| --- |
| license: apache-2.0 |
| tags: |
| - vision |
| - image-classification |
|
|
| datasets: |
| - imagenet-1k |
|
|
| widget: |
| - src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg |
| example_title: Tiger |
| - src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg |
| example_title: Teapot |
| - src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg |
| example_title: Palace |
|
|
| --- |
| |
| # Van |
|
|
| Van model trained on imagenet-1k. It was introduced in the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) and first released in [this repository](https://github.com/Visual-Attention-Network/VAN-Classification). |
|
|
| Disclaimer: The team releasing Van did not write a model card for this model so this model card has been written by the Hugging Face team. |
|
|
| ## Model description |
|
|
| This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations. |
|
|
| 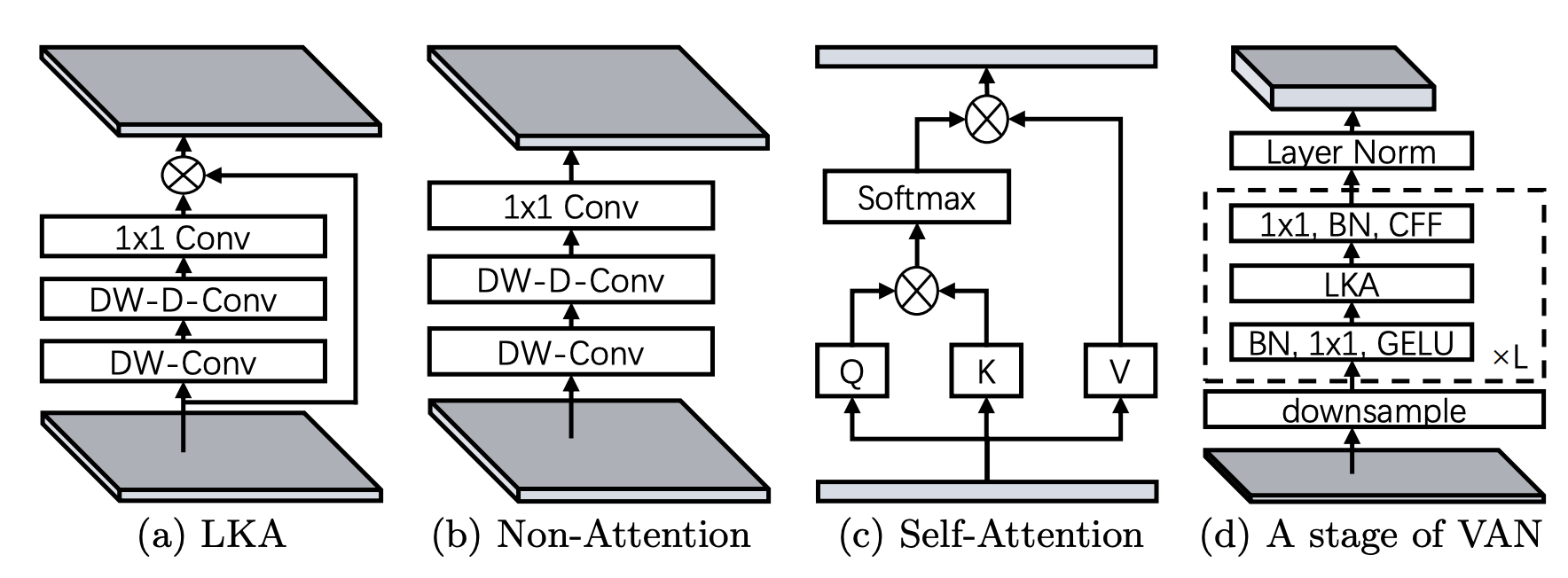 |
|
|
| ## Intended uses & limitations |
|
|
| You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=van) to look for |
| fine-tuned versions on a task that interests you. |
|
|
| ### How to use |
|
|
| Here is how to use this model: |
|
|
| ```python |
| >>> from transformers import AutoFeatureExtractor, VanForImageClassification |
| >>> import torch |
| >>> from datasets import load_dataset |
| |
| >>> dataset = load_dataset("huggingface/cats-image") |
| >>> image = dataset["test"]["image"][0] |
| |
| >>> feature_extractor = AutoFeatureExtractor.from_pretrained("Visual-Attention-Network/van-base") |
| >>> model = VanForImageClassification.from_pretrained("Visual-Attention-Network/van-base") |
| |
| >>> inputs = feature_extractor(image, return_tensors="pt") |
| |
| >>> with torch.no_grad(): |
| ... logits = model(**inputs).logits |
| |
| >>> # model predicts one of the 1000 ImageNet classes |
| >>> predicted_label = logits.argmax(-1).item() |
| >>> print(model.config.id2label[predicted_label]) |
| tabby, tabby cat |
| ``` |
|
|
|
|
|
|
| For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/van). |

