"soapwort_gentian, gentiana_saponaria\",\n \"striped_gentian, gentiana_villosa\",\n \"agueweed, ague_weed, five-flowered_gentian, stiff_gentian, gentianella_quinquefolia, gentiana_quinquefolia\",\n \"felwort, gentianella_amarella\",\n \"fringed_gentian\",\n \"gentianopsis_crinita, gentiana_crinita\",\n \"gentianopsis_detonsa, gentiana_detonsa\",\n \"gentianopsid_procera, gentiana_procera\",\n \"gentianopsis_thermalis, gentiana_thermalis\",\n \"tufted_gentian, gentianopsis_holopetala, gentiana_holopetala\",\n \"spurred_gentian\",\n \"sabbatia\",\n \"toothbrush_tree, mustard_tree, salvadora_persica\",\n \"olive_tree\",\n \"olive, european_olive_tree, olea_europaea\",\n \"olive\",\n \"black_maire, olea_cunninghamii\",\n \"white_maire, olea_lanceolata\",\n \"fringe_tree\",\n \"fringe_bush, chionanthus_virginicus\",\n \"forestiera\",\n \"forsythia\",\n \"ash, ash_tree\",\n \"white_ash, fraxinus_americana\",\n \"swamp_ash, fraxinus_caroliniana\",\n \"flowering_ash, fraxinus_cuspidata\",\n \"european_ash, common_european_ash, fraxinus_excelsior\",\n \"oregon_ash, fraxinus_latifolia, fraxinus_oregona\",\n \"black_ash, basket_ash, brown_ash, hoop_ash, fraxinus_nigra\",\n \"manna_ash, flowering_ash, fraxinus_ornus\",\n \"red_ash, downy_ash, fraxinus_pennsylvanica\",\n \"green_ash, fraxinus_pennsylvanica_subintegerrima\",\n \"blue_ash, fraxinus_quadrangulata\",\n \"mountain_ash, fraxinus_texensis\",\n \"pumpkin_ash, fraxinus_tomentosa\",\n \"arizona_ash, fraxinus_velutina\",\n \"jasmine\",\n \"primrose_jasmine, jasminum_mesnyi\",\n \"winter_jasmine, jasminum_nudiflorum\",\n \"common_jasmine, true_jasmine, jessamine, jasminum_officinale\",\n \"privet\",\n \"amur_privet, ligustrum_amurense\",\n \"japanese_privet, ligustrum_japonicum\",\n \"ligustrum_obtusifolium\",\n \"common_privet, ligustrum_vulgare\",\n \"devilwood, american_olive, osmanthus_americanus\",\n \"mock_privet\",\n \"lilac\",\n \"himalayan_lilac, syringa_emodi\",\n \"persian_lilac, syringa_persica\",\n \"japanese_tree_lilac, syringa_reticulata, syringa_amurensis_japonica\",\n \"japanese_lilac, syringa_villosa\",\n \"common_lilac, syringa_vulgaris\",\n \"bloodwort\",\n \"kangaroo_paw, kangaroo's_paw, kangaroo's-foot, kangaroo-foot_plant, australian_sword_lily, anigozanthus_manglesii\",\n \"virginian_witch_hazel, hamamelis_virginiana\",\n \"vernal_witch_hazel, hamamelis_vernalis\",\n \"winter_hazel, flowering_hazel\",\n \"fothergilla, witch_alder\",\n \"liquidambar\",\n \"sweet_gum, sweet_gum_tree, bilsted, red_gum, american_sweet_gum, liquidambar_styraciflua\",\n \"iron_tree, iron-tree, ironwood, ironwood_tree\",\n \"walnut, walnut_tree\",\n \"california_black_walnut, juglans_californica\",\n \"butternut, butternut_tree, white_walnut, juglans_cinerea\",\n \"black_walnut, black_walnut_tree, black_hickory, juglans_nigra\",\n \"english_walnut, english_walnut_tree, circassian_walnut, persian_walnut, juglans_regia\",\n \"hickory, hickory_tree\",\n \"water_hickory, bitter_pecan, water_bitternut, carya_aquatica\",\n \"pignut, pignut_hickory, brown_hickory, black_hickory, carya_glabra\",\n \"bitternut, bitternut_hickory, bitter_hickory, bitter_pignut, swamp_hickory, carya_cordiformis\",\n \"pecan, pecan_tree, carya_illinoensis, carya_illinoinsis\",\n \"big_shellbark, big_shellbark_hickory, big_shagbark, king_nut, king_nut_hickory, carya_laciniosa\",\n \"nutmeg_hickory, carya_myristicaeformis, carya_myristiciformis\",\n \"shagbark, shagbark_hickory, shellbark, shellbark_hickory, carya_ovata\",\n \"mockernut, mockernut_hickory, black_hickory, white-heart_hickory, big-bud_hickory, carya_tomentosa\",\n \"wing_nut, wing-nut\",\n \"caucasian_walnut, pterocarya_fraxinifolia\",\n \"dhawa, dhava\",\n \"combretum\",\n \"hiccup_nut, hiccough_nut, combretum_bracteosum\",\n \"bush_willow, combretum_appiculatum\",\n \"bush_willow, combretum_erythrophyllum\",\n \"button_tree, button_mangrove, conocarpus_erectus\",\n \"white_mangrove, laguncularia_racemosa\",\n \"oleaster\",\n \"water_milfoil\",\n \"anchovy_pear, anchovy_pear_tree, grias_cauliflora\",\n \"brazil_nut, brazil-nut_tree, bertholletia_excelsa\",\n \"loosestrife\",\n \"purple_loosestrife, spiked_loosestrife, lythrum_salicaria\",\n \"grass_poly, hyssop_loosestrife, lythrum_hyssopifolia\",\n \"crape_myrtle, crepe_myrtle, crepe_flower, lagerstroemia_indica\",\n \"queen's_crape_myrtle, pride-of-india, lagerstroemia_speciosa\",\n \"myrtaceous_tree\",\n \"myrtle\",\n \"common_myrtle, myrtus_communis\",\n \"bayberry, bay-rum_tree, jamaica_bayberry, wild_cinnamon, pimenta_acris\",\n \"allspice, allspice_tree, pimento_tree, pimenta_dioica\",\n \"allspice_tree, pimenta_officinalis\",\n \"sour_cherry, eugenia_corynantha\",\n \"nakedwood, eugenia_dicrana\",\n \"surinam_cherry, pitanga, eugenia_uniflora\",\n \"rose_apple, rose-apple_tree, jambosa, eugenia_jambos\",\n \"feijoa, feijoa_bush\",\n \"jaboticaba, jaboticaba_tree, myrciaria_cauliflora\",\n \"guava, true_guava, guava_bush, psidium_guajava\",\n \"guava, strawberry_guava, yellow_cattley_guava, psidium_littorale\",\n \"cattley_guava, purple_strawberry_guava, psidium_cattleianum, psidium_littorale_longipes\",\n \"brazilian_guava, psidium_guineense\",\n \"gum_tree, gum\",\n \"eucalyptus, eucalypt, eucalyptus_tree\",\n \"flooded_gum\",\n \"mallee\",\n \"stringybark\",\n \"smoothbark\",\n \"red_gum, peppermint, peppermint_gum, eucalyptus_amygdalina\",\n \"red_gum, marri, eucalyptus_calophylla\",\n \"river_red_gum, river_gum, eucalyptus_camaldulensis, eucalyptus_rostrata\",\n \"mountain_swamp_gum, eucalyptus_camphora\",\n \"snow_gum, ghost_gum, white_ash, eucalyptus_coriacea, eucalyptus_pauciflora\",\n \"alpine_ash, mountain_oak, eucalyptus_delegatensis\",\n \"white_mallee, congoo_mallee, eucalyptus_dumosa\",\n \"white_stringybark, thin-leaved_stringybark, eucalyptusd_eugenioides\",\n \"white_mountain_ash, eucalyptus_fraxinoides\",\n \"blue_gum, fever_tree, eucalyptus_globulus\",\n \"rose_gum, eucalypt_grandis\",\n \"cider_gum, eucalypt_gunnii\",\n \"swamp_gum, eucalypt_ovata\",\n \"spotted_gum, eucalyptus_maculata\",\n \"lemon-scented_gum, eucalyptus_citriodora, eucalyptus_maculata_citriodora\",\n \"black_mallee, black_sally, black_gum, eucalytus_stellulata\",\n \"forest_red_gum, eucalypt_tereticornis\",\n \"mountain_ash, eucalyptus_regnans\",\n \"manna_gum, eucalyptus_viminalis\",\n \"clove, clove_tree, syzygium_aromaticum, eugenia_aromaticum, eugenia_caryophyllatum\",\n \"clove\",\n \"tupelo, tupelo_tree\",\n \"water_gum, nyssa_aquatica\",\n \"sour_gum, black_gum, pepperidge, nyssa_sylvatica\",\n \"enchanter's_nightshade\",\n \"circaea_lutetiana\",\n \"willowherb\",\n \"fireweed, giant_willowherb, rosebay_willowherb, wickup, epilobium_angustifolium\",\n \"california_fuchsia, humming_bird's_trumpet, epilobium_canum_canum, zauschneria_californica\",\n \"fuchsia\",\n \"lady's-eardrop, ladies'-eardrop, lady's-eardrops, ladies'-eardrops, fuchsia_coccinea\",\n \"evening_primrose\",\n \"common_evening_primrose, german_rampion, oenothera_biennis\",\n \"sundrops, oenothera_fruticosa\",\n \"missouri_primrose, ozark_sundrops, oenothera_macrocarpa\",\n \"pomegranate, pomegranate_tree, punica_granatum\",\n \"mangrove, rhizophora_mangle\",\n \"daphne\",\n \"garland_flower, daphne_cneorum\",\n \"spurge_laurel, wood_laurel, daphne_laureola\",\n \"mezereon, february_daphne, daphne_mezereum\",\n \"indian_rhododendron, melastoma_malabathricum\",\n \"medinilla_magnifica\",\n \"deer_grass, meadow_beauty\",\n \"canna\",\n \"achira, indian_shot, arrowroot, canna_indica, canna_edulis\",\n \"arrowroot, american_arrowroot, obedience_plant, maranta_arundinaceae\",\n \"banana, banana_tree\",\n \"dwarf_banana, musa_acuminata\",\n \"japanese_banana, musa_basjoo\",\n \"plantain, plantain_tree, musa_paradisiaca\",\n \"edible_banana, musa_paradisiaca_sapientum\",\n \"abaca, manila_hemp, musa_textilis\",\n \"abyssinian_banana, ethiopian_banana, ensete_ventricosum, musa_ensete\",\n \"ginger\",\n \"common_ginger, canton_ginger, stem_ginger, zingiber_officinale\",\n \"turmeric, curcuma_longa, curcuma_domestica\",\n \"galangal, alpinia_galanga\",\n \"shellflower, shall-flower, shell_ginger, alpinia_zerumbet, alpinia_speciosa, languas_speciosa\",\n \"grains_of_paradise, guinea_grains, guinea_pepper, melagueta_pepper, aframomum_melegueta\",\n \"cardamom, cardamon, elettaria_cardamomum\",\n \"begonia\",\n \"fibrous-rooted_begonia\",\n \"tuberous_begonia\",\n \"rhizomatous_begonia\",\n \"christmas_begonia, blooming-fool_begonia, begonia_cheimantha\",\n \"angel-wing_begonia, begonia_cocchinea\",\n \"beefsteak_begonia, kidney_begonia, begonia_erythrophylla, begonia_feastii\",\n \"star_begonia, star-leaf_begonia, begonia_heracleifolia\",\n \"rex_begonia, king_begonia, painted-leaf_begonia, beefsteak_geranium, begonia_rex\",\n \"wax_begonia, begonia_semperflorens\",\n \"socotra_begonia, begonia_socotrana\",\n \"hybrid_tuberous_begonia, begonia_tuberhybrida\",\n \"dillenia\",\n \"guinea_gold_vine, guinea_flower\",\n \"poon\",\n \"calaba, santa_maria_tree, calophyllum_calaba\",\n \"maria, calophyllum_longifolium\",\n \"laurelwood, lancewood_tree, calophyllum_candidissimum\",\n \"alexandrian_laurel, calophyllum_inophyllum\",\n \"clusia\",\n \"wild_fig, clusia_flava\",\n \"waxflower, clusia_insignis\",\n \"pitch_apple, strangler_fig, clusia_rosea, clusia_major\",\n \"mangosteen, mangosteen_tree, garcinia_mangostana\",\n \"gamboge_tree, garcinia_hanburyi, garcinia_cambogia, garcinia_gummi-gutta\",\n \"st_john's_wort\",\n \"common_st_john's_wort, tutsan, hypericum_androsaemum\",\n \"great_st_john's_wort, hypericum_ascyron, hypericum_pyramidatum\",\n \"creeping_st_john's_wort, hypericum_calycinum\",\n \"low_st_andrew's_cross, hypericum_hypericoides\",\n \"klammath_weed, hypericum_perforatum\",\n \"shrubby_st_john's_wort, hypericum_prolificum, hypericum_spathulatum\",\n \"st_peter's_wort, hypericum_tetrapterum, hypericum_maculatum\",\n \"marsh_st-john's_wort, hypericum_virginianum\",\n \"mammee_apple, mammee, mamey, mammee_tree, mammea_americana\",\n \"rose_chestnut, ironwood, ironwood_tree, mesua_ferrea\",\n \"bower_actinidia, tara_vine, actinidia_arguta\",\n \"chinese_gooseberry, kiwi, kiwi_vine, actinidia_chinensis, actinidia_deliciosa\",\n \"silvervine, silver_vine, actinidia_polygama\",\n \"wild_cinnamon, white_cinnamon_tree, canella_winterana, canella-alba\",\n \"papaya, papaia, pawpaw, papaya_tree, melon_tree, carica_papaya\",\n \"souari, souari_nut, souari_tree, caryocar_nuciferum\",\n \"rockrose, rock_rose\",\n \"white-leaved_rockrose, cistus_albidus\",\n \"common_gum_cistus, cistus_ladanifer, cistus_ladanum\",\n \"frostweed, frost-weed, frostwort, helianthemum_canadense, crocanthemum_canadense\",\n \"dipterocarp\",\n \"red_lauan, red_lauan_tree, shorea_teysmanniana\",\n \"governor's_plum, governor_plum, madagascar_plum, ramontchi, batoko_palm, flacourtia_indica\",\n \"kei_apple, kei_apple_bush, dovyalis_caffra\",\n \"ketembilla, kitembilla, kitambilla, ketembilla_tree, ceylon_gooseberry, dovyalis_hebecarpa\",\n \"chaulmoogra, chaulmoogra_tree, chaulmugra, hydnocarpus_kurzii, taraktagenos_kurzii, taraktogenos_kurzii\",\n \"wild_peach, kiggelaria_africana\",\n \"candlewood\",\n \"boojum_tree, cirio, fouquieria_columnaris, idria_columnaris\",\n \"bird's-eye_bush, ochna_serrulata\",\n \"granadilla, purple_granadillo, passiflora_edulis\",\n \"granadilla, sweet_granadilla, passiflora_ligularis\",\n \"granadilla, giant_granadilla, passiflora_quadrangularis\",\n \"maypop, passiflora_incarnata\",\n \"jamaica_honeysuckle, yellow_granadilla, passiflora_laurifolia\",\n \"banana_passion_fruit, passiflora_mollissima\",\n \"sweet_calabash, passiflora_maliformis\",\n \"love-in-a-mist, running_pop, wild_water_lemon, passiflora_foetida\",\n \"reseda\",\n \"mignonette, sweet_reseda, reseda_odorata\",\n \"dyer's_rocket, dyer's_mignonette, weld, reseda_luteola\",\n \"false_tamarisk, german_tamarisk, myricaria_germanica\",\n \"halophyte\",\n \"viola\",\n \"violet\",\n \"field_pansy, heartsease, viola_arvensis\",\n \"american_dog_violet, viola_conspersa\",\n \"dog_violet, heath_violet, viola_canina\",\n \"horned_violet, tufted_pansy, viola_cornuta\",\n \"two-eyed_violet, heartsease, viola_ocellata\",\n \"bird's-foot_violet, pansy_violet, johnny-jump-up, wood_violet, viola_pedata\",\n \"downy_yellow_violet, viola_pubescens\",\n \"long-spurred_violet, viola_rostrata\",\n \"pale_violet, striped_violet, cream_violet, viola_striata\",\n \"hedge_violet, wood_violet, viola_sylvatica, viola_reichenbachiana\",\n \"nettle\",\n \"stinging_nettle, urtica_dioica\",\n \"roman_nettle, urtica_pipulifera\",\n \"ramie, ramee, chinese_silk_plant, china_grass, boehmeria_nivea\",\n \"wood_nettle, laportea_canadensis\",\n \"australian_nettle, australian_nettle_tree\",\n \"pellitory-of-the-wall, wall_pellitory, pellitory, parietaria_difussa\",\n \"richweed, clearweed, dead_nettle, pilea_pumilla\",\n \"artillery_plant, pilea_microphylla\",\n \"friendship_plant, panamica, panamiga, pilea_involucrata\",\n \"queensland_grass-cloth_plant, pipturus_argenteus\",\n \"pipturus_albidus\",\n \"cannabis, hemp\",\n \"indian_hemp, cannabis_indica\",\n \"mulberry, mulberry_tree\",\n \"white_mulberry, morus_alba\",\n \"black_mulberry, morus_nigra\",\n \"red_mulberry, morus_rubra\",\n \"osage_orange, bow_wood, mock_orange, maclura_pomifera\",\n \"breadfruit, breadfruit_tree, artocarpus_communis, artocarpus_altilis\",\n \"jackfruit, jackfruit_tree, artocarpus_heterophyllus\",\n \"marang, marang_tree, artocarpus_odoratissima\",\n \"fig_tree\",\n \"fig, common_fig, common_fig_tree, ficus_carica\",\n \"caprifig, ficus_carica_sylvestris\",\n \"golden_fig, florida_strangler_fig, strangler_fig, wild_fig, ficus_aurea\",\n \"banyan, banyan_tree, banian, banian_tree, indian_banyan, east_indian_fig_tree, ficus_bengalensis\",\n \"pipal, pipal_tree, pipul, peepul, sacred_fig, bo_tree, ficus_religiosa\",\n \"india-rubber_tree, india-rubber_plant, india-rubber_fig, rubber_plant, assam_rubber, ficus_elastica\",\n \"mistletoe_fig, mistletoe_rubber_plant, ficus_diversifolia, ficus_deltoidea\",\n \"port_jackson_fig, rusty_rig, little-leaf_fig, botany_bay_fig, ficus_rubiginosa\",\n \"sycamore, sycamore_fig, mulberry_fig, ficus_sycomorus\",\n \"paper_mulberry, broussonetia_papyrifera\",\n \"trumpetwood, trumpet-wood, trumpet_tree, snake_wood, imbauba, cecropia_peltata\",\n \"elm, elm_tree\",\n \"winged_elm, wing_elm, ulmus_alata\",\n \"american_elm, white_elm, water_elm, rock_elm, ulmus_americana\",\n \"smooth-leaved_elm, european_field_elm, ulmus_carpinifolia\",\n \"cedar_elm, ulmus_crassifolia\",\n \"witch_elm, wych_elm, ulmus_glabra\",\n \"dutch_elm, ulmus_hollandica\",\n \"huntingdon_elm, ulmus_hollandica_vegetata\",\n \"water_elm, ulmus_laevis\",\n \"chinese_elm, ulmus_parvifolia\",\n \"english_elm, european_elm, ulmus_procera\",\n \"siberian_elm, chinese_elm, dwarf_elm, ulmus_pumila\",\n \"slippery_elm, red_elm, ulmus_rubra\",\n \"jersey_elm, guernsey_elm, wheately_elm, ulmus_sarniensis, ulmus_campestris_sarniensis, ulmus_campestris_wheatleyi\",\n \"september_elm, red_elm, ulmus_serotina\",\n \"rock_elm, ulmus_thomasii\",\n \"hackberry, nettle_tree\",\n \"european_hackberry, mediterranean_hackberry, celtis_australis\",\n \"american_hackberry, celtis_occidentalis\",\n \"sugarberry, celtis_laevigata\",\n \"iridaceous_plant\",\n \"bearded_iris\",\n \"beardless_iris\",\n \"orrisroot, orris\",\n \"dwarf_iris, iris_cristata\",\n \"dutch_iris, iris_filifolia\",\n \"florentine_iris, orris, iris_germanica_florentina, iris_florentina\",\n \"stinking_iris, gladdon, gladdon_iris, stinking_gladwyn, roast_beef_plant, iris_foetidissima\",\n \"german_iris, iris_germanica\",\n \"japanese_iris, iris_kaempferi\",\n \"german_iris, iris_kochii\",\n \"dalmatian_iris, iris_pallida\",\n \"persian_iris, iris_persica\",\n \"dutch_iris, iris_tingitana\",\n \"dwarf_iris, vernal_iris, iris_verna\",\n \"spanish_iris, xiphium_iris, iris_xiphium\",\n \"blackberry-lily, leopard_lily, belamcanda_chinensis\",\n \"crocus\",\n \"saffron, saffron_crocus, crocus_sativus\",\n \"corn_lily\",\n \"blue-eyed_grass\",\n \"wandflower, sparaxis_tricolor\",\n \"amaryllis\",\n \"salsilla, bomarea_edulis\",\n \"salsilla, bomarea_salsilla\",\n \"blood_lily\",\n \"cape_tulip, haemanthus_coccineus\",\n \"hippeastrum, hippeastrum_puniceum\",\n \"narcissus\",\n \"daffodil, narcissus_pseudonarcissus\",\n \"jonquil, narcissus_jonquilla\",\n \"jonquil\",\n \"jacobean_lily, aztec_lily, strekelia_formosissima\",\n \"liliaceous_plant\",\n \"mountain_lily, lilium_auratum\",\n \"canada_lily, wild_yellow_lily, meadow_lily, wild_meadow_lily, lilium_canadense\",\n \"tiger_lily, leopard_lily, pine_lily, lilium_catesbaei\",\n \"columbia_tiger_lily, oregon_lily, lilium_columbianum\",\n \"tiger_lily, devil_lily, kentan, lilium_lancifolium\",\n \"easter_lily, bermuda_lily, white_trumpet_lily, lilium_longiflorum\",\n \"coast_lily, lilium_maritinum\",\n \"turk's-cap, martagon, lilium_martagon\",\n \"michigan_lily, lilium_michiganense\",\n \"leopard_lily, panther_lily, lilium_pardalinum\",\n \"turk's-cap, turk's_cap-lily, lilium_superbum\",\n \"african_lily, african_tulip, blue_african_lily, agapanthus_africanus\",\n \"colicroot, colic_root, crow_corn, star_grass, unicorn_root\",\n \"ague_root, ague_grass, aletris_farinosa\",\n \"yellow_colicroot, aletris_aurea\",\n \"alliaceous_plant\",\n \"hooker's_onion, allium_acuminatum\",\n \"wild_leek, levant_garlic, kurrat, allium_ampeloprasum\",\n \"canada_garlic, meadow_leek, rose_leek, allium_canadense\",\n \"keeled_garlic, allium_carinatum\",\n \"onion\",\n \"shallot, eschalot, multiplier_onion, allium_cepa_aggregatum, allium_ascalonicum\",\n \"nodding_onion, nodding_wild_onion, lady's_leek, allium_cernuum\",\n \"welsh_onion, japanese_leek, allium_fistulosum\",\n \"red-skinned_onion, allium_haematochiton\",\n \"daffodil_garlic, flowering_onion, naples_garlic, allium_neopolitanum\",\n \"few-flowered_leek, allium_paradoxum\",\n \"garlic, allium_sativum\",\n \"sand_leek, giant_garlic, spanish_garlic, rocambole, allium_scorodoprasum\",\n \"chives, chive, cive, schnittlaugh, allium_schoenoprasum\",\n \"crow_garlic, false_garlic, field_garlic, stag's_garlic, wild_garlic, allium_vineale\",\n \"wild_garlic, wood_garlic, ramsons, allium_ursinum\",\n \"garlic_chive, chinese_chive, oriental_garlic, allium_tuberosum\",\n \"round-headed_leek, allium_sphaerocephalum\",\n \"three-cornered_leek, triquetrous_leek, allium_triquetrum\",\n \"cape_aloe, aloe_ferox\",\n \"kniphofia, tritoma, flame_flower, flame-flower, flameflower\",\n \"poker_plant, kniphofia_uvaria\",\n \"red-hot_poker, kniphofia_praecox\",\n \"fly_poison, amianthum_muscaetoxicum, amianthum_muscitoxicum\",\n \"amber_lily, anthericum_torreyi\",\n \"asparagus, edible_asparagus, asparagus_officinales\",\n \"asparagus_fern, asparagus_setaceous, asparagus_plumosus\",\n \"smilax, asparagus_asparagoides\",\n \"asphodel\",\n \"jacob's_rod\",\n \"aspidistra, cast-iron_plant, bar-room_plant, aspidistra_elatio\",\n \"coral_drops, bessera_elegans\",\n \"christmas_bells\",\n \"climbing_onion, bowiea_volubilis\",\n \"mariposa, mariposa_tulip, mariposa_lily\",\n \"globe_lily, fairy_lantern\",\n \"cat's-ear\",\n \"white_globe_lily, white_fairy_lantern, calochortus_albus\",\n \"yellow_globe_lily, golden_fairy_lantern, calochortus_amabilis\",\n \"rose_globe_lily, calochortus_amoenus\",\n \"star_tulip, elegant_cat's_ears, calochortus_elegans\",\n \"desert_mariposa_tulip, calochortus_kennedyi\",\n \"yellow_mariposa_tulip, calochortus_luteus\",\n \"sagebrush_mariposa_tulip, calochortus_macrocarpus\",\n \"sego_lily, calochortus_nuttallii\",\n \"camas, camass, quamash, camosh, camash\",\n \"common_camas, camassia_quamash\",\n \"leichtlin's_camas, camassia_leichtlinii\",\n \"wild_hyacinth, indigo_squill, camassia_scilloides\",\n \"dogtooth_violet, dogtooth, dog's-tooth_violet\",\n \"white_dogtooth_violet, white_dog's-tooth_violet, blonde_lilian, erythronium_albidum\",\n \"yellow_adder's_tongue, trout_lily, amberbell, erythronium_americanum\",\n \"european_dogtooth, erythronium_dens-canis\",\n \"fawn_lily, erythronium_californicum\",\n \"glacier_lily, snow_lily, erythronium_grandiflorum\",\n \"avalanche_lily, erythronium_montanum\",\n \"fritillary, checkered_lily\",\n \"mission_bells, rice-grain_fritillary, fritillaria_affinis, fritillaria_lanceolata, fritillaria_mutica\",\n \"mission_bells, black_fritillary, fritillaria_biflora\",\n \"stink_bell, fritillaria_agrestis\",\n \"crown_imperial, fritillaria_imperialis\",\n \"white_fritillary, fritillaria_liliaceae\",\n \"snake's_head_fritillary, guinea-hen_flower, checkered_daffodil, leper_lily, fritillaria_meleagris\",\n \"adobe_lily, pink_fritillary, fritillaria_pluriflora\",\n \"scarlet_fritillary, fritillaria_recurva\",\n \"tulip\",\n \"dwarf_tulip, tulipa_armena, tulipa_suaveolens\",\n \"lady_tulip, candlestick_tulip, tulipa_clusiana\",\n \"tulipa_gesneriana\",\n \"cottage_tulip\",\n \"darwin_tulip\",\n \"gloriosa, glory_lily, climbing_lily, creeping_lily, gloriosa_superba\",\n \"lemon_lily, hemerocallis_lilio-asphodelus, hemerocallis_flava\",\n \"common_hyacinth, hyacinthus_orientalis\",\n \"roman_hyacinth, hyacinthus_orientalis_albulus\",\n \"summer_hyacinth, cape_hyacinth, hyacinthus_candicans, galtonia_candicans\",\n \"star-of-bethlehem\",\n \"bath_asparagus, prussian_asparagus, ornithogalum_pyrenaicum\",\n \"grape_hyacinth\",\n \"common_grape_hyacinth, muscari_neglectum\",\n \"tassel_hyacinth, muscari_comosum\",\n \"scilla, squill\",\n \"spring_squill, scilla_verna, sea_onion\",\n \"false_asphodel\",\n \"scotch_asphodel, tofieldia_pusilla\",\n \"sea_squill, sea_onion, squill, urginea_maritima\",\n \"squill\",\n \"butcher's_broom, ruscus_aculeatus\",\n \"bog_asphodel\",\n \"european_bog_asphodel, narthecium_ossifragum\",\n \"american_bog_asphodel, narthecium_americanum\",\n \"hellebore, false_hellebore\",\n \"white_hellebore, american_hellebore, indian_poke, bugbane, veratrum_viride\",\n \"squaw_grass, bear_grass, xerophyllum_tenax\",\n \"death_camas, zigadene\",\n \"alkali_grass, zigadenus_elegans\",\n \"white_camas, zigadenus_glaucus\",\n \"poison_camas, zigadenus_nuttalli\",\n \"grassy_death_camas, zigadenus_venenosus, zigadenus_venenosus_gramineus\",\n \"prairie_wake-robin, prairie_trillium, trillium_recurvatum\",\n \"dwarf-white_trillium, snow_trillium, early_wake-robin\",\n \"herb_paris, paris_quadrifolia\",\n \"sarsaparilla\",\n \"bullbrier, greenbrier, catbrier, horse_brier, horse-brier, brier, briar, smilax_rotundifolia\",\n \"rough_bindweed, smilax_aspera\",\n \"clintonia, clinton's_lily\",\n \"false_lily_of_the_valley, maianthemum_canadense\",\n \"false_lily_of_the_valley, maianthemum_bifolium\",\n \"solomon's-seal\",\n \"great_solomon's-seal, polygonatum_biflorum, polygonatum_commutatum\",\n \"bellwort, merry_bells, wild_oats\",\n \"strawflower, cornflower, uvularia_grandiflora\",\n \"pia, indian_arrowroot, tacca_leontopetaloides, tacca_pinnatifida\",\n \"agave, century_plant, american_aloe\",\n \"american_agave, agave_americana\",\n \"sisal, agave_sisalana\",\n \"maguey, cantala, agave_cantala\",\n \"maguey, agave_atrovirens\",\n \"agave_tequilana\",\n \"cabbage_tree, grass_tree, cordyline_australis\",\n \"dracaena\",\n \"tuberose, polianthes_tuberosa\",\n \"sansevieria, bowstring_hemp\",\n \"african_bowstring_hemp, african_hemp, sansevieria_guineensis\",\n \"ceylon_bowstring_hemp, sansevieria_zeylanica\",\n \"mother-in-law's_tongue, snake_plant, sansevieria_trifasciata\",\n \"spanish_bayonet, yucca_aloifolia\",\n \"spanish_bayonet, yucca_baccata\",\n \"joshua_tree, yucca_brevifolia\",\n \"soapweed, soap-weed, soap_tree, yucca_elata\",\n \"adam's_needle, adam's_needle-and-thread, spoonleaf_yucca, needle_palm, yucca_filamentosa\",\n \"bear_grass, yucca_glauca\",\n \"spanish_dagger, yucca_gloriosa\",\n \"our_lord's_candle, yucca_whipplei\",\n \"water_shamrock, buckbean, bogbean, bog_myrtle, marsh_trefoil, menyanthes_trifoliata\",\n \"butterfly_bush, buddleia\",\n \"yellow_jasmine, yellow_jessamine, carolina_jasmine, evening_trumpet_flower, gelsemium_sempervirens\",\n \"flax\",\n \"calabar_bean, ordeal_bean\",\n \"bonduc, bonduc_tree, caesalpinia_bonduc, caesalpinia_bonducella\",\n \"divi-divi, caesalpinia_coriaria\",\n \"mysore_thorn, caesalpinia_decapetala, caesalpinia_sepiaria\",\n \"brazilian_ironwood, caesalpinia_ferrea\",\n \"bird_of_paradise, poinciana, caesalpinia_gilliesii, poinciana_gilliesii\",\n \"shingle_tree, acrocarpus_fraxinifolius\",\n \"mountain_ebony, orchid_tree, bauhinia_variegata\",\n \"msasa, brachystegia_speciformis\",\n \"cassia\",\n \"golden_shower_tree, drumstick_tree, purging_cassia, pudding_pipe_tree, canafistola, canafistula, cassia_fistula\",\n \"pink_shower, pink_shower_tree, horse_cassia, cassia_grandis\",\n \"rainbow_shower, cassia_javonica\",\n \"horse_cassia, cassia_roxburghii, cassia_marginata\",\n \"carob, carob_tree, carob_bean_tree, algarroba, ceratonia_siliqua\",\n \"carob, carob_bean, algarroba_bean, algarroba, locust_bean, locust_pod\",\n \"paloverde\",\n \"royal_poinciana, flamboyant, flame_tree, peacock_flower, delonix_regia, poinciana_regia\",\n \"locust_tree, locust\",\n \"water_locust, swamp_locust, gleditsia_aquatica\",\n \"honey_locust, gleditsia_triacanthos\",\n \"kentucky_coffee_tree, bonduc, chicot, gymnocladus_dioica\",\n \"logwood, logwood_tree, campeachy, bloodwood_tree, haematoxylum_campechianum\",\n \"jerusalem_thorn, horsebean, parkinsonia_aculeata\",\n \"palo_verde, parkinsonia_florida, cercidium_floridum\",\n \"dalmatian_laburnum, petteria_ramentacea, cytisus_ramentaceus\",\n \"senna\",\n \"avaram, tanner's_cassia, senna_auriculata, cassia_auriculata\",\n \"alexandria_senna, alexandrian_senna, true_senna, tinnevelly_senna, indian_senna, senna_alexandrina, cassia_acutifolia, cassia_augustifolia\",\n \"wild_senna, senna_marilandica, cassia_marilandica\",\n \"sicklepod, senna_obtusifolia, cassia_tora\",\n \"coffee_senna, mogdad_coffee, styptic_weed, stinking_weed, senna_occidentalis, cassia_occidentalis\",\n \"tamarind, tamarind_tree, tamarindo, tamarindus_indica\",\n \"false_indigo, bastard_indigo, amorpha_californica\",\n \"false_indigo, bastard_indigo, amorpha_fruticosa\",\n \"hog_peanut, wild_peanut, amphicarpaea_bracteata, amphicarpa_bracteata\",\n \"angelim, andelmin\",\n \"cabbage_bark, cabbage-bark_tree, cabbage_tree, andira_inermis\",\n \"kidney_vetch, anthyllis_vulneraria\",\n \"groundnut, groundnut_vine, indian_potato, potato_bean, wild_bean, apios_americana, apios_tuberosa\",\n \"rooibos, aspalathus_linearis, aspalathus_cedcarbergensis\",\n \"milk_vetch, milk-vetch\",\n \"alpine_milk_vetch, astragalus_alpinus\",\n \"purple_milk_vetch, astragalus_danicus\",\n \"camwood, african_sandalwood, baphia_nitida\",\n \"wild_indigo, false_indigo\",\n \"blue_false_indigo, baptisia_australis\",\n \"white_false_indigo, baptisia_lactea\",\n \"indigo_broom, horsefly_weed, rattle_weed, baptisia_tinctoria\",\n \"dhak, dak, palas, butea_frondosa, butea_monosperma\",\n \"pigeon_pea, pigeon-pea_plant, cajan_pea, catjang_pea, red_gram, dhal, dahl, cajanus_cajan\",\n \"sword_bean, canavalia_gladiata\",\n \"pea_tree, caragana\",\n \"siberian_pea_tree, caragana_arborescens\",\n \"chinese_pea_tree, caragana_sinica\",\n \"moreton_bay_chestnut, australian_chestnut\",\n \"butterfly_pea, centrosema_virginianum\",\n \"judas_tree, love_tree, circis_siliquastrum\",\n \"redbud, cercis_canadensis\",\n \"western_redbud, california_redbud, cercis_occidentalis\",\n \"tagasaste, chamaecytisus_palmensis, cytesis_proliferus\",\n \"weeping_tree_broom\",\n \"flame_pea\",\n \"chickpea, chickpea_plant, egyptian_pea, cicer_arietinum\",\n \"chickpea, garbanzo\",\n \"kentucky_yellowwood, gopherwood, cladrastis_lutea, cladrastis_kentukea\",\n \"glory_pea, clianthus\",\n \"desert_pea, sturt_pea, sturt's_desert_pea, clianthus_formosus, clianthus_speciosus\",\n \"parrot's_beak, parrot's_bill, clianthus_puniceus\",\n \"butterfly_pea, clitoria_mariana\",\n \"blue_pea, butterfly_pea, clitoria_turnatea\",\n \"telegraph_plant, semaphore_plant, codariocalyx_motorius, desmodium_motorium, desmodium_gyrans\",\n \"bladder_senna, colutea_arborescens\",\n \"axseed, crown_vetch, coronilla_varia\",\n \"crotalaria, rattlebox\",\n \"guar, cluster_bean, cyamopsis_tetragonolobus, cyamopsis_psoraloides\",\n \"white_broom, white_spanish_broom, cytisus_albus, cytisus_multiflorus\",\n \"common_broom, scotch_broom, green_broom, cytisus_scoparius\",\n \"rosewood, rosewood_tree\",\n \"indian_blackwood, east_indian_rosewood, east_india_rosewood, indian_rosewood, dalbergia_latifolia\",\n \"sissoo, sissu, sisham, dalbergia_sissoo\",\n \"kingwood, kingwood_tree, dalbergia_cearensis\",\n \"brazilian_rosewood, caviuna_wood, jacaranda, dalbergia_nigra\",\n \"cocobolo, dalbergia_retusa\",\n \"blackwood, blackwood_tree\",\n \"bitter_pea\",\n \"derris\",\n \"derris_root, tuba_root, derris_elliptica\",\n \"prairie_mimosa, prickle-weed, desmanthus_ilinoensis\",\n \"tick_trefoil, beggar_lice, beggar's_lice\",\n \"beggarweed, desmodium_tortuosum, desmodium_purpureum\",\n \"australian_pea, dipogon_lignosus, dolichos_lignosus\",\n \"coral_tree, erythrina\",\n \"kaffir_boom, cape_kafferboom, erythrina_caffra\",\n \"coral_bean_tree, erythrina_corallodendrum\",\n \"ceibo, crybaby_tree, cry-baby_tree, common_coral_tree, erythrina_crista-galli\",\n \"kaffir_boom, transvaal_kafferboom, erythrina_lysistemon\",\n \"indian_coral_tree, erythrina_variegata, erythrina_indica\",\n \"cork_tree, erythrina_vespertilio\",\n \"goat's_rue, goat_rue, galega_officinalis\",\n \"poison_bush, poison_pea, gastrolobium\",\n \"spanish_broom, spanish_gorse, genista_hispanica\",\n \"woodwaxen, dyer's_greenweed, dyer's-broom, dyeweed, greenweed, whin, woadwaxen, genista_tinctoria\",\n \"chanar, chanal, geoffroea_decorticans\",\n \"gliricidia\",\n \"soy, soybean, soya_bean\",\n \"licorice, liquorice, glycyrrhiza_glabra\",\n \"wild_licorice, wild_liquorice, american_licorice, american_liquorice, glycyrrhiza_lepidota\",\n \"licorice_root\",\n \"western_australia_coral_pea, hardenbergia_comnptoniana\",\n \"sweet_vetch, hedysarum_boreale\",\n \"french_honeysuckle, sulla, hedysarum_coronarium\",\n \"anil, indigofera_suffruticosa, indigofera_anil\",\n \"scarlet_runner, running_postman, kennedia_prostrata\",\n \"hyacinth_bean, bonavist, indian_bean, egyptian_bean, lablab_purpureus, dolichos_lablab\",\n \"scotch_laburnum, alpine_golden_chain, laburnum_alpinum\",\n \"vetchling\",\n \"wild_pea\",\n \"everlasting_pea\",\n \"beach_pea, sea_pea, lathyrus_maritimus, lathyrus_japonicus\",\n \"grass_vetch, grass_vetchling, lathyrus_nissolia\",\n \"marsh_pea, lathyrus_palustris\",\n \"common_vetchling, meadow_pea, yellow_vetchling, lathyrus_pratensis\",\n \"grass_pea, indian_pea, khesari, lathyrus_sativus\",\n \"tangier_pea, tangier_peavine, lalthyrus_tingitanus\",\n \"heath_pea, earth-nut_pea, earthnut_pea, tuberous_vetch, lathyrus_tuberosus\",\n \"bicolor_lespediza, ezo-yama-hagi, lespedeza_bicolor\",\n \"japanese_clover, japan_clover, jap_clover, lespedeza_striata\",\n \"korean_lespedeza, lespedeza_stipulacea\",\n \"sericea_lespedeza, lespedeza_sericea, lespedeza_cuneata\",\n \"lentil, lentil_plant, lens_culinaris\",\n \"lentil\",\n \"prairie_bird's-foot_trefoil, compass_plant, prairie_lotus, prairie_trefoil, lotus_americanus\",\n \"bird's_foot_trefoil, bird's_foot_clover, babies'_slippers, bacon_and_eggs, lotus_corniculatus\",\n \"winged_pea, asparagus_pea, lotus_tetragonolobus\",\n \"lupine, lupin\",\n \"white_lupine, field_lupine, wolf_bean, egyptian_lupine, lupinus_albus\",\n \"tree_lupine, lupinus_arboreus\",\n \"wild_lupine, sundial_lupine, indian_beet, old-maid's_bonnet, lupinus_perennis\",\n \"bluebonnet, buffalo_clover, texas_bluebonnet, lupinus_subcarnosus\",\n \"texas_bluebonnet, lupinus_texensis\",\n \"medic, medick, trefoil\",\n \"moon_trefoil, medicago_arborea\",\n \"sickle_alfalfa, sickle_lucerne, sickle_medick, medicago_falcata\",\n \"calvary_clover, medicago_intertexta, medicago_echinus\",\n \"black_medick, hop_clover, yellow_trefoil, nonesuch_clover, medicago_lupulina\",\n \"alfalfa, lucerne, medicago_sativa\",\n \"millettia\",\n \"mucuna\",\n \"cowage, velvet_bean, bengal_bean, benghal_bean, florida_bean, mucuna_pruriens_utilis, mucuna_deeringiana, mucuna_aterrima, stizolobium_deeringiana\",\n \"tolu_tree, tolu_balsam_tree, myroxylon_balsamum, myroxylon_toluiferum\",\n \"peruvian_balsam, myroxylon_pereirae, myroxylon_balsamum_pereirae\",\n \"sainfoin, sanfoin, holy_clover, esparcet, onobrychis_viciifolia, onobrychis_viciaefolia\",\n \"restharrow, rest-harrow, ononis_repens\",\n \"bead_tree, jumby_bean, jumby_tree, ormosia_monosperma\",\n \"jumby_bead, jumbie_bead, ormosia_coarctata\",\n \"locoweed, crazyweed, crazy_weed\",\n \"purple_locoweed, purple_loco, oxytropis_lambertii\",\n \"tumbleweed\",\n \"yam_bean, pachyrhizus_erosus\",\n \"shamrock_pea, parochetus_communis\",\n \"pole_bean\",\n \"kidney_bean, frijol, frijole\",\n \"haricot\",\n \"wax_bean\",\n \"scarlet_runner, scarlet_runner_bean, dutch_case-knife_bean, runner_bean, phaseolus_coccineus, phaseolus_multiflorus\",\n \"lima_bean, lima_bean_plant, phaseolus_limensis\",\n \"sieva_bean, butter_bean, butter-bean_plant, lima_bean, phaseolus_lunatus\",\n \"tepary_bean, phaseolus_acutifolius_latifolius\",\n \"chaparral_pea, stingaree-bush, pickeringia_montana\",\n \"jamaica_dogwood, fish_fuddle, piscidia_piscipula, piscidia_erythrina\",\n \"pea\",\n \"garden_pea\",\n \"edible-pod_pea, edible-podded_pea, pisum_sativum_macrocarpon\",\n \"sugar_snap_pea, snap_pea\",\n \"field_pea, field-pea_plant, austrian_winter_pea, pisum_sativum_arvense, pisum_arvense\",\n \"field_pea\",\n \"common_flat_pea, native_holly, playlobium_obtusangulum\",\n \"quira\",\n \"roble, platymiscium_trinitatis\",\n \"panama_redwood_tree, panama_redwood, platymiscium_pinnatum\",\n \"indian_beech, pongamia_glabra\",\n \"winged_bean, winged_pea, goa_bean, goa_bean_vine, manila_bean, psophocarpus_tetragonolobus\",\n \"breadroot, indian_breadroot, pomme_blanche, pomme_de_prairie, psoralea_esculenta\",\n \"bloodwood_tree, kiaat, pterocarpus_angolensis\",\n \"kino, pterocarpus_marsupium\",\n \"red_sandalwood, red_sanders, red_sanderswood, red_saunders, pterocarpus_santalinus\",\n \"kudzu, kudzu_vine, pueraria_lobata\",\n \"bristly_locust, rose_acacia, moss_locust, robinia_hispida\",\n \"black_locust, yellow_locust, robinia_pseudoacacia\",\n \"clammy_locust, robinia_viscosa\",\n \"carib_wood, sabinea_carinalis\",\n \"colorado_river_hemp, sesbania_exaltata\",\n \"scarlet_wisteria_tree, vegetable_hummingbird, sesbania_grandiflora\",\n \"japanese_pagoda_tree, chinese_scholartree, chinese_scholar_tree, sophora_japonica, sophora_sinensis\",\n \"mescal_bean, coral_bean, frijolito, frijolillo, sophora_secundiflora\",\n \"kowhai, sophora_tetraptera\",\n \"jade_vine, emerald_creeper, strongylodon_macrobotrys\",\n \"hoary_pea\",\n \"bastard_indigo, tephrosia_purpurea\",\n \"catgut, goat's_rue, wild_sweet_pea, tephrosia_virginiana\",\n \"bush_pea\",\n \"false_lupine, golden_pea, yellow_pea, thermopsis_macrophylla\",\n \"carolina_lupine, thermopsis_villosa\",\n \"tipu, tipu_tree, yellow_jacaranda, pride_of_bolivia\",\n \"bird's_foot_trefoil, trigonella_ornithopodioides\",\n \"fenugreek, greek_clover, trigonella_foenumgraecum\",\n \"gorse, furze, whin, irish_gorse, ulex_europaeus\",\n \"vetch\",\n \"tufted_vetch, bird_vetch, calnada_pea, vicia_cracca\",\n \"broad_bean, fava_bean, horsebean\",\n \"bitter_betch, vicia_orobus\",\n \"bush_vetch, vicia_sepium\",\n \"moth_bean, vigna_aconitifolia, phaseolus_aconitifolius\",\n \"snailflower, snail-flower, snail_flower, snail_bean, corkscrew_flower, vigna_caracalla, phaseolus_caracalla\",\n \"mung, mung_bean, green_gram, golden_gram, vigna_radiata, phaseolus_aureus\",\n \"cowpea, cowpea_plant, black-eyed_pea, vigna_unguiculata, vigna_sinensis\",\n \"cowpea, black-eyed_pea\",\n \"asparagus_bean, yard-long_bean, vigna_unguiculata_sesquipedalis, vigna_sesquipedalis\",\n \"swamp_oak, viminaria_juncea, viminaria_denudata\",\n \"keurboom, virgilia_capensis, virgilia_oroboides\",\n \"keurboom, virgilia_divaricata\",\n \"japanese_wistaria, wisteria_floribunda\",\n \"chinese_wistaria, wisteria_chinensis\",\n \"american_wistaria, american_wisteria, wisteria_frutescens\",\n \"silky_wisteria, wisteria_venusta\",\n \"palm, palm_tree\",\n \"sago_palm\",\n \"feather_palm\",\n \"fan_palm\",\n \"palmetto\",\n \"coyol, coyol_palm, acrocomia_vinifera\",\n \"grugru, gri-gri, grugru_palm, macamba, acrocomia_aculeata\",\n \"areca\",\n \"betel_palm, areca_catechu\",\n \"sugar_palm, gomuti, gomuti_palm, arenga_pinnata\",\n \"piassava_palm, pissaba_palm, bahia_piassava, bahia_coquilla, attalea_funifera\",\n \"coquilla_nut\",\n \"palmyra, palmyra_palm, toddy_palm, wine_palm, lontar, longar_palm, borassus_flabellifer\",\n \"calamus\",\n \"rattan, rattan_palm, calamus_rotang\",\n \"lawyer_cane, calamus_australis\",\n \"fishtail_palm\",\n \"wine_palm, jaggery_palm, kitul, kittul, kitul_tree, toddy_palm, caryota_urens\",\n \"wax_palm, ceroxylon_andicola, ceroxylon_alpinum\",\n \"coconut, coconut_palm, coco_palm, coco, cocoa_palm, coconut_tree, cocos_nucifera\",\n \"carnauba, carnauba_palm, wax_palm, copernicia_prunifera, copernicia_cerifera\",\n \"caranday, caranda, caranda_palm, wax_palm, copernicia_australis, copernicia_alba\",\n \"corozo, corozo_palm\",\n \"gebang_palm, corypha_utan, corypha_gebanga\",\n \"latanier, latanier_palm\",\n \"talipot, talipot_palm, corypha_umbraculifera\",\n \"oil_palm\",\n \"african_oil_palm, elaeis_guineensis\",\n \"american_oil_palm, elaeis_oleifera\",\n \"palm_nut, palm_kernel\",\n \"cabbage_palm, euterpe_oleracea\",\n \"cabbage_palm, cabbage_tree, livistona_australis\",\n \"true_sago_palm, metroxylon_sagu\",\n \"nipa_palm, nipa_fruticans\",\n \"babassu, babassu_palm, coco_de_macao, orbignya_phalerata, orbignya_spesiosa, orbignya_martiana\",\n \"babassu_nut\",\n \"cohune_palm, orbignya_cohune, cohune\",\n \"cohune_nut\",\n \"date_palm, phoenix_dactylifera\",\n \"ivory_palm, ivory-nut_palm, ivory_plant, phytelephas_macrocarpa\",\n \"raffia_palm, raffia_farinifera, raffia_ruffia\",\n \"bamboo_palm, raffia_vinifera\",\n \"lady_palm\",\n \"miniature_fan_palm, bamboo_palm, fern_rhapis, rhapis_excelsa\",\n \"reed_rhapis, slender_lady_palm, rhapis_humilis\",\n \"royal_palm, roystonea_regia\",\n \"cabbage_palm, roystonea_oleracea\",\n \"cabbage_palmetto, cabbage_palm, sabal_palmetto\",\n \"saw_palmetto, scrub_palmetto, serenoa_repens\",\n \"thatch_palm, thatch_tree, silver_thatch, broom_palm, thrinax_parviflora\",\n \"key_palm, silvertop_palmetto, silver_thatch, thrinax_microcarpa, thrinax_morrisii, thrinax_keyensis\",\n \"english_plantain, narrow-leaved_plantain, ribgrass, ribwort, ripple-grass, buckthorn, plantago_lanceolata\",\n \"broad-leaved_plantain, common_plantain, white-man's_foot, whiteman's_foot, cart-track_plant, plantago_major\",\n \"hoary_plantain, plantago_media\",\n \"fleawort, psyllium, spanish_psyllium, plantago_psyllium\",\n \"rugel's_plantain, broad-leaved_plantain, plantago_rugelii\",\n \"hoary_plantain, plantago_virginica\",\n \"buckwheat, polygonum_fagopyrum, fagopyrum_esculentum\",\n \"prince's-feather, princess_feather, kiss-me-over-the-garden-gate, prince's-plume, polygonum_orientale\",\n \"eriogonum\",\n \"umbrella_plant, eriogonum_allenii\",\n \"wild_buckwheat, california_buckwheat, erigonum_fasciculatum\",\n \"rhubarb, rhubarb_plant\",\n \"himalayan_rhubarb, indian_rhubarb, red-veined_pie_plant, rheum_australe, rheum_emodi\",\n \"pie_plant, garden_rhubarb, rheum_cultorum, rheum_rhabarbarum, rheum_rhaponticum\",\n \"chinese_rhubarb, rheum_palmatum\",\n \"sour_dock, garden_sorrel, rumex_acetosa\",\n \"sheep_sorrel, sheep's_sorrel, rumex_acetosella\",\n \"bitter_dock, broad-leaved_dock, yellow_dock, rumex_obtusifolius\",\n \"french_sorrel, garden_sorrel, rumex_scutatus\",\n \"yellow-eyed_grass\",\n \"commelina\",\n \"spiderwort, dayflower\",\n \"pineapple, pineapple_plant, ananas_comosus\",\n \"pipewort, eriocaulon_aquaticum\",\n \"water_hyacinth, water_orchid, eichhornia_crassipes, eichhornia_spesiosa\",\n \"water_star_grass, mud_plantain, heteranthera_dubia\",\n \"naiad, water_nymph\",\n \"water_plantain, alisma_plantago-aquatica\",\n \"narrow-leaved_water_plantain\",\n \"hydrilla, hydrilla_verticillata\",\n \"american_frogbit, limnodium_spongia\",\n \"waterweed\",\n \"canadian_pondweed, elodea_canadensis\",\n \"tape_grass, eelgrass, wild_celery, vallisneria_spiralis\",\n \"pondweed\",\n \"curled_leaf_pondweed, curly_pondweed, potamogeton_crispus\",\n \"loddon_pondweed, potamogeton_nodosus, potamogeton_americanus\",\n \"frog's_lettuce\",\n \"arrow_grass, triglochin_maritima\",\n \"horned_pondweed, zannichellia_palustris\",\n \"eelgrass, grass_wrack, sea_wrack, zostera_marina\",\n \"rose, rosebush\",\n \"hip, rose_hip, rosehip\",\n \"banksia_rose, rosa_banksia\",\n \"damask_rose, summer_damask_rose, rosa_damascena\",\n \"sweetbrier, sweetbriar, brier, briar, eglantine, rosa_eglanteria\",\n \"cherokee_rose, rosa_laevigata\",\n \"musk_rose, rosa_moschata\",\n \"agrimonia, agrimony\",\n \"harvest-lice, agrimonia_eupatoria\",\n \"fragrant_agrimony, agrimonia_procera\",\n \"alderleaf_juneberry, alder-leaved_serviceberry, amelanchier_alnifolia\",\n \"flowering_quince\",\n \"japonica, maule's_quince, chaenomeles_japonica\",\n \"coco_plum, coco_plum_tree, cocoa_plum, icaco, chrysobalanus_icaco\",\n \"cotoneaster\",\n \"cotoneaster_dammeri\",\n \"cotoneaster_horizontalis\",\n \"parsley_haw, parsley-leaved_thorn, crataegus_apiifolia, crataegus_marshallii\",\n \"scarlet_haw, crataegus_biltmoreana\",\n \"blackthorn, pear_haw, pear_hawthorn, crataegus_calpodendron, crataegus_tomentosa\",\n \"cockspur_thorn, cockspur_hawthorn, crataegus_crus-galli\",\n \"mayhaw, summer_haw, crataegus_aestivalis\",\n \"red_haw, downy_haw, crataegus_mollis, crataegus_coccinea_mollis\",\n \"red_haw, crataegus_pedicellata, crataegus_coccinea\",\n \"quince, quince_bush, cydonia_oblonga\",\n \"mountain_avens, dryas_octopetala\",\n \"loquat, loquat_tree, japanese_medlar, japanese_plum, eriobotrya_japonica\",\n \"beach_strawberry, chilean_strawberry, fragaria_chiloensis\",\n \"virginia_strawberry, scarlet_strawberry, fragaria_virginiana\",\n \"avens\",\n \"yellow_avens, geum_alleppicum_strictum, geum_strictum\",\n \"yellow_avens, geum_macrophyllum\",\n \"prairie_smoke, purple_avens, geum_triflorum\",\n \"bennet, white_avens, geum_virginianum\",\n \"toyon, tollon, christmasberry, christmas_berry, heteromeles_arbutifolia, photinia_arbutifolia\",\n \"apple_tree\",\n \"apple, orchard_apple_tree, malus_pumila\",\n \"wild_apple, crab_apple, crabapple\",\n \"crab_apple, crabapple, cultivated_crab_apple\",\n \"siberian_crab, siberian_crab_apple, cherry_apple, cherry_crab, malus_baccata\",\n \"wild_crab, malus_sylvestris\",\n \"american_crab_apple, garland_crab, malus_coronaria\",\n \"oregon_crab_apple, malus_fusca\",\n \"southern_crab_apple, flowering_crab, malus_angustifolia\",\n \"iowa_crab, iowa_crab_apple, prairie_crab, western_crab_apple, malus_ioensis\",\n \"bechtel_crab, flowering_crab\",\n \"medlar, medlar_tree, mespilus_germanica\",\n \"cinquefoil, five-finger\",\n \"silverweed, goose-tansy, goose_grass, potentilla_anserina\",\n \"salad_burnet, burnet_bloodwort, pimpernel, poterium_sanguisorba\",\n \"plum, plum_tree\",\n \"wild_plum, wild_plum_tree\",\n \"allegheny_plum, alleghany_plum, sloe, prunus_alleghaniensis\",\n \"american_red_plum, august_plum, goose_plum, prunus_americana\",\n \"chickasaw_plum, hog_plum, hog_plum_bush, prunus_angustifolia\",\n \"beach_plum, beach_plum_bush, prunus_maritima\",\n \"common_plum, prunus_domestica\",\n \"bullace, prunus_insititia\",\n \"damson_plum, damson_plum_tree, prunus_domestica_insititia\",\n \"big-tree_plum, prunus_mexicana\",\n \"canada_plum, prunus_nigra\",\n \"plumcot, plumcot_tree\",\n \"apricot, apricot_tree\",\n \"japanese_apricot, mei, prunus_mume\",\n \"common_apricot, prunus_armeniaca\",\n \"purple_apricot, black_apricot, prunus_dasycarpa\",\n \"cherry, cherry_tree\",\n \"wild_cherry, wild_cherry_tree\",\n \"wild_cherry\",\n \"sweet_cherry, prunus_avium\",\n \"heart_cherry, oxheart, oxheart_cherry\",\n \"gean, mazzard, mazzard_cherry\",\n \"capulin, capulin_tree, prunus_capuli\",\n \"cherry_laurel, laurel_cherry, mock_orange, wild_orange, prunus_caroliniana\",\n \"cherry_plum, myrobalan, myrobalan_plum, prunus_cerasifera\",\n \"sour_cherry, sour_cherry_tree, prunus_cerasus\",\n \"amarelle, prunus_cerasus_caproniana\",\n \"morello, prunus_cerasus_austera\",\n \"marasca\",\n \"almond_tree\",\n \"almond, sweet_almond, prunus_dulcis, prunus_amygdalus, amygdalus_communis\",\n \"bitter_almond, prunus_dulcis_amara, amygdalus_communis_amara\",\n \"jordan_almond\",\n \"dwarf_flowering_almond, prunus_glandulosa\",\n \"holly-leaved_cherry, holly-leaf_cherry, evergreen_cherry, islay, prunus_ilicifolia\",\n \"fuji, fuji_cherry, prunus_incisa\",\n \"flowering_almond, oriental_bush_cherry, prunus_japonica\",\n \"cherry_laurel, laurel_cherry, prunus_laurocerasus\",\n \"catalina_cherry, prunus_lyonii\",\n \"bird_cherry, bird_cherry_tree\",\n \"hagberry_tree, european_bird_cherry, common_bird_cherry, prunus_padus\",\n \"hagberry\",\n \"pin_cherry, prunus_pensylvanica\",\n \"peach, peach_tree, prunus_persica\",\n \"nectarine, nectarine_tree, prunus_persica_nectarina\",\n \"sand_cherry, prunus_pumila, prunus_pumilla_susquehanae, prunus_susquehanae, prunus_cuneata\",\n \"japanese_plum, prunus_salicina\",\n \"black_cherry, black_cherry_tree, rum_cherry, prunus_serotina\",\n \"flowering_cherry\",\n \"oriental_cherry, japanese_cherry, japanese_flowering_cherry, prunus_serrulata\",\n \"japanese_flowering_cherry, prunus_sieboldii\",\n \"sierra_plum, pacific_plum, prunus_subcordata\",\n \"rosebud_cherry, winter_flowering_cherry, prunus_subhirtella\",\n \"russian_almond, dwarf_russian_almond, prunus_tenella\",\n \"flowering_almond, prunus_triloba\",\n \"chokecherry, chokecherry_tree, prunus_virginiana\",\n \"chokecherry\",\n \"western_chokecherry, prunus_virginiana_demissa, prunus_demissa\",\n \"pyracantha, pyracanth, fire_thorn, firethorn\",\n \"pear, pear_tree, pyrus_communis\",\n \"fruit_tree\",\n \"bramble_bush\",\n \"lawyerbush, lawyer_bush, bush_lawyer, rubus_cissoides, rubus_australis\",\n \"stone_bramble, rubus_saxatilis\",\n \"sand_blackberry, rubus_cuneifolius\",\n \"boysenberry, boysenberry_bush\",\n \"loganberry, rubus_loganobaccus, rubus_ursinus_loganobaccus\",\n \"american_dewberry, rubus_canadensis\",\n \"northern_dewberry, american_dewberry, rubus_flagellaris\",\n \"southern_dewberry, rubus_trivialis\",\n \"swamp_dewberry, swamp_blackberry, rubus_hispidus\",\n \"european_dewberry, rubus_caesius\",\n \"raspberry, raspberry_bush\",\n \"wild_raspberry, european_raspberry, framboise, rubus_idaeus\",\n \"american_raspberry, rubus_strigosus, rubus_idaeus_strigosus\",\n \"black_raspberry, blackcap, blackcap_raspberry, thimbleberry, rubus_occidentalis\",\n \"salmonberry, rubus_spectabilis\",\n \"salmonberry, salmon_berry, thimbleberry, rubus_parviflorus\",\n \"wineberry, rubus_phoenicolasius\",\n \"mountain_ash\",\n \"rowan, rowan_tree, european_mountain_ash, sorbus_aucuparia\",\n \"rowanberry\",\n \"american_mountain_ash, sorbus_americana\",\n \"western_mountain_ash, sorbus_sitchensis\",\n \"service_tree, sorb_apple, sorb_apple_tree, sorbus_domestica\",\n \"wild_service_tree, sorbus_torminalis\",\n \"spirea, spiraea\",\n \"bridal_wreath, bridal-wreath, saint_peter's_wreath, st._peter's_wreath, spiraea_prunifolia\",\n \"madderwort, rubiaceous_plant\",\n \"indian_madder, munjeet, rubia_cordifolia\",\n \"madder, rubia_tinctorum\",\n \"woodruff\",\n \"dagame, lemonwood_tree, calycophyllum_candidissimum\",\n \"blolly, west_indian_snowberry, chiococca_alba\",\n \"coffee, coffee_tree\",\n \"arabian_coffee, coffea_arabica\",\n \"liberian_coffee, coffea_liberica\",\n \"robusta_coffee, rio_nunez_coffee, coffea_robusta, coffea_canephora\",\n \"cinchona, chinchona\",\n \"cartagena_bark, cinchona_cordifolia, cinchona_lancifolia\",\n \"calisaya, cinchona_officinalis, cinchona_ledgeriana, cinchona_calisaya\",\n \"cinchona_tree, cinchona_pubescens\",\n \"cinchona, cinchona_bark, peruvian_bark, jesuit's_bark\",\n \"bedstraw\",\n \"sweet_woodruff, waldmeister, woodruff, fragrant_bedstraw, galium_odoratum, asperula_odorata\",\n \"northern_bedstraw, northern_snow_bedstraw, galium_boreale\",\n \"yellow_bedstraw, yellow_cleavers, our_lady's_bedstraw, galium_verum\",\n \"wild_licorice, galium_lanceolatum\",\n \"cleavers, clivers, goose_grass, catchweed, spring_cleavers, galium_aparine\",\n \"wild_madder, white_madder, white_bedstraw, infant's-breath, false_baby's_breath, galium_mollugo\",\n \"cape_jasmine, cape_jessamine, gardenia_jasminoides, gardenia_augusta\",\n \"genipa\",\n \"genipap_fruit, jagua, marmalade_box, genipa_americana\",\n \"hamelia\",\n \"scarlet_bush, scarlet_hamelia, coloradillo, hamelia_patens, hamelia_erecta\",\n \"lemonwood, lemon-wood, lemonwood_tree, lemon-wood_tree, psychotria_capensis\",\n \"negro_peach, sarcocephalus_latifolius, sarcocephalus_esculentus\",\n \"wild_medlar, wild_medlar_tree, medlar, vangueria_infausta\",\n \"spanish_tamarind, vangueria_madagascariensis\",\n \"abelia\",\n \"bush_honeysuckle, diervilla_sessilifolia\",\n \"american_twinflower, linnaea_borealis_americana\",\n \"honeysuckle\",\n \"american_fly_honeysuckle, fly_honeysuckle, lonicera_canadensis\",\n \"italian_honeysuckle, italian_woodbine, lonicera_caprifolium\",\n \"yellow_honeysuckle, lonicera_flava\",\n \"hairy_honeysuckle, lonicera_hirsuta\",\n \"japanese_honeysuckle, lonicera_japonica\",\n \"hall's_honeysuckle, lonicera_japonica_halliana\",\n \"morrow's_honeysuckle, lonicera_morrowii\",\n \"woodbine, lonicera_periclymenum\",\n \"trumpet_honeysuckle, coral_honeysuckle, trumpet_flower, trumpet_vine, lonicera_sempervirens\",\n \"european_fly_honeysuckle, european_honeysuckle, lonicera_xylosteum\",\n \"swamp_fly_honeysuckle\",\n \"snowberry, common_snowberry, waxberry, symphoricarpos_alba\",\n \"coralberry, indian_currant, symphoricarpos_orbiculatus\",\n \"blue_elder, blue_elderberry, sambucus_caerulea\",\n \"dwarf_elder, danewort, sambucus_ebulus\",\n \"american_red_elder, red-berried_elder, stinking_elder, sambucus_pubens\",\n \"european_red_elder, red-berried_elder, sambucus_racemosa\",\n \"feverroot, horse_gentian, tinker's_root, wild_coffee, triostium_perfoliatum\",\n \"cranberry_bush, cranberry_tree, american_cranberry_bush, highbush_cranberry, viburnum_trilobum\",\n \"wayfaring_tree, twist_wood, twistwood, viburnum_lantana\",\n \"guelder_rose, european_cranberrybush, european_cranberry_bush, crampbark, cranberry_tree, viburnum_opulus\",\n \"arrow_wood, viburnum_recognitum\",\n \"black_haw, viburnum_prunifolium\",\n \"weigela, weigela_florida\",\n \"teasel, teazel, teasle\",\n \"common_teasel, dipsacus_fullonum\",\n \"fuller's_teasel, dipsacus_sativus\",\n \"wild_teasel, dipsacus_sylvestris\",\n \"scabious, scabiosa\",\n \"sweet_scabious, pincushion_flower, mournful_widow, scabiosa_atropurpurea\",\n \"field_scabious, scabiosa_arvensis\",\n \"jewelweed, lady's_earrings, orange_balsam, celandine, touch-me-not, impatiens_capensis\",\n \"geranium\",\n \"cranesbill, crane's_bill\",\n \"wild_geranium, spotted_cranesbill, geranium_maculatum\",\n \"meadow_cranesbill, geranium_pratense\",\n \"richardson's_geranium, geranium_richardsonii\",\n \"herb_robert, herbs_robert, herb_roberts, geranium_robertianum\",\n \"sticky_geranium, geranium_viscosissimum\",\n \"dove's_foot_geranium, geranium_molle\",\n \"rose_geranium, sweet-scented_geranium, pelargonium_graveolens\",\n \"fish_geranium, bedding_geranium, zonal_pelargonium, pelargonium_hortorum\",\n \"ivy_geranium, ivy-leaved_geranium, hanging_geranium, pelargonium_peltatum\",\n \"apple_geranium, nutmeg_geranium, pelargonium_odoratissimum\",\n \"lemon_geranium, pelargonium_limoneum\",\n \"storksbill, heron's_bill\",\n \"musk_clover, muskus_grass, white-stemmed_filaree, erodium_moschatum\",\n \"incense_tree\",\n \"elephant_tree, bursera_microphylla\",\n \"gumbo-limbo, bursera_simaruba\",\n \"boswellia_carteri\",\n \"salai, boswellia_serrata\",\n \"balm_of_gilead, commiphora_meccanensis\",\n \"myrrh_tree, commiphora_myrrha\",\n \"protium_heptaphyllum\",\n \"protium_guianense\",\n \"water_starwort\",\n \"barbados_cherry, acerola, surinam_cherry, west_indian_cherry, malpighia_glabra\",\n \"mahogany, mahogany_tree\",\n \"chinaberry, chinaberry_tree, china_tree, persian_lilac, pride-of-india, azederach, azedarach, melia_azederach, melia_azedarach\",\n \"neem, neem_tree, nim_tree, margosa, arishth, azadirachta_indica, melia_azadirachta\",\n \"neem_seed\",\n \"spanish_cedar, spanish_cedar_tree, cedrela_odorata\",\n \"satinwood, satinwood_tree, chloroxylon_swietenia\",\n \"african_scented_mahogany, cedar_mahogany, sapele_mahogany, entandrophragma_cylindricum\",\n \"silver_ash\",\n \"native_beech, flindosa, flindosy, flindersia_australis\",\n \"bunji-bunji, flindersia_schottiana\",\n \"african_mahogany\",\n \"lanseh_tree, langsat, langset, lansium_domesticum\",\n \"true_mahogany, cuban_mahogany, dominican_mahogany, swietinia_mahogani\",\n \"honduras_mahogany, swietinia_macrophylla\",\n \"philippine_mahogany, philippine_cedar, kalantas, toona_calantas, cedrela_calantas\",\n \"caracolito, ruptiliocarpon_caracolito\",\n \"common_wood_sorrel, cuckoo_bread, shamrock, oxalis_acetosella\",\n \"bermuda_buttercup, english-weed, oxalis_pes-caprae, oxalis_cernua\",\n \"creeping_oxalis, creeping_wood_sorrel, oxalis_corniculata\",\n \"goatsfoot, goat's_foot, oxalis_caprina\",\n \"violet_wood_sorrel, oxalis_violacea\",\n \"oca, oka, oxalis_tuberosa, oxalis_crenata\",\n \"carambola, carambola_tree, averrhoa_carambola\",\n \"bilimbi, averrhoa_bilimbi\",\n \"milkwort\",\n \"senega, polygala_alba\",\n \"orange_milkwort, yellow_milkwort, candyweed, yellow_bachelor's_button, polygala_lutea\",\n \"flowering_wintergreen, gaywings, bird-on-the-wing, fringed_polygala, polygala_paucifolia\",\n \"seneca_snakeroot, seneka_snakeroot, senga_root, senega_root, senega_snakeroot, polygala_senega\",\n \"common_milkwort, gand_flower, polygala_vulgaris\",\n \"rue, herb_of_grace, ruta_graveolens\",\n \"citrus, citrus_tree\",\n \"orange, orange_tree\",\n \"sour_orange, seville_orange, bitter_orange, bitter_orange_tree, bigarade, marmalade_orange, citrus_aurantium\",\n \"bergamot, bergamot_orange, citrus_bergamia\",\n \"pomelo, pomelo_tree, pummelo, shaddock, citrus_maxima, citrus_grandis, citrus_decumana\",\n \"citron, citron_tree, citrus_medica\",\n \"grapefruit, citrus_paradisi\",\n \"mandarin, mandarin_orange, mandarin_orange_tree, citrus_reticulata\",\n \"tangerine, tangerine_tree\",\n \"clementine, clementine_tree\",\n \"satsuma, satsuma_tree\",\n \"sweet_orange, sweet_orange_tree, citrus_sinensis\",\n \"temple_orange, temple_orange_tree, tangor, king_orange, citrus_nobilis\",\n \"tangelo, tangelo_tree, ugli_fruit, citrus_tangelo\",\n \"rangpur, rangpur_lime, lemanderin, citrus_limonia\",\n \"lemon, lemon_tree, citrus_limon\",\n \"sweet_lemon, sweet_lime, citrus_limetta\",\n \"lime, lime_tree, citrus_aurantifolia\",\n \"citrange, citrange_tree, citroncirus_webberi\",\n \"fraxinella, dittany, burning_bush, gas_plant, dictamnus_alba\",\n \"kumquat, cumquat, kumquat_tree\",\n \"marumi, marumi_kumquat, round_kumquat, fortunella_japonica\",\n \"nagami, nagami_kumquat, oval_kumquat, fortunella_margarita\",\n \"cork_tree, phellodendron_amurense\",\n \"trifoliate_orange, trifoliata, wild_orange, poncirus_trifoliata\",\n \"prickly_ash\",\n \"toothache_tree, sea_ash, zanthoxylum_americanum, zanthoxylum_fraxineum\",\n \"hercules'-club, hercules'-clubs, hercules-club, zanthoxylum_clava-herculis\",\n \"bitterwood_tree\",\n \"marupa, simarouba_amara\",\n \"paradise_tree, bitterwood, simarouba_glauca\",\n \"ailanthus\",\n \"tree_of_heaven, tree_of_the_gods, ailanthus_altissima\",\n \"wild_mango, dika, wild_mango_tree, irvingia_gabonensis\",\n \"pepper_tree, kirkia_wilmsii\",\n \"jamaica_quassia, bitterwood, picrasma_excelsa, picrasma_excelsum\",\n \"quassia, bitterwood, quassia_amara\",\n \"nasturtium\",\n \"garden_nasturtium, indian_cress, tropaeolum_majus\",\n \"bush_nasturtium, tropaeolum_minus\",\n \"canarybird_flower, canarybird_vine, canary_creeper, tropaeolum_peregrinum\",\n \"bean_caper, syrian_bean_caper, zygophyllum_fabago\",\n \"palo_santo, bulnesia_sarmienti\",\n \"lignum_vitae, guaiacum_officinale\",\n \"creosote_bush, coville, hediondilla, larrea_tridentata\",\n \"caltrop, devil's_weed, tribulus_terestris\",\n \"willow, willow_tree\",\n \"osier\",\n \"white_willow, huntingdon_willow, salix_alba\",\n \"silver_willow, silky_willow, salix_alba_sericea, salix_sericea\",\n \"golden_willow, salix_alba_vitellina, salix_vitellina\",\n \"cricket-bat_willow, salix_alba_caerulea\",\n \"arctic_willow, salix_arctica\",\n \"weeping_willow, babylonian_weeping_willow, salix_babylonica\",\n \"wisconsin_weeping_willow, salix_pendulina, salix_blanda, salix_pendulina_blanda\",\n \"pussy_willow, salix_discolor\",\n \"sallow\",\n \"goat_willow, florist's_willow, pussy_willow, salix_caprea\",\n \"peachleaf_willow, peach-leaved_willow, almond-leaves_willow, salix_amygdaloides\",\n \"almond_willow, black_hollander, salix_triandra, salix_amygdalina\",\n \"hoary_willow, sage_willow, salix_candida\",\n \"crack_willow, brittle_willow, snap_willow, salix_fragilis\",\n \"prairie_willow, salix_humilis\",\n \"dwarf_willow, salix_herbacea\",\n \"grey_willow, gray_willow, salix_cinerea\",\n \"arroyo_willow, salix_lasiolepis\",\n \"shining_willow, salix_lucida\",\n \"swamp_willow, black_willow, salix_nigra\",\n \"bay_willow, laurel_willow, salix_pentandra\",\n \"purple_willow, red_willow, red_osier, basket_willow, purple_osier, salix_purpurea\",\n \"balsam_willow, salix_pyrifolia\",\n \"creeping_willow, salix_repens\",\n \"sitka_willow, silky_willow, salix_sitchensis\",\n \"dwarf_grey_willow, dwarf_gray_willow, sage_willow, salix_tristis\",\n \"bearberry_willow, salix_uva-ursi\",\n \"common_osier, hemp_willow, velvet_osier, salix_viminalis\",\n \"poplar, poplar_tree\",\n \"balsam_poplar, hackmatack, tacamahac, populus_balsamifera\",\n \"white_poplar, white_aspen, abele, aspen_poplar, silver-leaved_poplar, populus_alba\",\n \"grey_poplar, gray_poplar, populus_canescens\",\n \"black_poplar, populus_nigra\",\n \"lombardy_poplar, populus_nigra_italica\",\n \"cottonwood\",\n \"eastern_cottonwood, necklace_poplar, populus_deltoides\",\n \"black_cottonwood, western_balsam_poplar, populus_trichocarpa\",\n \"swamp_cottonwood, black_cottonwood, downy_poplar, swamp_poplar, populus_heterophylla\",\n \"aspen\",\n \"quaking_aspen, european_quaking_aspen, populus_tremula\",\n \"american_quaking_aspen, american_aspen, populus_tremuloides\",\n \"canadian_aspen, bigtooth_aspen, bigtoothed_aspen, big-toothed_aspen, large-toothed_aspen, large_tooth_aspen, populus_grandidentata\",\n \"sandalwood_tree, true_sandalwood, santalum_album\",\n \"quandong, quandang, quandong_tree, eucarya_acuminata, fusanus_acuminatus\",\n \"rabbitwood, buffalo_nut, pyrularia_pubera\",\n \"loranthaceae, family_loranthaceae, mistletoe_family\",\n \"mistletoe, loranthus_europaeus\",\n \"american_mistletoe, arceuthobium_pusillum\",\n \"mistletoe, viscum_album, old_world_mistletoe\",\n \"american_mistletoe, phoradendron_serotinum, phoradendron_flavescens\",\n \"aalii\",\n \"soapberry, soapberry_tree\",\n \"wild_china_tree, sapindus_drumondii, sapindus_marginatus\",\n \"china_tree, false_dogwood, jaboncillo, chinaberry, sapindus_saponaria\",\n \"akee, akee_tree, blighia_sapida\",\n \"soapberry_vine\",\n \"heartseed, cardiospermum_grandiflorum\",\n \"balloon_vine, heart_pea, cardiospermum_halicacabum\",\n \"longan, lungen, longanberry, dimocarpus_longan, euphorbia_litchi, nephelium_longana\",\n \"harpullia\",\n \"harpulla, harpullia_cupanioides\",\n \"moreton_bay_tulipwood, harpullia_pendula\",\n \"litchi, lichee, litchi_tree, litchi_chinensis, nephelium_litchi\",\n \"spanish_lime, spanish_lime_tree, honey_berry, mamoncillo, genip, ginep, melicocca_bijuga, melicocca_bijugatus\",\n \"rambutan, rambotan, rambutan_tree, nephelium_lappaceum\",\n \"pulasan, pulassan, pulasan_tree, nephelium_mutabile\",\n \"pachysandra\",\n \"allegheny_spurge, allegheny_mountain_spurge, pachysandra_procumbens\",\n \"bittersweet, american_bittersweet, climbing_bittersweet, false_bittersweet, staff_vine, waxwork, shrubby_bittersweet, celastrus_scandens\",\n \"spindle_tree, spindleberry, spindleberry_tree\",\n \"winged_spindle_tree, euonymous_alatus\",\n \"wahoo, burning_bush, euonymus_atropurpureus\",\n \"strawberry_bush, wahoo, euonymus_americanus\",\n \"evergreen_bittersweet, euonymus_fortunei_radicans, euonymus_radicans_vegetus\",\n \"cyrilla, leatherwood, white_titi, cyrilla_racemiflora\",\n \"titi, buckwheat_tree, cliftonia_monophylla\",\n \"crowberry\",\n \"maple\",\n \"silver_maple, acer_saccharinum\",\n \"sugar_maple, rock_maple, acer_saccharum\",\n \"red_maple, scarlet_maple, swamp_maple, acer_rubrum\",\n \"moosewood, moose-wood, striped_maple, striped_dogwood, goosefoot_maple, acer_pennsylvanicum\",\n \"oregon_maple, big-leaf_maple, acer_macrophyllum\",\n \"dwarf_maple, rocky-mountain_maple, acer_glabrum\",\n \"mountain_maple, mountain_alder, acer_spicatum\",\n \"vine_maple, acer_circinatum\",\n \"hedge_maple, field_maple, acer_campestre\",\n \"norway_maple, acer_platanoides\",\n \"sycamore, great_maple, scottish_maple, acer_pseudoplatanus\",\n \"box_elder, ash-leaved_maple, acer_negundo\",\n \"california_box_elder, acer_negundo_californicum\",\n \"pointed-leaf_maple, acer_argutum\",\n \"japanese_maple, full_moon_maple, acer_japonicum\",\n \"japanese_maple, acer_palmatum\",\n \"holly\",\n \"chinese_holly, ilex_cornuta\",\n \"bearberry, possum_haw, winterberry, ilex_decidua\",\n \"inkberry, gallberry, gall-berry, evergreen_winterberry, ilex_glabra\",\n \"mate, paraguay_tea, ilex_paraguariensis\",\n \"american_holly, christmas_holly\",\n \"low_gallberry_holly\",\n \"tall_gallberry_holly\",\n \"yaupon_holly\",\n \"deciduous_holly\",\n \"juneberry_holly\",\n \"largeleaf_holly\",\n \"geogia_holly\",\n \"common_winterberry_holly\",\n \"smooth_winterberry_holly\",\n \"cashew, cashew_tree, anacardium_occidentale\",\n \"goncalo_alves, astronium_fraxinifolium\",\n \"venetian_sumac, wig_tree, cotinus_coggygria\",\n \"laurel_sumac, malosma_laurina, rhus_laurina\",\n \"mango, mango_tree, mangifera_indica\",\n \"pistachio, pistacia_vera, pistachio_tree\",\n \"terebinth, pistacia_terebinthus\",\n \"mastic, mastic_tree, lentisk, pistacia_lentiscus\",\n \"australian_sumac, rhodosphaera_rhodanthema, rhus_rhodanthema\",\n \"sumac, sumach, shumac\",\n \"smooth_sumac, scarlet_sumac, vinegar_tree, rhus_glabra\",\n \"sugar-bush, sugar_sumac, rhus_ovata\",\n \"staghorn_sumac, velvet_sumac, virginian_sumac, vinegar_tree, rhus_typhina\",\n \"squawbush, squaw-bush, skunkbush, rhus_trilobata\",\n \"aroeira_blanca, schinus_chichita\",\n \"pepper_tree, molle, peruvian_mastic_tree, schinus_molle\",\n \"brazilian_pepper_tree, schinus_terebinthifolius\",\n \"hog_plum, yellow_mombin, yellow_mombin_tree, spondias_mombin\",\n \"mombin, mombin_tree, jocote, spondias_purpurea\",\n \"poison_ash, poison_dogwood, poison_sumac, toxicodendron_vernix, rhus_vernix\",\n \"poison_ivy, markweed, poison_mercury, poison_oak, toxicodendron_radicans, rhus_radicans\",\n \"western_poison_oak, toxicodendron_diversilobum, rhus_diversiloba\",\n \"eastern_poison_oak, toxicodendron_quercifolium, rhus_quercifolia, rhus_toxicodenedron\",\n \"varnish_tree, lacquer_tree, chinese_lacquer_tree, japanese_lacquer_tree, japanese_varnish_tree, japanese_sumac, toxicodendron_vernicifluum, rhus_verniciflua\",\n \"horse_chestnut, buckeye, aesculus_hippocastanum\",\n \"buckeye, horse_chestnut, conker\",\n \"sweet_buckeye\",\n \"ohio_buckeye\",\n \"dwarf_buckeye, bottlebrush_buckeye\",\n \"red_buckeye\",\n \"particolored_buckeye\",\n \"ebony, ebony_tree, diospyros_ebenum\",\n \"marblewood, marble-wood, andaman_marble, diospyros_kurzii\",\n \"marblewood, marble-wood\",\n \"persimmon, persimmon_tree\",\n \"japanese_persimmon, kaki, diospyros_kaki\",\n \"american_persimmon, possumwood, diospyros_virginiana\",\n \"date_plum, diospyros_lotus\",\n \"buckthorn\",\n \"southern_buckthorn, shittimwood, shittim, mock_orange, bumelia_lycioides\",\n \"false_buckthorn, chittamwood, chittimwood, shittimwood, black_haw, bumelia_lanuginosa\",\n \"star_apple, caimito, chrysophyllum_cainito\",\n \"satinleaf, satin_leaf, caimitillo, damson_plum, chrysophyllum_oliviforme\",\n \"balata, balata_tree, beefwood, bully_tree, manilkara_bidentata\",\n \"sapodilla, sapodilla_tree, manilkara_zapota, achras_zapota\",\n \"gutta-percha_tree, palaquium_gutta\",\n \"gutta-percha_tree\",\n \"canistel, canistel_tree, pouteria_campechiana_nervosa\",\n \"marmalade_tree, mammee, sapote, pouteria_zapota, calocarpum_zapota\",\n \"sweetleaf, symplocus_tinctoria\",\n \"asiatic_sweetleaf, sapphire_berry, symplocus_paniculata\",\n \"styrax\",\n \"snowbell, styrax_obassia\",\n \"japanese_snowbell, styrax_japonicum\",\n \"texas_snowbell, texas_snowbells, styrax_texana\",\n \"silver-bell_tree, silverbell_tree, snowdrop_tree, opossum_wood, halesia_carolina, halesia_tetraptera\",\n \"carnivorous_plant\",\n \"pitcher_plant\",\n \"common_pitcher_plant, huntsman's_cup, huntsman's_cups, sarracenia_purpurea\",\n \"hooded_pitcher_plant, sarracenia_minor\",\n \"huntsman's_horn, huntsman's_horns, yellow_trumpet, yellow_pitcher_plant, trumpets, sarracenia_flava\",\n \"tropical_pitcher_plant\",\n \"sundew, sundew_plant, daily_dew\",\n \"venus's_flytrap, venus's_flytraps, dionaea_muscipula\",\n \"waterwheel_plant, aldrovanda_vesiculosa\",\n \"drosophyllum_lusitanicum\",\n \"roridula\",\n \"australian_pitcher_plant, cephalotus_follicularis\",\n \"sedum\",\n \"stonecrop\",\n \"rose-root, midsummer-men, sedum_rosea\",\n \"orpine, orpin, livelong, live-forever, sedum_telephium\",\n \"pinwheel, aeonium_haworthii\",\n \"christmas_bush, christmas_tree, ceratopetalum_gummiferum\",\n \"hortensia, hydrangea_macrophylla_hortensis\",\n \"fall-blooming_hydrangea, hydrangea_paniculata\",\n \"carpenteria, carpenteria_californica\",\n \"decumary, decumaria_barbata, decumaria_barbara\",\n \"deutzia\",\n \"philadelphus\",\n \"mock_orange, syringa, philadelphus_coronarius\",\n \"saxifrage, breakstone, rockfoil\",\n \"yellow_mountain_saxifrage, saxifraga_aizoides\",\n \"meadow_saxifrage, fair-maids-of-france, saxifraga_granulata\",\n \"mossy_saxifrage, saxifraga_hypnoides\",\n \"western_saxifrage, saxifraga_occidentalis\",\n \"purple_saxifrage, saxifraga_oppositifolia\",\n \"star_saxifrage, starry_saxifrage, saxifraga_stellaris\",\n \"strawberry_geranium, strawberry_saxifrage, mother-of-thousands, saxifraga_stolonifera, saxifraga_sarmentosam\",\n \"astilbe\",\n \"false_goatsbeard, astilbe_biternata\",\n \"dwarf_astilbe, astilbe_chinensis_pumila\",\n \"spirea, spiraea, astilbe_japonica\",\n \"bergenia\",\n \"coast_boykinia, boykinia_elata, boykinia_occidentalis\",\n \"golden_saxifrage, golden_spleen\",\n \"umbrella_plant, indian_rhubarb, darmera_peltata, peltiphyllum_peltatum\",\n \"bridal_wreath, bridal-wreath, francoa_ramosa\",\n \"alumroot, alumbloom\",\n \"coralbells, heuchera_sanguinea\",\n \"leatherleaf_saxifrage, leptarrhena_pyrolifolia\",\n \"woodland_star, lithophragma_affine, lithophragma_affinis, tellima_affinis\",\n \"prairie_star, lithophragma_parviflorum\",\n \"miterwort, mitrewort, bishop's_cap\",\n \"five-point_bishop's_cap, mitella_pentandra\",\n \"parnassia, grass-of-parnassus\",\n \"bog_star, parnassia_palustris\",\n \"fringed_grass_of_parnassus, parnassia_fimbriata\",\n \"false_alumroot, fringe_cups, tellima_grandiflora\",\n \"foamflower, coolwart, false_miterwort, false_mitrewort, tiarella_cordifolia\",\n \"false_miterwort, false_mitrewort, tiarella_unifoliata\",\n \"pickaback_plant, piggyback_plant, youth-on-age, tolmiea_menziesii\",\n \"currant, currant_bush\",\n \"black_currant, european_black_currant, ribes_nigrum\",\n \"white_currant, ribes_sativum\",\n \"gooseberry, gooseberry_bush, ribes_uva-crispa, ribes_grossularia\",\n \"plane_tree, sycamore, platan\",\n \"london_plane, platanus_acerifolia\",\n \"american_sycamore, american_plane, buttonwood, platanus_occidentalis\",\n \"oriental_plane, platanus_orientalis\",\n \"california_sycamore, platanus_racemosa\",\n \"arizona_sycamore, platanus_wrightii\",\n \"greek_valerian, polemonium_reptans\",\n \"northern_jacob's_ladder, polemonium_boreale\",\n \"skunkweed, skunk-weed, polemonium_viscosum\",\n \"phlox\",\n \"moss_pink, mountain_phlox, moss_phlox, dwarf_phlox, phlox_subulata\",\n \"evening-snow, linanthus_dichotomus\",\n \"acanthus\",\n \"bear's_breech, bear's_breeches, sea_holly, acanthus_mollis\",\n \"caricature_plant, graptophyllum_pictum\",\n \"black-eyed_susan, black-eyed_susan_vine, thunbergia_alata\",\n \"catalpa, indian_bean\",\n \"catalpa_bignioides\",\n \"catalpa_speciosa\",\n \"desert_willow, chilopsis_linearis\",\n \"calabash, calabash_tree, crescentia_cujete\",\n \"calabash\",\n \"borage, tailwort, borago_officinalis\",\n \"common_amsinckia, amsinckia_intermedia\",\n \"anchusa\",\n \"bugloss, alkanet, anchusa_officinalis\",\n \"cape_forget-me-not, anchusa_capensis\",\n \"cape_forget-me-not, anchusa_riparia\",\n \"spanish_elm, equador_laurel, salmwood, cypre, princewood, cordia_alliodora\",\n \"princewood, spanish_elm, cordia_gerascanthus\",\n \"chinese_forget-me-not, cynoglossum_amabile\",\n \"hound's-tongue, cynoglossum_officinale\",\n \"hound's-tongue, cynoglossum_virginaticum\",\n \"blueweed, blue_devil, blue_thistle, viper's_bugloss, echium_vulgare\",\n \"beggar's_lice, beggar_lice\",\n \"gromwell, lithospermum_officinale\",\n \"puccoon, lithospermum_caroliniense\",\n \"virginia_bluebell, virginia_cowslip, mertensia_virginica\",\n \"garden_forget-me-not, myosotis_sylvatica\",\n \"forget-me-not, mouse_ear, myosotis_scorpiodes\",\n \"false_gromwell\",\n \"comfrey, cumfrey\",\n \"common_comfrey, boneset, symphytum_officinale\",\n \"convolvulus\",\n \"bindweed\",\n \"field_bindweed, wild_morning-glory, convolvulus_arvensis\",\n \"scammony, convolvulus_scammonia\",\n \"silverweed\",\n \"dodder\",\n \"dichondra, dichondra_micrantha\",\n \"cypress_vine, star-glory, indian_pink, ipomoea_quamoclit, quamoclit_pennata\",\n \"moonflower, belle_de_nuit, ipomoea_alba\",\n \"wild_potato_vine, wild_sweet_potato_vine, man-of-the-earth, manroot, scammonyroot, ipomoea_panurata, ipomoea_fastigiata\",\n \"red_morning-glory, star_ipomoea, ipomoea_coccinea\",\n \"man-of-the-earth, ipomoea_leptophylla\",\n \"scammony, ipomoea_orizabensis\",\n \"japanese_morning_glory, ipomoea_nil\",\n \"imperial_japanese_morning_glory, ipomoea_imperialis\",\n \"gesneriad\",\n \"gesneria\",\n \"achimenes, hot_water_plant\",\n \"aeschynanthus\",\n \"lace-flower_vine, alsobia_dianthiflora, episcia_dianthiflora\",\n \"columnea\",\n \"episcia\",\n \"gloxinia\",\n \"canterbury_bell, gloxinia_perennis\",\n \"kohleria\",\n \"african_violet, saintpaulia_ionantha\",\n \"streptocarpus\",\n \"cape_primrose\",\n \"waterleaf\",\n \"virginia_waterleaf, shawnee_salad, shawny, indian_salad, john's_cabbage, hydrophyllum_virginianum\",\n \"yellow_bells, california_yellow_bells, whispering_bells, emmanthe_penduliflora\",\n \"yerba_santa, eriodictyon_californicum\",\n \"nemophila\",\n \"baby_blue-eyes, nemophila_menziesii\",\n \"five-spot, nemophila_maculata\",\n \"scorpionweed, scorpion_weed, phacelia\",\n \"california_bluebell, phacelia_campanularia\",\n \"california_bluebell, whitlavia, phacelia_minor, phacelia_whitlavia\",\n \"fiddleneck, phacelia_tanacetifolia\",\n \"fiesta_flower, pholistoma_auritum, nemophila_aurita\",\n \"basil_thyme, basil_balm, mother_of_thyme, acinos_arvensis, satureja_acinos\",\n \"giant_hyssop\",\n \"yellow_giant_hyssop, agastache_nepetoides\",\n \"anise_hyssop, agastache_foeniculum\",\n \"mexican_hyssop, agastache_mexicana\",\n \"bugle, bugleweed\",\n \"creeping_bugle, ajuga_reptans\",\n \"erect_bugle, blue_bugle, ajuga_genevensis\",\n \"pyramid_bugle, ajuga_pyramidalis\",\n \"wood_mint\",\n \"hairy_wood_mint, blephilia_hirsuta\",\n \"downy_wood_mint, blephilia_celiata\",\n \"calamint\",\n \"common_calamint, calamintha_sylvatica, satureja_calamintha_officinalis\",\n \"large-flowered_calamint, calamintha_grandiflora, clinopodium_grandiflorum, satureja_grandiflora\",\n \"lesser_calamint, field_balm, calamintha_nepeta, calamintha_nepeta_glantulosa, satureja_nepeta, satureja_calamintha_glandulosa\",\n \"wild_basil, cushion_calamint, clinopodium_vulgare, satureja_vulgaris\",\n \"horse_balm, horseweed, stoneroot, stone-root, richweed, stone_root, collinsonia_canadensis\",\n \"coleus, flame_nettle\",\n \"country_borage, coleus_aromaticus, coleus_amboinicus, plectranthus_amboinicus\",\n \"painted_nettle, joseph's_coat, coleus_blumei, solenostemon_blumei, solenostemon_scutellarioides\",\n \"apalachicola_rosemary, conradina_glabra\",\n \"dragonhead, dragon's_head, dracocephalum_parviflorum\",\n \"elsholtzia\",\n \"hemp_nettle, dead_nettle, galeopsis_tetrahit\",\n \"ground_ivy, alehoof, field_balm, gill-over-the-ground, runaway_robin, glechoma_hederaceae, nepeta_hederaceae\",\n \"pennyroyal, american_pennyroyal, hedeoma_pulegioides\",\n \"hyssop, hyssopus_officinalis\",\n \"dead_nettle\",\n \"white_dead_nettle, lamium_album\",\n \"henbit, lamium_amplexicaule\",\n \"english_lavender, lavandula_angustifolia, lavandula_officinalis\",\n \"french_lavender, lavandula_stoechas\",\n \"spike_lavender, french_lavender, lavandula_latifolia\",\n \"dagga, cape_dagga, red_dagga, wilde_dagga, leonotis_leonurus\",\n \"lion's-ear, leonotis_nepetaefolia, leonotis_nepetifolia\",\n \"motherwort, leonurus_cardiaca\",\n \"pitcher_sage, lepechinia_calycina, sphacele_calycina\",\n \"bugleweed, lycopus_virginicus\",\n \"water_horehound, lycopus_americanus\",\n \"gipsywort, gypsywort, lycopus_europaeus\",\n \"origanum\",\n \"oregano, marjoram, pot_marjoram, wild_marjoram, winter_sweet, origanum_vulgare\",\n \"sweet_marjoram, knotted_marjoram, origanum_majorana, majorana_hortensis\",\n \"horehound\",\n \"common_horehound, white_horehound, marrubium_vulgare\",\n \"lemon_balm, garden_balm, sweet_balm, bee_balm, beebalm, melissa_officinalis\",\n \"corn_mint, field_mint, mentha_arvensis\",\n \"water-mint, water_mint, mentha_aquatica\",\n \"bergamot_mint, lemon_mint, eau_de_cologne_mint, mentha_citrata\",\n \"horsemint, mentha_longifolia\",\n \"peppermint, mentha_piperita\",\n \"spearmint, mentha_spicata\",\n \"apple_mint, applemint, mentha_rotundifolia, mentha_suaveolens\",\n \"pennyroyal, mentha_pulegium\",\n \"yerba_buena, micromeria_chamissonis, micromeria_douglasii, satureja_douglasii\",\n \"molucca_balm, bells_of_ireland, molucella_laevis\",\n \"monarda, wild_bergamot\",\n \"bee_balm, beebalm, bergamot_mint, oswego_tea, monarda_didyma\",\n \"horsemint, monarda_punctata\",\n \"bee_balm, beebalm, monarda_fistulosa\",\n \"lemon_mint, horsemint, monarda_citriodora\",\n \"plains_lemon_monarda, monarda_pectinata\",\n \"basil_balm, monarda_clinopodia\",\n \"mustang_mint, monardella_lanceolata\",\n \"catmint, catnip, nepeta_cataria\",\n \"basil\",\n \"beefsteak_plant, perilla_frutescens_crispa\",\n \"phlomis\",\n \"jerusalem_sage, phlomis_fruticosa\",\n \"physostegia\",\n \"plectranthus\",\n \"patchouli, patchouly, pachouli, pogostemon_cablin\",\n \"self-heal, heal_all, prunella_vulgaris\",\n \"mountain_mint\",\n \"rosemary, rosmarinus_officinalis\",\n \"clary_sage, salvia_clarea\",\n \"purple_sage, chaparral_sage, salvia_leucophylla\",\n \"cancerweed, cancer_weed, salvia_lyrata\",\n \"common_sage, ramona, salvia_officinalis\",\n \"meadow_clary, salvia_pratensis\",\n \"clary, salvia_sclarea\",\n \"pitcher_sage, salvia_spathacea\",\n \"mexican_mint, salvia_divinorum\",\n \"wild_sage, wild_clary, vervain_sage, salvia_verbenaca\",\n \"savory\",\n \"summer_savory, satureja_hortensis, satureia_hortensis\",\n \"winter_savory, satureja_montana, satureia_montana\",\n \"skullcap, helmetflower\",\n \"blue_pimpernel, blue_skullcap, mad-dog_skullcap, mad-dog_weed, scutellaria_lateriflora\",\n \"hedge_nettle, dead_nettle, stachys_sylvatica\",\n \"hedge_nettle, stachys_palustris\",\n \"germander\",\n \"american_germander, wood_sage, teucrium_canadense\",\n \"cat_thyme, marum, teucrium_marum\",\n \"wood_sage, teucrium_scorodonia\",\n \"thyme\",\n \"common_thyme, thymus_vulgaris\",\n \"wild_thyme, creeping_thyme, thymus_serpyllum\",\n \"blue_curls\",\n \"turpentine_camphor_weed, camphorweed, vinegarweed, trichostema_lanceolatum\",\n \"bastard_pennyroyal, trichostema_dichotomum\",\n \"bladderwort\",\n \"butterwort\",\n \"genlisea\",\n \"martynia, martynia_annua\",\n \"common_unicorn_plant, devil's_claw, common_devil's_claw, elephant-tusk, proboscis_flower, ram's_horn, proboscidea_louisianica\",\n \"sand_devil's_claw, proboscidea_arenaria, martynia_arenaria\",\n \"sweet_unicorn_plant, proboscidea_fragrans, martynia_fragrans\",\n \"figwort\",\n \"snapdragon\",\n \"white_snapdragon, antirrhinum_coulterianum\",\n \"yellow_twining_snapdragon, antirrhinum_filipes\",\n \"mediterranean_snapdragon, antirrhinum_majus\",\n \"kitten-tails\",\n \"alpine_besseya, besseya_alpina\",\n \"false_foxglove, aureolaria_pedicularia, gerardia_pedicularia\",\n \"false_foxglove, aureolaria_virginica, gerardia_virginica\",\n \"calceolaria, slipperwort\",\n \"indian_paintbrush, painted_cup\",\n \"desert_paintbrush, castilleja_chromosa\",\n \"giant_red_paintbrush, castilleja_miniata\",\n \"great_plains_paintbrush, castilleja_sessiliflora\",\n \"sulfur_paintbrush, castilleja_sulphurea\",\n \"shellflower, shell-flower, turtlehead, snakehead, snake-head, chelone_glabra\",\n \"maiden_blue-eyed_mary, collinsia_parviflora\",\n \"blue-eyed_mary, collinsia_verna\",\n \"foxglove, digitalis\",\n \"common_foxglove, fairy_bell, fingerflower, finger-flower, fingerroot, finger-root, digitalis_purpurea\",\n \"yellow_foxglove, straw_foxglove, digitalis_lutea\",\n \"gerardia\",\n \"blue_toadflax, old-field_toadflax, linaria_canadensis\",\n \"toadflax, butter-and-eggs, wild_snapdragon, devil's_flax, linaria_vulgaris\",\n \"golden-beard_penstemon, penstemon_barbatus\",\n \"scarlet_bugler, penstemon_centranthifolius\",\n \"red_shrubby_penstemon, redwood_penstemon\",\n \"platte_river_penstemon, penstemon_cyananthus\",\n \"hot-rock_penstemon, penstemon_deustus\",\n \"jones'_penstemon, penstemon_dolius\",\n \"shrubby_penstemon, lowbush_penstemon, penstemon_fruticosus\",\n \"narrow-leaf_penstemon, penstemon_linarioides\",\n \"balloon_flower, scented_penstemon, penstemon_palmeri\",\n \"parry's_penstemon, penstemon_parryi\",\n \"rock_penstemon, cliff_penstemon, penstemon_rupicola\",\n \"rydberg's_penstemon, penstemon_rydbergii\",\n \"cascade_penstemon, penstemon_serrulatus\",\n \"whipple's_penstemon, penstemon_whippleanus\",\n \"moth_mullein, verbascum_blattaria\",\n \"white_mullein, verbascum_lychnitis\",\n \"purple_mullein, verbascum_phoeniceum\",\n \"common_mullein, great_mullein, aaron's_rod, flannel_mullein, woolly_mullein, torch, verbascum_thapsus\",\n \"veronica, speedwell\",\n \"field_speedwell, veronica_agrestis\",\n \"brooklime, american_brooklime, veronica_americana\",\n \"corn_speedwell, veronica_arvensis\",\n \"brooklime, european_brooklime, veronica_beccabunga\",\n \"germander_speedwell, bird's_eye, veronica_chamaedrys\",\n \"water_speedwell, veronica_michauxii, veronica_anagallis-aquatica\",\n \"common_speedwell, gypsyweed, veronica_officinalis\",\n \"purslane_speedwell, veronica_peregrina\",\n \"thyme-leaved_speedwell, veronica_serpyllifolia\",\n \"nightshade\",\n \"horse_nettle, ball_nettle, bull_nettle, ball_nightshade, solanum_carolinense\",\n \"african_holly, solanum_giganteum\",\n \"potato_vine, solanum_jasmoides\",\n \"garden_huckleberry, wonderberry, sunberry, solanum_nigrum_guineese, solanum_melanocerasum, solanum_burbankii\",\n \"naranjilla, solanum_quitoense\",\n \"potato_vine, giant_potato_creeper, solanum_wendlandii\",\n \"potato_tree, brazilian_potato_tree, solanum_wrightii, solanum_macranthum\",\n \"belladonna, belladonna_plant, deadly_nightshade, atropa_belladonna\",\n \"bush_violet, browallia\",\n \"lady-of-the-night, brunfelsia_americana\",\n \"angel's_trumpet, maikoa, brugmansia_arborea, datura_arborea\",\n \"angel's_trumpet, brugmansia_suaveolens, datura_suaveolens\",\n \"red_angel's_trumpet, brugmansia_sanguinea, datura_sanguinea\",\n \"cone_pepper, capsicum_annuum_conoides\",\n \"bird_pepper, capsicum_frutescens_baccatum, capsicum_baccatum\",\n \"day_jessamine, cestrum_diurnum\",\n \"night_jasmine, night_jessamine, cestrum_nocturnum\",\n \"tree_tomato, tamarillo\",\n \"thorn_apple\",\n \"jimsonweed, jimson_weed, jamestown_weed, common_thorn_apple, apple_of_peru, datura_stramonium\",\n \"pichi, fabiana_imbricata\",\n \"henbane, black_henbane, stinking_nightshade, hyoscyamus_niger\",\n \"egyptian_henbane, hyoscyamus_muticus\",\n \"matrimony_vine, boxthorn\",\n \"common_matrimony_vine, duke_of_argyll's_tea_tree, lycium_barbarum, lycium_halimifolium\",\n \"christmasberry, christmas_berry, lycium_carolinianum\",\n \"plum_tomato\",\n \"mandrake, devil's_apples, mandragora_officinarum\",\n \"mandrake_root, mandrake\",\n \"apple_of_peru, shoo_fly, nicandra_physaloides\",\n \"flowering_tobacco, jasmine_tobacco, nicotiana_alata\",\n \"common_tobacco, nicotiana_tabacum\",\n \"wild_tobacco, indian_tobacco, nicotiana_rustica\",\n \"cupflower, nierembergia\",\n \"whitecup, nierembergia_repens, nierembergia_rivularis\",\n \"petunia\",\n \"large_white_petunia, petunia_axillaris\",\n \"violet-flowered_petunia, petunia_integrifolia\",\n \"hybrid_petunia, petunia_hybrida\",\n \"cape_gooseberry, purple_ground_cherry, physalis_peruviana\",\n \"strawberry_tomato, dwarf_cape_gooseberry, physalis_pruinosa\",\n \"tomatillo, jamberry, mexican_husk_tomato, physalis_ixocarpa\",\n \"tomatillo, miltomate, purple_ground_cherry, jamberry, physalis_philadelphica\",\n \"yellow_henbane, physalis_viscosa\",\n \"cock's_eggs, salpichroa_organifolia, salpichroa_rhomboidea\",\n \"salpiglossis\",\n \"painted_tongue, salpiglossis_sinuata\",\n \"butterfly_flower, poor_man's_orchid, schizanthus\",\n \"scopolia_carniolica\",\n \"chalice_vine, trumpet_flower, cupflower, solandra_guttata\",\n \"verbena, vervain\",\n \"lantana\",\n \"black_mangrove, avicennia_marina\",\n \"white_mangrove, avicennia_officinalis\",\n \"black_mangrove, aegiceras_majus\",\n \"teak, tectona_grandis\",\n \"spurge\",\n \"sun_spurge, wartweed, wartwort, devil's_milk, euphorbia_helioscopia\",\n \"petty_spurge, devil's_milk, euphorbia_peplus\",\n \"medusa's_head, euphorbia_medusae, euphorbia_caput-medusae\",\n \"wild_spurge, flowering_spurge, tramp's_spurge, euphorbia_corollata\",\n \"snow-on-the-mountain, snow-in-summer, ghost_weed, euphorbia_marginata\",\n \"cypress_spurge, euphorbia_cyparissias\",\n \"leafy_spurge, wolf's_milk, euphorbia_esula\",\n \"hairy_spurge, euphorbia_hirsuta\",\n \"poinsettia, christmas_star, christmas_flower, lobster_plant, mexican_flameleaf, painted_leaf, euphorbia_pulcherrima\",\n \"japanese_poinsettia, mole_plant, paint_leaf, euphorbia_heterophylla\",\n \"fire-on-the-mountain, painted_leaf, mexican_fire_plant, euphorbia_cyathophora\",\n \"wood_spurge, euphorbia_amygdaloides\",\n \"dwarf_spurge, euphorbia_exigua\",\n \"scarlet_plume, euphorbia_fulgens\",\n \"naboom, cactus_euphorbia, euphorbia_ingens\",\n \"crown_of_thorns, christ_thorn, christ_plant, euphorbia_milii\",\n \"toothed_spurge, euphorbia_dentata\",\n \"three-seeded_mercury, acalypha_virginica\",\n \"croton, croton_tiglium\",\n \"cascarilla, croton_eluteria\",\n \"cascarilla_bark, eleuthera_bark, sweetwood_bark\",\n \"castor-oil_plant, castor_bean_plant, palma_christi, palma_christ, ricinus_communis\",\n \"spurge_nettle, tread-softly, devil_nettle, pica-pica, cnidoscolus_urens, jatropha_urens, jatropha_stimulosus\",\n \"physic_nut, jatropha_curcus\",\n \"para_rubber_tree, caoutchouc_tree, hevea_brasiliensis\",\n \"cassava, casava\",\n \"bitter_cassava, manioc, mandioc, mandioca, tapioca_plant, gari, manihot_esculenta, manihot_utilissima\",\n \"cassava, manioc\",\n \"sweet_cassava, manihot_dulcis\",\n \"candlenut, varnish_tree, aleurites_moluccana\",\n \"tung_tree, tung, tung-oil_tree, aleurites_fordii\",\n \"slipper_spurge, slipper_plant\",\n \"candelilla, pedilanthus_bracteatus, pedilanthus_pavonis\",\n \"jewbush, jew-bush, jew_bush, redbird_cactus, redbird_flower, pedilanthus_tithymaloides\",\n \"jumping_bean, jumping_seed, mexican_jumping_bean\",\n \"camellia, camelia\",\n \"japonica, camellia_japonica\",\n \"umbellifer, umbelliferous_plant\",\n \"wild_parsley\",\n \"fool's_parsley, lesser_hemlock, aethusa_cynapium\",\n \"dill, anethum_graveolens\",\n \"angelica, angelique\",\n \"garden_angelica, archangel, angelica_archangelica\",\n \"wild_angelica, angelica_sylvestris\",\n \"chervil, beaked_parsley, anthriscus_cereifolium\",\n \"cow_parsley, wild_chervil, anthriscus_sylvestris\",\n \"wild_celery, apium_graveolens\",\n \"astrantia, masterwort\",\n \"greater_masterwort, astrantia_major\",\n \"caraway, carum_carvi\",\n \"whorled_caraway\",\n \"water_hemlock, cicuta_verosa\",\n \"spotted_cowbane, spotted_hemlock, spotted_water_hemlock\",\n \"hemlock, poison_hemlock, poison_parsley, california_fern, nebraska_fern, winter_fern, conium_maculatum\",\n \"earthnut, conopodium_denudatum\",\n \"cumin, cuminum_cyminum\",\n \"wild_carrot, queen_anne's_lace, daucus_carota\",\n \"eryngo, eringo\",\n \"sea_holly, sea_holm, sea_eryngium, eryngium_maritimum\",\n \"button_snakeroot, eryngium_aquaticum\",\n \"rattlesnake_master, rattlesnake's_master, button_snakeroot, eryngium_yuccifolium\",\n \"fennel\",\n \"common_fennel, foeniculum_vulgare\",\n \"florence_fennel, foeniculum_dulce, foeniculum_vulgare_dulce\",\n \"cow_parsnip, hogweed, heracleum_sphondylium\",\n \"lovage, levisticum_officinale\",\n \"sweet_cicely, myrrhis_odorata\",\n \"water_fennel, oenanthe_aquatica\",\n \"parsnip, pastinaca_sativa\",\n \"cultivated_parsnip\",\n \"wild_parsnip, madnep\",\n \"parsley, petroselinum_crispum\",\n \"italian_parsley, flat-leaf_parsley, petroselinum_crispum_neapolitanum\",\n \"hamburg_parsley, turnip-rooted_parsley, petroselinum_crispum_tuberosum\",\n \"anise, anise_plant, pimpinella_anisum\",\n \"sanicle, snakeroot\",\n \"purple_sanicle, sanicula_bipinnatifida\",\n \"european_sanicle, sanicula_europaea\",\n \"water_parsnip, sium_suave\",\n \"greater_water_parsnip, sium_latifolium\",\n \"skirret, sium_sisarum\",\n \"dogwood, dogwood_tree, cornel\",\n \"common_white_dogwood, eastern_flowering_dogwood, cornus_florida\",\n \"red_osier, red_osier_dogwood, red_dogwood, american_dogwood, redbrush, cornus_stolonifera\",\n \"silky_dogwood, cornus_obliqua\",\n \"silky_cornel, silky_dogwood, cornus_amomum\",\n \"common_european_dogwood, red_dogwood, blood-twig, pedwood, cornus_sanguinea\",\n \"bunchberry, dwarf_cornel, crackerberry, pudding_berry, cornus_canadensis\",\n \"cornelian_cherry, cornus_mas\",\n \"puka, griselinia_lucida\",\n \"kapuka, griselinia_littoralis\",\n \"valerian\",\n \"common_valerian, garden_heliotrope, valeriana_officinalis\",\n \"common_corn_salad, lamb's_lettuce, valerianella_olitoria, valerianella_locusta\",\n \"red_valerian, french_honeysuckle, centranthus_ruber\",\n \"filmy_fern, film_fern\",\n \"bristle_fern, filmy_fern\",\n \"hare's-foot_bristle_fern, trichomanes_boschianum\",\n \"killarney_fern, trichomanes_speciosum\",\n \"kidney_fern, trichomanes_reniforme\",\n \"flowering_fern, osmund\",\n \"royal_fern, royal_osmund, king_fern, ditch_fern, french_bracken, osmunda_regalis\",\n \"interrupted_fern, osmunda_clatonia\",\n \"crape_fern, prince-of-wales_fern, prince-of-wales_feather, prince-of-wales_plume, leptopteris_superba, todea_superba\",\n \"crepe_fern, king_fern, todea_barbara\",\n \"curly_grass, curly_grass_fern, schizaea_pusilla\",\n \"pine_fern, anemia_adiantifolia\",\n \"climbing_fern\",\n \"creeping_fern, hartford_fern, lygodium_palmatum\",\n \"climbing_maidenhair, climbing_maidenhair_fern, snake_fern, lygodium_microphyllum\",\n \"scented_fern, mohria_caffrorum\",\n \"clover_fern, pepperwort\",\n \"nardoo, nardo, common_nardoo, marsilea_drummondii\",\n \"water_clover, marsilea_quadrifolia\",\n \"pillwort, pilularia_globulifera\",\n \"regnellidium, regnellidium_diphyllum\",\n \"floating-moss, salvinia_rotundifolia, salvinia_auriculata\",\n \"mosquito_fern, floating_fern, carolina_pond_fern, azolla_caroliniana\",\n \"adder's_tongue, adder's_tongue_fern\",\n \"ribbon_fern, ophioglossum_pendulum\",\n \"grape_fern\",\n \"daisyleaf_grape_fern, daisy-leaved_grape_fern, botrychium_matricariifolium\",\n \"leathery_grape_fern, botrychium_multifidum\",\n \"rattlesnake_fern, botrychium_virginianum\",\n \"flowering_fern, helminthostachys_zeylanica\",\n \"powdery_mildew\",\n \"dutch_elm_fungus, ceratostomella_ulmi\",\n \"ergot, claviceps_purpurea\",\n \"rye_ergot\",\n \"black_root_rot_fungus, xylaria_mali\",\n \"dead-man's-fingers, dead-men's-fingers, xylaria_polymorpha\",\n \"sclerotinia\",\n \"brown_cup\",\n \"earthball, false_truffle, puffball, hard-skinned_puffball\",\n \"scleroderma_citrinum, scleroderma_aurantium\",\n \"scleroderma_flavidium, star_earthball\",\n \"scleroderma_bovista, smooth_earthball\",\n \"podaxaceae\",\n \"stalked_puffball\",\n \"stalked_puffball\",\n \"false_truffle\",\n \"rhizopogon_idahoensis\",\n \"truncocolumella_citrina\",\n \"mucor\",\n \"rhizopus\",\n \"bread_mold, rhizopus_nigricans\",\n \"slime_mold, slime_mould\",\n \"true_slime_mold, acellular_slime_mold, plasmodial_slime_mold, myxomycete\",\n \"cellular_slime_mold\",\n \"dictostylium\",\n \"pond-scum_parasite\",\n \"potato_wart_fungus, synchytrium_endobioticum\",\n \"white_fungus, saprolegnia_ferax\",\n \"water_mold\",\n \"downy_mildew, false_mildew\",\n \"blue_mold_fungus, peronospora_tabacina\",\n \"onion_mildew, peronospora_destructor\",\n \"tobacco_mildew, peronospora_hyoscyami\",\n \"white_rust\",\n \"pythium\",\n \"damping_off_fungus, pythium_debaryanum\",\n \"phytophthora_citrophthora\",\n \"phytophthora_infestans\",\n \"clubroot_fungus, plasmodiophora_brassicae\",\n \"geglossaceae\",\n \"sarcosomataceae\",\n \"rufous_rubber_cup\",\n \"devil's_cigar\",\n \"devil's_urn\",\n \"truffle, earthnut, earth-ball\",\n \"club_fungus\",\n \"coral_fungus\",\n \"tooth_fungus\",\n \"lichen\",\n \"ascolichen\",\n \"basidiolichen\",\n \"lecanora\",\n \"manna_lichen\",\n \"archil, orchil\",\n \"roccella, roccella_tinctoria\",\n \"beard_lichen, beard_moss, usnea_barbata\",\n \"horsehair_lichen, horsetail_lichen\",\n \"reindeer_moss, reindeer_lichen, arctic_moss, cladonia_rangiferina\",\n \"crottle, crottal, crotal\",\n \"iceland_moss, iceland_lichen, cetraria_islandica\",\n \"fungus\",\n \"promycelium\",\n \"true_fungus\",\n \"basidiomycete, basidiomycetous_fungi\",\n \"mushroom\",\n \"agaric\",\n \"mushroom\",\n \"mushroom\",\n \"toadstool\",\n \"horse_mushroom, agaricus_arvensis\",\n \"meadow_mushroom, field_mushroom, agaricus_campestris\",\n \"shiitake, shiitake_mushroom, chinese_black_mushroom, golden_oak_mushroom, oriental_black_mushroom, lentinus_edodes\",\n \"scaly_lentinus, lentinus_lepideus\",\n \"royal_agaric, caesar's_agaric, amanita_caesarea\",\n \"false_deathcap, amanita_mappa\",\n \"fly_agaric, amanita_muscaria\",\n \"death_cap, death_cup, death_angel, destroying_angel, amanita_phalloides\",\n \"blushing_mushroom, blusher, amanita_rubescens\",\n \"destroying_angel, amanita_verna\",\n \"chanterelle, chantarelle, cantharellus_cibarius\",\n \"floccose_chanterelle, cantharellus_floccosus\",\n \"pig's_ears, cantharellus_clavatus\",\n \"cinnabar_chanterelle, cantharellus_cinnabarinus\",\n \"jack-o-lantern_fungus, jack-o-lantern, jack-a-lantern, omphalotus_illudens\",\n \"inky_cap, inky-cap_mushroom, coprinus_atramentarius\",\n \"shaggymane, shaggy_cap, shaggymane_mushroom, coprinus_comatus\",\n \"milkcap, lactarius_delicioso\",\n \"fairy-ring_mushroom, marasmius_oreades\",\n \"fairy_ring, fairy_circle\",\n \"oyster_mushroom, oyster_fungus, oyster_agaric, pleurotus_ostreatus\",\n \"olive-tree_agaric, pleurotus_phosphoreus\",\n \"pholiota_astragalina\",\n \"pholiota_aurea, golden_pholiota\",\n \"pholiota_destruens\",\n \"pholiota_flammans\",\n \"pholiota_flavida\",\n \"nameko, viscid_mushroom, pholiota_nameko\",\n \"pholiota_squarrosa-adiposa\",\n \"pholiota_squarrosa, scaly_pholiota\",\n \"pholiota_squarrosoides\",\n \"stropharia_ambigua\",\n \"stropharia_hornemannii\",\n \"stropharia_rugoso-annulata\",\n \"gill_fungus\",\n \"entoloma_lividum, entoloma_sinuatum\",\n \"entoloma_aprile\",\n \"chlorophyllum_molybdites\",\n \"lepiota\",\n \"parasol_mushroom, lepiota_procera\",\n \"poisonous_parasol, lepiota_morgani\",\n \"lepiota_naucina\",\n \"lepiota_rhacodes\",\n \"american_parasol, lepiota_americana\",\n \"lepiota_rubrotincta\",\n \"lepiota_clypeolaria\",\n \"onion_stem, lepiota_cepaestipes\",\n \"pink_disease_fungus, corticium_salmonicolor\",\n \"bottom_rot_fungus, corticium_solani\",\n \"potato_fungus, pellicularia_filamentosa, rhizoctinia_solani\",\n \"coffee_fungus, pellicularia_koleroga\",\n \"blewits, clitocybe_nuda\",\n \"sandy_mushroom, tricholoma_populinum\",\n \"tricholoma_pessundatum\",\n \"tricholoma_sejunctum\",\n \"man-on-a-horse, tricholoma_flavovirens\",\n \"tricholoma_venenata\",\n \"tricholoma_pardinum\",\n \"tricholoma_vaccinum\",\n \"tricholoma_aurantium\",\n \"volvaria_bombycina\",\n \"pluteus_aurantiorugosus\",\n \"pluteus_magnus, sawdust_mushroom\",\n \"deer_mushroom, pluteus_cervinus\",\n \"straw_mushroom, chinese_mushroom, volvariella_volvacea\",\n \"volvariella_bombycina\",\n \"clitocybe_clavipes\",\n \"clitocybe_dealbata\",\n \"clitocybe_inornata\",\n \"clitocybe_robusta, clytocybe_alba\",\n \"clitocybe_irina, tricholoma_irinum, lepista_irina\",\n \"clitocybe_subconnexa\",\n \"winter_mushroom, flammulina_velutipes\",\n \"mycelium\",\n \"sclerotium\",\n \"sac_fungus\",\n \"ascomycete, ascomycetous_fungus\",\n \"clavicipitaceae, grainy_club_mushrooms\",\n \"grainy_club\",\n \"yeast\",\n \"baker's_yeast, brewer's_yeast, saccharomyces_cerevisiae\",\n \"wine-maker's_yeast, saccharomyces_ellipsoides\",\n \"aspergillus_fumigatus\",\n \"brown_root_rot_fungus, thielavia_basicola\",\n \"discomycete, cup_fungus\",\n \"leotia_lubrica\",\n \"mitrula_elegans\",\n \"sarcoscypha_coccinea, scarlet_cup\",\n \"caloscypha_fulgens\",\n \"aleuria_aurantia, orange_peel_fungus\",\n \"elf_cup\",\n \"peziza_domicilina\",\n \"blood_cup, fairy_cup, peziza_coccinea\",\n \"urnula_craterium, urn_fungus\",\n \"galiella_rufa\",\n \"jafnea_semitosta\",\n \"morel\",\n \"common_morel, morchella_esculenta, sponge_mushroom, sponge_morel\",\n \"disciotis_venosa, cup_morel\",\n \"verpa, bell_morel\",\n \"verpa_bohemica, early_morel\",\n \"verpa_conica, conic_verpa\",\n \"black_morel, morchella_conica, conic_morel, morchella_angusticeps, narrowhead_morel\",\n \"morchella_crassipes, thick-footed_morel\",\n \"morchella_semilibera, half-free_morel, cow's_head\",\n \"wynnea_americana\",\n \"wynnea_sparassoides\",\n \"false_morel\",\n \"lorchel\",\n \"helvella\",\n \"helvella_crispa, miter_mushroom\",\n \"helvella_acetabulum\",\n \"helvella_sulcata\",\n \"discina\",\n \"gyromitra\",\n \"gyromitra_californica, california_false_morel\",\n \"gyromitra_sphaerospora, round-spored_gyromitra\",\n \"gyromitra_esculenta, brain_mushroom, beefsteak_morel\",\n \"gyromitra_infula, saddled-shaped_false_morel\",\n \"gyromitra_fastigiata, gyromitra_brunnea\",\n \"gyromitra_gigas\",\n \"gasteromycete, gastromycete\",\n \"stinkhorn, carrion_fungus\",\n \"common_stinkhorn, phallus_impudicus\",\n \"phallus_ravenelii\",\n \"dog_stinkhorn, mutinus_caninus\",\n \"calostoma_lutescens\",\n \"calostoma_cinnabarina\",\n \"calostoma_ravenelii\",\n \"stinky_squid, pseudocolus_fusiformis\",\n \"puffball, true_puffball\",\n \"giant_puffball, calvatia_gigantea\",\n \"earthstar\",\n \"geastrum_coronatum\",\n \"radiigera_fuscogleba\",\n \"astreus_pteridis\",\n \"astreus_hygrometricus\",\n \"bird's-nest_fungus\",\n \"gastrocybe_lateritia\",\n \"macowanites_americanus\",\n \"polypore, pore_fungus, pore_mushroom\",\n \"bracket_fungus, shelf_fungus\",\n \"albatrellus_dispansus\",\n \"albatrellus_ovinus, sheep_polypore\",\n \"neolentinus_ponderosus\",\n \"oligoporus_leucospongia\",\n \"polyporus_tenuiculus\",\n \"hen-of-the-woods, hen_of_the_woods, polyporus_frondosus, grifola_frondosa\",\n \"polyporus_squamosus, scaly_polypore\",\n \"beefsteak_fungus, fistulina_hepatica\",\n \"agaric, fomes_igniarius\",\n \"bolete\",\n \"boletus_chrysenteron\",\n \"boletus_edulis\",\n \"frost's_bolete, boletus_frostii\",\n \"boletus_luridus\",\n \"boletus_mirabilis\",\n \"boletus_pallidus\",\n \"boletus_pulcherrimus\",\n \"boletus_pulverulentus\",\n \"boletus_roxanae\",\n \"boletus_subvelutipes\",\n \"boletus_variipes\",\n \"boletus_zelleri\",\n \"fuscoboletinus_paluster\",\n \"fuscoboletinus_serotinus\",\n \"leccinum_fibrillosum\",\n \"suillus_albivelatus\",\n \"old-man-of-the-woods, strobilomyces_floccopus\",\n \"boletellus_russellii\",\n \"jelly_fungus\",\n \"snow_mushroom, tremella_fuciformis\",\n \"witches'_butter, tremella_lutescens\",\n \"tremella_foliacea\",\n \"tremella_reticulata\",\n \"jew's-ear, jew's-ears, ear_fungus, auricularia_auricula\",\n \"rust, rust_fungus\",\n \"aecium\",\n \"flax_rust, flax_rust_fungus, melampsora_lini\",\n \"blister_rust, cronartium_ribicola\",\n \"wheat_rust, puccinia_graminis\",\n \"apple_rust, cedar-apple_rust, gymnosporangium_juniperi-virginianae\",\n \"smut, smut_fungus\",\n \"covered_smut\",\n \"loose_smut\",\n \"cornsmut, corn_smut\",\n \"boil_smut, ustilago_maydis\",\n \"sphacelotheca, genus_sphacelotheca\",\n \"head_smut, sphacelotheca_reiliana\",\n \"bunt, tilletia_caries\",\n \"bunt, stinking_smut, tilletia_foetida\",\n \"onion_smut, urocystis_cepulae\",\n \"flag_smut_fungus\",\n \"wheat_flag_smut, urocystis_tritici\",\n \"felt_fungus, septobasidium_pseudopedicellatum\",\n \"waxycap\",\n \"hygrocybe_acutoconica, conic_waxycap\",\n \"hygrophorus_borealis\",\n \"hygrophorus_caeruleus\",\n \"hygrophorus_inocybiformis\",\n \"hygrophorus_kauffmanii\",\n \"hygrophorus_marzuolus\",\n \"hygrophorus_purpurascens\",\n \"hygrophorus_russula\",\n \"hygrophorus_sordidus\",\n \"hygrophorus_tennesseensis\",\n \"hygrophorus_turundus\",\n \"neohygrophorus_angelesianus\",\n \"cortinarius_armillatus\",\n \"cortinarius_atkinsonianus\",\n \"cortinarius_corrugatus\",\n \"cortinarius_gentilis\",\n \"cortinarius_mutabilis, purple-staining_cortinarius\",\n \"cortinarius_semisanguineus\",\n \"cortinarius_subfoetidus\",\n \"cortinarius_violaceus\",\n \"gymnopilus_spectabilis\",\n \"gymnopilus_validipes\",\n \"gymnopilus_ventricosus\",\n \"mold, mould\",\n \"mildew\",\n \"verticillium\",\n \"monilia\",\n \"candida\",\n \"candida_albicans, monilia_albicans\",\n \"blastomycete\",\n \"yellow_spot_fungus, cercospora_kopkei\",\n \"green_smut_fungus, ustilaginoidea_virens\",\n \"dry_rot\",\n \"rhizoctinia\",\n \"houseplant\",\n \"bedder, bedding_plant\",\n \"succulent\",\n \"cultivar\",\n \"weed\",\n \"wort\",\n \"brier\",\n \"aril\",\n \"sporophyll, sporophyl\",\n \"sporangium, spore_case, spore_sac\",\n \"sporangiophore\",\n \"ascus\",\n \"ascospore\",\n \"arthrospore\",\n \"eusporangium\",\n \"tetrasporangium\",\n \"gametangium\",\n \"sorus\",\n \"sorus\",\n \"partial_veil\",\n \"lignum\",\n \"vascular_ray, medullary_ray\",\n \"phloem, bast\",\n \"evergreen, evergreen_plant\",\n \"deciduous_plant\",\n \"poisonous_plant\",\n \"vine\",\n \"creeper\",\n \"tendril\",\n \"root_climber\",\n \"lignosae\",\n \"arborescent_plant\",\n \"snag\",\n \"tree\",\n \"timber_tree\",\n \"treelet\",\n \"arbor\",\n \"bean_tree\",\n \"pollard\",\n \"sapling\",\n \"shade_tree\",\n \"gymnospermous_tree\",\n \"conifer, coniferous_tree\",\n \"angiospermous_tree, flowering_tree\",\n \"nut_tree\",\n \"spice_tree\",\n \"fever_tree\",\n \"stump, tree_stump\",\n \"bonsai\",\n \"ming_tree\",\n \"ming_tree\",\n \"undershrub\",\n \"subshrub, suffrutex\",\n \"bramble\",\n \"liana\",\n \"geophyte\",\n \"desert_plant, xerophyte, xerophytic_plant, xerophile, xerophilous_plant\",\n \"mesophyte, mesophytic_plant\",\n \"marsh_plant, bog_plant, swamp_plant\",\n \"hemiepiphyte, semiepiphyte\",\n \"strangler, strangler_tree\",\n \"lithophyte, lithophytic_plant\",\n \"saprobe\",\n \"autophyte, autophytic_plant, autotroph, autotrophic_organism\",\n \"root\",\n \"taproot\",\n \"prop_root\",\n \"prophyll\",\n \"rootstock\",\n \"quickset\",\n \"stolon, runner, offset\",\n \"tuberous_plant\",\n \"rhizome, rootstock, rootstalk\",\n \"rachis\",\n \"caudex\",\n \"cladode, cladophyll, phylloclad, phylloclade\",\n \"receptacle\",\n \"scape, flower_stalk\",\n \"umbel\",\n \"petiole, leafstalk\",\n \"peduncle\",\n \"pedicel, pedicle\",\n \"flower_cluster\",\n \"raceme\",\n \"panicle\",\n \"thyrse, thyrsus\",\n \"cyme\",\n \"cymule\",\n \"glomerule\",\n \"scorpioid_cyme\",\n \"ear, spike, capitulum\",\n \"spadix\",\n \"bulbous_plant\",\n \"bulbil, bulblet\",\n \"cormous_plant\",\n \"fruit\",\n \"fruitlet\",\n \"seed\",\n \"bean\",\n \"nut\",\n \"nutlet\",\n \"kernel, meat\",\n \"syconium\",\n \"berry\",\n \"aggregate_fruit, multiple_fruit, syncarp\",\n \"simple_fruit, bacca\",\n \"acinus\",\n \"drupe, stone_fruit\",\n \"drupelet\",\n \"pome, false_fruit\",\n \"pod, seedpod\",\n \"loment\",\n \"pyxidium, pyxis\",\n \"husk\",\n \"cornhusk\",\n \"pod, cod, seedcase\",\n \"accessory_fruit, pseudocarp\",\n \"buckthorn\",\n \"buckthorn_berry, yellow_berry\",\n \"cascara_buckthorn, bearberry, bearwood, chittamwood, chittimwood, rhamnus_purshianus\",\n \"cascara, cascara_sagrada, chittam_bark, chittem_bark\",\n \"carolina_buckthorn, indian_cherry, rhamnus_carolinianus\",\n \"coffeeberry, california_buckthorn, california_coffee, rhamnus_californicus\",\n \"redberry, red-berry, rhamnus_croceus\",\n \"nakedwood\",\n \"jujube, jujube_bush, christ's-thorn, jerusalem_thorn, ziziphus_jujuba\",\n \"christ's-thorn, jerusalem_thorn, paliurus_spina-christi\",\n \"hazel, hazel_tree, pomaderris_apetala\",\n \"fox_grape, vitis_labrusca\",\n \"muscadine, vitis_rotundifolia\",\n \"vinifera, vinifera_grape, common_grape_vine, vitis_vinifera\",\n \"pinot_blanc\",\n \"sauvignon_grape\",\n \"sauvignon_blanc\",\n \"muscadet\",\n \"riesling\",\n \"zinfandel\",\n \"chenin_blanc\",\n \"malvasia\",\n \"verdicchio\",\n \"boston_ivy, japanese_ivy, parthenocissus_tricuspidata\",\n \"virginia_creeper, american_ivy, woodbine, parthenocissus_quinquefolia\",\n \"true_pepper, pepper_vine\",\n \"betel, betel_pepper, piper_betel\",\n \"cubeb\",\n \"schizocarp\",\n \"peperomia\",\n \"watermelon_begonia, peperomia_argyreia, peperomia_sandersii\",\n \"yerba_mansa, anemopsis_californica\",\n \"pinna, pinnule\",\n \"frond\",\n \"bract\",\n \"bracteole, bractlet\",\n \"involucre\",\n \"glume\",\n \"palmate_leaf\",\n \"pinnate_leaf\",\n \"bijugate_leaf, bijugous_leaf, twice-pinnate\",\n \"decompound_leaf\",\n \"acuminate_leaf\",\n \"deltoid_leaf\",\n \"ensiform_leaf\",\n \"linear_leaf, elongate_leaf\",\n \"lyrate_leaf\",\n \"obtuse_leaf\",\n \"oblanceolate_leaf\",\n \"pandurate_leaf, panduriform_leaf\",\n \"reniform_leaf\",\n \"spatulate_leaf\",\n \"even-pinnate_leaf, abruptly-pinnate_leaf\",\n \"odd-pinnate_leaf\",\n \"pedate_leaf\",\n \"crenate_leaf\",\n \"dentate_leaf\",\n \"denticulate_leaf\",\n \"erose_leaf\",\n \"runcinate_leaf\",\n \"prickly-edged_leaf\",\n \"deadwood\",\n \"haulm, halm\",\n \"branchlet, twig, sprig\",\n \"osier\",\n \"giant_scrambling_fern, diplopterygium_longissimum\",\n \"umbrella_fern, fan_fern, sticherus_flabellatus, gleichenia_flabellata\",\n \"floating_fern, water_sprite, ceratopteris_pteridioides\",\n \"polypody\",\n \"licorice_fern, polypodium_glycyrrhiza\",\n \"grey_polypody, gray_polypody, resurrection_fern, polypodium_polypodioides\",\n \"leatherleaf, leathery_polypody, coast_polypody, polypodium_scouleri\",\n \"rock_polypody, rock_brake, american_wall_fern, polypodium_virgianum\",\n \"common_polypody, adder's_fern, wall_fern, golden_maidenhair, golden_polypody, sweet_fern, polypodium_vulgare\",\n \"bear's-paw_fern, aglaomorpha_meyeniana\",\n \"strap_fern\",\n \"florida_strap_fern, cow-tongue_fern, hart's-tongue_fern\",\n \"basket_fern, drynaria_rigidula\",\n \"snake_polypody, microgramma-piloselloides\",\n \"climbing_bird's_nest_fern, microsorium_punctatum\",\n \"golden_polypody, serpent_fern, rabbit's-foot_fern, phlebodium_aureum, polypodium_aureum\",\n \"staghorn_fern\",\n \"south_american_staghorn, platycerium_andinum\",\n \"common_staghorn_fern, elkhorn_fern, platycerium_bifurcatum, platycerium_alcicorne\",\n \"felt_fern, tongue_fern, pyrrosia_lingua, cyclophorus_lingua\",\n \"potato_fern, solanopteris_bifrons\",\n \"myrmecophyte\",\n \"grass_fern, ribbon_fern, vittaria_lineata\",\n \"spleenwort\",\n \"black_spleenwort, asplenium_adiantum-nigrum\",\n \"bird's_nest_fern, asplenium_nidus\",\n \"ebony_spleenwort, scott's_spleenwort, asplenium_platyneuron\",\n \"black-stem_spleenwort, black-stemmed_spleenwort, little_ebony_spleenwort\",\n \"walking_fern, walking_leaf, asplenium_rhizophyllum, camptosorus_rhizophyllus\",\n \"green_spleenwort, asplenium_viride\",\n \"mountain_spleenwort, asplenium_montanum\",\n \"lobed_spleenwort, asplenium_pinnatifidum\",\n \"lanceolate_spleenwort, asplenium_billotii\",\n \"hart's-tongue, hart's-tongue_fern, asplenium_scolopendrium, phyllitis_scolopendrium\",\n \"scale_fern, scaly_fern, asplenium_ceterach, ceterach_officinarum\",\n \"scolopendrium\",\n \"deer_fern, blechnum_spicant\",\n \"doodia, rasp_fern\",\n \"chain_fern\",\n \"virginia_chain_fern, woodwardia_virginica\",\n \"silver_tree_fern, sago_fern, black_tree_fern, cyathea_medullaris\",\n \"davallia\",\n \"hare's-foot_fern\",\n \"canary_island_hare's_foot_fern, davallia_canariensis\",\n \"squirrel's-foot_fern, ball_fern, davalia_bullata, davalia_bullata_mariesii, davallia_mariesii\",\n \"bracken, pteridium_esculentum\",\n \"soft_tree_fern, dicksonia_antarctica\",\n \"scythian_lamb, cibotium_barometz\",\n \"false_bracken, culcita_dubia\",\n \"thyrsopteris, thyrsopteris_elegans\",\n \"shield_fern, buckler_fern\",\n \"broad_buckler-fern, dryopteris_dilatata\",\n \"fragrant_cliff_fern, fragrant_shield_fern, fragrant_wood_fern, dryopteris_fragrans\",\n \"goldie's_fern, goldie's_shield_fern, goldie's_wood_fern, dryopteris_goldiana\",\n \"wood_fern, wood-fern, woodfern\",\n \"male_fern, dryopteris_filix-mas\",\n \"marginal_wood_fern, evergreen_wood_fern, leatherleaf_wood_fern, dryopteris_marginalis\",\n \"mountain_male_fern, dryopteris_oreades\",\n \"lady_fern, athyrium_filix-femina\",\n \"alpine_lady_fern, athyrium_distentifolium\",\n \"silvery_spleenwort, glade_fern, narrow-leaved_spleenwort, athyrium_pycnocarpon, diplazium_pycnocarpon\",\n \"holly_fern, cyrtomium_aculeatum, polystichum_aculeatum\",\n \"bladder_fern\",\n \"brittle_bladder_fern, brittle_fern, fragile_fern, cystopteris_fragilis\",\n \"mountain_bladder_fern, cystopteris_montana\",\n \"bulblet_fern, bulblet_bladder_fern, berry_fern, cystopteris_bulbifera\",\n \"silvery_spleenwort, deparia_acrostichoides, athyrium_thelypteroides\",\n \"oak_fern, gymnocarpium_dryopteris, thelypteris_dryopteris\",\n \"limestone_fern, northern_oak_fern, gymnocarpium_robertianum\",\n \"ostrich_fern, shuttlecock_fern, fiddlehead, matteuccia_struthiopteris, pteretis_struthiopteris, onoclea_struthiopteris\",\n \"hart's-tongue, hart's-tongue_fern, olfersia_cervina, polybotrya_cervina, polybotria_cervina\",\n \"sensitive_fern, bead_fern, onoclea_sensibilis\",\n \"christmas_fern, canker_brake, dagger_fern, evergreen_wood_fern, polystichum_acrostichoides\",\n \"holly_fern\",\n \"braun's_holly_fern, prickly_shield_fern, polystichum_braunii\",\n \"western_holly_fern, polystichum_scopulinum\",\n \"soft_shield_fern, polystichum_setiferum\",\n \"leather_fern, leatherleaf_fern, ten-day_fern, rumohra_adiantiformis, polystichum_adiantiformis\",\n \"button_fern, tectaria_cicutaria\",\n \"indian_button_fern, tectaria_macrodonta\",\n \"woodsia\",\n \"rusty_woodsia, fragrant_woodsia, oblong_woodsia, woodsia_ilvensis\",\n \"alpine_woodsia, northern_woodsia, flower-cup_fern, woodsia_alpina\",\n \"smooth_woodsia, woodsia_glabella\",\n \"boston_fern, nephrolepis_exaltata, nephrolepis_exaltata_bostoniensis\",\n \"basket_fern, toothed_sword_fern, nephrolepis_pectinata\",\n \"golden_fern, leather_fern, acrostichum_aureum\",\n \"maidenhair, maidenhair_fern\",\n \"common_maidenhair, venushair, venus'-hair_fern, southern_maidenhair, venus_maidenhair, adiantum_capillus-veneris\",\n \"american_maidenhair_fern, five-fingered_maidenhair_fern, adiantum_pedatum\",\n \"bermuda_maidenhair, bermuda_maidenhair_fern, adiantum_bellum\",\n \"brittle_maidenhair, brittle_maidenhair_fern, adiantum_tenerum\",\n \"farley_maidenhair, farley_maidenhair_fern, barbados_maidenhair, glory_fern, adiantum_tenerum_farleyense\",\n \"annual_fern, jersey_fern, anogramma_leptophylla\",\n \"lip_fern, lipfern\",\n \"smooth_lip_fern, alabama_lip_fern, cheilanthes_alabamensis\",\n \"lace_fern, cheilanthes_gracillima\",\n \"wooly_lip_fern, hairy_lip_fern, cheilanthes_lanosa\",\n \"southwestern_lip_fern, cheilanthes_eatonii\",\n \"bamboo_fern, coniogramme_japonica\",\n \"american_rock_brake, american_parsley_fern, cryptogramma_acrostichoides\",\n \"european_parsley_fern, mountain_parsley_fern, cryptogramma_crispa\",\n \"hand_fern, doryopteris_pedata\",\n \"cliff_brake, cliff-brake, rock_brake\",\n \"coffee_fern, pellaea_andromedifolia\",\n \"purple_rock_brake, pellaea_atropurpurea\",\n \"bird's-foot_fern, pellaea_mucronata, pellaea_ornithopus\",\n \"button_fern, pellaea_rotundifolia\",\n \"silver_fern, pityrogramma_argentea\",\n \"golden_fern, pityrogramma_calomelanos_aureoflava\",\n \"gold_fern, pityrogramma_chrysophylla\",\n \"pteris_cretica\",\n \"spider_brake, spider_fern, pteris_multifida\",\n \"ribbon_fern, spider_fern, pteris_serrulata\",\n \"potato_fern, marattia_salicina\",\n \"angiopteris, giant_fern, angiopteris_evecta\",\n \"skeleton_fork_fern, psilotum_nudum\",\n \"horsetail\",\n \"common_horsetail, field_horsetail, equisetum_arvense\",\n \"swamp_horsetail, water_horsetail, equisetum_fluviatile\",\n \"scouring_rush, rough_horsetail, equisetum_hyemale, equisetum_hyemale_robustum, equisetum_robustum\",\n \"marsh_horsetail, equisetum_palustre\",\n \"wood_horsetail, equisetum_sylvaticum\",\n \"variegated_horsetail, variegated_scouring_rush, equisetum_variegatum\",\n \"club_moss, club-moss, lycopod\",\n \"shining_clubmoss, lycopodium_lucidulum\",\n \"alpine_clubmoss, lycopodium_alpinum\",\n \"fir_clubmoss, mountain_clubmoss, little_clubmoss, lycopodium_selago\",\n \"ground_cedar, staghorn_moss, lycopodium_complanatum\",\n \"ground_fir, princess_pine, tree_clubmoss, lycopodium_obscurum\",\n \"foxtail_grass, lycopodium_alopecuroides\",\n \"spikemoss, spike_moss, little_club_moss\",\n \"meadow_spikemoss, basket_spikemoss, selaginella_apoda\",\n \"desert_selaginella, selaginella_eremophila\",\n \"resurrection_plant, rose_of_jericho, selaginella_lepidophylla\",\n \"florida_selaginella, selaginella_eatonii\",\n \"quillwort\",\n \"earthtongue, earth-tongue\",\n \"snuffbox_fern, meadow_fern, thelypteris_palustris_pubescens, dryopteris_thelypteris_pubescens\",\n \"christella\",\n \"mountain_fern, oreopteris_limbosperma, dryopteris_oreopteris\",\n \"new_york_fern, parathelypteris_novae-boracensis, dryopteris_noveboracensis\",\n \"massachusetts_fern, parathelypteris_simulata, thelypteris_simulata\",\n \"beech_fern\",\n \"broad_beech_fern, southern_beech_fern, phegopteris_hexagonoptera, dryopteris_hexagonoptera, thelypteris_hexagonoptera\",\n \"long_beech_fern, narrow_beech_fern, northern_beech_fern, phegopteris_connectilis, dryopteris_phegopteris, thelypteris_phegopteris\",\n \"shoestring_fungus\",\n \"armillaria_caligata, booted_armillaria\",\n \"armillaria_ponderosa, white_matsutake\",\n \"armillaria_zelleri\",\n \"honey_mushroom, honey_fungus, armillariella_mellea\",\n \"milkweed, silkweed\",\n \"white_milkweed, asclepias_albicans\",\n \"poke_milkweed, asclepias_exaltata\",\n \"swamp_milkweed, asclepias_incarnata\",\n \"mead's_milkweed, asclepias_meadii, asclepia_meadii\",\n \"purple_silkweed, asclepias_purpurascens\",\n \"showy_milkweed, asclepias_speciosa\",\n \"poison_milkweed, horsetail_milkweed, asclepias_subverticillata\",\n \"butterfly_weed, orange_milkweed, chigger_flower, chiggerflower, pleurisy_root, tuber_root, indian_paintbrush, asclepias_tuberosa\",\n \"whorled_milkweed, asclepias_verticillata\",\n \"cruel_plant, araujia_sericofera\",\n \"wax_plant, hoya_carnosa\",\n \"silk_vine, periploca_graeca\",\n \"stapelia, carrion_flower, starfish_flower\",\n \"stapelias_asterias\",\n \"stephanotis\",\n \"madagascar_jasmine, waxflower, stephanotis_floribunda\",\n \"negro_vine, vincetoxicum_hirsutum, vincetoxicum_negrum\",\n \"zygospore\",\n \"tree_of_knowledge\",\n \"orangery\",\n \"pocketbook\",\n \"shit, dump\",\n \"cordage\",\n \"yard, pace\",\n \"extremum, peak\",\n \"leaf_shape, leaf_form\",\n \"equilateral\",\n \"figure\",\n \"pencil\",\n \"plane_figure, two-dimensional_figure\",\n \"solid_figure, three-dimensional_figure\",\n \"line\",\n \"bulb\",\n \"convex_shape, convexity\",\n \"concave_shape, concavity, incurvation, incurvature\",\n \"cylinder\",\n \"round_shape\",\n \"heart\",\n \"polygon, polygonal_shape\",\n \"convex_polygon\",\n \"concave_polygon\",\n \"reentrant_polygon, reentering_polygon\",\n \"amorphous_shape\",\n \"closed_curve\",\n \"simple_closed_curve, jordan_curve\",\n \"s-shape\",\n \"wave, undulation\",\n \"extrados\",\n \"hook, crotchet\",\n \"envelope\",\n \"bight\",\n \"diameter\",\n \"cone, conoid, cone_shape\",\n \"funnel, funnel_shape\",\n \"oblong\",\n \"circle\",\n \"circle\",\n \"equator\",\n \"scallop, crenation, crenature, crenel, crenelle\",\n \"ring, halo, annulus, doughnut, anchor_ring\",\n \"loop\",\n \"bight\",\n \"helix, spiral\",\n \"element_of_a_cone\",\n \"element_of_a_cylinder\",\n \"ellipse, oval\",\n \"quadrate\",\n \"triangle, trigon, trilateral\",\n \"acute_triangle, acute-angled_triangle\",\n \"isosceles_triangle\",\n \"obtuse_triangle, obtuse-angled_triangle\",\n \"right_triangle, right-angled_triangle\",\n \"scalene_triangle\",\n \"parallel\",\n \"trapezoid\",\n \"star\",\n \"pentagon\",\n \"hexagon\",\n \"heptagon\",\n \"octagon\",\n \"nonagon\",\n \"decagon\",\n \"rhombus, rhomb, diamond\",\n \"spherical_polygon\",\n \"spherical_triangle\",\n \"convex_polyhedron\",\n \"concave_polyhedron\",\n \"cuboid\",\n \"quadrangular_prism\",\n \"bell, bell_shape, campana\",\n \"angular_distance\",\n \"true_anomaly\",\n \"spherical_angle\",\n \"angle_of_refraction\",\n \"acute_angle\",\n \"groove, channel\",\n \"rut\",\n \"bulge, bump, hump, swelling, gibbosity, gibbousness, jut, prominence, protuberance, protrusion, extrusion, excrescence\",\n \"belly\",\n \"bow, arc\",\n \"crescent\",\n \"ellipsoid\",\n \"hypotenuse\",\n \"balance, equilibrium, equipoise, counterbalance\",\n \"conformation\",\n \"symmetry, proportion\",\n \"spheroid, ellipsoid_of_revolution\",\n \"spherule\",\n \"toroid\",\n \"column, tower, pillar\",\n \"barrel, drum\",\n \"pipe, tube\",\n \"pellet\",\n \"bolus\",\n \"dewdrop\",\n \"ridge\",\n \"rim\",\n \"taper\",\n \"boundary, edge, bound\",\n \"incisure, incisura\",\n \"notch\",\n \"wrinkle, furrow, crease, crinkle, seam, line\",\n \"dermatoglyphic\",\n \"frown_line\",\n \"line_of_life, life_line, lifeline\",\n \"line_of_heart, heart_line, love_line, mensal_line\",\n \"crevice, cranny, crack, fissure, chap\",\n \"cleft\",\n \"roulette, line_roulette\",\n \"node\",\n \"tree, tree_diagram\",\n \"stemma\",\n \"brachium\",\n \"fork, crotch\",\n \"block, cube\",\n \"ovoid\",\n \"tetrahedron\",\n \"pentahedron\",\n \"hexahedron\",\n \"regular_polyhedron, regular_convex_solid, regular_convex_polyhedron, platonic_body, platonic_solid, ideal_solid\",\n \"polyhedral_angle\",\n \"cube, regular_hexahedron\",\n \"truncated_pyramid\",\n \"truncated_cone\",\n \"tail, tail_end\",\n \"tongue, knife\",\n \"trapezohedron\",\n \"wedge, wedge_shape, cuneus\",\n \"keel\",\n \"place, shoes\",\n \"herpes\",\n \"chlamydia\",\n \"wall\",\n \"micronutrient\",\n \"chyme\",\n \"ragweed_pollen\",\n \"pina_cloth\",\n \"chlorobenzylidenemalononitrile, cs_gas\",\n \"carbon, c, atomic_number_6\",\n \"charcoal, wood_coal\",\n \"rock, stone\",\n \"gravel, crushed_rock\",\n \"aflatoxin\",\n \"alpha-tocopheral\",\n \"leopard\",\n \"bricks_and_mortar\",\n \"lagging\",\n \"hydraulic_cement, portland_cement\",\n \"choline\",\n \"concrete\",\n \"glass_wool\",\n \"soil, dirt\",\n \"high_explosive\",\n \"litter\",\n \"fish_meal\",\n \"greek_fire\",\n \"culture_medium, medium\",\n \"agar, nutrient_agar\",\n \"blood_agar\",\n \"hip_tile, hipped_tile\",\n \"hyacinth, jacinth\",\n \"hydroxide_ion, hydroxyl_ion\",\n \"ice, water_ice\",\n \"inositol\",\n \"linoleum, lino\",\n \"lithia_water\",\n \"lodestone, loadstone\",\n \"pantothenic_acid, pantothen\",\n \"paper\",\n \"papyrus\",\n \"pantile\",\n \"blacktop, blacktopping\",\n \"tarmacadam, tarmac\",\n \"paving, pavement, paving_material\",\n \"plaster\",\n \"poison_gas\",\n \"ridge_tile\",\n \"roughcast\",\n \"sand\",\n \"spackle, spackling_compound\",\n \"render\",\n \"wattle_and_daub\",\n \"stucco\",\n \"tear_gas, teargas, lacrimator, lachrymator\",\n \"toilet_tissue, toilet_paper, bathroom_tissue\",\n \"linseed, flaxseed\",\n \"vitamin\",\n \"fat-soluble_vitamin\",\n \"water-soluble_vitamin\",\n \"vitamin_a, antiophthalmic_factor, axerophthol, a\",\n \"vitamin_a1, retinol\",\n \"vitamin_a2, dehydroretinol\",\n \"b-complex_vitamin, b_complex, vitamin_b_complex, vitamin_b, b_vitamin, b\",\n \"vitamin_b1, thiamine, thiamin, aneurin, antiberiberi_factor\",\n \"vitamin_b12, cobalamin, cyanocobalamin, antipernicious_anemia_factor\",\n \"vitamin_b2, vitamin_g, riboflavin, lactoflavin, ovoflavin, hepatoflavin\",\n \"vitamin_b6, pyridoxine, pyridoxal, pyridoxamine, adermin\",\n \"vitamin_bc, vitamin_m, folate, folic_acid, folacin, pteroylglutamic_acid, pteroylmonoglutamic_acid\",\n \"niacin, nicotinic_acid\",\n \"vitamin_d, calciferol, viosterol, ergocalciferol, cholecalciferol, d\",\n \"vitamin_e, tocopherol, e\",\n \"biotin, vitamin_h\",\n \"vitamin_k, naphthoquinone, antihemorrhagic_factor\",\n \"vitamin_k1, phylloquinone, phytonadione\",\n \"vitamin_k3, menadione\",\n \"vitamin_p, bioflavinoid, citrin\",\n \"vitamin_c, c, ascorbic_acid\",\n \"planking\",\n \"chipboard, hardboard\",\n \"knothole\"\n]","isConversational":false}}}],"truncated":false,"partial":false},"paginationData":{"pageIndex":0,"numItemsPerPage":100,"numTotalItems":10340,"offset":0,"length":100}},"jwt":"eyJhbGciOiJFZERTQSJ9.eyJyZWFkIjp0cnVlLCJwZXJtaXNzaW9ucyI6eyJyZXBvLmNvbnRlbnQucmVhZCI6dHJ1ZX0sImlhdCI6MTc3MzExODY3Niwic3ViIjoiL2RhdGFzZXRzL3N0ZXZlbmJ1Y2FpbGxlL2ltYWdlLWNsYXNzaWZpY2F0aW9uLW1vZGVscy1kYXRhc2V0IiwiZXhwIjoxNzczMTIyMjc2LCJpc3MiOiJodHRwczovL2h1Z2dpbmdmYWNlLmNvIn0.pGcV2dwFL6_wVKtDwt9yyzHeOgmqkauyYZOA3z0CjC-8ElSA4DyltKROM3nsUe_KJBkKyF0FVMSu2heQMdoWAw","displayUrls":true,"splitSizeSummaries":[{"config":"default","split":"train","numRows":10340,"numBytesParquet":14653461}]},"discussionsStats":{"closed":0,"open":1,"total":1},"fullWidth":true,"hasGatedAccess":true,"hasFullAccess":true,"isEmbedded":false,"savedQueries":{"community":[],"user":[]}}">

model_id stringlengths 7 105 | model_card stringlengths 1 130k | model_labels listlengths 2 80k |
|---|---|---|
Falconsai/nsfw_image_detection | # Model Card: Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification
## Model Description
The **Fine-Tuned Vision Transformer (ViT)** is a variant of the transformer encoder architecture, similar to BERT, that has been adapted for image classification tasks. This specific model, named "google/vit-base-patch16-224-in21k," is pre-trained on a substantial collection of images in a supervised manner, leveraging the ImageNet-21k dataset. The images in the pre-training dataset are resized to a resolution of 224x224 pixels, making it suitable for a wide range of image recognition tasks.
During the training phase, meticulous attention was given to hyperparameter settings to ensure optimal model performance. The model was fine-tuned with a judiciously chosen batch size of 16. This choice not only balanced computational efficiency but also allowed for the model to effectively process and learn from a diverse array of images.
To facilitate this fine-tuning process, a learning rate of 5e-5 was employed. The learning rate serves as a critical tuning parameter that dictates the magnitude of adjustments made to the model's parameters during training. In this case, a learning rate of 5e-5 was selected to strike a harmonious balance between rapid convergence and steady optimization, resulting in a model that not only learns swiftly but also steadily refines its capabilities throughout the training process.
This training phase was executed using a proprietary dataset containing an extensive collection of 80,000 images, each characterized by a substantial degree of variability. The dataset was thoughtfully curated to include two distinct classes, namely "normal" and "nsfw." This diversity allowed the model to grasp nuanced visual patterns, equipping it with the competence to accurately differentiate between safe and explicit content.
The overarching objective of this meticulous training process was to impart the model with a deep understanding of visual cues, ensuring its robustness and competence in tackling the specific task of NSFW image classification. The result is a model that stands ready to contribute significantly to content safety and moderation, all while maintaining the highest standards of accuracy and reliability.
## Intended Uses & Limitations
### Intended Uses
- **NSFW Image Classification**: The primary intended use of this model is for the classification of NSFW (Not Safe for Work) images. It has been fine-tuned for this purpose, making it suitable for filtering explicit or inappropriate content in various applications.
### How to use
Here is how to use this model to classifiy an image based on 1 of 2 classes (normal,nsfw):
```markdown
# Use a pipeline as a high-level helper
from PIL import Image
from transformers import pipeline
img = Image.open("<path_to_image_file>")
classifier = pipeline("image-classification", model="Falconsai/nsfw_image_detection")
classifier(img)
```
<hr>
``` markdown
# Load model directly
import torch
from PIL import Image
from transformers import AutoModelForImageClassification, ViTImageProcessor
img = Image.open("<path_to_image_file>")
model = AutoModelForImageClassification.from_pretrained("Falconsai/nsfw_image_detection")
processor = ViTImageProcessor.from_pretrained('Falconsai/nsfw_image_detection')
with torch.no_grad():
inputs = processor(images=img, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_label = logits.argmax(-1).item()
model.config.id2label[predicted_label]
```
<hr>
Run Yolo Version
``` markdown
import os
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import onnxruntime as ort
import json # Added import for json
# Predict using YOLOv9 model
def predict_with_yolov9(image_path, model_path, labels_path, input_size):
"""
Run inference using the converted YOLOv9 model on a single image.
Args:
image_path (str): Path to the input image file.
model_path (str): Path to the ONNX model file.
labels_path (str): Path to the JSON file containing class labels.
input_size (tuple): The expected input size (height, width) for the model.
Returns:
str: The predicted class label.
PIL.Image.Image: The original loaded image.
"""
def load_json(file_path):
with open(file_path, "r") as f:
return json.load(f)
# Load labels
labels = load_json(labels_path)
# Preprocess image
original_image = Image.open(image_path).convert("RGB")
image_resized = original_image.resize(input_size, Image.Resampling.BILINEAR)
image_np = np.array(image_resized, dtype=np.float32) / 255.0
image_np = np.transpose(image_np, (2, 0, 1)) # [C, H, W]
input_tensor = np.expand_dims(image_np, axis=0).astype(np.float32)
# Load YOLOv9 model
session = ort.InferenceSession(model_path)
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name # Assuming classification output
# Run inference
outputs = session.run([output_name], {input_name: input_tensor})
predictions = outputs[0]
# Postprocess predictions (assuming classification output)
# Adapt this section if your model output is different (e.g., detection boxes)
predicted_index = np.argmax(predictions)
predicted_label = labels[str(predicted_index)] # Assumes labels are indexed by string numbers
return predicted_label, original_image
# Display prediction for a single image
def display_single_prediction(image_path, model_path, labels_path, input_size):
"""
Predicts the class for a single image and displays the image with its prediction.
Args:
image_path (str): Path to the input image file.
model_path (str): Path to the ONNX model file.
labels_path (str): Path to the JSON file containing class labels.
input_size (tuple): The expected input size (height, width) for the model.
"""
try:
# Run prediction
prediction, img = predict_with_yolov9(image_path, model_path, labels_path, input_size)
# Display image and prediction
fig, ax = plt.subplots(1, 1, figsize=(8, 8)) # Create a single plot
ax.imshow(img)
ax.set_title(f"Prediction: {prediction}", fontsize=14)
ax.axis("off") # Hide axes ticks and labels
plt.tight_layout()
plt.show()
except FileNotFoundError:
print(f"Error: Image file not found at {image_path}")
except Exception as e:
print(f"An error occurred: {e}")
# --- Main Execution ---
# Paths and parameters - **MODIFY THESE**
single_image_path = "path/to/your/single_image.jpg" # <--- Replace with the actual path to your image file
model_path = "path/to/your/yolov9_model.onnx" # <--- Replace with the actual path to your ONNX model
labels_path = "path/to/your/labels.json" # <--- Replace with the actual path to your labels JSON file
input_size = (224, 224) # Standard input size, adjust if your model differs
# Check if the image file exists before proceeding (optional but recommended)
if os.path.exists(single_image_path):
# Run prediction and display for the single image
display_single_prediction(single_image_path, model_path, labels_path, input_size)
else:
print(f"Error: The specified image file does not exist: {single_image_path}")
```
<hr>
### Limitations
- **Specialized Task Fine-Tuning**: While the model is adept at NSFW image classification, its performance may vary when applied to other tasks.
- Users interested in employing this model for different tasks should explore fine-tuned versions available in the model hub for optimal results.
## Training Data
The model's training data includes a proprietary dataset comprising approximately 80,000 images. This dataset encompasses a significant amount of variability and consists of two distinct classes: "normal" and "nsfw." The training process on this data aimed to equip the model with the ability to distinguish between safe and explicit content effectively.
### Training Stats
``` markdown
- 'eval_loss': 0.07463177293539047,
- 'eval_accuracy': 0.980375,
- 'eval_runtime': 304.9846,
- 'eval_samples_per_second': 52.462,
- 'eval_steps_per_second': 3.279
```
<hr>
**Note:** It's essential to use this model responsibly and ethically, adhering to content guidelines and applicable regulations when implementing it in real-world applications, particularly those involving potentially sensitive content.
For more details on model fine-tuning and usage, please refer to the model's documentation and the model hub.
## References
- [Hugging Face Model Hub](https://huggingface.co/models)
- [Vision Transformer (ViT) Paper](https://arxiv.org/abs/2010.11929)
- [ImageNet-21k Dataset](http://www.image-net.org/)
**Disclaimer:** The model's performance may be influenced by the quality and representativeness of the data it was fine-tuned on. Users are encouraged to assess the model's suitability for their specific applications and datasets. | [
"normal",
"nsfw"
] |
google/vit-base-patch16-224 |
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTImageProcessor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/vit.html#).
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-tiny-224 |
# ConvNeXT (tiny-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.
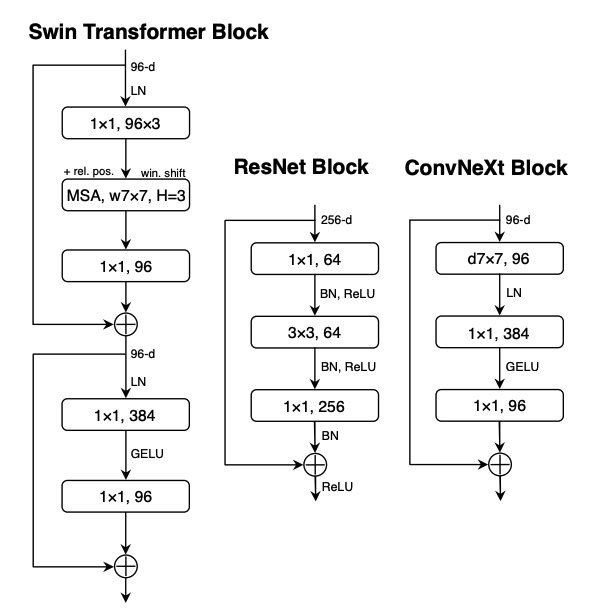
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-tiny-224")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
dima806/facial_emotions_image_detection | Returns facial emotion with about 91% accuracy based on facial human image.
See https://www.kaggle.com/code/dima806/facial-emotions-image-detection-vit for more details.

```
Classification report:
precision recall f1-score support
sad 0.8394 0.8632 0.8511 3596
disgust 0.9909 1.0000 0.9954 3596
angry 0.9022 0.9035 0.9028 3595
neutral 0.8752 0.8626 0.8689 3595
fear 0.8788 0.8532 0.8658 3596
surprise 0.9476 0.9449 0.9463 3596
happy 0.9302 0.9372 0.9336 3596
accuracy 0.9092 25170
macro avg 0.9092 0.9092 0.9091 25170
weighted avg 0.9092 0.9092 0.9091 25170
``` | [
"sad",
"disgust",
"angry",
"neutral",
"fear",
"surprise",
"happy"
] |
dima806/fairface_age_image_detection | Detects age group with about 59% accuracy based on an image.
See https://www.kaggle.com/code/dima806/age-group-image-classification-vit for details.

```
Classification report:
precision recall f1-score support
0-2 0.7803 0.7500 0.7649 180
3-9 0.7998 0.7998 0.7998 1249
10-19 0.5361 0.4236 0.4733 1086
20-29 0.6402 0.7221 0.6787 3026
30-39 0.4935 0.5083 0.5008 2099
40-49 0.4848 0.4386 0.4606 1238
50-59 0.5000 0.4814 0.4905 725
60-69 0.4497 0.4685 0.4589 286
more than 70 0.6897 0.1802 0.2857 111
accuracy 0.5892 10000
macro avg 0.5971 0.5303 0.5459 10000
weighted avg 0.5863 0.5892 0.5844 10000
``` | [
"0-2",
"3-9",
"10-19",
"20-29",
"30-39",
"40-49",
"50-59",
"60-69",
"more than 70"
] |
WinKawaks/vit-small-patch16-224 |
Google didn't publish vit-tiny and vit-small model checkpoints in Hugging Face. I converted the weights from the [timm repository](https://github.com/rwightman/pytorch-image-models). This model is used in the same way as [ViT-base](https://huggingface.co/google/vit-base-patch16-224).
Note that [safetensors] model requires torch 2.0 environment. | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/beit-large-patch16-512 |
# BEiT (large-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 512x512. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-large-patch16-512')
model = BeitForImageClassification.from_pretrained('microsoft/beit-large-patch16-512')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/resnet-50 |
# ResNet-50 v1.5
ResNet model pre-trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by He et al.
Disclaimer: The team releasing ResNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ResNet (Residual Network) is a convolutional neural network that democratized the concepts of residual learning and skip connections. This enables to train much deeper models.
This is ResNet v1.5, which differs from the original model: in the bottleneck blocks which require downsampling, v1 has stride = 2 in the first 1x1 convolution, whereas v1.5 has stride = 2 in the 3x3 convolution. This difference makes ResNet50 v1.5 slightly more accurate (\~0.5% top1) than v1, but comes with a small performance drawback (~5% imgs/sec) according to [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch).

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=resnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, ResNetForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = AutoImageProcessor.from_pretrained("microsoft/resnet-50")
model = ResNetForImageClassification.from_pretrained("microsoft/resnet-50")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/resnet).
### BibTeX entry and citation info
```bibtex
@inproceedings{he2016deep,
title={Deep residual learning for image recognition},
author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
pages={770--778},
year={2016}
}
```
| [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
Devarshi/Brain_Tumor_Classification |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Brain_Tumor_Classification
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1012
- Accuracy: 0.9647
- F1: 0.9647
- Recall: 0.9647
- Precision: 0.9647
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Recall | Precision |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:------:|:---------:|
| 0.4856 | 0.99 | 83 | 0.3771 | 0.8444 | 0.8444 | 0.8444 | 0.8444 |
| 0.3495 | 1.99 | 166 | 0.2608 | 0.8949 | 0.8949 | 0.8949 | 0.8949 |
| 0.252 | 2.99 | 249 | 0.1445 | 0.9487 | 0.9487 | 0.9487 | 0.9487 |
| 0.2364 | 3.99 | 332 | 0.1029 | 0.9588 | 0.9588 | 0.9588 | 0.9588 |
| 0.2178 | 4.99 | 415 | 0.1012 | 0.9647 | 0.9647 | 0.9647 | 0.9647 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
| [
"glioma_tumor",
"meningioma_tumor",
"no_tumor",
"pituitary_tumor"
] |
tonyassi/vogue-fashion-collection-15 |
# vogue-fashion-collection-15
## Model description
This model classifies an image into a fashion collection. It is trained on the [tonyassi/vogue-runway-top15-512px](https://huggingface.co/datasets/tonyassi/vogue-runway-top15-512px) dataset and fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k).
Try the [demo](https://huggingface.co/spaces/tonyassi/which-fashion-collection).
## Dataset description
[tonyassi/vogue-runway-top15-512px](https://huggingface.co/datasets/tonyassi/vogue-runway-top15-512px)
- 15 fashion houses
- 1679 collections
- 87,547 images
### How to use
```python
from transformers import pipeline
# Initialize image classification pipeline
pipe = pipeline("image-classification", model="tonyassi/vogue-fashion-collection-15")
# Perform classification
result = pipe('image.png')
# Print results
print(result)
```
## Examples

**fendi,spring 2023 couture**

**gucci,spring 2017 ready to wear**

**prada,fall 2018 ready to wear**
## Training and evaluation data
It achieves the following results on the evaluation set:
- Loss: 0.1795
- Accuracy: 0.9454
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 15
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0 | [
"alexander mcqueen,fall 1996 ready to wear",
"alexander mcqueen,fall 1997 ready to wear",
"alexander mcqueen,fall 2005 ready to wear",
"alexander mcqueen,spring 2012 menswear",
"louis vuitton,pre fall 2009",
"louis vuitton,pre fall 2010",
"louis vuitton,pre fall 2011",
"louis vuitton,pre fall 2012",
... |
glazzova/body_type | # body_type
Эта модель дообучена на [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50) с помощью
датасета, который содержит фотографии мужчин разных телосложений. Модель может определяет являетесь ли вы качком, скуфом, дрищом
или просто нормальным.
### Запуск модели
```python
import torch
from PIL import Image
from transformers import ResNetForImageClassification, AutoImageProcessor
processor = AutoImageProcessor.from_pretrained("glazzova/body_type")
model = ResNetForImageClassification.from_pretrained('glazzova/body_type')
image = Image.open('your_pic.jpeg')
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 4 classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]) | [
"skinny",
"ordinary",
"overweight",
"hulk"
] |
carlosleao/FER-Facial-Expression-Recognition |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FER-Facial-Expression-Recognition
This model is a fine-tuned version of [motheecreator/vit-Facial-Expression-Recognition](https://huggingface.co/motheecreator/vit-Facial-Expression-Recognition) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4710
- Accuracy: 0.8474
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 1.8868 | 0.8959 | 100 | 1.7638 | 0.5923 |
| 1.2277 | 1.7962 | 200 | 1.1092 | 0.7253 |
| 0.8414 | 2.6965 | 300 | 0.8105 | 0.8041 |
| 0.7076 | 3.5969 | 400 | 0.6746 | 0.8256 |
| 0.6079 | 4.4972 | 500 | 0.6111 | 0.8287 |
| 0.5624 | 5.3975 | 600 | 0.5529 | 0.8379 |
| 0.5254 | 6.2979 | 700 | 0.5266 | 0.8399 |
| 0.4784 | 7.1982 | 800 | 0.4978 | 0.8433 |
| 0.4634 | 8.0985 | 900 | 0.4844 | 0.8458 |
| 0.4305 | 8.9944 | 1000 | 0.4710 | 0.8474 |
| 0.3995 | 9.8947 | 1100 | 0.4381 | 0.8564 |
### Framework versions
- Transformers 4.46.2
- Pytorch 2.5.1+cu124
- Datasets 3.1.0
- Tokenizers 0.20.3
| [
"neutral",
"happiness",
"surprise",
"sadness",
"anger",
"disgust",
"fear",
"contempt"
] |
Ateeqq/ai-vs-human-image-detector |
# AI and Human Image Classification Model
A fine-tuned model trained on 60,000 AI-generated and 60,000 human images.
The model demonstrates strong capability in detecting high-quality, state-of-the-art AI-generated images from models such as Midjourney v6.1, Flux 1.1 Pro, Stable Diffusion 3.5, GPT-4o, and other trending generation models.
Detailed Training Code is available here: [blog/ai/fine-tuning-siglip2](https://exnrt.com/blog/ai/fine-tuning-siglip2/)
## Evaluation Metrics

### 🏋️♂️ Train Metrics
- **Epoch:** 5.0
- **Total FLOPs:** 51,652,280,821 GF
- **Train Loss:** 0.0799
- **Train Runtime:** 2:39:49.46
- **Train Samples/Sec:** 69.053
- **Train Steps/Sec:** 4.316
### 📊 Evaluation Metrics (Fine-Tuned Model on Test Set)
- **Epoch:** 5.0
- **Eval Accuracy:** 0.9923
- **Eval Loss:** 0.0551
- **Eval Runtime:** 0:02:35.78
- **Eval Samples/Sec:** 212.533
- **Eval Steps/Sec:** 6.644
### 🔦 Prediction Metrics (on test set):
```
{
"test_loss": 0.05508904904127121,
"test_accuracy": 0.9923283699296264,
"test_runtime": 167.1844,
"test_samples_per_second": 198.039,
"test_steps_per_second": 6.191
}
```
* Final Test Accuracy: 0.9923
* Final Test F1 Score (Macro): 0.9923
* Final Test F1 Score (Weighted): 0.9923
## Usage
```
pip install -q transformers torch Pillow accelerate
```
```python
import torch
from PIL import Image as PILImage
from transformers import AutoImageProcessor, SiglipForImageClassification
MODEL_IDENTIFIER = r"Ateeqq/ai-vs-human-image-detector"
# Device: Use GPU if available, otherwise CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# Load Model and Processor
try:
print(f"Loading processor from: {MODEL_IDENTIFIER}")
processor = AutoImageProcessor.from_pretrained(MODEL_IDENTIFIER)
print(f"Loading model from: {MODEL_IDENTIFIER}")
model = SiglipForImageClassification.from_pretrained(MODEL_IDENTIFIER)
model.to(device)
model.eval()
print("Model and processor loaded successfully.")
except Exception as e:
print(f"Error loading model or processor: {e}")
exit()
# Load and Preprocess the Image
IMAGE_PATH = r"/content/images.jpg"
try:
print(f"Loading image: {IMAGE_PATH}")
image = PILImage.open(IMAGE_PATH).convert("RGB")
except FileNotFoundError:
print(f"Error: Image file not found at {IMAGE_PATH}")
exit()
except Exception as e:
print(f"Error opening image: {e}")
exit()
print("Preprocessing image...")
# Use the processor to prepare the image for the model
inputs = processor(images=image, return_tensors="pt").to(device)
# Perform Inference
print("Running inference...")
with torch.no_grad(): # Disable gradient calculations for inference
outputs = model(**inputs)
logits = outputs.logits
# Interpret the Results
# Get the index of the highest logit score -> this is the predicted class ID
predicted_class_idx = logits.argmax(-1).item()
# Use the model's config to map the ID back to the label string ('ai' or 'hum')
predicted_label = model.config.id2label[predicted_class_idx]
# Optional: Get probabilities using softmax
probabilities = torch.softmax(logits, dim=-1)
predicted_prob = probabilities[0, predicted_class_idx].item()
print("-" * 30)
print(f"Image: {IMAGE_PATH}")
print(f"Predicted Label: {predicted_label}")
print(f"Confidence Score: {predicted_prob:.4f}")
print("-" * 30)
# You can also print the scores for all classes:
print("Scores per class:")
for i, label in model.config.id2label.items():
print(f" - {label}: {probabilities[0, i].item():.4f}")
```
## Output
```
Using device: cpu
Model and processor loaded successfully.
Loading image: /content/images.jpg
Preprocessing image...
Running inference...
------------------------------
Image: /content/images.jpg
Predicted Label: ai
Confidence Score: 0.9996
------------------------------
Scores per class:
- ai: 0.9996
- hum: 0.0004
``` | [
"ai",
"hum"
] |
prithivMLmods/Hand-Gesture-2-Robot |

# **Hand-Gesture-2-Robot**
> **Hand-Gesture-2-Robot** is an image classification vision-language encoder model fine-tuned from **google/siglip2-base-patch16-224** for a single-label classification task. It is designed to recognize hand gestures and map them to specific robot commands using the **SiglipForImageClassification** architecture.
```py
Classification Report:
precision recall f1-score support
"rotate anticlockwise" 0.9926 0.9958 0.9942 944
"increase" 0.9975 0.9975 0.9975 789
"release" 0.9941 1.0000 0.9970 670
"switch" 1.0000 0.9986 0.9993 728
"look up" 0.9984 0.9984 0.9984 635
"Terminate" 0.9983 1.0000 0.9991 580
"decrease" 0.9942 1.0000 0.9971 684
"move backward" 0.9986 0.9972 0.9979 725
"point" 0.9965 0.9913 0.9939 1716
"rotate clockwise" 1.0000 1.0000 1.0000 868
"grasp" 0.9922 0.9961 0.9941 767
"pause" 0.9991 1.0000 0.9995 1079
"move forward" 1.0000 0.9944 0.9972 886
"Confirm" 0.9983 0.9983 0.9983 573
"look down" 0.9985 0.9970 0.9977 664
"move left" 0.9952 0.9968 0.9960 622
"move right" 1.0000 1.0000 1.0000 622
accuracy 0.9972 13552
macro avg 0.9973 0.9977 0.9975 13552
weighted avg 0.9972 0.9972 0.9972 13552
```

The model categorizes hand gestures into 17 different robot commands:
- **Class 0:** "rotate anticlockwise"
- **Class 1:** "increase"
- **Class 2:** "release"
- **Class 3:** "switch"
- **Class 4:** "look up"
- **Class 5:** "Terminate"
- **Class 6:** "decrease"
- **Class 7:** "move backward"
- **Class 8:** "point"
- **Class 9:** "rotate clockwise"
- **Class 10:** "grasp"
- **Class 11:** "pause"
- **Class 12:** "move forward"
- **Class 13:** "Confirm"
- **Class 14:** "look down"
- **Class 15:** "move left"
- **Class 16:** "move right"
# **Run with Transformers🤗**
```python
!pip install -q transformers torch pillow gradio
```
```python
import gradio as gr
from transformers import AutoImageProcessor
from transformers import SiglipForImageClassification
from transformers.image_utils import load_image
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/Hand-Gesture-2-Robot"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
def gesture_classification(image):
"""Predicts the robot command from a hand gesture image."""
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
labels = {
"0": "rotate anticlockwise",
"1": "increase",
"2": "release",
"3": "switch",
"4": "look up",
"5": "Terminate",
"6": "decrease",
"7": "move backward",
"8": "point",
"9": "rotate clockwise",
"10": "grasp",
"11": "pause",
"12": "move forward",
"13": "Confirm",
"14": "look down",
"15": "move left",
"16": "move right"
}
predictions = {labels[str(i)]: round(probs[i], 3) for i in range(len(probs))}
return predictions
# Create Gradio interface
iface = gr.Interface(
fn=gesture_classification,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(label="Prediction Scores"),
title="Hand Gesture to Robot Command",
description="Upload an image of a hand gesture to predict the corresponding robot command."
)
# Launch the app
if __name__ == "__main__":
iface.launch()
```
# **Intended Use:**
The **Hand-Gesture-2-Robot** model is designed to classify hand gestures into corresponding robot commands. Potential use cases include:
- **Human-Robot Interaction:** Enabling intuitive control of robots using hand gestures.
- **Assistive Technology:** Helping individuals with disabilities communicate commands.
- **Industrial Automation:** Enhancing robotic operations in manufacturing.
- **Gaming & VR:** Providing gesture-based controls for immersive experiences.
- **Security & Surveillance:** Implementing gesture-based access control. | [
"\"rotate anticlockwise\"",
"\"increase\"",
"\"release\"",
"\"switch\"",
"\"look up\"",
"\"terminate\"",
"\"decrease\"",
"\"move backward\"",
"\"point\"",
"\"rotate clockwise\"",
"\"grasp\"",
"\"pause\"",
"\"move forward\"",
"\"confirm\"",
"\"look down\"",
"\"move left\"",
"\"move ri... |
prithivMLmods/Fashion-Product-Season |

# **Fashion-Product-Season**
> **Fashion-Product-Season** is a vision-language model fine-tuned from **google/siglip2-base-patch16-224** using the **SiglipForImageClassification** architecture. It classifies fashion product images based on their suitable **season of use**.
```py
Classification Report:
precision recall f1-score support
Fall 0.6173 0.5655 0.5903 11414
Spring 0.9738 0.7665 0.8578 2711
Summer 0.7051 0.8107 0.7542 21438
Winter 0.8007 0.6432 0.7134 8509
accuracy 0.7121 44072
macro avg 0.7742 0.6965 0.7289 44072
weighted avg 0.7174 0.7121 0.7103 44072
```
The model predicts one of the following **season categories**:
- **0:** Fall
- **1:** Spring
- **2:** Summer
- **3:** Winter
---
# **Run with Transformers 🤗**
```python
!pip install -q transformers torch pillow gradio
```
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/Fashion-Product-Season" # Replace with your actual model path
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
0: "Fall",
1: "Spring",
2: "Summer",
3: "Winter"
}
def classify_season(image):
"""Predicts the most suitable season for a fashion product."""
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
predictions = {id2label[i]: round(probs[i], 3) for i in range(len(probs))}
predictions = dict(sorted(predictions.items(), key=lambda item: item[1], reverse=True))
return predictions
# Gradio interface
iface = gr.Interface(
fn=classify_season,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(label="Season Prediction Scores"),
title="Fashion-Product-Season",
description="Upload a fashion product image to predict its most suitable season (Fall, Spring, Summer, Winter)."
)
# Launch the app
if __name__ == "__main__":
iface.launch()
```
---
# **Intended Use**
This model can be used for:
- **Seasonal tagging in fashion e-commerce**
- **Improved recommendations for seasonal shopping trends**
- **Inventory planning based on product seasonality**
- **Data labeling for fashion-specific recommendation engines** | [
"fall",
"spring",
"summer",
"winter"
] |
prithivMLmods/siglip2-x256-explicit-content |

# **siglip2-x256-explicit-content**
> **siglip2-x256-explicit-content** is a vision-language encoder model fine-tuned from **siglip2-base-patch16-256** for **multi-class image classification**. Built on the **SiglipForImageClassification** architecture, the model is trained to identify and categorize content types in images, especially for **explicit, suggestive, or safe media filtering**.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
```py
Classification Report:
precision recall f1-score support
Anime Picture 0.8940 0.8718 0.8827 5600
Hentai 0.8961 0.8935 0.8948 4180
Normal 0.9100 0.8895 0.8997 5503
Pornography 0.9496 0.9654 0.9574 5600
Enticing or Sensual 0.9132 0.9429 0.9278 5600
accuracy 0.9137 26483
macro avg 0.9126 0.9126 0.9125 26483
weighted avg 0.9135 0.9137 0.9135 26483
```

---
## **Label Space: 5 Classes**
The model classifies each image into one of the following content categories:
```
Class 0: "Anime Picture"
Class 1: "Hentai"
Class 2: "Normal"
Class 3: "Pornography"
Class 4: "Enticing or Sensual"
```
---
## **Install Dependencies**
```bash
pip install -q transformers torch pillow gradio
```
---
## **Inference Code**
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/siglip2-x256-explicit-content" # Replace with your model path if needed
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# ID to Label mapping
id2label = {
"0": "Anime Picture",
"1": "Hentai",
"2": "Normal",
"3": "Pornography",
"4": "Enticing or Sensual"
}
def classify_explicit_content(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_explicit_content,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=5, label="Predicted Content Type"),
title="siglip2-x256-explicit-content",
description="Classifies images into explicit, suggestive, or safe categories (e.g., Hentai, Pornography, Normal)."
)
if __name__ == "__main__":
iface.launch()
```
---
## **Intended Use**
This model is intended for applications such as:
- **Content Moderation**: Automatically detect NSFW or suggestive content.
- **Parental Controls**: Enable AI-based filtering for safe media browsing.
- **Dataset Preprocessing**: Clean and categorize image datasets for research or deployment.
- **Online Platforms**: Help enforce content guidelines for uploads and user-generated media. | [
"anime picture",
"hentai",
"normal",
"pornography",
"enticing or sensual"
] |
prithivMLmods/open-scene-detection |

# open-scene-detection
> open-scene-detection is a vision-language encoder model fine-tuned from [`siglip2-base-patch16-512`](https://huggingface.co/google/siglip-base-patch16-512) for multi-class scene classification. It is trained to recognize and categorize natural and urban scenes using a curated visual dataset. The model uses the `SiglipForImageClassification` architecture.
```py
Classification Report:
precision recall f1-score support
buildings 0.9755 0.9570 0.9662 2625
forest 0.9989 0.9955 0.9972 2694
glacier 0.9564 0.9517 0.9540 2671
mountain 0.9540 0.9592 0.9566 2723
sea 0.9934 0.9898 0.9916 2758
street 0.9595 0.9819 0.9706 2874
accuracy 0.9728 16345
macro avg 0.9730 0.9725 0.9727 16345
weighted avg 0.9729 0.9728 0.9728 16345
```

---
## Label Space: 6 Classes
The model classifies an image into one of the following scenes:
```
Class 0: Buildings
Class 1: Forest
Class 2: Glacier
Class 3: Mountain
Class 4: Sea
Class 5: Street
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/open-scene-detection" # Updated model name
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Updated label mapping
id2label = {
"0": "Buildings",
"1": "Forest",
"2": "Glacier",
"3": "Mountain",
"4": "Sea",
"5": "Street"
}
def classify_image(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=6, label="Scene Classification"),
title="open-scene-detection",
description="Upload an image to classify the scene into one of six categories: Buildings, Forest, Glacier, Mountain, Sea, or Street."
)
if __name__ == "__main__":
iface.launch()
```
---
## Intended Use
`open-scene-detection` is designed for:
* **Scene Recognition** – Automatically classify natural and urban scenes.
* **Environmental Mapping** – Support geographic and ecological analysis from visual data.
* **Dataset Annotation** – Efficiently label large-scale image datasets by scene.
* **Visual Search and Organization** – Enable smart scene-based filtering or retrieval.
* **Autonomous Systems** – Assist navigation and perception modules with scene understanding. | [
"buildings",
"forest",
"glacier",
"mountain",
"sea",
"street"
] |
LukeXOTWOD/vit-base-fruits-360 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-fruits-360
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the Boosso/fruits-360 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0005
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.0078 | 1.0 | 3385 | 0.0086 | 0.9999 |
| 0.0067 | 2.0 | 6770 | 0.0027 | 0.9999 |
| 0.001 | 3.0 | 10155 | 0.0012 | 0.9999 |
| 0.0005 | 4.0 | 13540 | 0.0006 | 1.0 |
| 0.0003 | 5.0 | 16925 | 0.0005 | 1.0 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
| [
"apple braeburn",
"apple crimson snow",
"apple golden",
"apple granny smith",
"apple pink lady",
"apple red",
"apple red delicious",
"apple red yellow",
"apricot",
"avocado",
"avocado ripe",
"banana",
"banana lady finger",
"banana red",
"beetroot",
"blueberry",
"cactus fruit",
"can... |
Ateeqq/nsfw-image-detection |
# NSFW Image Detection – A Top Performer
This model is fine-tuned for **NSFW image classification**. It classifies content into three safety-critical categories, making it useful for moderation, safety filtering, and compliant content handling systems.
<p>
<a href="https://exnrt.com/blog/ai/fine-tuning-siglip2/" target="_blank">
<img src="https://img.shields.io/badge/View%20Training%20Code-blue?style=for-the-badge&logo=readthedocs"/>
</a>
<a href="https://exnrt.com/blog/ai/fine-tuning-siglip2/" target="_blank">https://exnrt.com/blog/ai/fine-tuning-siglip2/</a>
</p>
---
## 🚀 Usage Example
```python
import torch
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch.nn.functional as F
model_path = "Ateeqq/nsfw-image-detection"
processor = AutoImageProcessor.from_pretrained(model_path)
model = SiglipForImageClassification.from_pretrained(model_path)
image_path = r"/content/download.jpg"
image = Image.open(image_path).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
probabilities = F.softmax(logits, dim=1)
predicted_class_id = logits.argmax().item()
predicted_class_label = model.config.id2label[predicted_class_id]
confidence_scores = probabilities[0].tolist()
print(f"Predicted class ID: {predicted_class_id}")
print(f"Predicted class label: {predicted_class_label}\n")
for i, score in enumerate(confidence_scores):
label = model.config.id2label[i]
print(f"Confidence for '{label}': {score:.6f}")
```
## Output
```
Predicted class ID: 2
Predicted class label: safe_normal
Confidence for 'gore_bloodshed_violent': 0.000002
Confidence for 'nudity_pornography': 0.000005
Confidence for 'safe_normal': 0.999993
```
---
## 🧠 Model Details
* **Base model**: `google/siglip2-base-patch16-224`
* **Task**: Image Classification (NSFW/Safe detection)
* **Framework**: PyTorch / Hugging Face Transformers
* **Fine-tuned on**: Custom dataset with 3 content categories
* **Selected checkpoint**: Epoch 5
* **Batch size**: 64
* **Epochs trained**: 5
---
### 📌 Confusion Matrix

---
### 🏷️ Categories
| ID | Label |Excluded|
| -- | ---------------------------|---------------|
| 0 | ✅`gore_bloodshed_violent` |❌ Fight, Accident, Angry|
| 1 | ✅`nudity_pornography` |❌ Normal Romance, Normal Kissing|
| 2 | ✅`safe_normal` |❌ |
### 🧾 Label Mapping
```python
label2id = {'gore_bloodshed_violent': 0, 'nudity_pornography': 1, 'safe_normal': 2}
id2label = {0: 'gore_bloodshed_violent', 1: 'nudity_pornography', 2: 'safe_normal'}
```
---
## 📊 Training Metrics (Epoch 5 Selected ✅)
| Epoch | Training Loss | Validation Loss | Accuracy |
| ----- | ------------- | --------------- | ---------- |
| 1 | 0.0765 | 0.1166 | 95.70% |
| 2 | 0.0719 | 0.0477 | 98.34% |
| 3 | 0.0089 | 0.0634 | 98.05% |
| 4 | 0.0109 | 0.0437 | 98.61% |
| 5 ✅ | 0.0001 | 0.0389 | **99.02%** |
### 📌 Epoch Training Results

- **Training runtime**: 1h 21m 40s
- **Final Training Loss**: 0.0727
- **Steps/sec**: 0.11 | **Samples/sec**: 6.99 | [
"gore_bloodshed_violent",
"nudity_pornography",
"safe_normal"
] |
AkshatSurolia/BEiT-FaceMask-Finetuned |
# BEiT for Face Mask Detection
BEiT model pre-trained and fine-tuned on Self Currated Custom Face-Mask18K Dataset (18k images, 2 classes) at resolution 224x224. It was introduced in the paper BEIT: BERT Pre-Training of Image Transformers by Hangbo Bao, Li Dong and Furu Wei.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches. Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Training Metrics
epoch = 0.55
total_flos = 576468516GF
train_loss = 0.151
train_runtime = 0:58:16.56
train_samples_per_second = 16.505
train_steps_per_second = 1.032
---
## Evaluation Metrics
epoch = 0.55
eval_accuracy = 0.975
eval_loss = 0.0803
eval_runtime = 0:03:13.02
eval_samples_per_second = 18.629
eval_steps_per_second = 2.331 | [
"no mask",
"mask"
] |
AkshatSurolia/ConvNeXt-FaceMask-Finetuned |
# ConvNeXt for Face Mask Detection
ConvNeXt model pre-trained and fine-tuned on Self Currated Custom Face-Mask18K Dataset (18k images, 2 classes) at resolution 224x224. It was introduced in the paper A ConvNet for the 2020s by Zhuang Liu, Hanzi Mao et al.
## Training Metrics
epoch = 3.54
total_flos = 1195651761GF
train_loss = 0.0079
train_runtime = 1:08:20.25
train_samples_per_second = 14.075
train_steps_per_second = 0.22
---
## Evaluation Metrics
epoch = 3.54
eval_accuracy = 0.9961
eval_loss = 0.0151
eval_runtime = 0:01:23.47
eval_samples_per_second = 43.079
eval_steps_per_second = 5.391 | [
"no mask",
"mask"
] |
AkshatSurolia/DeiT-FaceMask-Finetuned |
# Distilled Data-efficient Image Transformer for Face Mask Detection
Distilled data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on Self Currated Custom Face-Mask18K Dataset (18k images, 2 classes) at resolution 224x224. It was first introduced in the paper Training data-efficient image transformers & distillation through attention by Touvron et al.
## Model description
This model is a distilled Vision Transformer (ViT). It uses a distillation token, besides the class token, to effectively learn from a teacher (CNN) during both pre-training and fine-tuning. The distillation token is learned through backpropagation, by interacting with the class ([CLS]) and patch tokens through the self-attention layers.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
## Training Metrics
epoch = 2.0
total_flos = 2078245655GF
train_loss = 0.0438
train_runtime = 1:37:16.87
train_samples_per_second = 9.887
train_steps_per_second = 0.309
---
## Evaluation Metrics
epoch = 2.0
eval_accuracy = 0.9922
eval_loss = 0.0271
eval_runtime = 0:03:17.36
eval_samples_per_second = 18.22
eval_steps_per_second = 2.28 | [
"no mask",
"mask"
] |
AkshatSurolia/ViT-FaceMask-Finetuned |
# Vision Transformer (ViT) for Face Mask Detection
Vision Transformer (ViT) model pre-trained and fine-tuned on Self Currated Custom Face-Mask18K Dataset (18k images, 2 classes) at resolution 224x224. It was first introduced in the paper Training data-efficient image transformers & distillation through attention by Touvron et al.
Vision Transformer (ViT) model pre-trained and fine-tuned on Self Currated Custom Face-Mask18K Dataset (18k images, 2 classes) at resolution 224x224. It was introduced in the paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale by Dosovitskiy et al.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not provide any fine-tuned heads, as these were zero'd by Google researchers. However, the model does include the pre-trained pooler, which can be used for downstream tasks (such as image classification).
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Training Metrics
epoch = 0.89
total_flos = 923776502GF
train_loss = 0.057
train_runtime = 0:40:10.40
train_samples_per_second = 23.943
train_steps_per_second = 1.497
---
## Evaluation Metrics
epoch = 0.89
eval_accuracy = 0.9894
eval_loss = 0.0395
eval_runtime = 0:00:36.81
eval_samples_per_second = 97.685
eval_steps_per_second = 12.224 | [
"no mask",
"mask"
] |
NhatPham/vit-base-patch16-224-recylce-ft |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ## labels
- 0: Object
- 1: Recycle
- 2: Non-Recycle
# vit-base-patch16-224
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1510
- Accuracy: 0.9443
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 60
- eval_batch_size: 60
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 240
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1438 | 1.0 | 150 | 0.1645 | 0.9353 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
| [
"object",
"recycle",
"non-recycle "
] |
Rajaram1996/FacialEmoRecog |
# metrics:
# - accuracy
# model-index:
# - name: FacialEmoRecog
# results:
# - task:
# name: Image Classification
# type: image-classification
# - metrics:
# name: Accuracy
# type: accuracy
# value: 0.9189583659172058
# FacialEmoRecog
Create your own image classifier for **anything** by running this repo
## Example Images | [
"anger",
"contempt",
"disgust",
"fear",
"happy",
"neutral",
"sadness",
"surprise"
] |
WinKawaks/vit-tiny-patch16-224 |
Google didn't publish vit-tiny and vit-small model checkpoints in Hugging Face. I converted the weights from the [timm repository](https://github.com/rwightman/pytorch-image-models). This model is used in the same way as [ViT-base](https://huggingface.co/google/vit-base-patch16-224).
Note that [safetensors] model requires torch 2.0 environment. | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
addy88/perceiver_image_classifier | ### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationLearned
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("addy88/perceiver_image_classifier")
model = PerceiverForImageClassificationLearned.from_pretrained("addy88/perceiver_image_classifier")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare input
encoding = feature_extractor(image, return_tensors="pt")
inputs = encoding.pixel_values
# forward pass
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
``` | [
"apple",
"aquarium_fish",
"baby",
"bear",
"beaver",
"bed",
"bee",
"beetle",
"bicycle",
"bottle",
"bowl",
"boy",
"bridge",
"bus",
"butterfly",
"camel",
"can",
"castle",
"caterpillar",
"cattle",
"chair",
"chimpanzee",
"clock",
"cloud",
"cockroach",
"couch",
"cra",
... |
akahana/vit-base-cats-vs-dogs |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-cats-vs-dogs
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the cats_vs_dogs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0369
- Accuracy: 0.9883
## how to use
```python
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
model = ViTModel.from_pretrained('akahana/vit-base-cats-vs-dogs')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0949 | 1.0 | 2488 | 0.0369 | 0.9883 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
| [
"cat",
"dog"
] |
davanstrien/convnext_flyswot |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext_flyswot
This model is a fine-tuned version of [facebook/convnext-base-224-22k](https://huggingface.co/facebook/convnext-base-224-22k) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1441
- F1: 0.9592
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 666
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 52 | 0.6833 | 0.7484 |
| No log | 2.0 | 104 | 0.3666 | 0.8750 |
| No log | 3.0 | 156 | 0.2090 | 0.9321 |
| No log | 4.0 | 208 | 0.1478 | 0.9449 |
| No log | 5.0 | 260 | 0.1002 | 0.9518 |
| No log | 6.0 | 312 | 0.1053 | 0.9506 |
| No log | 7.0 | 364 | 0.1182 | 0.9616 |
| No log | 8.0 | 416 | 0.1102 | 0.9592 |
| No log | 9.0 | 468 | 0.1262 | 0.9616 |
| 0.203 | 10.0 | 520 | 0.1286 | 0.9616 |
| 0.203 | 11.0 | 572 | 0.1355 | 0.9592 |
| 0.203 | 12.0 | 624 | 0.1299 | 0.9592 |
| 0.203 | 13.0 | 676 | 0.1154 | 0.9592 |
| 0.203 | 14.0 | 728 | 0.1385 | 0.9580 |
| 0.203 | 15.0 | 780 | 0.1330 | 0.9592 |
| 0.203 | 16.0 | 832 | 0.1390 | 0.9592 |
| 0.203 | 17.0 | 884 | 0.1386 | 0.9592 |
| 0.203 | 18.0 | 936 | 0.1390 | 0.9592 |
| 0.203 | 19.0 | 988 | 0.1409 | 0.9592 |
| 0.0006 | 20.0 | 1040 | 0.1411 | 0.9592 |
| 0.0006 | 21.0 | 1092 | 0.1413 | 0.9592 |
| 0.0006 | 22.0 | 1144 | 0.1415 | 0.9592 |
| 0.0006 | 23.0 | 1196 | 0.1426 | 0.9592 |
| 0.0006 | 24.0 | 1248 | 0.1435 | 0.9592 |
| 0.0006 | 25.0 | 1300 | 0.1438 | 0.9592 |
| 0.0006 | 26.0 | 1352 | 0.1434 | 0.9592 |
| 0.0006 | 27.0 | 1404 | 0.1437 | 0.9592 |
| 0.0006 | 28.0 | 1456 | 0.1441 | 0.9592 |
| 0.0002 | 29.0 | 1508 | 0.1440 | 0.9592 |
| 0.0002 | 30.0 | 1560 | 0.1441 | 0.9592 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.6
| [
"container",
"control shot",
"cover",
"edge + spine",
"flysheet",
"other",
"page + folio",
"scroll"
] |
davanstrien/convnext_manuscript_iiif |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext_manuscript_iiif
This model is a fine-tuned version of [facebook/convnext-base-224-22k](https://huggingface.co/facebook/convnext-base-224-22k) on the davanstrien/iiif_manuscripts_label_ge_50 dataset.
It achieves the following results on the evaluation set:
- Loss: 5.5856
- F1: 0.0037
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 64
- eval_batch_size: 64
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 6.5753 | 1.0 | 2038 | 6.4121 | 0.0016 |
| 5.9865 | 2.0 | 4076 | 5.9466 | 0.0021 |
| 5.6521 | 3.0 | 6114 | 5.7645 | 0.0029 |
| 5.3123 | 4.0 | 8152 | 5.6890 | 0.0033 |
| 5.0337 | 5.0 | 10190 | 5.6692 | 0.0034 |
| 4.743 | 6.0 | 12228 | 5.5856 | 0.0037 |
| 4.4387 | 7.0 | 14266 | 5.5969 | 0.0042 |
| 4.1422 | 8.0 | 16304 | 5.6711 | 0.0043 |
| 3.8372 | 9.0 | 18342 | 5.6761 | 0.0044 |
| 3.5244 | 10.0 | 20380 | 5.8469 | 0.0042 |
| 3.2321 | 11.0 | 22418 | 5.8774 | 0.0045 |
| 2.9004 | 12.0 | 24456 | 6.1186 | 0.0047 |
| 2.5937 | 13.0 | 26494 | 6.2398 | 0.0046 |
| 2.2983 | 14.0 | 28532 | 6.3732 | 0.0049 |
| 2.0611 | 15.0 | 30570 | 6.5024 | 0.0045 |
| 1.8153 | 16.0 | 32608 | 6.6585 | 0.0047 |
| 1.6075 | 17.0 | 34646 | 6.8333 | 0.0043 |
| 1.4342 | 18.0 | 36684 | 6.9529 | 0.0044 |
| 1.2614 | 19.0 | 38722 | 7.1129 | 0.0046 |
| 1.1463 | 20.0 | 40760 | 7.1977 | 0.0039 |
| 1.0387 | 21.0 | 42798 | 7.2700 | 0.0044 |
| 0.9635 | 22.0 | 44836 | 7.3375 | 0.0040 |
| 0.8872 | 23.0 | 46874 | 7.4003 | 0.0039 |
| 0.8156 | 24.0 | 48912 | 7.4884 | 0.0039 |
| 0.7544 | 25.0 | 50950 | 7.4764 | 0.0039 |
| 0.6893 | 26.0 | 52988 | 7.5153 | 0.0042 |
| 0.6767 | 27.0 | 55026 | 7.5427 | 0.0043 |
| 0.6098 | 28.0 | 57064 | 7.5547 | 0.0042 |
| 0.5871 | 29.0 | 59102 | 7.5533 | 0.0041 |
| 0.5696 | 30.0 | 61140 | 7.5595 | 0.0041 |
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.6
| [
"upper cover",
"inside upper cover",
"4th upper flyleaf verso",
"fol. f5v",
"fol. [c6]v",
"320r",
"320v",
"321r",
"321v",
"322r",
"322v",
"323r",
"323v",
"324r",
"324v",
"fol. [c7]r",
"detail from 193r: initial 's'",
"detail from 221r: initial 'i'",
"detail from 231v: initial 'u'... |
davanstrien/flyswot_iiif |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flyswot_iiif
This model is a fine-tuned version of [facebook/convnext-base-224-22k](https://huggingface.co/facebook/convnext-base-224-22k) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.1280
- F1: 0.0034
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 666
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
- label_smoothing_factor: 0.1
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 8.5184 | 0.26 | 500 | 7.9280 | 0.0005 |
| 7.7409 | 0.52 | 1000 | 7.5824 | 0.0007 |
| 7.4649 | 0.78 | 1500 | 7.3841 | 0.0010 |
| 7.3285 | 1.04 | 2000 | 7.2652 | 0.0012 |
| 7.1404 | 1.3 | 2500 | 7.1559 | 0.0014 |
| 7.0322 | 1.56 | 3000 | 7.0551 | 0.0016 |
| 6.9197 | 1.82 | 3500 | 6.9449 | 0.0019 |
| 6.7822 | 2.09 | 4000 | 6.8773 | 0.0018 |
| 6.6506 | 2.35 | 4500 | 6.7980 | 0.0020 |
| 6.5811 | 2.61 | 5000 | 6.7382 | 0.0022 |
| 6.538 | 2.87 | 5500 | 6.6582 | 0.0022 |
| 6.4136 | 3.13 | 6000 | 6.6013 | 0.0024 |
| 6.3325 | 3.39 | 6500 | 6.5369 | 0.0024 |
| 6.2566 | 3.65 | 7000 | 6.4875 | 0.0025 |
| 6.2285 | 3.91 | 7500 | 6.4342 | 0.0027 |
| 6.1281 | 4.17 | 8000 | 6.4066 | 0.0027 |
| 6.0762 | 4.43 | 8500 | 6.3674 | 0.0027 |
| 6.0309 | 4.69 | 9000 | 6.3336 | 0.0027 |
| 6.0123 | 4.95 | 9500 | 6.2932 | 0.0030 |
| 5.9089 | 5.21 | 10000 | 6.2835 | 0.0029 |
| 5.8901 | 5.47 | 10500 | 6.2481 | 0.0030 |
| 5.86 | 5.74 | 11000 | 6.2295 | 0.0030 |
| 5.8586 | 6.0 | 11500 | 6.2068 | 0.0033 |
| 5.7768 | 6.26 | 12000 | 6.1937 | 0.0031 |
| 5.7591 | 6.52 | 12500 | 6.1916 | 0.0032 |
| 5.7443 | 6.78 | 13000 | 6.1579 | 0.0033 |
| 5.7125 | 7.04 | 13500 | 6.1478 | 0.0033 |
| 5.6751 | 7.3 | 14000 | 6.1379 | 0.0035 |
| 5.6648 | 7.56 | 14500 | 6.1304 | 0.0035 |
| 5.6644 | 7.82 | 15000 | 6.1280 | 0.0034 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.6
| [
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9",
"10",
"11",
"12",
"13",
"14",
"15",
"16",
"17",
"18",
"19",
"20",
"21",
"22",
"23",
"24",
"25",
"26",
"27",
"28",
"29",
"30",
"31",
"32",
"33",
"34",
"35",
"36",
"37",
"38",
"39",
"40",
... |
davanstrien/flyswot_test |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flyswot_test
This model is a fine-tuned version of [facebook/convnext-base-224-22k](https://huggingface.co/facebook/convnext-base-224-22k) on the image_folder dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.1518
- eval_f1: 0.9595
- eval_runtime: 5.9337
- eval_samples_per_second: 69.603
- eval_steps_per_second: 2.191
- epoch: 7.0
- step: 364
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 666
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.6
| [
"container",
"control shot",
"cover",
"edge + spine",
"flysheet",
"other",
"page + folio",
"scroll"
] |
davanstrien/iiif_manuscript_vit |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# iiif_manuscript_vit
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5684
- F1: 0.5996
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
- label_smoothing_factor: 0.1
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.5639 | 1.0 | 2269 | 0.5822 | 0.5516 |
| 0.5834 | 2.0 | 4538 | 0.5825 | 0.5346 |
| 0.5778 | 3.0 | 6807 | 0.5794 | 0.6034 |
| 0.5735 | 4.0 | 9076 | 0.5742 | 0.5713 |
| 0.5731 | 5.0 | 11345 | 0.5745 | 0.6008 |
| 0.5701 | 6.0 | 13614 | 0.5729 | 0.5499 |
| 0.5696 | 7.0 | 15883 | 0.5717 | 0.5952 |
| 0.5683 | 8.0 | 18152 | 0.5680 | 0.6005 |
| 0.5648 | 9.0 | 20421 | 0.5679 | 0.5967 |
| 0.564 | 10.0 | 22690 | 0.5684 | 0.5996 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| [
"cover",
"flyleaf",
"1st upper flyleaf verso",
"2nd upper flyleaf verso",
"3rd upper flyleaf verso",
"fol",
"1st lower flyleaf verso",
"2nd lower flyleaf verso",
"3rd lower flyleaf verso",
"lower flyleaf verso",
"upper flyleaf verso",
"blank leaf recto",
"blank leaf verso"
] |
davanstrien/vit_flyswot_test |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit_flyswot_test
This model is a fine-tuned version of [](https://huggingface.co/) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4777
- F1: 0.8492
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 666
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 52 | 1.2007 | 0.3533 |
| No log | 2.0 | 104 | 1.0037 | 0.5525 |
| No log | 3.0 | 156 | 0.8301 | 0.6318 |
| No log | 4.0 | 208 | 0.7224 | 0.6946 |
| No log | 5.0 | 260 | 0.7298 | 0.7145 |
| No log | 6.0 | 312 | 0.6328 | 0.7729 |
| No log | 7.0 | 364 | 0.6010 | 0.7992 |
| No log | 8.0 | 416 | 0.5174 | 0.8364 |
| No log | 9.0 | 468 | 0.5084 | 0.8479 |
| 0.6372 | 10.0 | 520 | 0.4777 | 0.8492 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.6
| [
"container",
"control shot",
"cover",
"edge + spine",
"flysheet",
"other",
"page + folio",
"scroll"
] |
deepmind/vision-perceiver-conv |
# Perceiver IO for vision (convolutional processing)
Perceiver IO model pre-trained on ImageNet (14 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For image classification, the output is a tensor containing the logits, of shape (batch_size, num_labels).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model directly on raw pixel values, rather than on patches as is done in ViT. This particular model employs a simple 2D conv+maxpool preprocessing network on the pixel values, before using the inputs for cross-attention with the latents.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by replacing the classification decoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for other fine-tuned versions on a task that may interest you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationConvProcessing
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-conv")
model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare input
inputs = feature_extractor(image, return_tensors="pt").pixel_values
# forward pass
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
```
## Training data
This model was pretrained on [ImageNet](http://www.image-net.org/), a dataset consisting of 14 million images and 1k classes.
## Training procedure
### Preprocessing
Images are center cropped and resized to a resolution of 224x224 and normalized across the RGB channels. Note that data augmentation was used during pre-training, as explained in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
### Pretraining
Hyperparameter details can be found in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
This model is able to achieve a top-1 accuracy of 82.1 on ImageNet-1k.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
deepmind/vision-perceiver-fourier |
# Perceiver IO for vision (fixed Fourier position embeddings)
Perceiver IO model pre-trained on ImageNet (14 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For image classification, the output is a tensor containing the logits, of shape (batch_size, num_labels).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model directly on raw pixel values, rather than on patches as is done in ViT. This particular model only adds fixed Fourier 2D position embeddings to the pixel values.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by replacing the classification decoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for other fine-tuned versions on a task that may interest you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverImageProcessor, PerceiverForImageClassificationFourier
import requests
from PIL import Image
processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver-fourier")
model = PerceiverForImageClassificationFourier.from_pretrained("deepmind/vision-perceiver-fourier")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare input
inputs = processor(image, return_tensors="pt").pixel_values
# forward pass
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
```
## Training data
This model was pretrained on [ImageNet](http://www.image-net.org/), a dataset consisting of 14 million images and 1k classes.
## Training procedure
### Preprocessing
Images are center cropped and resized to a resolution of 224x224 and normalized across the RGB channels. Note that data augmentation was used during pre-training, as explained in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
### Pretraining
Hyperparameter details can be found in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
This model is able to achieve a top-1 accuracy of 79.0 on ImageNet-1k, and 84.5 when pre-trained on a large-scale dataset (JFT-300M, an internal dataset of Google).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
deepmind/vision-perceiver-learned |
# Perceiver IO for vision (learned position embeddings)
Perceiver IO model pre-trained on ImageNet (14 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For image classification, the output is a tensor containing the logits, of shape (batch_size, num_labels).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model directly on raw pixel values, rather than on patches as is done in ViT. This particular model only adds learned 1D position embeddings to the pixel values, hence it is given no privileged information about the 2D structure of images.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by replacing the classification decoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for other fine-tuned versions on a task that may interest you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationLearned
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-learned")
model = PerceiverForImageClassificationLearned.from_pretrained("deepmind/vision-perceiver-learned")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare input
encoding = feature_extractor(image, return_tensors="pt")
inputs = encoding.pixel_values
# forward pass
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
```
## Training data
This model was pretrained on [ImageNet](http://www.image-net.org/), a dataset consisting of 14 million images and 1k classes.
## Training procedure
### Preprocessing
Images are center cropped and resized to a resolution of 224x224 and normalized across the RGB channels. Note that data augmentation was used during pre-training, as explained in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
### Pretraining
Hyperparameter details can be found in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
This model is able to achieve a top-1 accuracy of 72.7 on ImageNet-1k, despite having no privileged information about the 2D structure of images.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-base-224-22k-1k |
# ConvNeXT (base-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-base-224-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-base-384-224-1k")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-base-224-22k |
# ConvNeXT (base-sized model)
ConvNeXT model trained on ImageNet-22k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-base-224-22k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-base-224-22k")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 22k ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
facebook/convnext-base-224 |
# ConvNeXT (base-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-base-224")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-base-224")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-base-384-22k-1k |
# ConvNeXT (base-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-base-384-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-base-384-22k-1k")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-base-384 |
# ConvNeXT (base-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-base-384")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-base-384")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-large-224-22k-1k |
# ConvNeXT (large-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-large-224-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-large-224-22k-1k")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1k ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-large-224-22k |
# ConvNeXT (large-sized model)
ConvNeXT model trained on ImageNet-22k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-large-224-22k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-large-224-22k")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 22k ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
facebook/convnext-large-224 |
# ConvNeXT (large-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-large-224")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-large-224")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-large-384-22k-1k |
# ConvNeXT (large-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-large-384-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-large-384-22k-1k")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-large-384 |
# ConvNeXT (large-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-large-384")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-large-384")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-small-224 |
# ConvNeXT (large-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-small-224")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-small-224")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-xlarge-224-22k-1k |
# ConvNeXT (xlarge-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-xlarge-224-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-xlarge-224-22k-1k")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/convnext-xlarge-224-22k |
# ConvNeXT (xlarge-sized model)
ConvNeXT model trained on ImageNet-22k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-xlarge-224-22k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-xlarge-224-22k")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 22k ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
facebook/convnext-xlarge-384-22k-1k |
# ConvNeXT (xlarge-sized model)
ConvNeXT model pre-trained on ImageNet-22k and fine-tuned on ImageNet-1k at resolution 384x384. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextImageProcessor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = ConvNextImageProcessor.from_pretrained("facebook/convnext-xlarge-384-22k-1k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-xlarge-384-22k-1k")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/deit-base-distilled-patch16-224 |
# Distilled Data-efficient Image Transformer (base-sized model)
Distilled data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is a distilled Vision Transformer (ViT). It uses a distillation token, besides the class token, to effectively learn from a teacher (CNN) during both pre-training and fine-tuning. The distillation token is learned through backpropagation, by interacting with the class ([CLS]) and patch tokens through the self-attention layers.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a distilled ViT model, you can plug it into DeiTModel, DeiTForImageClassification or DeiTForImageClassificationWithTeacher. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, DeiTForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-base-distilled-patch16-224')
model = DeiTForImageClassificationWithTeacher.from_pretrained('facebook/deit-base-distilled-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
# forward pass
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
This model was pretrained and fine-tuned with distillation on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| **DeiT-base distilled** | **83.4** | **96.5** | **87M** | **https://huggingface.co/facebook/deit-base-distilled-patch16-224** |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/deit-base-distilled-patch16-384 |
# Distilled Data-efficient Image Transformer (base-sized model)
Distilled data-efficient Image Transformer (DeiT) model pre-trained at resolution 224x224 and fine-tuned at resolution 384x384 on ImageNet-1k (1 million images, 1,000 classes). It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is a distilled Vision Transformer (ViT). It uses a distillation token, besides the class token, to effectively learn from a teacher (CNN) during both pre-training and fine-tuning. The distillation token is learned through backpropagation, by interacting with the class ([CLS]) and patch tokens through the self-attention layers.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a distilled ViT model, you can plug it into DeiTModel, DeiTForImageClassification or DeiTForImageClassificationWithTeacher. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, DeiTForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-base-distilled-patch16-384')
model = DeiTForImageClassificationWithTeacher.from_pretrained('facebook/deit-base-distilled-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
This model was pretrained and fine-tuned with distillation on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (438x438), center-cropped at 384x384 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Pre-training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|-------------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| **DeiT-base distilled 384 (1000 epochs)** | **85.2** | **97.2** | **88M** | **https://huggingface.co/facebook/deit-base-distilled-patch16-384** |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/deit-base-patch16-224 |
# Data-efficient Image Transformer (base-sized model)
Data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is actually a more efficiently trained Vision Transformer (ViT).
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pre-trained and fine-tuned on a large collection of images in a supervised fashion, namely ImageNet-1k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a more efficiently trained ViT model, you can plug it into ViTModel or ViTForImageClassification. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('facebook/deit-base-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
The ViT model was pretrained on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| **DeiT-base** | **81.8** | **95.6** | **86M** | **https://huggingface.co/facebook/deit-base-patch16-224** |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/deit-base-patch16-384 |
# Data-efficient Image Transformer (base-sized model)
Data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 384x384. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is actually a more efficiently trained Vision Transformer (ViT).
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pre-trained at resolution 224 and fine-tuned at resolution 384 on a large collection of images in a supervised fashion, namely ImageNet-1k.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a more efficiently trained ViT model, you can plug it into ViTModel or ViTForImageClassification. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-base-patch16-384')
model = ViTForImageClassification.from_pretrained('facebook/deit-base-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
The ViT model was pretrained on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (438x438), center-cropped at 384x384 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Pre-training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| **DeiT-base 384** | **82.9** | **96.2** | **87M** | **https://huggingface.co/facebook/deit-base-patch16-384** |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/deit-small-distilled-patch16-224 |
# Distilled Data-efficient Image Transformer (small-sized model)
Distilled data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is a distilled Vision Transformer (ViT). It uses a distillation token, besides the class token, to effectively learn from a teacher (CNN) during both pre-training and fine-tuning. The distillation token is learned through backpropagation, by interacting with the class ([CLS]) and patch tokens through the self-attention layers.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a distilled ViT model, you can plug it into DeiTModel, DeiTForImageClassification or DeiTForImageClassificationWithTeacher. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, DeiTForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-small-distilled-patch16-224')
model = DeiTForImageClassificationWithTeacher.from_pretrained('facebook/deit-small-distilled-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
This model was pretrained and fine-tuned with distillation on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| **DeiT-small distilled** | **81.2** | **95.4** | **22M** | **https://huggingface.co/facebook/deit-small-distilled-patch16-224** |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/deit-small-patch16-224 |
# Data-efficient Image Transformer (small-sized model)
Data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is actually a more efficiently trained Vision Transformer (ViT).
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pre-trained and fine-tuned on a large collection of images in a supervised fashion, namely ImageNet-1k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a more efficiently trained ViT model, you can plug it into ViTModel or ViTForImageClassification. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-small-patch16-224')
model = ViTForImageClassification.from_pretrained('facebook/deit-small-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
The ViT model was pretrained on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| **DeiT-small** | **79.9** | **95.0** | **22M** | **https://huggingface.co/facebook/deit-small-patch16-224** |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/deit-tiny-distilled-patch16-224 |
# Distilled Data-efficient Image Transformer (tiny-sized model)
Distilled data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is a distilled Vision Transformer (ViT). It uses a distillation token, besides the class token, to effectively learn from a teacher (CNN) during both pre-training and fine-tuning. The distillation token is learned through backpropagation, by interacting with the class ([CLS]) and patch tokens through the self-attention layers.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a distilled ViT model, you can plug it into DeiTModel, DeiTForImageClassification or DeiTForImageClassificationWithTeacher. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, DeiTForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-tiny-distilled-patch16-224')
model = DeiTForImageClassificationWithTeacher.from_pretrained('facebook/deit-tiny-distilled-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
This model was pretrained and fine-tuned with distillation on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| **DeiT-tiny distilled** | **74.5** | **91.9** | **6M** | **https://huggingface.co/facebook/deit-tiny-distilled-patch16-224** |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
facebook/deit-tiny-patch16-224 |
# Data-efficient Image Transformer (tiny-sized model)
Data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is actually a more efficiently trained Vision Transformer (ViT).
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pre-trained and fine-tuned on a large collection of images in a supervised fashion, namely ImageNet-1k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a more efficiently trained ViT model, you can plug it into ViTModel or ViTForImageClassification. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-tiny-patch16-224')
model = ViTForImageClassification.from_pretrained('facebook/deit-tiny-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
The ViT model was pretrained on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| **DeiT-tiny** | **72.2** | **91.1** | **5M** | **https://huggingface.co/facebook/deit-tiny-patch16-224** |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
google/vit-base-patch16-384 |
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-384')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224 during pre-training, 384x384 during fine-tuning) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
google/vit-base-patch32-384 |
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch32-384')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch32-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224 during pre-training, 384x384 during fine-tuning) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.2010.11929,
doi = {10.48550/ARXIV.2010.11929},
url = {https://arxiv.org/abs/2010.11929},
author = {Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Artificial Intelligence (cs.AI), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
publisher = {arXiv},
year = {2020},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
google/vit-large-patch16-224 |
# Vision Transformer (large-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at the same resolution, 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-large-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-large-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
google/vit-large-patch16-384 |
# Vision Transformer (large-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-large-patch16-384')
model = ViTForImageClassification.from_pretrained('google/vit-large-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224 during pre-training, 384x384 during fine-tuning) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
google/vit-large-patch32-384 |
# Vision Transformer (large-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-large-patch32-384')
model = ViTForImageClassification.from_pretrained('google/vit-large-patch32-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224 during pre-training, 384x384 during fine-tuning) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
imjeffhi/pokemon_classifier | # Pokémon Classifier
# Intro
A fine-tuned version of ViT-base on a collected set of Pokémon images. You can read more about the model [here](https://medium.com/@imjeffhi4/tutorial-using-vision-transformer-vit-to-create-a-pok%C3%A9mon-classifier-cb3f26ff2c20).
# Using the model
```python
from transformers import ViTForImageClassification, ViTFeatureExtractor
from PIL import Image
import torch
# Loading in Model
device = "cuda" if torch.cuda.is_available() else "cpu"
model = ViTForImageClassification.from_pretrained( "imjeffhi/pokemon_classifier").to(device)
feature_extractor = ViTFeatureExtractor.from_pretrained('imjeffhi/pokemon_classifier')
# Caling the model on a test image
img = Image.open('test.jpg')
extracted = feature_extractor(images=img, return_tensors='pt').to(device)
predicted_id = model(**extracted).logits.argmax(-1).item()
predicted_pokemon = model.config.id2label[predicted_id]
``` | [
"bulbasaur",
"ivysaur",
"venusaur",
"charmander",
"charmeleon",
"charizard",
"squirtle",
"wartortle",
"blastoise",
"caterpie",
"metapod",
"butterfree",
"weedle",
"kakuna",
"beedrill",
"pidgey",
"pidgeotto",
"pidgeot",
"rattata",
"raticate",
"spearow",
"fearow",
"ekans",
... |
ismgar01/vit-base-cats-vs-dogs |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-cats-vs-dogs
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the cats_vs_dogs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0182
- Accuracy: 0.9937
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 32
- eval_batch_size: 32
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1177 | 1.0 | 622 | 0.0473 | 0.9832 |
| 0.057 | 2.0 | 1244 | 0.0362 | 0.9883 |
| 0.0449 | 3.0 | 1866 | 0.0261 | 0.9886 |
| 0.066 | 4.0 | 2488 | 0.0248 | 0.9923 |
| 0.0328 | 5.0 | 3110 | 0.0182 | 0.9937 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.8.1+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
| [
"cat",
"dog"
] |
microsoft/beit-base-patch16-224-pt22k-ft22k |
# BEiT (base-sized model, fine-tuned on ImageNet-22k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-22k - also called ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on the same dataset at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitImageProcessor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = BeitImageProcessor.from_pretrained('microsoft/beit-base-patch16-224-pt22k-ft22k')
model = BeitForImageClassification.from_pretrained('microsoft/beit-base-patch16-224-pt22k-ft22k')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 21,841 ImageNet-22k classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on the same dataset.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution. Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
microsoft/beit-base-patch16-224 |
# BEiT (base-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitImageProcessor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = BeitImageProcessor.from_pretrained('microsoft/beit-base-patch16-224')
model = BeitForImageClassification.from_pretrained('microsoft/beit-base-patch16-224')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/beit-base-patch16-384 |
# BEiT (base-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-base-patch16-384')
model = BeitForImageClassification.from_pretrained('microsoft/beit-base-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/beit-large-patch16-224-pt22k-ft22k |
# BEiT (large-sized model, fine-tuned on ImageNet-22k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-22k - also called ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on the same dataset at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitImageProcessor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = BeitImageProcessor.from_pretrained('microsoft/beit-large-patch16-224-pt22k-ft22k')
model = BeitForImageClassification.from_pretrained('microsoft/beit-large-patch16-224-pt22k-ft22k')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 21,841 ImageNet-22k classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on the same dataset.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution. Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
microsoft/beit-large-patch16-224 |
# BEiT (large-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-large-patch16-224')
model = BeitForImageClassification.from_pretrained('microsoft/beit-large-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/beit-large-patch16-384 |
# BEiT (large-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-large-patch16-384')
model = BeitForImageClassification.from_pretrained('microsoft/beit-large-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/swin-base-patch4-window12-384-in22k |
# Swin Transformer (large-sized model)
Swin Transformer model pre-trained on ImageNet-21k (14 million images, 21,841 classes) at resolution 384x384. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-base-patch4-window12-384-in22k")
model = SwinForImageClassification.from_pretrained("microsoft/swin-base-patch4-window12-384-in22k")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
microsoft/swin-base-patch4-window12-384 |
# Swin Transformer (base-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 384x384. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-base-patch4-window12-384")
model = SwinForImageClassification.from_pretrained("microsoft/swin-base-patch4-window12-384")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/swin-base-patch4-window7-224-in22k |
# Swin Transformer (large-sized model)
Swin Transformer model pre-trained on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("microsoft/swin-base-patch4-window7-224-in22k")
model = SwinForImageClassification.from_pretrained("microsoft/swin-base-patch4-window7-224-in22k")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
microsoft/swin-base-patch4-window7-224 |
# Swin Transformer (base-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-base-patch4-window7-224")
model = SwinForImageClassification.from_pretrained("microsoft/swin-base-patch4-window7-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/swin-large-patch4-window12-384-in22k |
# Swin Transformer (large-sized model)
Swin Transformer model pre-trained on ImageNet-21k (14 million images, 21,841 classes) at resolution 384x384. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-large-patch4-window12-384-in22k")
model = SwinForImageClassification.from_pretrained("microsoft/swin-large-patch4-window12-384-in22k")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
microsoft/swin-large-patch4-window12-384 |
# Swin Transformer (large-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 384x384. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-large-patch4-window12-384")
model = SwinForImageClassification.from_pretrained("microsoft/swin-large-patch4-window12-3844")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/swin-large-patch4-window7-224-in22k |
# Swin Transformer (large-sized model)
Swin Transformer model pre-trained on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-large-patch4-window7-224-in22k")
model = SwinForImageClassification.from_pretrained("microsoft/swin-large-patch4-window7-224-in22k")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
microsoft/swin-large-patch4-window7-224 |
# Swin Transformer (large-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-large-patch4-window7-224")
model = SwinForImageClassification.from_pretrained("microsoft/swin-large-patch4-window7-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/swin-small-patch4-window7-224 |
# Swin Transformer (small-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-small-patch4-window7-224")
model = SwinForImageClassification.from_pretrained("microsoft/swin-small-patch4-window7-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
microsoft/swin-tiny-patch4-window7-224 |
# Swin Transformer (tiny-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, AutoModelForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
model = AutoModelForImageClassification.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
mrm8488/vit-base-patch16-224_finetuned-kvasirv2-colonoscopy |
# Vision Transformer fine-tuned on kvasir_v2 for colonoscopy classification
## Demo
### Drag the following images to the widget to test the model
- 
- 
- 
- 
## Training
You can find the code [here](https://github.com/qanastek/HugsVision/blob/main/recipes/kvasir_v2/binary_classification/Kvasir_v2_Image_Classifier.ipynb)
## Metrics
```
precision recall f1-score support
dyed-lifted-polyps 0.95 0.93 0.94 60
dyed-resection-margins 0.97 0.95 0.96 64
esophagitis 0.93 0.79 0.85 67
normal-cecum 1.00 0.98 0.99 54
normal-pylorus 0.95 1.00 0.97 57
normal-z-line 0.82 0.93 0.87 67
polyps 0.92 0.92 0.92 52
ulcerative-colitis 0.93 0.95 0.94 59
accuracy 0.93 480
macro avg 0.93 0.93 0.93 480
weighted avg 0.93 0.93 0.93 480
```
## How to use
```py
from transformers import ViTFeatureExtractor, ViTForImageClassification
from hugsvision.inference.VisionClassifierInference import VisionClassifierInference
path = "mrm8488/vit-base-patch16-224_finetuned-kvasirv2-colonoscopy"
classifier = VisionClassifierInference(
feature_extractor = ViTFeatureExtractor.from_pretrained(path),
model = ViTForImageClassification.from_pretrained(path),
)
img = "Your image path"
label = classifier.predict(img_path=img)
print("Predicted class:", label)
```
> Disclaimer: This model was trained for research only
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain | [
"dyed-lifted-polyps",
"dyed-resection-margins",
"esophagitis",
"normal-cecum",
"normal-pylorus",
"normal-z-line",
"polyps",
"ulcerative-colitis"
] |
nateraw/food |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nateraw/food
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the nateraw/food101 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4501
- Accuracy: 0.8913
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 128
- eval_batch_size: 128
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8271 | 1.0 | 592 | 0.6070 | 0.8562 |
| 0.4376 | 2.0 | 1184 | 0.4947 | 0.8691 |
| 0.2089 | 3.0 | 1776 | 0.4876 | 0.8747 |
| 0.0882 | 4.0 | 2368 | 0.4639 | 0.8857 |
| 0.0452 | 5.0 | 2960 | 0.4501 | 0.8913 |
### Framework versions
- Transformers 4.9.0.dev0
- Pytorch 1.9.0+cu102
- Datasets 1.9.1.dev0
- Tokenizers 0.10.3
| [
"apple_pie",
"baby_back_ribs",
"bruschetta",
"waffles",
"caesar_salad",
"cannoli",
"caprese_salad",
"carrot_cake",
"ceviche",
"cheese_plate",
"cheesecake",
"chicken_curry",
"chicken_quesadilla",
"baklava",
"chicken_wings",
"chocolate_cake",
"chocolate_mousse",
"churros",
"clam_ch... |
nateraw/huggingpics-package-demo-2 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# huggingpics-package-demo-2
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3761
- Acc: 0.9403
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0328 | 1.0 | 24 | 0.9442 | 0.7463 |
| 0.8742 | 2.0 | 48 | 0.7099 | 0.9403 |
| 0.6451 | 3.0 | 72 | 0.5050 | 0.9403 |
| 0.508 | 4.0 | 96 | 0.3761 | 0.9403 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Tokenizers 0.10.3
| [
"corgi",
"husky",
"shibu inu"
] |
nateraw/huggingpics-package-demo |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# huggingpics-package-demo
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3761
- Acc: 0.9403
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0328 | 1.0 | 24 | 0.9442 | 0.7463 |
| 0.8742 | 2.0 | 48 | 0.7099 | 0.9403 |
| 0.6451 | 3.0 | 72 | 0.5050 | 0.9403 |
| 0.508 | 4.0 | 96 | 0.3761 | 0.9403 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Tokenizers 0.10.3
| [
"corgi",
"husky",
"shibu inu"
] |
nateraw/pasta-shapes |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pasta-shapes
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3761
- Acc: 0.9403
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0328 | 1.0 | 24 | 0.9442 | 0.7463 |
| 0.8742 | 2.0 | 48 | 0.7099 | 0.9403 |
| 0.6451 | 3.0 | 72 | 0.5050 | 0.9403 |
| 0.508 | 4.0 | 96 | 0.3761 | 0.9403 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Tokenizers 0.10.3
| [
"corgi",
"husky",
"shibu inu"
] |
nateraw/planes-trains-automobiles |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# planes-trains-automobiles
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the huggingpics dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0534
- Accuracy: 0.9851
## Model description
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### automobiles

#### planes

#### trains

## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0283 | 1.0 | 48 | 0.0434 | 0.9851 |
| 0.0224 | 2.0 | 96 | 0.0548 | 0.9851 |
| 0.0203 | 3.0 | 144 | 0.0445 | 0.9851 |
| 0.0195 | 4.0 | 192 | 0.0534 | 0.9851 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
| [
"automobiles",
"planes",
"trains"
] |
nateraw/test_model_a |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_model_a
This model is a fine-tuned version of [lysandre/tiny-vit-random](https://huggingface.co/lysandre/tiny-vit-random) on the image_folder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 40
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Datasets 1.9.1.dev0
- Tokenizers 0.10.3
| [
"cat",
"dog"
] |
nateraw/trainer-rare-puppers |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trainer-rare-puppers
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the huggingpics dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 48 | 0.4087 | 0.8806 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
| [
"corgi",
"samoyed",
"shiba inu"
] |
nateraw/vit-age-classifier |
A vision transformer finetuned to classify the age of a given person's face.
```python
import requests
from PIL import Image
from io import BytesIO
from transformers import ViTFeatureExtractor, ViTForImageClassification
# Get example image from official fairface repo + read it in as an image
r = requests.get('https://github.com/dchen236/FairFace/blob/master/detected_faces/race_Asian_face0.jpg?raw=true')
im = Image.open(BytesIO(r.content))
# Init model, transforms
model = ViTForImageClassification.from_pretrained('nateraw/vit-age-classifier')
transforms = ViTFeatureExtractor.from_pretrained('nateraw/vit-age-classifier')
# Transform our image and pass it through the model
inputs = transforms(im, return_tensors='pt')
output = model(**inputs)
# Predicted Class probabilities
proba = output.logits.softmax(1)
# Predicted Classes
preds = proba.argmax(1)
``` | [
"0-2",
"3-9",
"10-19",
"20-29",
"30-39",
"40-49",
"50-59",
"60-69",
"more than 70"
] |
nateraw/vit-base-beans-demo-v2 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans-demo-v2
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0099
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0705 | 1.54 | 100 | 0.0562 | 0.9925 |
| 0.0123 | 3.08 | 200 | 0.0124 | 1.0 |
| 0.008 | 4.62 | 300 | 0.0099 | 1.0 |
### Framework versions
- Transformers 4.10.0.dev0
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
| [
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
nateraw/vit-base-beans-demo-v3 |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans-demo-v3
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0645
- Accuracy: 0.9850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0397 | 1.54 | 100 | 0.0645 | 0.9850 |
### Framework versions
- Transformers 4.10.0.dev0
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
| [
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
nateraw/vit-base-beans-demo |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans-demo
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0853
- Accuracy: 0.9774
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0545 | 1.54 | 100 | 0.1436 | 0.9624 |
| 0.006 | 3.08 | 200 | 0.1058 | 0.9699 |
| 0.0038 | 4.62 | 300 | 0.0853 | 0.9774 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
| [
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
nateraw/vit-base-beans |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0942
- Accuracy: 0.9774
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2809 | 1.0 | 130 | 0.2287 | 0.9699 |
| 0.1097 | 2.0 | 260 | 0.1676 | 0.9624 |
| 0.1027 | 3.0 | 390 | 0.0942 | 0.9774 |
| 0.0923 | 4.0 | 520 | 0.1104 | 0.9699 |
| 0.1726 | 5.0 | 650 | 0.1030 | 0.9699 |
### Framework versions
- Transformers 4.10.0.dev0
- Pytorch 1.9.0+cu102
- Datasets 1.11.1.dev0
- Tokenizers 0.10.3
| [
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
nateraw/vit-base-cats-vs-dogs |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-cats-vs-dogs
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the cats_vs_dogs dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0202
- Accuracy: 0.9935
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 64
- eval_batch_size: 64
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.064 | 1.0 | 311 | 0.0483 | 0.9849 |
| 0.0622 | 2.0 | 622 | 0.0275 | 0.9903 |
| 0.0366 | 3.0 | 933 | 0.0262 | 0.9917 |
| 0.0294 | 4.0 | 1244 | 0.0219 | 0.9932 |
| 0.0161 | 5.0 | 1555 | 0.0202 | 0.9935 |
### Framework versions
- Transformers 4.8.1
- Pytorch 1.9.0+cu102
- Datasets 1.11.1.dev0
- Tokenizers 0.10.3
| [
"cat",
"dog"
] |
nateraw/vit-base-patch16-224-cifar10 |
# Vision Transformer Fine Tuned on CIFAR10
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) and **fine-tuned on CIFAR10** at resolution 224x224.
Check out the code at my [my Github repo](https://github.com/nateraw/huggingface-vit-finetune).
## Usage
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'https://www.cs.toronto.edu/~kriz/cifar-10-sample/dog10.png'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('nateraw/vit-base-patch16-224-cifar10')
model = ViTForImageClassification.from_pretrained('nateraw/vit-base-patch16-224-cifar10')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
preds = outputs.logits.argmax(dim=1)
classes = [
'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'
]
classes[preds[0]]
```
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not provide any fine-tuned heads, as these were zero'd by Google researchers. However, the model does include the pre-trained pooler, which can be used for downstream tasks (such as image classification).
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
| [
"label_0",
"label_1",
"label_2",
"label_3",
"label_4",
"label_5",
"label_6",
"label_7",
"label_8",
"label_9"
] |
nickmuchi/vit-base-beans |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0505
- Accuracy: 0.9850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1166 | 1.54 | 100 | 0.0764 | 0.9850 |
| 0.1607 | 3.08 | 200 | 0.2114 | 0.9398 |
| 0.0067 | 4.62 | 300 | 0.0692 | 0.9774 |
| 0.005 | 6.15 | 400 | 0.0944 | 0.9624 |
| 0.0043 | 7.69 | 500 | 0.0505 | 0.9850 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| [
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
nielsr/beit-base-patch16-224 |
# BEiT (base-sized model, fine-tuned on ImageNet-1k after being intermediately fine-tuned on ImageNet-22k)
BEiT (BERT pre-training of Image Transformers) model pre-trained in a self-supervised way on ImageNet-22k (14 million images, 21,841 classes) at resolution 224x224, and also fine-tuned on the same dataset at the same resolution. It was introduced in the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team. | [
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio... |
nielsr/beit-large-patch16-224-pt22k-ft22k |
# BEiT (large-sized model, fine-tuned on ImageNet-22k)
BEiT (BERT pre-training of Image Transformers) model pre-trained in a self-supervised way on ImageNet-22k (14 million images, 21,841 classes) at resolution 224x224, and also fine-tuned on the same dataset at the same resolution. It was introduced in the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team. | [
"organism, being",
"benthos",
"heterotroph",
"cell",
"person, individual, someone, somebody, mortal, soul",
"animal, animate_being, beast, brute, creature, fauna",
"plant, flora, plant_life",
"food, nutrient",
"artifact, artefact",
"hop",
"check-in",
"dressage",
"curvet, vaulting",
"piaffe... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.