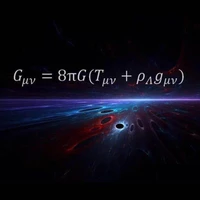SafeEraser: Enhancing Safety in Multimodal Large Language Models through Multimodal Machine Unlearning
As Multimodal Large Language Models (MLLMs) develop, their potential security issues have become increasingly prominent. Machine Unlearning (MU), as an effective strategy for forgetting specific knowledge in training data, has been widely used in privacy protection. However, MU for safety in MLLM has yet to be fully explored. To address this issue, we propose SAFEERASER, a safety unlearning benchmark for MLLMs, consisting of 3,000 images and 28.8K VQA pairs. We comprehensively evaluate unlearning methods from two perspectives: forget quality and model utility. Our findings show that existing MU methods struggle to maintain model performance while implementing the forget operation and often suffer from over-forgetting. Hence, we introduce Prompt Decouple (PD) Loss to alleviate over-forgetting through decouple prompt during unlearning process. To quantitatively measure over-forgetting mitigated by PD Loss, we propose a new metric called Safe Answer Refusal Rate (SARR). Experimental results demonstrate that combining PD Loss with existing unlearning methods can effectively prevent over-forgetting and achieve a decrease of 79.5% in the SARR metric of LLaVA-7B and LLaVA-13B, while maintaining forget quality and model utility. Our code and dataset will be released upon acceptance. Warning: This paper contains examples of harmful language and images, and reader discretion is recommended.