![]()
💻 Github | 📊 Dataset | 📄 Paper | 🚀 Demo
# Introduction We develop Infinity-Parser, an end-to-end scanned document parsing model trained with reinforcement learning. By incorporating verifiable rewards based on layout and content, Infinity-Parser maintains the original document's structure and content with high fidelity. Extensive evaluations on benchmarks in cluding OmniDocBench, olmOCR-Bench, PubTabNet, and FinTabNet show that Infinity-Parser consistently achieves state-of-the-art performance across a broad range of document types, languages, and structural complexities, substantially outperforming both specialized document parsing systems and general-purpose vision-language models while preserving the model’s general multimodal understanding capability. ## Key Features - LayoutRL Framework: a reinforcement learning framework that explicitly trains models to be layout-aware through verifiable multi-aspect rewards combining edit distance, paragraph accuracy, and reading order preservation. - Infinity-Doc-400K Dataset: a large-scale dataset of 400K scanned documents that integrates high-quality synthetic data with diverse real-world samples, featuring rich layout variations and comprehensive structural annotations. - Infinity-Parser Model: a VLM-based parser that achieves new state-of-the-art performance on OCR, table and formula extraction, and reading-order detection benchmarks in both English and Chinese, while maintaining nearly the same general multimodal understanding capability as the base model. # Architecture Overview of Infinity-Parser training framework. Our model is optimized via reinforcement finetuning with edit distance, layout, and order-based rewards.  # Performance ## olmOCR-bench 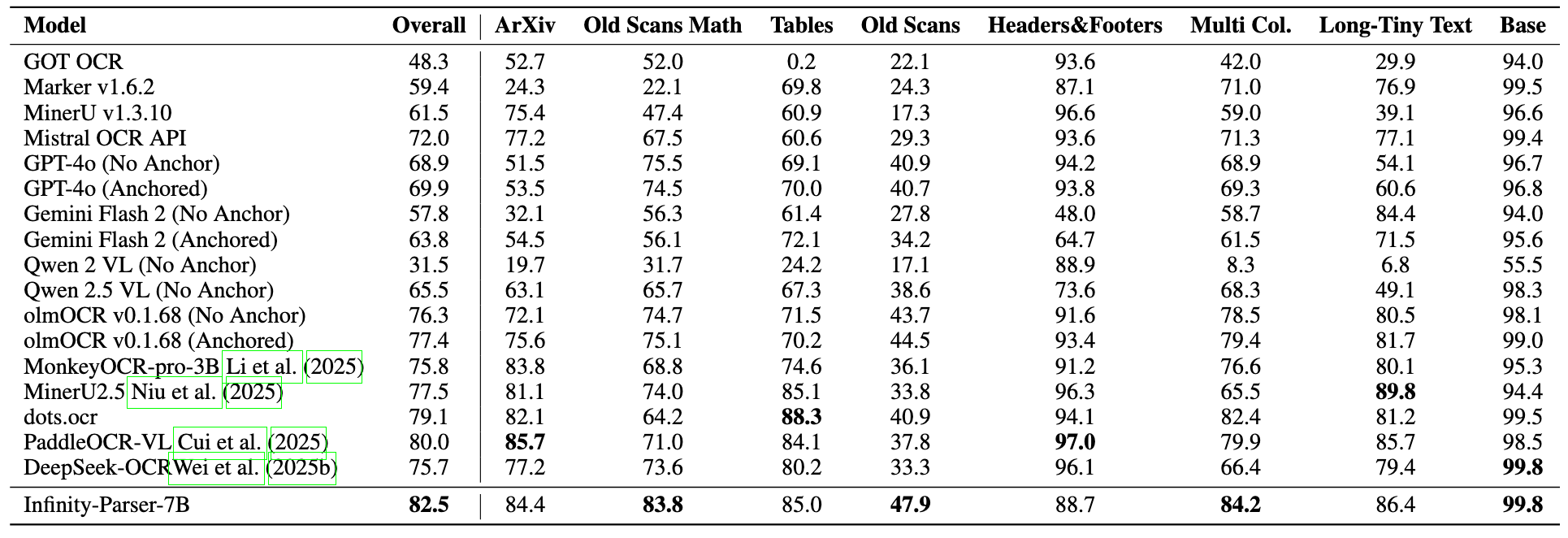 ## OmniDocBench 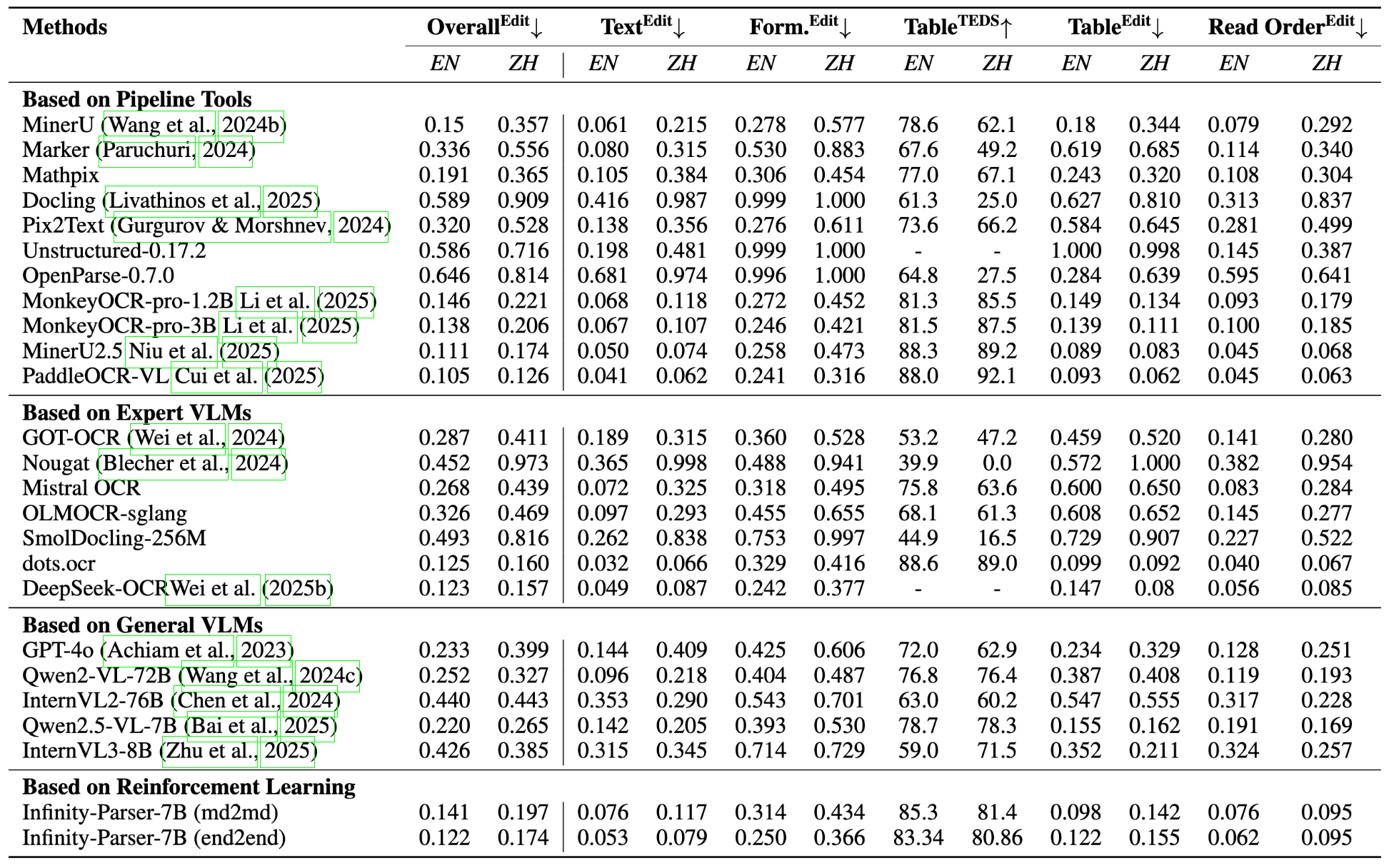 ## Table Recognition 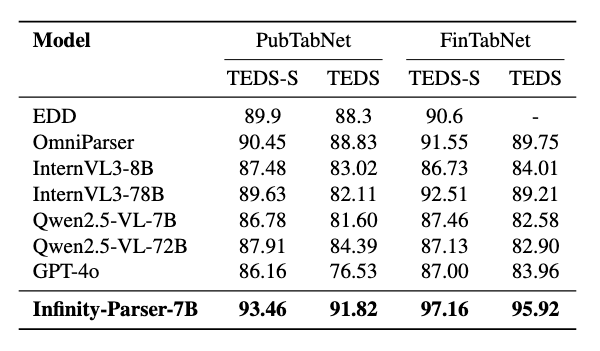 ## General Multimodal Capability Evaluation  > **Note:** The baseline model is **Qwen2.5-VL-7B**, and all metrics are evaluated using the **LMMS-Eval** framework. # Quick Start Please refer to Quick_Start. # Visualization ## Comparison Examples  # Synthetic Data Generation The generation code is available at Infinity-Synth. # Limitation & Future Work ## Limitations - **Layout / BBox**: The current model does not provide layout or bounding box (bbox) information, which limits its ability to support downstream tasks such as structured document reconstruction or reading order prediction. - **Charts & Figures**: The model lacks perception and understanding of charts and figures, and therefore cannot perform visual reasoning or structured extraction for graphical elements. ## Future Work We are dedicated to enabling our model to **read like humans**, and we firmly believe that **Vision-Language Models (VLMs)** can make this vision possible. We have conducted **preliminary explorations of reinforcement learning (RL) for document parsing** and achieved promising initial results. In future research, we will continue to deepen our efforts in the following directions: - **Chart & Figure Understanding**: Extend the model’s capability to handle chart detection, semantic interpretation, and structured data extraction from graphical elements. - **General-Purpose Perception**: Move toward a unified **Vision-Language perception model** that integrates detection, image captioning, OCR, layout analysis, and chart understanding into a single framework. # Acknowledgments We would like to thank [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL), [MinerU](https://github.com/opendatalab/MinerU), [MonkeyOCR](https://github.com/Yuliang-Liu/MonkeyOCR), [EasyR1](https://github.com/hiyouga/EasyR1), [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) [OmniDocBench](https://github.com/opendatalab/OmniDocBench), [dots.ocr](https://github.com/rednote-hilab/dots.ocr), for providing code and models. # Citation ``` @misc{wang2025infinityparserlayoutaware, title={Infinity Parser: Layout Aware Reinforcement Learning for Scanned Document Parsing}, author={Baode Wang and Biao Wu and Weizhen Li and Meng Fang and Zuming Huang and Jun Huang and Haozhe Wang and Yanjie Liang and Ling Chen and Wei Chu and Yuan Qi}, year={2025}, eprint={2506.03197}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2506.03197}, } ``` # License This model is licensed under apache-2.0.